El Gradiente de Riesgo entre los Patrones de AI

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Todo framework de gobernanza de AI comete eventualmente el mismo error: tratar toda la AI como igualmente peligrosa.
El resultado es predecible. Los equipos de gobernanza escriben políticas generales que aplican el mismo proceso de aprobación, el mismo ciclo de revisión y el mismo nivel de restricción a un chatbot que responde preguntas de políticas de RRHH y a un agente que puede emitir reembolsos en Stripe. El chatbot de RRHH muere en un ciclo de revisión de seis meses. El agente de reembolsos se lanza con controles débiles porque nadie lo distinguió del chatbot.
Ambos resultados son malos. La excesiva gobernanza de patrones de bajo riesgo mata la adopción y hace que los equipos de AI rodeen el proceso de gobernanza. La gobernanza insuficiente de patrones de alto riesgo causa los incidentes que aparecen en los titulares.
La solución es la gobernanza proporcional: ajuste sus controles al nivel de riesgo real de cada patrón, no a una idea genérica de "la AI es riesgosa." Eso comienza con entender dónde se ubica cada patrón en el gradiente de riesgo. El Framework de Gestión de Riesgos de AI del NIST recomienda exactamente este enfoque, gobernando, mapeando, midiendo y gestionando el riesgo de AI en contexto, escalado al caso de uso específico y sus consecuencias potenciales. Si todavía está familiarizándose con los 10 patrones principales, comience con qué es un patrón de AI primero.
Qué impulsa el riesgo en los patrones de AI
Tres factores determinan el nivel de riesgo base de un patrón.
Reversibilidad de las acciones Execute. Los patrones que no incluyen un paso Execute conllevan el menor riesgo: si la AI se equivoca, nada en el mundo externo ha cambiado. El humano lee la salida y decide si actuar. Los patrones que sí hacen Execute conllevan riesgo proporcional a cuán difícil es deshacer la acción. Actualizar un campo de CRM es fácilmente reversible. Enviar un email a un cliente es más difícil de revertir (puede enviar una corrección, pero no puede deshacer el envío). Emitir un reembolso, realizar un pedido o bloquear una transacción tiene el mayor costo de reversibilidad.
La Taxonomía de Riesgos de AI de Gartner 2025 clasifica la irreversibilidad como el multiplicador de riesgo único más alto en los frameworks de gobernanza de AI, por delante de la sensibilidad de los datos y la exposición regulatoria, porque los errores irreversibles escalan más rápido y se resisten a la corrección una vez que el bucle Execute se ha ejecutado en volumen.
Calibración de confianza de las salidas de Predict. Los patrones que dependen de Predict para impulsar el enrutamiento o las decisiones conllevan riesgo proporcional a qué tan bien calibrada está la confianza del modelo. Un modelo de lead scoring que dice "82% de probabilidad de conversión" debería equivocarse aproximadamente el 18% de las veces cuando puntúa leads al 82%. Si la calibración del modelo está desajustada (consistentemente demasiado confiado o poco confiado), cada decisión de enrutamiento posterior basada en esas puntuaciones se degrada. La confianza mal calibrada es invisible hasta que audita los resultados contra las predicciones.
Ubicación del humano en el bucle. El riesgo es menor cuando una puerta de revisión humana se ubica entre Generate y Execute. Es mayor cuando Execute se activa automáticamente según un umbral o regla. Y es más alto cuando Execute está dentro de un bucle, ejecutándose múltiples veces por objetivo, donde los errores tempranos se acumulan a través de pasos posteriores. El límite entre Generate y Execute es la decisión de diseño crítica para cualquier patrón que incluya Execute.
La Doctrina del Gradiente de Riesgo
La gobernanza de AI debe ser proporcional a la reversibilidad y autonomía del paso Execute de cada patrón, no uniforme en todos los sistemas de AI. Un patrón que lee y genera (Nivel 1) necesita registro de auditoría y capacitación de usuarios, no puertas de aprobación. Un patrón que ejecuta de forma autónoma en un bucle (Nivel 4) necesita límites de alcance, límites de velocidad, capacidad de reversión y supervisión humana al lanzamiento. Aplicar gobernanza de Nivel 4 a patrones de Nivel 1 mata la adopción sin reducir el riesgo. Aplicar gobernanza de Nivel 1 a patrones de Nivel 4 es la causa directa de los incidentes de AI que aparecen en los titulares.
Key Facts: Riesgo y Gobernanza de AI
- El 80% de las organizaciones han encontrado comportamientos riesgosos o inesperados de AI agents, con casi cada incidente rastreando de regreso a un paso Execute que se ejecutó sin validación adecuada corriente arriba (McKinsey, 2025)
- Las organizaciones que aplican gobernanza uniforme en todos los patrones de AI gastan 3 veces más en gastos generales de cumplimiento que aquellas que usan controles proporcionales al riesgo por niveles, mientras logran peores resultados de seguridad (Deloitte AI Governance Report, 2025)
- Los incidentes de AI que resultan en daño empresarial medible son 4,7 veces más probables de involucrar patrones Execute autónomos o automatizados que patrones Generate de solo lectura (Forrester AI Incident Analysis, 2025)
El espectro de riesgo: cuatro niveles

Nivel 1: Solo lectura, sin Execute
Patrones: RAG Assistant, Generative Research, Document Review
Estos patrones ingesan, analizan, generan y se detienen. Nada en el mundo externo cambia. La salida es un artefacto de texto (una respuesta, un informe, un conjunto de indicadores) que un humano lee, evalúa y actúa. Si la AI se equivoca, el humano lo detecta antes de que nada se confirme.
El RAG Assistant produce respuestas desde una base de conocimiento. Si recupera los pasajes incorrectos y genera una respuesta incorrecta, el humano que hace la pregunta lee una respuesta incorrecta. Eso es un problema. Pero es un problema contenido: una persona obtiene información incorrecta. Puede actuar en base a ella, o puede notar que es incorrecta y verificarla.
Generative Research sintetiza un informe de múltiples fuentes. Si atribuye incorrectamente una cita o saca una inferencia incorrecta, el lector obtiene un informe defectuoso. El riesgo escala con cuánto el lector confía y actúa en base a la salida sin verificación.
Document Review marca riesgos en contratos o políticas. Si pierde una cláusula no estándar, el equipo legal podría no detectarla. Ese riesgo es real, pero es un riesgo de omisión (indicador perdido), no de comisión (acción incorrecta tomada por la AI).
Riesgo base: Bajo. El control clave es el aseguramiento de calidad, no las puertas de gobernanza. Capacite a los usuarios para verificar las salidas importantes, especialmente para documentos de alto riesgo en Document Review. Mantenga registros de auditoría de consultas y salidas.
Nivel 2: Execute con aprobación humana
Patrones: Workflow Copilot, Meeting Intelligence, Vision Extract
Estos patrones incluyen Execute, pero con una puerta de aprobación humana que se ubica entre Generate y Execute en la implementación estándar.
Workflow Copilot redacta un email o una actualización de CRM. El humano revisa el borrador y hace clic en enviar. Execute se activa solo después de la aprobación humana. El riesgo está en lo que sucede cuando usted quita esa puerta de aprobación (que es lo primero que hacen los equipos cuando deciden que la AI es "suficientemente confiable para confiar"). Quitar la puerta convierte un patrón de Nivel 2 en algo más cercano al Nivel 3.
Meeting Intelligence genera resúmenes de llamadas y notas de CRM, a menudo con un paso de revisión del representante antes de que se envíen. En algunas implementaciones, el envío al CRM es automático. Cuando es automático, un mal resumen se convierte en un mal registro de CRM, lo que afecta los informes de pipeline, la precisión de las previsiones y la calidad del coaching. Ese es un resultado de riesgo medio.
Vision Extract envía registros estructurados a un sistema de registro. En la mayoría de las implementaciones, un humano verifica una muestra de registros antes de que se confirmen. Cuando la verificación se elimina (a menudo por razones de costo), los errores de extracción se convierten en errores de base de datos.
Riesgo base: Medio-bajo. El control de gobernanza principal es mantener la puerta de revisión humana y auditar lo que sucede cuando la elimina. Defina el manejo de excepciones: ¿qué hace el sistema con los registros que no puede extraer con confianza? Enrute a revisión manual, no a confirmación automática con baja confianza.
Nivel 3: Execute con reglas (sin aprobación humana por acción)
Patrones: Scoring plus Routing, Anomaly Agent, Personalization Engine
Estos patrones ejecutan automáticamente basándose en umbrales, reglas o salidas del modelo. No hay un humano aprobando cada acción individual. Un lead puntúa por encima de 80 y automáticamente se enruta al equipo enterprise. Una transacción puntúa como anómala y automáticamente se marca o bloquea. El historial de comportamiento de un usuario activa una recomendación de producto personalizada. Las acciones ocurren en volumen, continuamente, sin que un humano esté en el bucle en cada una.
El desafío de gobernanza: los controles están en la parte superior (calibración del modelo, configuración de umbrales, colas de excepciones) no en el punto de acción. Si el modelo de lead scoring está mal calibrado, el 20% de su pipeline de ingresos está enrutando al equipo incorrecto, y no lo verá hasta que audite los resultados. Si la línea base del anomaly agent es incorrecta, está bloqueando clientes legítimos o perdiendo fraude real. Ninguno de los errores es visible en tiempo real sin monitoreo.
Riesgo base: Medio-alto. Requisitos de gobernanza: umbrales de confianza definidos con colas de revisión humana para casos extremos, auditorías regulares del modelo comparando predicciones con resultados, procedimientos de reversión para cambios de reglas y manejo de excepciones documentado para elementos que caen por debajo del umbral de confianza. No establezca un umbral y lo olvide. Revise los umbrales trimestralmente basándose en datos de resultados.
Nivel 4: Execute en bucles, alta autonomía
Patrón: Autonomous Agent
El Autonomous Agent usa las cinco capacidades en un bucle, persiguiendo un objetivo a través de múltiples pasos y múltiples sistemas. Cada iteración del bucle puede incluir acciones Execute. Un error en un paso temprano (Analyze incorrecto, Predict mal calibrado) se propaga a través de cada acción Execute posterior en el bucle. Y el bucle se ejecuta de nuevo, y de nuevo, hasta que se alcanza el objetivo o el agente decide que no puede continuar.
Esto es categóricamente diferente de los otros niveles. El Workflow Copilot ejecuta una vez, con un humano revisando el borrador. El Autonomous Agent puede ejecutar 15 veces mientras completa una tarea de investigación y alcance, sin que ningún humano revise los pasos 2 al 14.
Los escenarios que causan daño real: un agente que investiga prospectos y envía emails de alcance a escala, equivocando el mapeo de cuentas y enviando mensajes inapropiados a la empresa incorrecta. Un agente que gestiona solicitudes de reembolso y emite reembolsos basándose en una regla de coincidencia defectuosa. Un agente que reserva tiempo en calendarios y crea tareas de CRM, ejecutando a través de una lista de 300 contactos, equivocando la integración del calendario y creando ruido en el horario de todo el equipo. McKinsey reporta que el 80% de las organizaciones han encontrado comportamientos riesgosos de AI agents, y los patrones anteriores representan precisamente los modos de fallo que aparecen en esos incidentes.
Riesgo base: Alto. Gobernanza requerida: límites de alcance explícitos (qué sistemas puede tocar el agente, qué acciones puede tomar), límites de velocidad en las acciones Execute (no más de X emails por hora, no más de $Y en reembolsos por día sin revisión humana), capacidad de reversión para acciones ejecutadas y supervisión humana requerida para la primera ejecución en producción antes de escalar. El límite de velocidad es el control más olvidado: convierte un posible error masivo en uno contenido y corregible.
Los 10 patrones en el gradiente
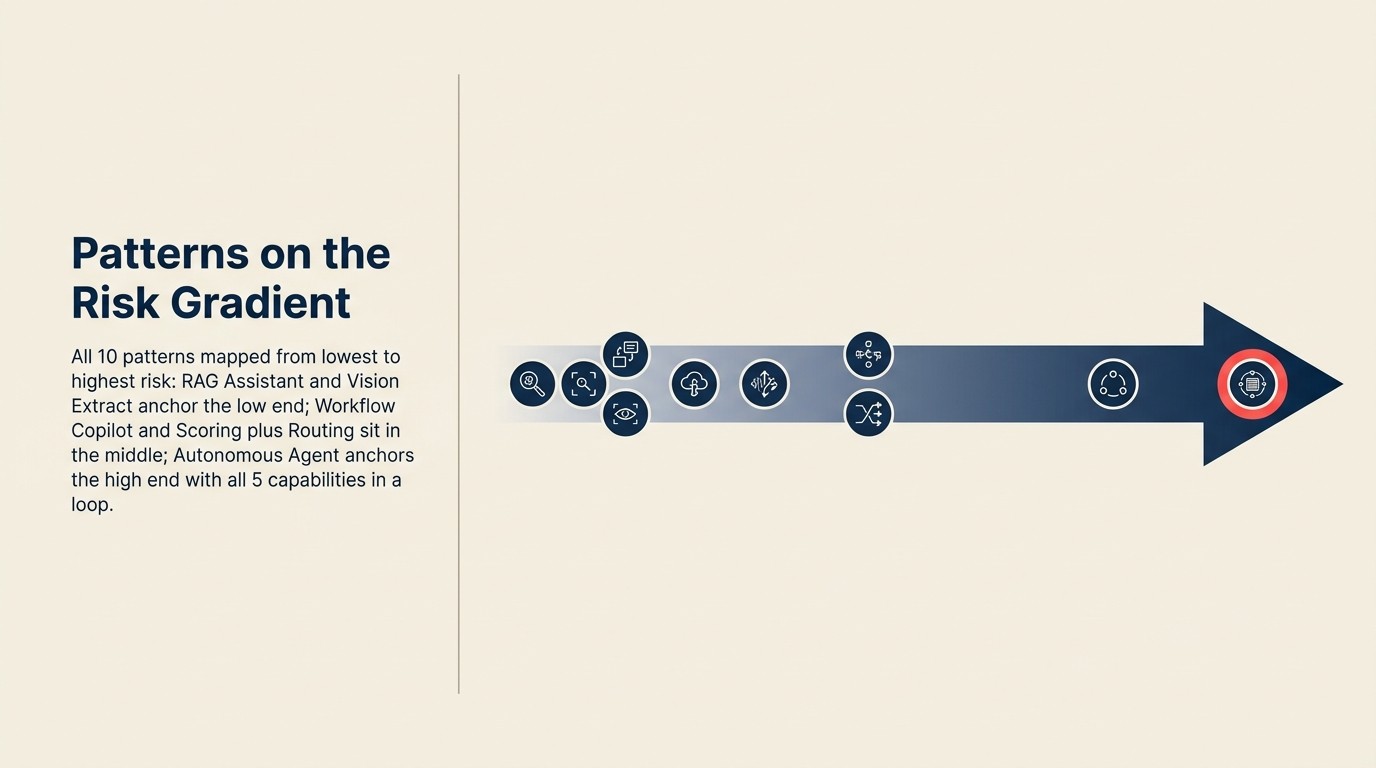
| Patrón | Nivel de riesgo | ¿Execute? | ¿Puerta humana? | Riesgo principal |
|---|---|---|---|---|
| RAG Assistant | Nivel 1 (Bajo) | No | N/A | Respuesta incorrecta o desactualizada |
| Generative Research | Nivel 1 (Bajo) | No | N/A | Síntesis incorrecta, fuentes mal atribuidas |
| Document Review | Nivel 1 (Bajo) | No | N/A | Indicadores perdidos (riesgo de omisión) |
| Workflow Copilot | Nivel 2 (Medio-bajo) | Sí, con control humano | Revisión antes de Execute | Eliminación de la puerta; borradores incorrectos confirmados |
| Meeting Intelligence | Nivel 2 (Medio-bajo) | Sí, a menudo con control humano | Revisión antes de envío | Notas inexactas en el sistema de registro |
| Vision Extract | Nivel 2 (Medio-bajo) | Sí, con control humano | Verificación antes de confirmación | Errores de extracción en base de datos |
| Scoring plus Routing | Nivel 3 (Medio-alto) | Sí, automático | Umbrales + cola de excepciones | Modelo mal calibrado enrutando a escala |
| Anomaly Agent | Nivel 3 (Medio-alto) | Sí, automático | Umbrales + cola de excepciones | Línea base incorrecta; falsos positivos o alertas perdidas |
| Personalization Engine | Nivel 3 (Medio-alto) | Sí, automático | Umbrales + monitoreo | Personalización discriminatoria; exposición de precios |
| Autonomous Agent | Nivel 4 (Alto) | Sí, en bucle | Límites de velocidad + supervisión inicial | Errores acumulados a través de pasos Execute |
Cómo el contexto del dominio multiplica el riesgo
El nivel anterior representa el riesgo base. El contexto del dominio es un multiplicador.
Un patrón Vision Extract que procesa tarjetas de presentación en un CRM es riesgo base de Nivel 2. Un campo incorrecto (número de teléfono con un dígito equivocado, nombre de empresa mal escrito) es un problema molesto de calidad de datos. Corregible.
El mismo patrón Vision Extract que lee formularios de admisión de pacientes y actualiza un sistema de registros médicos es un problema de gobernanza de Nivel 3. Un valor de campo incorrecto (medicamento incorrecto, alergia incorrecta, dosis incorrecta) en un registro de paciente puede afectar las decisiones clínicas. Misma fórmula de capacidades, dominio diferente, nivel de riesgo diferente.
Un patrón Scoring plus Routing que enruta leads de ventas entrantes es riesgo base de Nivel 3. Un modelo mal calibrado enruta algunos leads al equipo incorrecto. Impacto en ingresos, molesto, auditable.
El mismo patrón Scoring plus Routing aplicado a solicitudes de crédito es un problema de gobernanza de Nivel 4 en mercados regulados. ECOA, Fair Housing Act y GDPR Artículo 22 requieren explicabilidad y derechos de revisión humana para decisiones impulsadas por AI que afectan el acceso al crédito. La exposición regulatoria convierte un problema técnico de Nivel 3 en uno legal de Nivel 4.
Ajuste el nivel de cada patrón hacia arriba cuando: la salida afecta decisiones reguladas (crédito, empleo, vivienda, salud), los datos involucran información personal sensible, la acción Execute es financiera o legalmente consecuente, o la escala de la acción automatizada hace que los errores sean difíciles de detectar antes de que se acumulen.
Subestimaciones comunes de riesgo por patrón
Scoring plus Routing se siente seguro porque "solo enruta cosas." Las decisiones de enrutamiento a escala son decisiones de ingresos. Si su modelo de lead scoring se equivoca sobre qué leads son de alta prioridad, sus mejores representantes están trabajando las cuentas incorrectas. Si su enrutador de tickets de soporte clasifica incorrectamente la urgencia, los clientes enterprise esperan en la cola estándar. Estos no son riesgos abstractos. Son medibles: verifique la distribución de actividad de sus representantes, las tasas de incumplimiento de SLA y la precisión de enrutamiento mensualmente.
Personalization Engine parece benigno porque es solo "mostrar contenido relevante." Los precios personalizados (mostrar diferentes precios a diferentes usuarios) pueden crear exposición legal bajo las leyes de protección al consumidor en varias jurisdicciones, particularmente cuando la personalización se correlaciona con características protegidas. Las ofertas de empleo personalizadas que excluyen ciertos grupos demográficos basadas en targeting de comportamiento han sido objeto de investigaciones de la EEOC y de la UE. "Solo estamos personalizando contenido" no es una respuesta de gobernanza.
Workflow Copilot parece de bajo riesgo porque un humano revisa todo. Hasta que el humano deja de revisar. La puerta de revisión es toda la estructura de gobernanza para este patrón. Cuando los equipos deciden que la AI es "suficientemente buena" y eliminan el paso de revisión, acaban de desplegar un Execute automatizado sin controles de gobernanza de Nivel 3. La transición debe ser deliberada y documentada, no un cambio de proceso silencioso.
Requisitos de gobernanza por nivel

Nivel 1: Registros de auditoría de consultas y salidas. Proceso de revisión de calidad (muestreo periódico de salidas por un revisor humano). Capacitación de usuarios sobre las expectativas de verificación (los casos de uso de alto riesgo requieren verificación independiente). No se necesitan puertas de aprobación para el uso estándar.
Nivel 2: Mantener las puertas de revisión humana como política explícita. Documentar qué flujos de trabajo tienen confirmación automática habilitada frente a revisión requerida. Tasas de verificación de muestras para registros confirmados automáticamente. Enrutamiento de excepciones para salidas de baja confianza.
Nivel 3: Monitoreo de precisión del modelo con auditorías periódicas de resultados (comparar predicciones con resultados reales). Umbrales de confianza con colas de excepciones para elementos por debajo del umbral. Revisión trimestral de umbrales basada en datos de resultados. Documentación de reglas de enrutamiento y rutas de escalación. Alerta sobre la desviación del modelo.
Nivel 4: Límites de alcance explícitos documentados y aplicados a nivel del sistema (no solo en política). Límites de velocidad en las acciones Execute. Capacidad de reversión para revertir acciones ejecutadas. Supervisión humana requerida para la primera ejecución en producción. Implementación por etapas (comience con cuentas o casos de uso de bajo riesgo antes de escalar). Plan de respuesta a incidentes para cuando el agente toma una acción incorrecta a escala.
Construir su registro de riesgos
Un registro de riesgos para patrones de AI activos no necesita ser complejo. Para cada patrón actualmente en producción, documente:
- Nombre del patrón y caso de uso específico (por ejemplo, "Scoring plus Routing para la asignación de leads entrantes")
- Nivel de riesgo (1-4)
- Multiplicadores de dominio (¿datos regulados? ¿consecuencia financiera? ¿datos personales sensibles?)
- Responsable (quién es responsable de monitorear la precisión y gobernanza de este patrón)
- Frecuencia de revisión (Nivel 1: anual; Nivel 2: trimestral; Nivel 3: mensual; Nivel 4: semanal hasta que sea estable)
- Controles actuales (qué está realmente en su lugar)
- Brechas conocidas (qué debería estar en su lugar y no lo está)
El registro es un documento vivo. A medida que agrega patrones, ajusta dominios o cambia configuraciones, actualícelo. El punto no es la perfección: es que alguien sea dueño de la postura de riesgo de cada patrón y la revise según un horario.
Rework Analysis: El error de gobernanza que vemos con más frecuencia es organizaciones que escriben una política de AI que aplica uniformemente a todos los sistemas de AI. La política termina calibrada al patrón más peligroso en producción (a menudo un autonomous agent o un sistema de enrutamiento automatizado) y aplicada a todo. El resultado: los RAG Assistants de bajo riesgo se bloquean en revisiones de seguridad de seis meses mientras los Autonomous Agents de alto riesgo que están lanzando solo tienen una revisión de casilla. La gobernanza por niveles, ajustada al riesgo Execute real de cada patrón, cuesta menos y controla más. El modelo de cuatro niveles anterior le da a los equipos de riesgo y cumplimiento el vocabulario para escribir reglas proporcionales en lugar de generales.
Preguntas Frecuentes
¿Qué es el gradiente de riesgo entre los patrones de AI?
El gradiente de riesgo clasifica los patrones de AI desde el Nivel 1 (solo lectura, sin Execute) hasta el Nivel 4 (bucles autónomos con pasos Execute repetidos). Los patrones de Nivel 1 como RAG Assistant y Generative Research conllevan bajo riesgo porque la AI produce salida de texto en la que un humano actúa. Los patrones de Nivel 4 como Autonomous Agent conllevan alto riesgo porque Execute se activa múltiples veces por objetivo sin revisión humana, y los errores se acumulan a través de los pasos.
¿Qué hace que un patrón de AI sea de alto riesgo?
Tres factores impulsan el riesgo del patrón de AI: la reversibilidad de las acciones Execute (cuán difícil es deshacer lo que hizo la AI), la calibración de confianza de las salidas de Predict (si las puntuaciones reflejan con precisión la probabilidad real) y la ubicación del humano en el bucle (si un humano revisa las salidas antes de que se active Execute). El Análisis de Incidentes de AI de Forrester 2025 encontró que los incidentes de AI que involucran patrones Execute son 4,7 veces más propensos a causar daño empresarial medible que los incidentes que involucran patrones Generate de solo lectura.
¿Cómo debe escalar la gobernanza entre los niveles de riesgo de patrones de AI?
Los patrones de Nivel 1 necesitan registro de auditoría y capacitación de usuarios sobre expectativas de verificación. Los patrones de Nivel 2 necesitan puertas de revisión humana mantenidas y enrutamiento de excepciones para salidas de baja confianza. Los patrones de Nivel 3 necesitan monitoreo de precisión del modelo, umbrales de confianza con colas de excepciones y auditorías trimestrales de resultados. Los patrones de Nivel 4 necesitan límites de alcance, límites de velocidad en las acciones Execute, capacidad de reversión y supervisión humana durante las ejecuciones iniciales en producción.
¿Por qué el patrón Workflow Copilot es de menor riesgo que Scoring plus Routing?
Workflow Copilot incluye una puerta de aprobación humana explícita entre Generate y Execute: la AI redacta, el humano aprueba antes de que nada se envíe o confirme. Scoring plus Routing ejecuta automáticamente a escala basándose en puntuaciones del modelo, sin revisión humana por acción. El riesgo en Workflow Copilot escala con la eliminación de la puerta. El riesgo en Scoring plus Routing escala con la mala calibración del modelo, que es invisible hasta que se auditan los resultados.
¿Qué es la Doctrina del Gradiente de Riesgo?
La Doctrina del Gradiente de Riesgo establece que la gobernanza de AI debe ser proporcional a la reversibilidad y autonomía del paso Execute de cada patrón, no uniforme en todos los sistemas de AI. Aplicar los mismos controles a un RAG Assistant de solo lectura y a un Autonomous Agent al mismo tiempo gobierna de manera excesiva los sistemas de bajo riesgo y de manera insuficiente los de alto riesgo. La gobernanza por niveles ajustada al perfil Execute real de cada patrón cuesta menos y controla más que la política de AI general.
¿El contexto del dominio afecta el nivel de riesgo de un patrón?
Sí. El contexto del dominio es un multiplicador del riesgo base. Vision Extract que procesa tarjetas de presentación es riesgo base de Nivel 2. El mismo patrón que actualiza registros médicos que contienen datos de alergias o medicamentos es un problema de gobernanza de Nivel 4 porque los errores afectan directamente las decisiones clínicas. De manera similar, Scoring plus Routing para la asignación de leads es Nivel 3, pero el mismo patrón aplicado a decisiones de crédito activa obligaciones regulatorias bajo ECOA y GDPR Artículo 22 que lo llevan al Nivel 4.
Aprenda más
- Requisitos de Gobernanza por Patrón de AI
- Riesgo de Alucinación por Patrón de AI
- Autonomous Agent: Objetivos de Múltiples Pasos con Uso de Herramientas
- Cómo Elegir el Patrón de AI Correcto para su Problema
- El Límite Generate vs. Execute: Por Qué Importan las Barreras
- El Patrón Meeting Intelligence
- Midiendo el ROI del Patrón de AI

Co-Founder, Rework.com
On this page
- Qué impulsa el riesgo en los patrones de AI
- La Doctrina del Gradiente de Riesgo
- El espectro de riesgo: cuatro niveles
- Nivel 1: Solo lectura, sin Execute
- Nivel 2: Execute con aprobación humana
- Nivel 3: Execute con reglas (sin aprobación humana por acción)
- Nivel 4: Execute en bucles, alta autonomía
- Los 10 patrones en el gradiente
- Cómo el contexto del dominio multiplica el riesgo
- Subestimaciones comunes de riesgo por patrón
- Requisitos de gobernanza por nivel
- Construir su registro de riesgos
- Aprenda más