KI-Sales-Ops-Governance und Audit Trails

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Das ACE Framework zieht eine klare Linie zwischen Generate und Execute. Der Artikel zur Generate-vs.-Execute-Grenze erklärt, warum diese Unterscheidung für ein sicheres KI-Deployment grundlegend ist. Generate produziert einen Entwurf, der zur Überprüfung vorliegt. Execute ändert den Status in der Welt: es sendet die E-Mail, aktualisiert den CRM-Datensatz, leitet den Lead weiter. Diese Linie ist wichtig, weil Execute Konsequenzen hat, die sich nicht sauber rückgängig machen lassen.
In KI-Sales-Ops passieren Execute-Aktionen dutzendfach täglich ohne menschliche Augen auf jeder: Lead-Routing-Zuteilungen, automatische CRM-Feld-Updates, Scoring-Entscheidungen, die bestimmen, welche Leads priorisiert werden, automatisierte Follow-up-Sequenzen, ausgelöst durch Gesprächsprotokolle. Meistens sind diese Entscheidungen korrekt. Wenn sie es nicht sind, muss die Organisation wissen, was passiert ist, warum und wer verantwortlich war.
Governance in KI-Sales-Ops ist keine Bürokratie. Sie ist der Grund, warum die Organisation der KI genug vertraut, ihr im Laufe der Zeit mehr Autonomie zu geben. Ein Team, das nicht erklären kann, warum ein Lead an einen bestimmten Rep weitergeleitet wurde, wird diese Weiterleitung schließlich in einem Vergütungsstreit, einem Bias-Audit oder einer Compliance-Review in Frage gestellt haben. Ein Team, das das Entscheidungsprotokoll, die Modellversion und den Eingabedaten-Status zeigen kann, hat etwas, worauf es stehen kann.
Was im Vier-Muster-Stack Governance benötigt
Key Facts: KI-Governance-Risiko und Compliance in 2026
- DSGVO-Bußgelder übersteigen nun kumulativ 7,1 Milliarden Euro, mit 1,2 Milliarden Euro allein in 2025. Mehr als 60 % des Gesamtbetrags wurde seit Januar 2023 verhängt, was die beschleunigte Durchsetzung im Zuge der wachsenden KI-Adoption widerspiegelt. (Kiteworks, 2026)
- 54 % der Vorstände sind nicht aktiv in die KI-Governance eingebunden, was erhebliches organisatorisches Risiko für KI-Sales-Ops-Deployments schafft, die persönliche Daten betreffen. (Improvado, 2025)
- SOC-2-Typ-II-Zertifizierung ist nun eine De-facto-Anforderung für KI-Plattform-Verträge über 50.000 Dollar, was bedeutet, dass nicht geprüfte KI-Tools Beschaffungsverzögerungen sowie Compliance-Risiken schaffen. (MindStudio, 2025)
Nicht jede KI-Aktion trägt dasselbe Risiko. Einen Draft-E-Mail-Vorschlag zu generieren, den ein Rep liest und verwirft, hat niedrige Einsätze. Eine Follow-up-E-Mail automatisch an einen Interessenten zu senden ohne Rep-Review hat hohe Einsätze. Das Governance-Modell muss zwischen ihnen unterscheiden.
Hier ist, was jedes Muster produziert, das potenziell Governance benötigt:
Scoring and Routing (Muster 1):
- Lead-Score: eine numerische Ausgabe (z. B. 87/100), die die Priorisierung bestimmt
- Routing-Zuteilung: welcher Rep oder welches Team den Lead erhält
- Deprioritisierungs-Entscheidungen: Leads, die niedrig genug bewertet werden, um zu Nurture vs. bearbeitet zu werden
Die Routing-Entscheidung hat direkte Rep-Vergütungs-Implikationen, wenn Ihr Team territory-basierte oder lead-volumen-basierte Vergütungsstrukturen verwendet. Sie hat auch potenzielle DSGVO-Artikel-22-Implikationen, wenn das Scoring persönliche Daten über die bewertete Person einbezieht. Der Artikel zu Governance-Anforderungen nach KI-Muster kartiert diese Pflichten über alle 10 Muster, nicht nur Scoring and Routing.
Meeting Intelligence (Muster 2):
- Recording-Zustimmungs-Log: wurde Zustimmung erhalten, durch welchen Mechanismus, zu welchem Zeitpunkt?
- CRM-Auto-Write: welche Protokolldaten wurden automatisch in welche Felder geschrieben?
- Coaching-Datenzugriff: welche Manager haben auf welche Anrufaufzeichnungen von Reps zugegriffen?
Aufzeichnen ohne Zustimmung ist eine Rechtsverletzung in mehreren Rechtsordnungen. Das Zustimmungs-Log ist ein Compliance-Artefakt, kein bloßes operatives Protokoll.
Generative Research (Muster 3):
- Research-Brief-Quell-Attribution: welche Datenquellen wurden für die Generierung des Briefings verwendet?
- Datenlizenz-Compliance: wurden die Nutzungsbedingungen der Quell-Anbieter eingehalten?
Research-Briefings sind niedrigriskante Execute-Aktionen, weil sie typischerweise menschliche Entscheidungen informieren statt automatisierte auslösen. Die Governance-Anforderung ist leichter, aber Quell-Attribution ist wichtig, wenn ein Briefing falsche Informationen enthält, die eine Vertriebsentscheidung beeinflussen.
Workflow Copilot (Muster 4):
- NBA-Vorschläge, die Reps gezeigt wurden: was wurde vorgeschlagen, wurde es ausgeführt?
- Auto-erstellte E-Mails: was war der Prompt-Input, was wurde generiert, was hat der Rep geändert, was wurde gesendet?
- CRM-Hygiene-Auto-Updates: welche Felder wurden automatisch geändert, von welchem Wert zu welchem Wert?
- Pipeline-Review-Daten: wie wurden Risiko-Flags generiert, welche Dateneingaben lösten sie aus?
Die drei Governance-Modelle
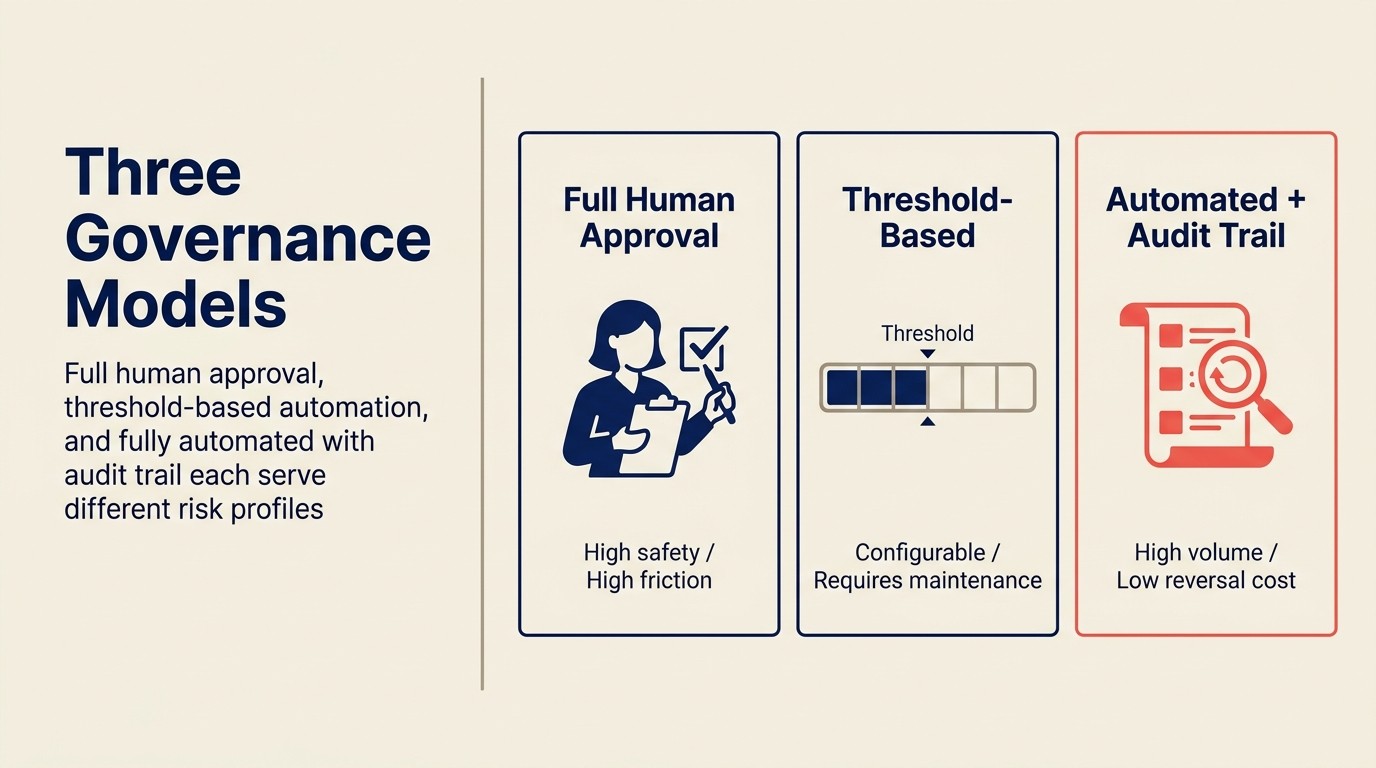
Für jede Execute-Aktion in Ihrem KI-Stack müssen Sie eines von drei Governance-Modellen wählen:
Vollständige menschliche Genehmigung
Jede KI-generierte Aktion erfordert explizite menschliche Genehmigung vor der Ausführung.
Wann verwenden: Hochriskante Aktionen (E-Mails an Enterprise-Interessenten, vergütungsbeeinflussende Routing-Entscheidungen), rechtlich sensible Kontexte, früh in einem KI-Deployment, wenn Sie noch Vertrauen in das Modell aufbauen.
Trade-off: Hohe Sicherheit, hohe Reibung. Reps werden zu Engpässen. Die Zeitersparnis der KI wird teilweise durch die Genehmigungslast aufgewogen. Für einen Copilot, der täglich 20 E-Mail-Entwürfe generiert, macht das Erfordern vollständiger Genehmigung bei jedem ein zeitersparendes Tool zu einer kognitiven Belastung.
Praktisches Setup: Genehmigungswarteschlange im CRM oder E-Mail-Tool. KI generiert, Mensch überprüft, Klick zum Senden/Committen. Setzen Sie eine 24-Stunden-SLA für Genehmigungen, damit generierte Aktionen nicht in der Warteschlange sitzen, bis sie veraltet sind.
Schwellenwert-basierte Automatisierung
Aktionen unterhalb eines Konfidenz-Schwellenwerts (oder unterhalb eines Risiko-Schwellenwerts) werden automatisch ausgeführt. Aktionen oberhalb des Schwellenwerts erfordern menschliche Genehmigung.
Wann verwenden: Die meisten ausgereiften KI-Sales-Ops-Stacks. Die Schwellenwert-Kalibrierung ist die entscheidende Variable.
Beispiel: Lead-Routing. Leads mit Score über 80 UND mit einer einzelnen klaren Territory-Regel: auto-routen. Leads mit Score zwischen 40-80 ODER mit einer gemeinsamen Territory-Regel: in die Sales-Ops-Review-Warteschlange. Leads mit Score unter 40: auto-routen zu Nurture. So werden die klaren Fälle automatisiert; die mehrdeutigen erhalten menschliches Urteilsvermögen.
Trade-off: Erfordert laufende Schwellenwert-Wartung. Wenn die Modellgenauigkeit verbessert, können Sie den Auto-Execute-Schwellenwert erhöhen. Wenn sich Ihr Unternehmen ändert (neue Territorien, neue Produkte), müssen die Schwellenwerte überprüft werden. Jemand muss das besitzen.
Praktisches Setup: Schwellenwert-Konfiguration in Ihrer KI-Plattform. Monitoring-Dashboard, das das Genehmigungswarteschlangen-Volumen zeigt (wenn die Warteschlange dauerhaft groß ist, sind die Schwellenwerte zu konservativ; wenn die Genehmigungsqualität abnimmt, sind die Schwellenwerte zu aggressiv).
Vollautomatisiert mit Audit Trail
Aktionen werden automatisch ausgeführt. Alles wird protokolliert. Menschliche Überprüfung findet nachträglich statt, durch regelmäßige Revision statt Genehmigung pro Aktion.
Wann verwenden: Hochkonfidens-, Hochvolumen-, Niedrigrückgängigmach-Kosten-Aktionen. CRM-Feld-Vervollständigung aus Protokollen. Lead-Quelle taggen. "Zuletzt kontaktiert"-Zeitstempel aktualisieren. Aktionen, bei denen die Kosten des Falschliegens niedrig sind und manuelle Überprüfung mehr Last schaffen würde als Wert.
Nicht geeignet für: Vergütungsbeeinflussende Aktionen, Aktionen mit regulierten persönlichen Datenentscheidungen, kundenorientierte Kommunikation.
Praktisches Setup: Umfassendes Audit-Log mit wöchentlicher Überprüfung durch den Sales-Ops-Manager. Alert-Regeln für Anomalie-Muster (z. B. wenn mehr als 5 % der auto-gerouteten Leads in einer Woche manuell neu zugewiesen werden, ist das ein Signal, dass das Modell driftet).
DSGVO-Durchsetzung gegen KI-gesteuerte automatisierte Entscheidungen beschleunigt sich. Eine Berliner Bank wurde 2023 mit 300.000 Euro bestraft, weil sie einen Kandidaten nicht transparent über die Begründung einer automatisierten Kreditantrags-Ablehnung informiert hatte. B2B-Sales-Ops-Teams, die Leads automatisch basierend auf Scoring ohne Erklärungsdokumentation routen, sind strukturell ähnlich.
Der 4-Muster-Audit-Log-Standard
Der 4-Pattern Audit Log Standard spezifiziert den Mindest-Feldsatz, der für einen verteidigbaren Audit Trail für jedes der vier KI-Sales-Ops-Muster erforderlich ist. Für Scoring and Routing: Zeitstempel, Aktionstyp, Lead-ID, Modellversion, Eingabe-Features mit Werten, Ausgabe-Score, zugewiesener Rep, betrachtete Alternativen und Override-Flag. Für Meeting Intelligence: Aufzeichnungs-Zeitstempel, Zustimmungsmethode und Zeitstempel, geschriebene CRM-Felder, Werte vor und nach, Rep-Zugriffs-Log. Für Generative Research: Brief-Generierungs-Zeitstempel, verwendete Datenquellen, Brief-Content-Hash, Zustellungskanal. Für Workflow Copilot: Vorschlagstyp, Auslösebedingung, Eingabezustand, generierter Inhalt, Rep-Aktion (akzeptiert/abgelehnt/geändert), endgültiges Ergebnis. Organisationen mit diesen vier Audit-Logs können auf jeden Routing-Streit, jede Compliance-Anfrage oder jede Modellgenauigkeits-Review reagieren, ohne Entscheidungen aus dem Gedächtnis zu rekonstruieren.
Audit-Trail-Feld-Spezifikation
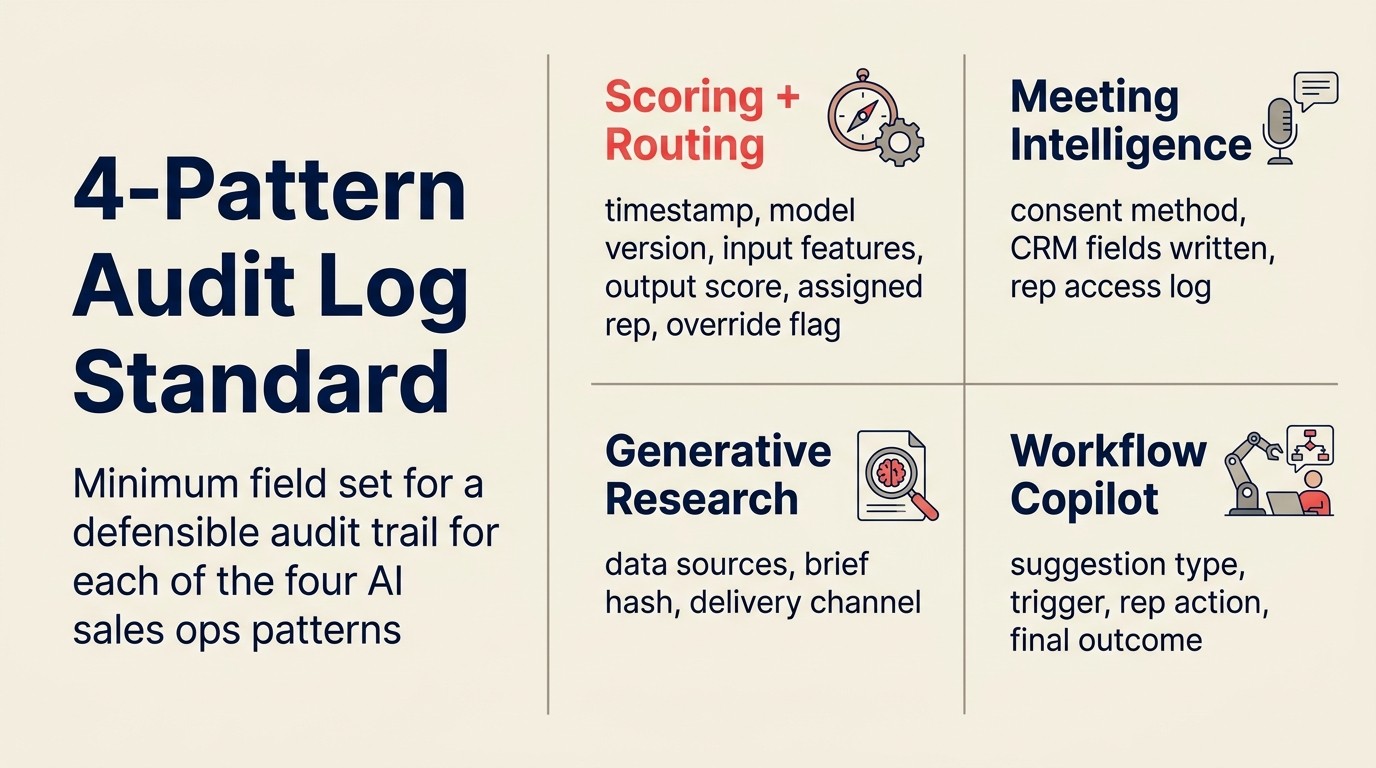
Ein guter Audit Trail für eine KI-Sales-Ops-Aktion enthält die folgenden Felder. Das ist das Minimum für eine verteidigbare Governance; Enterprise-Compliance kann zusätzliche Felder erfordern:
Für eine Lead-Scoring-Entscheidung:
timestamp: 2026-05-19T09:23:14Z
action_type: lead_score
lead_id: CRM-1234567
model_id: scoring-model-v2.3
model_version_date: 2026-03-01
input_features: {
company_size: "50-200",
industry: "SaaS",
title: "VP of Operations",
intent_score: 72,
website_visits_30d: 4,
email_opens_30d: 3
}
output_score: 87
confidence: 0.91
action_taken: routed_to_rep_sarah_jones
alternatives_considered: [rep_alex_chen (score 0.87), rep_michael_kim (score 0.84)]
human_reviewer: null
override: false
Für einen auto-erstellten E-Mail-Entwurf:
timestamp: 2026-05-19T14:11:02Z
action_type: email_draft
deal_id: CRM-DEAL-98765
prompt_inputs: {
contact_name: "Jennifer Wu",
last_call_summary: "discussed budget approval timeline",
days_since_last_contact: 5,
deal_stage: "Proposal Sent"
}
generated_text: "[vollständiger Entwurfstext]"
rep_edits: "[was der Rep vor dem Senden geändert hat]"
final_sent_text: "[tatsächlich gesendeter Text]"
rep_id: REP-44
sent: true
sent_timestamp: 2026-05-19T14:38:22Z
Für eine Routing-Zuteilung:
timestamp: 2026-05-19T10:05:33Z
action_type: lead_route
lead_id: CRM-9876543
routing_rule_applied: "territory_rule_northeast_enterprise"
input_state: {
lead_location: "Boston, MA",
company_size: "500-1000",
lead_score: 87,
product_interest: ["Sales Ops", "Work Ops"]
}
assigned_to: REP-12 (Sarah Jones)
alternatives_evaluated: [REP-15, REP-22]
reason: "territory match + highest capacity score"
human_override: false
override_by: null
Diese Datensätze müssen nicht in einem maßgefertigten System leben. Die meisten CRM-Plattformen können benutzerdefinierte Log-Datensätze speichern. Eine dedizierte Audit-Tabelle in Salesforce oder eine Webhook-Logging-Service-Architektur funktioniert für die meisten Mid-Market-Teams.
Modell-Versionierung und Change Management
Wenn Sie ein Scoring-Modell neu trainieren oder aktualisieren, muss der Audit Trail verfolgen, welche Modellversion welche Entscheidung getroffen hat. Das ist nicht optional.
Grund: Angenommen, Ihr Scoring-Modell von März 2026 (v2.1) wurde später als zu stark auf Unternehmensgröße überangepasst gefunden, mit Untergewichtung von Intent-Signalen. Sie trainieren im Mai 2026 (v2.3) mit korrigierten Feature-Gewichten neu. Wenn ein Rep eine Lead-Routing-Entscheidung aus April 2026 bestreitet, müssen Sie zeigen können, welches Modell diese Entscheidung getroffen hat, was seine Feature-Gewichte waren und warum die Entscheidung angesichts der damals verfügbaren Informationen verteidigbar war.
Ohne Modell-Versionierung im Audit-Log können Sie diese Frage nicht beantworten. Sie können nur die aktuelle Modell-Logik zeigen, die sich möglicherweise geändert hat.
Modell-Governance-Mindestanforderungen:
- Jedes Modell-Deployment erhält einen Versions-Identifier und ein Deployment-Datum
- Alle Scoring-Entscheidungen werden mit der Modellversion protokolliert, die sie produziert hat
- Modell-Changelog, der dokumentiert, was zwischen Versionen geändert wurde und warum
- Vierteljährliche Genauigkeits-Review, die die Modellversions-Performance auf Holdout-Deals vergleicht
Der Routing-Streit-Prozess
Wenn ein Rep glaubt, er wurde einem Lead falsch zugewiesen (oder nicht zugewiesen), muss es einen definierten Prozess geben. Ohne einen werden Streitigkeiten informell, unverfolgt und anfällig für Eskalation.
Ein funktionierender Drei-Schritte-Routing-Streit-Prozess:
Schritt 1: Rep reicht einen Routing-Streit ein. Strukturiertes Formular im CRM: Lead-ID, Datum der Routing-Entscheidung, Grund für den Streit (Territory-Mismatch, Kapazitäts-Ungleichgewicht, präferenzbasierter Anspruch). Ein präferenzbasierter Anspruch ("Ich wollte diesen Lead") ist ein schwacher Streit. Ein Territory-Mismatch-Anspruch ("Dieser Lead ist in meinem Territory gemäß der Q1-Territory-Karte") ist ein starker Streit.
Schritt 2: Sales-Ops-Manager überprüft. Innerhalb von 48 Stunden. Überprüft das Audit-Log: welche Regel das Routing ausgelöst hat, welche Eingaben verwendet wurden, ob die Regel korrekt angewendet wurde. Wenn die Regel korrekt angewendet wurde und die Territory-Karte korrekt war, wird der Streit gegen den Rep gelöst. Wenn es eine Regel-Mehrdeutigkeit oder eine Territory-Karten-Diskrepanz gibt, kann der Streit bestätigt werden.
Schritt 3: Entscheidung wird protokolliert. Ob bestätigt oder abgewiesen, das Ergebnis geht in das Audit-Log verknüpft mit dem ursprünglichen Routing-Ereignis. Wenn bestätigt, werden die Modell-Eingaben zur Überprüfung geflaggt (war das ein Grenzfall, den das Modell anders behandeln sollte?). Wenn abgewiesen mit einem gültigen Regelstreit (z. B. die Territory-Karte war mehrdeutig), wird die Territory-Karte aktualisiert, um eine Wiederholung zu verhindern.
Dieser Prozess schützt sowohl die Organisation als auch den Rep. Er schafft Rechenschaftspflicht für Routing-Entscheidungen und gibt Reps einen legitimen Kanal für gültige Streitigkeiten, ohne die Tür für Manipulation zu öffnen.
Datenschutz in KI-Sales-Ops
Drei Compliance-Frameworks gelten für KI-Sales-Ops in den meisten Mid-Market-Unternehmen. Wissen Sie, welche gelten, bevor Sie deployen.
DSGVO-Artikel 22 (EU-Datenschutzbetroffene): Wenn Ihr KI-System automatisierte Entscheidungen trifft, die Einzelpersonen erheblich betreffen, und diese Personen EU-Datenschutzbetroffene sind, kann Artikel 22 gelten. Lead-Routing-Entscheidungen basierend auf automatisiertem Scoring könnten in den Anwendungsbereich fallen, wenn die Entscheidung eine wesentliche Wirkung auf die Person hat (z. B. Beeinflussung ihres Zugangs zu Dienstleistungen oder ihrer Behandlung durch ein Unternehmen). Die relevanten Verpflichtungen umfassen: das Recht auf menschliche Überprüfung, eine Erklärung der Entscheidungslogik und das Recht, die Entscheidung anzufechten. DSGVO-Artikel 22 zur automatisierten Entscheidungsfindung ist die spezifische Bestimmung, die mit Ihrem Rechtsteam überprüft werden muss. Viele B2B-Sales-Ops-Teams argumentieren, dass ihr Lead-Routing den "erheblichen Effekt"-Schwellenwert für Artikel 22 nicht erfüllt. Eine Rechts-Review ist erforderlich, keine Annahme.
SOX (Sarbanes-Oxley, für US-amerikanische börsennotierte Unternehmen): Wenn KI-gesteuerte Forecasting oder Pipeline-Management wesentliche Umsatzerkennungs-Entscheidungen beeinflusst, können SOX-interne Kontrollen gelten. Insbesondere Abschnitt 302 (Offenlegungskontrollen) und Abschnitt 404 (interne Kontrollen über die Finanzberichterstattung) verlangen, dass das Management die Wirksamkeit der Kontrollen über die Finanzberichterstattung bewertet und bestätigt. Ein KI-System, das Umsatzprognose-Daten ohne angemessene Dokumentation und Tests von Kontrollen beeinflusst, ist ein potenzielles SOX-Risiko. Börsennotierte Unternehmen, die KI-Forecasting deployen, sollten ihre internen Audit- und externen Audit-Teams frühzeitig einbeziehen.
EU-KI-Gesetz (alle EU-Markt-Unternehmen, 2026-2027): Verordnung (EU) 2024/1689, das EU-KI-Gesetz, trat im August 2024 in Kraft und gilt mit gestaffelten Compliance-Fristen bis 2027. KI-Systeme, die bei der Einstellung, dem Mitarbeitermanagement oder dem Zugang zu Dienstleistungen eingesetzt werden, fallen in höhere Risikokategorien, die Konformitätsbewertungen und Dokumentationsanforderungen erfordern. B2B-Sales-Ops-Teams, die auf EU-Märkten tätig sind, sollten beurteilen, welche Bestimmungen auf ihre KI-Scoring- und Routing-Systeme vor der Compliance-Frist im August 2026 anwendbar sind.
MAR/MiFID-II (Finanzdienstleistungen, EU): Für Finanzdienstleistungsunternehmen, die KI-Sales-Ops nutzen, fügen die Marktmissbrauchsverordnung und MiFID-II Kommunikations-Archivierungsanforderungen, Eignungsbeurteilungs-Dokumentationsanforderungen und Best-Execution-Audit-Trails hinzu. Call-Recordings im Finanzdienstleistungsbereich sind nicht nur ein Coaching-Tool; sie sind ein regulatorisches Archiv. Die Aufbewahrungsfristen (typischerweise 5-7 Jahre) und die Zugangskontrollanforderungen sind strenger als die Standard-Sales-Ops-Governance.
Für die meisten nicht regulierten Mid-Market-B2B-Unternehmen ist DSGVO-Artikel 22 das primäre relevante Framework für Lead-Scoring und Routing, und es erfordert eine Rechts-Review, nicht unbedingt einen Compliance-Programmaufbau. Die wichtigste Aktion: dokumentieren Sie, dass Ihr Rechtsteam den KI-Scoring-Anwendungsfall überprüft hat und zu dem Schluss kam, dass er den "erheblichen Effekt"-Schwellenwert von Artikel 22 erfüllt oder nicht, und bewahren Sie diese Dokumentation auf.
Governance-Reifestufen
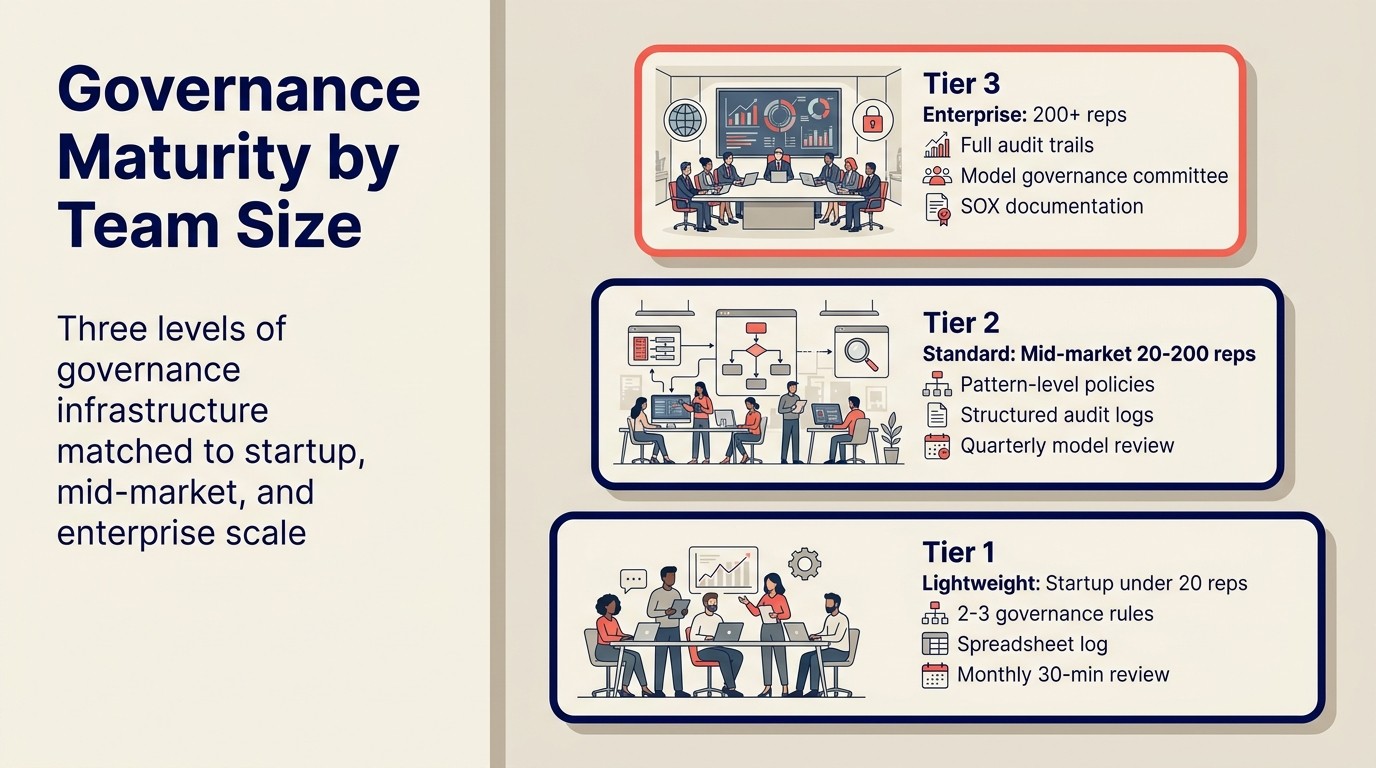
Governance-Anforderungen skalieren mit Unternehmensgröße, Komplexität und regulatorischem Risiko. Bauen Sie keine Enterprise-Governance-Infrastruktur für ein 10-Personen-Vertriebsteam.
Leichtgewichtig (Startup, unter 20 Reps):
- 2-3 Governance-Regeln: Recording-Zustimmungsprozess, Routing-Streit-Pfad, E-Mail-Genehmigung für Enterprise-Accounts
- Audit-Logs in CRM-benutzerdefinierten Feldern oder einer gemeinsamen Tabellenkalkulation
- Monatliche 30-minütige Überprüfung durch den Sales-Ops-Lead
- Kein dediziertes Governance-Tooling erforderlich
Standard (Mid-Market, 20-200 Reps):
- Muster-level-Richtlinien pro KI-Tool dokumentiert
- Strukturierte Audit-Logs im CRM oder einer dedizierten Log-Tabelle
- Vierteljährliche Genauigkeits-Review des Scoring-Modells
- Routing-Streit-Prozess mit definierter SLA
- DSGVO-Rechts-Review abgeschlossen und dokumentiert
- Jährliche Anbieter-Sicherheits-Review (SOC-2-Bericht, Datenverarbeitungsvereinbarung aktuell)
Enterprise (200+ Reps oder regulierte Branchen):
- Vollständige Audit-Trails über alle vier Muster, nach Deal und Rep verknüpft
- Modell-Governance-Komitee (RevOps-Lead, Legal, Data Engineering)
- Vierteljährliche Modellgenauigkeits- und Bias-Reviews
- Routing-Streit-Prozess mit Eskalationspfad zu VP RevOps
- SOX-interne Kontrollen-Dokumentation wenn börsennotiert
- Datenhaltungs-Verifizierung pro Betriebsrechtsordnung
- Jährlicher Penetrationstest der KI-Datenpipelines
Governance und Vertrauen: der eigentliche Grund, warum es wichtig ist
Das praktische Argument für Governance ist Compliance und Streit-Lösung. Aber das strategische Argument ist Vertrauen.
Ein KI-System, das unsichtbare Entscheidungen trifft, ohne Erklärung, ohne Log und ohne Streitpfad, wird schließlich das Vertrauen der Reps verlieren, die mit seinen Ausgaben leben. Reps, die dem Routing-Modell nicht vertrauen, ignorieren seine Zuteilungen. Reps, die dem Scoring-Modell nicht vertrauen, bearbeiten die Leads, die sie bearbeiten möchten, nicht die, die das Modell empfiehlt.
Jeder hier dokumentierte Governance-Mechanismus (das Audit-Log, der Streitprozess, die Genehmigungstore) ist auch ein Vertrauensmechanismus. Er sagt zum Rep: "Wir wissen, dass dieses System Entscheidungen trifft, die Sie betreffen. Wir haben eine Aufzeichnung dieser Entscheidungen. Wenn Sie denken, eine Entscheidung war falsch, hier ist, wie Sie sie anfechten." Das ist keine Bürokratie. Das ist der Betriebsvertrag, der KI-Sales-Ops tatsächlich nutzt.
Sehen Sie Failure-Modi: Wenn KI-Sales-Ops nach hinten losgeht für das, was passiert, wenn Governance übersprungen wird, und Vom Anruf zum automatischen CRM-Update für die Konfiguration des CRM-Auto-Write mit angemessenen Review-Toren.
Rework-Analyse: Die Governance-Lücke, die wir am konsistentesten sehen, liegt nicht in der DSGVO-Artikel-22-Analyse (die meisten Teams tun das), sondern in der Modell-Versionierung. Teams können in der Regel ihre aktuellen Routing-Regeln erklären. Sie können eine Routing-Entscheidung von vor vier Monaten nicht erklären, weil sie das Scoring-Modell seitdem zweimal aktualisiert haben und nicht protokolliert haben, welche Version welche Entscheidung getroffen hat. Modell-Versionierung im Audit-Log ist die einzelne höchstwertige Governance-Verbesserung für Mid-Market-Teams, die grundlegende Protokollierung haben, aber anfangen, Modelle neu zu trainieren, wenn sich Daten ansammeln.
Was als nächstes lesen
- Die Generate-vs.-Execute-Grenze: Warum Guardrails wichtig sind: das grundlegende ACE-Prinzip hinter allem Governance-Design
- Governance-Anforderungen nach KI-Muster: Muster-level-Governance-Pflichten über alle 10 KI-Muster
- KI-Sales-Ops-Implementierungs-Roadmap: wie Governance in den phasenweisen Deployment-Plan passt
- Failure-Modi: Wenn KI-Sales-Ops nach hinten losgeht: was schiefgeht, wenn Governance als optional behandelt wird

Co-Founder, Rework.com
On this page
- Was im Vier-Muster-Stack Governance benötigt
- Die drei Governance-Modelle
- Vollständige menschliche Genehmigung
- Schwellenwert-basierte Automatisierung
- Vollautomatisiert mit Audit Trail
- Der 4-Muster-Audit-Log-Standard
- Audit-Trail-Feld-Spezifikation
- Modell-Versionierung und Change Management
- Der Routing-Streit-Prozess
- Datenschutz in KI-Sales-Ops
- Governance-Reifestufen
- Governance und Vertrauen: der eigentliche Grund, warum es wichtig ist
- Was als nächstes lesen