Persyaratan Governance per Pola AI
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
"Manusia harus meninjau output AI sebelum bertindak berdasarkannya." Jika kebijakan governance AI Anda mengandung kalimat itu, itu tidak berisi apa-apa. Kalimat tersebut mendeskripsikan segalanya dan tidak mengatur apapun.
Governance yang terikat pada pola spesifik adalah hal yang sama sekali berbeda. "Untuk deployment Autonomous Agent dalam konteks yang berhadapan dengan pelanggan, wajibkan persetujuan manusia sebelum langkah Execute apa pun yang mengubah catatan keuangan atau mengirim komunikasi eksternal" dapat ditindaklanjuti. Anda bisa mengauditnya. Anda bisa melatih seseorang tentangnya. Anda bisa menunjukkannya kepada regulator dan menjelaskan apa artinya dalam praktik.
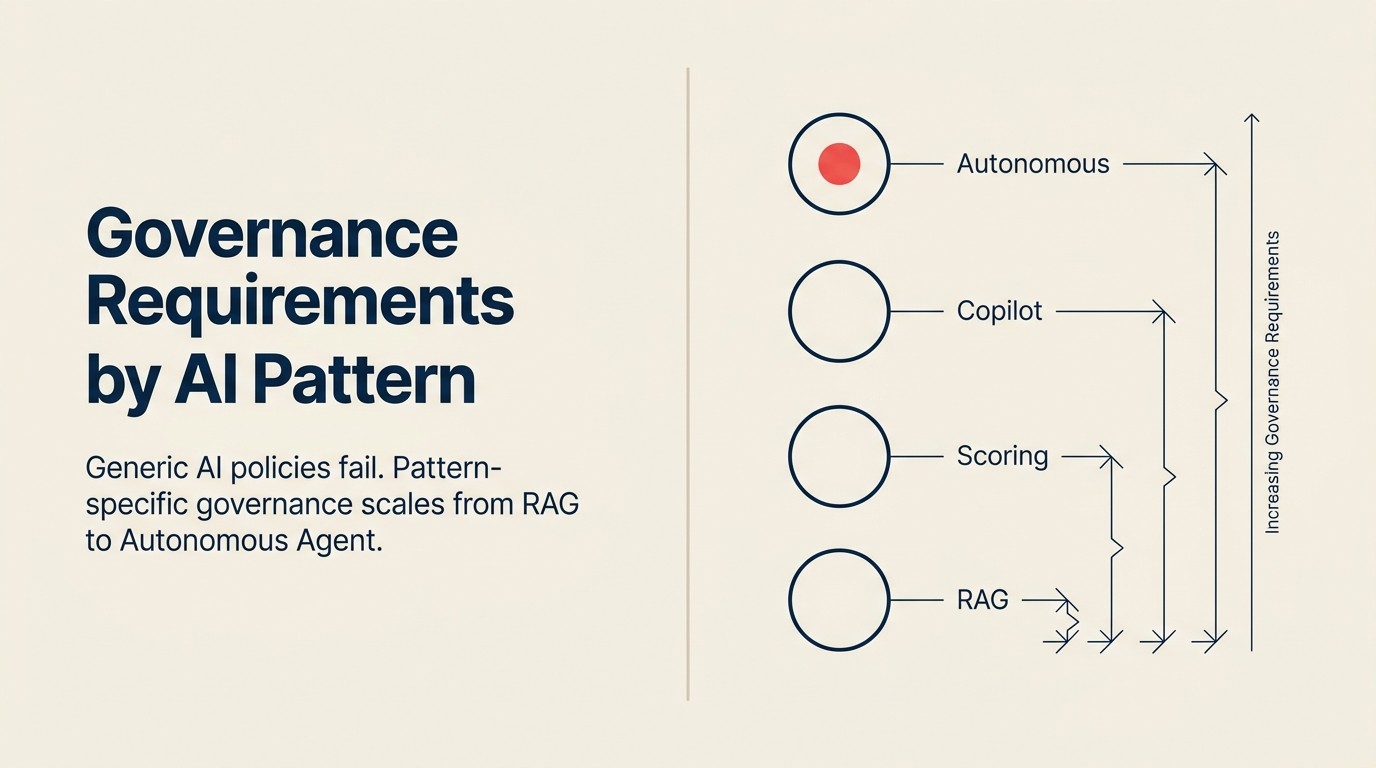
Sebagian besar framework governance AI ditulis pada tingkat abstraksi yang salah karena dirancang untuk mencakup seluruh permukaan AI sebuah organisasi. Keluasan itu memaksa ketidakjelasan. Artikel ini mengambil arah sebaliknya: persyaratan spesifik untuk masing-masing dari 10 pola AI bisnis, dibangun di atas empat dimensi governance yang berlaku secara konsisten. Batas antara generate dan execute adalah konsep tunggal terpenting untuk dipahami sebelum membaca persyaratan ini.
Mengapa governance bersifat spesifik per pola
Persyaratan governance mengikuti risiko. Dan risiko dalam sistem AI hampir seluruhnya berasal dari dua sumber: apa yang dilakukan kemampuan Execute, dan di domain apa ia beroperasi. NIST AI Risk Management Framework (AI RMF 1.0) mengkodifikasi ini dengan empat fungsi: GOVERN, MAP, MEASURE, dan MANAGE. Yang dilakukan artikel ini di tingkat pola adalah implementasi fungsi MAP dan MEASURE: membuat permukaan risiko AI menjadi spesifik, dapat diaudit, dan operasional alih-alih teoritis.
RAG Assistant yang membaca dokumen kebijakan dan menjawab pertanyaan karyawan memiliki kebutuhan governance yang rendah. Hasil terburuk yang realistis adalah jawaban yang percaya diri tapi salah tentang kelayakan tunjangan. Menjengkelkan. Dapat diperbaiki. Bukan peristiwa liability.
Autonomous Agent yang mengirim email ke klien, memperbarui catatan keuangan di ERP Anda, dan menjadwalkan meeting atas nama CEO Anda memiliki risiko yang sama sekali berbeda. Hasil terburuk yang realistis adalah tindakan yang tidak dapat dibatalkan yang dilakukan dalam skala besar berdasarkan premis yang dihallusinasikan. Itu adalah peristiwa liability.
Gradien risiko di seluruh pola hampir sepenuhnya sesuai dengan intensitas Execute setiap pola. Pola yang berada di Analyze atau Generate membawa beban governance yang terbatas. Pola yang Execute berulang kali, secara otonom, dan dalam skala besar membawa beban yang substansial. Lihat gradien risiko di seluruh pola AI untuk framework lengkapnya.
Key Facts: Kesenjangan Governance AI Enterprise
- 83% organisasi sudah menggunakan alat AI, tetapi hanya 25% yang telah mengimplementasikan framework governance yang kuat. (Compliance Week, 2026)
- EU AI Act mencapai penegakan penuh pada 2 Agustus 2026, dengan denda hingga 35 juta euro atau 7% pendapatan global untuk pelanggaran praktik AI yang dilarang. Pelanggaran sistem AI berisiko tinggi membawa denda hingga 15 juta euro atau 3% pendapatan global.
- Pasar governance AI akan tumbuh dari $309 juta pada 2025 menjadi $5,88 miliar pada 2035, CAGR 34%, mencerminkan institusionalisasi cepat persyaratan governance di seluruh deployment AI enterprise.
"Pada 2026, setengah dari pemerintah dunia mengharapkan perusahaan untuk mematuhi undang-undang AI dan persyaratan privasi data. Organisasi yang membangun infrastruktur governance pada 2024 dan 2025 kini memiliki audit trail, checkpoint HITL, dan mekanisme override yang siap untuk tinjauan regulator. Organisasi yang tidak melakukannya sedang melakukan retrofitting di bawah tenggat kepatuhan." (Modulos AI Compliance Guide, 2026)
Empat dimensi governance
Untuk setiap pola, governance dipecah menjadi empat dimensi. Keempatnya konsisten, sehingga Anda dapat membangun kebijakan governance AI sebagai tabel daripada narasi:
Persyaratan audit trail. Catatan apa yang perlu disimpan, dalam bentuk apa, dan berapa lama? Audit trail melayani dua tujuan: debugging ketika sesuatu berjalan salah, dan mendemonstrasikan kepatuhan ketika ada yang bertanya. Kedua tujuan memerlukan kekhususan tentang input dan output mana yang dicatat.
Checkpoint human-in-the-loop. Di mana dalam alur kerja manusia perlu meninjau sebelum sistem melanjutkan? Bukan "manusia harus meninjau output." Langkah spesifik, kondisi spesifik, titik keputusan spesifik.
Mekanisme override dan rollback. Ketika manusia tidak setuju dengan tindakan AI, atau ketika langkah Execute ternyata salah, apa yang terjadi? Setiap pola yang dapat Execute membutuhkan jalur rollback yang terdefinisi.
Frekuensi review dan retraining. Seberapa sering pola itu sendiri ditinjau untuk akurasi, drift, dan relevansi yang berkelanjutan? Model Scoring+Routing yang dilatih pada lead tahun lalu mungkin secara aktif menyesatkan tahun ini. Seseorang perlu memiliki tinjauan itu sesuai jadwal.
Governance RAG Assistant
RAG Assistant adalah pola yang paling banyak di-deploy dan membawa risiko Execute terendah dari sistem AI mana pun yang berbicara kembali kepada pengguna. Tapi "risiko rendah" bukan berarti "tanpa governance."
Audit trail: Catat query dan respons. Tandai setiap respons dengan dokumen sumber yang digunakan. Sertakan skor kepercayaan atau jumlah kutipan jika tersedia. Retensi minimum: 90 hari untuk debugging, lebih lama untuk industri yang diregulasi.
Checkpoint HITL: Tidak diperlukan untuk kasus penggunaan read-only di mana pengguna memahami mereka berinteraksi dengan AI. Diperlukan ketika output RAG digunakan dalam komunikasi eksternal: draf email yang berhadapan dengan pelanggan, pengajuan regulasi, proposal klien. Jika output meninggalkan organisasi, manusia meninjauinya terlebih dahulu.
Mekanisme override: Tentukan proses koreksi knowledge base. Ketika pengguna menemukan jawaban yang salah, siapa yang dapat memperbarui dokumen sumber? Berapa SLA turnaround untuk koreksi kritis?
Jadwal review: Audit knowledge base triwulanan. Periksa dokumen yang sudah usang, tautan sumber yang rusak, dan topik di mana pertanyaan pengguna tidak terjawab (sinyal untuk kesenjangan pengetahuan). Tinjauan tahunan kualitas retrieval menggunakan set query pengujian.
Governance Scoring + Routing
Pola ini membawa beban governance langsung yang ringan tetapi eksposur kepatuhan yang signifikan ketika diterapkan pada orang (rekrutmen, pinjaman, asuransi, peradilan pidana). Ketika Scoring+Routing menentukan perlakuan apa yang diterima manusia mana, ECOA, GDPR Pasal 22, dan Title VII semuanya menjadi relevan.
Audit trail: Catat setiap keputusan scoring dengan fitur input yang digunakan dan skor yang dihasilkan. Ini tidak dapat dinegosiasikan untuk kasus penggunaan yang diregulasi. "Model kami mengatakan 62" bukan catatan governance. "Model versi 3.1, fitur input: ukuran perusahaan=enterprise, keterlibatan=tinggi, demo=selesai, skor=62, diarahkan ke: tim enterprise-west" adalah.
Checkpoint HITL: Override manusia tersedia pada setiap keputusan routing. Rep penjualan harus dapat menetapkan ulang lead secara manual. Tim support harus dapat mengeskalasi tiket secara manual terlepas dari skor AI. Rute AI adalah default, bukan kunci.
Mekanisme override: Bypass routing manual untuk setiap titik keputusan. Pastikan tindakan bypass juga dicatat. Pola override manual sering menandai drift model atau masalah kualitas data.
Jadwal review: Tinjauan distribusi skor bulanan. Jika median skor bergeser atau bucket skor tinggi menipis, ada sesuatu yang berubah dalam data atau pasar Anda. Tinjauan akurasi model triwulanan terhadap data uji yang disimpan.
Governance Vision Extract
Pola ini menggantikan entri data manusia. Pertanyaan governance adalah: apa yang terjadi ketika salah, dan siapa yang menangkapnya?
Audit trail: Catat semua catatan yang diekstraksi dengan gambar sumber, skor kepercayaan ekstraksi, dan nilai field yang diekstraksi. Simpan gambar sumber selama masa hidup bisnis catatan tersebut.
Checkpoint HITL: Diperlukan untuk ekstraksi dengan kepercayaan rendah. Tentukan ambang kepercayaan Anda (biasanya apa pun di bawah 85% akurasi pada field kritis diarahkan ke antrean tinjauan manusia). Juga diperlukan untuk ekstraksi apa pun yang akan digunakan dalam transaksi keuangan tanpa verifikasi tambahan.
Mekanisme override: Alur kerja koreksi field manual dengan audit log. Setiap koreksi manusia harus dicatat. Ini adalah sinyal pelatihan Anda untuk peningkatan model.
Jadwal review: Spot-check akurasi bulanan pada sampel ekstraksi berkepercayaan tinggi. Anda mencari kesalahan sistematis yang jatuh di atas ambang kepercayaan. Penambahan tipe dokumen atau perubahan format dari vendor harus memicu spot-check segera.
Governance Meeting Intelligence
Pola Meeting Intelligence memiliki dua masalah governance berbeda yang sering diremehkan sebagian besar deployment: persetujuan, dan kualitas data CRM. Untuk contoh lengkap governance dalam konteks AI sales ops, governance AI sales ops dan audit trail mencakup framework audit penuh.
Persyaratan persetujuan: Persetujuan rekaman tidak seragam. Negara bagian dengan persetujuan satu pihak (termasuk sebagian besar AS) mengizinkan rekaman jika satu pihak menyetujui. Negara bagian dua pihak (California, Florida, lainnya) mengharuskan semua pihak menyetujui. GDPR memperluas persyaratan persetujuan ke warga negara UE terlepas dari mana mereka menelepon. Jika rep Anda menggunakan Meeting Intelligence pada panggilan apa pun dengan peserta Eropa mana pun, Anda memerlukan persetujuan yang terdokumentasi. Menyimpan rekaman tanpa persetujuan adalah liability, bukan hanya kotak centang kepatuhan.
Audit trail: Penyimpanan rekaman dengan jadwal retensi yang sesuai dengan industri Anda (biasanya 1-3 tahun untuk panggilan penjualan, berpotensi lebih lama untuk layanan keuangan atau kesehatan). Log push CRM: kapan AI menulis apa ke catatan mana?
Checkpoint HITL: Tinjauan manusia atas push CRM sebelum menjadi data sistem catatan. Output Meeting Intelligence harus masuk ke area staging terlebih dahulu, tidak langsung menulis ke field CRM aktif. Tinjauan lima menit oleh rep sebelum menyetujui push menangkap sebagian besar kesalahan tanpa menghancurkan penghematan waktu.
Mekanisme override: Alur kerja koreksi untuk entri CRM. Catatan yang ditulis AI yang salah harus dapat diperbaiki dengan stempel waktu yang menunjukkan koreksi dimulai oleh manusia.
Jadwal review: Spot-check bulanan kualitas data CRM untuk catatan yang ditulis AI. Apakah item tindakan akurat? Apakah atribusi pembicara benar? Apakah ringkasan menangkap komitmen yang tepat?
Governance Anomaly Agent
Masalah governance utama di sini adalah biaya false positive: bertindak berdasarkan anomali yang ternyata merupakan variasi bisnis normal.
Audit trail: Semua alert dicatat dengan data sinyal yang memicu alert, tingkat kepercayaan model, dan disposisi (ditinjau, diabaikan, dieskalasi). Audit trail ini penting untuk debugging dan analisis false positive.
Checkpoint HITL: Tinjauan manusia diperlukan sebelum tindakan Execute apa pun pada anomali yang ditandai. Anomaly Agent seharusnya memberi alert dan mengantrekan, bukan memberi alert dan bertindak. Jika pola Anda memiliki blokir otomatis (pencegahan penipuan), ambang untuk tindakan otomatis harus sangat tinggi, dan semua tindakan otomatis harus ditinjau setelah kejadian.
Mekanisme override: Penindasan tanda untuk pola false positive yang diketahui. Jika pembayaran vendor selalu tampak anomalus karena siklus penagihan mereka, pola itu harus ditekan di sumbernya daripada ditinjau secara manual setiap bulan.
Jadwal review: Tingkat false positive ditinjau bulanan. Jika tingkat false positive Anda di atas 15%, overhead governance menghabiskan nilainya. Jika di bawah 1%, Anda mungkin melewatkan anomali nyata. Titik operasional optimal bergantung pada domain dan biaya tindakan.
Generative Research, Document Review, dan Workflow Copilot
Ketiga pola ini berbagi profil governance yang umum: risiko utama adalah mendistribusikan teks yang dibuat AI sebagai otoritatif tanpa tinjauan yang memadai.
Generative Research: Setiap output yang didistribusikan di luar tim langsung memerlukan pengecekan fakta manusia terhadap sumber primer. Audit trail mencatat query, sumber yang diakses, dan siapa yang menyetujui output untuk distribusi. Jadwal review: spot-check akurasi output bulanan, terutama untuk kasus penggunaan berisiko tinggi (brief investor, pengajuan regulasi, deliverable klien).
Document Review: Output AI adalah sistem penandaan, bukan pendapat hukum. Pengacara meninjau sebelum bertindak atas tanda apa pun. Audit trail mencatat dokumen mana, klausul mana yang ditandai, dan apa disposisi pengacara manusia. Tidak ada tindakan kontrak otomatis tanpa persetujuan manusia.
Workflow Copilot: Governance berfokus pada kebocoran data. Data apa yang dilihat copilot? Jika menarik dari CRM, dapatkah ia mengakses catatan di luar wilayah normal rep? Batas akses data untuk copilot perlu didefinisikan dan diaudit, tidak diasumsikan.
Governance Autonomous Agent
Ini adalah bagian governance paling kritis dalam framework, dan yang paling sering diremehkan sebagian besar implementasi sampai sesuatu berjalan salah.
Autonomous Agent bersiklus melalui semua lima kemampuan dalam loop: Ingest, Analyze, Predict, Generate, Execute, kemudian berulang. Setiap langkah Execute memiliki konsekuensi. Kesalahan bertambah di seluruh iterasi. Langkah perantara yang dihallusinasikan dalam iterasi loop ke-3 dapat mendorong serangkaian tindakan yang salah dalam iterasi ke-4 hingga ke-8 sebelum manusia mana pun melihat hasilnya.
Audit trail: Setiap pemanggilan tool dicatat dengan parameter input, output, dan alasan keputusan (langkah Generate yang mendorong keputusan Execute). Bukan hanya "agent mengirim email" tetapi "agent menerima permintaan konfirmasi meeting, menentukan jendela penjadwalan melalui pencarian kalender, menghasilkan draf email, dikirim ke kontak eksternal." Provenance penuh dari niat ke tindakan.
Checkpoint HITL (wajib):
- Sebelum langkah Execute apa pun yang mengirim komunikasi eksternal
- Sebelum langkah Execute apa pun yang mengubah catatan keuangan
- Sebelum langkah Execute apa pun yang memodifikasi catatan yang dimiliki seseorang di luar tim pemrakarsa tugas
- Sebelum urutan 3+ langkah Execute dalam satu tugas
Ini bukan saran. Ini adalah persyaratan minimum untuk deployment Autonomous Agent yang berhadapan dengan pelanggan. Deployment apa pun tanpa checkpoint ini bertaruh bahwa agent tidak akan menghallusinasikan jalannya ke tindakan yang tidak dapat dibatalkan. Taruhan itu pada akhirnya akan kalah. EU AI Act, Pasal 14 mengamanatkan bahwa sistem AI berisiko tinggi dirancang agar orang alami dapat "mendeteksi dan mengatasi anomali, tetap menyadari bias otomasi, menafsirkan output sistem dengan benar, dan memutuskan untuk tidak menggunakan sistem." Persyaratan ini memetakan langsung ke checkpoint ini untuk agent yang beroperasi dalam konteks ketenagakerjaan, layanan keuangan, atau berhadapan dengan pelanggan.
Batas cakupan: Tentukan allowlist eksplisit alat yang dapat diakses agent. Agent yang perlu menjadwalkan meeting tidak membutuhkan akses ke sistem penagihan Anda. Agent yang melakukan riset akun tidak membutuhkan akses kirim ke klien email Anda. Batas cakupan adalah pertahanan utama Anda terhadap perilaku Execute yang tidak terduga.
Mekanisme override: Kemampuan penghentian tugas dan rollback. Operator membutuhkan kemampuan untuk menghentikan tugas agent yang sedang berjalan di tengah eksekusi dan membalik langkah Execute yang sudah diambil. Jika platform Anda tidak mendukung penghentian tugas dan rollback, postur governance Anda lemah terlepas dari kebijakan apa yang telah Anda tulis.
Jadwal review: Mingguan selama deployment awal (60 hari pertama). Bulanan setelah baseline terbentuk. Audit penuh semua tindakan Execute triwulanan, secara khusus meninjau kasus di mana agent menyelesaikan tugas dengan cara yang tidak terduga.
| Pola | Intensitas Execute | Masalah kepatuhan utama | Persyaratan HITL minimum | Retensi audit trail |
|---|---|---|---|---|
| RAG Assistant | Tidak ada (read-only) | Jawaban yang percaya diri tapi salah | Diperlukan hanya untuk distribusi eksternal | 90 hari |
| Scoring + Routing | Ringan (keputusan routing) | Bias algoritmik dalam HR/pinjaman | Override manusia tersedia pada setiap keputusan routing | 12 bulan (diregulasi) |
| Vision Extract | Sedang (penggantian entri data) | Akurasi catatan keuangan | Ekstraksi berkepercayaan rendah diantrekan ke tinjauan manusia | Selama masa hidup bisnis catatan |
| Meeting Intelligence | Ringan (push CRM) | Persetujuan rekaman per yurisdiksi | Tinjauan manusia sebelum staging CRM aktif | 1-3 tahun (bergantung industri) |
| Anomaly Agent | Sedang (alert + blokir) | Biaya tindakan false positive | Tinjauan manusia sebelum tindakan Execute pada item yang ditandai | 12 bulan |
| Generative Research | Tidak ada (menghasilkan teks) | Kutipan yang dihallusinasikan didistribusikan secara eksternal | Pengecekan fakta manusia sebelum distribusi eksternal | 90 hari |
| Document Review | Tidak ada (menandai, tidak mengubah) | Liability pendapat hukum jika diperlakukan sebagai opini hukum | Tinjauan pengacara sebelum bertindak atas tanda apa pun | Siklus hidup kontrak |
| Workflow Copilot | Ringan (menyarankan, manusia menyetujui) | Kebocoran batas akses data | Persetujuan manusia sebelum mengirim | 90 hari |
| Autonomous Agent | Tinggi (loop Execute multi-langkah) | Tindakan tidak dapat dibatalkan dalam skala besar pada premis yang dihallusinasikan | Sebelum komunikasi eksternal, perubahan keuangan, 3+ langkah Execute | Provenance penuh, 2+ tahun |
Per-Pattern Governance Footprint
Per-Pattern Governance Footprint adalah format kebijakan terstruktur yang menentukan, untuk setiap deployment pola AI yang aktif, empat hal dengan tepat: spesifikasi audit trail (format, field yang dicatat, dan periode retensi), checkpoint human-in-the-loop (langkah spesifik, kondisi pemicu, siapa yang menyetujui), mekanisme override dan rollback (siapa yang dapat melakukan override, bagaimana, dengan catatan apa yang disimpan), dan frekuensi review dan retraining (siapa yang meninjau, apa yang mereka cari, pada jadwal apa). Framework dibangun atas prinsip bahwa persyaratan governance mengikuti intensitas Execute: pola pada langkah Analyze dan Generate membawa beban governance yang terbatas, sementara pola yang Execute berulang kali, secara otonom, atau dalam skala besar membawa beban substansial yang sebanding dengan permukaan konsekuensinya.
Rework Analysis: Berdasarkan temuan Compliance Week bahwa 83% enterprise menggunakan AI tetapi hanya 25% yang memiliki framework governance yang kuat, dan penegakan penuh EU AI Act yang mencapai sistem AI berisiko tinggi pada Agustus 2026, Per-Pattern Governance Footprint mewakili struktur governance minimal yang layak untuk organisasi mana pun yang mengoperasikan AI dalam konteks ketenagakerjaan, keuangan, kesehatan, atau berhadapan dengan pelanggan. Data implementasi governance Rework menunjukkan bahwa tim yang mendefinisikan Per-Pattern Governance Footprint sebelum men-deploy setiap pola mengurangi waktu persiapan audit kepatuhan mereka rata-rata 8 minggu dibandingkan tim yang mendokumentasikan governance secara retrospektif setelah regulator atau insiden memerlukannya.
Membangun kebijakan governance dari framework ini
Kebijakan governance spesifik per pola memiliki struktur ini:
Inventaris pola. Daftarkan setiap deployment pola AI yang aktif dalam organisasi, tim yang memilikinya, dan tindakan Execute yang dapat dilakukannya.
Klasifikasi risiko. Menggunakan empat dimensi di atas, klasifikasikan setiap deployment pada skala 1-5. Deployment Autonomous Agent yang berhadapan dengan pelanggan mendapat skor 5. RAG Assistant read-only mendapat skor 1.
Tabel persyaratan. Untuk setiap deployment: spesifikasi audit trail (format, field, retensi), checkpoint HITL (langkah spesifik, kondisi pemicu spesifik), mekanisme override (siapa yang dapat melakukan override, bagaimana, dengan catatan apa), dan jadwal review (siapa yang meninjau, apa yang mereka cari, kapan).
Penugasan kepemilikan. Setiap deployment pola memiliki pemilik operasional bernama yang bertanggung jawab atas jadwal review dan untuk respons insiden.
Prosedur respons insiden. Ketika sebuah pola menghasilkan output yang menyebabkan kerugian (tindakan salah diambil, data bocor, hallusinasi didistribusikan secara eksternal), siapa yang diberitahu, siapa yang menginvestigasi, dan apa titik keputusan untuk penangguhan vs. operasi lanjutan dengan kontrol tambahan?
Ini bukan latihan kepatuhan. Ini adalah prosedur operasi yang memungkinkan Anda menjalankan pola otonomi tinggi dengan aman. Tanpanya, setiap deployment Autonomous Agent hanya satu insiden dari dimatikan secara permanen.
Tujuan governance bukan untuk memperlambat adopsi AI. Ini untuk membuat adopsi menjadi tahan lama. Prinsip AI OECD, diadopsi oleh 42 negara dan referensi dasar untuk EU AI Act dan framework NIST, mendeskripsikan akuntabilitas sebagai prinsip inti: aktor AI bertanggung jawab atas fungsi sistem AI yang tepat dan penghormatan terhadap norma yang berlaku. Governance spesifik per pola adalah bagaimana akuntabilitas itu menjadi operasional daripada aspirasional. Tim yang men-deploy tanpa struktur governance mendapatkan pola mereka dimatikan oleh legal atau kepatuhan setelah insiden pertama dan menghabiskan berbulan-bulan membangun kembali kepercayaan. Tim yang men-deploy dengan governance spesifik per pola dapat bergerak lebih cepat pada deployment berikutnya karena mereka telah menunjukkan disiplin operasional pada yang pertama.
Pola-polanya kuat. Governance adalah yang membuatnya terus berjalan. Mulailah dengan risiko hallusinasi per pola untuk mode kegagalan spesifik yang dirancang untuk ditangkap governance, dan mengukur ROI per pola untuk data audit trail yang memberi makan analisis ROI Anda.
Pertanyaan yang Sering Diajukan
Mengapa pola AI memerlukan governance spesifik per pola daripada kebijakan tunggal?
Karena persyaratan governance mengikuti intensitas Execute, dan intensitas Execute sangat bervariasi di seluruh pola. RAG Assistant yang menjawab pertanyaan karyawan hampir tidak membawa risiko Execute. Autonomous Agent yang mengirim email, memperbarui catatan keuangan, dan menjadwalkan meeting membawa risiko irreversibilitas yang substansial. Kebijakan tunggal yang mencakup keduanya baik mengatur RAG Assistant terlalu ketat (memperlambat adopsi) atau mengatur Autonomous Agent terlalu longgar (menciptakan risiko insiden).
Apa itu Per-Pattern Governance Footprint?
Per-Pattern Governance Footprint menentukan empat hal untuk setiap pola AI yang aktif: spesifikasi audit trail (format, field, retensi), checkpoint human-in-the-loop (langkah dan kondisi pemicu spesifik), mekanisme override dan rollback (siapa yang dapat melakukan override, bagaimana, dengan catatan apa), dan frekuensi review dan retraining. Ini mengubah pernyataan governance generik menjadi prosedur operasional yang dapat diaudit, dilatihkan, dan ditunjukkan kepada regulator.
Persyaratan EU AI Act apa yang berlaku untuk deployment Autonomous Agent?
Pasal 14 mengamanatkan bahwa sistem AI berisiko tinggi memungkinkan manusia mendeteksi dan mengatasi anomali, tetap menyadari bias otomasi, menafsirkan output sistem dengan benar, dan memutuskan untuk tidak menggunakan sistem. Ini memetakan langsung ke empat persyaratan governance Autonomous Agent: kemampuan penghentian tugas dan rollback, pencatatan false positive dan jadwal review, audit trail provenance penuh dari niat ke tindakan, dan persetujuan manusia sebelum langkah Execute yang tidak dapat dibatalkan. Denda ketidakpatuhan EU AI Act mencapai 35 juta euro atau 7% pendapatan global untuk praktik yang dilarang.
Seberapa sering pola AI harus ditinjau untuk model drift?
Model Scoring dan Routing harus ditinjau bulanan untuk perubahan distribusi skor dan triwulanan untuk akurasi terhadap data uji yang disimpan. Anomaly Agent harus memiliki tingkat false positive yang ditinjau bulanan. RAG Assistant memerlukan audit knowledge base triwulanan. Autonomous Agent harus ditinjau mingguan dalam 60 hari pertama, kemudian bulanan, dengan audit penuh semua tindakan Execute triwulanan. Model drift adalah kesenjangan governance paling umum dalam deployment tahun kedua karena tim membangun jadwal review ke dalam rencana peluncuran dan kemudian mendeprioritaskannya seiring pekerjaan lain bertambah.
Apa mode kegagalan governance paling kritis untuk Autonomous Agent?
Deployment tanpa kemampuan penghentian tugas dan rollback. Autonomous Agent bersiklus melalui semua lima kemampuan ACE dalam loop, artinya setiap langkah Execute dibangun di atas yang sebelumnya. Langkah perantara yang dihallusinasikan dalam iterasi loop ke-3 dapat mendorong serangkaian tindakan yang salah dalam iterasi ke-4 hingga ke-8 sebelum manusia mana pun melihat hasilnya. Tanpa kemampuan untuk menghentikan agent di tengah eksekusi dan membalik langkah Execute yang sudah diambil, postur governance bersifat teoritis daripada operasional. Jika platform agent Anda tidak mendukung penghentian tugas dan rollback, ini adalah persyaratan pemblokir sebelum deployment.
Bagaimana pola Scoring dan Routing menciptakan risiko kepatuhan dalam konteks HR?
Ketika Scoring dan Routing menentukan kandidat mana yang maju dalam proses rekrutmen, EEOC Title VII, GDPR Pasal 22, dan undang-undang bias AI negara bagian yang muncul berlaku. Model tidak boleh menggunakan karakteristik yang dilindungi sebagai fitur (atau fitur yang berfungsi sebagai proxy untuk karakteristik yang dilindungi). Audit trail harus mencatat setiap keputusan scoring dengan fitur input yang digunakan. Override manusia harus tersedia pada setiap keputusan routing. Di AS, 40+ negara bagian kini memiliki undang-undang AI yang aktif, dengan Texas TRAIGA dan California SB 53 keduanya berlaku mulai 1 Januari 2026, menciptakan kewajiban kepatuhan konkret untuk keputusan ketenagakerjaan algoritmik.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Mengapa governance bersifat spesifik per pola
- Empat dimensi governance
- Governance RAG Assistant
- Governance Scoring + Routing
- Governance Vision Extract
- Governance Meeting Intelligence
- Governance Anomaly Agent
- Generative Research, Document Review, dan Workflow Copilot
- Governance Autonomous Agent
- Per-Pattern Governance Footprint
- Membangun kebijakan governance dari framework ini
- Pelajari lebih lanjut