Risk Gradient Trong Các AI Pattern

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hầu hết mọi AI governance framework đều mắc cùng một sai lầm: coi tất cả AI nguy hiểm như nhau.
Kết quả thì có thể đoán trước. Governance team viết blanket policy áp dụng cùng approval process, cùng review cycle và cùng mức hạn chế cho chatbot trả lời câu hỏi chính sách HR lẫn agent có thể xử lý hoàn tiền trong Stripe. Chatbot HR chết trong review cycle sáu tháng. Agent hoàn tiền được deploy với kiểm soát lỏng lẻo vì không ai phân biệt nó với chatbot.
Cả hai kết quả đều tệ. Over-govern pattern rủi ro thấp giết adoption và khiến AI team làm việc vòng quanh governance process. Under-govern pattern rủi ro cao tạo ra sự cố lên báo.
Cách sửa là proportional governance: khớp control với mức rủi ro thực tế của mỗi pattern, không phải theo cảm giác chung chung "AI là rủi ro". Bắt đầu bằng việc hiểu mỗi pattern nằm ở đâu trên risk gradient. NIST AI Risk Management Framework khuyến nghị đúng cách tiếp cận này: govern, map, measure và manage AI risk theo context, điều chỉnh theo use case cụ thể và potential consequence. Nếu bạn vẫn đang làm quen với 10 core pattern, hãy bắt đầu với AI pattern là gì trước.
Điều Gì Thúc Đẩy Rủi Ro Trong AI Pattern
Ba yếu tố xác định mức rủi ro cơ bản của một pattern.
Tính đảo ngược của Execute action. Pattern không có bước Execute có rủi ro thấp nhất: nếu AI sai, không có gì trong thế giới bên ngoài thay đổi. Con người đọc output và tự quyết định có hành động hay không. Pattern có Execute mang rủi ro tương xứng với mức độ khó hoàn tác của action. Cập nhật CRM field dễ đảo ngược. Gửi email cho khách hàng khó đảo ngược hơn (bạn có thể gửi đính chính, nhưng không thể recall email đã gửi). Xử lý hoàn tiền, đặt hàng hoặc block transaction có reversal cost cao nhất.
Gartner AI Risk Classification 2025 xếp irreversibility là single highest-weight risk factor trong AI governance framework, đứng trên data sensitivity và regulatory exposure, vì irreversible error compounding nhanh hơn và resist correction một khi Execute loop đã chạy ở volume lớn.
Confidence calibration của Predict output. Pattern dựa vào Predict để drive routing hoặc decision mang rủi ro tương xứng với mức độ model confidence được calibrate tốt. Lead scoring model nói "82% conversion probability" nên sai khoảng 18% thời gian khi score lead ở 82%. Nếu model calibration lệch (liên tục overconfident hoặc underconfident), mọi downstream routing decision dựa trên những score đó đều bị suy giảm. Miscalibrated confidence vô hình cho đến khi bạn audit outcome so với prediction.
Vị trí đặt human-in-the-loop. Rủi ro thấp hơn khi human review gate nằm giữa Generate và Execute. Cao hơn khi Execute tự động trigger theo threshold hay rule. Cao nhất khi Execute nằm trong loop, chạy nhiều lần mỗi goal, nơi early error compounding qua các bước sau. Ranh giới Generate vs. Execute là design decision quan trọng nhất cho bất kỳ pattern nào có Execute.
Risk Gradient Doctrine
AI governance phải tương xứng với reversibility và autonomy của bước Execute trong mỗi pattern, không đồng nhất trên tất cả AI system. Pattern read-and-generate (Tier 1) cần audit logging và user training, không cần approval gate. Pattern thực thi autonomous trong loop (Tier 4) cần scope limit, rate limit, rollback capability và human oversight lúc launch. Áp Tier 4 governance cho Tier 1 pattern giết adoption mà không giảm rủi ro. Áp Tier 1 governance cho Tier 4 pattern là nguyên nhân trực tiếp của các AI incident lên báo.
Thông Tin Quan Trọng: Rủi Ro AI và Governance
- 80% tổ chức đã gặp risky hoặc unexpected behavior từ AI agent, với gần như mọi incident đều bắt nguồn từ Execute step trigger mà không có upstream verification đủ. (McKinsey, 2025)
- Tổ chức áp uniform governance trên tất cả AI pattern chi 3 lần nhiều vào compliance cost so với tổ chức dùng tiered risk-proportionate control, trong khi đạt safety outcome thấp hơn. (Deloitte AI Governance Report, 2025)
- AI incident dẫn đến measurable business damage có khả năng xảy ra 4,7 lần cao hơn khi liên quan đến autonomous hoặc automated Execute pattern so với read-only Generate pattern. (Forrester AI Incident Analysis, 2025)
Phổ Rủi Ro: Bốn Tầng

Tier 1: Chỉ đọc, không Execute
Pattern: RAG Assistant, Generative Research, Document Review
Các pattern này Ingest, Analyze, Generate và dừng. Không có gì trong thế giới bên ngoài thay đổi. Output là text artifact (câu trả lời, báo cáo, tập hợp flag) mà con người đọc, đánh giá và hành động theo. AI sai thì con người bắt được trước khi bất cứ thứ gì được commit.
RAG Assistant tạo câu trả lời từ knowledge base. Nó retrieve sai đoạn và tạo ra inaccurate answer thì người hỏi đọc câu trả lời sai. Đó là vấn đề. Nhưng là vấn đề có giới hạn: một người nhận thông tin sai. Họ có thể hành động theo, hoặc nhận ra nó sai và verify.
Generative Research tổng hợp báo cáo từ nhiều nguồn. Nó cite sai hoặc rút suy luận không chính xác thì người đọc nhận được báo cáo có khiếm khuyết. Rủi ro tăng theo mức độ reader tin tưởng và hành động dựa trên output mà không verify.
Document Review flag risk trong hợp đồng hoặc chính sách. Nó bỏ sót một nonstandard clause thì legal team có thể không bắt được. Rủi ro đó là thật, nhưng là rủi ro bỏ sót (flag bị miss), không phải wrong action (AI thực thi hành động sai).
Rủi ro cơ bản: Thấp. Control chính là quality assurance, không phải approval gate. Đào tạo user verify các output quan trọng, đặc biệt với high-stakes document trong Document Review. Duy trì audit log về query và output.
Tier 2: Execute với human approval
Pattern: Workflow Copilot, Meeting Intelligence, Vision Extract
Các pattern này có Execute, nhưng với human approval gate nằm giữa Generate và Execute trong standard deployment.
Workflow Copilot draft email hoặc cập nhật CRM. Con người review draft và nhấn gửi. Execute chỉ trigger sau human approval. Rủi ro nằm ở việc loại bỏ approval gate (điều đầu tiên team làm khi quyết định AI "đủ tốt để trust"). Bỏ gate biến Tier 2 pattern thành gần Tier 3 hơn.
Meeting Intelligence tạo call summary và CRM note, thường với rep review step trước khi push. Trong một số deployment, push CRM là tự động. Khi tự động, bad summary trở thành bad CRM record, ảnh hưởng đến pipeline reporting, forecast accuracy và coaching quality. Đó là medium-risk outcome.
Vision Extract push structured record vào system of record. Trong hầu hết deployment, ai đó spot-check sample record trước khi commit. Khi spot-check bị bỏ (thường vì cost), extraction error trở thành database error.
Rủi ro cơ bản: Medium thấp. Core governance control là duy trì human review gate và audit những gì xảy ra khi bạn loại nó. Xác định exception handling: hệ thống làm gì với record không thể extract confidently? Route sang manual review, không phải auto-commit với low confidence.
Tier 3: Execute với rule (không có per-action human approval)
Pattern: Scoring + Routing, Anomaly Agent, Personalization Engine
Các pattern này Execute tự động dựa trên threshold, rule hoặc model output. Không có con người approve từng action riêng lẻ. Lead score trên 80 thì tự động route đến enterprise team. Transaction đánh giá là anomalous thì tự động flag hoặc block. User behavior history trigger personalized product recommendation. Action xảy ra ở volume lớn, liên tục, không có human trong loop ở mỗi action.
Governance challenge: control nằm ở upstream (model calibration, threshold setting, exception queue) không phải tại điểm action. Lead scoring model miscalibrated thì 20% revenue pipeline đang route đến wrong team, và bạn sẽ không thấy nó cho đến khi audit outcome. Anomaly agent baseline sai thì bạn đang block legitimate customer hoặc miss real fraud. Không sai lầm nào visible real-time mà không có monitoring.
Rủi ro cơ bản: Medium cao. Governance requirement: confidence threshold xác định với human review queue cho edge case, periodic model audit so sánh prediction với outcome, rollback process cho rule change, và documented exception handling cho item rơi xuống dưới confidence threshold. Đừng set threshold rồi quên. Review threshold hàng quý dựa trên outcome data.
Tier 4: Execute trong loop, autonomy cao
Pattern: Autonomous Agent
Autonomous Agent dùng cả năm capability trong loop, pursue goal qua nhiều bước và nhiều system. Mỗi loop iteration có thể có Execute action. Error ở bước đầu (Analyze sai, Predict miscalibrated) lan truyền qua mọi Execute action tiếp theo trong loop. Và loop chạy lại, và lại, cho đến khi goal đạt hoặc agent quyết định không thể tiếp tục.
Điều này khác về chất so với các tier khác. Workflow Copilot Execute một lần, có human review draft. Autonomous Agent có thể Execute 15 lần khi hoàn thành một research và outreach task, không có human review step 2 đến 14.
Các scenario gây thiệt hại thực sự: agent research prospect và gửi outreach email ở scale, map sai account và gửi wrong message đến wrong company. Agent xử lý refund request dựa trên matching rule có lỗi. Agent schedule meeting và tạo CRM task, chạy qua danh sách 300 contact, lấy sai calendar integration và tạo chaos trên toàn bộ team calendar. McKinsey báo cáo 80% tổ chức đã gặp risky behavior từ AI agent, và các pattern trên là chính xác những failure mode xuất hiện trong các incident đó.
Rủi ro cơ bản: Cao. Mandatory governance: rõ ràng scope limit (agent có thể touch system nào, có thể thực hiện action nào), rate limit trên Execute action (không quá X email mỗi giờ, không quá $Y refund mỗi ngày không có human review), rollback capability cho executed action, và human-in-the-loop ở production run đầu tiên trước khi scale. Rate limit là control bị skip nhiều nhất: nó biến potential batch mistake thành bounded, fixable mistake.
Tất Cả 10 Pattern Trên Risk Gradient
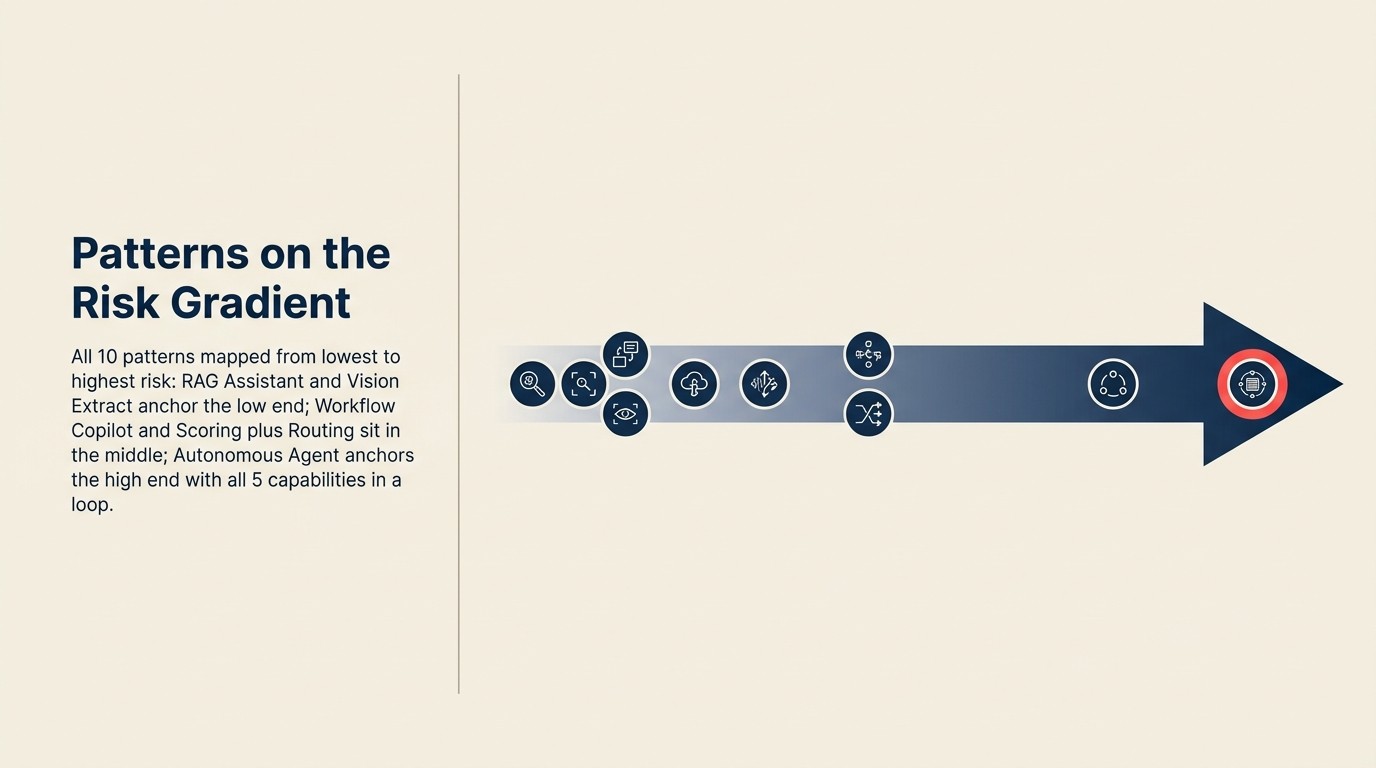
| Pattern | Risk Tier | Execute? | Human Gate? | Rủi ro chính |
|---|---|---|---|---|
| RAG Assistant | Tier 1 (Thấp) | Không | N/A | Câu trả lời sai hoặc lỗi thời |
| Generative Research | Tier 1 (Thấp) | Không | N/A | Tổng hợp không chính xác, cite sai nguồn |
| Document Review | Tier 1 (Thấp) | Không | N/A | Flag bị bỏ sót (miss risk) |
| Workflow Copilot | Tier 2 (Medium thấp) | Có, human gate | Review trước Execute | Bỏ gate; bad draft được commit |
| Meeting Intelligence | Tier 2 (Medium thấp) | Có, thường human gate | Review trước push | Inaccurate note trong system of record |
| Vision Extract | Tier 2 (Medium thấp) | Có, human gate | Spot-check trước commit | Extraction error trong database |
| Scoring + Routing | Tier 3 (Medium cao) | Có, tự động | Threshold + exception queue | Miscalibrated model route ở scale |
| Anomaly Agent | Tier 3 (Medium cao) | Có, tự động | Threshold + exception queue | Wrong baseline; false positive hoặc miss alert |
| Personalization Engine | Tier 3 (Medium cao) | Có, tự động | Threshold + monitoring | Discriminatory personalization; pricing exposure |
| Autonomous Agent | Tier 4 (Cao) | Có, loop | Rate limit + initial oversight | Error compound qua Execute step |
Ngữ Cảnh Domain Nhân Rủi Ro
Tier trên đại diện cho rủi ro cơ bản. Domain context là multiplier.
Vision Extract xử lý business card vào CRM là Tier 2 baseline risk. Field sai (số điện thoại sai một chữ số, tên công ty viết sai) là data quality problem khó chịu. Fixable.
Cùng Vision Extract đọc patient intake form và cập nhật medical record system là Tier 3 governance concern. Wrong field value (sai medication, sai allergy, sai dosage) trong patient record có thể ảnh hưởng đến clinical decision. Cùng capability formula, domain khác, risk tier khác.
Scoring + Routing cho inbound sales lead là Tier 3 baseline risk. Miscalibrated model route một số lead đến wrong team. Revenue impact, khó chịu, auditable.
Cùng Scoring + Routing cho credit application là Tier 4 governance concern trong regulated market. ECOA, Fair Housing Act và GDPR Article 22 đòi explainability và human review right cho AI-driven decision ảnh hưởng đến credit access. Regulatory exposure biến Tier 3 technical problem thành Tier 4 legal concern.
Điều chỉnh tier của mọi pattern lên cao hơn khi: output ảnh hưởng đến regulated decision (credit, employment, housing, healthcare), data liên quan đến sensitive personal information, Execute action có financial hoặc legal consequence, hoặc automation scale làm cho error khó phát hiện trước khi nó compound. Bài viết đo lường ROI của AI pattern trong phần Tìm Hiểu Thêm trình bày cách quantify khi risk-adjusted return biện hộ cho deployment.
Các Đánh Giá Rủi Ro Thấp Phổ Biến Theo Pattern
Scoring + Routing có vẻ safe vì nó "chỉ route mọi thứ". Routing decision ở scale là revenue decision. Lead scoring model sai về lead nào là high priority thì best rep của bạn đang làm việc với wrong account. Support ticket router classify sai urgency thì enterprise customer ngồi chờ trong standard queue. Đây không phải abstract risk. Có thể đo: kiểm tra rep activity distribution, SLA breach rate và routing accuracy hàng tháng.
Personalization Engine có vẻ benign vì nó chỉ "hiển thị relevant content". Personalized pricing (hiển thị giá khác nhau cho user khác nhau) có thể tạo legal exposure theo consumer protection law ở một số jurisdiction, đặc biệt khi personalization correlate với protected characteristic. Job listing personalization exclude nhóm demographic nhất định dựa trên behavioral targeting đã là chủ đề của EEOC và EU investigation. "Chúng tôi chỉ personalize content" không phải là governance answer.
Workflow Copilot có vẻ low-risk vì con người review mọi thứ. Cho đến khi con người ngừng review. Review gate là toàn bộ governance structure cho pattern này. Khi team quyết định AI "đủ tốt" và bỏ review step, họ vừa deploy automated Execute mà không có Tier 3 governance control. Transition đó nên có chủ đích và documented, không phải silent process change.
Yêu Cầu Governance Theo Tier

Tier 1: Audit log về query và output. Quality review process (periodic sampling output bởi reviewer). User training về verification expectation (high-stakes use case đòi independent verification). Không cần approval gate cho standard use.
Tier 2: Duy trì human review gate như explicit policy. Document workflow nào có auto-commit enabled so với review-required. Sample spot-check rate cho auto-commit record. Exception routing cho low-confidence output.
Tier 3: Model accuracy monitoring với periodic outcome audit (so sánh prediction với actual outcome). Confidence threshold với exception queue cho item dưới threshold. Quarterly threshold review dựa trên outcome data. Documentation về routing rule và escalation path. Model drift alert.
Tier 4: Rõ ràng scope limit được document và enforce ở system level (không chỉ policy). Rate limit trên Execute action. Rollback capability để undo executed action. Human oversight requirement cho production run đầu tiên. Phased rollout (bắt đầu với low-risk account hoặc use case trước khi scale). Incident response plan khi agent thực hiện wrong action ở large scale.
Xây Dựng Risk Register Của Bạn
Risk register cho AI pattern đang chạy không cần phức tạp. Với mỗi pattern trong production, ghi lại:
- Tên pattern và use case cụ thể (ví dụ: "Scoring + Routing cho inbound lead assignment")
- Risk tier (1-4)
- Domain multiplier (regulated data? financial consequence? sensitive personal data?)
- Owner (ai chịu trách nhiệm monitor accuracy và governance của pattern này)
- Review frequency (Tier 1: hàng năm; Tier 2: hàng quý; Tier 3: hàng tháng; Tier 4: hàng tuần cho đến khi stable)
- Current control (những gì thực sự đang có)
- Known gap (những gì nên có mà chưa có)
Register là living document. Khi bạn thêm pattern, adjust domain hoặc thay đổi configuration, cập nhật nó. Điểm quan trọng không phải là hoàn hảo: mà là ai đó own risk posture của mỗi pattern và review nó theo schedule.
Phân Tích Rework: Governance mistake chúng tôi thấy thường xuyên nhất là tổ chức viết một AI policy áp dụng đồng nhất cho tất cả AI system. Policy cuối cùng calibrate theo pattern nguy hiểm nhất trong production (thường là autonomous agent hoặc automated routing system) và áp cho mọi thứ. Kết quả: low-risk RAG Assistant bị block trong sáu tháng security review trong khi high-risk Autonomous Agent thực sự đang deploy chỉ với checkbox review. Tiered governance, khớp với actual Execute profile của mỗi pattern, tốn ít hơn và control nhiều hơn so với blanket AI policy.
Câu Hỏi Thường Gặp
Risk gradient trong các AI pattern là gì?
Risk gradient xếp hạng AI pattern từ Tier 1 (read-only, không Execute) đến Tier 4 (autonomous loop với lặp lại Execute step). Tier 1 pattern như RAG Assistant và Generative Research có rủi ro thấp vì AI tạo text output mà con người hành động theo. Tier 4 pattern như Autonomous Agent có rủi ro cao vì Execute trigger nhiều lần mỗi goal mà không có human review, và error compound qua các bước.
Điều gì làm cho AI pattern có rủi ro cao?
Ba yếu tố thúc đẩy AI pattern risk: tính đảo ngược của Execute action (mức độ khó undo những gì AI đã làm), confidence calibration của Predict output (liệu score có phản ánh chính xác actual probability), và vị trí đặt human-in-the-loop (liệu con người có review output trước khi Execute trigger). Forrester AI Incident Analysis 2025 phát hiện AI incident liên quan đến Execute pattern có khả năng gây measurable business damage cao hơn 4,7 lần so với incident liên quan đến read-only Generate pattern.
Governance nên tăng thế nào theo AI pattern risk tier?
Tier 1 pattern cần audit logging và user training về verification expectation. Tier 2 cần duy trì human review gate và exception routing cho low-confidence output. Tier 3 cần model accuracy monitoring, confidence threshold với exception queue, và quarterly outcome audit. Tier 4 cần scope limit, rate limit trên Execute action, rollback capability và human oversight trong production run ban đầu.
Tại sao Workflow Copilot có rủi ro thấp hơn Scoring + Routing?
Workflow Copilot có explicit human approval gate giữa Generate và Execute: AI draft, con người approve trước khi bất cứ thứ gì gửi hoặc commit. Scoring + Routing Execute tự động ở scale dựa trên model score, không có per-action human review. Rủi ro trong Workflow Copilot tăng khi gate bị bỏ. Rủi ro trong Scoring + Routing tăng theo miscalibrated model, điều vô hình cho đến khi bạn audit outcome.
Risk Gradient Doctrine là gì?
Risk Gradient Doctrine phát biểu rằng AI governance phải tương xứng với reversibility và autonomy của Execute step trong mỗi pattern, không đồng nhất trên tất cả AI system. Áp cùng control cho read-only RAG Assistant và Autonomous Agent vừa over-govern low-risk system vừa under-govern high-risk system. Tiered governance khớp với actual Execute profile của mỗi pattern tốn ít hơn và control nhiều hơn so với blanket AI policy.
Domain context có ảnh hưởng đến risk tier của một pattern không?
Có. Domain context là multiplier trên baseline risk. Vision Extract xử lý business card là Tier 2 baseline risk. Cùng pattern cập nhật medical record chứa allergy hoặc medication data là Tier 4 governance concern vì error trực tiếp ảnh hưởng đến clinical decision. Tương tự, Scoring + Routing cho lead assignment là Tier 3, nhưng cùng pattern cho credit decision kích hoạt regulatory obligation theo ECOA và GDPR Article 22, đẩy nó lên Tier 4.
Tìm Hiểu Thêm

Co-Founder, Rework.com
On this page
- Điều Gì Thúc Đẩy Rủi Ro Trong AI Pattern
- Risk Gradient Doctrine
- Phổ Rủi Ro: Bốn Tầng
- Tier 1: Chỉ đọc, không Execute
- Tier 2: Execute với human approval
- Tier 3: Execute với rule (không có per-action human approval)
- Tier 4: Execute trong loop, autonomy cao
- Tất Cả 10 Pattern Trên Risk Gradient
- Ngữ Cảnh Domain Nhân Rủi Ro
- Các Đánh Giá Rủi Ro Thấp Phổ Biến Theo Pattern
- Yêu Cầu Governance Theo Tier
- Xây Dựng Risk Register Của Bạn
- Tìm Hiểu Thêm