AI Lead Scoring Além dos Modelos Baseados em Regras

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A maioria do "lead scoring" implantado hoje é ponderação manual disfarçada de inteligência.
A lógica é: um envio de formulário vale 10 pontos, um cargo de VP adiciona 20, uma empresa com 200+ funcionários adiciona 15, visitar a página de preços adiciona 25. Some tudo e qualquer coisa acima de 70 é um "lead quente". A equipe de vendas trabalha os leads quentes primeiro.
O problema é óbvio assim que você o articula: um humano decidiu esses pesos. Ele fez um julgamento, provavelmente informado por alguma intuição e alguns anedotas da equipe de vendas, e o codificou como regras estáticas. Os pesos não se atualizam quando o mercado muda. Eles não se recalibram quando seu ICP (Ideal Customer Profile) muda depois que você levanta uma Série B. E definitivamente não capturam a interação entre os sinais.
Um cargo de VP de uma empresa de 50 pessoas às 2h da manhã de um sábado converte a uma taxa completamente diferente do mesmo cargo de uma empresa de 300 pessoas às 10h de uma terça-feira.
O lead scoring com machine learning (ML) deixa os dados escolherem os pesos em vez dos humanos. Essa é a diferença conceitual completa. Mas executá-lo bem requer entender como o modelo funciona, quais dados ele precisa e onde os deployments falham. Este é o Padrão 1 na arquitetura do AI Sales Operator, e a fundação sobre a qual tudo o mais se constrói.
O que o scoring baseado em regras perde
Regras são categóricas. Modelos de ML são probabilísticos. A pesquisa da McKinsey sobre AI em vendas B2B identifica a qualificação de leads como um dos casos de uso de AI de maior impacto para equipes de vendas, precisamente porque a melhoria se multiplica: melhor scoring significa que os reps trabalham leads melhores, o que significa mais fechamentos, o que significa melhores dados de treinamento para a próxima iteração do modelo. Essa distinção produz um conjunto de pontos cegos sistemáticos nas abordagens baseadas em regras:
Esparsidade de campos. A maioria dos formulários de leads captura 4-6 campos. A maioria dos registros de CRM tem dezenas de campos potencialmente relevantes, muitos deles vazios. As regras tratam campos vazios como neutros. Os modelos de ML podem aprender que um URL do LinkedIn ausente em uma faixa específica de tamanho de empresa se correlaciona com taxas de fechamento mais baixas, porque é isso que os dados históricos mostram. A ausência de informação é em si um sinal.
Timing e sequência. Um lead que visita a página de preços no primeiro dia e preenche o formulário de demo no mesmo dia converte de forma diferente de um lead que visitou a página de preços três semanas antes de enviar o formulário e depois visitou novamente no dia anterior. As regras podem detectar "visita à página de preços = 25 pontos", mas não capturam curvas de recência ou sequências comportamentais. Os modelos de ML capturam.
Sinais de mudança firmográfica. Uma empresa que acabou de contratar um VP de Vendas é um prospect fundamentalmente diferente da mesma empresa seis meses atrás. Uma rodada de financiamento recente muda a capacidade de compra. Um novo lançamento de produto cria necessidades tecnológicas. Regras estáticas não captam esses sinais dinâmicos. Modelos de ML alimentados com dados firmográficos recentes (de fontes como LinkedIn, Clearbit ou 6sense) podem levá-los em consideração.
Interações multi-touch. A combinação de "cargo VP + página de preços + fonte de indicação = canal de parceiros" pode converter em 40%. Cada elemento isolado pode valer 10%. As regras pontuam independentemente; o ML captura o efeito de interação.
Key Facts: AI Lead Scoring
- A McKinsey identifica a qualificação de leads como um dos casos de uso de AI de maior impacto para equipes de vendas B2B, porque melhor scoring se multiplica: leads melhores fecham com mais frequência, gerando dados de treinamento melhores para a próxima iteração do modelo
- Um mínimo de 200 deals fechados é necessário para um modelo de ML de lead scoring confiável; abaixo de 100, a maioria das ferramentas comerciais produz output estatisticamente indistinguível de atribuição aleatória
- Empresas usando lead scoring assistido por AI relatam taxas de conversão de lead para oportunidade 10-20% mais altas em comparação a modelos baseados em regras estáticas, de acordo com dados de clientes da MadKudu e 6sense (2022-2024)
Como funciona o lead scoring com ML (sem o PhD)
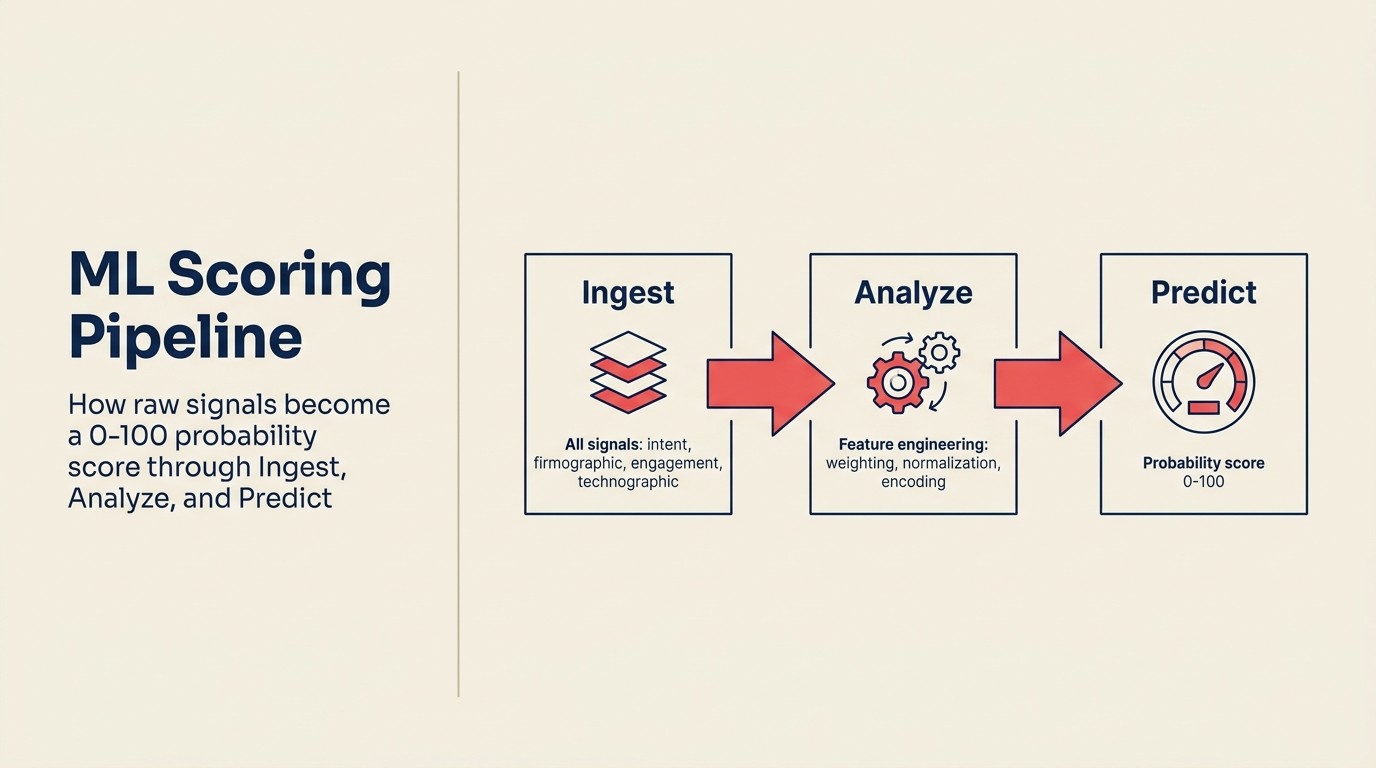
A mecânica é mais simples do que a maioria dos fornecedores faz parecer. Aqui está a lógica operacional, usando o vocabulário do ACE Framework:
Ingest puxa todos os sinais disponíveis para cada lead: campos de CRM (cargo, tamanho da empresa, setor, fonte), dados comportamentais (páginas visitadas, e-mails abertos, webinar assistido), enriquecimento firmográfico (faixa de receita, headcount, estágio de financiamento, stack tecnológica) e dados baseados em tempo (quando as atividades aconteceram, intervalos entre elas).
Analyze extrai features a partir desses dados brutos. Features são as variáveis de input nas quais o modelo realmente treina. Algumas são diretas (cargo = "VP" → feature binária). Algumas são construídas (dias entre a primeira visita e o envio do formulário → feature numérica). Algumas são termos de interação (tamanho da empresa × frequência de engajamento → sinal composto). A engenharia de features é onde a maior parte do trabalho acontece, e onde as equipes de ops que entendem seus próprios dados têm uma vantagem sobre os modelos genéricos out-of-the-box.
Predict treina um modelo em dados históricos rotulados: deals que fecharam (ganho) e deals que não fecharam (perdido), junto com todas as features acima. Por baixo dos panos, a maioria das ferramentas comerciais de lead scoring usa regressão logística ou gradient boosting, técnicas de ML bem compreendidas que produzem uma probabilidade entre 0 e 1. O modelo aprende quais combinações de features se correlacionam com resultados closed-won na sua base de clientes específica e aplica esses pesos aprendidos a cada novo lead, produzindo um output de probabilidade: esse lead tem 73% de chance de converter, dado o que sabemos sobre ele.
É isso. Um número de probabilidade de 0 a 100, fundamentado no seu próprio histórico de ganho/perda, atualizado à medida que novos deals fecham. O ciclo de recalibração é o que separa um modelo funcional de um que vai se desviando lentamente.
O Padrão de Score de Lead Probabilístico
O Padrão de Score de Lead Probabilístico define o que um score de lead de AI defensável deve incluir: um output de probabilidade entre 0 e 1 fundamentado no histórico de ganho/perda da empresa, treinado em pelo menos 200 resultados closed-won, recalibrado no mínimo trimestralmente contra novos resultados de deals, e exposto aos reps com atribuição de features (quais sinais impulsionaram esse score). Qualquer sistema de pontuação que falha em um desses quatro critérios é mais bem classificado como scoring baseado em regras aprimorado do que verdadeiro scoring de ML, porque o output não é estatisticamente fundamentado em padrões de conversão medidos.
Tipos de sinais classificados por lift de conversão

Nem todos os sinais são igualmente úteis. Com base em padrões da pesquisa da MadKudu e dos dados de intenção de comprador da 6sense publicados entre 2022 e 2024, veja como as categorias de sinais geralmente se classificam em contribuição de lift para SaaS B2B:
| Tipo de Sinal | Exemplos | Contribuição de Lift | Notas |
|---|---|---|---|
| Sinais de intenção | Visitas à página de preços, páginas de comparação com concorrentes, visualizações de categoria no G2 | Muito Alto | Sinais de compra em estágio tardio; recência importa (últimos 7 dias >> últimos 30 dias) |
| Recência de engajamento | Abertura de e-mails, visitas ao site nos últimos 14 dias, webinar assistido | Alto | A curva de recência importa: decaimento exponencial após 30 dias |
| Fit firmográfico | Tamanho da empresa, vertical do setor, estágio de financiamento | Alto | Sua definição de ICP codificada matematicamente |
| Fit tecnográfico | Tipo de CRM (Salesforce vs. HubSpot), integrações conhecidas, stack tecnológica atual | Médio-Alto | Maior lift quando seu produto substitui ou complementa uma ferramenta específica |
| Gatilhos de notícias | Financiamento recente, anúncios de contratação, lançamentos de produtos | Médio | Sinal forte para outbound frio; menos preditivo para inbound |
| Fit em nível de contato | Cargo, senioridade, departamento | Médio | Mais forte quando combinado com fit em nível de empresa, mais fraco isoladamente |
| Fonte do lead | Busca orgânica, indicação de parceiro, download de conteúdo | Baixo-Médio | Varia drasticamente por empresa; sempre teste em vez de assumir |
| Comportamento no formulário | Tempo no formulário, campos preenchidos, tipo de dispositivo | Baixo | Útil como desempate; não é um sinal primário |
A ordenação muda com base no seu produto e mercado. Para uma ferramenta de desenvolvedor, o fit tecnográfico pode ser o sinal mais forte. Para um produto de serviços financeiros, a faixa firmográfica e o contexto regulatório podem dominar. O modelo aprende a sua classificação específica a partir dos seus dados; a tabela acima é uma hipótese inicial.
Checklist de prontidão de dados antes de implantar
Esse é o passo que a maioria das empresas pula. O AI lead scoring não produz bons resultados com dados ruins. Antes de comprar ou configurar qualquer ferramenta de scoring de ML, percorra este checklist:
Requisitos mínimos:
- Pelo menos 6 meses de deals fechados com labeling consistente de ganho/perda (12 meses preferencial)
- Pelo menos 200 deals closed-won no total (mais é melhor; abaixo de 100 produz modelos não confiáveis)
- Os estágios de deal do CRM são consistentes em toda a equipe (sem variações "Fechado Ganho" vs. "Ganho" vs. "Fechado")
- A fonte de primeiro toque é capturada em pelo menos 70% dos registros
- Nome da empresa e domínio preenchidos em 80%+ dos registros
Bom ter (melhora significativamente a qualidade do modelo):
- Cargo e senioridade do contato capturados em pelo menos 60% dos leads
- Tamanho da empresa (contagem de funcionários) capturado ou enriquecível para 70%+ dos registros
- Dados comportamentais do site (rastreamento HubSpot, Segment ou equivalente) enviando eventos ao CRM
- Pelo menos uma fonte de enriquecimento firmográfico (Clearbit, Apollo, ZoomInfo) alimentando o CRM
Sinais de alerta que sugerem trabalho de dados antes do scoring:
- Mais de 20% dos deals fechados sem um label de resultado
- Três ou mais nomes de estágio diferentes para a mesma posição no ciclo de vida
- Menos de 6 meses de histórico de deals desde uma migração de CRM (os dados pré-migração são frequentemente não confiáveis)
- Zero dados de rastreamento comportamental (sem histórico de visita de página, sem rastreamento de abertura de e-mail)
Se estiver faltando vários itens da lista mínima, gaste de quatro a seis semanas limpando os dados antes de implantar o scoring. O modelo será construído com o que você alimentar.
Do output do modelo ao threshold de roteamento
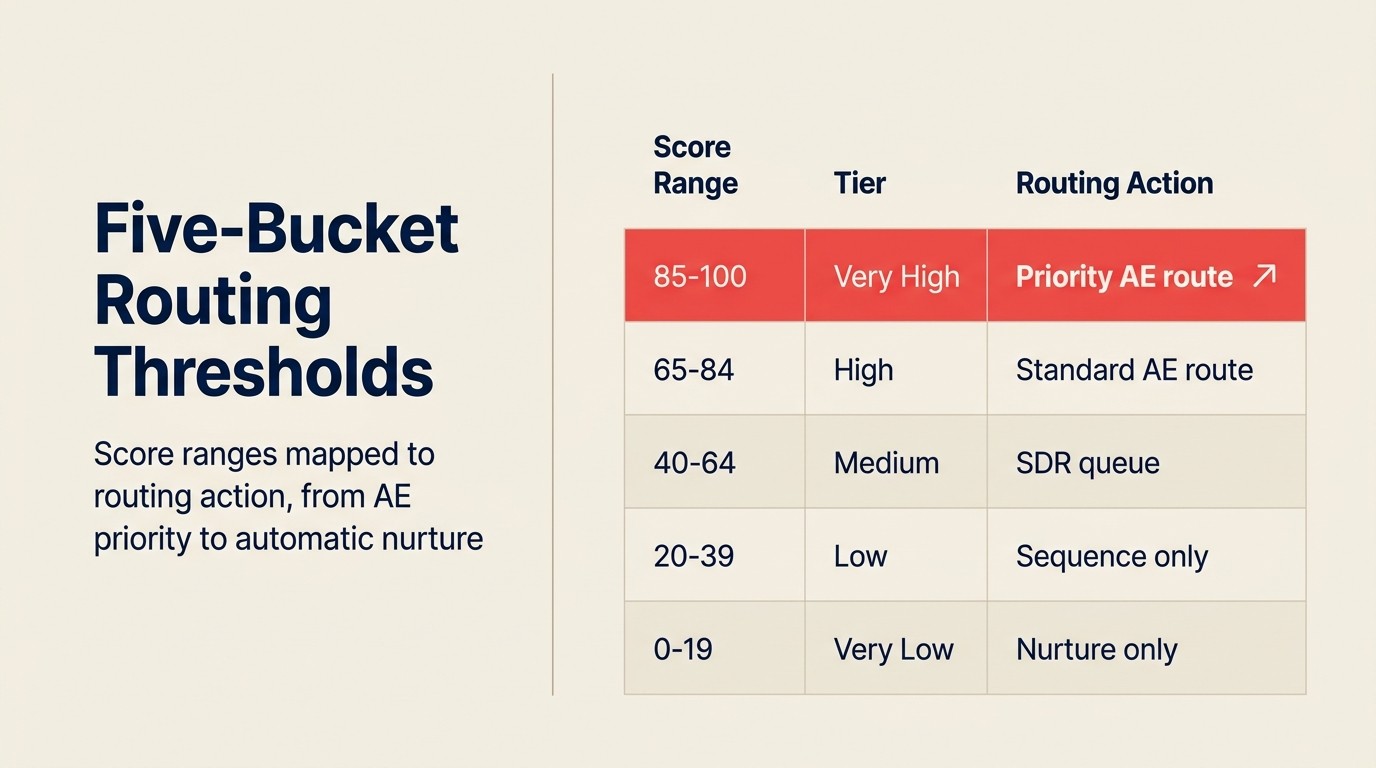
Um modelo dá uma probabilidade. Você ainda precisa decidir o que fazer com ela.
A maioria dos deployments define de três a cinco buckets com lógica de roteamento anexada:
| Faixa de Score | Label | Ação de Roteamento |
|---|---|---|
| 85-100% | Muito Alto | Encaminhar ao AE sênior, notificação imediata no Slack, sem filtro de SDR |
| 65-84% | Alto | Fila do AE, SLA: entrar em contato em 2 horas |
| 40-64% | Médio | Encaminhar ao SDR para qualificação, inscrever na sequência de médio toque |
| 20-39% | Baixo | Inscrição automática em sequência de nutrição, sem atribuição de rep |
| 0-19% | Muito Baixo | Nenhuma ação; adicionar apenas à lista de newsletter |
Os números de threshold são seus para definir, não do fornecedor. Eles devem refletir: quanta capacidade de rep você tem (mais reps = threshold mais baixo para atribuição direta), com que frequência você pode tolerar um falso positivo (um lead de alto score que se mostra errado = tempo de rep desperdiçado) e quais são seus compromissos atuais de SLA de contato.
Acertar os thresholds é um exercício de calibração, não uma configuração única. Execute com os thresholds iniciais por 60 dias, depois compare: para cada bucket, qual foi a taxa de conversão real? Se o seu bucket "Alto" está convertendo em 8% e o seu bucket "Médio" está convertendo em 12%, seus thresholds estão mal calibrados. Ajuste e observe novamente. E fique sempre atento ao volume da fila: um desvio de threshold que de repente envia 40% dos leads para o bucket "Alto" destruirá a confiança do rep em semanas.
Modos de falha comuns
Modelo treinado em dados históricos tendenciosos. Se seus ganhos históricos se inclinam para um canal específico (por exemplo, 70% dos seus deals fechados vieram de indicações de parceiros), o modelo aprenderá a pontuar leads de fontes de parceiros alto. Quando você se expandir para um novo canal, o modelo pontuará esses leads baixo. Não porque são leads ruins, mas porque não tem dados de treinamento para esse padrão. Correção: retreinar com dados mais amplos, ou segmentar modelos por fonte.
Scores que não são apresentados aos reps. O modelo produz um bom output, mas vive em um campo de CRM que ninguém olha. Os reps continuam trabalhando leads em ordem de chegada. Isso é uma falha de adoção, não uma falha do modelo. Correção: apresentar scores no fluxo de trabalho diário do rep (notificação no Slack, fila de CRM classificada por score) e treinar os reps sobre o que o score significa antes do go-live.
Sem ciclo de feedback para retreinamento. O modelo é configurado em janeiro e nunca mais tocado. Doze meses depois, o mercado mudou, o ICP evoluiu e o modelo ainda está otimizando para padrões de 18 meses atrás. Correção: construir um processo de recalibração trimestral. O líder de RevOps revisa métricas de performance do modelo (precisão, precisão e recall por bucket) e aciona um retreinamento quando a precisão cai mais de 5 pontos percentuais.
Threshold set-and-forget. Os thresholds iniciais são definidos no go-live e nunca revisados. 90 dias depois, 40% de todos os leads estão pontuando "Alto" porque o modelo aprendeu de forma muito ampla. A fila "Alto" está sobrecarregando os reps e a confiança colapsa. Correção: revisar a distribuição de thresholds mensalmente e ajustar para manter o volume de fila certo para a capacidade do rep.
Tratamento completo das armadilhas comuns de AI lead scoring.
Snapshot de fornecedores
Salesforce Einstein Lead Scoring está incluído no Sales Cloud Enterprise e superior. Treina diretamente nos seus dados do Salesforce, sem precisar exportar ou conectar a uma ferramenta de terceiros. O modelo se recalibra automaticamente em um cronograma periódico. A qualidade é forte para empresas com dados limpos do Salesforce e 12+ meses de histórico. Configuração limitada para engenharia de features avançada ou fontes de dados personalizadas.
HubSpot Predictive Lead Scoring está disponível no Marketing Hub Professional/Enterprise e Sales Hub Enterprise. Arquitetura similar ao Einstein: treina em dados do HubSpot, produz scores visíveis no pipeline do HubSpot. Mais fraco para empresas com dados comportamentais significativos fora do HubSpot ou necessidades de segmentação firmográfica complexas.
MadKudu é uma plataforma de scoring B2B construída especificamente que se conecta ao Salesforce, HubSpot e múltiplas fontes de enriquecimento de dados. Apresenta importância de features (quais sinais impulsionaram um score específico), tornando mais fácil para o RevOps auditar e calibrar. Melhor para empresas que querem transparência na lógica do modelo e estão dispostas a fazer o trabalho de integração de dados.
6sense foca em sinais de intenção (identificação do comitê de compras, rastreamento de visitantes anônimos) mais do que na probabilidade de conversão. Sua força é a priorização de contas em médio funil, especialmente para vendas baseadas em contas. Frequentemente usado em camadas em cima de um modelo de scoring nativo do CRM em vez de substituí-lo.
Rework Sales AI inclui Scoring+Routing integrado ao CRM como parte da arquitetura completa de AI Sales Operator. Os scores se recalibram a partir dos resultados de deals, encaminham automaticamente para filas de rep e alimentam diretamente o Workflow Copilot para rascunhos de follow-up. Melhor para equipes que querem scoring integrado sem gerenciar um relacionamento com um fornecedor separado.
Rework Analysis: A falha de ML lead scoring mais comum que vemos não é um modelo ruim. É um modelo bom que ninguém recalibra. As equipes implantam no primeiro trimestre, veem resultados sólidos no segundo, e no quarto estão se perguntando por que os leads "quentes" não estão mais fechando. O modelo foi treinado em um mercado que existia há 9 meses. Seu ICP mudou após uma mudança de preços, um novo concorrente entrou ou um novo caso de uso surgiu. A recalibração trimestral não é manutenção opcional; é o mecanismo que mantém o output de probabilidade conectado à realidade atual. Equipes que incorporam a revisão de recalibração no seu calendário de ops desde o primeiro dia sustentam o ROI de 12-18 meses. Aquelas que tratam o modelo como uma instalação única geralmente veem a performance atingir um platô em 6 meses.
O ciclo de feedback é o jogo inteiro
O scoring baseado em regras é uma hipótese: esses atributos deveriam prever a conversão. Você o define uma vez e torce para que envelheça bem.
O scoring com ML é uma medição: esses atributos previram a conversão, com base em resultados reais, atualizado à medida que novos resultados chegam.
Mas "o scoring com ML é uma medição" só vale se o sistema de medição tem um ciclo de feedback. Sem recalibração, o modelo também é uma hipótese, apenas uma treinada em dados em vez de intuição. Uma hipótese que se desvia à medida que as condições de mercado mudam.
Os deployments que entregam ROI sustentado são aqueles onde o RevOps é dono do ciclo de feedback. Eles rastreiam a precisão do modelo trimestralmente. Retreinam quando a precisão cai. Auditam a performance dos thresholds mensalmente. Tratam o modelo de scoring como infraestrutura, não um projeto único.
Essa propriedade operacional é o que separa um deployment de AI lead scoring que continua melhorando de um que produz bons resultados por três meses e depois se torna ruído de fundo. Uma vez que o modelo de pontuação está calibrado e alimentando os leads certos aos reps certos, a próxima pergunta é o que acontece com esses leads quando chegam.
Perguntas Frequentes
O que é AI lead scoring?
O AI lead scoring usa modelos de machine learning treinados em dados históricos de CRM para atribuir a cada lead inbound um score de probabilidade entre 0 e 100. Em vez de pesos de pontos atribuídos por humanos (scoring baseado em regras), o modelo aprende quais combinações de sinais realmente se correlacionam com resultados closed-won na sua base de clientes específica e aplica esses pesos aprendidos a cada novo lead. O score se atualiza à medida que novos deals fecham, tornando-o auto-calibrante em vez de estático.
Como o AI lead scoring é diferente do scoring baseado em regras?
O scoring baseado em regras codifica uma hipótese humana: "cargo VP adiciona 20 pontos, visita à página de preços adiciona 25." O scoring com AI mede o que realmente converteu: o modelo encontra as combinações de sinais que se correlacionam com deals ganhos nos seus dados históricos e as pondera de acordo. A diferença prática é que as regras não se adaptam quando seu ICP muda, não capturam efeitos de interação entre sinais e não melhoram com o tempo. Os modelos de AI fazem as três coisas quando recalibrados adequadamente.
Quais dados um modelo de AI lead scoring precisa para funcionar?
Os requisitos mínimos são pelo menos 6 meses de deals fechados com labeling consistente de ganho/perda (12 meses preferencial), pelo menos 200 deals closed-won no total, definições consistentes de estágio de CRM, fonte de primeiro toque capturada em 70%+ dos registros e nome da empresa/domínio preenchido em 80%+ dos registros. Modelos treinados em menos de 100 deals ganhos produzem output estatisticamente indistinguível de atribuição aleatória.
Quais sinais mais importam para B2B lead scoring?
Sinais de intenção (visitas à página de preços, páginas de comparação com concorrentes, visualizações de categoria no G2) carregam o maior lift de conversão porque indicam comportamento de compra em estágio tardio. A recência de engajamento vem a seguir, com decaimento exponencial após 30 dias. O fit firmográfico (tamanho da empresa, setor, estágio de financiamento) é a terceira categoria mais preditiva para a maioria dos produtos SaaS B2B. A classificação específica varia por produto; o modelo aprende a ordenação real da sua empresa a partir dos seus dados.
Com que frequência um modelo de AI lead scoring deve ser recalibrado?
A recalibração trimestral é o padrão mínimo. O responsável de RevOps deve revisar a precisão do modelo (precisão e recall por bucket de score) a cada trimestre e acionar um retreinamento quando a precisão cair mais de 5 pontos percentuais da baseline. Os ICPs mudam, novos canais surgem e mudanças de preços alteram quais leads convertem. Um modelo treinado há 9-12 meses sem recalibração pode estar otimizando para padrões que não refletem mais os compradores atuais.
Quais são os modos de falha mais comuns de AI lead scoring?
Os quatro modos de falha mais comuns são: (1) modelo treinado em dados históricos tendenciosos (por exemplo, 70% dos ganhos de um canal, tornando o modelo ruim para pontuar outros canais); (2) scores não apresentados no fluxo de trabalho diário do rep, para que os reps os ignorem; (3) sem processo de recalibração, causando desvio de precisão à medida que o mercado muda; e (4) miscalibração de threshold, onde muitos leads pontuam "Alto" e sobrecarregam a capacidade do rep até que a confiança no sistema colapse.
Quais ações de roteamento devem ser acionadas por diferentes faixas de score?
Um modelo de roteamento padrão de cinco buckets mapeia para: 85-100% (direto ao AE sênior, notificação imediata no Slack), 65-84% (fila do AE, SLA de contato de 2 horas), 40-64% (qualificação do SDR, inscrever na sequência de médio toque), 20-39% (nutrição automatizada, sem atribuição de rep) e 0-19% (apenas newsletter). Os thresholds específicos devem ser calibrados para a capacidade de rep da sua equipe e revisados mensalmente para manter o volume de fila certo para o seu headcount atual.
Saiba Mais
- O Que É um AI Sales Operator?
- Roteamento Automatizado de Leads: Round Robin vs. AI
- Balanceamento de Carga de Trabalho de SDR com AI
- Armadilhas Comuns de AI Lead Scoring
- Triagem de Leads Inbound em Escala
- Modos de Falha: Quando AI Sales Ops Sai pela Culatra
- Scoring e Routing: Triagem de AI em Escala
- Predict: Como a AI Prevê Resultados de Negócios

Co-Founder, Rework.com
On this page
- O que o scoring baseado em regras perde
- Como funciona o lead scoring com ML (sem o PhD)
- O Padrão de Score de Lead Probabilístico
- Tipos de sinais classificados por lift de conversão
- Checklist de prontidão de dados antes de implantar
- Do output do modelo ao threshold de roteamento
- Modos de falha comuns
- Snapshot de fornecedores
- O ciclo de feedback é o jogo inteiro
- Saiba Mais