Workflow Copilot: AI sebagai Asisten Setingkat Rekan
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Alasan paling umum inisiatif AI gagal bukan model. Ini adalah adopsi pengguna.
Tim menerapkan alat AI, dan tiga bulan kemudian penggunaan di bawah 15%. Para pengguna tidak pernah keberatan dalam rapat perencanaan. Mereka hanya tidak mengubah cara kerja mereka. AI berdiri di samping workflow mereka alih-alih di dalamnya, dan mengklik ke alat tersebut terasa seperti pekerjaan ekstra daripada lebih sedikit.
Workflow Copilot adalah pattern dengan tingkat adopsi tertinggi karena tidak meminta pengguna untuk mengubah pekerjaan mereka. Ia muncul di dalam pekerjaan yang sudah mereka lakukan, menyarankan apa yang harus dilakukan selanjutnya, dan menunggu mereka mengatakan ya atau tidak. Riset McKinsey 2025 tentang AI di tempat kerja menemukan bahwa pengguna AI paling canggih menghasilkan pekerjaan berkualitas lebih tinggi, dan pattern yang mereka gunakan hampir secara universal adalah beberapa bentuk model copilot.
Ini bukan pattern yang paling kuat dalam ACE Framework. Tetapi ini adalah yang benar-benar digunakan. Dan sistem AI yang digunakan mengalahkan sistem yang secara teoritis unggul tetapi tidak.
Formulanya
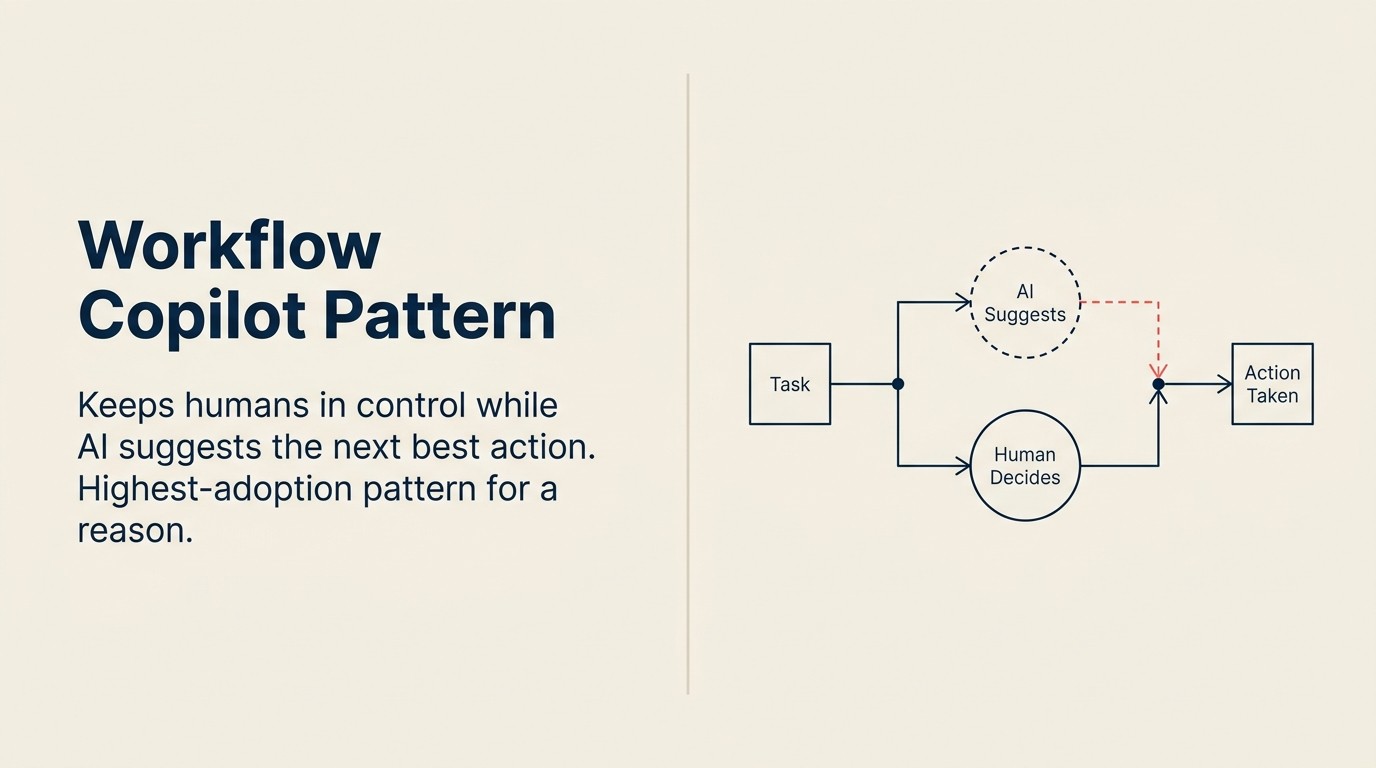
Pattern Workflow Copilot adalah kombinasi spesifik dari empat kemampuan ACE dalam siklus yang berulang:
Ingest (konteks pengguna saat ini) → Analyze (intent dan next-best-action) → Generate (saran atau draf) → Execute (dengan persetujuan manusia eksplisit) → ulangi
Setiap elemen membawa bobot:
Ingest berarti copilot membaca konteks aktif pengguna, bukan prompt generik. Dalam CRM copilot, itu adalah catatan deal yang terbuka, utas email terakhir, tahapan dalam Pipeline. Dalam coding copilot, itu adalah tanda tangan fungsi yang sedang ditulis pengembang, import di atasnya, komentar yang mendeskripsikan intent. Dalam finance copilot, itu adalah template laporan, kumpulan data yang terlihat, dan query yang mulai dibangun analis. Kualitas langkah Ingest menentukan segalanya di hilir.
Analyze mengekstrak intent pengguna saat ini dan memetakannya ke next-best-action. Di sinilah sistem memutuskan jenis saran apa yang berguna saat ini. Bukan setiap saran yang mungkin. Satu yang berguna. "Deal ini berada di tahap proposal, email terakhir empat hari lalu, prospek berada di layanan keuangan" menjadi "sarankan email tindak lanjut yang membahas pertanyaan kepatuhan yang mereka ajukan."
Generate menghasilkan saran aktual. Draf email. Penyelesaian kode. Query SQL. Kalimat untuk ditambahkan ke laporan. Outputnya adalah draf, bukan tindakan langsung. Belum ada yang berubah di dunia. Pengguna masih memegang keputusan. Untuk definisi kemampuan Generate lengkap, lihat Generate: apa yang dapat AI buat untuk bisnis Anda.
Execute (dengan persetujuan manusia) adalah gerbang. Pengguna membaca saran, menerimanya, memodifikasinya, atau mengabaikannya. Jika mereka menerima, tindakan menyala. Kirim email, sisipkan kode, jalankan query. Jika mereka memodifikasi, versi yang dimodifikasi dieksekusi. Jika mereka mengabaikannya, tidak ada yang terjadi.
"Ulangi" adalah yang menjadikannya pattern daripada panggilan AI tunggal. Copilot berputar melalui loop ini secara terus-menerus sementara pengguna bekerja. Setiap kali konteks bergeser, saran baru muncul. Pengguna tetap bergerak; AI tetap mendukung.
Key Facts: Adopsi dan Dampak Workflow Copilot
- Deployment Workflow Copilot mencapai tingkat adopsi 90 hari 3-5x lebih tinggi daripada deployment autonomous agent yang menargetkan tugas knowledge work yang sama, karena gerbang persetujuan memungkinkan pengguna membangun kepercayaan secara bertahap tanpa menyerahkan kendali (Forrester AI Adoption Study, 2025)
- Sales rep yang menggunakan alat copilot tertanam CRM menyelesaikan tugas pasca-panggilan dalam 3-5 menit versus 15-25 menit secara manual, sambil mempertahankan kualitas output yang lebih tinggi karena AI menampilkan konteks yang sebaliknya akan dibiarkan tidak digunakan oleh rep (Gong Sales Intelligence, 2024)
- Organisasi dengan deployment copilot yang matang menargetkan tingkat penerimaan saran 55-75%, yang menunjukkan pengguna terlibat dengan penuh pertimbangan daripada menerima begitu saja (GitHub Copilot Enterprise Study, 2025)
Masalah bisnis yang dipecahkannya
Ada celah antara "tidak ada AI" dan "autopilot penuh" di mana sebagian besar pengguna sebenarnya berada. Autopilot penuh menciptakan kecemasan. Pengguna khawatir tentang apa yang tidak mereka lihat, apa yang tidak mereka kendalikan, apa yang terjadi ketika AI salah. Dalam konteks berisiko tinggi seperti pekerjaan yang menghadap klien, industri yang diregulasi, atau di mana pun dengan akuntabilitas pribadi, kecemasan tersebut sangat rasional.
Tetapi tidak ada AI berarti pengguna menangani segalanya secara manual. Setiap email yang dibuat dari awal. Setiap langkah selanjutnya yang diputuskan sendirian. Setiap laporan yang dibangun baris per baris.
Workflow Copilot adalah posisi tengah yang berhasil. Pengguna tetap di kursi pengemudi. AI adalah co-pilot yang mengatakan "Anda bisa belok di sini" tetapi sebenarnya hanya belok jika pengemudi mengatakannya.
Arsitektur ini memecahkan masalah adopsi karena tidak memerlukan kepercayaan yang belum dibangun pengguna. Pengguna dapat memverifikasi setiap saran sebelum menjadi tindakan. Seiring waktu, seiring saran terbukti andal, langkah persetujuan menjadi lebih cepat. Tetapi pengguna tidak pernah harus menyerahkan kendali untuk mendapatkan nilai. Itulah mengapa tingkat adopsi untuk deployment copilot secara signifikan lebih tinggi daripada untuk deployment autonomous agent yang menargetkan tugas knowledge work yang sama.
Empat contoh nyata secara mendalam
Sales rep copilot dalam CRM
Ingest: Copilot membaca catatan peluang yang terbuka, tahapan Pipeline saat ini, pertukaran email terakhir, dan catatan rapat apa pun yang terkait dengan deal.
Analyze: Ia mengidentifikasi bahwa deal macet di tahap proposal, kontak terakhir enam hari lalu, dan email terbaru prospek menyebutkan waktu tinjauan anggaran.
Generate: Ini menyusun email tindak lanjut: dua paragraf, mereferensikan timeline tinjauan anggaran yang disebutkan prospek, menyarankan panggilan check-in singkat, menyertakan permintaan langkah selanjutnya yang jelas.
Execute: Rep membaca draf di sidebar CRM. Mereka mengedit paragraf kedua untuk menambahkan case study spesifik, lalu klik Kirim. Email meninggalkan akun rep, CRM mencatatnya sebagai aktivitas keluar, dan tahapan diperbarui.
Rep menulis email 6 kata dalam seperempat waktu yang akan dibutuhkan jendela compose kosong. Kualitasnya lebih tinggi dari rata-rata mereka, karena draf memasukkan konteks yang mungkin dibiarkan tidak digunakan oleh rep.
Coding copilot
Ingest: Copilot membaca tanda tangan fungsi, konteks kode di sekitarnya, import di bagian atas file, dan komentar apa pun yang ditulis pengembang yang menggambarkan apa yang harus dilakukan fungsi tersebut.
Analyze: Ia menentukan pengembang sedang menulis fungsi validasi yang memeriksa apakah alamat email diformat dengan benar dan apakah ada dalam daftar izin yang disimpan dalam file konfigurasi.
Generate: Ia menyelesaikan badan fungsi: pemeriksaan regex untuk format, pencarian terhadap objek config, pengembalian kesalahan untuk setiap kasus kegagalan.
Execute: Pengembang membaca saran di overlay inline. Mereka menerima bagian regex dan memodifikasi pencarian config untuk menggunakan nama bidang spesifik dalam struktur config mereka. Tab untuk menerima, edit satu baris, lanjutkan.
Pengembang tidak memulai dari fungsi kosong. Copilot menangani pola boilerplate; pengembang membuat keputusan yang memerlukan pengetahuan tentang sistem spesifik mereka.
Marketing copilot
Ingest: Copilot membaca brief kampanye, segmen target, dan diferensiator produk yang ditandai tim sebagai utama untuk audiens ini.
Analyze: Ia mengidentifikasi pendekatan headline yang diminta brief (dipimpin masalah, bukan dipimpin fitur), batasan jumlah kata, dan contoh nada yang ditautkan dari panduan merek.
Generate: Ini menyusun tiga varian headline dan meta description. Setiap varian mengambil sudut pandang yang berbeda pada brief yang sama.
Execute: Marketer memilih varian dua, menyesuaikan frasa di klausa terakhir, dan menyalinnya ke dalam pembuat kampanye. Brief memerlukan 20 menit penyusunan halaman kosong. Copilot memampatkan itu menjadi 3 menit pemilihan dan pengeditan ringan.
Finance analyst copilot
Ingest: Copilot membaca template laporan, skema sumber data, dan pertanyaan varians spesifik yang diketik analis: "Mengapa pendapatan APAC Q1 12% di bawah rencana?"
Analyze: Ia mengidentifikasi bidang yang dibutuhkan (aktual vs. rencana berdasarkan wilayah dan lini produk), periode perbandingan, dan jenis narasi yang diminta format laporan.
Generate: Ia menulis query SQL untuk menarik perbandingan, dan menyusun penjelasan varians 3 kalimat: slip deal di dua akun enterprise, dampak FX pada pemesanan berdenominasi SGD, satu pembaruan besar yang dipindah ke Q2.
Execute: Analis menjalankan query, memvalidasi output terhadap pengetahuan mereka sendiri tentang buku APAC, mengkonfirmasi dua akun enterprise cocok dengan ingatan mereka, dan menempelkan narasi dengan satu edit. Laporan selesai dalam 25 menit alih-alih 90.
The Peer-Level Assistant Principle
Workflow Copilot bekerja pada tingkat rekan yang mengetahui konteks pekerjaan Anda, bukan asisten yang menunggu instruksi eksplisit atau otomasi yang berjalan tanpa Anda. Kerangka tingkat rekan berarti: satu saran berguna pada momen yang tepat, didasarkan pada apa yang benar-benar Anda lakukan, ditahan hingga Anda memutuskan. Bukan banjir opsi. Bukan tindakan otonom yang mengejutkan Anda. Workflow Copilot yang terus menginterupsi menjadi kebisingan. Yang tetap diam sampai ada sesuatu yang benar-benar berguna untuk dikatakan mendapatkan perhatian pengguna. The Peer-Level Assistant Principle mengatur kadence saran, ruang lingkup konteks, dan desain interaksi persetujuan: ketiganya harus meminimalkan gesekan bagi pengguna, bukan bagi sistem.
Mengapa human-in-the-loop adalah fitur, bukan keterbatasan
Ada godaan untuk memperlakukan langkah persetujuan manusia sebagai kompromi teknis, solusi sementara untuk sistem AI yang belum cukup baik untuk sepenuhnya mengotomatisasi pekerjaan. Framing tersebut salah.
Pada risiko Tier 2 (tingkat di mana knowledge work dengan output yang terlihat klien berada), langkah persetujuan manusia bukan pajak kinerja. Ini adalah yang membuat pattern dapat diterapkan dalam konteks yang benar-benar penting. Riset MIT Sloan tentang tata kelola AI agentic secara konsisten menemukan bahwa pengawasan manusia dalam sistem AI bukan hanya alat manajemen risiko. Ini adalah yang mempertahankan kepercayaan pengguna dari waktu ke waktu, yang merupakan prasyarat untuk adopsi yang berkelanjutan.
Pikirkan tentang kasus sales rep. Nama rep ada di email. Hubungan mereka dengan prospek adalah aset. Mereka perlu memiliki apa yang dikirim. Copilot yang menghilangkan kepemilikan tersebut tidak membantu rep. Ini menggantikan mereka dengan sistem yang tidak mereka percaya karena mereka tidak dapat memverifikasinya pada saat itu.
Langkah persetujuan membuat manusia bertanggung jawab dan terinformasi. Ini berarti rep membaca setiap saran sebelum menyala. Itu berarti rep menangkap kasus di mana copilot salah membaca konteks: komentar "tinjauan anggaran" sebenarnya adalah lelucon tentang vendor sebelumnya, bukan sinyal tentang waktu. Rep menangkapnya dalam 3 detik. Tanpa gerbang, itu keluar.
Tujuan desain yang benar bukan untuk menghilangkan langkah persetujuan. Ini untuk meminimalkan gesekan dari langkah persetujuan. Satu saran yang jelas, ditampilkan dalam konteks, dengan satu interaksi Terima/Edit/Abaikan. Bukan dialog modal. Bukan panel samping yang memerlukan peralihan fokus. Saran tinggal di dalam workflow, dapat dilihat sekilas, dapat ditindaklanjuti tanpa menghentikan gerakan pengguna.
Ketika langkah persetujuan tidak bergesekan, copilot lebih cepat daripada bekerja tanpanya dan lebih aman dari autonomous agent. Itulah target desain.
Failure modes
Deployment copilot gagal dengan cara yang konsisten. Ini bukan risiko teoritis. Ini adalah pola yang membunuh adopsi dalam deployment nyata.
Terlalu banyak saran membunuh aliran. Copilot yang menginterupsi setiap tiga klik berhenti membantu dan mulai menjadi gangguan. Pengguna melewatinya. Panel saran secara mental diarsipkan di samping lencana notifikasi: sesuatu untuk diabaikan. Perbaikan: satu saran pada satu waktu, ditampilkan hanya ketika konteks telah berubah secara bermakna. Copilot yang tetap diam dan menunggu momen yang tepat untuk berbicara lebih berharga dari yang terus berbicara.
Saran berkualitas rendah mengikis kepercayaan. Satu saran buruk di awal pilot melakukan kerusakan yang tidak proporsional. Pengguna mencoba sistem untuk pertama kalinya, membentuk model mental mereka tentang apakah itu andal. Saran yang jelas salah, yang salah membaca konteks atau mengusulkan sesuatu yang diketahui pengguna salah, menanam benih keraguan yang tidak hilang. Perbaikan: saran kepercayaan tinggi saja di minggu-minggu pertama. Tampilkan saran hanya ketika skor kepercayaan sistem melampaui threshold. Lebih baik tetap diam dan melewatkan beberapa kesempatan daripada menampilkan saran buruk yang akan diingat pengguna selama berbulan-bulan.
Context drift. Copilot kehilangan jejak utas percakapan dan mulai menyarankan tindakan berdasarkan konteks yang sudah usang. Dalam CRM copilot, ini mungkin berarti sistem masih bernalar tentang deal yang ditutup dua menit lalu, menyarankan langkah selanjutnya untuk prospek yang baru saja dipindahkan rep ke "Closed Lost." Perbaikan: refresh konteks eksplisit yang terikat ke peristiwa navigasi pengguna, bukan hanya interval waktu.
Copilot creep. Tim merasa nyaman dengan sistem dan mulai melewati langkah persetujuan karena "selalu benar." Seseorang mengonfigurasi workflow sehingga saran dieksekusi dengan satu tab daripada memerlukan persetujuan eksplisit. Kecepatan meningkat. Kemudian kesalahan serius pertama terjadi. Rep mengirimkan penetapan harga yang salah, atau penggabungan kode terjadi tanpa tinjauan akhir, dan tiba-tiba organisasi memiliki percakapan tentang apakah harus mematikan seluruh sistem. Perbaikan: buat langkah persetujuan struktural, bukan opsional, dan perlakukan solusi apa pun sebagai insiden tata kelola yang layak ditangani.
Kapan memilih Workflow Copilot vs. alternatif
Vs. RAG Assistant: RAG adalah tanya-jawab sesuai permintaan. Pengguna bertanya; AI mengambil dan menjawab. Workflow Copilot bersifat proaktif. AI mengawasi apa yang Anda lakukan dan menyarankan apa yang harus dilakukan selanjutnya, tanpa pengguna harus bertanya. Gunakan RAG ketika pengguna perlu mencari sesuatu. Gunakan Workflow Copilot ketika pengguna perlu menghasilkan sesuatu.
Vs. Autonomous Agent: Pattern Autonomous Agent menjalankan loop tugas tanpa keterlibatan pengguna yang berkelanjutan. Pengguna memberikan tujuan; agen mencari tahu langkah-langkahnya, menggunakan alat, menangani kegagalan, dan menyampaikan hasilnya. Workflow Copilot menjaga pengguna dalam loop sepanjang waktu. Gunakan Autonomous Agent untuk tugas terbatas di mana pengguna tidak perlu dilibatkan di setiap langkah dan tugas memiliki status penyelesaian yang jelas. Gunakan Workflow Copilot ketika penilaian pengguna diperlukan di setiap langkah atau ketika akuntabilitas tetap pada pengguna.
Vs. Scoring dan Routing: Scoring menangani triage inbound tanpa pengguna dalam loop sama sekali. Lead masuk tiba; AI memberi skor dan merutekannya ke rep yang tepat. Tidak ada manusia yang membuat keputusan routing tersebut. Scoring dan Routing sesuai untuk input terstruktur bervolume tinggi di mana aturan routing terdefinisi dengan baik dan biaya misroute sesekali rendah. Workflow Copilot adalah untuk pekerjaan yang tidak memiliki satu jawaban yang benar, di mana penilaian dan konteks pengguna tidak tergantikan.
Memahami gradien risiko di seluruh AI pattern berguna di sini. Workflow Copilot berada di tengah kurva risiko. Lebih terlibat dari pencarian RAG. Kurang berisiko dari autonomous agent. Cocok ketika tugas memerlukan penilaian tetapi kepemilikan manusia penting.
ROI signals
Ukur ini untuk mengetahui apakah copilot Anda berfungsi:
| Metrik | Apa yang dikatakan |
|---|---|
| Waktu penyelesaian tugas | Apakah rep menulis email lebih cepat? Analis membangun laporan dalam waktu lebih sedikit? |
| Tingkat kesalahan dalam pekerjaan yang dihasilkan pengguna | Apakah output yang dibantu copilot lebih akurat dari yang tidak dibantu? |
| Tingkat penerimaan saran | Berapa persentase saran copilot yang ditindaklanjuti pengguna? Di bawah 20% berarti masalah relevansi. Di atas 90% mungkin berarti standar terlalu rendah. |
| Skor kepuasan pengguna | Sinyal kualitatif. Pengguna yang menyukai copilot akan memberi tahu Anda apa yang harus diperbaiki. |
| Volume yang diproses per pengguna per hari | Throughput bersih dengan AI vs. tanpanya. Ini adalah item baris produktivitas yang dipedulikan finance. |
| Latensi saran | Waktu dari pergeseran konteks hingga saran muncul. Lebih dari 2 detik merusak adopsi. |
Lacak tingkat penerimaan saran dengan hati-hati. Tingkat yang sangat tinggi (di atas 95%) dapat berarti pengguna menerima tanpa membaca, yang merupakan risiko tata kelola, bukan sinyal keberhasilan.
Organisasi dengan deployment copilot yang matang menargetkan tingkat penerimaan saran 55-75%, yang menunjukkan pengguna terlibat dengan penuh pertimbangan daripada menerima begitu saja, dan saran copilot cukup relevan untuk dipertimbangkan (GitHub Copilot Enterprise Study, 2025). Di bawah 20% menunjukkan masalah relevansi. Di atas 90% menunjukkan masalah tinjauan.
Desain untuk kepercayaan
Kualitas saran di minggu pertama deployment copilot menentukan adopsi jangka panjang. Pengguna membentuk pendapat dengan cepat. Jika lima saran pertama tepat sasaran, pengguna mulai mencari yang berikutnya. Jika tiga pertama salah, pengguna berhenti mencari. Panel copilot menjadi tidak terlihat.
Tiga keputusan desain menentukan kualitas di minggu pertama. Riset HBR tentang knowledge workers AI mencatat bahwa deployment AI terbaik berasal dari organisasi yang memperlakukan AI sebagai kolaborator daripada utilitas, yang persis merupakan filosofi desain yang diwujudkan oleh pattern copilot:
Ruang lingkup jendela konteks. Jendela konteks copilot harus sengaja dibatasi pada input sinyal tinggi. Dalam CRM copilot, itu adalah deal saat ini, utas email terbaru, dan tugas terbuka rep. Ini seharusnya bukan seluruh riwayat CRM rep atau umpan global. Jendela konteks yang sempit dan relevan menghasilkan saran yang lebih baik dari yang lebar dan berisik.
Filter kepercayaan. Jangan tampilkan setiap saran yang dihasilkan model. Tetapkan threshold kepercayaan dan hanya tampilkan saran yang melampauinya. Pengguna harus menerima satu saran yang bagus daripada lima yang biasa-biasa. Yang pertama mendapat kepercayaan. Yang terakhir membakarnya.
Tampilan kepercayaan. Pertimbangkan untuk menunjukkan kepada pengguna mengapa copilot membuat saran tertentu. Bukan skor probabilitas (pengguna tidak menginterpretasikannya dengan baik) tetapi catatan dasar singkat: "Disarankan berdasarkan email terakhir prospek tentang timeline kepatuhan." Transparansi mengurangi perasaan kotak hitam yang membuat pengguna tidak mempercayai output yang dihasilkan AI. Pengguna yang memahami mengapa saran muncul lebih cenderung mengevaluasinya dengan serius daripada menerima atau menolak secara refleks.
Copilot yang dirancang dengan baik yang menampilkan satu saran yang bagus lebih berharga dari panel sepuluh yang biasa-biasa. Ekonomi kepercayaan bersifat asimetris: dibutuhkan puluhan saran yang baik untuk membangun kredibilitas, dan satu yang buruk untuk merusaknya secara signifikan.
Apa yang akan datang selanjutnya
Workflow Copilot adalah pattern masuk untuk tim yang merasa nyaman dengan AI dalam workflow inti mereka. Ini bukan batas atas.
Seiring kepercayaan organisasi Anda pada output yang dihasilkan AI tumbuh dan seiring tooling Anda mengakumulasi riwayat audit, beberapa workflow adalah kandidat untuk meningkatkan otonomi. Perkembangannya disengaja: copilot pertama, dengan gerbang manusia eksplisit; kemudian otomatisasi selektif jalur persetujuan yang dipahami dengan baik; kemudian eksekusi otonom sejati untuk kategori tugas yang terbatas dan berisiko rendah.
Menumpuk Workflow Copilot dengan pattern lain adalah cara AI Agents di Level 3 dibangun. Gabungkan Scoring dan Routing (triage inbound), Meeting Intelligence (analisis panggilan), dan Workflow Copilot (draf outreach) dan Anda memiliki sesuatu yang mendekati AI Sales Operator. Pattern-pattern tersebut bertambah. Lihat Menumpuk Pattern untuk Membangun AI Agents untuk cara kerja kombinasi tersebut dalam praktik. Untuk deployment khusus penjualan dari pattern ini, kebersihan data CRM dengan AI copilot dan next best action untuk setiap deal yang terbuka menunjukkannya dalam tindakan.
Rework Analysis: Keunggulan adopsi Workflow Copilot berasal dari pilihan desain sederhana: pengguna tidak pernah harus mempercayai AI sebelum mendapatkan nilai darinya. Setiap saran dapat ditinjau. Setiap tindakan dapat dibalik sebelum menyala. Ini berarti pengguna yang skeptis dapat mencoba copilot selama dua minggu tanpa risiko, memverifikasi bahwa saran relevan, dan membangun kepercayaan dengan kecepatan mereka sendiri. Deployment Autonomous Agent tidak menawarkan ini. Mereka membutuhkan kepercayaan di muka, itulah mengapa tingkat adopsi tertinggal. Model copilot mendapatkan kepercayaan melalui rekam jejak yang dapat dilihat pengguna, saran demi saran. Tim yang memaksimalkan ROI copilot membuat tiga hal mudah: membaca saran (satu output yang jelas, dalam konteks), bertindak atasnya (satu ketukan, bukan tiga klik), dan mengesampingkannya (abaikan tanpa gesekan tanpa saran langsung kembali). Tiga pilihan desain tersebut membuat perbedaan antara alat yang mengubah cara orang bekerja dan fitur yang tidak digunakan siapapun.
Pertanyaan yang Sering Diajukan
Apa itu Workflow Copilot AI pattern?
Workflow Copilot adalah AI pattern yang membantu knowledge worker di dalam tugas aktif mereka dengan terus berputar melalui: Ingest (konteks saat ini), Analyze (intent dan next-best-action), Generate (saran atau draf), Execute (dengan persetujuan manusia eksplisit). Ini berbeda dari autonomous agent dalam hal manusia menyetujui setiap tindakan sebelum menyala. Ini berbeda dari RAG dalam hal bersifat proaktif (mengawasi apa yang dilakukan pengguna dan menyarankan) daripada reaktif (menunggu pertanyaan).
Apa itu The Peer-Level Assistant Principle?
The Peer-Level Assistant Principle menyatakan bahwa Workflow Copilot harus beroperasi pada tingkat rekan yang mengetahui konteks Anda, bukan asisten yang menunggu instruksi atau otomasi yang berjalan tanpa Anda. Dalam praktiknya ini berarti: satu saran berguna pada momen yang tepat, didasarkan pada apa yang benar-benar Anda lakukan, ditahan hingga Anda memutuskan. Bukan banjir opsi. Bukan tindakan otonom. Prinsip ini mengatur kadence saran (diam sampai ada sesuatu yang benar-benar berguna), ruang lingkup konteks (sempit dan relevan), dan UX persetujuan (tidak bergesekan, dalam konteks, interaksi tunggal).
Mengapa Workflow Copilot memiliki adopsi yang lebih tinggi dari autonomous agent?
Workflow Copilot mencapai tingkat adopsi 90 hari 3-5x lebih tinggi daripada deployment autonomous agent yang menargetkan tugas yang sama (Forrester, 2025) karena gerbang persetujuan memungkinkan pengguna membangun kepercayaan secara bertahap. Pengguna dapat mencoba copilot selama berminggu-minggu tanpa risiko, memverifikasi saran relevan, dan memutuskan kecepatan ketergantungan mereka sendiri. Autonomous agent membutuhkan kepercayaan sebelum pengguna memiliki rekam jejak untuk membenarkannya. Copilot mendapatkan kepercayaan melalui riwayat saran yang terlihat yang dapat dievaluasi pengguna secara langsung.
Tingkat penerimaan saran apa yang menunjukkan Workflow Copilot yang sehat?
Tingkat penerimaan yang sehat adalah 55-75%, menunjukkan pengguna terlibat dengan penuh pertimbangan daripada menerima begitu saja (GitHub Copilot Enterprise Study, 2025). Di bawah 20% menandakan masalah relevansi: jendela konteks copilot terlalu lebar, filter kepercayaan terlalu longgar, atau kasus penggunaan tidak cocok dengan pattern. Di atas 90% menandakan masalah tinjauan: pengguna menerima tanpa membaca, yang merupakan risiko tata kelola. Satu saran yang diterima yang buruk yang mencapai klien atau system-of-record dapat merusak kepercayaan lebih dari berbulan-bulan saran yang baik dapat membangunnya.
Apa failure mode Workflow Copilot yang paling umum?
Empat failure mode secara konsisten membunuh adopsi: terlalu banyak saran (menginterupsi aliran, diabaikan), saran awal berkualitas rendah (pengguna membentuk kesan negatif yang bertahan di minggu pertama), context drift (copilot bernalar tentang deal atau tugas yang sudah ditutup), dan copilot creep (tim melewati langkah persetujuan dan secara tidak sengaja menerapkan autonomous agent tanpa tata kelola autonomous agent). Yang paling merusak adalah saran awal berkualitas rendah, karena kepercayaan bersifat asimetris: puluhan saran yang baik membangun kredibilitas, satu yang buruk merusaknya secara signifikan.
Bagaimana Workflow Copilot berbeda dari Autonomous Agent?
Workflow Copilot menjaga pengguna dalam loop sepanjang waktu, memerlukan persetujuan eksplisit sebelum setiap tindakan. Autonomous Agent menjalankan loop tugas yang mengejar tujuan dengan titik pemeriksaan manusia yang minimal. Gunakan Workflow Copilot ketika penilaian pengguna diperlukan di setiap langkah atau ketika akuntabilitas pribadi tetap pada manusia (pekerjaan yang menghadap klien, industri yang diregulasi). Gunakan Autonomous Agent untuk tugas terbatas dengan status penyelesaian yang jelas di mana pengguna tidak perlu menyetujui langkah-langkah perantara. Kedua pattern berada di jalur yang sama: copilot membangun kepercayaan yang pada akhirnya membenarkan eksekusi otonom selektif.
Pelajari lebih lanjut

Co-Founder, Rework.com
On this page
- Formulanya
- Masalah bisnis yang dipecahkannya
- Empat contoh nyata secara mendalam
- Sales rep copilot dalam CRM
- Coding copilot
- Marketing copilot
- Finance analyst copilot
- The Peer-Level Assistant Principle
- Mengapa human-in-the-loop adalah fitur, bukan keterbatasan
- Failure modes
- Kapan memilih Workflow Copilot vs. alternatif
- ROI signals
- Desain untuk kepercayaan
- Apa yang akan datang selanjutnya
- Pelajari lebih lanjut