AI Lead Scoring Más Allá de los Modelos Basados en Reglas

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La mayoría del "lead scoring" desplegado hoy es ponderación manual disfrazada de inteligencia.
La lógica es: un envío de formulario vale 10 puntos, un título de VP agrega 20, una empresa con más de 200 empleados agrega 15, visitar la página de precios agrega 25. Súmelo y todo lo que supere 70 es un "lead caliente". El equipo de ventas trabaja primero los leads calientes.
El problema es obvio una vez que lo dice en voz alta: un humano decidió esos pesos. Hizo un juicio, probablemente informado por algo de intuición y algunos anécdotas del equipo de ventas, y lo codificó como reglas estáticas. Los pesos no se actualizan cuando el mercado cambia. No se recalibran cuando su Ideal Customer Profile (ICP) cambia después de levantar una Serie B. Y definitivamente no capturan la interacción entre señales.
Un título de VP de una empresa de 50 personas a las 2 AM de un sábado convierte a una tasa completamente diferente que el mismo título de una empresa de 300 personas a las 10 AM de un martes.
El lead scoring con machine learning (ML) deja que los datos elijan los pesos en lugar de los humanos. Esa es la diferencia conceptual completa. Pero ejecutarlo bien requiere entender cómo funciona el modelo, qué datos necesita y dónde fallan los despliegues. Este es el Patrón 1 en la arquitectura del AI Sales Operator, y la base sobre la que se construye todo lo demás.
Lo que el scoring basado en reglas pierde
Las reglas son categóricas. Los modelos de ML son probabilísticos. La investigación de McKinsey sobre IA en ventas B2B identifica la calificación de leads como uno de los casos de uso de IA de mayor impacto para los equipos de ventas, precisamente porque la mejora se compone: mejor scoring significa que los representantes trabajan mejores leads, lo que significa más cierres, lo que significa mejores datos de entrenamiento para la siguiente iteración del modelo. Esa distinción produce un conjunto de puntos ciegos sistemáticos en los enfoques basados en reglas:
Escasez de campos. La mayoría de los formularios de leads capturan 4-6 campos. La mayoría de los registros del CRM tienen docenas de campos potencialmente relevantes, muchos de ellos vacíos. Las reglas tratan los campos vacíos como neutros. Los modelos de ML pueden aprender que una URL de LinkedIn faltante en una banda específica de tamaño de empresa se correlaciona con tasas de cierre más bajas, porque eso es lo que muestran los datos históricos. La ausencia de información es en sí misma una señal.
Timing y secuencia. Un lead que visita la página de precios el día uno y completa el formulario de demo el mismo día convierte de manera diferente que un lead que visitó la página de precios tres semanas antes de enviar el formulario, luego volvió a visitar el día anterior. Las reglas pueden detectar "visita a la página de precios = 25 puntos", pero no capturan curvas de recencia ni secuencias de comportamiento. Los modelos de ML sí.
Señales de cambio firmográfico. Una empresa que acaba de contratar a un VP de Ventas es un prospecto fundamentalmente diferente a la misma empresa seis meses atrás. Una ronda de financiamiento reciente cambia la capacidad de compra. Un nuevo lanzamiento de producto crea necesidades tecnológicas. Las reglas estáticas no captan estas señales dinámicas. Los modelos de ML alimentados con datos firmográficos recientes (de fuentes como LinkedIn, Clearbit o 6sense) pueden tenerlos en cuenta.
Interacciones multi-touch. La combinación "título VP + página de precios + fuente de referencia = canal de socios" podría convertir al 40%. Cada elemento por sí solo podría valer el 10%. Las reglas los puntúan de forma independiente; el ML captura el efecto de interacción.
Key Facts: AI Lead Scoring
- McKinsey identifica la calificación de leads como uno de los casos de uso de IA de mayor impacto para los equipos de ventas B2B, porque mejor scoring se compone: mejores leads cierran con más frecuencia, generando mejores datos de entrenamiento para la siguiente iteración del modelo
- Se requiere un mínimo de 200 deals cerrados-ganados para un modelo confiable de AI lead scoring con ML; por debajo de 100, la mayoría de las herramientas comerciales producen output estadísticamente indistinguible de una asignación aleatoria
- Las empresas que usan AI lead scoring reportan tasas de conversión de lead a oportunidad un 10-20% más altas en comparación con los modelos estáticos basados en reglas, según los datos de clientes de MadKudu y 6sense (2022-2024)
Cómo funciona el AI lead scoring con ML (sin necesidad de un doctorado)
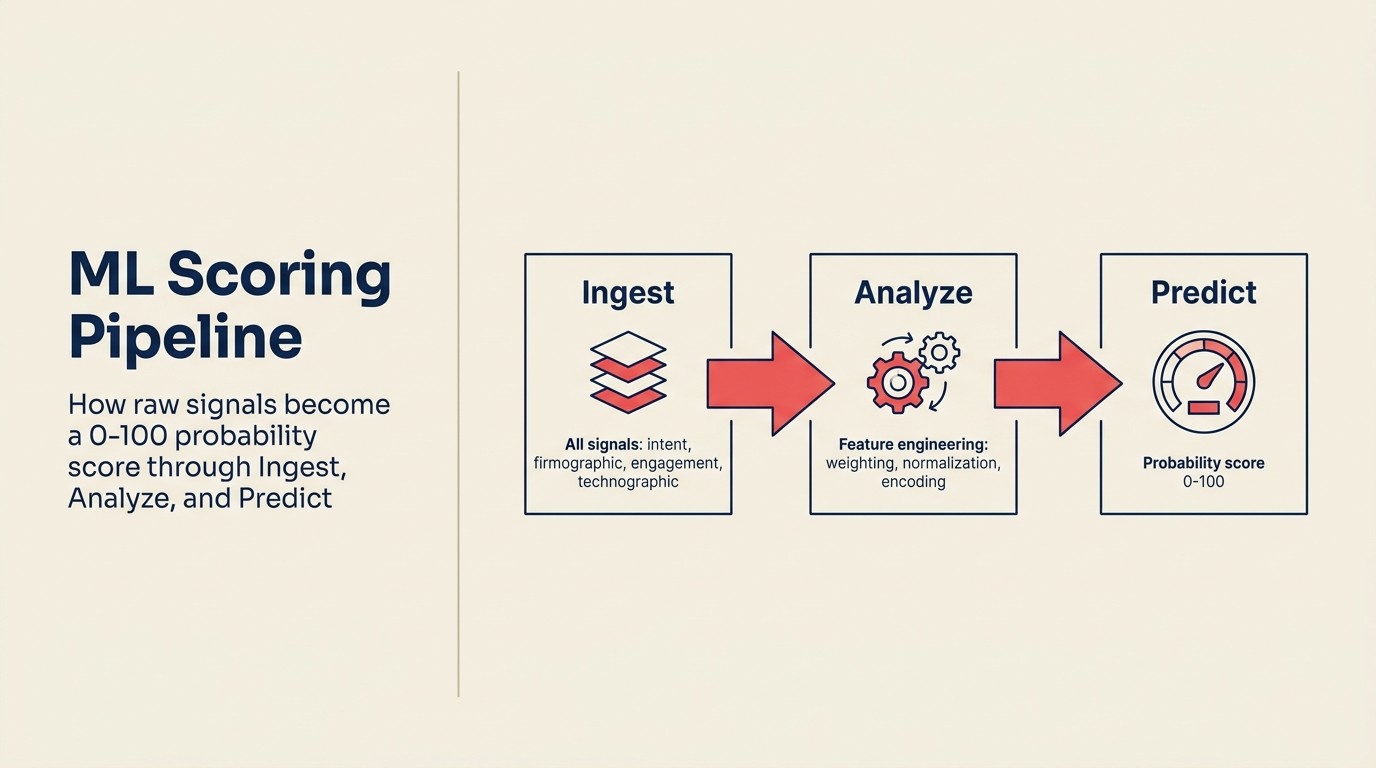
La mecánica es más simple de lo que la mayoría de los proveedores hacen parecer. Aquí está la lógica operativa, usando el vocabulario del ACE Framework:
Ingest extrae todas las señales disponibles para cada lead: campos del CRM (título, tamaño de empresa, industria, fuente), datos de comportamiento (páginas visitadas, emails abiertos, webinar al que asistió), enriquecimiento firmográfico (banda de ingresos, headcount, etapa de financiamiento, tech stack) y datos temporales (cuándo ocurrieron las actividades, intervalos entre ellas).
Analyze extrae características de esos datos brutos. Las características son las variables de input con las que realmente se entrena el modelo. Algunas son directas (título = "VP" → característica binaria). Algunas están diseñadas (días entre la primera visita y el envío del formulario → característica numérica). Algunas son términos de interacción (tamaño de empresa × frecuencia de engagement → señal compuesta). La ingeniería de características es donde ocurre la mayor parte del trabajo, y donde los equipos de ops que entienden sus propios datos tienen una ventaja sobre los modelos genéricos listos para usar.
Predict entrena un modelo en datos históricos etiquetados: deals que cerraron (ganados) y deals que no cerraron (perdidos), junto con todas las características anteriores. Bajo el capó, la mayoría de las herramientas comerciales de lead scoring usan regresión logística o gradient boosting, ambas técnicas de ML bien entendidas que producen una probabilidad entre 0 y 1. El modelo aprende qué combinaciones de características se correlacionan con resultados de cerrado-ganado en su base de clientes específica y aplica esos pesos aprendidos a cada nuevo lead, produciendo un output de probabilidad: este lead tiene un 73% de probabilidad de convertir, dado lo que sabemos sobre él.
Eso es todo. Un número de probabilidad del 0 al 100, fundamentado en su propio historial de ganados/perdidos, actualizado a medida que cierran nuevos deals. El ciclo de recalibración es lo que separa un modelo que funciona de uno que deriva gradualmente.
El Estándar de Puntuación de Lead Probabilística
El Estándar de Puntuación de Lead Probabilística define lo que debe incluir una puntuación de lead AI defendible: un output de probabilidad entre 0 y 1 fundamentado en el historial propio de ganados/perdidos de la empresa, entrenado en al menos 200 resultados de cerrado-ganados, recalibrado no menos de una vez por trimestre contra nuevos resultados de deals, y expuesto a los representantes con atribución de características (qué señales impulsaron esta puntuación). Cualquier sistema de puntuación que no cumpla uno de estos cuatro criterios se clasifica mejor como scoring mejorado basado en reglas que como verdadero scoring con ML, porque el output no está estadísticamente fundamentado en patrones de conversión medidos.
Tipos de señales clasificados por lift de conversión

No todas las señales son igualmente útiles. Basándose en patrones de la investigación de MadKudu y los datos de intención de compra de 6sense publicados entre 2022 y 2024, así es como se clasifican generalmente las categorías de señales en la contribución de lift para B2B SaaS:
| Tipo de Señal | Ejemplos | Contribución de Lift | Notas |
|---|---|---|---|
| Señales de intención | Visitas a la página de precios, páginas de comparación de competidores, vistas de categoría en G2 | Muy alta | Señales de compra en etapa tardía; la recencia importa (últimos 7 días >> últimos 30 días) |
| Recencia de engagement | Aperturas de email, visitas al sitio en los últimos 14 días, webinar al que asistió | Alta | La curva de recencia importa: decaimiento exponencial pasados los 30 días |
| Ajuste firmográfico | Tamaño de empresa, vertical de industria, etapa de financiamiento | Alta | Su definición de ICP codificada matemáticamente |
| Ajuste tecnográfico | Tipo de CRM (Salesforce vs. HubSpot), integraciones conocidas, tech stack actual | Media-Alta | Mayor lift cuando su producto desplaza o complementa una herramienta específica |
| Desencadenantes de noticias | Financiamiento reciente, anuncios de nuevas contrataciones, lanzamientos de productos | Media | Señal fuerte para el outbound frío; menos predictivo para el inbound |
| Ajuste a nivel de contacto | Título, antigüedad, departamento | Media | Más fuerte cuando se combina con el ajuste a nivel de empresa, más débil en aislamiento |
| Fuente del lead | Búsqueda orgánica, referencia de socio, descarga de contenido | Baja-Media | Varía enormemente por empresa; siempre pruebe en lugar de asumir |
| Comportamiento en el formulario | Tiempo en el formulario, campos completados, tipo de dispositivo | Baja | Útil como desempate; no es una señal principal |
El orden cambia según su producto y mercado. Para una herramienta de desarrolladores, el ajuste tecnográfico podría ser la señal más fuerte. Para un producto de servicios financieros, la banda firmográfica y el contexto regulatorio podrían dominar. El modelo aprende el orden específico de su empresa a partir de sus datos; la tabla anterior es una hipótesis de partida.
Lista de verificación de preparación de datos antes de desplegar
Este es el paso que la mayoría de las empresas omiten. El AI lead scoring no produce buenos resultados con datos malos. Antes de comprar o configurar cualquier herramienta de scoring con ML, revise esta lista:
Requisitos mínimos:
- Al menos 6 meses de deals cerrados con etiquetado consistente de ganado/perdido (se prefieren 12 meses)
- Al menos 200 deals cerrados-ganados en total (más es mejor; por debajo de 100 se producen modelos poco confiables)
- Las etapas del deal en el CRM son consistentes en todo el equipo (sin variaciones de "Cerrado Ganado" vs. "Ganado" vs. "Cerrado")
- La fuente del primer contacto está capturada en al menos el 70% de los registros
- El nombre y dominio de la empresa están completados en más del 80% de los registros
Bueno tener (mejora significativamente la calidad del modelo):
- Título y antigüedad del contacto capturados en al menos el 60% de los leads
- Tamaño de empresa (número de empleados) capturado o enriquecible para más del 70% de los registros
- Datos de comportamiento del sitio web (seguimiento de HubSpot, Segment o equivalente) enviando eventos al CRM
- Al menos una fuente de enriquecimiento firmográfico (Clearbit, Apollo, ZoomInfo) alimentando el CRM
Señales de advertencia que sugieren trabajo en los datos antes del scoring:
- Más del 20% de los deals cerrados sin una etiqueta de resultado
- Tres o más nombres de etapa diferentes para la misma posición en el ciclo de vida
- Menos de 6 meses de historial de deals desde una migración del CRM (los datos pre-migración suelen ser poco confiables)
- Cero datos de seguimiento de comportamiento (sin historial de visitas a páginas, sin seguimiento de aperturas de email)
Si le faltan múltiples elementos de la lista mínima, pase cuatro a seis semanas limpiando datos antes de desplegar el scoring. El modelo se construirá con lo que le dé.
Del output del modelo al umbral de routing
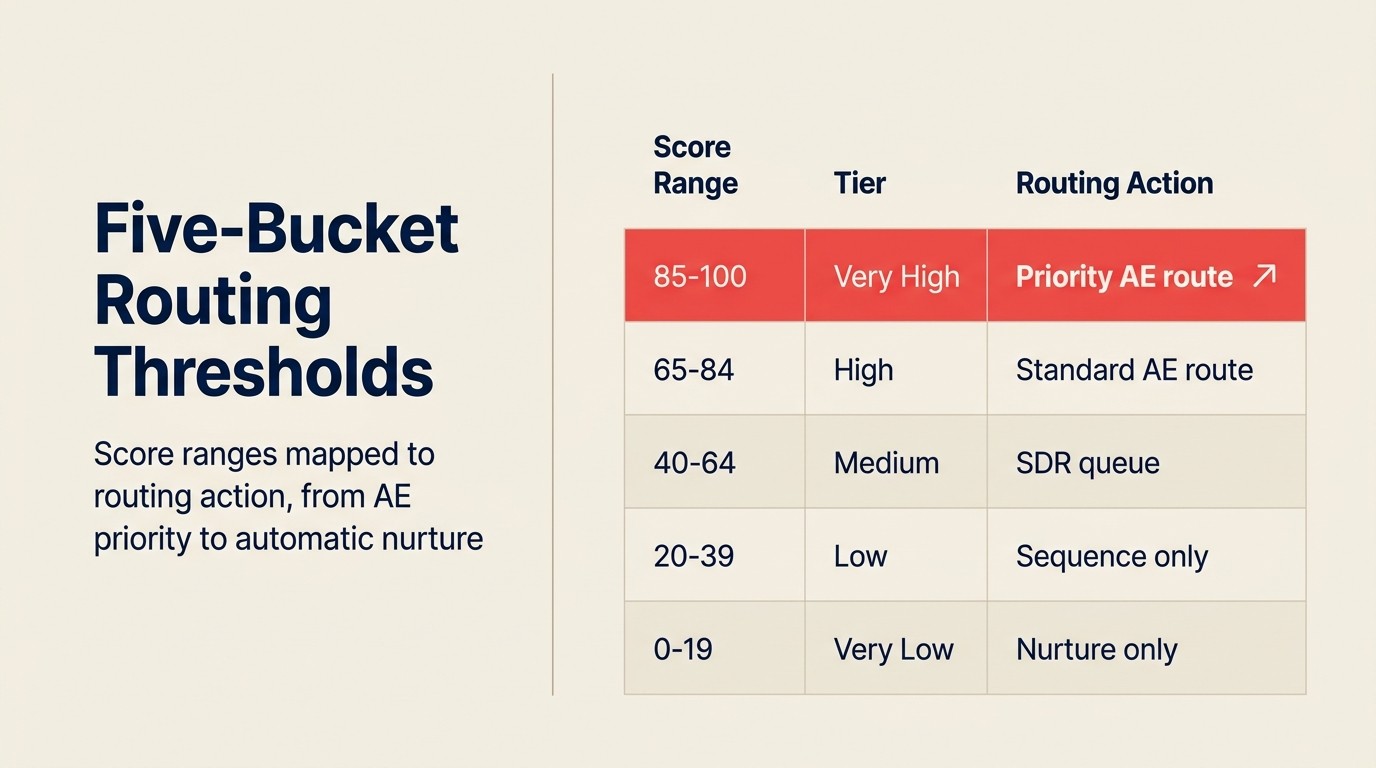
Un modelo le da una probabilidad. Todavía necesita decidir qué hacer con ella.
La mayoría de los despliegues definen tres a cinco buckets con lógica de routing adjunta:
| Rango de Puntuación | Etiqueta | Acción de Routing |
|---|---|---|
| 85-100% | Muy Alto | Enrutar al AE senior, notificación inmediata en Slack, sin filtro de SDR |
| 65-84% | Alto | Cola de AE, SLA: contactar dentro de 2 horas |
| 40-64% | Medio | Enrutar al SDR para calificación, inscribir en secuencia de toque medio |
| 20-39% | Bajo | Inscripción automática en secuencia de nurturing, sin asignación de representante |
| 0-19% | Muy Bajo | Sin acción; agregar solo a la lista de newsletter |
Los números de umbral son suyos para establecer, no del proveedor. Deben reflejar: cuánta capacidad de representante tiene (más representantes = umbral más bajo para la asignación directa), con qué frecuencia puede tolerar un falso positivo (un lead con puntuación alta que resulta ser incorrecto = tiempo del representante desperdiciado) y cuáles son sus compromisos actuales de SLA de contacto.
Establecer correctamente los umbrales es un ejercicio de calibración, no una configuración única. Ejecute con los umbrales iniciales durante 60 días, luego compare: para cada bucket, ¿cuál fue la tasa de conversión real? Si su bucket "Alto" convierte al 8% y su bucket "Medio" convierte al 12%, sus umbrales están mal calibrados. Ajuste y vuelva a observar. Y siempre preste atención al volumen de la cola: una deriva de umbrales que de repente envía el 40% de los leads al bucket "Alto" destruirá la confianza de los representantes en semanas.
Modos de fallo comunes
Modelo entrenado con datos históricos sesgados. Si sus victorias históricas se inclinan hacia un canal específico (por ejemplo, el 70% de sus deals cerrados provino de referencias de socios), el modelo aprenderá a puntuar alto los leads provenientes de socios. Cuando se expanda a un nuevo canal, el modelo puntuará esos leads de forma deficiente. No porque sean malos leads, sino porque no tiene datos de entrenamiento para ese patrón. Corrección: vuelva a entrenar con datos más amplios, o segmente los modelos por fuente.
Puntuaciones que no se muestran a los representantes. El modelo produce un buen output, pero vive en un campo del CRM que nadie mira. Los representantes siguen trabajando los leads en orden de llegada. Este es un fallo de adopción, no un fallo del modelo. Corrección: muestre las puntuaciones en el flujo de trabajo diario del representante (notificación en Slack, cola del CRM ordenada por puntuación) y capacite a los representantes sobre qué significa la puntuación antes de la puesta en marcha.
Sin ciclo de retroalimentación para volver a entrenar. El modelo se configura en enero y nunca se vuelve a tocar. Doce meses después, el mercado ha cambiado, el ICP ha evolucionado y el modelo todavía está optimizando para patrones de hace 18 meses. Corrección: construya un proceso trimestral de recalibración. El líder de RevOps revisa las métricas de rendimiento del modelo (exactitud, precisión, recall por bucket) y activa un re-entrenamiento cuando la exactitud cae más de 5 puntos porcentuales.
Umbrales establecidos y olvidados. Los umbrales iniciales se establecen en la puesta en marcha y nunca se revisan. 90 días después, el 40% de todos los leads puntúan "Alto" porque el modelo aprendió demasiado ampliamente. La cola "Alta" está abrumando a los representantes y la confianza colapsa. Corrección: revise la distribución de umbrales mensualmente y ajuste para mantener el volumen de cola correcto para la capacidad de representantes.
Tratamiento completo de los errores comunes de AI lead scoring.
Instantánea de proveedores
Salesforce Einstein Lead Scoring está incluido con Sales Cloud Enterprise y superiores. Se entrena directamente con sus datos de Salesforce, sin necesidad de exportar ni conectar a una herramienta de terceros. El modelo se recalibra automáticamente en un horario periódico. La calidad es sólida para empresas con datos limpios de Salesforce y 12+ meses de historial. Configuración limitada para ingeniería de características avanzada o fuentes de datos personalizadas.
HubSpot Predictive Lead Scoring está disponible en Marketing Hub Professional/Enterprise y Sales Hub Enterprise. Arquitectura similar a Einstein: se entrena con datos de HubSpot, produce puntuaciones visibles en el Pipeline de HubSpot. Más débil para empresas con datos de comportamiento significativos fuera de HubSpot o necesidades complejas de segmentación firmográfica.
MadKudu es una plataforma de scoring B2B diseñada específicamente que se conecta a Salesforce, HubSpot y múltiples fuentes de enriquecimiento de datos. Muestra la importancia de las características (qué señales impulsaron una puntuación específica), lo que facilita la auditoría y calibración por parte de RevOps. Ideal para empresas que quieren transparencia en la lógica del modelo y están dispuestas a realizar el trabajo de integración de datos.
6sense se enfoca en señales de intención (identificación del comité de compras, seguimiento de visitantes anónimos) más que en probabilidad de conversión. Su fortaleza es la priorización de cuentas en la etapa media del funnel, especialmente para la venta basada en cuentas. A menudo se usa como capa encima de un modelo de scoring nativo del CRM en lugar de reemplazarlo.
Rework Sales AI incluye Scoring+Routing integrado en el CRM como parte de la arquitectura completa del AI Sales Operator. Las puntuaciones se recalibran a partir de los resultados de deals, se enrutan automáticamente a las colas de representantes y se alimentan directamente en el Workflow Copilot para borradores de seguimiento. La mejor opción para equipos que quieren scoring integrado sin gestionar una relación de proveedor separada.
Rework Analysis: El fallo más común de AI lead scoring con ML que vemos no es un mal modelo. Es un buen modelo que nadie recalibra. Los equipos despliegan en Q1, ven buenos resultados en Q2, y para Q4 se preguntan por qué los leads "calientes" ya no cierran. El modelo fue entrenado en un mercado que existió hace 9 meses. Su ICP cambió después de un cambio de precios, un nuevo competidor entró al mercado, o surgió un nuevo caso de uso. La recalibración trimestral no es mantenimiento opcional; es el mecanismo que mantiene el output de probabilidad conectado a la realidad actual. Los equipos que incorporan la revisión de recalibración en su calendario de ops desde el primer día mantienen el ROI durante 12-18 meses. Los que tratan el modelo como una instalación única típicamente ven el rendimiento estabilizarse en 6 meses.
El ciclo de retroalimentación es todo el juego
El scoring basado en reglas es una hipótesis: estos atributos deberían predecir la conversión. Lo establece una vez y espera que envejezca bien.
El scoring con ML es una medición: estos atributos sí predijeron la conversión, basándose en resultados reales, actualizados a medida que llegan nuevos resultados.
Pero "el scoring con ML es una medición" solo se mantiene si el sistema de medición tiene un ciclo de retroalimentación. Sin recalibración, el modelo también es una hipótesis, solo que entrenada en datos en lugar de en intuición. Una hipótesis que deriva a medida que cambian las condiciones del mercado.
Los despliegues que entregan un ROI sostenido son aquellos donde RevOps es dueño del ciclo de retroalimentación. Rastrean la exactitud del modelo trimestralmente. Vuelven a entrenar cuando cae la exactitud. Auditan el rendimiento de los umbrales mensualmente. Tratan el modelo de scoring como infraestructura, no como un proyecto único.
Esa propiedad operacional es lo que separa un despliegue de AI lead scoring que sigue mejorando de uno que produce buenos resultados durante tres meses y luego se convierte en ruido de fondo. Una vez que el modelo de scoring está calibrado y alimentando los leads correctos a los representantes correctos, la siguiente pregunta es qué sucede con esos leads cuando llegan.
Preguntas Frecuentes
¿Qué es el AI lead scoring?
El AI lead scoring usa modelos de machine learning entrenados en datos históricos del CRM para asignar a cada lead inbound una puntuación de probabilidad entre 0 y 100. En lugar de pesos de puntos asignados por humanos (scoring basado en reglas), el modelo aprende qué combinaciones de señales se correlacionan realmente con resultados de cerrado-ganado en su base de clientes específica y aplica esos pesos aprendidos a cada nuevo lead. La puntuación se actualiza a medida que cierran nuevos deals, haciéndola auto-calibrante en lugar de estática.
¿En qué se diferencia el AI lead scoring del scoring basado en reglas?
El scoring basado en reglas codifica una hipótesis humana: "el título VP agrega 20 puntos, la visita a la página de precios agrega 25." El scoring con IA mide lo que realmente convirtió: el modelo encuentra las combinaciones de señales que se correlacionan con los deals ganados en sus datos históricos y las pondera en consecuencia. La diferencia práctica es que las reglas no se adaptan cuando cambia su ICP, no capturan los efectos de interacción entre señales y no mejoran con el tiempo. Los modelos de IA hacen las tres cosas cuando se recalibran correctamente.
¿Qué datos necesita un modelo de AI lead scoring para funcionar?
Los requisitos mínimos son al menos 6 meses de deals cerrados con etiquetado consistente de ganado/perdido (se prefieren 12 meses), al menos 200 deals cerrados-ganados en total, definiciones consistentes de etapas del CRM, fuente del primer contacto capturada en más del 70% de los registros y nombre/dominio de empresa completados en más del 80% de los registros. Los modelos entrenados con menos de 100 deals ganados producen output estadísticamente indistinguible de una asignación aleatoria.
¿Qué señales importan más para el lead scoring B2B?
Las señales de intención (visitas a la página de precios, páginas de comparación de competidores, vistas de categoría en G2) llevan el mayor lift de conversión porque indican comportamiento de compra en etapa tardía. La recencia del engagement le sigue, con decaimiento exponencial pasados los 30 días. El ajuste firmográfico (tamaño de empresa, industria, etapa de financiamiento) es la tercera categoría más predictiva para la mayoría de los productos B2B SaaS. El orden específico varía según el producto; el modelo aprende el orden real de su empresa a partir de sus datos.
¿Con qué frecuencia debería recalibrarse un modelo de AI lead scoring?
La recalibración trimestral es el estándar mínimo. El propietario de RevOps debe revisar la exactitud del modelo (precisión y recall por bucket de puntuación) cada trimestre y activar un re-entrenamiento cuando la exactitud caiga más de 5 puntos porcentuales desde la línea base. Los ICPs cambian, surgen nuevos canales y los cambios de precios alteran qué leads convierten. Un modelo entrenado hace 9-12 meses sin recalibración puede estar optimizando para patrones que ya no reflejan los compradores actuales.
¿Cuáles son los modos de fallo más comunes del AI lead scoring?
Los cuatro fallos más comunes son: (1) modelo entrenado con datos históricos sesgados (por ejemplo, el 70% de las victorias de un canal, haciendo que el modelo sea deficiente para puntuar otros canales); (2) puntuaciones que no se muestran en el flujo de trabajo diario del representante, por lo que las ignoran; (3) sin proceso de recalibración, lo que provoca que la exactitud derive a medida que cambia el mercado; y (4) calibración incorrecta de umbrales, donde demasiados leads puntúan "Alto" y abruman la capacidad de los representantes hasta que colapsa la confianza en el sistema.
¿Qué acciones de routing deberían activar diferentes rangos de puntuación?
Un modelo de routing estándar de cinco buckets se mapea a: 85-100% (directo al AE senior, notificación inmediata en Slack), 65-84% (cola de AE, SLA de contacto de 2 horas), 40-64% (calificación del SDR, inscribir en secuencia de toque medio), 20-39% (nurturing automatizado, sin asignación de representante) y 0-19% (solo newsletter). Los umbrales específicos deben calibrarse según la capacidad de representantes de su equipo y revisarse mensualmente para mantener el volumen de cola correcto para su headcount actual.
Más información
- ¿Qué es un AI Sales Operator?
- Routing Automatizado de Leads: Round Robin vs. IA
- Balanceo de Carga de Trabajo de SDR con IA
- Errores Comunes en el AI Lead Scoring
- Triaje de Leads Inbound a Escala
- Modos de Fallo: Cuando las AI Sales Ops Salen Mal
- Scoring y Routing: Triaje de IA a Escala
- Predict: Cómo la IA Pronostica Resultados de Negocio

Co-Founder, Rework.com
On this page
- Lo que el scoring basado en reglas pierde
- Cómo funciona el AI lead scoring con ML (sin necesidad de un doctorado)
- El Estándar de Puntuación de Lead Probabilística
- Tipos de señales clasificados por lift de conversión
- Lista de verificación de preparación de datos antes de desplegar
- Del output del modelo al umbral de routing
- Modos de fallo comunes
- Instantánea de proveedores
- El ciclo de retroalimentación es todo el juego
- Más información