Häufige Fehler beim AI Lead Scoring (und wie man sie behebt)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die meisten AI-Lead-Scoring-Deployments scheitern still. Es gibt keinen Systemabsturz, keine Fehlermeldung und keinen Moment, in dem jemand erklärt, es sei kaputt. Das Modell läuft, Scores erscheinen im Customer Relationship Management (CRM), Reps schauen ein paar Wochen drauf und hören dann auf, sie zu nutzen. Das Tool bleibt im Vertrag. Die Scores aktualisieren sich weiter. Sechs Monate später, wenn jemand fragt, ob Lead Scoring funktioniert, weiß es niemand wirklich.
Das stille Scheitern ist die schlimmste Art: teuer, unsichtbar und dem falschen Grund zugeschrieben. „Unsere Leads sind dieses Quartal einfach von geringerer Qualität." „Reps brauchen besseres Training in der Qualifizierung." „Vielleicht braucht das Modell mehr Daten." All das könnte stimmen. Aber oft ist das tieferliegende Problem struktureller Natur, kein Datenvolumen-Problem oder Rep-Leistungsproblem.
Dieser Artikel ist eine Diagnose für Ops-Führungskräfte, die AI Lead Scoring deployt haben und nicht die erwartete Verhaltensänderung sehen. Die folgenden Fehler sind die häufigsten Muster, und die meisten lassen sich durch operative Änderungen beheben, nicht durch Anbieterwechsel.
Fehler 1: Training mit voreingenommenen historischen Daten

Das Problem: Ihr Modell wurde mit vergangenen Closed-Won-Deals trainiert, und Ihre vergangenen Closed-Won-Deals überrepräsentieren ein Segment. Das Modell hat gelernt, dieses Segment hoch zu bewerten. Aber dieses Segment repräsentiert möglicherweise nicht Ihre tatsächlich besten Accounts heute.
Wie das in der Praxis aussieht: Ein SaaS-Unternehmen hat sein Lead-Scoring-Modell mit drei Jahren Closed Deals trainiert. Die meisten dieser Deals waren SMB, weil das vor drei Jahren ihr primärer Markt war. Inzwischen haben sie sich in Richtung Enterprise verlagert. Das Modell bewertet SMB-Leads weiterhin hoch und Enterprise-Leads niedrig, obwohl das Mandat des Salesteams Enterprise ist. Sales-Leadership denkt, das Scoring sei „verkehrt herum". Es ist nicht verkehrt herum; es hat die Vergangenheit akkurat gelernt. Die Vergangenheit passt nur nicht zur heutigen Strategie.
Die Lösung: Vor dem Retraining eine Closed-Won-Analyse durchführen. Historische Closed-Won-Deals nach Deal-Größe, Branche und Ideal Customer Profile (ICP)-Segment gruppieren. Wenn Ihr aktueller Zielmarkt im Trainings-Set nicht proportional repräsentiert ist, braucht Ihr Modell entweder Retraining auf einem gefilterten, repräsentativen Subset oder eine ICP-gewichtete Scoring-Ebene obendrauf. Deshalb betont AI Lead Scoring, dass die Modellarchitektur nur so gut ist wie die Trainingslabels. Die Labels kommen zuerst.
Wichtige Fakten: Fehlerquoten bei AI Lead Scoring
- Das NIST AI Risk Management Framework identifiziert kontinuierliches Monitoring und Messung als Kernanforderung für die Vertrauenswürdigkeit deployter KI-Systeme; ein Scoring-Modell ohne Retraining-Cadence verletzt diese Anforderung per Design
- Modelle, die mit weniger als 100 Closed-Won-Ergebnissen trainiert wurden, produzieren einen Output, der statistisch nicht von zufälliger Zuweisung zu unterscheiden ist; unter 200 ist die Modellzuverlässigkeit marginal
- Score-zu-Conversion-Korrelationsstudien zeigen konsistent, dass 25 bis 30% aller Inbound-Leads, die als „hot" eingestuft werden, der Schwellenwert ist, ab dem Schwellenwert-Fehlkalibrierung das Rep-Vertrauen zu erodieren beginnt; über 30% bricht die Adoption typischerweise innerhalb von 60 Tagen zusammen
Die 5 Lead-Scoring-Fehlerquellen
Die 5 Lead-Scoring-Fehlerquellen ist ein Diagnose-Framework für AI-Scoring-Deployments, die scheinbar laufen, aber kein Rep-Verhalten ändern. Die fünf Quellen sind: (1) Voreingenommene Trainingsdaten, bei denen historische Wins ein Marktsegment überrepräsentieren, von dem sich das Team inzwischen wegbewegt hat; (2) Score-Surfacing-Fehler, bei dem Scores in einem CRM-Feld existieren, das Reps nie sehen; (3) Kein Feedback-Loop, bei dem das Modell niemals retrainiert wird und die Genauigkeit über Zeit abnimmt; (4) Schwellenwert-Fehlkalibrierung, bei der zu viele Leads als „hot" eingestuft werden und die Bezeichnung bedeutungslos wird; und (5) Intent-Lücke, bei der Fit-basiertes Scoring ICP-passende Accounts identifiziert, aber aktive Kaufsignale verpasst. Jede Quelle hat eine eigene Lösung. Die meisten Ausfälle beinhalten mehrere Quellen gleichzeitig.
Fehler 2: Scores nicht dort angezeigt, wo Reps arbeiten
Das Problem: Ein Score, der drei Klicks tief in einem CRM-Feld vergraben ist, erzeugt null Verhaltensänderung. Reps ändern keine Workflows, um Informationen zu finden; Informationen müssen dort sein, wo sie bereits arbeiten.
Wie das in der Praxis aussieht: Revenue Operations (RevOps) richtet ein benutzerdefiniertes Feld namens „AI Lead Score" in Salesforce ein. Es steht auf der Lead-Datensatz-Detailseite, unterhalb des sichtbaren Bereichs, neben 40 anderen Feldern. Niemand ändert die Standard-Listenansicht. Keine Benachrichtigungen werden ausgelöst, wenn ein Score aktualisiert wird. Reps lernen, es zu ignorieren, weil es ihren bestehenden Workflow nicht unterbricht.
Die Lösung: Score-Surfacing ist ein Workflow-Design-Problem, nicht nur ein Datenproblem. Der Score muss in der Lead-Listenansicht erscheinen (sortierbar), als Benachrichtigungsauslöser (Alert, wenn ein Lead einen Schwellenwert überschreitet) und im täglichen Digest oder der Task-Queue des Reps. Wenn Sie eine Sales-Engagement-Plattform wie Outreach oder Salesloft verwenden, sollte der Score steuern, welche Leads in welche Sequences eintreten. Der Test: Wenn ein Rep seinen gesamten Arbeitstag verbringen könnte, ohne den Score zu sehen, ist er nicht surfaced. Das ist einer der am einfachsten zu behebenden und am häufigsten übersehenen Fehler.
Fehler 3: Kein Feedback-Loop
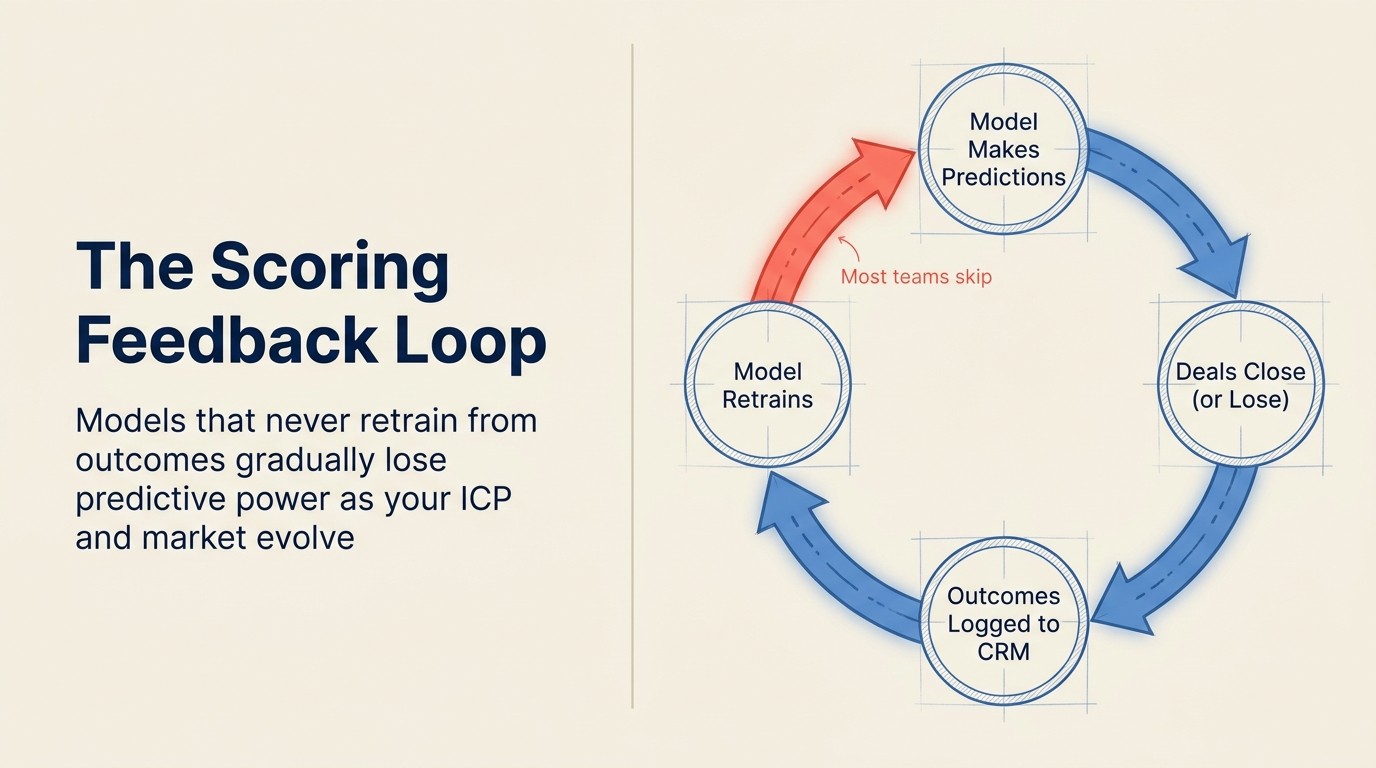
Das Problem: Das Modell scored auf statischen Trainingsdaten auf unbestimmte Zeit, ohne Mechanismus zum Retraining bei neuen Closed-Won- und Closed-Lost-Ergebnissen. Jedes Quartal driftet das Modell weiter von der aktuellen Realität ab, aber niemand bemerkt es, weil die Scores weiter aktualisiert werden und die Oberfläche gleich aussieht.
Das ist die strukturell wichtigste Fehlerquelle. Anders als die anderen, die graduell degradieren, verursacht kein Feedback-Loop eine kumulative Genauigkeitsabnahme. Ein im ersten Quartal des letzten Jahres trainiertes und nie aktualisiertes Modell hat inzwischen vier Quartale Deal-Ergebnisse verpasst, die seine Vorhersagen hätten schärfen können. Das NIST AI Risk Management Framework identifiziert kontinuierliches Monitoring und Messung ausdrücklich als Kernanforderung für die Vertrauenswürdigkeit jedes deployen KI-Systems, nicht als einmalige Einrichtungsaufgabe.
Wie das in der Praxis aussieht: Ein Unternehmen deployt HubSpot Predictive Lead Scoring im Februar. Es trainiert auf 18 Monaten historischer Deals. Im April launchen sie eine neue Produktlinie, die ihr Käuferprofil verändert. Im Juni stellen sie 5 neue Account Executives (AEs) ein, die ein anderes Deal-Profil abschließen. Im September bemerkt ein Manager, dass Scores nicht mit ihren besten Deals korrelieren. Das Modell war im Februar gut. Es degradiert seit April. Niemand hat ein Retraining ausgelöst, weil das System keine Drift-Alerts aussendet.
Die Lösung: Eine Retraining-Cadence vor dem Launch definieren, nicht nachdem das Problem bemerkt wurde. Quartalsweise ist das Minimum für die meisten Unternehmen; monatlich ist besser für schnell wachsende Teams mit sich verschiebenden ICPs. Die Auslöseereignisse für ein außerordentliches Retraining: neuer Produkt-Launch, signifikante ICP-Änderung, wichtige Kanalergänzung oder Änderung der Sales-Motion. Der Mechanismus: sicherstellen, dass Ihr CRM Closed-Won- und Closed-Lost-Ergebnisse konsistent mit den Feldern protokolliert, die Ihr Modell als Features verwendet. Ohne diese Protokollierungsdisziplin haben Sie keine neuen Trainingsdaten zum Einspeisen.
Das ist auch der Grund, warum menschenlesbare Score-Erklärungen (Fehler 6) für das Feedback wichtig sind. Wenn ein Rep sehen kann, dass ein Lead hoch gescored hat wegen „Unternehmensgröße + Tech-Stack + Branchenmatch", kann er signalisieren, wenn diese Logik nicht mehr das widerspiegelt, was konvertiert. Reps sind Ihr Frühwarnsystem für Modell-Drift, aber nur wenn sie die Scoring-Logik verstehen.
Fehler 4: Zu viele Input-Features, zu wenig Daten
Das Problem: Overfitting. Das Modell verwendet 40 Input-Features, um Leads aus einem Trainings-Set von 300 historischen Deals zu bewerten. Es memoriert Muster in den Trainingsdaten statt zu neuen Leads zu generalisieren. Es sieht in der Evaluation beeindruckend aus (hohe Genauigkeit bei Trainingsdaten) und scheitert bei Live-Leads.
Wie das in der Praxis aussieht: Ein RevOps-Analyst baut ein benutzerdefiniertes Lead-Scoring-Modell in Python mit 45 Features aus Salesforce (jedes Feld, das ihm eingefallen ist: Page Views, E-Mail-Öffnungen, Job-Titel-Level, Unternehmensalter, LinkedIn-Follower, Finanzierungsstatus usw.). Die Modell-Evaluation zeigt 89% Genauigkeit. Nach dem Deployment bemerken Reps, dass das Modell 90+-Scores an Leads gibt, die sich nie engagieren, und niedrige Scores an Leads, die klar qualifiziert sind. Das Modell hat das Trainings-Set memoriert. Es hat keinen prädiktiven Wert für neue Daten.
Die Lösung: Für Teams mit unter 1.000 historischen Ergebnissen ein einfacheres Modell mit weniger Features verwenden. 5 bis 10 hochwertige Features, konsistent befüllt, übertreffen 45 spärliche oder inkonsistente Features. Die klassischen hochwertigen Features: Unternehmensgröße, Branchenmatch, Job-Titel-Seniorität, Formular-Quelle (welche Seite/Kanal) und Produkt-Nutzungssignale für Expansion-Leads. Spärlich beginnen. Features hinzufügen, wenn das Datenvolumen wächst.
Für Teams mit begrenzten historischen Daten ist es oft zuverlässiger, mit dem vortrainierten Modell eines Anbieters (Salesforce Einstein, HubSpot Predictive Lead Scoring) zu beginnen und Ihre ICP-Kriterien obendraufzulegen, als von Grund auf neu zu bauen.
Fehler 5: Score-Schwellenwert-Mismatch
Das Problem: Das Modell gibt Wahrscheinlichkeiten aus, aber die Routing-Schwellenwerte sind falsch gesetzt. Ein zu niedriger Schwellenwert überschwemmt Reps mit „heißen" Leads, die eigentlich nicht heiß sind. Ein zu hoher Schwellenwert bedeutet, dass qualifizierte Leads nie zur menschlichen Aufmerksamkeit eskalieren.
Wie das in der Praxis aussieht: Ein Team setzt seinen „hot lead"-Schwellenwert bei 40 von 100. Ihr Scoring-Modell wurde so kalibriert, dass 40 eine 40%ige Conversion-Wahrscheinlichkeit darstellt. Mit einem Schwellenwert bei 40 werden 60% ihres Inbounds als heiß markiert und an Senior Sales Development Representatives (SDRs) geroutet. Diese SDRs sind überwältigt. Ihre Connect-Rate bei „heißen" Leads sieht schlecht aus, weil es zu viele Leads zu bearbeiten gibt. Das Problem ist nicht das Scoring-Modell; es ist der Schwellenwert.
Die Lösung: Die Schwellenwert-Einstellung sollte gegen historische Conversion-Raten nach Score-Band kalibriert werden, nicht willkürlich gesetzt. Die letzten 6 bis 12 Monate geskorter Leads und Conversion-Ergebnisse herausziehen (falls vorhanden). Das Score-Band finden, bei dem die Conversion-Rate signifikant steigt. Das ist Ihr Routing-Schwellenwert. Wenn Sie Scoring zum ersten Mal ohne historisch geskorte Leads einrichten, mit einem hohen Schwellenwert (70+) beginnen, der das Hot-Lead-Volumen handhabbar hält, und im Laufe der Zeit nach unten anpassen, wenn Score-zu-Ergebnis-Daten anfallen.
Die Schwellenwert-Frage erstreckt sich auch auf Routing-Tiers. Mindestens drei Routing-Tiers definieren: hochprioritär (menschliche Eskalation, schnelles SLA), standard (normale SDR-Queue) und nurture (automatisierte Sequence, kein Rep-Kontakt bis Intent-Signal auslöst). Die Schwellenwerte zwischen diesen Tiers müssen justiert werden, nicht angenommen. Und 25 bis 30% der Leads, die als „heiß" eingestuft werden, ist die diagnostische Obergrenze: Wenn Sie darüber liegen, den Schwellenwert senken, bevor Reps dem System vollständig misstrauen.
Fehler 6: Rep-Misstrauen durch unerklärliche Scores
Das Problem: Black-Box-Scoring verliert Rep-Adoption. Ein Rep, der nicht versteht, warum ein Lead 87 gescored hat, handelt nicht konsistent danach. Und wenn das Modell einen Fehler macht, den der Rep erkennen kann (ein klar minderwertiger Lead mit einem Score von 90), verliert das gesamte Scoring-System in diesem Rep's Augen Glaubwürdigkeit.
Wie das in der Praxis aussieht: Ein Unternehmen deployt ein Scoring-Modell mit 15 gewichteten Signalen. Die Oberfläche zeigt Reps eine einzige Zahl: „Lead Score: 82." Ein Rep schaut sich den Lead an, sieht ein 3-Personen-Startup eines Unternehmenstyps, der für sie selten konvertiert, und ignoriert die 82. Nächste Woche ignorieren sie eine 91. Innerhalb von zwei Monaten haben Reps Scoring mental als unzuverlässig abgeschrieben. Das Modell war vielleicht im Durchschnitt genau, aber einzelne Fehler ohne Erklärung haben die Adoption zerstört.
Die Lösung: Score-Erklärungen sollten am Verwendungsort erscheinen. Nicht nur „Score: 82", sondern „Score: 82, weil Unternehmensgröße (Mid-Market), Branche (Finanzdienstleistungen) und jüngste Finanzierungsrunde alle zu Ihrem ICP passen. Intent-Signale: moderat. Fehlend: bestätigter Entscheidungsträger-Kontakt." Mit diesem Kontext, selbst wenn ein Rep einem Score widerspricht, versteht er die Begründung. Er kann den richtigen Input in Frage stellen (vielleicht ist die „Mid-Market"-Klassifizierung falsch, weil dieses Unternehmen kürzlich geschrumpft ist) statt den gesamten Score abzulehnen.
Einige Tools bieten das nativ an (Salesforce Einstein's Score-Faktoren, HubSpot's Score-Aufschlüsselung). Benutzerdefinierte Modelle müssen es explizit eingebaut haben.
Fehler 7: Timing-Signale ignorieren (Fit ohne Intent)
Das Problem: Fit-basiertes Scoring sagt Ihnen, dass ein Unternehmen Ihrem ICP entspricht. Es sagt Ihnen nicht, dass es aktiv kauft. Ein perfekt passendes Unternehmen, das nicht auf dem Markt ist, scored hoch, konvertiert aber schlecht. Ein durchschnittlich passendes Unternehmen in aktiver Evaluierung scored mittelmäßig, konvertiert aber besser. Intent plus Fit zusammen übertrifft beides allein.
Wie das in der Praxis aussieht: Das Modell eines Teams bewertet Accounts vollständig auf firmografischem Fit: Unternehmensgröße, Branche, Tech-Stack, Umsatzbereich. Ihre „Tier-1"-Leads sind konsistent gut passende Accounts. Aber Reps beklagen, dass sie diese Leads nicht zum Engagement bringen können. Es sind kalte ICP-Matches, keine warmen Käufer. Währenddessen zeigen Intent-Daten (Bombora, 6sense) mehrere Mid-Tier-Accounts, die die Kategorie des Unternehmens aktiv recherchieren. Diese Accounts tauchen nie auf, weil sie beim firmografischen Fit nicht hoch gescored haben.
Die Lösung: Timing-Signale als Scoring-Ebene hinzufügen. Drittanbieter-Intent (Bombora, 6sense, Demandbase) sagt Ihnen, wer gerade aktiv recherchiert. First-Party-Signale (Pricing-Page-Besuche, Dokumentationslesungen, Feature-Vergleichsansichten) sagen Ihnen, welche Formular-Einreichenden sich im aktiven Evaluierungsmodus befinden. Ein Lead, der 60 beim Fit scored, aber hohe Intent-Signale hat, sollte anders geroutet werden als ein Lead, der 90 beim Fit scored, aber keine Intent zeigt. Das kombinierte Modell findet Käufer, die Sie mit einem einzelnen Signal verpassen würden. Der Artikel Buyer Intent Signal Synthesis mit AI zeigt, wie man diese Signale in der Praxis schichtet.
Rework-Analyse: Das stille Scheitern-Muster ist das teuerste, das wir bei AI-Lead-Scoring-Deployments sehen. Das Modell läuft technisch, der Anbieter wird technisch noch bezahlt, aber Reps haben den Scores vor drei Monaten aufgehört zu vertrauen und niemand hat es offiziell anerkannt. Das Zeichen ist eine Umfragefrage: „Schauen Sie sich den AI-Lead-Score an, bevor Sie entscheiden, welche Leads Sie zuerst bearbeiten?" Wenn weniger als 40% der Reps ja sagen, ist das Scoring-System dekorativ. Die Lösung erfordert fast nie einen neuen Anbieter. Sie erfordert die Lösung derjenigen der fünf Fehlerquellen, die das Vertrauen hat erodieren lassen, normalerweise Schwellenwert-Fehlkalibrierung oder Score-Surfacing-Fehler, die zwei operativ am leichtesten behebbaren Probleme auf der Liste.
Audit-Checkliste: Diagnosefragen für Ihr Scoring-Deployment
Verwenden Sie diese, um zu diagnostizieren, welche Fehler Ihr aktuelles System betreffen:
Trainingsdaten
- Wann wurde das Modell zuletzt retrainiert? Gibt es eine geplante Cadence?
- Welcher Prozentsatz Ihrer aktuellen Closed-Won-Deals stammt aus Segmenten, die in den Trainingsdaten prominent waren?
- Sind Closed-Lost-Deals im Trainings-Set enthalten, oder nur Closed-Won?
Surfacing und Adoption
- Kann ein Rep den Score sehen, ohne seine Standard-Listenansicht zu verlassen?
- Gibt es eine Benachrichtigung oder einen Alert, wenn ein Lead einen Schwellenwert überschreitet?
- Drei Reps fragen: „Was bedeutet ein hoher Lead Score für Ihren täglichen Workflow?" Wenn die Antworten vage sind, ändern die Scores kein Verhalten.
Feedback-Loop
- Gibt es einen formalen Retraining-Auslöser? Wer ist dafür verantwortlich?
- Sind Closed-Won- und Closed-Lost-Felder in Ihrem CRM mit konsistenten Definitionen Pflichtfelder?
- Wie würden Sie wissen, wenn die Modellgenauigkeit sinkt?
Schwellenwert-Kalibrierung
- Welcher Prozentsatz Ihres Inbound-Volumens wird als „heiß" eingestuft? Wenn er über 25 bis 30% liegt, ist der Schwellenwert wahrscheinlich zu niedrig.
- Haben Sie Score-zu-Conversion-Ergebnisdaten zur Validierung Ihrer aktuellen Schwellenwerte?
Erklärbarkeit
- Kann ein Rep sehen, was einen Score angetrieben hat?
- Wenn ein Rep einem Score widerspricht, weiß er, welchen Input er in Frage stellen soll?
Intent-Integration
- Sind Timing/Intent-Daten im Scoring enthalten, oder nur firmografischer Fit?
- Haben Sie First-Party-Verhaltenssignale im Scoring-Modell (Page Views, E-Mail-Engagement, Demo-Anfrage)?
Wenn Sie bei mehr als drei dieser Fragen „nein" geantwortet haben, hat Ihr Scoring-System mindestens ein strukturelles Problem. Der Artikel AI Lead Scoring jenseits regelbasierter Modelle behandelt, wie ein gut funktionierendes Modell aufgebaut wird. Dieser Artikel behandelt, warum diese Modelle in der Praxis scheitern.
Failure Modes: Wenn AI Sales Ops nach hinten losgeht erweitert diese Analyse über Scoring hinaus auf den breiteren RevOps-Stack.
Das ehrliche Fazit
AI-Lead-Scoring-Fehler sind alle behebbar. Aber die meisten Korrekturen sind operativer, nicht technischer Natur. Sie brauchen für die meisten davon keinen anderen Anbieter. Sie brauchen eine Retraining-Cadence, einen Score-Surfacing-Workflow, einen Schwellenwert-Kalibrierungsprozess und eine Erklärbarkeits-Ebene.
Die gefährlichste Fehlerquelle ist auch die häufigste: ein Modell, das unbegrenzt ohne Feedback-Loop läuft und sich langsam von der Realität entfernt, während alle annehmen, es funktioniere noch, weil die Oberfläche unverändert aussieht. Scoring ohne Retraining ist wie Navigation mit einer Karte vom letzten Jahr. Das Gelände könnte sich verändert haben; die Karte weiß es noch nicht.
Mehr erfahren
- AI Lead Scoring jenseits regelbasierter Modelle
- Automatisiertes Lead Routing: Round Robin vs. AI-gesteuerte Zuweisung
- Inbound Lead Triage im großen Maßstab
- Buyer Intent Signal Synthesis mit AI
- Failure Modes: Wenn AI Sales Ops nach hinten losgeht
- Scoring and Routing: AI Triage at Scale
- Wenn AI Patterns zu Tech Debt werden

Co-Founder, Rework.com
On this page
- Fehler 1: Training mit voreingenommenen historischen Daten
- Die 5 Lead-Scoring-Fehlerquellen
- Fehler 2: Scores nicht dort angezeigt, wo Reps arbeiten
- Fehler 3: Kein Feedback-Loop
- Fehler 4: Zu viele Input-Features, zu wenig Daten
- Fehler 5: Score-Schwellenwert-Mismatch
- Fehler 6: Rep-Misstrauen durch unerklärliche Scores
- Fehler 7: Timing-Signale ignorieren (Fit ohne Intent)
- Audit-Checkliste: Diagnosefragen für Ihr Scoring-Deployment
- Das ehrliche Fazit
- Mehr erfahren