Errores Comunes en el Lead Scoring con IA (y Cómo Corregirlos)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La mayoría de los despliegues de lead scoring con IA fallan en silencio. No hay un fallo del sistema, no hay mensaje de error, y no hay un momento en que alguien declare que está roto. El modelo corre, los scores aparecen en el CRM, los reps los consultan durante unas semanas y luego dejan de usarlos. La herramienta sigue en el contrato. Los scores siguen actualizándose. Seis meses después, cuando alguien pregunta si el lead scoring está funcionando, nadie lo sabe realmente.
El fallo silencioso es el peor tipo: es costoso, es invisible, y se atribuye a la causa equivocada. "Nuestros leads tienen menor calidad este trimestre." "Los reps necesitan mejor capacitación en calificación." "Quizás el modelo necesita más datos." Todo eso podría ser cierto. Pero con frecuencia el problema más profundo es estructural, no un problema de volumen de datos ni de rendimiento de los reps.
Este artículo es un diagnóstico para líderes de operaciones que han desplegado lead scoring con IA y no están viendo el cambio de comportamiento esperado. Los fallos que se describen a continuación son los patrones más comunes, y la mayoría se pueden corregir con cambios operativos en lugar de cambios de proveedor.
Error 1: Entrenamiento con datos históricos sesgados

El problema: El modelo se entrenó con deals cerrados en el pasado, y esos deals sobre-representan un segmento. El modelo aprendió a puntuar alto ese segmento. Pero ese segmento puede no representar sus mejores cuentas objetivo hoy.
Cómo se manifiesta en la práctica: Una empresa SaaS entrenó su modelo de lead scoring con tres años de deals cerrados. La mayoría eran SMB, porque ese era su mercado principal hace tres años. Desde entonces han hecho un movimiento hacia el mercado enterprise. El modelo sigue puntuando alto los leads SMB y bajo los leads enterprise, aunque el mandato del equipo de ventas sea enterprise. La dirección de ventas cree que el scoring está "al revés". No está al revés; aprendió el pasado con precisión. El pasado simplemente ya no corresponde a la estrategia de hoy.
La solución: Antes de reentrenar, realice una auditoría de closed-won. Agrupe sus deals históricos por tamaño de deal, industria y segmento ICP. Si su mercado objetivo actual no está representado proporcionalmente en el conjunto de entrenamiento, el modelo necesita reentrenamiento con un subconjunto filtrado y representativo, o una capa de scoring ponderada por ICP encima. Por eso el lead scoring con IA enfatiza que la arquitectura del modelo solo es tan buena como las etiquetas de entrenamiento. Las etiquetas van primero.
Key Facts: Tasas de Fallo en Lead Scoring con IA
- El Marco de Gestión de Riesgos de IA del NIST identifica el monitoreo y la medición continuos como un requisito central de confiabilidad para los sistemas de IA desplegados; un modelo de scoring sin una cadencia de reentrenamiento viola este requisito por diseño
- Los modelos entrenados con menos de 100 resultados closed-won producen resultados estadísticamente indistinguibles de una asignación aleatoria; por debajo de 200, la fiabilidad del modelo es marginal
- Los estudios de correlación entre score y conversión muestran consistentemente que el 25-30% de los leads inbound con puntuación "alta" es el umbral donde la mala calibración empieza a degradar la confianza de los reps; por encima del 30%, la adopción típicamente colapsa en 60 días
Los 5 Modos de Fallo en Lead Scoring
The 5 Lead Scoring Failure Modes es un marco de diagnóstico para despliegues de scoring con IA que aparentemente funcionan pero no están cambiando el comportamiento de los reps. Los cinco modos son: (1) Biased Training Data, donde las victorias históricas sobre-representan un segmento de mercado del que el equipo ya se alejó; (2) Score Surfacing Failure, donde los scores existen en un campo del CRM que los reps nunca ven; (3) No Feedback Loop, donde el modelo nunca se reentrena y la precisión decae con el tiempo; (4) Threshold Miscalibration, donde demasiados leads puntúan como "alta prioridad" y la designación pierde significado; y (5) Intent Gap, donde el scoring basado en fit identifica cuentas que coinciden con el ICP pero no detecta señales activas de compra. Cada modo tiene una solución específica. La mayoría de los fallos involucran más de un modo simultáneamente.
Error 2: Los scores no visibles donde trabajan los reps
El problema: Un score enterrado en un campo del CRM a tres clics de profundidad no produce ningún cambio de comportamiento. Los reps no modifican sus flujos de trabajo para buscar información; la información necesita encontrarlos donde ya están.
Cómo se manifiesta en la práctica: RevOps configura un campo personalizado llamado "AI Lead Score" en Salesforce. Está en la página de detalle del lead, debajo del pliegue, junto a otros 40 campos. Nadie cambia la vista de lista predeterminada. No se disparan notificaciones cuando un score se actualiza. Los reps aprenden a ignorarlo porque no interrumpe su flujo de trabajo existente.
La solución: La visibilidad del score es un problema de diseño de flujo de trabajo, no solo un problema de datos. El score necesita aparecer en la vista de lista de leads (ordenable), como disparador de notificación (alerta cuando un lead supera un umbral), y en el resumen diario o la cola de tareas del rep. Si usa una plataforma de sales engagement como Outreach o Salesloft, el score debería controlar qué leads entran en qué secuencias. La prueba: si un rep puede hacer toda su jornada de trabajo sin ver el score, no está visible. Este es uno de los errores más fáciles de corregir y uno de los que más frecuentemente se pasan por alto.
Error 3: Sin feedback loop
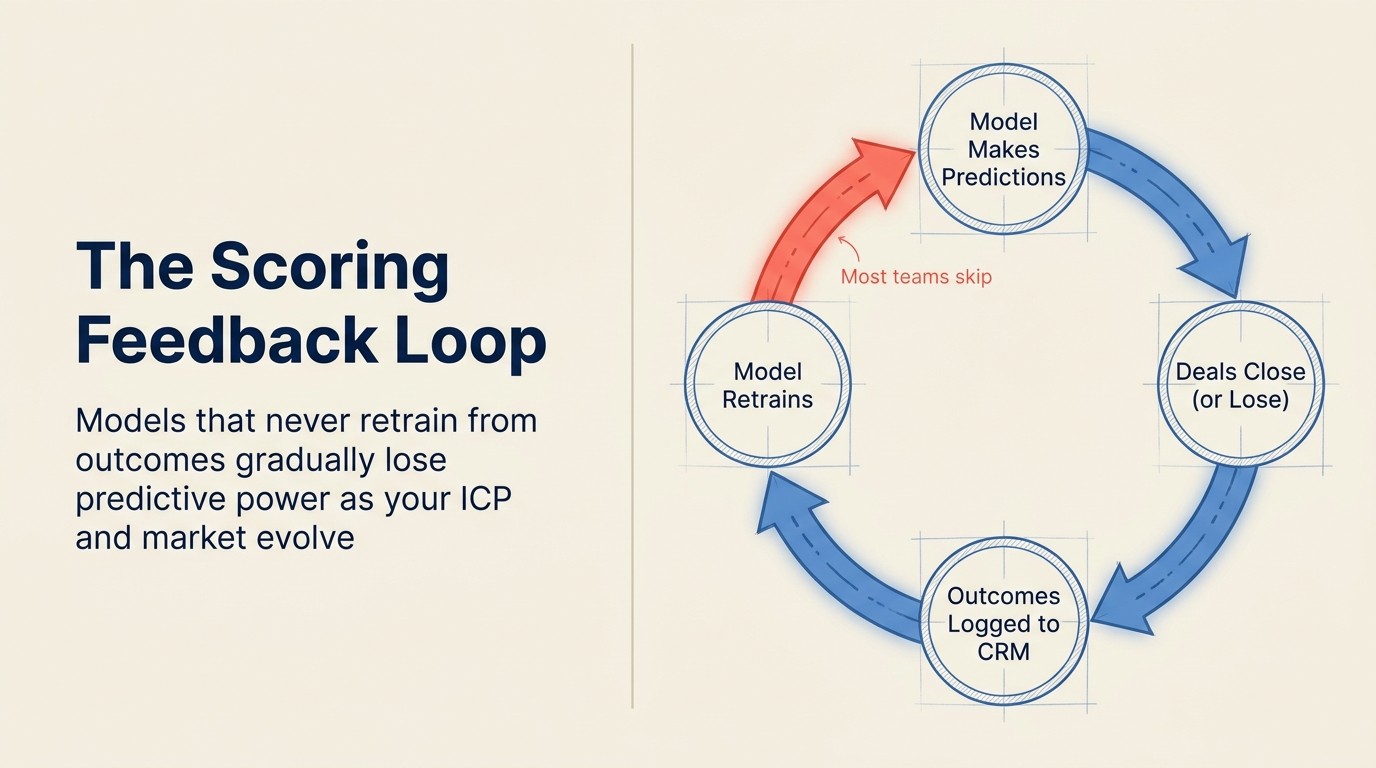
El problema: El modelo puntúa sobre datos de entrenamiento estáticos indefinidamente, sin ningún mecanismo para reentrenarse con nuevos resultados closed-won y closed-lost. Cada trimestre el modelo se aleja más de la realidad actual, pero nadie lo nota porque los scores siguen actualizándose y la interfaz sigue igual.
Este es el modo de fallo estructuralmente más importante. A diferencia de los otros, que se degradan gradualmente, la ausencia de feedback loop provoca un deterioro acumulativo de la precisión. Un modelo entrenado en el primer trimestre del año pasado y nunca actualizado ha dejado de considerar cuatro trimestres de resultados de deals que podrían haber afinado sus predicciones. El Marco de Gestión de Riesgos de IA del NIST identifica específicamente el monitoreo y la medición continuos como un requisito central de confiabilidad para cualquier sistema de IA desplegado, no como una configuración inicial de una sola vez.
Cómo se manifiesta en la práctica: Una empresa despliega HubSpot Predictive Lead Scoring en febrero. Se entrena con 18 meses de deals históricos. En abril lanza una nueva línea de productos que cambia el perfil del comprador. En junio contrata 5 nuevos AEs que empiezan a cerrar un perfil de deal diferente. En septiembre, un manager nota que los scores no se correlacionan con sus mejores deals. El modelo estaba bien en febrero. Ha estado deteriorándose desde abril. Nadie activó un reentrenamiento porque el sistema no alerta sobre la deriva.
La solución: Defina una cadencia de reentrenamiento antes de lanzar, no después de notar el problema. Trimestral es el mínimo para la mayoría de las empresas; mensual es mejor para equipos en rápido crecimiento con ICP cambiantes. Los eventos desencadenantes para un reentrenamiento fuera de ciclo: lanzamiento de nuevo producto, cambio significativo de ICP, adición de canal importante o cambio en el motion de ventas. La mecánica: asegúrese de que su CRM registre los resultados closed-won y closed-lost de forma consistente con los campos que el modelo usa como features. Sin esa disciplina de registro, no hay nuevos datos de entrenamiento para retroalimentar el modelo.
Esta es también la razón por la que las explicaciones de score legibles para humanos (Error 6) son importantes para el feedback. Si un rep puede ver que un lead puntuó alto por "tamaño de empresa + tech stack + coincidencia de industria", puede señalar cuando esa lógica ya no refleja lo que está convirtiendo. Los reps son su sistema de alerta temprana para la deriva del modelo, pero solo si entienden la lógica de scoring.
Error 4: Demasiadas features de entrada, muy pocos datos
El problema: Overfitting. El modelo usa 40 features de entrada para puntuar leads de un conjunto de entrenamiento de 300 deals históricos. Memoriza patrones en los datos de entrenamiento en lugar de generalizar a nuevos leads. Parece impresionante en la evaluación (alta precisión en datos de entrenamiento) y falla en leads en vivo.
Cómo se manifiesta en la práctica: Un analista de RevOps construye un modelo personalizado de lead scoring en Python usando 45 features de Salesforce (cada campo que se le ocurrió: páginas vistas, aperturas de email, nivel del cargo, antigüedad de la empresa, seguidores en LinkedIn, estado de financiamiento, etc.). La evaluación del modelo muestra 89% de precisión. Al desplegarse, los reps notan que el modelo da puntuaciones de 90+ a leads que nunca se comprometen y puntuaciones bajas a leads claramente calificados. El modelo memorizó el conjunto de entrenamiento. No tiene valor predictivo en datos nuevos.
La solución: Para equipos con menos de 1,000 resultados históricos, use un modelo más simple con menos features. 5-10 features de alta señal, consistentemente pobladas, superan a 45 features dispersas o inconsistentes. Las features de alto valor clásicas: tamaño de empresa, coincidencia de industria, nivel de cargo, fuente del formulario (qué página/canal) y señales de uso del producto para leads de expansión. Empiece simple. Añada features a medida que crezca el volumen de datos.
Para equipos con datos históricos limitados, comenzar con el modelo pre-entrenado de un proveedor (Salesforce Einstein, HubSpot Predictive Lead Scoring) y agregar sus criterios ICP encima es frecuentemente más fiable que construir desde cero.
Error 5: Mala calibración del umbral de score
El problema: El modelo produce probabilidades, pero los umbrales de routing están configurados incorrectamente. Un umbral demasiado bajo inunda a los reps con leads "calientes" que en realidad no lo son. Un umbral demasiado alto significa que los leads calificados nunca escalan a atención humana.
Cómo se manifiesta en la práctica: Un equipo configura su umbral de "lead caliente" en 40 sobre 100. Su modelo de scoring fue calibrado para que 40 represente una probabilidad de conversión del 40%. Con un umbral de 40, el 60% de su volumen inbound se marca como caliente y se enruta a SDRs senior. Esos SDRs están desbordados. Su tasa de conexión en leads "calientes" es terrible porque hay demasiados leads para trabajar correctamente. El problema no es el modelo de scoring; es el umbral.
La solución: La configuración del umbral debe calibrarse contra las tasas de conversión históricas por banda de score, no establecerse arbitrariamente. Extraiga sus últimos 6-12 meses de leads con score y resultados de conversión (si los tiene). Encuentre la banda de score donde la tasa de conversión sube de forma significativa. Ese es su umbral de routing. Si está configurando scoring por primera vez sin leads con score histórico, empiece con un umbral alto (70+) que mantenga el volumen de leads calientes manejable, y ajústelo hacia abajo con el tiempo a medida que acumule datos de score-a-resultado.
La pregunta del umbral también se extiende a los niveles de routing. Defina al menos tres niveles: alta prioridad (escalación humana, SLA rápido), estándar (cola normal de SDR), y nurture (secuencia automatizada, sin contacto de rep hasta que una señal de intent lo dispare). Los umbrales entre esos niveles deben ajustarse, no asumirse. Y el 25-30% de leads con puntuación "caliente" es el techo diagnóstico: si está por encima, baje el umbral antes de que los reps dejen de confiar en el sistema por completo.
Error 6: Desconfianza de los reps por scores inexplicables
El problema: El scoring de caja negra pierde la adopción de los reps. Un rep que no entiende por qué un lead puntuó 87 no actuará sobre ello de forma consistente. Y cuando el modelo comete un error que el rep puede detectar (un lead claramente de baja calidad con una puntuación de 90), todo el sistema de scoring pierde credibilidad en la mente de ese rep.
Cómo se manifiesta en la práctica: Una empresa despliega un modelo de scoring que usa 15 señales ponderadas. La interfaz muestra a los reps un solo número: "Lead Score: 82." Un rep mira el lead, ve una startup de 3 personas en un tipo de empresa que raramente convierte para ellos, e ignora el 82. La semana siguiente ignoran un 91. En dos meses, los reps han descartado mentalmente el scoring como poco fiable. El modelo podría haber sido preciso en promedio, pero los errores individuales sin explicación destruyeron la adopción.
La solución: Las explicaciones del score deben aparecer en el punto de uso. No solo "Score: 82" sino "Score: 82 porque el tamaño de empresa (mid-market), la industria (servicios financieros) y la ronda de financiamiento reciente coinciden con su ICP. Señales de intent: moderadas. Falta: contacto confirmado con el decisor." Con ese contexto, incluso cuando un rep no está de acuerdo con un score, entiende el razonamiento. Puede cuestionar el input correcto (quizás la clasificación "mid-market" es incorrecta porque esta empresa se redujo recientemente) en lugar de descartar todo el score.
Algunas herramientas ofrecen esto de forma nativa (los factores de score de Salesforce Einstein, el desglose de score de HubSpot). Los modelos personalizados necesitan que se construya deliberadamente.
Error 7: Ignorar las señales de timing (fit sin intent)
El problema: El scoring basado en fit le dice que una empresa coincide con su ICP. No le dice que están comprando activamente. Una empresa con fit perfecto que no está en el mercado puntúa alto pero convierte poco. Una empresa con fit promedio en evaluación activa puntúa medio pero convierte mejor. Intent más fit juntos supera a cualquiera de los dos por separado.
Cómo se manifiesta en la práctica: El modelo de un equipo puntúa cuentas enteramente en base al fit firmográfico: tamaño de empresa, industria, tech stack, rango de ingresos. Sus leads "Tier 1" son cuentas consistentemente bien emparejadas. Pero los reps se quejan de que no pueden lograr que estos leads se comprometan. Son coincidencias ICP frías, no compradores activos. Mientras tanto, los datos de intent (Bombora, 6sense) muestran varias cuentas de nivel medio investigando activamente la categoría de la empresa. Esas cuentas nunca aparecen porque no puntuaron alto en fit firmográfico.
La solución: Añada señales de timing como una capa de scoring. El intent de terceros (Bombora, 6sense, Demandbase) le dice quién está investigando activamente ahora mismo. Las señales de primera parte (visitas a la página de precios, lecturas de documentación, vistas de comparación de funcionalidades) le dicen qué personas que rellenaron formularios están en modo de evaluación activa. Un lead que puntúa 60 en fit pero tiene señales de intent altas debería enrutarse de forma diferente a un lead que puntúa 90 en fit pero no muestra intent. El modelo combinado captura compradores que perdería con cualquiera de las dos señales por separado. El artículo sobre síntesis de señales de buyer intent con IA muestra cómo combinar estas señales en la práctica.
Rework Analysis: El patrón de fallo silencioso es el más costoso que vemos en los despliegues de lead scoring con IA. El modelo está técnicamente corriendo, el proveedor técnicamente sigue siendo pagado, pero los reps dejaron de confiar en los scores hace tres meses y nadie lo reconoció oficialmente. La señal de alerta es una pregunta de encuesta: "¿Consulta el AI lead score antes de decidir en qué leads trabajar primero?" Cuando menos del 40% de los reps responde que sí, el sistema de scoring es decorativo. La solución casi nunca requiere un nuevo proveedor. Requiere resolver cuál de los cinco modos de fallo causó que la confianza se erosionara, generalmente la mala calibración del umbral o el fallo en la visibilidad del score, los dos problemas más fáciles de corregir operativamente de la lista.
Lista de verificación de auditoría: preguntas de diagnóstico para su despliegue de scoring
Use estas preguntas para diagnosticar qué errores afectan a su sistema actual:
Datos de entrenamiento
- ¿Cuándo fue reentrenado el modelo por última vez? ¿Existe una cadencia programada?
- ¿Qué porcentaje de sus deals closed-won actuales proviene de segmentos que eran prominentes en los datos de entrenamiento?
- ¿Se incluyen los deals closed-lost en el conjunto de entrenamiento, o solo los closed-won?
Visibilidad y adopción
- ¿Puede un rep ver el score sin salir de su vista de lista predeterminada?
- ¿Existe una notificación o alerta cuando un lead supera un umbral?
- Pregunte a tres reps: "¿Qué significa un lead score alto para su flujo de trabajo diario?" Si las respuestas son vagas, los scores no están cambiando el comportamiento.
Feedback loop
- ¿Existe un disparador formal de reentrenamiento? ¿Quién lo gestiona?
- ¿Son obligatorios los campos closed-won y closed-lost en su CRM, con definiciones consistentes?
- ¿Cómo sabría si la precisión del modelo estuviera disminuyendo?
Calibración del umbral
- ¿Qué porcentaje de su volumen inbound puntúa como "caliente"? Si está por encima del 25-30%, el umbral probablemente es demasiado bajo.
- ¿Tiene datos de resultado de score-a-conversión para validar sus umbrales actuales?
Explicabilidad
- ¿Puede un rep ver qué impulsó un score?
- Cuando un rep no está de acuerdo con un score, ¿sabe qué input cuestionar?
Integración de intent
- ¿Se incluyen datos de timing/intent en el scoring, o solo el fit firmográfico?
- ¿Tiene señales conductuales de primera parte en el modelo de scoring (páginas vistas, compromiso por email, solicitud de demo)?
Si respondió "no" a más de tres de estas preguntas, su sistema de scoring tiene al menos un problema estructural. El artículo sobre AI lead scoring explica cómo se construye un modelo bien funcionando. Este artículo explica por qué esos modelos fallan en el campo.
Los modos de fallo: cuando las Sales Ops con IA salen mal extiende este análisis más allá del scoring al stack de RevOps completo.
El resumen honesto
Los errores en el lead scoring con IA son todos corregibles. Pero la mayoría de las correcciones son operativas, no técnicas. No necesita un proveedor diferente para la mayoría de estos problemas. Necesita una cadencia de reentrenamiento, un flujo de trabajo de visibilidad del score, un proceso de calibración del umbral y una capa de explicabilidad.
El modo de fallo más peligroso es también el más común: un modelo que funciona indefinidamente sin un feedback loop, alejándose lentamente de la realidad mientras todos asumen que sigue funcionando porque la interfaz no ha cambiado. El scoring sin reentrenamiento es como navegar con un mapa del año pasado. El terreno puede haber cambiado; el mapa no lo sabe todavía.
Más información

Co-Founder, Rework.com
On this page
- Error 1: Entrenamiento con datos históricos sesgados
- Los 5 Modos de Fallo en Lead Scoring
- Error 2: Los scores no visibles donde trabajan los reps
- Error 3: Sin feedback loop
- Error 4: Demasiadas features de entrada, muy pocos datos
- Error 5: Mala calibración del umbral de score
- Error 6: Desconfianza de los reps por scores inexplicables
- Error 7: Ignorar las señales de timing (fit sin intent)
- Lista de verificación de auditoría: preguntas de diagnóstico para su despliegue de scoring
- El resumen honesto
- Más información