Những Lỗi Phổ Biến Khi Triển Khai AI Lead Scoring (Và Cách Khắc Phục)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hầu hết AI lead scoring triển khai xong rồi chết lặng lẽ. Không có sự cố, không có thông báo lỗi, không ai chính thức tuyên bố nó hỏng. Model chạy, điểm số xuất hiện trong CRM, reps liếc qua vài tuần rồi thôi. Công cụ vẫn còn trong hợp đồng. Điểm số vẫn cập nhật mỗi ngày. Sáu tháng sau, khi ai đó hỏi lead scoring có đang hoạt động không, không ai thực sự biết.
Thất bại lặng lẽ là loại tệ nhất: tốn kém, vô hình, và bị đổ thừa cho nguyên nhân sai. "Lead quý này chất lượng thấp hơn." "Rep cần đào tạo thêm về qualification." "Có lẽ model cần thêm dữ liệu." Những lý do đó có thể đúng. Nhưng thường vấn đề gốc rễ nằm ở cấu trúc, không phải thiếu dữ liệu hay vấn đề của rep.
Bài này là công cụ chẩn đoán dành cho ops leaders đã triển khai AI lead scoring nhưng chưa thấy thay đổi hành vi như kỳ vọng. Những failure mode dưới đây là các mẫu phổ biến nhất. Và hầu hết đều có thể khắc phục bằng thay đổi vận hành, không cần đổi vendor.
Lỗi 1: Huấn luyện trên dữ liệu lịch sử có thiên lệch
Vấn đề: Model huấn luyện trên các deal đã thắng trong quá khứ, và những deal đó đại diện quá nhiều cho một phân khúc. Model học chấm điểm cao phân khúc đó. Nhưng phân khúc đó có thể không còn là tài khoản phù hợp nhất với chiến lược hiện tại.
Thực tế trông như thế nào: Một công ty SaaS huấn luyện model lead scoring trên ba năm deal đã đóng. Hầu hết là SMB vì đó là thị trường chính của họ ba năm trước. Từ đó họ chuyển lên enterprise. Nhưng model vẫn chấm SMB lead cao, enterprise lead thấp, dù mandate của đội sales là enterprise. Sales leadership nói scoring "đang ngược." Không phải ngược. Model học quá khứ chính xác. Quá khứ chỉ đơn giản là sai với chiến lược hôm nay.
Cách khắc phục: Trước khi retrain, audit các closed-won deal. Phân nhóm theo deal size, ngành, và ICP segment. Nếu thị trường mục tiêu hiện tại không được đại diện đúng tỷ lệ trong training set, model cần retrain trên tập con đã lọc và đại diện, hoặc thêm lớp ICP-weighted scoring lên trên. Đây là lý do AI lead scoring nhấn mạnh kiến trúc model chỉ tốt bằng các training label. Label đến trước.
Key Facts: Tỷ Lệ Thất Bại Trong AI Lead Scoring
- NIST AI Risk Management Framework xác định giám sát và đo lường liên tục là yêu cầu trustworthiness cốt lõi cho các hệ thống AI đã triển khai. Model scoring không có retraining cadence vi phạm yêu cầu này theo thiết kế
- Model huấn luyện trên dưới 100 closed-won outcome tạo ra output không thể phân biệt thống kê với phân công ngẫu nhiên. Dưới 200, độ tin cậy rất thấp
- Các nghiên cứu score-to-conversion nhất quán cho thấy: khi 25-30% tổng inbound lead được chấm "hot", threshold miscalibration bắt đầu làm suy giảm sự tin tưởng của rep. Vượt 30%, adoption thường sụp đổ trong 60 ngày

5 Lead Scoring Failure Modes
5 Lead Scoring Failure Modes là framework chẩn đoán cho các AI scoring deployment có vẻ đang chạy nhưng không thay đổi hành vi của rep. Năm mode gồm: (1) Biased Training Data, khi các deal thắng lịch sử đại diện quá nhiều cho một phân khúc mà đội nhóm đã không còn nhắm tới; (2) Score Surfacing Failure, khi điểm số tồn tại trong CRM field mà rep không bao giờ thấy; (3) No Feedback Loop, khi model không bao giờ retrain và độ chính xác giảm dần; (4) Threshold Miscalibration, khi quá nhiều lead được chấm "hot" khiến nhãn đó mất ý nghĩa; và (5) Intent Gap, khi fit-based scoring tìm được tài khoản phù hợp ICP nhưng bỏ lỡ active buying signal. Mỗi mode có cách khắc phục riêng. Hầu hết các thất bại liên quan đến nhiều hơn một mode cùng lúc.
Lỗi 2: Điểm số không hiển thị nơi rep làm việc
Vấn đề: Điểm số bị chôn trong CRM field cần ba lần click để tìm thì không tạo ra thay đổi hành vi nào. Rep không thay đổi workflow để đi tìm thông tin. Thông tin phải tự đến nơi họ đang làm việc.
Thực tế trông như thế nào: RevOps tạo custom field "AI Lead Score" trong Salesforce. Field nằm trên trang chi tiết lead record, bên dưới fold, cạnh 40 field khác. Không ai đổi default list view. Không có notification nào khi điểm số thay đổi. Rep học cách bỏ qua nó vì nó không can thiệp vào workflow hiện tại của họ.
Cách khắc phục: Score surfacing là bài toán thiết kế workflow, không chỉ bài toán dữ liệu. Điểm số phải xuất hiện trong lead list view (có thể sort), như notification trigger (cảnh báo khi lead vượt ngưỡng), và trong daily digest hoặc task queue của rep. Nếu dùng sales engagement platform như Outreach hay Salesloft, điểm số phải kiểm soát lead nào vào sequence nào. Bài test đơn giản: nếu rep có thể làm việc cả ngày mà không thấy điểm số, thì nó chưa được surfaced. Đây là pitfall dễ khắc phục nhất và hay bị bỏ qua nhất.
Lỗi 3: Không có feedback loop
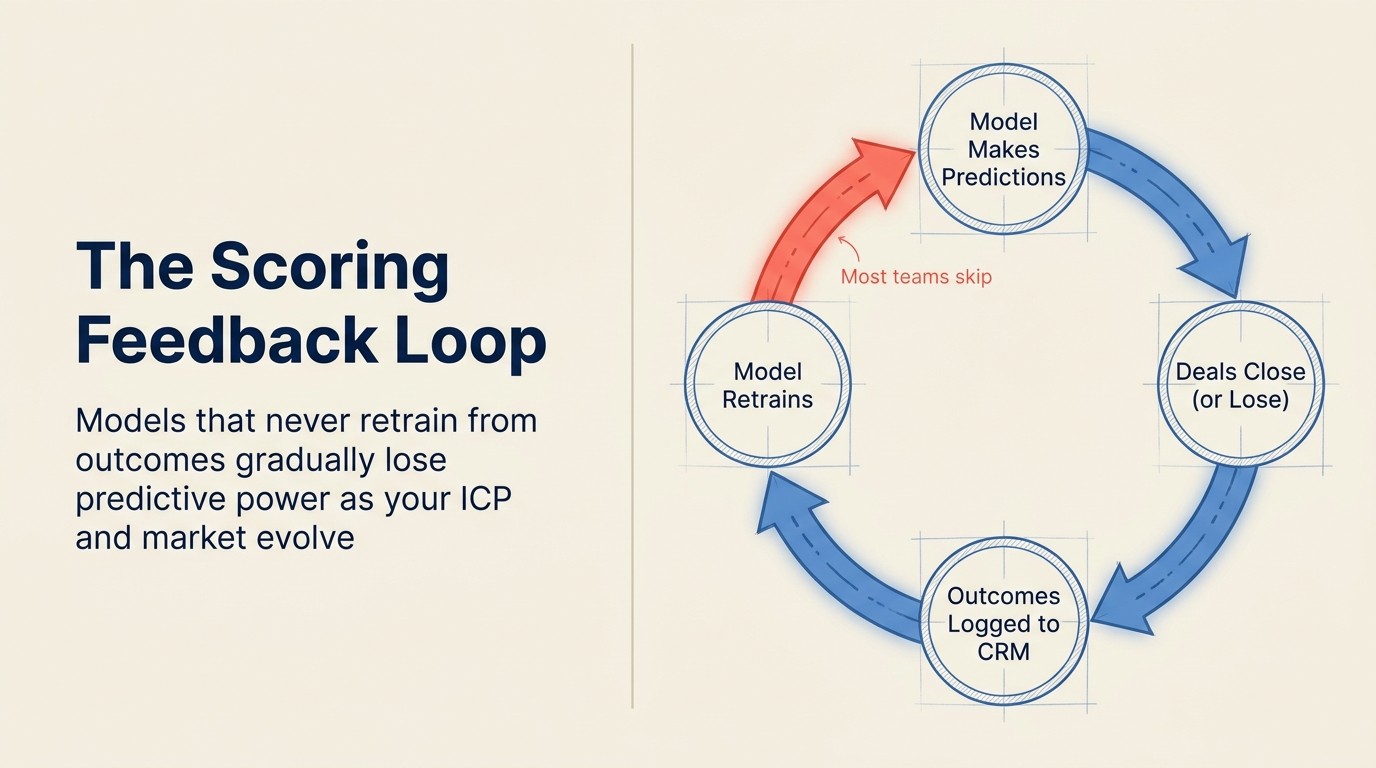
Vấn đề: Model chấm điểm mãi trên training data cũ, không có cơ chế retrain từ closed-won và closed-lost outcome mới. Mỗi quý model ngày càng xa rời thực tế. Nhưng không ai nhận ra vì điểm số vẫn cập nhật và giao diện vẫn trông như cũ.
Đây là failure mode quan trọng nhất về mặt cấu trúc. Các failure mode khác suy giảm dần. Không có feedback loop gây ra suy giảm độ chính xác theo cấp số nhân. Model retrain từ quý 1 năm ngoái mà chưa bao giờ update đã bỏ lỡ bốn quý deal outcome có thể cải thiện dự đoán của nó. NIST AI Risk Management Framework xác định giám sát liên tục là yêu cầu trustworthiness cốt lõi, không phải tác vụ thiết lập một lần.
Thực tế trông như thế nào: Một công ty triển khai HubSpot Predictive Lead Scoring vào tháng Hai. Model huấn luyện trên 18 tháng deal lịch sử. Tháng Tư, họ ra mắt dòng sản phẩm mới thay đổi buyer profile. Tháng Sáu, họ tuyển 5 AE mới bắt đầu đóng deal theo profile khác. Tháng Chín, một manager nhận ra điểm số không tương quan với các deal tốt nhất. Model ổn vào tháng Hai. Nó đã suy giảm từ tháng Tư. Không ai trigger retrain vì hệ thống không cảnh báo về model drift.
Cách khắc phục: Xác định retraining cadence trước khi ra mắt, không phải sau khi nhận ra vấn đề. Hàng quý là tối thiểu cho hầu hết doanh nghiệp. Hàng tháng tốt hơn cho các đội tăng trưởng nhanh hoặc đang thay đổi ICP. Trigger để retrain ngoài chu kỳ: ra mắt sản phẩm mới, thay đổi ICP đáng kể, thêm kênh lớn, hoặc thay đổi sales motion. Điều kiện tiên quyết: CRM phải ghi lại closed-won và closed-lost nhất quán với các field mà model dùng làm feature. Không có logging discipline đó, không có training data mới để đưa vào.
Đây cũng là lý do giải thích điểm số bằng ngôn ngữ con người (Lỗi 6) quan trọng với feedback. Nếu rep thấy lead được chấm cao vì "company size + tech stack + industry match," họ có thể báo hiệu khi logic đó không còn phản ánh thực tế chuyển đổi. Rep là hệ thống cảnh báo sớm cho model drift. Nhưng chỉ khi họ hiểu được logic scoring.
Lỗi 4: Quá nhiều input feature, quá ít dữ liệu
Vấn đề: Overfitting. Model dùng 40 input feature để chấm lead từ training set 300 deal lịch sử. Nó ghi nhớ các pattern trong training data thay vì khái quát hóa cho lead mới. Trông ấn tượng lúc đánh giá (độ chính xác cao trên training data) nhưng thất bại trên live lead.
Thực tế trông như thế nào: Một RevOps analyst xây dựng custom lead scoring model bằng Python với 45 feature từ Salesforce, mọi field họ nghĩ được: page views, email opens, job title level, company age, LinkedIn followers, funding status, v.v. Model evaluation cho thấy độ chính xác 89%. Khi triển khai, rep nhận ra model cho điểm 90+ cho lead không bao giờ engage và điểm thấp cho lead rõ ràng đã qualified. Model ghi nhớ training set. Nó không có giá trị dự đoán trên dữ liệu mới.
Cách khắc phục: Đội có dưới 1.000 historical outcome nên dùng model đơn giản hơn với ít feature hơn. 5-10 high-signal feature, điền nhất quán, vượt trội 45 feature thưa thớt hoặc không nhất quán. Các feature có giá trị cao kinh điển: company size, industry match, job title seniority, form source (trang/kênh nào), và product-usage signal cho expansion lead. Bắt đầu đơn giản. Thêm feature khi data volume tăng.
Đội có dữ liệu lịch sử hạn chế nên bắt đầu với pre-trained model của vendor (Salesforce Einstein, HubSpot Predictive Lead Scoring) và layer thêm tiêu chí ICP lên trên. Thường đáng tin cậy hơn tự xây từ đầu.
Lỗi 5: Ngưỡng điểm số không khớp
Vấn đề: Model xuất ra xác suất, nhưng routing threshold đặt sai. Threshold quá thấp thì rep bị ngập với "hot" lead thực ra không hot. Threshold quá cao thì qualified lead không bao giờ leo lên được tầm chú ý của con người.
Thực tế trông như thế nào: Một đội đặt "hot lead" threshold ở mức 40/100. Model calibrated để 40 đại diện xác suất chuyển đổi 40%. Với threshold ở 40, 60% inbound bị flag là hot và routing đến senior SDR. SDR bị ngập. Connect rate trên "hot" lead trông thảm hại vì có quá nhiều lead để làm đúng cách. Vấn đề không phải scoring model. Đó là threshold.
Cách khắc phục: Đặt threshold phải dựa trên historical conversion rate theo score band, không đặt tùy tiện. Lấy 6-12 tháng scored lead và conversion outcome (nếu có). Tìm score band nơi conversion rate tăng đột biến. Đó là routing threshold. Nếu thiết lập scoring lần đầu mà chưa có historical scored lead, bắt đầu với threshold cao (70+) để giữ hot-lead volume ở mức quản lý được, rồi điều chỉnh dần xuống.
Câu hỏi threshold cũng mở rộng đến routing tier. Cần xác định ít nhất ba tier: high-priority (human escalation, SLA nhanh), standard (hàng đợi SDR thông thường), và nurture (automated sequence, không có rep contact cho đến khi intent signal kích hoạt). Các ngưỡng giữa tier phải được tuned, không phải giả định. Và 25-30% lead được chấm "hot" là trần chẩn đoán: vượt mức đó thì hạ threshold ngay trước khi rep ngừng tin tưởng hệ thống hoàn toàn.
Lỗi 6: Rep không tin vì điểm số không giải thích được
Vấn đề: Black-box scoring phá vỡ adoption. Rep không hiểu tại sao lead được chấm 87 thì không hành động theo đó nhất quán. Khi model mắc lỗi mà rep nhìn ra ngay (lead chất lượng thấp rõ ràng được chấm 90), toàn bộ hệ thống mất uy tín trong mắt rep đó.
Thực tế trông như thế nào: Một công ty triển khai scoring model dùng 15 weighted signal. Giao diện chỉ hiển thị một con số: "Lead Score: 82." Rep nhìn vào lead, thấy startup 3 người thuộc loại công ty hiếm khi chuyển đổi, bỏ qua điểm 82. Tuần sau bỏ qua điểm 91. Sau hai tháng, rep gạch bỏ scoring trong đầu. Model có thể chính xác trung bình, nhưng các lỗi cá nhân không có giải thích phá hủy adoption.
Cách khắc phục: Giải thích điểm số phải xuất hiện ngay tại điểm sử dụng. Không chỉ "Score: 82" mà "Score: 82 vì company size (mid-market), industry (financial services), và vòng funding gần đây đều khớp ICP. Intent signal: trung bình. Thiếu: chưa xác nhận contact decision-maker." Với context đó, dù rep không đồng ý với điểm số, họ hiểu lý luận. Họ có thể thách thức đúng input (có thể phân loại "mid-market" sai vì công ty vừa co lại) thay vì bác bỏ cả hệ thống.
Một số tool cung cấp điều này natively (Salesforce Einstein score factors, HubSpot score breakdown). Custom model cần xây dựng có chủ đích.
Lỗi 7: Bỏ qua timing signal (fit mà không có intent)
Vấn đề: Fit-based scoring cho biết công ty có khớp ICP không. Nó không cho biết họ có đang tích cực mua không. Công ty khớp ICP hoàn hảo nhưng không đang trong thị trường thì điểm cao nhưng chuyển đổi kém. Công ty khớp ICP trung bình nhưng đang trong quá trình đánh giá tích cực thì điểm trung bình nhưng chuyển đổi tốt hơn. Intent kết hợp với fit vượt trội bất kỳ yếu tố nào đơn lẻ.
Thực tế trông như thế nào: Model của một đội chấm tài khoản hoàn toàn theo firmographic fit: company size, industry, tech stack, revenue range. Lead "Tier 1" nhất quán là các tài khoản phù hợp tốt. Nhưng rep phàn nàn không thể khiến những lead đó engage. Đó là ICP match lạnh, không phải buyer ấm. Trong khi đó, intent data từ Bombora và 6sense cho thấy một số tài khoản mid-tier đang tích cực nghiên cứu danh mục của công ty. Các tài khoản đó không bao giờ nổi lên vì firmographic fit thấp.
Cách khắc phục: Thêm timing signal như một scoring layer. Third-party intent (Bombora, 6sense, Demandbase) cho biết ai đang tích cực nghiên cứu ngay lúc này. First-party signal (xem trang pricing, đọc documentation, so sánh tính năng) cho biết ai trong số những người submit form đang trong chế độ đánh giá tích cực. Lead chấm 60 về fit nhưng intent signal cao phải routing khác với lead chấm 90 về fit nhưng không có intent. Model kết hợp bắt được các buyer mà bạn sẽ bỏ lỡ với bất kỳ signal đơn lẻ nào. Bài viết buyer intent signal synthesis with AI chỉ cách layer các signal này trong thực tế.
Phân Tích Rework: Silent failure pattern là loại tốn kém nhất chúng tôi thấy trong AI lead scoring deployment. Model đang chạy về mặt kỹ thuật, vendor vẫn được thanh toán, nhưng rep ngừng tin vào điểm số từ ba tháng trước và không ai chính thức thừa nhận. Dấu hiệu nhận biết là một câu hỏi khảo sát đơn giản: "Bạn có xem AI lead score trước khi quyết định làm lead nào trước không?" Khi dưới 40% rep nói có, hệ thống scoring chỉ là trang trí. Cách khắc phục hầu như không bao giờ cần vendor mới. Cần giải quyết đúng failure mode đã làm mất tin tưởng, thường là threshold miscalibration hoặc score surfacing failure, hai vấn đề dễ khắc phục về mặt vận hành nhất trong danh sách.
Audit checklist: câu hỏi chẩn đoán cho hệ thống scoring của bạn
Dùng những câu hỏi này để chẩn đoán pitfall nào đang ảnh hưởng đến hệ thống hiện tại:
Dữ liệu huấn luyện
- Model retrain lần cuối khi nào? Có cadence được lên lịch không?
- Bao nhiêu phần trăm closed-won deal hiện tại đến từ các phân khúc nổi bật trong training data?
- Closed-lost deal có được đưa vào training set không, hay chỉ closed-won?
Surfacing và adoption
- Rep có thể thấy điểm số mà không cần rời khỏi default list view không?
- Có notification hoặc alert khi lead vượt ngưỡng không?
- Hỏi ba rep: "Điểm lead cao có nghĩa gì với workflow hàng ngày của bạn?" Nếu câu trả lời mơ hồ, điểm số không thay đổi hành vi.
Feedback loop
- Có trigger retrain chính thức không? Ai sở hữu nó?
- Các field closed-won và closed-lost có bắt buộc trong CRM với định nghĩa nhất quán không?
- Làm thế nào bạn biết nếu độ chính xác model đang giảm?
Threshold calibration
- Bao nhiêu phần trăm inbound volume được chấm "hot"? Trên 25-30% thì threshold có thể quá thấp.
- Bạn có dữ liệu score-to-conversion outcome để xác nhận threshold hiện tại không?
Khả năng giải thích
- Rep có thể thấy điều gì đã thúc đẩy một điểm số không?
- Khi rep không đồng ý với điểm số, họ có biết input nào để thách thức không?
Tích hợp intent
- Timing/intent data có được đưa vào scoring không, hay chỉ firmographic fit?
- Có first-party behavioral signal nào trong scoring model không (page views, email engagement, demo request)?
Nếu bạn trả lời "không" cho hơn ba câu, hệ thống scoring có ít nhất một vấn đề cấu trúc. Bài viết AI lead scoring overview nói về cách xây model hoạt động tốt. Bài này nói về lý do những model đó thất bại trong thực tế.
Failure modes: khi AI sales ops phản tác dụng mở rộng phân tích này ra ngoài scoring đến toàn bộ RevOps stack.
Tóm tắt thực tế
Các pitfall trong AI lead scoring đều có thể khắc phục. Nhưng hầu hết cách khắc phục là về vận hành, không phải kỹ thuật. Bạn không cần vendor khác cho hầu hết vấn đề này. Bạn cần retraining cadence, score surfacing workflow, quy trình threshold calibration, và explainability layer.
Failure mode nguy hiểm nhất cũng là phổ biến nhất: model chạy mãi không có feedback loop, dần dần xa rời thực tế trong khi mọi người vẫn nghĩ nó hoạt động vì giao diện trông như cũ. Scoring không có retraining giống điều hướng bằng bản đồ từ năm ngoái. Địa hình đã thay đổi. Bản đồ chưa biết điều đó.
Câu Hỏi Thường Gặp
Tại sao hầu hết AI lead scoring deployment thất bại lặng lẽ?
Thất bại lặng lẽ xảy ra vì không có thông báo lỗi khi scoring model ngừng hữu ích. Model tiếp tục tạo ra điểm số, CRM field tiếp tục cập nhật, vendor tiếp tục tính phí. Nhưng rep dần ngừng hành động theo điểm số và không ai chính thức ghi nhận hệ thống đã ngừng hoạt động. Thất bại bị đổ cho chất lượng lead hay hiệu suất rep thay vì các vấn đề cấu trúc thực sự: biased training data, không có retraining cadence, miscalibrated threshold, hoặc điểm số bị chôn trong CRM field không ai thấy.
AI lead scoring failure mode quan trọng nhất là gì?
Feedback loop failure, khi model chạy mãi không retrain từ closed outcome mới, là quan trọng nhất về mặt cấu trúc. Các failure mode khác suy giảm dần. Không có feedback loop gây ra suy giảm độ chính xác theo cấp số nhân. Model huấn luyện từ quý 1 mà chưa bao giờ retrain đã bỏ lỡ mọi thay đổi thị trường, thay đổi ICP, và thêm kênh từ đó đến nay. NIST AI Risk Management Framework phân loại giám sát liên tục là yêu cầu trustworthiness cốt lõi, không phải bảo trì tùy chọn.
Làm thế nào biết AI lead scoring threshold bị miscalibrated?
Ba tín hiệu chỉ ra vấn đề threshold: hơn 25-30% tổng inbound volume được chấm "hot" (threshold quá thấp), rep phàn nàn hot lead không chuyển đổi (cùng vấn đề), hoặc rep tự sắp xếp lại lead theo trực giác thay vì theo điểm số (threshold mất uy tín). Khắc phục bằng cách lấy 6-12 tháng scored lead có outcome, tìm score band nơi conversion rate tăng đột biến, và đặt hot-lead threshold tại band đó.
Rep nên thấy gì khi nhìn vào lead score?
Trải nghiệm score surfacing hoàn chỉnh hiển thị: bản thân điểm số (ví dụ 82/100), ba yếu tố hàng đầu thúc đẩy điểm (ví dụ company size: mid-market, industry: financial services, recent funding: Series B), bất kỳ intent signal nào phát hiện được, và điều gì còn thiếu để cải thiện điểm (ví dụ chưa có confirmed decision-maker contact). Không có context này, rep không thể thách thức input sai, không thể xây dựng trực giác về ý nghĩa của điểm cao, và không thể tin hệ thống khi thấy lỗi cá nhân.
AI lead scoring model nên retrain bao lâu một lần?
Hàng quý là tối thiểu. Hàng tháng tốt hơn cho đội tăng trưởng nhanh hoặc đang thay đổi ICP. Trigger retrain ngoài chu kỳ gồm ra mắt sản phẩm mới, thay đổi ICP đáng kể, kênh mới lớn, hoặc thay đổi vật chất trong deal size distribution. Cơ chế retrain đòi hỏi closed-won và closed-lost outcome phải được ghi lại nhất quán với các field mà model dùng làm feature. Không có logging discipline đó thì không có training data mới để đưa vào.
Sự khác biệt giữa fit scoring và intent scoring là gì?
Fit scoring đo mức độ phù hợp của công ty với ICP trên các chiều firmographic: company size, industry, tech stack, revenue range. Intent scoring đo công ty có đang tích cực nghiên cứu và mua ngay lúc này không: dữ liệu third-party từ Bombora hoặc 6sense cho thấy category research, cộng với first-party signal như xem trang pricing và so sánh tính năng. Fit-only scoring cho ra danh sách khách hàng tiềm năng tốt nhất, hầu hết không đang trong chế độ mua hàng hôm nay. Kết hợp fit và intent bộc lộ ai vừa tốt nhất vừa sẵn sàng nhất. Lead 60-fit/high-intent thường chuyển đổi tốt hơn lead 90-fit/no-intent.
Tại sao rep ngừng tin AI lead score sau vài tuần?
Niềm tin sụp đổ khi rep thấy điểm cao trên lead họ biết là sai mà không có giải thích. Rep thấy công ty chất lượng thấp rõ ràng với điểm 85, không thấy lý do tại sao, kết luận cả hệ thống không đáng tin. Black-box scoring phá hủy adoption vì rep không thể phân biệt model tốt mắc lỗi hiếm với model hỏng ra số ngẫu nhiên. Giải thích điểm số ngăn điều này: với context, rep có thể thách thức đúng input thay vì bỏ cả hệ thống.
Đọc Thêm

Co-Founder, Rework.com
On this page
- Lỗi 1: Huấn luyện trên dữ liệu lịch sử có thiên lệch
- 5 Lead Scoring Failure Modes
- Lỗi 2: Điểm số không hiển thị nơi rep làm việc
- Lỗi 3: Không có feedback loop
- Lỗi 4: Quá nhiều input feature, quá ít dữ liệu
- Lỗi 5: Ngưỡng điểm số không khớp
- Lỗi 6: Rep không tin vì điểm số không giải thích được
- Lỗi 7: Bỏ qua timing signal (fit mà không có intent)
- Audit checklist: câu hỏi chẩn đoán cho hệ thống scoring của bạn
- Tóm tắt thực tế
- Đọc Thêm