Perangkap AI Lead Scoring yang Biasa (Dan Cara Mengatasinya)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Kebanyakan pelancaran AI lead scoring gagal secara senyap. Tiada ranap sistem, tiada mesej ralat, dan tiada saat di mana sesiapa mengisytiharkannya rosak. Model berjalan, skor muncul dalam Customer Relationship Management (CRM), rep memandangnya selama beberapa minggu, dan kemudian berhenti menggunakannya. Alat itu kekal dalam kontrak. Skor terus dikemas kini. Enam bulan kemudian, apabila seseorang bertanya sama ada lead scoring berfungsi, tiada siapa yang benar-benar tahu.
Kegagalan senyap adalah yang paling teruk: ia mahal, ia tidak kelihatan, dan dikaitkan dengan sebab yang salah. "Lead kami hanya berkualiti lebih rendah suku ini." "Rep memerlukan latihan yang lebih baik dalam kelayakan." "Mungkin model memerlukan lebih banyak data." Semua itu mungkin benar. Tetapi selalunya masalah yang lebih mendalam adalah berstruktur, bukan masalah volum data atau masalah prestasi rep.
Artikel ini adalah diagnostik untuk pemimpin ops yang telah melancarkan AI lead scoring dan tidak melihat perubahan tingkah laku yang dijangka. Kegagalan di bawah adalah corak yang paling biasa, dan kebanyakannya boleh diperbaiki dengan perubahan operasi dan bukannya penukaran vendor.
Perangkap 1: Latihan pada data sejarah yang berat sebelah

Masalah: Model Anda dilatih pada urusan closed-won masa lalu, dan urusan closed-won masa lalu Anda mewakili secara berlebihan satu segmen. Model tersebut belajar untuk memberi skor tinggi kepada segmen itu. Tetapi segmen itu mungkin tidak mewakili akaun terbaik Anda hari ini.
Apa yang kelihatan dalam praktik: Syarikat SaaS melatih model lead scoring mereka dengan tiga tahun urusan yang ditutup. Kebanyakan urusan tersebut adalah SMB, kerana itulah pasaran utama mereka tiga tahun lalu. Mereka sejak itu beralih ke atas pasaran. Model terus memberi skor tinggi kepada lead SMB dan skor rendah kepada lead perusahaan, walaupun mandat pasukan jualan adalah perusahaan. Kepimpinan jualan berpendapat scoring adalah "terbalik." Ia bukan terbalik; ia belajar masa lalu dengan tepat. Masa lalu sahaja yang salah untuk strategi hari ini.
Pembetulan: Sebelum melatih semula, lakukan audit closed-won. Kumpulkan urusan closed-won sejarah Anda mengikut saiz urusan, industri, dan segmen Ideal Customer Profile (ICP). Jika pasaran sasaran semasa Anda tidak diwakili secara berkadaran dalam set latihan, model Anda memerlukan sama ada latihan semula pada subset yang ditapis dan mewakili, atau lapisan scoring berwajaran ICP di atas. Inilah sebabnya AI lead scoring menekankan bahawa seni bina model hanya sebaik label latihan. Label mesti datang dahulu.
Fakta Utama: Kadar Kegagalan AI Lead Scoring
- NIST AI Risk Management Framework mengenal pasti pemantauan dan pengukuran berterusan sebagai keperluan kebolehpercayaan teras untuk sistem AI yang digunakan; model scoring tanpa kadaran latihan semula melanggar keperluan ini secara reka bentuk
- Model yang dilatih pada kurang daripada 100 hasil closed-won menghasilkan output yang secara statistik tidak dapat dibezakan daripada tugasan rawak; di bawah 200, kebolehpercayaan model adalah marginal
- Kajian korelasi skor-ke-penukaran secara konsisten menunjukkan bahawa 25-30% daripada semua lead masuk yang mendapat skor "panas" adalah ambang di mana salah kalibrasi ambang mula merendahkan kepercayaan rep; melebihi 30%, penggunaan biasanya runtuh dalam masa 60 hari
The 5 Lead Scoring Failure Modes
The 5 Lead Scoring Failure Modes adalah rangka kerja diagnostik untuk pelancaran scoring AI yang kelihatan berjalan tetapi tidak mengubah tingkah laku rep. Lima mod itu adalah: (1) Biased Training Data, di mana kemenangan sejarah mewakili secara berlebihan segmen pasaran yang telah ditinggalkan pasukan; (2) Score Surfacing Failure, di mana skor wujud dalam medan CRM yang tidak pernah dilihat rep; (3) No Feedback Loop, di mana model tidak pernah dilatih semula dan ketepatan merosot dari masa ke masa; (4) Threshold Miscalibration, di mana terlalu banyak lead mendapat skor "panas" dan penandaan itu menjadi tidak bermakna; dan (5) Intent Gap, di mana scoring berasaskan kesesuaian mengenal pasti akaun yang sepadan dengan ICP tetapi terlepas isyarat pembelian aktif. Setiap mod mempunyai pembetulan yang berbeza. Kebanyakan kegagalan melibatkan lebih daripada satu mod secara serentak.
Perangkap 2: Skor tidak dipaparkan di mana rep bekerja
Masalah: Skor yang tersembunyi dalam medan CRM yang memerlukan tiga klik tidak menghasilkan sebarang perubahan tingkah laku. Rep tidak mengubah aliran kerja untuk mencari maklumat; maklumat perlu menemui mereka di tempat mereka sudah berada.
Apa yang kelihatan dalam praktik: Revenue Operations (RevOps) menyediakan medan tersuai bernama "AI Lead Score" dalam Salesforce. Ia ada di halaman butiran rekod lead, di bawah lipatan, bersebelahan 40 medan lain. Tiada siapa yang mengubah paparan senarai lalai. Tiada pemberitahuan yang dihantar apabila skor dikemas kini. Rep belajar untuk mengabaikannya kerana ia tidak mengganggu aliran kerja sedia ada mereka.
Pembetulan: Pemaparan skor adalah masalah reka bentuk aliran kerja, bukan sahaja masalah data. Skor perlu muncul dalam paparan senarai lead (boleh diisih), sebagai pencetus pemberitahuan (amaran apabila lead melepasi ambang), dan dalam digest harian atau baruan tugasan rep. Jika Anda menggunakan platform penglibatan jualan seperti Outreach atau Salesloft, skor harus mengawal lead mana yang memasuki urutan mana. Ujiannya: jika rep boleh menjalani seluruh hari kerja mereka tanpa melihat skor, ia tidak dipaparkan. Ini adalah salah satu perangkap yang paling mudah diperbaiki dan paling kerap terlepas.
Perangkap 3: Tiada gelung maklum balas
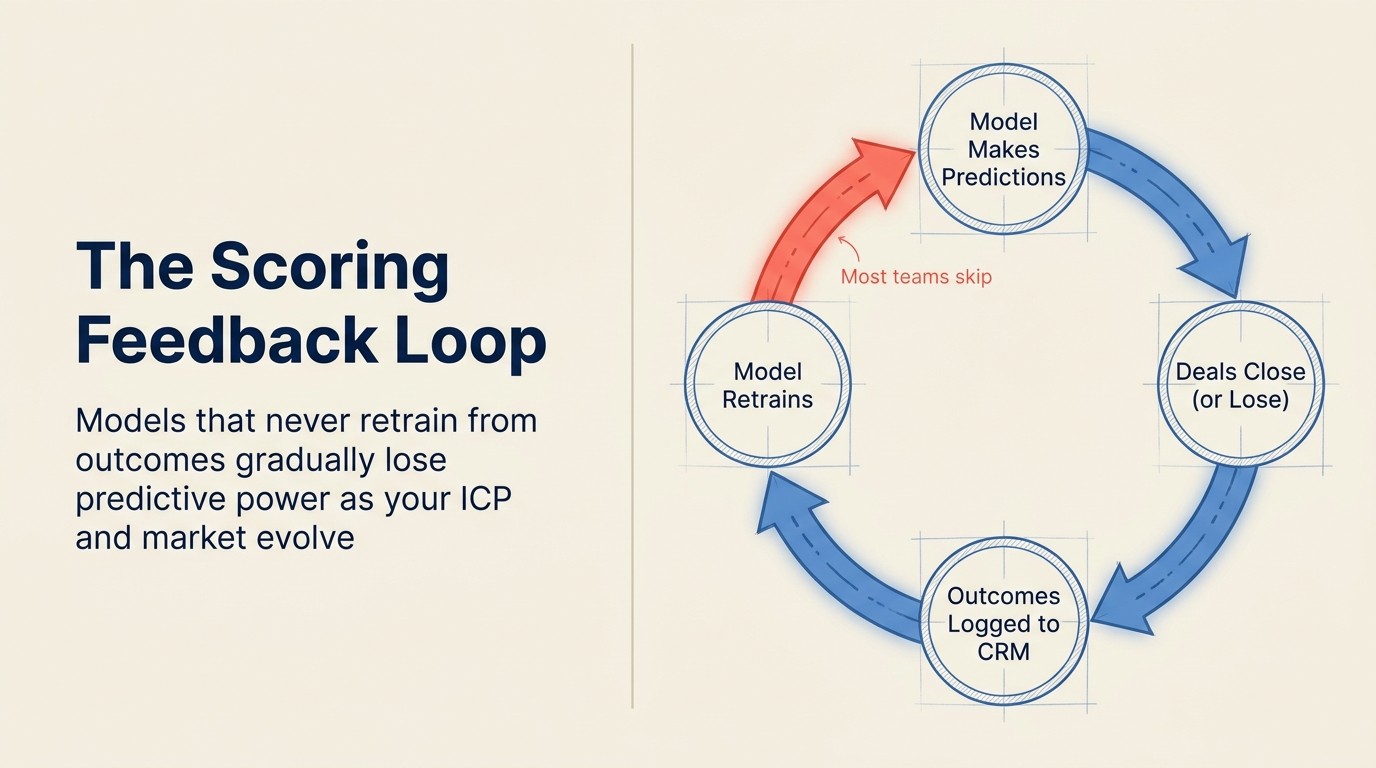
Masalah: Model scoring pada data latihan statik selama-lamanya, tanpa mekanisme untuk melatih semula pada hasil closed-won dan closed-lost baru. Setiap suku model semakin menyimpang dari realiti semasa, tetapi tiada siapa yang menyedarinya kerana skor terus dikemas kini dan antara muka kelihatan sama.
Ini adalah mod kegagalan yang paling penting secara struktur. Tidak seperti yang lain, yang merosot secara beransur-ansur, tiada gelung maklum balas menyebabkan kemerosotan ketepatan yang berganda. Model yang dilatih pada S1 tahun lalu dan tidak pernah dikemas kini kini telah melepasi empat suku hasil urusan yang boleh mempertajam ramalan. NIST AI Risk Management Framework secara khusus mengenal pasti pemantauan dan pengukuran berterusan sebagai keperluan kebolehpercayaan teras untuk sebarang sistem AI yang digunakan, bukan tugas persediaan sekali sahaja.
Apa yang kelihatan dalam praktik: Syarikat melancarkan HubSpot Predictive Lead Scoring pada bulan Februari. Ia dilatih pada 18 bulan urusan sejarah. Pada bulan April, mereka melancarkan lini produk baru yang mengubah profil pembeli mereka. Pada bulan Jun, mereka mengambil 5 Account Executives (AEs) baru yang mula menutup profil urusan yang berbeza. Pada bulan September, seorang pengurus menyedari bahawa skor tidak berkorelasi dengan urusan terbaik mereka. Model itu baik pada bulan Februari. Ia telah merosot sejak bulan April. Tiada siapa yang mencetuskan latihan semula kerana sistem tidak memberi amaran tentang penyimpangan.
Pembetulan: Tentukan kadaran latihan semula sebelum Anda melancarkan, bukan selepas Anda menyedari masalah. Suku tahunan adalah minimum untuk kebanyakan perniagaan; bulanan adalah lebih baik untuk pasukan yang berkembang pesat dengan ICP yang berubah. Peristiwa pencetus untuk latihan semula di luar kitaran: pelancaran produk baru, perubahan ICP yang ketara, penambahan saluran utama, atau perubahan gerakan jualan. Mekaniknya: pastikan CRM Anda merekod closed-won dan closed-lost secara konsisten dengan medan yang digunakan model Anda sebagai ciri. Tanpa disiplin pengelogan itu, Anda tidak mempunyai data latihan baru untuk dimasukkan semula.
Ini juga sebabnya penjelasan skor yang boleh dibaca manusia (Perangkap 6) penting untuk maklum balas. Jika rep boleh melihat bahawa lead mendapat skor tinggi kerana "saiz syarikat + tech stack + padanan industri," mereka boleh memberi isyarat apabila logik itu tidak lagi mencerminkan apa yang sedang bertukar. Rep adalah sistem amaran awal Anda untuk penyimpangan model, tetapi hanya jika mereka memahami logik scoring.
Perangkap 4: Terlalu banyak ciri input, terlalu sedikit data
Masalah: Overfitting. Model menggunakan 40 ciri input untuk memberi skor lead dari set latihan 300 urusan sejarah. Ia menghafal corak dalam data latihan daripada membuat generalisasi kepada lead baru. Ia kelihatan mengesankan dalam penilaian (ketepatan tinggi pada data latihan) dan gagal pada lead langsung.
Apa yang kelihatan dalam praktik: Penganalisis RevOps membina model lead scoring tersuai dalam Python menggunakan 45 ciri dari Salesforce (setiap medan yang boleh mereka fikirkan: paparan halaman, pembukaan e-mel, peringkat jawatan, usia syarikat, pengikut LinkedIn, status pembiayaan, dan lain-lain). Penilaian model menunjukkan 89% ketepatan. Apabila digunakan, rep menyedari model memberi skor 90+ kepada lead yang tidak pernah terlibat dan skor rendah kepada lead yang jelas berkelayakan. Model menghafal set latihan. Ia tidak mempunyai nilai ramalan pada data baru.
Pembetulan: Untuk pasukan dengan kurang daripada 1,000 hasil sejarah, gunakan model yang lebih mudah dengan ciri yang lebih sedikit. 5-10 ciri isyarat tinggi yang diisi secara konsisten mengatasi 45 ciri yang jarang atau tidak konsisten. Ciri nilai tinggi klasik: saiz syarikat, padanan industri, senioriti jawatan, sumber borang (halaman/saluran mana), dan isyarat penggunaan produk untuk lead pengembangan. Mulakan dengan jarang. Tambah ciri apabila volum data Anda berkembang.
Untuk pasukan dengan data sejarah yang terhad, memulakan dengan model pra-latih vendor (Salesforce Einstein, HubSpot Predictive Lead Scoring) dan melapisi kriteria ICP Anda di atas sering lebih boleh dipercayai berbanding membina dari awal.
Perangkap 5: Ketidakpadanan ambang skor
Masalah: Model menghasilkan kebarangkalian, tetapi ambang routing ditetapkan dengan salah. Ambang yang terlalu rendah membanjiri rep dengan lead "panas" yang sebenarnya tidak panas. Ambang yang terlalu tinggi bermakna lead yang layak tidak pernah meningkat ke perhatian manusia.
Apa yang kelihatan dalam praktik: Pasukan menetapkan ambang "lead panas" mereka pada 40 daripada 100. Model scoring mereka dikalibrasi supaya 40 mewakili kebarangkalian penukaran 40%. Dengan ambang pada 40, 60% masuk mereka ditandai sebagai panas dan dihalakan ke SDR kanan. SDR tersebut terlebih beban. Kadar sambungan mereka pada lead "panas" kelihatan teruk kerana terlalu banyak lead untuk diusahakan dengan betul. Masalahnya bukan model scoring; ia adalah ambang.
Pembetulan: Penetapan ambang harus dikalibrasi berbanding kadar penukaran sejarah mengikut kumpulan skor, bukan ditetapkan sewenang-wenangnya. Tarik 6-12 bulan terakhir lead yang mendapat skor dengan hasil penukaran (jika Anda mempunyainya). Cari kumpulan skor di mana kadar penukaran meningkat dengan bermakna. Itulah ambang routing Anda. Jika Anda menyediakan scoring buat pertama kali tanpa lead berskor sejarah, mulakan dengan ambang yang tinggi (70+) yang memastikan volum lead panas boleh diurus, dan laraskan ke bawah dari masa ke masa apabila Anda mengumpul data skor-ke-hasil.
Soalan ambang juga meluas ke peringkat routing. Tentukan sekurang-kurangnya tiga peringkat routing: keutamaan tinggi (peningkatan manusia, SLA pantas), standard (baruan SDR biasa), dan nurture (urutan automatik, tiada kenalan rep sehingga isyarat niat mencetuskan). Ambang antara peringkat tersebut perlu ditala, bukan diandaikan. Dan 25-30% lead yang mendapat skor "panas" adalah siling diagnostik: jika Anda melebihi itu, turunkan ambang sebelum rep berhenti mempercayai sistem sepenuhnya.
Perangkap 6: Ketidakpercayaan rep akibat skor yang tidak dapat dijelaskan
Masalah: Scoring kotak hitam kehilangan penggunaan rep. Rep yang tidak faham mengapa lead mendapat skor 87 tidak akan bertindak atasnya secara konsisten. Dan apabila model membuat kesilapan yang boleh dikesan rep (lead jelas berkualiti rendah dengan skor 90), keseluruhan sistem scoring kehilangan kredibiliti dalam fikiran rep tersebut.
Apa yang kelihatan dalam praktik: Syarikat melancarkan model scoring yang menggunakan 15 isyarat berwajaran. Antara muka menunjukkan rep satu nombor: "Lead Score: 82." Rep melihat lead, melihat syarikat 3-orang pada jenis syarikat yang jarang bertukar untuk mereka, dan mengabaikan skor 82. Minggu berikut mereka mengabaikan skor 91. Dalam masa dua bulan, rep telah membuang secara mental scoring sebagai tidak boleh dipercayai. Model mungkin tepat secara purata, tetapi kesilapan individu tanpa penjelasan menghancurkan penggunaan.
Pembetulan: Penjelasan skor harus muncul di tempat penggunaan. Bukan sahaja "Skor: 82" tetapi "Skor: 82 kerana saiz syarikat (pertengahan pasaran), industri (perkhidmatan kewangan), dan pusingan pembiayaan terkini semuanya sepadan dengan ICP Anda. Isyarat niat: sederhana. Yang tiada: kenalan pembuat keputusan yang disahkan." Dengan konteks itu, walaupun apabila rep tidak bersetuju dengan skor, mereka memahami penaakulan. Mereka boleh mencabar input yang betul (mungkin klasifikasi "pertengahan pasaran" adalah salah kerana syarikat ini baru-baru ini mengecut) daripada menolak keseluruhan skor.
Beberapa alat menawarkan ini secara semula jadi (faktor skor Salesforce Einstein, pecahan skor HubSpot). Model tersuai memerlukannya dibina secara sengaja.
Perangkap 7: Mengabaikan isyarat masa (kesesuaian tanpa niat)
Masalah: Scoring berasaskan kesesuaian memberitahu Anda bahawa syarikat sepadan dengan ICP Anda. Ia tidak memberitahu Anda mereka sedang aktif membeli. Syarikat yang sangat sesuai yang tidak berada di pasaran mendapat skor tinggi tetapi bertukar dengan teruk. Syarikat yang sesuai purata dalam penilaian aktif mendapat skor sederhana tetapi bertukar lebih baik. Niat ditambah kesesuaian bersama-sama mengatasi mana-mana sahaja.
Apa yang kelihatan dalam praktik: Model pasukan memberi skor akaun sepenuhnya berdasarkan kesesuaian firmografi: saiz syarikat, industri, tech stack, julat hasil. Lead "Peringkat 1" mereka secara konsisten adalah akaun yang sepadan dengan baik. Tetapi rep mengadu mereka tidak dapat mendapatkan lead ini untuk terlibat. Mereka adalah padanan ICP sejuk, bukan pembeli yang hangat. Sementara itu, data niat (Bombora, 6sense) menunjukkan beberapa akaun peringkat pertengahan yang sedang aktif menyelidik kategori syarikat. Akaun tersebut tidak pernah muncul kerana mereka tidak mendapat skor tinggi pada kesesuaian firmografi.
Pembetulan: Tambah isyarat masa sebagai lapisan scoring. Niat pihak ketiga (Bombora, 6sense, Demandbase) memberitahu Anda siapa yang sedang aktif menyelidik sekarang. Isyarat pihak pertama (lawatan halaman harga, pembacaan dokumentasi, paparan perbandingan ciri) memberitahu Anda pengirim borang mana yang berada dalam mod penilaian aktif. Lead yang mendapat skor 60 pada kesesuaian tetapi mempunyai isyarat niat tinggi harus dihalakan secara berbeza berbanding lead yang mendapat skor 90 pada kesesuaian tetapi tidak menunjukkan niat. Model gabungan menangkap pembeli yang akan terlepas dengan mana-mana isyarat sahaja. Artikel buyer intent signal synthesis with AI menunjukkan cara melapisi isyarat ini dalam praktik.
Analisis Rework: Corak kegagalan senyap adalah yang paling mahal yang kami lihat dalam pelancaran AI lead scoring. Model secara teknikal berjalan, vendor secara teknikal masih dibayar, tetapi rep berhenti mempercayai skor tiga bulan lalu dan tiada siapa yang mengakuinya secara rasmi. Petandanya adalah soalan tinjauan: "Adakah Anda melihat skor AI lead sebelum memutuskan lead mana yang perlu diusahakan dahulu?" Apabila kurang daripada 40% rep menjawab ya, sistem scoring adalah hiasan. Pembetulan hampir tidak pernah memerlukan vendor baru. Ia memerlukan penyelesaian mana-mana daripada lima mod kegagalan yang menyebabkan kepercayaan terhakis, biasanya salah kalibrasi ambang atau kegagalan pemaparan skor, dua masalah yang paling mudah diperbaiki secara operasi dalam senarai.
Senarai semak audit: soalan diagnostik untuk pelancaran scoring Anda
Gunakan ini untuk mendiagnosis perangkap mana yang mempengaruhi sistem semasa Anda:
Data latihan
- Bilakah model terakhir kali dilatih semula? Adakah ada kadaran yang dijadualkan?
- Berapa peratus urusan closed-won semasa Anda berasal dari segmen yang menonjol dalam data latihan?
- Adakah urusan closed-lost disertakan dalam set latihan, atau hanya closed-won?
Pemaparan dan penggunaan
- Bolehkah rep melihat skor tanpa meninggalkan paparan senarai lalai mereka?
- Adakah ada pemberitahuan atau amaran apabila lead melepasi ambang?
- Tanya tiga rep: "Apa yang skor lead tinggi bermakna untuk aliran kerja harian Anda?" Jika jawapannya tidak jelas, skor tidak mengubah tingkah laku.
Gelung maklum balas
- Adakah ada pencetus latihan semula yang formal? Siapa yang memilikinya?
- Adakah medan closed-won dan closed-lost wajib dalam CRM Anda, dengan definisi yang konsisten?
- Bagaimana Anda tahu jika ketepatan model sedang menurun?
Kalibrasi ambang
- Berapa peratus volum masuk Anda yang mendapat skor "panas"? Jika melebihi 25-30%, ambang mungkin terlalu rendah.
- Adakah Anda mempunyai data hasil skor-ke-penukaran untuk mengesahkan ambang semasa Anda?
Kebolehjelasan
- Bolehkah rep melihat apa yang mendorong skor?
- Apabila rep tidak bersetuju dengan skor, adakah mereka tahu input mana yang perlu dicabar?
Integrasi niat
- Adakah data masa/niat disertakan dalam scoring, atau hanya kesesuaian firmografi?
- Adakah Anda mempunyai sebarang isyarat tingkah laku pihak pertama dalam model scoring (paparan halaman, penglibatan e-mel, permintaan demo)?
Jika Anda menjawab "tidak" kepada lebih daripada tiga soalan ini, sistem scoring Anda mempunyai sekurang-kurangnya satu masalah berstruktur. Artikel gambaran keseluruhan AI lead scoring meliputi bagaimana model yang berfungsi dengan baik dibina. Artikel ini meliputi sebab model tersebut gagal di lapangan.
Failure modes: when AI sales ops backfires memperluaskan analisis ini melampaui scoring ke tindanan RevOps yang lebih luas.
Ringkasan jujur
Perangkap AI lead scoring semuanya boleh diperbaiki. Tetapi kebanyakan pembetulan adalah operasi, bukan teknikal. Anda tidak memerlukan vendor yang berbeza untuk kebanyakan ini. Anda memerlukan kadaran latihan semula, aliran kerja pemaparan skor, proses kalibrasi ambang, dan lapisan kebolehjelasan.
Mod kegagalan yang paling berbahaya juga yang paling biasa: model yang berjalan tanpa batas tanpa gelung maklum balas, secara perlahan menyimpang dari realiti sementara semua orang menganggap ia masih berfungsi kerana antara muka kelihatan tidak berubah. Scoring tanpa latihan semula adalah seperti menavigasi dengan peta dari tahun lalu. Medan mungkin sudah berubah; peta tidak mengetahuinya lagi.
Soalan Lazim
Mengapa kebanyakan pelancaran AI lead scoring gagal secara senyap?
Kegagalan senyap berlaku kerana tiada mesej ralat atau ranap sistem apabila model scoring berhenti berguna. Model terus menghasilkan skor, medan CRM terus dikemas kini, dan vendor terus membil. Tetapi rep secara beransur-ansur berhenti bertindak atas skor, dan tiada siapa yang secara rasmi merekodkan bahawa sistem telah berhenti berfungsi. Kegagalan dikaitkan dengan kualiti lead atau prestasi rep daripada masalah berstruktur yang mendorongnya: data latihan yang berat sebelah, tiada kadaran latihan semula, ambang yang salah kalibrasi, atau skor yang tersembunyi dalam medan CRM yang tidak dilihat sesiapa.
Apakah mod kegagalan AI lead scoring yang paling kritikal?
Kegagalan gelung maklum balas, di mana model berjalan selama-lamanya tanpa latihan semula pada hasil yang ditutup baru, adalah yang paling penting secara struktur. Tidak seperti mod kegagalan lain yang merosot secara beransur-ansur, tiada gelung maklum balas menyebabkan kemerosotan ketepatan yang berganda. Model yang dilatih pada S1 yang tidak pernah dilatih semula telah melepasi setiap peralihan pasaran, perubahan ICP, dan penambahan saluran sejak itu. NIST AI Risk Management Framework mengklasifikasikan pemantauan berterusan sebagai keperluan kebolehpercayaan teras, bukan penyelenggaraan pilihan.
Bagaimana Anda tahu jika ambang AI lead scoring Anda salah kalibrasi?
Tiga isyarat menunjukkan masalah ambang: lebih daripada 25-30% daripada jumlah volum masuk mendapat skor "panas" (ambang terlalu rendah), rep mengadu lead panas tidak bertukar (masalah yang sama), atau rep secara manual menyusun semula lead berdasarkan naluri daripada skor (ambang telah kehilangan kredibiliti). Perbaiki dengan menarik 6-12 bulan lead berskor dengan hasil, mencari kumpulan skor di mana kadar penukaran meningkat dengan bermakna, dan menetapkan ambang lead panas pada kumpulan tersebut.
Apa yang harus dilihat rep apabila mereka melihat skor lead?
Pengalaman pemaparan skor yang lengkap menunjukkan: skor itu sendiri (contoh: 82/100), tiga faktor teratas yang mendorong skor (contoh: saiz syarikat: pertengahan pasaran, industri: perkhidmatan kewangan, pembiayaan terkini: Siri B), sebarang isyarat niat yang dikesan, dan apa yang tiada yang akan meningkatkan skor (contoh: tiada kenalan pembuat keputusan yang disahkan). Tanpa konteks ini, rep tidak dapat mencabar input yang salah, tidak dapat membina intuisi tentang maksud skor tinggi, dan tidak dapat mempercayai sistem apabila mereka melihat kesilapan individu.
Seberapa kerap model AI lead scoring harus dilatih semula?
Suku tahunan adalah minimum; bulanan adalah lebih baik untuk pasukan yang berkembang pesat atau mereka yang mengalih ICP. Pencetus latihan semula di luar kitaran termasuk pelancaran produk baru, perubahan ICP yang ketara, saluran baru utama, atau perubahan material dalam pengagihan saiz urusan. Mekanisme latihan semula memerlukan bahawa hasil closed-won dan closed-lost dilog secara konsisten dengan medan yang digunakan model sebagai ciri. Tanpa disiplin pengelogan itu, tiada data latihan baru untuk dimasukkan semula ke dalam model.
Apakah perbezaan antara fit scoring dan intent scoring?
Fit scoring mengukur seberapa baik syarikat sepadan dengan ICP Anda pada dimensi firmografi: saiz syarikat, industri, tech stack, julat hasil. Intent scoring mengukur sama ada syarikat sedang aktif menyelidik dan membeli sekarang: data pihak ketiga dari Bombora atau 6sense yang menunjukkan penyelidikan kategori, ditambah isyarat pihak pertama seperti lawatan halaman harga dan paparan perbandingan ciri. Scoring kesesuaian sahaja menghasilkan senarai pelanggan berpotensi terbaik Anda, kebanyakannya tidak dalam mod pembelian hari ini. Menggabungkan kesesuaian dan niat menunjukkan siapa yang terbaik DAN paling bersedia. Lead dengan kesesuaian-60/niat-tinggi sering bertukar lebih baik berbanding lead dengan kesesuaian-90/tiada-niat.
Mengapa rep berhenti mempercayai skor AI lead selepas beberapa minggu?
Kepercayaan runtuh apabila rep melihat skor tinggi pada lead yang mereka tahu adalah salah, tanpa penjelasan mengapa lead mendapat skor tinggi. Rep yang melihat syarikat berkualiti jelas rendah dengan skor 85, dan tidak dapat melihat apa yang mendorong skor itu, menyimpulkan keseluruhan sistem tidak boleh dipercayai. Scoring kotak hitam menghancurkan penggunaan kerana rep tidak dapat membezakan antara model yang genuinely baik yang membuat kesilapan jarang dan model yang rosak yang menghasilkan nombor rawak. Penjelasan skor menghalang ini: dengan konteks, rep boleh mencabar input tertentu daripada membuang sistem.
Baca Lanjut

Co-Founder, Rework.com
On this page
- Perangkap 1: Latihan pada data sejarah yang berat sebelah
- The 5 Lead Scoring Failure Modes
- Perangkap 2: Skor tidak dipaparkan di mana rep bekerja
- Perangkap 3: Tiada gelung maklum balas
- Perangkap 4: Terlalu banyak ciri input, terlalu sedikit data
- Perangkap 5: Ketidakpadanan ambang skor
- Perangkap 6: Ketidakpercayaan rep akibat skor yang tidak dapat dijelaskan
- Perangkap 7: Mengabaikan isyarat masa (kesesuaian tanpa niat)
- Senarai semak audit: soalan diagnostik untuk pelancaran scoring Anda
- Ringkasan jujur
- Baca Lanjut