Erros Comuns no AI Lead Scoring (E Como Corrigi-los)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A maioria dos deployments de AI lead scoring falha silenciosamente. Não há travamento do sistema, nenhuma mensagem de erro e nenhum momento em que alguém declare que está quebrado. O modelo roda, as pontuações aparecem no Customer Relationship Management (CRM), os reps as olham por algumas semanas e então param de usá-las. A ferramenta permanece no contrato. As pontuações continuam sendo atualizadas. Seis meses depois, quando alguém pergunta se o lead scoring está funcionando, ninguém realmente sabe.
A falha silenciosa é o pior tipo: é cara, é invisível e é atribuída à causa errada. "Nossos leads estão com qualidade mais baixa neste trimestre." "Os reps precisam de melhor treinamento em qualificação." "Talvez o modelo precise de mais dados." Tudo isso pode ser verdade. Mas frequentemente o problema mais profundo é estrutural, não um problema de volume de dados ou de performance do rep.
Este artigo é um diagnóstico para líderes de ops que fizeram o deployment de AI lead scoring e não estão vendo a mudança de comportamento esperada. As falhas abaixo são os padrões mais comuns, e a maioria delas é corrigível com mudanças operacionais, não com troca de fornecedor.
Erro 1: Treinamento com dados históricos enviesados

O problema: Seu modelo treinou em deals fechados do passado, e seus deals passados super-representam um segmento. O modelo aprendeu a pontuar esse segmento alto. Mas esse segmento pode não representar suas melhores contas hoje.
Como isso se parece na prática: Uma empresa SaaS treinou seu modelo de lead scoring em três anos de deals fechados. A maioria desses deals era SMB, porque esse era seu mercado principal três anos atrás. Eles migraram para o upmarket desde então. O modelo continua pontuando leads SMB alto e leads enterprise baixo, mesmo que o mandato da equipe de vendas seja enterprise. A liderança de vendas acha que o scoring está "ao contrário." Não está ao contrário; ele aprendeu o passado com precisão. O passado é que está errado para a estratégia de hoje.
A correção: Antes de retreinar, faça uma auditoria de deals fechados. Agrupe seus deals históricos por tamanho de deal, setor e segmento de Ideal Customer Profile (ICP). Se seu mercado-alvo atual não está proporcionalmente representado no conjunto de treinamento, seu modelo precisa ou de retreinamento em um subconjunto filtrado e representativo, ou de uma camada de scoring ponderada por ICP por cima. É por isso que o AI lead scoring enfatiza que a arquitetura do modelo é tão boa quanto os labels de treinamento. Os labels vêm primeiro.
Dados Relevantes: Taxas de Falha de AI Lead Scoring
- O NIST AI Risk Management Framework identifica monitoramento e medição contínuos como um requisito central de confiabilidade para sistemas de AI deployados; um modelo de scoring sem cadência de retreinamento viola esse requisito por design
- Modelos treinados com menos de 100 resultados de deals fechados produzem output estatisticamente indistinguível de atribuição aleatória; abaixo de 200, a confiabilidade do modelo é marginal
- Estudos de correlação pontuação-para-conversão mostram consistentemente que 25 a 30% de todos os leads inbound pontuando como "quentes" é o limiar onde a miscalibração do limiar começa a degradar a confiança do rep; acima de 30%, a adoção tipicamente colapsa dentro de 60 dias
Os 5 Modos de Falha de Lead Scoring
Os 5 Modos de Falha de Lead Scoring é um framework de diagnóstico para deployments de scoring com AI que parecem estar rodando mas não estão mudando o comportamento dos reps. Os cinco modos são: (1) Dados de Treinamento Enviesados, onde os ganhos históricos super-representam um segmento de mercado do qual a equipe se afastou; (2) Falha de Surfaceamento de Pontuação, onde as pontuações existem em um campo do CRM que os reps nunca veem; (3) Sem Loop de Feedback, onde o modelo nunca retreina e a precisão decai ao longo do tempo; (4) Miscalibração de Limiar, onde muitos leads pontuam como "quentes" e a designação se torna sem sentido; e (5) Lacuna de Intent, onde o scoring baseado em fit identifica contas que correspondem ao ICP mas perde sinais de compra ativos. Cada modo tem uma correção distinta. A maioria das falhas envolve mais de um modo simultaneamente.
Erro 2: Pontuações não surfaceadas onde os reps trabalham
O problema: Uma pontuação enterrada em um campo do CRM que está três cliques de profundidade não produz nenhuma mudança de comportamento. Reps não mudam workflows para encontrar informações; as informações precisam encontrá-los onde eles já estão.
Como isso se parece na prática: A Revenue Operations (RevOps) configura um campo personalizado chamado "AI Lead Score" no Salesforce. Está na página de detalhes do registro de lead, abaixo do fold, ao lado de outros 40 campos. Ninguém muda a visualização de lista padrão. Nenhuma notificação dispara quando uma pontuação atualiza. Os reps aprendem a ignorá-la porque não interrompe seu workflow existente.
A correção: Surfaceamento de pontuação é um problema de design de workflow, não apenas um problema de dados. A pontuação precisa aparecer na visualização de lista de leads (classificável), como gatilho de notificação (alerta quando um lead cruza um limiar) e no resumo diário ou fila de tarefas do rep. Se você estiver usando uma plataforma de sales engagement como Outreach ou Salesloft, a pontuação deve controlar quais leads entram em quais sequências. O teste: se um rep pudesse passar todo o seu dia de trabalho sem ver a pontuação, ela não está surfaceada. Este é um dos erros mais fáceis de corrigir e um dos mais frequentemente perdidos.
Erro 3: Sem loop de feedback
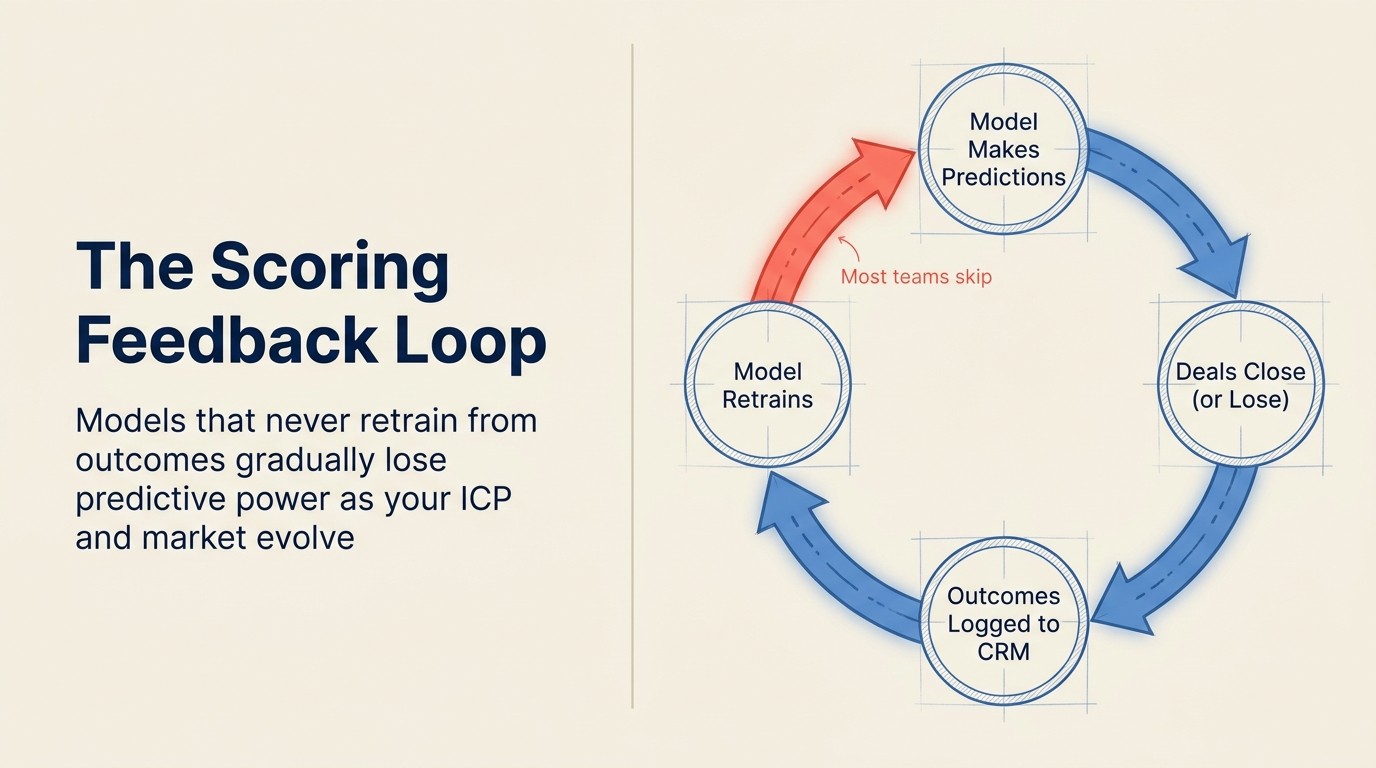
O problema: O modelo pontua em dados de treinamento estáticos indefinidamente, sem mecanismo para retreinar em novos resultados de deals fechados e perdidos. A cada trimestre o modelo deriva mais da realidade atual, mas ninguém percebe porque as pontuações continuam atualizando e a interface parece igual.
Este é o modo de falha mais estruturalmente importante. Diferente dos outros, que degradam gradualmente, nenhum loop de feedback causa decaimento de precisão composto. Um modelo treinado no 1T do ano passado e nunca atualizado perdeu quatro trimestres de resultados de deals que poderiam ter aguçado suas previsões. O NIST AI Risk Management Framework especificamente identifica monitoramento e medição contínuos como um requisito central de confiabilidade para qualquer sistema de AI deployado, não uma tarefa única de configuração.
Como isso se parece na prática: Uma empresa faz o deployment do HubSpot Predictive Lead Scoring em fevereiro. Ele treina em 18 meses de deals históricos. Em abril, eles lançam uma nova linha de produto que muda seu perfil de comprador. Em junho, eles contratam 5 novos Account Executives (AEs) que começam a fechar um perfil de deal diferente. Em setembro, um gestor percebe que as pontuações não se correlacionam com seus melhores deals. O modelo estava bom em fevereiro. Ele vem degradando desde abril. Ninguém disparou um retreinamento porque o sistema não alerta sobre deriva.
A correção: Defina uma cadência de retreinamento antes de fazer o launch, não depois de notar o problema. Trimestral é o mínimo para a maioria dos negócios; mensal é melhor para equipes de crescimento rápido com ICPs em mudança. Os eventos gatilho para um retreinamento fora do ciclo: lançamento de novo produto, mudança significativa de ICP, adição de canal importante ou mudança no motion de vendas. O mecanismo: certifique-se de que seu CRM está registrando deals fechados ganhos e perdidos de forma consistente com os campos que seu modelo usa como features. Sem essa disciplina de registro, você não tem novos dados de treinamento para alimentar de volta.
Isso também é por que as explicações de pontuação legíveis por humanos (Erro 6) importam para o feedback. Se um rep pode ver que um lead pontuou alto por causa de "tamanho da empresa + tech stack + match de setor", ele pode sinalizar quando essa lógica não reflete mais o que está convertendo. Reps são seu sistema de aviso antecipado para deriva do modelo, mas somente se entenderem a lógica de scoring.
Erro 4: Muitos features de entrada, dados insuficientes
O problema: Overfitting. O modelo usa 40 features de entrada para pontuar leads de um conjunto de treinamento de 300 deals históricos. Ele memoriza padrões nos dados de treinamento em vez de generalizar para novos leads. Parece impressionante na avaliação (alta precisão nos dados de treinamento) e falha em leads ao vivo.
Como isso se parece na prática: Um analista de RevOps constrói um modelo personalizado de lead scoring em Python usando 45 features do Salesforce (todos os campos em que conseguiram pensar: visualizações de página, aberturas de e-mail, nível de cargo, idade da empresa, seguidores do LinkedIn, status de funding, etc.). A avaliação do modelo mostra 89% de precisão. Quando deployado, os reps percebem que o modelo dá pontuações acima de 90 para leads que nunca se engajam e pontuações baixas para leads claramente qualificados. O modelo memorizou o conjunto de treinamento. Não tem valor preditivo em dados novos.
A correção: Para equipes com menos de 1.000 resultados históricos, use um modelo mais simples com menos features. 5 a 10 features de alto sinal, consistentemente preenchidas, superam 45 features esparsas ou inconsistentes. As features clássicas de alto valor: tamanho da empresa, match de setor, senioridade do cargo, fonte do formulário (qual página/canal) e sinais de uso do produto para leads de expansão. Comece simples. Adicione features conforme o volume de dados cresce.
Para equipes com dados históricos limitados, começar com o modelo pré-treinado de um fornecedor (Salesforce Einstein, HubSpot Predictive Lead Scoring) e colocar seus critérios de ICP por cima é frequentemente mais confiável do que construir do zero.
Erro 5: Miscalibração do limiar de pontuação
O problema: O modelo gera probabilidades, mas os limiares de roteamento são definidos incorretamente. Um limiar muito baixo inunda os reps com leads "quentes" que não são realmente quentes. Um limiar muito alto significa que leads qualificados nunca escalam para atenção humana.
Como isso se parece na prática: Uma equipe define seu limiar de "lead quente" em 40 de 100. Seu modelo de scoring foi calibrado de forma que 40 representa 40% de probabilidade de conversão. Com um limiar em 40, 60% do inbound deles é sinalizado como quente e roteado para Sales Development Representatives (SDRs) sênior. Esses SDRs estão sobrecarregados. Sua taxa de contato em leads "quentes" parece terrível porque há leads demais para trabalhar adequadamente. O problema não é o modelo de scoring; é o limiar.
A correção: A definição do limiar deve ser calibrada em relação às taxas de conversão históricas por faixa de pontuação, não definida arbitrariamente. Puxe seus últimos 6 a 12 meses de leads pontuados e resultados de conversão (se você os tiver). Encontre a faixa de pontuação onde a taxa de conversão aumenta significativamente. Esse é o seu limiar de roteamento. Se você está configurando scoring pela primeira vez sem leads pontuados historicamente, comece com um limiar alto (70+) que mantém o volume de leads quentes gerenciável e ajuste para baixo ao longo do tempo conforme acumula dados de pontuação para resultado.
A questão do limiar também se estende aos tiers de roteamento. Defina pelo menos três tiers de roteamento: alta prioridade (escalada humana, SLA rápido), padrão (fila normal de SDR) e nurture (sequência automatizada, sem contato de rep até que um sinal de intent dispare). Os limiares entre esses tiers precisam ser ajustados, não assumidos. E 25 a 30% dos leads pontuando como "quentes" é o teto de diagnóstico: se você estiver acima disso, abaixe o limiar antes que os reps parem de confiar completamente no sistema.
Erro 6: Desconfiança dos reps por pontuações inexplicáveis
O problema: O scoring de caixa preta perde a adoção dos reps. Um rep que não entende por que um lead pontuou 87 não agirá com base nele de forma consistente. E quando o modelo comete um erro que o rep consegue identificar (um lead claramente de baixa qualidade com pontuação 90), todo o sistema de scoring perde credibilidade na mente daquele rep.
Como isso se parece na prática: Uma empresa faz o deployment de um modelo de scoring que usa 15 sinais ponderados. A interface mostra aos reps um único número: "Lead Score: 82." Um rep olha o lead, vê uma startup de 3 pessoas de um tipo de empresa que raramente converte para eles e ignora o 82. Na semana seguinte, ele ignora um 91. Em dois meses, os reps descartaram mentalmente o scoring como não confiável. O modelo pode ter sido preciso em média, mas erros individuais sem explicação destruíram a adoção.
A correção: As explicações de pontuação devem aparecer no ponto de uso. Não apenas "Score: 82" mas "Score: 82 porque tamanho da empresa (médio porte), setor (serviços financeiros) e rodada de funding recente correspondem ao seu ICP. Sinais de intent: moderado. Faltando: contato confirmado de tomador de decisão." Com esse contexto, mesmo quando um rep discorda de uma pontuação, ele entende o raciocínio. Ele pode contestar o input correto (talvez a classificação de "médio porte" esteja errada porque essa empresa contraiu recentemente) em vez de descartar toda a pontuação.
Algumas ferramentas oferecem isso nativamente (fatores de pontuação da Salesforce Einstein, detalhamento de pontuação do HubSpot). Modelos personalizados precisam disso construído deliberadamente.
Erro 7: Ignorar sinais de timing (fit sem intent)
O problema: O scoring baseado em fit diz que uma empresa corresponde ao seu ICP. Não diz que ela está comprando ativamente. Uma empresa de fit perfeito que não está no mercado pontua alto mas converte mal. Uma empresa de fit médio em avaliação ativa pontua médio mas converte melhor. Intent mais fit juntos superam qualquer um isolado.
Como isso se parece na prática: O modelo de uma equipe pontua contas inteiramente em fit firmográfico: tamanho da empresa, setor, tech stack, faixa de receita. Seus leads "Tier 1" são consistentemente contas bem correspondidas. Mas os reps reclamam que não conseguem fazer esses leads se engajarem. São matches de ICP frios, não compradores quentes. Enquanto isso, dados de intent (Bombora, 6sense) mostram várias contas de tier médio pesquisando ativamente a categoria da empresa. Essas contas nunca surfaceiam porque não pontuaram alto em fit firmográfico.
A correção: Adicione sinais de timing como camada de scoring. Third-party intent (Bombora, 6sense, Demandbase) diz quem está pesquisando ativamente agora. Sinais first-party (visitas à página de preços, leituras de documentação, visualizações de comparação de recursos) dizem quais enviadores de formulário estão em modo de avaliação ativa. Um lead que pontua 60 em fit mas tem altos sinais de intent deve ser roteado de forma diferente de um lead que pontua 90 em fit mas não mostra intent. O modelo combinado captura compradores que você perderia com qualquer sinal isolado. O artigo sobre síntese de sinais de buyer intent com AI mostra como combinar esses sinais na prática.
Análise Rework: O padrão de falha silenciosa é o mais caro que vemos nos deployments de AI lead scoring. O modelo está tecnicamente rodando, o fornecedor está tecnicamente sendo pago, mas os reps pararam de confiar nas pontuações três meses atrás e ninguém reconheceu isso oficialmente. O indicador é uma pergunta de pesquisa: "Você olha a pontuação de AI lead antes de decidir quais leads trabalhar primeiro?" Quando menos de 40% dos reps dizem sim, o sistema de scoring é decorativo. A correção quase nunca requer um novo fornecedor. Requer resolver qual dos cinco modos de falha causou a erosão da confiança, geralmente miscalibração de limiar ou falha de surfaceamento de pontuação, os dois problemas mais operacionalmente corrigíveis da lista.
Checklist de auditoria: perguntas de diagnóstico para seu deployment de scoring
Use estas para diagnosticar quais erros afetam seu sistema atual:
Dados de treinamento
- Quando o modelo foi retreinado pela última vez? Há uma cadência agendada?
- Que porcentagem dos seus deals fechados atuais vem de segmentos que eram proeminentes nos dados de treinamento?
- Os deals fechados perdidos estão incluídos no conjunto de treinamento, ou apenas os fechados ganhos?
Surfaceamento e adoção
- Um rep consegue ver a pontuação sem sair de sua visualização de lista padrão?
- Há uma notificação ou alerta quando um lead cruza um limiar?
- Pergunte a três reps: "O que uma pontuação de lead alta significa para seu workflow diário?" Se as respostas forem vagas, as pontuações não estão mudando o comportamento.
Loop de feedback
- Há um gatilho formal de retreinamento? Quem é o responsável?
- Os campos de deals fechados ganhos e perdidos são obrigatórios no seu CRM, com definições consistentes?
- Como você saberia se a precisão do modelo estivesse declinando?
Calibração de limiar
- Que porcentagem do seu volume inbound pontua como "quente"? Se estiver acima de 25 a 30%, o limiar provavelmente está muito baixo.
- Você tem dados de resultado de pontuação-para-conversão para validar seus limiares atuais?
Explicabilidade
- Um rep consegue ver o que impulsionou uma pontuação?
- Quando um rep discorda de uma pontuação, ele sabe qual input contestar?
Integração de intent
- Os dados de timing/intent estão incluídos no scoring, ou apenas o fit firmográfico?
- Você tem sinais comportamentais first-party no modelo de scoring (visualizações de página, engajamento em e-mail, solicitação de demo)?
Se você respondeu "não" para mais de três desses, seu sistema de scoring tem pelo menos um problema estrutural. A visão geral do AI lead scoring cobre como um modelo bem funcionando é construído. Este artigo cobre por que esses modelos falham em campo.
Modos de falha: quando o AI sales ops sai pela culatra estende essa análise além do scoring para o stack mais amplo de RevOps.
O resumo honesto
Os erros de AI lead scoring são todos corrigíveis. Mas a maioria das correções é operacional, não técnica. Você não precisa de um fornecedor diferente para a maioria desses problemas. Você precisa de uma cadência de retreinamento, um workflow de surfaceamento de pontuação, um processo de calibração de limiar e uma camada de explicabilidade.
O modo de falha mais perigoso é também o mais comum: um modelo que roda indefinidamente sem loop de feedback, divergindo lentamente da realidade enquanto todos assumem que ainda está funcionando porque a interface parece inalterada. Scoring sem retreinamento é como navegar com um mapa do ano passado. O terreno pode ter mudado; o mapa não sabe disso ainda.
Perguntas Frequentes
Por que a maioria dos deployments de AI lead scoring falha silenciosamente?
A falha silenciosa acontece porque não há mensagem de erro ou travamento do sistema quando um modelo de scoring para de ser útil. O modelo continua produzindo pontuações, o campo do CRM continua atualizando e o fornecedor continua faturando. Mas os reps gradualmente param de agir com base nas pontuações, e ninguém registra oficialmente que o sistema parou de funcionar. A falha é atribuída à qualidade dos leads ou à performance dos reps em vez dos problemas estruturais que a impulsionam: dados de treinamento enviesados, sem cadência de retreinamento, limiares miscalibrados ou pontuações enterradas em um campo do CRM que ninguém vê.
Qual é o modo de falha de AI lead scoring mais crítico?
A falha do loop de feedback, onde o modelo roda indefinidamente sem retreinar em novos resultados fechados, é a mais estruturalmente importante. Diferente de outros modos de falha que degradam gradualmente, nenhum loop de feedback causa decaimento de precisão composto. Um modelo treinado no 1T que nunca retreina perdeu todas as mudanças de mercado, mudanças de ICP e adições de canal desde então. O NIST AI Risk Management Framework classifica o monitoramento contínuo como um requisito central de confiabilidade, não manutenção opcional.
Como você sabe se os limiares do seu AI lead scoring estão miscalibrados?
Três sinais indicam problemas de limiar: mais de 25 a 30% do volume inbound total pontua como "quente" (limiar muito baixo), reps reclamam que leads quentes não estão convertendo (mesmo problema), ou reps estão re-priorizando leads manualmente com base no instinto em vez da pontuação (o limiar perdeu credibilidade). Corrija puxando os últimos 6 a 12 meses de leads pontuados com resultados, encontrando a faixa de pontuação onde a taxa de conversão aumenta significativamente e definindo o limiar de lead quente nessa faixa.
O que um rep deve conseguir ver quando olha uma pontuação de lead?
Uma experiência completa de surfaceamento de pontuação mostra: a própria pontuação (por exemplo, 82/100), os três principais fatores que impulsionaram a pontuação (por exemplo, tamanho da empresa: médio porte, setor: serviços financeiros, funding recente: Série B), quaisquer sinais de intent detectados e o que está faltando que melhoraria a pontuação (por exemplo, sem contato confirmado de tomador de decisão). Sem esse contexto, os reps não conseguem contestar inputs errados, não conseguem desenvolver intuição sobre o que pontuações altas significam e não conseguem confiar no sistema quando veem erros individuais.
Com que frequência um modelo de AI lead scoring deve ser retreinado?
Trimestral é o mínimo; mensal é melhor para equipes de crescimento rápido ou aquelas mudando de ICP. Gatilhos de retreinamento fora do ciclo incluem lançamentos de novos produtos, mudanças significativas de ICP, novos canais principais ou mudanças materiais na distribuição de tamanho de deal. O mecanismo de retreinamento requer que resultados de deals fechados ganhos e perdidos sejam registrados consistentemente com os campos que o modelo usa como features. Sem essa disciplina de registro, não há novos dados de treinamento para alimentar de volta no modelo.
Qual é a diferença entre scoring de fit e scoring de intent?
O scoring de fit mede o quanto uma empresa corresponde ao seu ICP em dimensões firmográficas: tamanho da empresa, setor, tech stack, faixa de receita. O scoring de intent mede se uma empresa está ativamente pesquisando e comprando agora: dados de terceiros do Bombora ou 6sense mostrando pesquisa de categoria, mais sinais first-party como visitas à página de preços e visualizações de comparação de recursos. O scoring somente de fit produz uma lista das suas melhores clientes potenciais, a maioria das quais não está em modo de compra hoje. Combinar fit e intent surfaceia quem é o melhor E mais pronto. Um lead 60-fit/alto-intent frequentemente converte melhor do que um lead 90-fit/sem-intent.
Por que os reps param de confiar nas AI lead scores após algumas semanas?
A confiança colapsa quando os reps veem pontuações altas em leads que eles sabem estar errados, sem explicação sobre por que o lead pontuou alto. Um rep que vê uma empresa claramente de baixa qualidade com pontuação 85, e não consegue ver o que impulsionou essa pontuação, conclui que todo o sistema é não confiável. O scoring de caixa preta destrói a adoção porque os reps não conseguem distinguir entre um modelo genuinamente bom cometendo um erro raro e um modelo quebrado produzindo números aleatórios. As explicações de pontuação previnem isso: com contexto, os reps podem contestar um input específico em vez de descartar o sistema.
Saiba Mais
- AI Lead Scoring Além de Modelos Baseados em Regras
- Roteamento Automatizado de Leads: Round Robin vs. AI
- Triagem de Leads Inbound em Escala
- Síntese de Sinais de Buyer Intent com AI
- Modos de Falha: Quando o AI Sales Ops Sai pela Culatra
- Scoring e Routing: Triagem de AI em Escala
- Quando Padrões de AI Se Tornam Dívida Técnica

Co-Founder, Rework.com
On this page
- Erro 1: Treinamento com dados históricos enviesados
- Os 5 Modos de Falha de Lead Scoring
- Erro 2: Pontuações não surfaceadas onde os reps trabalham
- Erro 3: Sem loop de feedback
- Erro 4: Muitos features de entrada, dados insuficientes
- Erro 5: Miscalibração do limiar de pontuação
- Erro 6: Desconfiança dos reps por pontuações inexplicáveis
- Erro 7: Ignorar sinais de timing (fit sem intent)
- Checklist de auditoria: perguntas de diagnóstico para seu deployment de scoring
- O resumo honesto
- Saiba Mais