AI Lead Scoringのよくある落とし穴(と修正方法)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ほとんどのAI Lead Scoring導入は静かに失敗する。システムクラッシュも、エラーメッセージも、「壊れた」と宣言する瞬間もない。モデルが動き、CRM (Customer Relationship Management) にスコアが表示され、担当者は数週間それを確認し、その後使わなくなる。ツールは契約に残り続ける。スコアは更新され続ける。6ヶ月後、誰かがLead Scoringが機能しているかと尋ねると、誰も本当のところはわからない。
静かな失敗が最も悪い種類だ。コストがかかり、見えにくく、原因の誤った特定につながる。「今四半期はリードの質が下がっているだけだ」「担当者には資格審査のトレーニングが必要だ」「モデルはもっとデータが必要かもしれない」これらはすべて真実かもしれない。しかし多くの場合、より深い問題は構造的なものであり、データ量の問題でも担当者のパフォーマンスの問題でもない。
この記事は、AI Lead Scoringを導入したが期待していた行動変容を見られないOpsリーダーのための診断ツールだ。以下の失敗は最も一般的なパターンであり、ほとんどはベンダーを変えるのではなくオペレーショナルな変更で修正できる。
落とし穴1: バイアスがかかった過去データでの学習

問題: モデルが過去のクローズ成立ディールで学習されており、その過去のクローズ成立ディールが1つのセグメントを過剰に代表している。モデルはそのセグメントを高く評価するよう学習した。しかし、そのセグメントは今日の実際のベストフィットアカウントを代表していない可能性がある。
実際にどう見えるか: あるSaaS企業が3年間のクローズディールでLeadスコアリングモデルを学習させた。それらのディールのほとんどはSMBで、3年前の主要市場だった。それ以来、企業はアップマーケットに移行した。モデルはSMBのLeadを高く、エンタープライズのLeadを低く評価し続ける。営業チームのマンデートはエンタープライズなのにだ。営業リーダーはスコアリングが「逆転している」と考える。逆転しているのではなく、過去を正確に学習しただけだ。問題は過去が今日の戦略に合っていないことだ。
修正方法: 再学習の前に、クローズ成立ディールの監査を行う。過去のクローズ成立ディールをディールサイズ、業種、ICP (Ideal Customer Profile) セグメントでグループ分けする。現在のターゲット市場が学習セットに比例して代表されていない場合、モデルは代表的なサブセットでの再学習か、その上のICP加重スコアリングレイヤーが必要だ。これが、AI Lead Scoringにおいてモデルアーキテクチャは学習ラベルと同程度にしか良くなれないと強調される理由だ。ラベルが先だ。
Key Facts: AI Lead Scoring失敗率
- NIST AI Risk Management Frameworkは、継続的なモニタリングと計測を導入されたAIシステムの中核的な信頼性要件として特定している。再学習サイクルのないスコアリングモデルは、設計上この要件に違反している
- クローズ成立が100件未満の結果で学習されたモデルは、統計的にランダムな割り当てと区別できない出力を生成する。200件未満では、モデルの信頼性はマージナルだ
- スコアとコンバージョンの相関研究では、全インバウンドLeadの25〜30%が「ホット」とスコアリングされるのが閾値のミスキャリブレーションが担当者の信頼を低下させ始める閾値だと示されている。30%を超えると、導入は通常60日以内に崩壊する
5つのLead Scoring失敗モード
5つのLead Scoring失敗モードは、実行されているが担当者の行動を変えていないAIスコアリング導入のための診断フレームワークだ。5つのモードは: (1) バイアスがかかった学習データ: 過去の成功実績がチームが離れたセグメントを過剰に代表している。(2) スコアのサーフェシング失敗: 担当者が見ないCRMフィールドにスコアが存在する。(3) フィードバックループなし: モデルが再学習せず、時間とともに精度が低下する。(4) 閾値のミスキャリブレーション: 「ホット」とスコアリングされるLeadが多すぎて、その指定が意味をなさなくなる。(5) Intentギャップ: フィットベースのスコアリングがICPに合致するアカウントを特定するが、能動的な購買シグナルを見逃す。各モードには異なる修正方法がある。ほとんどの失敗は複数のモードを同時に含む。
落とし穴2: 担当者が働く場所にスコアがサーフェスされていない
問題: 3クリック先の深いところにあるCRMフィールドに埋もれたスコアは、行動変容をゼロにする。担当者は情報を見つけるためにワークフローを変えない。情報が担当者のいる場所に届く必要がある。
実際にどう見えるか: RevOps (Revenue Operations) がSalesforceに "AI Lead Score" というカスタムフィールドを設定した。Leadレコードの詳細ページ、折り返し部分の下、他の40のフィールドの隣にある。デフォルトのリストビューは変更されない。スコアが更新されてもアラートは発火しない。担当者は既存のワークフローを中断しないため、それを無視するようになる。
修正方法: スコアのサーフェシングはデータの問題だけでなく、ワークフロー設計の問題だ。スコアはLeadリストビュー (ソート可能)、通知トリガー (Leadが閾値を超えたときのアラート)、担当者の日次ダイジェストやタスクキューに表示される必要がある。OutreachやSalesloftのようなSales Engagementプラットフォームを使っている場合、スコアはどのLeadがどのシーケンスに入るかをゲートすべきだ。テスト: 担当者がスコアを見ずに一日中作業できるなら、それはサーフェスされていない。これは修正が最も容易な落とし穴の一つでありながら、最も頻繁に見逃されるものの一つだ。
落とし穴3: フィードバックループなし
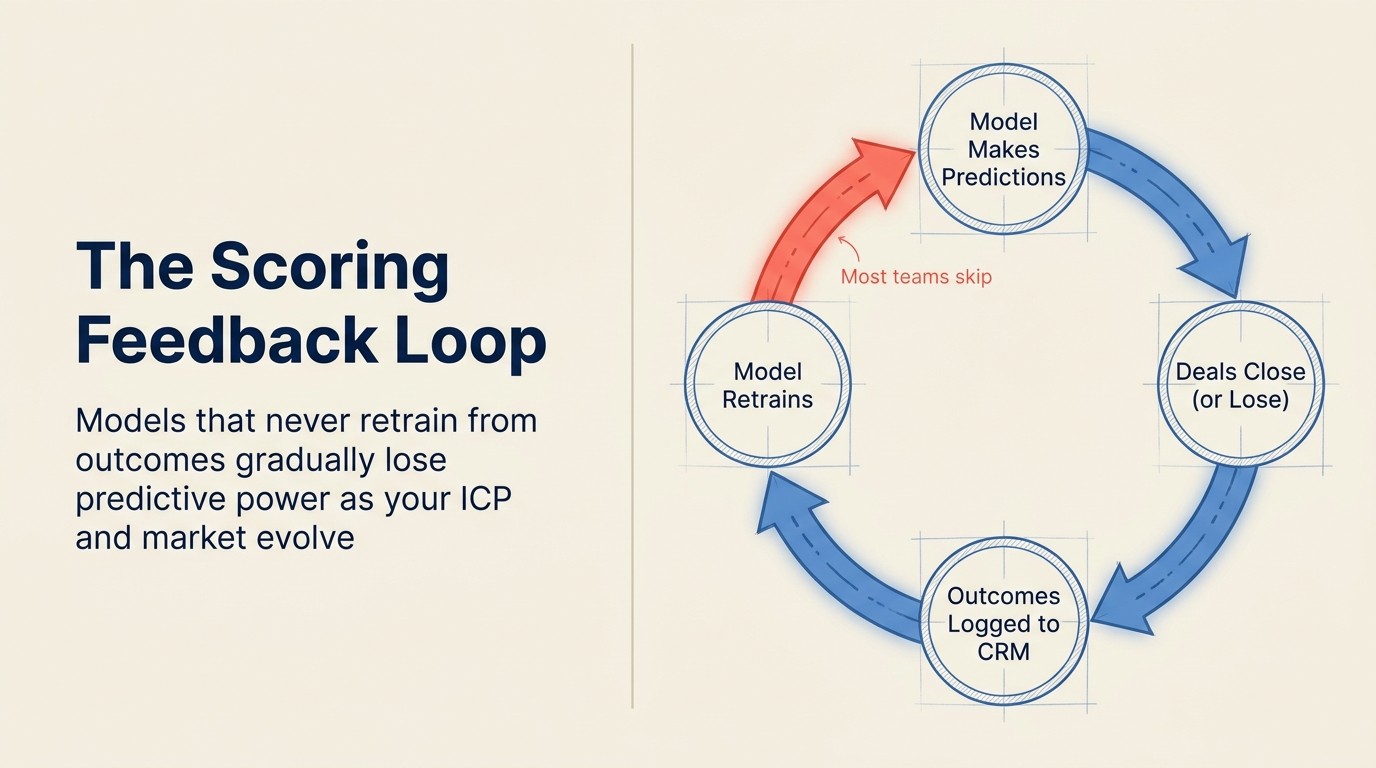
問題: モデルが静的な学習データで無期限にスコアリングを行い、新しいクローズ成立・クローズ失敗の結果で再学習するメカニズムがない。四半期ごとにモデルは現在の現実からさらに乖離していくが、スコアが更新され続けインターフェースが同じに見えるため、誰も気づかない。
これは構造的に最も重要な失敗モードだ。 他のモードが徐々に低下するのとは異なり、フィードバックループがないと精度が複利で低下する。昨年Q1に学習されて一度も更新されていないモデルは、予測を精度向上させることができたはずの4四半期分のディール結果を見逃している。NIST AI Risk Management Frameworkは特に、継続的なモニタリングと計測を一回限りのセットアップタスクではなく、導入されたAIシステムの中核的な信頼性要件として特定している。
実際にどう見えるか: ある企業が2月にHubSpot Predictive Lead Scoringを導入した。18ヶ月の過去のディールで学習した。4月に新しい製品ラインを立ち上げ、購買者プロフィールが変わった。6月に5人の新しいAE (Account Executive) を採用し、異なるディールプロフィールをクローズし始めた。9月、マネージャーはスコアがベストディールと相関していないことに気づく。モデルは2月時点では良好だった。4月以降は低下し続けていた。システムがドリフトをアラートしないため、誰も再学習をトリガーしなかった。
修正方法: 問題に気づいた後ではなく、立ち上げ前に再学習サイクルを定義する。ほとんどのビジネスでは四半期ごとが最低限。ICPが急速に変化しているチームには月次がより良い。サイクル外の再学習のトリガーイベント: 新製品立ち上げ、重要なICP変更、主要チャネル追加、または営業モーションの変更。仕組み: CRMがクローズ成立とクローズ失敗を、モデルが特徴として使うフィールドとともに一貫してログしていることを確認する。そのログの規律なしには、フィードバックする新しい学習データがない。
これは、人間が読めるスコア説明 (落とし穴6) がフィードバックにとって重要な理由でもある。担当者が「会社規模+技術スタック+業種マッチ」によってLeadが高くスコアリングされたことを確認できれば、そのロジックがもはやコンバージョンを反映していないときにフラグを立てられる。担当者はモデルドリフトの早期警戒システムだが、スコアリングロジックを理解している場合のみ機能する。
落とし穴4: 入力特徴が多すぎてデータが少なすぎる
問題: 過学習 (Overfitting)。モデルが300件の過去ディールの学習セットから40の入力特徴を使ってLeadをスコアリングする。新しいLeadに汎化するのではなく、学習データのパターンを記憶する。評価では印象的に見える (学習データで高精度) が、実際のLeadでは失敗する。
実際にどう見えるか: RevOpsアナリストがSalesforceの45の特徴 (思いつくあらゆるフィールド: ページビュー、メール開封、役職レベル、会社年齢、LinkedInフォロワー、資金調達状況など) を使ってPythonでカスタムLeadスコアリングモデルを構築した。モデル評価は89%の精度を示す。導入後、担当者はモデルがエンゲージしないLeadに90+のスコアを付け、明らかに適格なLeadに低いスコアを付けることに気づく。モデルは学習セットを記憶していた。新しいデータに対する予測価値はない。
修正方法: 過去の結果が1,000件未満のチームには、特徴の少ないシンプルなモデルを使う。一貫して入力されている5〜10の高シグナル特徴は、45の疎なまたは不一致な特徴を上回る。典型的な高価値特徴: 会社規模、業種マッチ、役職のシニオリティ、フォームソース (どのページ/チャネル)、拡大LeadのプロダクトUsageシグナル。少ない特徴から始め、データ量が増えるにつれて特徴を追加する。
過去のデータが限られているチームには、ベンダーの事前学習済みモデル (Salesforce Einstein、HubSpot Predictive Lead Scoring) から始め、その上にICP基準を重ねることが、ゼロから構築するよりも信頼性が高いことが多い。
落とし穴5: スコア閾値のミスマッチ
問題: モデルは確率を出力するが、ルーティング閾値が正しく設定されていない。閾値が低すぎると、実際にはホットではない「ホット」LeadがあふれてAEになる。閾値が高すぎると、適格なLeadが人間の注意に昇格しない。
実際にどう見えるか: あるチームが「ホットLead」閾値を100点満点の40点に設定した。スコアリングモデルは40が40%のコンバージョン確率を表すようにキャリブレートされていた。閾値を40にすると、インバウンドの60%がホットとフラグされ、シニアSDRにルーティングされた。そのSDRは圧倒された。「ホット」LeadのConnect率は悪く見える。処理するLeadが多すぎて適切に対応できないためだ。問題はスコアリングモデルではなく、閾値だ。
修正方法: 閾値設定は任意に設定するのではなく、スコアバンド別の過去のコンバージョン率でキャリブレートすべきだ。過去6〜12ヶ月のスコアリングされたLeadとコンバージョン結果 (あれば) を引き出す。コンバージョン率が有意に跳ね上がるスコアバンドを見つける。それがルーティング閾値だ。スコアリングされたLeadの過去の結果なしに初めてスコアリングを設定する場合は、ホットLeadの件数を管理可能に保つ高い閾値 (70+) から始め、スコアと結果のデータが蓄積されるにつれて調整する。
閾値の問題はルーティングティアにも及ぶ。少なくとも3つのルーティングティアを定義する: 高優先度 (人的エスカレーション、高速SLA)、標準 (通常のSDRキュー)、ナーチャー (自動シーケンス、インテントシグナルがトリガーされるまで担当者コンタクトなし)。これらのティア間の閾値はチューニングが必要で、仮定してはいけない。Leadの25〜30%が「ホット」とスコアリングされるのが診断上限だ。これを超えると、担当者がシステムを完全に信頼しなくなる前に閾値を下げること。
落とし穴6: 説明できないスコアによる担当者の不信感
問題: ブラックボックスのスコアリングは担当者の導入を失わせる。リードが87とスコアリングされた理由を理解しない担当者は、一貫してそれに基づいて行動しない。モデルが担当者が見抜けるエラーを犯したとき (明らかに低品質なLeadが90スコア)、その担当者の心の中でスコアリングシステム全体の信頼性が失われる。
実際にどう見えるか: ある企業が15の加重シグナルを使うスコアリングモデルを導入した。インターフェースには担当者に単一の数値が表示される: "Lead Score: 82." 担当者はLeadを見て、自分たちにはほとんどコンバートしないタイプの会社の3人規模のスタートアップを確認し、82を無視する。翌週、91も無視する。2ヶ月以内に、担当者はスコアリングを信頼できないとして精神的に切り捨てた。モデルは平均して正確だったかもしれないが、説明のない個別のエラーが導入を破壊した。
修正方法: スコアの説明は使用ポイントに表示されるべきだ。「スコア: 82」だけでなく「スコア: 82、理由: 会社規模 (中堅市場)、業種 (金融サービス)、最近の資金調達ラウンドがすべてICPに一致。インテントシグナル: 中程度。不足: 確認された意思決定者の連絡先」というかたちで。このコンテキストがあれば、担当者がスコアに同意しない場合でも、理由を理解できる。スコア全体を否定するのではなく、正しい入力に異議を唱えられる (「中堅市場」の分類が、この会社が最近縮小したため間違っているかもしれない)。
一部のツールはこれをネイティブに提供している (Salesforce EinsteinのScore Factors、HubSpotのScore Breakdown)。カスタムモデルには意図的に組み込む必要がある。
落とし穴7: タイミングシグナルを無視する (フィットのみでIntentなし)
問題: フィットベースのスコアリングはICPに合致する会社を教えてくれる。しかし、能動的に購買しているとは教えてくれない。完全にフィットする会社が市場にいなければ高くスコアリングされるが、コンバージョン率は低い。平均的なフィットの会社が能動的に評価中であれば、中程度のスコアだがコンバージョン率は高い。フィットとIntentを組み合わせると、どちら単独よりも優れた結果を生む。
実際にどう見えるか: あるチームのモデルは、ファーモグラフィックフィットのみでアカウントをスコアリングする: 会社規模、業種、技術スタック、売上範囲。「Tier 1」Leadは一貫して適格なアカウントだ。しかし担当者はこれらのLeadにエンゲージさせることができないと不満を言う。コールドなICPマッチであり、温かいバイヤーではない。その間、インテントデータ (Bombora、6sense) は、会社のカテゴリーを能動的に調査している複数の中ティアアカウントを示している。それらのアカウントはファーモグラフィックフィットで高くスコアリングされなかったため、浮上しない。
修正方法: タイミングシグナルをスコアリングレイヤーとして追加する。サードパーティIntentデータ (Bombora、6sense、Demandbase) は今まさに誰が能動的に調査しているかを教えてくれる。ファーストパーティシグナル (価格ページの閲覧、ドキュメントの閲覧、機能比較の確認) は、どのフォーム送信者が能動的な評価モードにいるかを教えてくれる。フィット60でIntentシグナルが高いLeadは、フィット90でIntentがないLeadとは異なるルーティングをすべきだ。組み合わせたモデルは、どちらのシグナル単独でも見逃すバイヤーを検出する。バイヤーIntentシグナルのAIによる統合では、これらのシグナルを実践的に重ねる方法を示している。
Rework分析: 静かな失敗パターンは、AI Lead Scoring導入で目にする最もコストのかかるものだ。モデルは技術的に動いており、ベンダーは技術的にまだ支払われているが、担当者は3ヶ月前にスコアを信頼するのをやめており、誰もそれを公式に認めていない。見分け方は調査の質問だ。「どのLeadを最初に対応するかを決める前にAI Lead Scoreを確認しますか?」40%未満の担当者がYesと答えるなら、スコアリングシステムは装飾品だ。修正には新しいベンダーがほとんど必要ない。信頼を侵食した5つの失敗モードのどれかを解決する必要がある。通常は閾値のミスキャリブレーションかスコアのサーフェシング失敗のどちらかで、リストの中で最もオペレーショナルに修正可能な2つの問題だ。
監査チェックリスト: スコアリング導入の診断質問
これらを使って、現在のシステムに影響している落とし穴を診断する:
学習データ
- モデルが最後に再学習されたのはいつか?スケジュールされたサイクルはあるか?
- 現在のクローズ成立ディールの何パーセントが学習データで目立っていたセグメントから来ているか?
- クローズ失敗ディールが学習セットに含まれているか、それともクローズ成立のみか?
サーフェシングと導入
- 担当者はデフォルトのリストビューを離れずにスコアを確認できるか?
- LeadがScoreの閾値を超えたときに通知やアラートはあるか?
- 3人の担当者に聞く: 「高いLead Scoreはあなたの日常ワークフローにとって何を意味しますか?」答えが曖昧なら、スコアは行動を変えていない。
フィードバックループ
- 公式な再学習のトリガーはあるか?誰がオーナーか?
- CRMでクローズ成立とクローズ失敗フィールドは必須になっており、一貫した定義があるか?
- モデルの精度が低下していることをどのように知ることができるか?
閾値キャリブレーション
- インバウンド件数の何パーセントが「ホット」とスコアリングされているか?25〜30%を超えているなら、閾値がおそらく低すぎる。
- 現在の閾値を検証するためのスコアとコンバージョン結果のデータはあるか?
説明可能性
- 担当者はスコアを駆動したものを確認できるか?
- 担当者がスコアに同意しない場合、どの入力に異議を唱えるべきかわかるか?
インテント統合
- タイミング/インテントデータがスコアリングに含まれているか、それともファーモグラフィックフィットのみか?
- スコアリングモデルにファーストパーティの行動シグナル (ページビュー、メールエンゲージメント、Demoリクエスト) はあるか?
これらのうち3つ以上に「いいえ」と答えた場合、スコアリングシステムには少なくとも1つの構造的な問題がある。AI Lead Scoringの概要では、適切に機能するモデルがどのように構築されるかを説明している。この記事は、それらのモデルが現場でなぜ失敗するかを説明している。
AIセールスオペレーションが逆効果になる場合のフェイルモードは、この分析をスコアリングを超えてRevOpsスタック全体に広げている。
まとめ
AI Lead Scoringの落とし穴はすべて修正可能だ。しかしほとんどの修正はオペレーショナルなものであり、技術的なものではない。これらのほとんどに別のベンダーは必要ない。再学習サイクル、スコアのサーフェシングワークフロー、閾値キャリブレーションのプロセス、説明可能性レイヤーが必要だ。
最も危険な失敗モードは最も一般的でもある。フィードバックループなしに無期限に動き続けるモデルが、静かに現実から乖離し続け、インターフェースが変わらないためまだ動いていると全員が思い込む。再学習なしのスコアリングは昨年の地図でナビゲートするようなものだ。地形は変わったかもしれない。地図はそれを知らない。
よくある質問
なぜほとんどのAI Lead Scoring導入は静かに失敗するのですか?
静かな失敗が起こるのは、スコアリングモデルが役に立たなくなってもエラーメッセージやシステムクラッシュがないためです。モデルはスコアを生成し続け、CRMフィールドは更新され続け、ベンダーは請求し続けます。しかし担当者は徐々にスコアに基づいて行動しなくなり、システムが機能しなくなったことを誰も公式に記録しません。失敗はそれを駆動する構造的な問題ではなく、リードの質や担当者のパフォーマンスに帰属されます。バイアスがかかった学習データ、再学習サイクルなし、ミスキャリブレートされた閾値、誰も見ないCRMフィールドに埋もれたスコアなどが原因です。
AI Lead Scoringの最も重要な失敗モードは何ですか?
フィードバックループの失敗、つまりモデルが新しいクローズ結果で再学習することなく無期限に動き続けることが、構造的に最も重要です。他の失敗モードが徐々に低下するのとは異なり、フィードバックループがないと精度が複利で低下します。Q1に学習されて一度も再学習しないモデルは、それ以降のすべての市場変化、ICP変更、チャネル追加を見逃しています。NIST AI Risk Management Frameworkは継続的なモニタリングをオプショナルなメンテナンスではなく、中核的な信頼性要件として分類しています。
AI Lead Scoringの閾値がミスキャリブレートされているかどうかをどのように知ることができますか?
3つのシグナルが閾値の問題を示します: 全インバウンド件数の25〜30%以上が「ホット」とスコアリングされている (閾値が低すぎる)、担当者がホットLeadがコンバートしていないと不満を言っている (同じ問題)、または担当者がスコアではなく直感に基づいてLeadを手動で再優先順位付けしている (閾値が信頼性を失った)。修正は、結果と共に過去6〜12ヶ月のスコアリングされたLeadを引き出し、コンバージョン率が有意に増加するスコアバンドを見つけ、ホットLead閾値をそのバンドに設定することだ。
担当者はLeadスコアを確認するときに何を見られるべきですか?
完全なスコアサーフェシング体験では、スコア自体 (例: 82/100)、スコアを駆動している上位3つの要因 (例: 会社規模: 中堅市場、業種: 金融サービス、最近の資金調達: Series B)、検出されたIntentシグナル、スコアを向上させる欠落情報 (例: 確認された意思決定者の連絡先なし) が表示されます。このコンテキストなしでは、担当者は間違った入力に異議を唱えることも、高いスコアが何を意味するかについての直感を構築することも、個別のエラーを見てもシステムを信頼することもできません。
AI Lead Scoringモデルはどのくらいの頻度で再学習すべきですか?
四半期ごとが最低限です。ICPが急速に変化しているチームや変わっているチームには月次がより良い。サイクル外の再学習トリガーには、新製品立ち上げ、重要なICP変更、主要な新チャネル、ディールサイズ分布の大幅な変化が含まれます。再学習のメカニズムには、クローズ成立とクローズ失敗の結果が、モデルが特徴として使うフィールドとともに一貫してログされていることが必要です。そのログの規律なしには、モデルにフィードバックする新しい学習データがありません。
フィットスコアリングとIntentスコアリングの違いは何ですか?
フィットスコアリングは会社がICPにどれだけ合致するかをファーモグラフィックな側面で計測します: 会社規模、業種、技術スタック、売上範囲。Intentスコアリングは会社が今まさに能動的に調査・購買しているかどうかを計測します: カテゴリー調査を示すBomboraや6senseからのサードパーティデータ、加えて価格ページの閲覧や機能比較の確認などのファーストパーティシグナル。フィットのみのスコアリングは最良の潜在的顧客のリストを生成しますが、そのほとんどは今日購買モードにありません。フィットとIntentを組み合わせると、最良で最も準備ができているものが浮かび上がります。フィット60/高Intentのリードは、フィット90/Intentなしのリードよりもしばしば良いコンバージョンをします。
なぜ担当者は数週間後にAI Lead Scoreを信頼しなくなるのですか?
信頼が崩壊するのは、担当者が間違っていることを知っているLeadに高いスコアが付いているのを見て、なぜそのLeadが高くスコアリングされたかの説明がない場合です。明らかに低品質な会社に85のスコアが付いていて、何がそのスコアを駆動したかを確認できない担当者は、システム全体が信頼できないと結論付けます。ブラックボックスのスコアリングは、担当者が稀なエラーを犯している本当に良いモデルとランダムな数値を生成している壊れたモデルを区別できないため、導入を破壊します。スコアの説明がこれを防ぎます: コンテキストがあれば、担当者はシステムを切り捨てるのではなく特定の入力に異議を唱えられます。
関連記事
