KI-generierter personalisierter Outreach in großem Maßstab

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
"Ich habe gesehen, dass Sie kürzlich auf LinkedIn über Sales Enablement gepostet haben. Ich dachte, das könnte für Sie relevant sein."
Das ist keine Personalisierung. Das ist ein Template mit einer Referenz, die von einem Skript eingefügt wurde, das Ihre letzten Posts gescannt hat. Jeder VP of Sales und RevOps-Leader, der täglich 30 Outbound-E-Mails bekommt, erkennt es sofort. Er löscht sie, noch bevor er den zweiten Satz liest.
Echte Personalisierung ist anders: "Ihr Team hat im ersten Quartal 12 SDRs hinzugefügt und sucht noch nach einem VP of RevOps. Ich nehme an, Pipeline-Sichtbarkeit und Rep-Ramp-Zeit stehen beide auf der Liste für dieses Halbjahr. Wir arbeiten mit wachsenden Sales-Teams genau an diesem Problem."
Beide E-Mails sind technisch gesehen "personalisiert." Eine enthält Informationen, die nur durch einen Blick auf die tatsächliche Situation des Unternehmens gewonnen werden können. Die andere enthält eine LinkedIn-Post-Referenz, die für jeden hätte generiert werden können. Käufer erkennen den Unterschied in weniger als drei Sekunden. Harvard Business Reviews Forschung zu B2B-Personalisierung in großem Maßstab fand, dass die Verkäufer, die durchkommen, diejenigen sind, die spezifische Account-Intelligence mit dem richtigen Timing kombinieren -- nicht diejenigen, die das höchste Volumen produzieren.
Das Argument für KI-generierten Outreach ist real: Er kann Erstentwürfe schneller produzieren, die Nachrichtenqualität in einem großen Team aufrechterhalten und automatisch auf Account-Recherche aufbauen. Aber das Argument gilt nur, wenn die KI mit spezifischen, relevanten Inputs arbeitet. Dies ist das Generative-Research-Muster in der Praxis: Ohne die Rechercheschicht, die den Generate-Schritt speist, produzieren Sie Personalisierungstheater in großem Maßstab statt echter Relevanz.
Das Personalisierungstheater-Problem

Key Facts: KI-personalisierter Outreach Performance
- Personalisierung jenseits von Vorname-Merge-Tags erhöht die B2B-Kalt-E-Mail-Antwortrate laut Cold-Outreach-Benchmark-Forschung um 340 % im Vergleich zu generischen Templates. (Outreaches.ai, 2025)
- Multichannel-Outreach-Sequenzen mit 3 oder mehr Kanälen erzielen 287 % mehr Antworten als einkanaliges E-Mail allein. (Outreach.io, 2025)
- KI-SDR-Tools mit forschungsbasierter Personalisierung steigern Antwortraten um 70 % oder mehr im Vergleich zu Standard-Template-basiertem Outreach. (Landbase, 2025)
Die meisten KI-Outreach-Tools scheitern aus einem strukturellen, nicht technischen Grund.
Das technische Problem ist gering. Moderne LLMs produzieren fließendes, grammatikalisch korrektes, professionelles E-Mail-Texting. Die Ausgabe klingt menschlich genug. Das ist nicht der Flaschenhals.
Das strukturelle Problem besteht darin, dass die meisten KI-Outreach-Tools so konfiguriert sind, dass sie Personalisierung aus den falschen Inputs generieren. Sie nehmen: Name, Unternehmensname, Berufsbezeichnung, kürzlicher LinkedIn-Post und vielleicht Unternehmens-Finanzierungsphase. Dann generieren sie eine First-Touch-E-Mail, die diese Fakten referenziert.
Aber diese Fakten sind nicht die tatsächliche Situation des Interessenten. Sie sind öffentlich sichtbare Signale. Jeder andere SDR, der darauf trainiert wurde, vor dem Outreach zu "recherchieren", hat dieselben Signale. Die resultierenden E-Mails sind voneinander nicht zu unterscheiden -- nicht weil KI sie geschrieben hat, sondern weil jeder dieselben Daten als Input verwendet.
Käufer haben sich darauf eingestellt. Eine Entscheidungsträger bei einem gut finanzierten SaaS-Unternehmen im Jahr 2026 hat Tausende von "Ich habe bemerkt, dass Sie kürzlich eine Series-B-Runde abgeschlossen haben"-E-Mails gesehen. Das Muster ist so vorhersehbar, dass dessen Erkennung automatisch geworden ist. Die E-Mail wird als KI-Müll abgelegt, bevor der Name des Reps registriert wird.
Echte Personalisierung erfordert Kontext, der spezifisch für diesen Interessenten in diesem Moment ist -- nicht generisch für seine Berufsbezeichnung. Dieser Kontext kommt aus der KI-Account-Recherche, die vor der Generierung des Outreach durchgeführt wird, nicht aus oberflächlichem Scraping öffentlicher Profile.
Was echte Personalisierung erfordert
Die Inputs, die genuinen relevanten First-Touch-Nachrichten produzieren, sind:
Unternehmensspezifische Signale aus der jüngsten Vergangenheit. Nicht "Sie sind VP of Sales." Das trifft auf jeden im Segment zu. Aber "Ihr Team hat im ersten Quartal 12 SDRs hinzugefügt und Sie suchen aktiv nach einem VP of RevOps": Das sind zwei spezifische Datenpunkte über die aktuelle Wachstumsphase, die die meisten Reps sich nicht die Zeit genommen haben herauszufinden.
Tech-Stack-Kontext. Zu wissen, dass sie Salesforce und Outreach ohne ein Conversation-Intelligence-Tool betreiben, ist relevanter als ihr LinkedIn-Profil. Es zeigt dem Rep genau, wo eine Lücke besteht.
Timing-Signale. Eine Führungskraft, die vor 60 Tagen eingestellt wurde, ist in einem grundlegend anderen Modus als eine, die seit 3 Jahren in der Rolle ist. Ein Unternehmen, das gerade eine Finanzierungsrunde abgeschlossen hat, evaluiert Tools anders als eines, das sich im Kostenoptimierungsmodus befindet. Timing-Kontext macht die Nachricht relevant für wann, nicht nur für wen. Buyer Intent Signal Synthesis fügt hier eine weitere Schicht hinzu, indem Accounts aufgedeckt werden, die aktiv im Recherchemodus sind.
Rollenspezifischer Schmerz, nicht Kategorieschmerz. "Sales-Leader haben mit Forecast-Genauigkeit Schwierigkeiten" ist Kategorie-Messaging. Es stimmt und bedeutet nichts. "Sie bauen eine RevOps-Funktion auf, haben gerade Ihren ersten RevOps-Analysten eingestellt, und haben wahrscheinlich noch keine zuverlässigen Pipeline-Daten, weil es bisher keine Vollzeitaufgabe von jemandem war": Das ist rollenspezifisch für ihre aktuelle Phase.
Die Quelle für all dies ist das KI-Account-Recherche-Brief. Der Generate-Schritt für Outreach beginnt nicht mit einer leeren Seite. Er beginnt mit einem Recherche-Brief, das bereits die relevanten Signale enthält, gefiltert und strukturiert.
Der Test: Personalisierungstheater vs. Forschungsbasiert
Der Test Personalisierungstheater vs. Forschungsbasiert ist ein Einzel-Fragen-Qualitätstor für KI-generierten Outreach: Hätte diese E-Mail an jeden mit derselben Berufsbezeichnung geschickt werden können, oder enthält sie mindestens zwei Signale, die spezifisch für die aktuelle Situation dieses Accounts sind? E-Mails, die den Test bestehen, sind forschungsbasiert. E-Mails, die ihn nicht bestehen, sind Personalisierungstheater, unabhängig davon, wie natürlich der Text klingt. Der Test dauert 10 Sekunden und sollte Teil des Review-Schritts jedes Reps sein, bevor KI-Entwürfe genehmigt werden.
B2B-Käufer im Jahr 2026 erhalten durchschnittlich 50+ Outbound-E-Mails pro Woche. Diejenigen, die den Personalisierungstheater-Test bestehen, werden gelesen. Diejenigen, die ihn nicht bestehen, werden in unter 3 Sekunden gelöscht -- oft bevor der Name des Reps registriert wird.
Die Generative-Research + Generate Pipeline
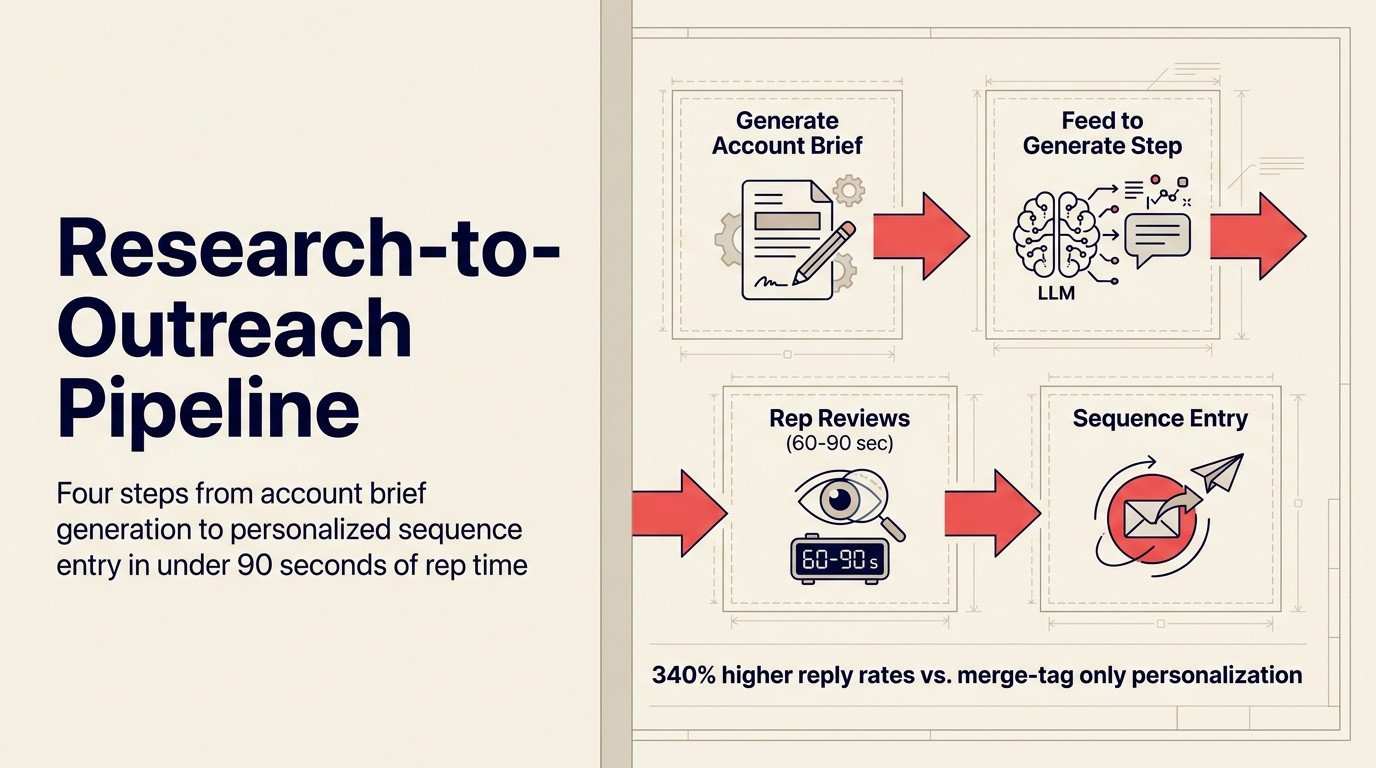
Das ACE-Muster, das forschungsbasierten Outreach antreibt, ist Generative Research, das direkt Generate speist. Für den vollständigen Überblick, wie das Generative-Research-Muster funktioniert, behandelt dieser Artikel die Ingest-Analyze-Generate-Pipeline in der Tiefe.
Schritt 1: Account-Brief generieren. Mit Clay, Apollo, ZoomInfo Copilot oder Rework Sales AI die relevanten Signale für den Account abrufen: aktuelles Hiring, Tech-Stack, Nachrichten, Führungswechsel, ICP-Fit-Bewertung. Das dauert bei einem gut konfigurierten Workflow unter 5 Minuten.
Schritt 2: Das Brief in den Generate-Schritt einspeisen. Die KI schreibt einen Erstentwurf der Outreach-E-Mail mit dem Brief als primärem Input. Die Prompt-Struktur sieht ungefähr so aus: "Schreibe basierend auf dem folgenden Account-Kontext eine First-Touch-E-Mail für [Rep-Name]. Ton: direkt, kein Jargon, gehe davon aus, dass der Leser beschäftigt ist. Länge: 4-6 Sätze. Referenziere zwei bis drei spezifische Signale aus dem Brief. Schließe mit einer klaren Einzelfrage für die Antwort ab."
Schritt 3: Rep prüft und personalisiert. Der KI-Entwurf deckt 80 % der E-Mail ab. Der Rep liest ihn, nimmt eventuelle Anpassungen auf Basis persönlichen Wissens vor (eine gemeinsame Verbindung, eine Referenz von einem gemeinsamen Kunden) und genehmigt. Das dauert 60-90 Sekunden pro E-Mail.
Schritt 4: Sequence-Entry. Die genehmigte E-Mail geht in die Sales Engagement-Plattform (Salesloft, Outreach) als ersten Kontaktpunkt in der Sequence ein. Folgekontakte in derselben Sequence sind entweder ebenfalls KI-generiert aus dem Brief oder verwenden Standard-Templates, je nach Präferenz des Teams.
Diese Pipeline ist das, was Tools wie Lavender, Smartwriter und Regie.ai zu unterstützen konzipiert sind, mit unterschiedlichem Grad der Account-Recherche-Integration. Lavender konzentriert sich auf E-Mail-Qualitätsbewertung und KI-unterstützte Texterstellung; Smartwriter betont LinkedIn- und nachrichtenbasierte Personalisierung; Regie fokussiert auf Multi-Touch-Sequence-Generierung. Alle drei funktionieren am besten, wenn sie mit spezifischem Account-Kontext statt nur Name und Titel versorgt werden.
Schlechte vs. gute Personalisierung: Ein direkter Vergleich
Personalisierungstheater (vermeiden Sie dies):
Hallo Sarah,
Ich habe Ihren kürzlichen Post über den Aufbau eines hochleistungsfähigen SDR-Teams gesehen und er hat wirklich resoniert. Wir helfen schnell wachsenden Vertriebsorganisationen, die Pipeline-Effizienz zu steigern.
Wären Sie offen für ein kurzes Gespräch, um zu erkunden, ob es einen Fit gibt?
Beste Grüße, Alex
Diese E-Mail hätte an 5.000 Personen verschickt werden können, mit einem ausgetauschten LinkedIn-Post-Verweis. Sarah weiß das. Sie löscht sie.
Forschungsbasierte Personalisierung:
Hallo Sarah,
Sie haben seit Januar 12 SDRs eingestellt und Ihre VP-of-RevOps-Stelle ist seit März offen. Wenn Sie diese Person einstellen, wird eines ihrer ersten Probleme die Pipeline-Sichtbarkeit bei einem größeren Team ohne klare Datengrundlage sein.
Wir helfen RevOps-Leadern in Unternehmen genau in dieser Phase, diese Grundlage in 60 Tagen aufzubauen.
Wäre ein 20-minütiges Gespräch sinnvoll, um zu sehen, ob das Timing passt?
Alex
Diese E-Mail hat 5 Sätze. Sie enthält zwei spezifische Datenpunkte über Sarahs Unternehmen, die tatsächliche Recherche erfordert haben. Sie verbindet diese Punkte mit einem Problem, das sie wahrscheinlich erlebt. Sie bittet um eine kleine Zusage.
Die Leserate ist anders. Die Antwortrate ist anders. Und weil es ein Recherche-Brief als Input erforderte, kann es nicht ohne echten Aufwand für 5.000 Personen generiert werden.
Volumen ohne Uniformität
Eine legitime Sorge bezüglich KI-Outreach: Wenn alle im Team dieselben Tools und dieselben Prompts verwenden, wird die Ausgabe erkennbar. Käufer beginnen, das Muster zu erkennen -- nicht nur den Inhalt.
Volumen ohne Uniformität erfordert Variationsstrategien:
Winkelrotation. Definieren Sie 4-5 verschiedene Einstiegswinkel für den Wert Ihres Produkts (Zeiteinsparung, Pipeline-Sichtbarkeit, Rep-Performance, Forecast-Genauigkeit). Die KI generiert aus einem anderen Winkel für verschiedene Account-Kontexte, sodass nicht jede E-Mail wie dieselbe Formel klingt.
Tonvarianz nach Persona. Eine CRO-E-Mail klingt anders als eine SDR-Manager-E-Mail. Konfigurieren Sie verschiedene Tonparameter für verschiedene Personas in Ihrem ICP: strategisch und ergebnisorientiert für VP-und-höher, taktisch und spezifisch für IC-und-Manager-Rollen.
Benutzerdefinierte Hooks für priorisierte Accounts. Für Ihre Top-20-%-Accounts nach ACV-Potenzial ist das Recherche-Brief umfangreicher, und der Rep fügt vor der Genehmigung einen benutzerdefinierten Hook aus persönlichem Wissen hinzu. Volumenautomatisierung deckt den Rest ab; hands-on-Personalisierung deckt die Accounts ab, bei denen es die Zeit wert ist.
Sequence-Varianz. Nicht jeder Account erhält dieselbe Follow-up-Kadenz. Konfigurieren Sie kürzere Kadenzen (3-4 Kontakte) für Senior-Käufer, von denen bekannt ist, dass sie schnell antworten oder gar nicht, und längere Kadenzen (6-8 Kontakte) für Mid-Market-Käufer, die möglicherweise mehr Kontakte benötigen, bevor sie sich engagieren.
KI-Outreach-Performance testen
Die einzige Möglichkeit zu wissen, ob KI-generierter Outreach performt, ist, ihn gegen die Alternativen zu messen.
Die A/B-Test-Struktur, die die nützlichsten Daten liefert:
- Kontrollarm: Standard-Rep-geschriebene Templates, aktuelle Sequence-Struktur
- Testarm A: KI-generiert aus Account-Brief, rep-geprüft, gleiche Sequence-Struktur
- Testarm B: KI-generiert aus Account-Brief, rep-geprüft, optimierte Sequence-Struktur
60-90 Tage laufen lassen. Messen:
- Open Rate: Primär beeinflusst durch Betreffzeile. Wenn KI auch Betreffzeilen generiert, diese in den Test einbeziehen.
- Reply Rate: Alle Antworten, einschließlich "nicht interessiert."
- Positive Reply Rate: Antworten, die zu einem Meeting oder einer Anfrage nach weiteren Informationen führen.
- Meeting Booked Rate: Meetings generiert pro eingegebener Sequence.
In den meisten Deployments produziert KI-generierter Outreach aus einem guten Recherche-Brief 15-30 % höhere positive Antwortraten als Standard-Templates. Die am besten dokumentierten Fälle zeigen 52 % höhere Antwortraten, wenn die Personalisierungstiefe über Merge-Tags hinaus zu unternehmensspezifischen Signalen geht, laut Cold-Outreach-Benchmarks. Aber der Test ist die einzige ehrliche Antwort für Ihr spezifisches Segment und Team.
Rework Analysis: Basierend auf Outreach-Daten von B2B-SaaS-Sales-Teams ist die Performance-Lücke zwischen Personalisierungstheater und forschungsbasiertem KI-Outreach am größten im Segment mit 100-500 Mitarbeitern. Entscheidungsträger in dieser Größenordnung erhalten genug Outbound, um kalibrierte Detektoren für generischen Outreach zu haben, sind aber noch nicht durch Gatekeeper geschützt wie Enterprise-Käufer. Für dieses Segment ist der zweite Satz einer First-Touch-E-Mail der wichtigste Entscheidungspunkt: Er enthält entweder ein spezifisches, zeitgemäßes Unternehmenssignal, oder die E-Mail ist weg.
Der Test zeigt auch, wo KI am schwächsten ist. In der Regel: Betreffzeilen (KI ist konservativ, Templates können aggressiver getestet werden), Follow-up-Kontakte nach Kontakt eins (KI hat weniger neue Informationen, mit denen sie arbeiten kann) und Breakup-E-Mails (die besser performen, wenn sie wie der Rep klingen, nicht wie ein System).
Compliance und Zustellbarkeit
KI-generierter Outreach in großem Maßstab schafft ein Zustellbarkeitsrisiko, das rein manuelle Outreach nicht hat.
Das Risiko liegt in Volumen und Sendeverhalten. Wenn ein SDR, der normalerweise 40 E-Mails pro Tag sendet, plötzlich 400 sendet, weil er die First-Touch-Generierung automatisiert hat, passieren zwei Dinge: E-Mail-Anbieter markieren den Account für ungewöhnliches Sendeverhalten, und das Reply-to-Send-Verhältnis (ein wichtiges Spam-Filter-Signal) fällt ins Bodenlose, weil 400 E-Mails nicht 10-mal mehr Antworten generieren.
Zustellbarkeitsschutz erfordert:
Listen-Hygiene. E-Mail-Adressen vor dem Senden verifizieren. Eine Liste mit 15 % ungültigen Adressen verursacht Bounce-Raten, die den Sender-Reputation innerhalb von Wochen schädigen. E-Mail-Verifizierungstools (Hunter, NeverBounce, ZeroBounce) auf jeder Liste verwenden, bevor sie in eine Sequence eingeht.
Sending Warm-up. Neue Sendingdomains oder Domains, die noch kein hohes Volumen gesendet haben, sollten sich langsam aufwärmen. Mit 20-30 E-Mails pro Tag beginnen und über 4-6 Wochen um 20-25 % pro Woche steigern. Automatisierte Warm-up-Tools (Lemwarm, Mailreach) können das für neue Domains übernehmen.
Rate-Limiting pro Rep. Selbst bei KI-Texterstellung First-Touch-Sends auf einem nachhaltigen Niveau begrenzen. Für die meisten B2B-Outbound-Motions ist 80-120 First-Touch-E-Mails pro Rep pro Tag die Obergrenze, bevor Zustellbarkeit und Antwortqualität zu sinken beginnen.
CAN-SPAM- und DSGVO-Compliance. Jede E-Mail benötigt einen sichtbaren Abmeldelink, einen genauen Absendernamen und eine physische Adresse. Der FTC CAN-SPAM-Compliance-Leitfaden ist die maßgebliche Referenz für kommerzielle E-Mail-Anforderungen in den USA, einschließlich Opt-out-Verarbeitungsfristen und Strafen von bis zu 53.088 Dollar pro Verstoß. Für EU-Interessenten bestätigen, dass Kontakte regelkonform bezogen wurden und Opt-out-Anfragen innerhalb von 10 Werktagen bearbeitet werden. DSGVO-Artikel 22 zur automatisierten Entscheidungsfindung ist besonders relevant, wenn KI zur Bewertung, Priorisierung oder Segmentierung von Interessenten für Outreach eingesetzt wird. KI-generiertes Volumen befreit Sie nicht von diesen Anforderungen. Es macht es wichtiger, sie richtig umzusetzen.
Fazit
KI-generierter Outreach verdient das Recht zur Skalierung, indem er wirklich relevant ist. Nicht dadurch, einen Vornamen geschickter einzufügen, und nicht dadurch, einen LinkedIn-Post zu referenzieren, den jeder andere SDR ebenfalls gesehen hat.
Die Generate-Fähigkeit im ACE-Framework kann Erstentwürfe für Outreach in einem Tempo produzieren, das kein menschliches Team erreichen kann. Aber Generate ist nur so gut wie das, was es speist. Forschungsbasierter Outreach, der mit einem spezifischen, zeitgemäßen Account-Brief beginnt, mit relevanten Inputs generiert wird und von einem Rep vor dem Senden geprüft wird, ist ein genuinen anderes Produkt als Template-mit-Variableneinfügung.
Der Test ist einfach: Würde ein menschlicher SDR, der die E-Mail liest, ohne zu wissen, dass sie KI-generiert ist, erkennen, dass sie speziell für diesen Interessenten geschrieben wurde? Wenn die Antwort Ja lautet, funktioniert der Outreach. Wenn die Antwort "er hätte an jeden geschickt werden können" lautet, braucht der Workflow spezifischere Inputs, nicht besseren Text. Bauen Sie zuerst die Rechercheschicht auf, und die Generierungsschicht folgt natürlich.
Häufig gestellte Fragen
Was ist der Unterschied zwischen KI-Outreach und Personalisierungstheater?
Personalisierungstheater ist KI-generierte E-Mail, die öffentlich sichtbare Signale referenziert (ein LinkedIn-Post, eine Finanzierungsrunde), ohne sie mit der spezifischen aktuellen Situation des Interessenten zu verbinden. Genuiner KI-Outreach verwendet ein Recherche-Brief mit unternehmensspezifischen Signalen (aktuelles Hiring, Tech-Stack-Lücken, Führungswechsel) als Input und produziert eine Nachricht, die nur für diesen Account in diesem Moment relevant ist. Der Test Personalisierungstheater vs. Forschungsbasiert unterscheidet die beiden: Hätte diese E-Mail mit einem Variablenswap an 1.000 Personen gesendet werden können? Wenn ja, ist es Theater.
Wie viel verbessert forschungsbasierter KI-Outreach die Antwortraten?
B2B-Kalt-Outreach-Benchmarks zeigen, dass Personalisierung jenseits von Vorname-Merge-Tags die Antwortraten um bis zu 340 % im Vergleich zu generischen Templates erhöht. Teams, die KI-Outreach-Tools mit Account-Recherche als Input verwenden, berichten von 70 %+ Antwortratensteigerungen im Vergleich zu Template-basierten Sends. Die Lücke ist am größten im Segment mit 100-500 Mitarbeitern, wo Käufer kalibrierte Detektoren für generischen Outreach haben, aber noch nicht durch Enterprise-Gatekeeper geschützt sind.
Welche Inputs benötigt KI, um nützlichen personalisierten Outreach zu generieren?
Vier Inputkategorien produzieren die relevantesten First-Touch-Nachrichten: unternehmensspezifische Signale der letzten 90 Tage (Einstellungsaktivität, Finanzierung, Nachrichten), Tech-Stack-Kontext (aktuelle Tools, sichtbare Lücken), Timing-Signale (neue Führungskraft tritt ein, Finanzierungsereignisse, Wachstumsphase) und rollenspezifischer Schmerz (was diese Person angesichts ihrer aktuellen Phase wahrscheinlich zu lösen versucht). Diese stammen aus einem KI-generierten Account-Recherche-Brief, nicht allein aus Name-und-Titel-Daten.
Was ist eine gute Cold-E-Mail-Antwortrate für B2B-SaaS-Teams?
Für B2B-SaaS-Outbound sind 3-5 % durchschnittlich für alle Cold-E-Mails, 5-10 % sind solide für gut zielgerichtete Segmente, und 10-15 % sind hervorragend. Top-Quartil-Performer mit engem ICP-Targeting und forschungsbasierter Personalisierung übertreffen routinemäßig 15 % bei priorisierten Account-Segmenten. Kampagnen mit automatisierter, forschungsgestützter Personalisierung erreichen typischerweise Open Rates, die 18 Prozentpunkte höher sind, und 2,7-mal höhere Antwortraten als undifferenzierte Sends. (Outreaches.ai-Benchmarks, 2025)
Wie beeinflusst die E-Mail-Zustellbarkeit KI-Outreach in großem Maßstab?
KI-generierter Outreach ermöglicht ein Volumen, das manueller Outreach nicht erreichen kann, aber das Senden von 400 E-Mails pro Tag auf einer Domain, die an 40 gewöhnt ist, löst Spam-Filter aus und schädigt die Sender-Reputation. Listen-Hygiene (E-Mail-Verifizierung vor dem Senden), schrittweises Sending-Warm-up (Volumen um 20-25 % pro Woche steigern) und Rate-Limiting pro Rep (maximal 80-120 First-Touch-Sends pro Tag) sind die drei Kontrollen, die die Zustellbarkeit schützen, wenn KI-Outreach skaliert.
Was sind die Compliance-Anforderungen für KI-generierten B2B-Outreach?
Jede kommerzielle E-Mail benötigt einen sichtbaren Abmeldelink, genauen Absendernamen und physische Adresse nach CAN-SPAM, mit Strafen von bis zu 53.088 Dollar pro Verstoß. Für EU-Interessenten müssen Opt-out-Anfragen innerhalb von 10 Werktagen nach DSGVO bearbeitet werden. KI-generiertes Volumen vergrößert die Compliance-Fläche: Systeme, die Accounts automatisch in Sequences einschreiben, müssen überprüfen, ob Kontakte sich nicht zuvor abgemeldet haben, bevor Sends ausgelöst werden.
Was Sie als Nächstes lesen sollten
- Generative Research: Compressing Hours of Reading: das zugrundeliegende ACE-Muster, das forschungsbasierten Outreach antreibt
- KI-gestützte Account-Recherche vor dem ersten Kontakt: das Recherche-Brief, das den Generate-Schritt speist
- Buyer Intent Signal Synthesis With AI: Intent-Signale zur Account-Recherche hinzufügen für besseres Outreach-Timing
- Auto Drafted Sales Follow Up Emails: KI-Generierung angewendet auf Follow-up-Sequences, nicht nur First Touch
- Industry Insight Briefings for Account Executives: tiefere Recherche für AEs, die sich auf Late-Stage-Deals vorbereiten

Co-Founder, Rework.com
On this page
- Das Personalisierungstheater-Problem
- Was echte Personalisierung erfordert
- Der Test: Personalisierungstheater vs. Forschungsbasiert
- Die Generative-Research + Generate Pipeline
- Schlechte vs. gute Personalisierung: Ein direkter Vergleich
- Volumen ohne Uniformität
- KI-Outreach-Performance testen
- Compliance und Zustellbarkeit
- Fazit
- Was Sie als Nächstes lesen sollten