Kesalahan Umum AI Lead Scoring (Dan Cara Memperbaikinya)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Sebagian besar deployment AI lead scoring gagal secara diam-diam. Tidak ada crash sistem, tidak ada pesan error, dan tidak ada momen ketika seseorang menyatakannya rusak. Model berjalan, skor muncul di CRM, reps melihatnya sebentar selama beberapa minggu, lalu berhenti menggunakannya. Alat tetap dalam kontrak. Skor terus diperbarui. Enam bulan kemudian, ketika seseorang bertanya apakah lead scoring berfungsi, tidak ada yang benar-benar tahu.
Kegagalan diam-diam adalah yang terburuk: mahal, tidak terlihat, dan disalahkan pada penyebab yang salah. "Kualitas lead kami memang lebih rendah kuartal ini." "Reps perlu pelatihan kualifikasi yang lebih baik." "Mungkin modelnya butuh lebih banyak data." Semua itu mungkin benar. Tapi seringkali masalah yang lebih dalam bersifat struktural, bukan masalah volume data atau performa rep.
Artikel ini adalah alat diagnostik bagi pemimpin ops yang telah men-deploy AI lead scoring namun tidak melihat perubahan perilaku yang diharapkan. Kegagalan di bawah ini adalah pola paling umum, dan sebagian besar bisa diperbaiki dengan perubahan operasional, bukan pergantian vendor.
Pitfall 1: Pelatihan pada data historis yang bias

Masalahnya: Model Anda dilatih pada closed-won deals masa lalu, dan closed-won deals masa lalu Anda terlalu mewakili satu segmen. Model belajar memberi skor tinggi pada segmen itu. Tapi segmen tersebut mungkin tidak mewakili akun yang paling cocok untuk Anda saat ini.
Seperti apa ini dalam praktik: Sebuah perusahaan SaaS melatih model lead scoring mereka pada tiga tahun closed deals. Sebagian besar deals tersebut adalah SMB, karena itu adalah pasar utama mereka tiga tahun lalu. Sejak itu mereka telah bergerak ke segmen yang lebih besar. Model terus memberi skor tinggi pada lead SMB dan skor rendah pada lead enterprise, meski mandat tim sales adalah enterprise. Sales leadership menganggap scoring-nya "terbalik." Bukan terbalik; model belajar masa lalu dengan akurat. Masa lalu itulah yang salah untuk strategi saat ini.
Cara memperbaikinya: Sebelum retraining, lakukan audit closed-won. Kelompokkan closed-won deals historis Anda berdasarkan ukuran deal, industri, dan segmen ICP. Jika target market Anda saat ini tidak terwakili secara proporsional dalam training set, model Anda memerlukan retraining pada subset yang representatif dan tersaring, atau lapisan ICP-weighted scoring di atasnya. Inilah mengapa AI lead scoring menekankan bahwa arsitektur model hanya sebaik training labels-nya. Label dulu yang harus benar.
Key Facts: Tingkat Kegagalan AI Lead Scoring
- NIST AI Risk Management Framework mengidentifikasi pemantauan dan pengukuran berkelanjutan sebagai persyaratan kepercayaan inti untuk sistem AI yang di-deploy; model scoring tanpa jadwal retraining melanggar persyaratan ini secara desain
- Model yang dilatih pada kurang dari 100 closed-won outcomes menghasilkan output yang secara statistik tidak dapat dibedakan dari penugasan acak; di bawah 200, reliabilitas model masih marjinal
- Studi korelasi skor-ke-konversi secara konsisten menunjukkan bahwa 25-30% dari semua inbound lead yang mendapat skor "hot" adalah ambang batas di mana miscalibration threshold mulai menurunkan kepercayaan rep; di atas 30%, adopsi biasanya runtuh dalam 60 hari
The 5 Lead Scoring Failure Modes
The 5 Lead Scoring Failure Modes adalah framework diagnostik untuk deployment AI scoring yang tampak berjalan tetapi tidak mengubah perilaku rep. Lima mode tersebut adalah: (1) Biased Training Data, di mana kemenangan historis terlalu mewakili segmen pasar yang telah ditinggalkan tim; (2) Score Surfacing Failure, di mana skor ada di field CRM yang tidak pernah dilihat rep; (3) No Feedback Loop, di mana model tidak pernah dilatih ulang dan akurasi menurun seiring waktu; (4) Threshold Miscalibration, di mana terlalu banyak lead mendapat skor "hot" dan penunjukan tersebut menjadi tidak berarti; dan (5) Intent Gap, di mana fit-based scoring mengidentifikasi akun yang cocok dengan ICP tetapi melewatkan sinyal pembelian aktif. Setiap mode memiliki perbaikan yang berbeda. Sebagian besar kegagalan melibatkan lebih dari satu mode secara bersamaan.
Pitfall 2: Skor tidak ditampilkan di tempat rep bekerja
Masalahnya: Skor yang tersembunyi di field CRM tiga klik di kedalaman tidak menghasilkan perubahan perilaku sama sekali. Reps tidak mengubah workflow untuk mencari informasi; informasi perlu menemui mereka di tempat mereka sudah berada.
Seperti apa ini dalam praktik: RevOps menyiapkan custom field bernama "AI Lead Score" di Salesforce. Letaknya di halaman detail lead record, di bawah fold, di sebelah 40 field lainnya. Tidak ada yang mengubah default list view. Tidak ada notifikasi yang terpicu ketika skor diperbarui. Reps belajar mengabaikannya karena tidak mengganggu workflow mereka yang sudah ada.
Cara memperbaikinya: Surfacing skor adalah masalah desain workflow, bukan hanya masalah data. Skor perlu muncul di lead list view (bisa diurutkan), sebagai trigger notifikasi (alert ketika lead melewati threshold), dan dalam daily digest atau task queue rep. Jika Anda menggunakan sales engagement platform seperti Outreach atau Salesloft, skor harus mengatur lead mana yang masuk ke sequence mana. Tesnya: jika rep bisa menjalani seluruh hari kerja tanpa melihat skor, berarti skor belum tersurfacing. Ini adalah salah satu pitfall paling mudah diperbaiki dan paling sering terlewat.
Pitfall 3: Tidak ada feedback loop
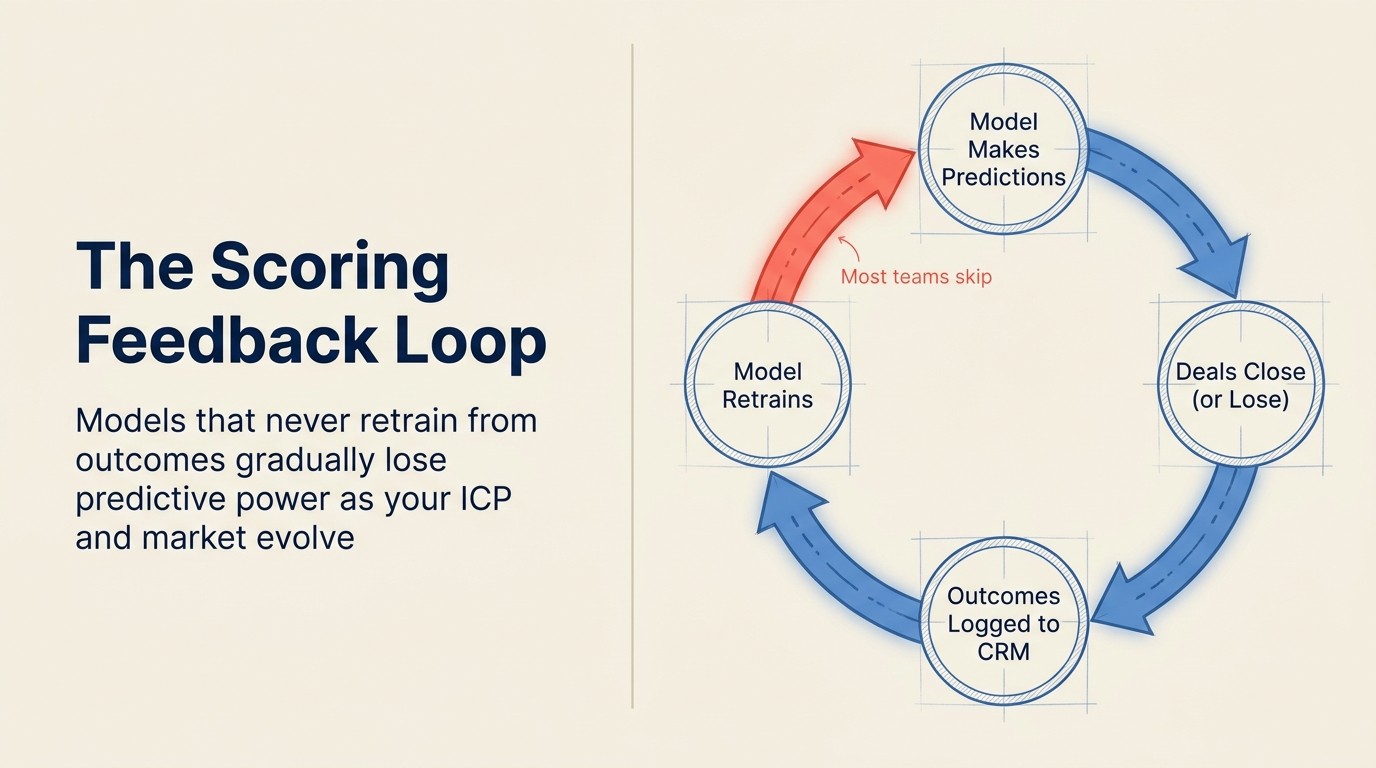
Masalahnya: Model memberi skor berdasarkan data training statis tanpa batas waktu, tanpa mekanisme untuk retraining pada closed-won dan closed-lost outcomes baru. Setiap kuartal model semakin jauh dari realita saat ini, tetapi tidak ada yang menyadarinya karena skor terus diperbarui dan antarmukanya terlihat sama.
Ini adalah failure mode paling penting secara struktural. Tidak seperti yang lain yang menurun secara bertahap, tidak adanya feedback loop menyebabkan peluruhan akurasi yang berlipat ganda. Model yang dilatih di Q1 tahun lalu dan tidak pernah diperbarui sekarang telah melewatkan empat kuartal deal outcomes yang bisa mempertajam prediksinya. NIST AI Risk Management Framework secara khusus mengidentifikasi pemantauan dan pengukuran berkelanjutan sebagai persyaratan kepercayaan inti untuk sistem AI yang di-deploy, bukan tugas pengaturan satu kali.
Seperti apa ini dalam praktik: Sebuah perusahaan men-deploy HubSpot Predictive Lead Scoring pada bulan Februari. Dilatih pada 18 bulan historical deals. Pada April, mereka meluncurkan lini produk baru yang mengubah profil pembeli mereka. Pada Juni, mereka merekrut 5 AE baru yang mulai menutup profil deal yang berbeda. Pada September, seorang manajer menyadari bahwa skor tidak berkorelasi dengan deals terbaik mereka. Model baik-baik saja pada Februari. Sudah menurun sejak April. Tidak ada yang memicu retraining karena sistem tidak memberi alert tentang drift.
Cara memperbaikinya: Tentukan jadwal retraining sebelum Anda meluncurkan, bukan setelah Anda menyadari masalah. Kuartalan adalah minimum untuk sebagian besar bisnis; bulanan lebih baik untuk tim yang berkembang cepat dengan ICP yang berubah. Event pemicu untuk retraining di luar siklus: peluncuran produk baru, perubahan ICP yang signifikan, penambahan channel besar, atau perubahan sales motion. Mekanismenya: pastikan CRM Anda mencatat closed-won dan closed-lost secara konsisten dengan field yang digunakan model Anda sebagai fitur. Tanpa disiplin logging itu, Anda tidak memiliki data training baru untuk dimasukkan kembali.
Ini juga mengapa penjelasan skor yang dapat dibaca manusia (Pitfall 6) penting untuk feedback. Jika rep dapat melihat bahwa lead mendapat skor tinggi karena "ukuran perusahaan + tech stack + kecocokan industri," mereka dapat menandai ketika logika itu tidak lagi mencerminkan apa yang berkonversi. Reps adalah sistem peringatan dini Anda untuk model drift, tetapi hanya jika mereka memahami logika scoring.
Pitfall 4: Terlalu banyak input features, terlalu sedikit data
Masalahnya: Overfitting. Model menggunakan 40 input features untuk memberi skor lead dari training set 300 historical deals. Model menghafal pola dalam data training, bukan menggeneralisasi ke lead baru. Terlihat mengesankan dalam evaluasi (akurasi tinggi pada data training) dan gagal pada lead langsung.
Seperti apa ini dalam praktik: Seorang analis RevOps membangun model lead scoring kustom di Python menggunakan 45 fitur dari Salesforce (setiap field yang bisa mereka pikirkan: page views, email opens, level jabatan, usia perusahaan, followers LinkedIn, status pendanaan, dll.). Evaluasi model menunjukkan akurasi 89%. Ketika di-deploy, reps memperhatikan model memberi skor 90+ kepada lead yang tidak pernah engage dan skor rendah kepada lead yang jelas-jelas berkualifikasi. Model menghafal training set. Tidak memiliki nilai prediktif pada data baru.
Cara memperbaikinya: Untuk tim dengan kurang dari 1.000 historical outcomes, gunakan model yang lebih sederhana dengan lebih sedikit fitur. 5-10 fitur sinyal tinggi yang konsisten diisi mengalahkan 45 fitur yang jarang atau tidak konsisten. Fitur nilai tinggi klasik: ukuran perusahaan, kecocokan industri, senioritas jabatan, sumber form (halaman/channel mana), dan sinyal product-usage untuk expansion leads. Mulai sederhana. Tambahkan fitur seiring bertambahnya volume data Anda.
Untuk tim dengan data historis terbatas, memulai dengan model pre-trained vendor (Salesforce Einstein, HubSpot Predictive Lead Scoring) dan melapisi kriteria ICP Anda di atasnya seringkali lebih andal daripada membangun dari awal.
Pitfall 5: Score threshold yang tidak sesuai
Masalahnya: Model menghasilkan probabilitas, tetapi routing thresholds diatur dengan salah. Threshold yang terlalu rendah membanjiri reps dengan lead "hot" yang sebenarnya tidak hot. Threshold yang terlalu tinggi berarti lead berkualifikasi tidak pernah naik ke perhatian manusia.
Seperti apa ini dalam praktik: Sebuah tim menetapkan threshold "hot lead" mereka pada 40 dari 100. Model scoring mereka dikalibrasi sehingga 40 mewakili probabilitas konversi 40%. Dengan threshold di 40, 60% inbound mereka ditandai sebagai hot dan diarahkan ke SDR senior. SDR tersebut kewalahan. Connect rate mereka pada lead "hot" terlihat buruk karena ada terlalu banyak lead untuk dikerjakan dengan baik. Masalahnya bukan model scoring; masalahnya adalah threshold.
Cara memperbaikinya: Penetapan threshold harus dikalibrasi terhadap conversion rates historis per score band, bukan ditetapkan secara sewenang-wenang. Ambil 6-12 bulan terakhir lead yang diberi skor dan conversion outcomes (jika ada). Temukan score band di mana conversion rate naik secara bermakna. Itulah routing threshold Anda. Jika Anda menyiapkan scoring untuk pertama kalinya tanpa historical scored leads, mulai dengan threshold tinggi (70+) yang menjaga volume hot-lead tetap dapat dikelola, dan sesuaikan ke bawah seiring waktu saat Anda mengumpulkan data skor-ke-outcome.
Pertanyaan threshold juga meluas ke routing tiers. Tentukan setidaknya tiga routing tiers: high-priority (eskalasi manusia, SLA cepat), standard (antrean SDR normal), dan nurture (sequence otomatis, tidak ada kontak rep sampai intent signal terpicu). Threshold antar tier tersebut perlu disetel, bukan diasumsikan. Dan 25-30% lead yang mendapat skor "hot" adalah batas diagnostik: jika Anda di atas itu, turunkan threshold sebelum reps berhenti mempercayai sistem sepenuhnya.
Pitfall 6: Ketidakpercayaan rep dari skor yang tidak bisa dijelaskan
Masalahnya: Black-box scoring kehilangan adopsi rep. Rep yang tidak memahami mengapa lead mendapat skor 87 tidak akan bertindak berdasarkan itu secara konsisten. Dan ketika model membuat kesalahan yang bisa dideteksi rep (lead berkualitas rendah yang jelas dengan skor 90), seluruh sistem scoring kehilangan kredibilitas di benak rep tersebut.
Seperti apa ini dalam praktik: Sebuah perusahaan men-deploy model scoring yang menggunakan 15 sinyal berbobot. Antarmuka menampilkan satu angka kepada reps: "Lead Score: 82." Seorang rep melihat lead, melihat startup 3 orang dari tipe perusahaan yang jarang berkonversi untuk mereka, dan mengabaikan angka 82. Minggu berikutnya mereka mengabaikan angka 91. Dalam dua bulan, reps secara mental telah membuang scoring sebagai tidak dapat diandalkan. Model mungkin akurat rata-rata, tetapi kesalahan individual tanpa penjelasan menghancurkan adopsi.
Cara memperbaikinya: Penjelasan skor harus muncul di titik penggunaan. Bukan hanya "Score: 82" tetapi "Score: 82 karena ukuran perusahaan (mid-market), industri (layanan keuangan), dan putaran pendanaan terbaru semuanya cocok dengan ICP Anda. Sinyal Intent: sedang. Yang kurang: kontak decision-maker yang dikonfirmasi." Dengan konteks itu, bahkan ketika rep tidak setuju dengan skor, mereka memahami alasannya. Mereka dapat menantang input yang tepat (mungkin klasifikasi "mid-market" salah karena perusahaan ini baru-baru ini mengalami penyusutan) daripada menolak seluruh skor.
Beberapa alat menawarkan ini secara native (faktor skor Salesforce Einstein, breakdown skor HubSpot). Model kustom perlu dibangun dengan sengaja.
Pitfall 7: Mengabaikan timing signals (fit tanpa intent)
Masalahnya: Fit-based scoring memberi tahu Anda bahwa perusahaan cocok dengan ICP Anda. Tidak memberi tahu Anda bahwa mereka sedang aktif membeli. Perusahaan yang sangat cocok tetapi tidak sedang in-market mendapat skor tinggi tetapi berkonversi buruk. Perusahaan dengan kesesuaian rata-rata dalam evaluasi aktif mendapat skor sedang tetapi berkonversi lebih baik. Intent plus fit bersama-sama mengungguli keduanya secara terpisah.
Seperti apa ini dalam praktik: Model tim memberi skor akun sepenuhnya berdasarkan firmographic fit: ukuran perusahaan, industri, tech stack, kisaran pendapatan. Lead "Tier 1" mereka secara konsisten adalah akun yang cocok dengan baik. Tetapi reps mengeluh bahwa mereka tidak bisa membuat lead ini engage. Mereka adalah ICP match yang dingin, bukan pembeli yang hangat. Sementara itu, data intent (Bombora, 6sense) menunjukkan beberapa akun mid-tier yang secara aktif meneliti kategori perusahaan. Akun tersebut tidak pernah muncul karena mereka tidak mendapat skor tinggi pada firmographic fit.
Cara memperbaikinya: Tambahkan timing signals sebagai lapisan scoring. Intent pihak ketiga (Bombora, 6sense, Demandbase) memberi tahu Anda siapa yang aktif meneliti sekarang. Sinyal first-party (kunjungan halaman harga, pembacaan dokumentasi, tampilan perbandingan fitur) memberi tahu Anda form submitter mana yang sedang dalam mode evaluasi aktif. Lead yang mendapat skor 60 pada fit tetapi memiliki sinyal intent tinggi harus diarahkan berbeda dari lead yang mendapat skor 90 pada fit tetapi tidak menunjukkan intent. Model gabungan menangkap pembeli yang akan Anda lewatkan dengan salah satu sinyal saja. Artikel buyer intent signal synthesis with AI menunjukkan cara melapisi sinyal-sinyal ini dalam praktik.
Rework Analysis: Pola kegagalan diam-diam adalah yang paling mahal yang kami lihat dalam deployment AI lead scoring. Model secara teknis berjalan, vendor secara teknis masih dibayar, tetapi reps berhenti mempercayai skor tiga bulan lalu dan tidak ada yang secara resmi mengakuinya. Tandanya adalah pertanyaan survei: "Apakah Anda melihat AI lead score sebelum memutuskan lead mana yang dikerjakan terlebih dahulu?" Ketika kurang dari 40% reps mengatakan ya, sistem scoring bersifat dekoratif. Perbaikannya hampir tidak pernah memerlukan vendor baru. Ini memerlukan penyelesaian salah satu dari lima failure mode yang menyebabkan kepercayaan terkikis, biasanya threshold miscalibration atau score surfacing failure, dua masalah yang paling bisa diperbaiki secara operasional dalam daftar.
Daftar periksa audit: pertanyaan diagnostik untuk deployment scoring Anda
Gunakan ini untuk mendiagnosis pitfall mana yang mempengaruhi sistem Anda saat ini:
Data training
- Kapan model terakhir dilatih ulang? Apakah ada jadwal yang ditetapkan?
- Berapa persentase closed-won deals Anda saat ini yang berasal dari segmen yang menonjol dalam data training?
- Apakah closed-lost deals disertakan dalam training set, atau hanya closed-won?
Surfacing dan adopsi
- Bisakah rep melihat skor tanpa meninggalkan default list view mereka?
- Apakah ada notifikasi atau alert ketika lead melewati threshold?
- Tanyakan tiga reps: "Apa arti lead score tinggi untuk workflow harian Anda?" Jika jawabannya samar, skor tidak mengubah perilaku.
Feedback loop
- Apakah ada trigger retraining formal? Siapa yang bertanggung jawab?
- Apakah field closed-won dan closed-lost wajib diisi di CRM Anda, dengan definisi yang konsisten?
- Bagaimana Anda tahu jika akurasi model sedang menurun?
Kalibrasi threshold
- Berapa persentase volume inbound Anda yang mendapat skor "hot"? Jika di atas 25-30%, threshold mungkin terlalu rendah.
- Apakah Anda memiliki data outcome skor-ke-konversi untuk memvalidasi threshold Anda saat ini?
Explainability
- Bisakah rep melihat apa yang mendorong skor?
- Ketika rep tidak setuju dengan skor, apakah mereka tahu input mana yang perlu ditantang?
Integrasi intent
- Apakah data timing/intent disertakan dalam scoring, atau hanya firmographic fit?
- Apakah ada sinyal perilaku first-party dalam model scoring (page views, keterlibatan email, permintaan demo)?
Jika Anda menjawab "tidak" untuk lebih dari tiga dari ini, sistem scoring Anda memiliki setidaknya satu masalah struktural. Artikel AI lead scoring overview membahas bagaimana model yang berfungsi dengan baik dibangun. Artikel ini membahas mengapa model tersebut gagal di lapangan.
Failure modes: when AI sales ops backfires memperluas analisis ini melampaui scoring ke stack RevOps yang lebih luas.
Ringkasan jujur
Pitfall AI lead scoring semuanya bisa diperbaiki. Tetapi sebagian besar perbaikan bersifat operasional, bukan teknis. Anda tidak memerlukan vendor berbeda untuk sebagian besar dari ini. Anda memerlukan jadwal retraining, workflow surfacing skor, proses kalibrasi threshold, dan lapisan explainability.
Failure mode yang paling berbahaya juga yang paling umum: model yang berjalan tanpa batas waktu tanpa feedback loop, perlahan menyimpang dari realita sementara semua orang mengira itu masih berfungsi karena antarmuka terlihat tidak berubah. Scoring tanpa retraining seperti navigasi dengan peta dari tahun lalu. Medan mungkin sudah berubah; peta tidak mengetahuinya.
Pertanyaan yang Sering Diajukan
Mengapa sebagian besar deployment AI lead scoring gagal secara diam-diam?
Kegagalan diam-diam terjadi karena tidak ada pesan error atau crash sistem ketika model scoring berhenti berguna. Model terus menghasilkan skor, field CRM terus diperbarui, dan vendor terus menagih. Tetapi reps secara bertahap berhenti bertindak berdasarkan skor, dan tidak ada yang secara resmi mencatat bahwa sistem telah berhenti berfungsi. Kegagalan dikaitkan dengan kualitas lead atau performa rep daripada masalah struktural yang mendorongnya: data training yang bias, tidak ada jadwal retraining, threshold yang salah kalibrasi, atau skor yang tersembunyi di field CRM yang tidak dilihat siapapun.
Apa failure mode AI lead scoring yang paling kritis?
Kegagalan feedback loop, di mana model berjalan tanpa batas waktu tanpa retraining pada closed outcomes baru, adalah yang paling penting secara struktural. Tidak seperti failure mode lain yang menurun secara bertahap, tidak adanya feedback loop menyebabkan peluruhan akurasi yang berlipat ganda. Model yang dilatih di Q1 yang tidak pernah dilatih ulang telah melewatkan setiap pergeseran pasar, perubahan ICP, dan penambahan channel sejak saat itu. NIST AI Risk Management Framework mengklasifikasikan pemantauan berkelanjutan sebagai persyaratan kepercayaan inti, bukan pemeliharaan opsional.
Bagaimana Anda tahu apakah threshold AI lead scoring Anda salah kalibrasi?
Tiga sinyal mengindikasikan masalah threshold: lebih dari 25-30% dari total volume inbound mendapat skor "hot" (threshold terlalu rendah), reps mengeluh bahwa hot leads tidak berkonversi (masalah yang sama), atau reps secara manual memprioritaskan ulang lead berdasarkan intuisi daripada skor (threshold telah kehilangan kredibilitas). Perbaiki dengan mengambil 6-12 bulan terakhir scored leads dengan outcomes, menemukan score band di mana conversion rate meningkat secara bermakna, dan menetapkan hot-lead threshold pada band tersebut.
Apa yang harus bisa dilihat rep ketika melihat lead score?
Pengalaman score surfacing yang lengkap menampilkan: skor itu sendiri (misalnya 82/100), tiga faktor teratas yang mendorong skor (misalnya ukuran perusahaan: mid-market, industri: layanan keuangan, pendanaan terbaru: Seri B), sinyal intent yang terdeteksi, dan apa yang kurang yang akan meningkatkan skor (misalnya tidak ada kontak decision-maker yang dikonfirmasi). Tanpa konteks ini, reps tidak dapat menantang input yang salah, tidak dapat membangun intuisi tentang apa arti skor tinggi, dan tidak dapat mempercayai sistem ketika mereka melihat kesalahan individual.
Seberapa sering model AI lead scoring harus dilatih ulang?
Kuartalan adalah minimum; bulanan lebih baik untuk tim yang berkembang cepat atau yang menggeser ICP. Trigger retraining di luar siklus mencakup peluncuran produk baru, perubahan ICP yang signifikan, channel baru yang besar, atau perubahan material dalam distribusi ukuran deal. Mekanisme retraining mengharuskan closed-won dan closed-lost outcomes dicatat secara konsisten dengan field yang digunakan model sebagai fitur. Tanpa disiplin logging itu, tidak ada data training baru untuk dimasukkan kembali ke dalam model.
Apa perbedaan antara fit scoring dan intent scoring?
Fit scoring mengukur seberapa baik perusahaan cocok dengan ICP Anda pada dimensi firmografi: ukuran perusahaan, industri, tech stack, kisaran pendapatan. Intent scoring mengukur apakah perusahaan sedang aktif meneliti dan membeli sekarang: data pihak ketiga dari Bombora atau 6sense yang menunjukkan penelitian kategori, ditambah sinyal first-party seperti kunjungan halaman harga dan tampilan perbandingan fitur. Fit-only scoring menghasilkan daftar pelanggan potensial terbaik Anda, sebagian besar tidak sedang dalam mode pembelian hari ini. Menggabungkan fit dan intent memunculkan siapa yang terbaik DAN paling siap. Lead dengan fit 60/intent tinggi seringkali berkonversi lebih baik daripada lead fit 90/tanpa intent.
Mengapa reps berhenti mempercayai AI lead scores setelah beberapa minggu?
Kepercayaan runtuh ketika reps melihat skor tinggi pada lead yang mereka tahu salah, tanpa penjelasan mengapa lead itu mendapat skor tinggi. Rep yang melihat perusahaan berkualitas rendah yang jelas dengan skor 85, dan tidak bisa melihat apa yang mendorong skor itu, menyimpulkan bahwa seluruh sistem tidak dapat diandalkan. Black-box scoring menghancurkan adopsi karena reps tidak bisa membedakan antara model yang benar-benar baik yang membuat kesalahan langka dan model yang rusak yang menghasilkan angka acak. Penjelasan skor mencegah ini: dengan konteks, reps dapat menantang input tertentu daripada membuang sistemnya.
Pelajari Lebih Lanjut

Co-Founder, Rework.com
On this page
- Pitfall 1: Pelatihan pada data historis yang bias
- The 5 Lead Scoring Failure Modes
- Pitfall 2: Skor tidak ditampilkan di tempat rep bekerja
- Pitfall 3: Tidak ada feedback loop
- Pitfall 4: Terlalu banyak input features, terlalu sedikit data
- Pitfall 5: Score threshold yang tidak sesuai
- Pitfall 6: Ketidakpercayaan rep dari skor yang tidak bisa dijelaskan
- Pitfall 7: Mengabaikan timing signals (fit tanpa intent)
- Daftar periksa audit: pertanyaan diagnostik untuk deployment scoring Anda
- Ringkasan jujur
- Pelajari Lebih Lanjut