CRM-Datenhygiene mit einem AI Copilot

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Garbage in, garbage out.
Sie haben das oft genug gehört, dass es wie eine Platitude klingt. Aber in KI-gestützten Sales Operations ist es die grundlegende Gleichung. Ihr Lead-Scoring-Modell wird mit CRM-Daten trainiert. Ihre Account-Tier-Zuweisungen ziehen aus CRM-Firmografiken. Ihre Pipeline-Prognose wird aus Deal-Stage-Daten berechnet. Ihr Intent-Signal-Routing feuert basierend auf Account-Datensätzen im CRM.
Jede KI-Funktion in Ihrem Sales-Stack ist nachgelagert zur CRM-Datenqualität. Wenn diese Daten unordentlich sind, sind Ihre KI-Outputs mit Sicherheit falsch. Und mit Sicherheit falsch ist schlimmer als eingestandenermaßen unsicher, weil Reps danach handeln. Gartner schätzt, dass schlechte Datenqualität Organisationen durchschnittlich 15 Millionen Dollar jährlich kostet, wobei CRM-Datenqualitätsprobleme eine der wirkungsstärksten Kostenquellen für Commercial-Teams darstellen.
CRM-Hygiene ist keine glamouröse Arbeit. RevOps-Leader wissen das. Die meisten haben ein Datenbereinigungsprojekt gestartet, es ein Quartal lang durchgeführt, den Sieg erklärt und zugesehen, wie die Datenqualität innerhalb von 6 Monaten wieder sinkt. Das quartalsweise Bereinigungsmodell funktioniert nicht, weil Daten nicht quartalsmäßig schlecht werden. Sie verschlechtern sich kontinuierlich, in einer Rate, die durch Ihr Deal-Volumen, die Disziplin Ihrer Reps und das Veränderungstempo in Ihren Accounts bestimmt wird.
Das Workflow-Copilot-Muster, angewendet auf CRM-Hygiene, ist ein anderes Modell: kontinuierliche, automatisierte Erkennung und Korrektur mit einer Governance-Schicht, die Menschen für alles über einem Konfidenz-Schwellenwert in der Entscheidungskette hält. Dieser Artikel behandelt, wie es funktioniert, die vier Problemtypen, die es behandelt, und warum es die Infrastrukturinvestition ist, die alles andere in Ihrem KI-Stack zuverlässiger macht.
Was CRM-Datenhygiene operativ bedeutet
Key Facts: Die Kosten schlechter CRM-Daten
- Schlechte CRM-Datenqualität kostet das durchschnittliche B2B-Unternehmen laut Gartner/ZoomInfo 12,9 bis 15 Millionen Dollar pro Jahr durch verschwendete Marketingausgaben, verlorene Verkaufschancen und operative Ineffizienzen. (Gartner / ZoomInfo, 2025)
- Vertriebsmitarbeiter verschwenden 27 % ihrer Zeit mit dem Umgang mit schlechten Daten, was geschätzte 32.000 Dollar pro Rep jährlich an verlorener Produktivität kostet. (Validity, 2025)
- B2B-Kontaktdaten verfallen mit ca. 2,1 % pro Monat, was bedeutet, dass 22-30 % der CRM-Kontaktdatensätze ohne aktive Hygiene innerhalb eines Jahres ungenau werden. (Salesgenie, 2025)
"Datenhygiene" ist ein Sammelbegriff. Für RevOps-Zwecke deckt er vier unterschiedliche Problemtypen ab:
Duplikate. Dasselbe Unternehmen existiert als zwei Datensätze ("Acme Corp" und "Acme Corporation Inc"). Derselbe Kontakt ist dreimal aus drei verschiedenen Import-Ereignissen im System. Duplikate teilen die Aktivitätshistorie, fragmentieren den Beziehungskontext und produzieren aufgeblähte Kontaktzähler, die Ihre Gebietszuweisungen durcheinanderbringen.
Feld-Vollständigkeit. Pflichtfelder sind leer. Keine Branchenvertikale. Keine Mitarbeiterzahl. Keine letzte Finanzierungsrunde. Kein primärer Kontakt auf dem Account. Diese Lücken brechen Scoring-Modelle, die diese Felder als Inputs verwenden, und produzieren leere Zellen in Berichten, die Entscheidungsflächen sein sollten.
Veraltete Datensätze. In den letzten 180 Tagen keine Aktivität protokolliert, aber der Deal ist in Ihrer Pipeline noch offen. Das Unternehmen des Kontakts wurde vor 8 Monaten übernommen, aber der Account-Datensatz wurde nicht aktualisiert. Der primäre Champion hat das Unternehmen verlassen, ist aber noch als Hauptkontakt aufgeführt. Veraltete Datensätze erzeugen falsches Pipeline-Vertrauen und verpasste Outreach-Gelegenheiten für lebendige Opportunities.
Anreicherungsdrift. Daten waren beim Eintrag genau und sind seitdem durch externe Veränderungen falsch geworden. Unternehmen ziehen um. Kontakte wechseln Jobs. Telefonnummern werden ungültig. Finanzierungsrunden finden statt. Mitarbeiterzahlen ändern sich. Das CRM weiß das nicht; es speichert nur, was eingegeben wurde. Im Laufe der Zeit wächst die Kluft zwischen CRM-Datensätzen und der Realität.
Alle vier Problemtypen verschlechtern die KI-Ausgabequalität auf spezifische Weisen. Duplikate verwirren Scoring-Modelle mit geteilten Signaldaten. Fehlende Felder reduzieren die Modellgenauigkeit und produzieren nicht bewertete Datensätze. Veraltete Datensätze blähen Pipeline-Zahlen auf und verzerren Prognosen. Anreicherungsdrift produziert Outreach an falsche Kontakte und falsche Qualifikationskriterien.
Wie der Workflow Copilot Hygiene handhabt
Das Workflow-Copilot-Muster im ACE-Framework beschreibt eine kontinuierliche Assist-Schleife: den aktuellen Kontext einsammeln, analysieren, um zu identifizieren, was Aufmerksamkeit benötigt, eine Empfehlung generieren, mit menschlicher Genehmigung ausführen (oder automatisierte Aktion für Fälle mit hoher Konfidenz), dann wiederholen.
Angewendet auf CRM-Hygiene:
Ingest liest den aktuellen CRM-Zustand. Alle Datensätze, alle Aktivitätsprotokolle, alle Feldwerte. Das geschieht auf kontinuierlicher Basis (neue Datensätze lösen sofortige Prüfungen aus) und auf einem geplanten Batch-Basis (vollständiger Datenbank-Scan wöchentlich).
Analyze identifiziert Datenprobleme über die vier Problemtypen:
- Duplikaterkennung: Abgleich auf Unternehmensname, Domain, Telefonnummer und Adressähnlichkeit
- Vollständigkeitsprüfung: jeden Datensatz gegen Pflichtfeld-Definitionen bewerten
- Aktualitätsbewertung: Datensätze ohne protokollierte Aktivität über konfigurierbaren Schwellen markieren
- Anreicherungsdrift-Erkennung: CRM-Daten mit externen Datenquellen (Unternehmensdatenbanken, LinkedIn, Domain-Lookup) vergleichen
Generate produziert eine empfohlene Korrektur für jedes identifizierte Problem:
- Für Duplikate: eine Merge-Empfehlung, die angibt, welchen Datensatz als primären behalten und welche Felder von jedem Datensatz übernehmen
- Für fehlende Felder: automatisch ausgefüllte Werte aus Anreicherungsquellen mit Konfidenz-Scores
- Für veraltete Datensätze: empfohlene Statusänderung (als inaktiv markieren, neu qualifizieren, archivieren) mit Kontext
- Für Drift: aktualisierte Feldwerte aus Anreicherung, klar beschriftet
Execute leitet die empfohlene Korrektur durch einen von zwei Pfaden, abhängig von der Konfidenz:
- Hohe Konfidenz (über Schwelle): Korrektur automatisch ausführen und Aktion protokollieren
- Unter Schwelle: zur Rep- oder RevOps-Überprüfung in die Warteschlange stellen mit der präsentierten Empfehlung
Die Governance-Schicht ist das, was dies von Chaos trennt. Automatisierte Ausführung bei allem produziert eine andere Art von Datenqualitätsproblem: im großen Maßstab ohne Überprüfung angewendete Korrekturen können Fehler genauso effizient verbreiten, wie sie sie beheben. Für die breiteren Governance-Prinzipien, die auf alle KI-Systeme angewendet werden, behandelt AI Sales Ops Governance und Audit Trails das Framework ausführlich.
B2B-Kontaktdaten verfallen mit 2,1 % pro Monat, und 30 % aller CRM-Datensätze werden jährlich veraltet. Eine quartalsweise Bereinigungskampagne bedeutet, dass die durchschnittliche Organisation für den Großteil des Jahres mit 5-7 % verschlechterten Daten arbeitet.
Die Konfidenz-Schwellen-Auto-Fix-Regel
Die Konfidenz-Schwellen-Auto-Fix-Regel ist das Governance-Prinzip, das bestimmt, welche CRM-Hygienekorrekturen automatisch ausgeführt werden und welche eine menschliche Überprüfung erfordern. Sie hat drei Stufen: über 90 % Konfidenz auf einer bekannten Anreicherungsquelle löst Auto-Fix mit einem Audit-Log-Eintrag aus; zwischen 50-90 % Konfidenz generiert eine Empfehlung, die zur RevOps- oder Rep-Genehmigung in die Warteschlange gestellt wird; unter 50 % Konfidenz produziert nur eine Markierung, keine empfohlene Korrektur. Die Regel verhindert zwei Fehlermodi: Unterautomatisierung (ein Rückstand, den niemand verarbeitet) und Überautomatisierung (sichere Fehler, die im großen Maßstab verbreitet werden). Die Schwellenprozentsätze sollten vierteljährlich basierend auf gesampelten Audit-Reviews von Auto-Korrekturen kalibriert werden.
Auto-Fix vs. Rep-Review-Schwellen
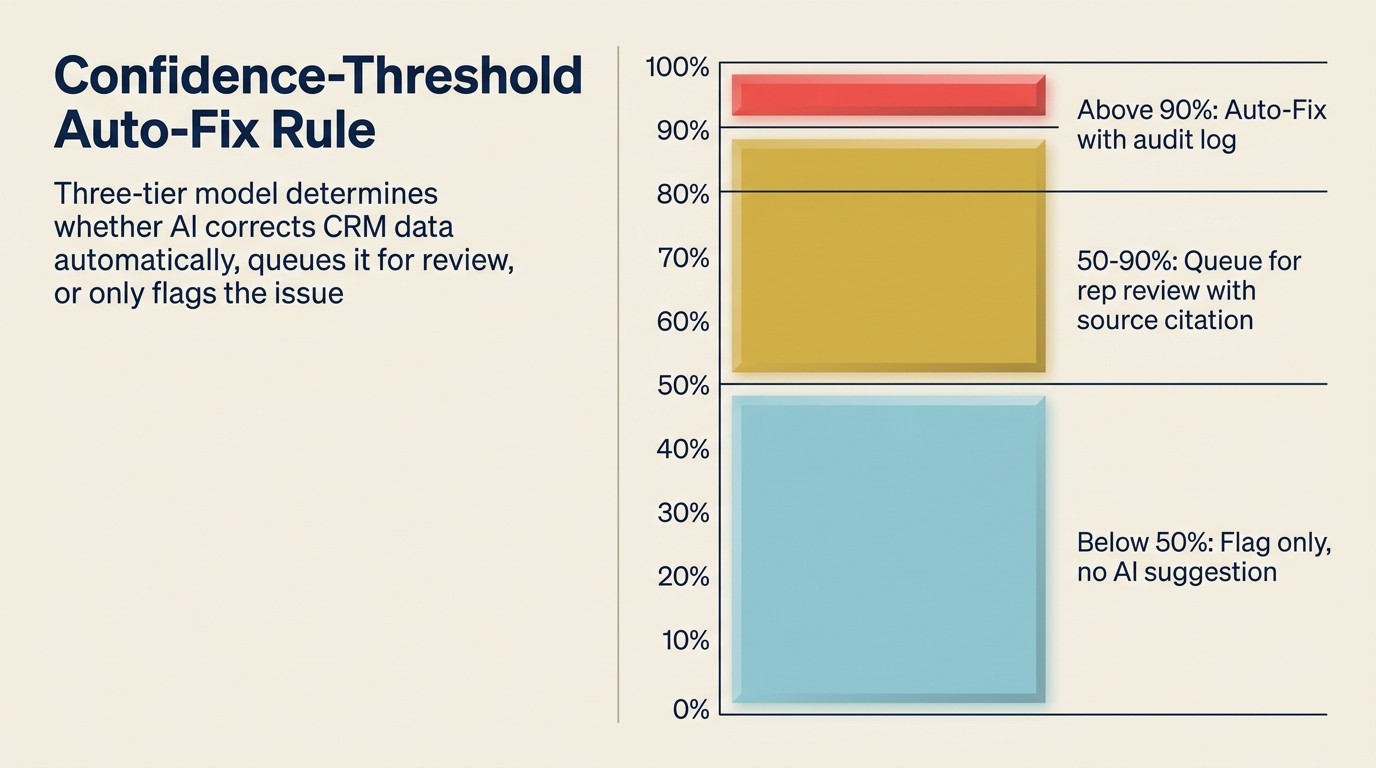
Das Governance-Modell ist die wichtigste Designentscheidung in einem KI-CRM-Hygiensystem.
Was automatisch korrigiert wird:
- Exakt übereinstimmende Duplikat-Datensätze (gleiche E-Mail-Adresse, gleiche Domain, bestätigtes gleiche Unternehmen) ohne widersprüchliche Felddaten: automatisch zusammenführen, die Zusammenführung protokollieren
- Fehlende Felder, bei denen die Konfidenz der Anreicherungsquelle hoch ist (über 90 %): automatisch füllen
- Datensätze ohne Aktivität und ohne Deal-Historie, die älter als 365 Tage sind: automatisch archivieren mit einem 30-Tage-Wiederherstellungsfenster
Was zur Überprüfung in die Warteschlange gestellt wird:
- Fuzzy-Match-Duplikate (gleicher Unternehmensname, verschiedene Domains): eine Merge-Empfehlung präsentieren, menschliche Bestätigung erfordern
- Fehlende Felder, bei denen die Anreicherungskonfidenz moderat ist (50 % bis 90 %): den Füllvorschlag mit Quellangabe vorschlagen, Bestätigung erfordern
- Veraltete aktive Deals (keine Aktivität in 90 Tagen, Deal-Status noch offen): den Deal-Inhaber alertieren, nicht automatisch schließen
- Anreicherungsdrift bei Schlüsselfeldern wie Unternehmensname oder Primärkontakt: zur Rep-Überprüfung markieren, nicht still überschreiben
Was nur markiert wird:
- Potenzielle Anreicherungsdrift mit niedriger Konfidenz: als "dies könnte veraltet sein" aufzeigen, ohne eine spezifische Korrektur vorzuschlagen
- Datensätze, die widersprüchliche Daten über Felder hinweg zu haben scheinen, ohne eine klare Lösung
Die Schwellenkalibrierung erfordert Feinabstimmung basierend auf Ihrer Datenumgebung. Beginnen Sie konservativ (mehr Überprüfung, weniger Automatisierung) und bewegen Sie sich in Richtung Automatisierung, wenn Sie Vertrauen in die Genauigkeit des Modells für Ihre spezifischen Datenmuster aufbauen.
Eine nützliche Denkweise: Wenn die KI bei diesem Konfidenzniveau einen Fehler macht, wie schlimm sind die Konsequenzen? Für exakt übereinstimmende Duplikate ist die Kosten einer falschen Zusammenführung behebbar. Für das Überschreiben der Informationen eines Schlüsselkontakts mit falschen Anreicherungsdaten ist die Konsequenz, dass ein Rep die falsche Person über einen laufenden Deal anruft. Unterschiedliche Risikoprofile erfordern unterschiedliche Schwellen.
Die vier Hygieneproblemstypen im Detail

Duplikate
Duplikat-Datensätze sind das häufigste CRM-Datenproblem und das rechentechnisch interessanteste zu erkennen. Exakte Übereinstimmungen auf E-Mail oder Domain sind einfach. Die schwierigen Fälle sind:
- "Acme Corp" und "Acme Corporation" (gleiche Unternehmen, verschiedene Namensstrings)
- Zwei Kontaktdatensätze für "John Smith" mit derselben Telefonnummer, aber verschiedenen aufgeführten Unternehmen (Jobwechsel, nicht verschiedene Personen)
- Ein Unternehmen, das übernommen wurde und jetzt sowohl als eigenständiger Account als auch als Tochtergesellschaft unter dem Erwerber existiert
KI-Deduplizierung verwendet mehrere Abgleichssignale: String-Ähnlichkeit beim Unternehmensnamen, Domain-Abgleich, Adress-Abgleich, Telefon-Abgleich und Netzwerkgraph-Analyse (Kontakte, die über verschiedene Pfade mit demselben Unternehmen verknüpft sind). Die Kombination von Signalen produziert einen Konfidenz-Score für jede potenzielle Zusammenführung.
Die wichtigste operative Entscheidung: Sollten Zusammenführungen automatisch erfolgen oder erfordert jede Zusammenführung eine menschliche Überprüfung? Für Organisationen mit hohem Volumen, die 50.000+ Datensätze betreiben, erzeugt die Anforderung einer menschlichen Überprüfung bei jeder Zusammenführung einen Rückstand, den niemand verarbeiten wird. Definieren Sie Ihren Automatisierungsschwellenwert und prüfen Sie monatlich eine Stichprobe von Auto-Zusammenführungen auf Genauigkeit.
Feld-Vollständigkeit
Pflichtfeld-Definitionen variieren je nach Organisation. Aber ein Mindeststandard für KI-gestützte Sales Operations umfasst: Unternehmensbranchenvertikale, Mitarbeiterzahlbereich, letztes Finanzierungsdatum und -runde, Primärkontakt mit verifizierter E-Mail und Sales-Qualified-Lead-Status.
KI füllt fehlende Felder aus Anreicherungsquellen: Clearbit, ZoomInfo, LinkedIn, Crunchbase und Unternehmens-Website-Daten. Die Qualität variiert nach Feldtyp. Mitarbeiterzahl und Finanzierung sind in der Regel zuverlässig. Branchenklassifikation kann driften (einige Anreicherungsanbieter verwenden unterschiedliche Taxonomiesysteme). Einzelne Kontaktdaten verschlechtern sich schnell, da Personen Jobs wechseln.
Vollständigkeitsraten als ständige RevOps-Metrik verfolgen. Anstreben von 90%+ Vollständigkeit bei Pflichtfeldern für aktive Accounts. MIT Sloans Forschung zur Datenqualität zeigt, dass Organisationen, die Datenqualität als kontinuierlichen Prozess statt als periodisches Projekt behandeln, drei- bis viermal bessere Ergebnisse aus ihren datengetriebenen Initiativen sehen. Wenn die Vollständigkeit unter den Schwellenwert fällt, prüfen, ob das Problem im Dateneingabe-Workflow liegt (Reps, die Felder überspringen) oder in der Anreicherungsabdeckung (Ihr Anreicherungsanbieter hat keine Daten für kleine Unternehmen in Ihrer Zielbranche).
Veraltete Datensätze
Veraltete Datensätze in der Pipeline sind das gefährlichste Hygieneproblem, weil sie falsches Umsatzvertrauen erzeugen. Ein Pipeline-Bericht, der 2,4 Mio. Dollar in offenen Deals zeigt, ist irreführend, wenn 800.000 Dollar davon in Deals stecken, die seit 6 Monaten keine Aktivität hatten.
KI-Erkennung veralteter Datensätze verwendet Aktivitäts-Zeitstempel-Daten: letzte E-Mail, letzter Anruf, letztes Meeting, letzte CRM-Notiz. Datensätze, die konfigurierbare Schwellen überschreiten (90 Tage für Früh-Stage-Deals, 180 Tage für Spät-Stage-Deals), werden markiert.
Die angemessene Aktion hängt vom Datensatztyp ab. Für offene Deals: den Deal-Inhaber alertieren, entweder Aktivität zu protokollieren oder den Deal als inaktiv zu markieren. Aktive Deals nicht automatisch schließen. Für Kontakte ohne Aktivität: prüfen, ob sie noch beim Unternehmen beschäftigt sind, bevor entschieden wird, was zu tun ist. Für Accounts ohne Aktivität: zwischen Accounts ohne aktive Sequence (in Ordnung) und Accounts unterscheiden, die in einer Nurture-Sequence sein sollten, es aber nicht sind.
Anreicherungsdrift
Das ist das stillste Problem und eines der schädlichsten. Die Daten waren beim Eintrag richtig. Die externe Realität hat sich geändert. Das CRM wurde nicht aktualisiert.
Kontakt-Jobwechsel sind am häufigsten: Der Champion, den Sie gepflegt haben, hat das Unternehmen vor 3 Monaten verlassen und Ihr Rep schickt noch E-Mails an die alte Adresse. Unternehmensübernahmen: Das Unternehmen, das Sie verfolgen, wurde gekauft und ist jetzt eine Tochtergesellschaft mit einem anderen Beschaffungsprozess. Finanzierungsereignisse: Das Unternehmen hat gerade eine Series-B-Runde abgeschlossen, was ihre Kaufkraft und wahrscheinlich ihren Zeitplan für Technologieentscheidungen verändert.
KI-Drifterkennung vergleicht CRM-Datensätze mit externen Signalen: LinkedIn-Änderungen (Kontakt-Titel oder Unternehmensänderungen), Nachrichtenereignisse (Übernahmeankündigungen, Finanzierungsrunden), Unternehmens-Website-Änderungen. Wenn ein Missverhältnis erkannt wird, erscheint es als Markierung statt als automatische Korrektur, weil der Kontext wichtig ist. "Der LinkedIn dieses Kontakts zeigt jetzt ein anderes Unternehmen" ist ein Signal, keine definitive Korrektur.
Kontinuierliche Hygiene vs. quartalsweise Bereinigung
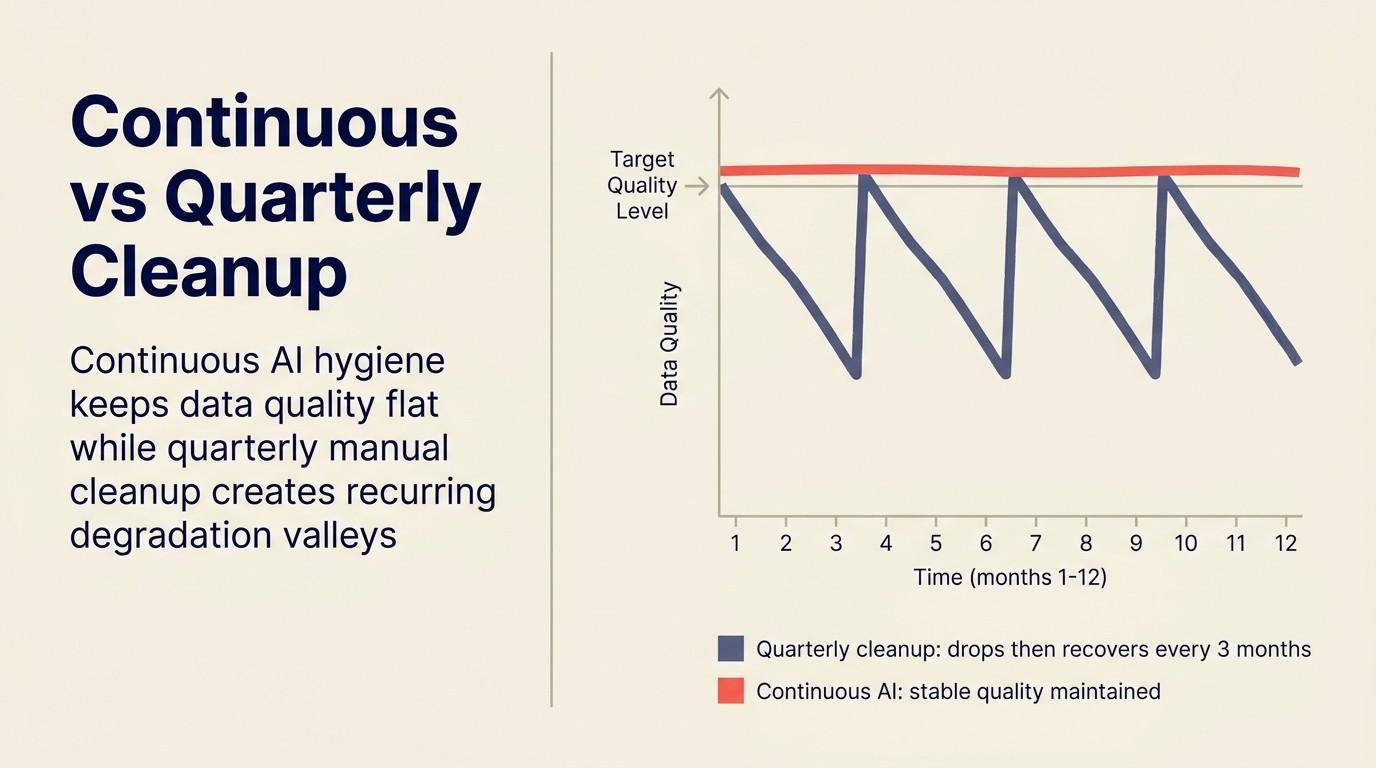
Die meisten Organisationen nähern sich der CRM-Hygiene als Projekt: quartalsweise Bereinigungskampagnen, in der Regel ausgelöst durch eine Prognoseüberprüfung, bei der Zahlen falsch aussehen, oder ein Audit, bei dem die Datenqualität verschlechtert erscheint.
Das Problem mit quartalsweisen Kampagnen ist die Datenverschlechterungskurve. Für eine Organisation mit aktivem Deal-Flow hier eine grobe Schätzung, wie schnell sich jeder Problemtyp ansammelt:
- Neue Duplikate: 5 bis 15 pro Woche aus Import-Ereignissen, manuellem Eintrag und Systemintegrationen
- Feld-Vollständigkeitslücken: jeder neue Datensatz, der ohne vollständigen Aufnahmeprozess erstellt wird
- Veraltete Datensätze: jeder Deal, der ins Stocken gerät, jeder Kontakt, der kalt wird
- Anreicherungsdrift: 2 bis 3 % der aktiven Kontaktdatensätze werden monatlich allein durch Jobwechsel ungenau
Wenn eine quartalsweise Bereinigungskampagne läuft, haben sich Monate der Verschlechterung angesammelt. Die Bereinigung ist jedes Mal ein größeres Projekt. Und sie verhindert keine Verschlechterung; sie stellt nur die Baseline wieder her, bevor der nächste Verfallszyklus beginnt.
Kontinuierliche KI-Hygiene verändert die Wirtschaftlichkeit. Statt monatelang angesammelte Probleme im Batch zu korrigieren, läuft die KI kontinuierlich und erkennt Probleme nah an dem Zeitpunkt, an dem sie auftreten. Die Wartungsarbeit pro Problem ist geringer. Die Datenqualitäts-Untergrenze ist höher. Und die KI-gestützten nachgelagerten Funktionen, Scoring, Routing, Forecasting, operieren alle das Quartal über auf saubereren Daten, nicht nur in den zwei Wochen nach einem Bereinigungsprojekt.
Upstream-Abhängigkeit: Warum saubere Daten nicht nur ein Hygieneanliegen sind
Jede KI-Funktion in Ihrem Sales-Stack ist nachgelagert zur CRM-Datenqualität. Diese Abhängigkeitskette macht Datenhygiene zu einer strategischen Investition, nicht nur zu einer operativen.
AI Lead Scoring Beyond Rules-Based Models hängt von CRM-Feld-Vollständigkeit für Scoring-Inputs ab. Fehlende Branchen- oder Mitarbeiterdaten produzieren nicht bewertete oder schlecht bewertete Datensätze.
From Call to CRM Update Automatically produziert sauberere CRM-Daten als Outputs, hängt aber davon ab, dass Account- und Kontaktdatensätze korrekt strukturiert sind, um zu wissen, wohin Updates zu schreiben sind.
Next Best Action for Each Open Deal verwendet Deal-Stage-Daten, letzte Aktivitätsdaten und Kontakt-Vollständigkeit zur Generierung von Empfehlungen. Veraltete Deal-Daten und fehlende Kontaktinformationen verschlechtern die Empfehlungsqualität direkt.
Der Kumulations-Effekt: CRM-Hygiene-Probleme produzieren keine isolierten Fehler. Sie verbreiten sich. Ein duplizierter Account-Datensatz bedeutet, dass Scoring-Signale auf zwei Datensätze aufgeteilt werden, wodurch der scheinbare Intent für beide reduziert wird. Ein veralteter Deal bläht die Pipeline-Prognose auf, was zu überoptimistischer Ressourcenplanung führt. Ein veralteter Kontakt bedeutet, dass Outreach an die falsche Person geht, die keine Antwort generiert, was das KI-Scoring-Modell als geringe Engagement interpretiert, was den Prioritäts-Score des Accounts senkt.
Saubere Daten verbessern jeden KI-Output nachgelagert. Es geht nicht darum, ordentliche Datensätze zu haben. Es geht um die Qualität jeder KI-generierten Entscheidung, die Ihre Organisation aus diesen Datensätzen trifft.
Implementierungstools
Rework CRM enthält KI-gestützte Datenhygiene als Teil seiner Sales-Operations-Schicht. Duplikaterkennung, Feld-Vervollständigung aus Anreicherungsquellen und Veraltungsmarkierung sind in den Account- und Kontaktverwaltungs-Workflow integriert. Das Governance-Modell (Auto-Fix vs. Review-Warteschlange) ist nach Feldtyp und Konfidenz-Schwelle konfigurierbar.
Salesforce Duplicate Management bietet native Duplikat-Regeln und Matching-Regeln mit automatisierter Erkennung und Zusammenführung. Drittanbieter-Tools (Cloudingo, DemandTools) erweitern dies mit ausgefeilterer Matching-Logik und Batch-Operationen. KI-Anreicherung wird typischerweise über Integration mit Clearbit oder ZoomInfo hinzugefügt.
HubSpot Data Quality Tools umfassen Duplikatsmanagement für Kontakte und Unternehmen mit einer dedizierten Review-Warteschlange. Feld-Level-Datengesundheits-Berichterstattung zeigt Vollständigkeitsraten über die gesamte Datenbank. HubSpots native Anreicherung (über sein Datenanreicherungs-Feature) füllt grundlegende Unternehmensfelder automatisch für identifizierte Datensätze aus.
Clay ist eine komponierbarer Option für Teams, die benutzerdefinierte Anreicherungs-Workflows aufbauen möchten. Mehrere Datenquellen verbinden (Clearbit, Apollo, LinkedIn, Domain-Daten), Anreicherungs-Wasserfälle definieren (Quelle A versuchen, auf Quelle B zurückfallen) und saubere Daten zurück in Ihr CRM pushen. Erfordert mehr Setup als native CRM-Tools, bietet aber mehr Flexibilität für nicht standardmäßige Anwendungsfälle.
Die Analyze-Fähigkeit behandelt die Erkennungs- und Klassifikationslogik, die der Hygieneanalyse zugrunde liegt. Der Artikel über Datenbereitschaft als Voraussetzung erklärt, warum saubere CRM-Daten die Torvoraussetzung für jedes KI-System in Ihrem Stack sind. Gartners 12 Maßnahmen zur Verbesserung der Datenqualität ist eine praktische Begleitressource für RevOps-Leader, die ein formelles Datenqualitätsprogramm zusammen mit ihrem KI-Hygienetooling aufbauen.
Das Infrastrukturargument
CRM-Hygiene ist der am wenigsten glamouröse Budgetposten in einem RevOps-Budget. Sie generiert direkt keinen Umsatz, fügt keine neue Fähigkeit hinzu und produziert keine Metrik, die in einem Board-Bericht erscheint.
Aber sie ist die Infrastruktur, die alles andere genau macht. Lead-Scoring-Genauigkeit, Routing-Präzision, Pipeline-Prognose-Zuverlässigkeit, Rep-Next-Action-Qualität: Alles davon hängt von der Datenqualität ab.
Das KI-gestützte kontinuierliche Hygienemodell verändert die Ressourcengleichung. Statt einem großen Bereinigungsprojekt pro Quartal, das 40 bis 80 Stunden RevOps-Zeit verbraucht, haben Sie ein Always-on-System, das Probleme an der Quelle erkennt und korrigiert. Der insgesamt erforderliche menschliche Zeitaufwand ist geringer. Die Datenqualität ist konsistent höher.
Und wenn Sie Ihrem Sales-Stack eine neue KI-Fähigkeit hinzufügen, beginnen Sie nicht mit einem Datenproblem. Sie bauen auf sauberen Daten. Das ist die kumulierte Rendite der Infrastrukturinvestition.
Datenhygiene ist kein Produkt, das Sie einmal kaufen. Es ist ein Prozess, den Sie kontinuierlich ausführen. KI macht es möglich, diesen Prozess ohne proportionales Headcount-Wachstum auszuführen. Das ist das Argument dafür. Und das ist der Grund, warum jedes andere KI-Tool in Ihrem Stack besser funktioniert, wenn Sie dieses richtig hinbekommen.
Rework Analysis: Bei RevOps-Deployments ist die wichtigste frühe Kalibrierungsentscheidung der Auto-Fix-Schwellenwert für Duplikat-Zusammenführungen. Ihn zu niedrig zu setzen (Auto-Zusammenführung von Fuzzy-Matches unter 85 % Konfidenz) erzeugt ein anderes Datenqualitätsproblem: legitime Unternehmen mit ähnlichen Namen werden fälschlicherweise zusammengeführt und produzieren eine Aktivitätshistorie-Kontamination, die schwieriger zu entwirren ist als die ursprünglichen Duplikate. Beginnen Sie bei 95 % Konfidenz für Auto-Zusammenführung, verifizieren Sie 50 zufällige Auto-Zusammenführungen im ersten Monat, dann passen Sie den Schwellenwert basierend auf der Fehlerrate an. Die meisten Teams können nach dem ersten Kalibrierungszyklus auf 90 % wechseln.
Organisationen mit kontinuierlichen KI-Datenhygieneprogrammen halten 90 %+ Feld-Vollständigkeit bei Pflichtfeldern aufrecht. Organisationen, die sich auf quartalsweise manuelle Bereinigung verlassen, erreichen durchschnittlich 65-75 % Vollständigkeit, mit der niedrigsten Genauigkeit in den sechs Wochen vor jedem Bereinigungszyklus. (MIT Sloan Datenqualitätsforschung)
Häufig gestellte Fragen
Was kostet schlechte CRM-Datenqualität tatsächlich?
Schlechte Datenqualität kostet das durchschnittliche B2B-Unternehmen laut Gartner-Schätzungen 12,9 bis 15 Millionen Dollar pro Jahr durch verschwendete Marketingausgaben, verlorene Verkaufschancen und operative Ineffizienzen. Auf der einzelnen Rep-Ebene verschwenden Vertriebsmitarbeiter 27 % ihrer Zeit mit dem Umgang mit schlechten Daten, was ca. 32.000 Dollar pro Rep jährlich kostet. Die organisatorischen Kosten steigen, weil jede KI-Funktion nachgelagert zum CRM (Lead-Scoring, Pipeline-Forecasting, Next-Best-Action) mit Sicherheit falsche Outputs aus schmutzigen Inputs produziert.
Wie schnell verfallen CRM-Daten?
B2B-Kontaktdaten verfallen mit ca. 2,1 % pro Monat, was bedeutet, dass 22-30 % aller Kontaktdatensätze ohne aktive Hygiene innerhalb eines Jahres ungenau werden. Jobwechsel sind der Haupttreiber: Kontakte wechseln kontinuierlich Arbeitgeber, Titel und E-Mail-Adressen. Unternehmensebenen-Daten (Firmografiken, Finanzierungsphase, Tech-Stack) ändern sich langsamer, sind aber genauso wirkungsvoll, wenn sie es tun, weil sie die Scoring-Modell-Inputs und Qualifikationskriterien betreffen.
Was ist die Konfidenz-Schwellen-Auto-Fix-Regel?
Die Konfidenz-Schwellen-Auto-Fix-Regel ist ein dreistufiges Governance-Modell für KI-CRM-Korrekturen: über 90 % Konfidenz auf einer bekannten Anreicherungsquelle löst automatische Korrektur mit einem Audit-Log aus; zwischen 50-90 % Konfidenz stellt eine Empfehlung zur menschlichen Überprüfung in die Warteschlange; unter 50 % produziert nur eine Markierung. Die Regel verhindert Unterautomatisierung (Rückstand, den niemand verarbeitet) und Überautomatisierung (sichere Fehler im großen Maßstab). Die Schwellenwerte sollten vierteljährlich durch Stichproben-Audit-Reviews von Auto-Korrekturen kalibriert werden. Die meisten Teams beginnen bei 95 % für den Auto-Fix-Tier und wechseln nach dem ersten Kalibrierungszyklus auf 90 %.
Welche vier Typen von CRM-Datenproblemen behandelt KI-Hygiene?
KI-CRM-Hygiene behandelt Duplikate (gleiche Unternehmen oder Kontakte in mehreren Datensätzen), Feld-Vollständigkeitslücken (Pflichtfelder leer), veraltete Datensätze (offene Deals oder Kontakte ohne Aktivität für 90-180+ Tage) und Anreicherungsdrift (Daten, die beim Eintrag genau waren, aber seitdem durch externe Veränderungen falsch geworden sind). Jeder Problemtyp verschlechtert unterschiedliche nachgelagerte KI-Funktionen: Duplikate teilen Scoring-Signale, fehlende Felder reduzieren Modellgenauigkeit, veraltete Datensätze blähen Pipeline-Prognosen auf, und Drift produziert Outreach an falsche Kontakte.
Warum ist quartalsweise CRM-Bereinigung unzureichend?
Quartalsweise Bereinigung behandelt Datenqualität als Projekt statt als Prozess. Für eine Organisation mit aktivem Deal-Flow akkumulieren sich neue Duplikate mit 5-15 pro Woche, Feld-Vollständigkeitslücken erscheinen mit jedem neuen Datensatz, veraltete Deals häufen sich kontinuierlich an, und 2,1 % der Kontakte driften monatlich. Wenn eine quartalsweise Kampagne läuft, haben sich Monate der Verschlechterung angesammelt. Kontinuierliche KI-Hygiene erkennt Probleme nah an dem Zeitpunkt, an dem sie auftreten, und reduziert sowohl den Rückstand als auch die Konsequenzen von Fehlern, die 90 Tage vor der Korrektur bestehen.
Wie beeinflusst die CRM-Datenqualität das KI-Lead-Scoring?
KI-Lead-Scoring-Modelle trainieren und laufen gegen CRM-Daten. Fehlende Felder (keine Branchenvertikale, keine Mitarbeiterzahl) produzieren nicht bewertete oder ungenau bewertete Datensätze. Duplikat-Datensätze teilen Intent-Signale auf zwei Accounts auf, sodass jeder weniger engagiert erscheint als er tatsächlich ist. Veraltete Deal-Daten verzerren Trainingssets durch das Einschließen inaktiver Deals, als wären sie lebendige Interessenten. Organisationen mit 90 %+ CRM-Vollständigkeitsraten sehen bedeutend höhere Lead-Scoring-Genauigkeit als Organisationen mit 65-75 % Vollständigkeit, weil das Modell vollständigere Signaldaten hat, mit denen es arbeiten kann.
Was Sie als Nächstes lesen sollten
- Workflow Copilot: AI as Peer-Level Assistant: das ACE-Muster hinter kontinuierlicher KI-Unterstützung in Sales-Workflows
- AI Lead Scoring Beyond Rules-Based Models: wie CRM-Datenqualität die Scoring-Modell-Genauigkeit direkt beeinflusst
- Next Best Action for Each Open Deal: die nachgelagerte KI-Funktion, die am stärksten von sauberen Deal-Daten abhängt
- AI Sales Ops Governance und Audit Trails: Governance-Frameworks für automatisierte Datenoperationen

Co-Founder, Rework.com
On this page
- Was CRM-Datenhygiene operativ bedeutet
- Wie der Workflow Copilot Hygiene handhabt
- Die Konfidenz-Schwellen-Auto-Fix-Regel
- Auto-Fix vs. Rep-Review-Schwellen
- Die vier Hygieneproblemstypen im Detail
- Duplikate
- Feld-Vollständigkeit
- Veraltete Datensätze
- Anreicherungsdrift
- Kontinuierliche Hygiene vs. quartalsweise Bereinigung
- Upstream-Abhängigkeit: Warum saubere Daten nicht nur ein Hygieneanliegen sind
- Implementierungstools
- Das Infrastrukturargument
- Was Sie als Nächstes lesen sollten