Buy vs. Build für KI-Sales-Operations

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Jedes RevOps-Team führt irgendwann dasselbe Gespräch. Der CTO sagt, die OpenAI-API kostet 0,002 Dollar pro 1.000 Token. Der VP Sales sagt, Gong kostet 120 Dollar pro Lizenz pro Jahr. "Warum zahlen wir Gong sechsstellige Summen, wenn wir das einfach selbst mit GPT bauen könnten?"
Die erste Runde ist eine vernünftige Frage. Die Antwort wird schnell kompliziert.
Die Buy-vs.-Build-Frage in KI-Sales-Ops ist keine einzelne Frage. Es sind vier separate Fragen, eine für jedes Muster im KI-Sales-Operator-Stack: Scoring and Routing, Meeting Intelligence, Generative Research und Workflow Copilot. Die Antwort ist für jedes anders. Das Verständnis der echten Kostenstruktur dauert etwa 20 Minuten ehrliche Kalkulation.
Die Build-Versuchung und ihre echten Kosten
Key Facts: KI-Sales-Ops Build vs. Buy Wirtschaft
- Ein realistischer Single-Pattern-KI-Sales-Ops-Build erfordert 1.000-2.000 Engineering-Stunden im ersten Jahr, was bei typischen loaded-Engineering-Kosten 100.000-200.000 Dollar ergibt, bevor API- oder Infrastrukturkosten anfallen. (Rework-Analyse)
- 75 % der B2B-Unternehmen berichten, dass ihre KI-Sales-Ops-Implementierungen bei gekauften Plattformen schneller und zu niedrigeren Gesamtkosten deployed wurden als bei eigenen Builds, hauptsächlich wegen unterschätzter Integrations- und Governance-Engineering-Aufwände. (Forrester, 2025)
- Die Enterprise-KI-Plattform-Ausgaben in B2B-Sales-Operations sollen von 2,2 Milliarden Dollar im Jahr 2022 auf 7,3 Milliarden Dollar bis 2030 wachsen, was die anhaltende Präferenz für Plattform-Käufe gegenüber Custom-KI-Builds widerspiegelt. (CPQ.se, 2025)
Bevor zur Muster-für-Muster-Analyse übergegangen wird, lohnt es sich, auszurechnen, was "bauen" eigentlich bedeutet.
Ein LLM-API-Aufruf ist günstig. Ein Production-KI-Sales-Ops-Feature ist es nicht. Was Bauen typischerweise erfordert:
Data-Pipeline-Engineering. Ihre CRM-Daten fließen nicht sauber in ein LLM. Sie benötigen ETL-Pipelines, die Deal-Datensätze normalisieren, Schema-Änderungen behandeln, wenn Ihr Vertriebsteam Felder neu konfiguriert, und nach einem Zeitplan aktualisiert, der die KI-Ausgaben frisch hält. Das ist ein 2-4-wöchiges Engineering-Projekt, dann laufende Wartung.
CRM-Integration. Write-back zu Salesforce oder HubSpot ist nicht trivial. Rate-Limits, Feld-Validierung, Fehlerbehandlung, Sync-Konflikte und Webhook-Zuverlässigkeit brauchen alle Production-Grade-Engineering. Fügen Sie 3-6 Wochen hinzu.
Prompt-Engineering und Governance. Prompts, die in Demos funktionieren, driften in Production. Jemand muss Prompt-Versionierung, Regressions-Tests und die monatliche Aufgabe besitzen, ob KI-Ausgaben noch korrekt sind, während Ihr Produkt und ICP sich entwickeln.
Model-Governance. Wenn Ihr Scoring-Modell eine schlechte Empfehlung produziert, die einen 200.000-Dollar-Enterprise-Lead an einen Junior-Rep sendet, wer überprüft die Entscheidung? Was ist der Audit Trail? Was ist das Rollback-Verfahren? Das sind keine Nachgedanken. Das ist Engineering-Scope.
Compliance-Arbeit. DSGVO-Artikel 22 gilt für automatisierte Entscheidungen, die Einzelpersonen betreffen. Wenn Ihre KI-Routing Leads ohne menschliche Überprüfung zuweist, könnte das in Scope fallen. Call-Recording-Zustimmungsanforderungen variieren je nach Rechtsraum. Jemand muss die Compliance-Schicht bauen und warten.
Eine realistische Schätzung für einen Single-Pattern-Build: 1.000-2.000 Engineering-Stunden im ersten Jahr. Bei 100 Dollar/Stunde loaded Cost für ein Mid-Market-Engineering-Team sind das 100.000-200.000 Dollar, bevor ein einziger Prompt geschrieben wurde. Auf 50 Lizenzen verteilt sind das 2.000-4.000 Dollar pro Lizenz im ersten Jahr nur für den Build-Cost, vor allen API-Kosten.
Jetzt vergleichen Sie das mit Gong bei 120 Dollar pro Lizenz pro Jahr oder Rework Sales Ops Standard bei rund 156 Dollar/Lizenz/Jahr für ein 10-Personen-Team. Bauen ist bei 50 Lizenzen fast nie günstiger. Manchmal bei 500.
Muster 1: Scoring and Routing: Kaufen gewinnt fast immer
Lead-Scoring erfordert historische Win-Loss-Daten, Feature-Engineering-Expertise und laufende Model-Retraining-Infrastruktur. Anbieter wie MadKudu, 6sense und Salesforce Einstein haben ihre Modelle an Zehnen von Millionen Deal-Ergebnissen über Tausende von Unternehmen trainiert. Ihr 500-Deal-Datensatz kann nicht mithalten.
Die mathematische Realität: Scoring-Modelle benötigen mindestens einige Tausend beschriftete Beispiele, um zuverlässige Wahrscheinlichkeitsschätzungen zu produzieren. Die meisten SMBs und Mid-Market-Unternehmen haben das nicht. Selbst Unternehmen mit 10+ Jahren CRM-Historie haben oft inkonsistente Beschriftung (Reps ändern manuell Deal-Phasen ohne dem Prozess zu folgen), was die Trainingsdaten vergiftet.
Ein Scoring-Modell zu kaufen bedeutet, ein Modell zu bekommen, das auf einem Datenvorteil trainiert wurde, den Sie nicht replizieren können. MadKudu behauptet, ihre Modelle verbessern sich nach dem Zugriff auf 6-12 Monate Ihrer eigenen Daten, die auf ihr Basismodell geschichtet werden. Das ist ein Hybrid: ihre Infrastruktur, Ihr Signal. Das Beste aus beiden Welten zu einem Bruchteil der Build-Kosten.
Routing-Logik ist leicht anders. Wenn Ihr Territory-Modell wirklich komplex ist (benutzerdefinierte Geographie, Produktspezialisierung, Sprachanforderungen, Partner-Channel-Routing), müssen Sie möglicherweise Routing-Regeln auf einem Scoring-Kauf aufbauen. Die meisten Unternehmen haben keine so ungewöhnliche Routing-Logik. Standard-Routing-Features in Salesforce, HubSpot und Rework decken 90 % der realen Anwendungsfälle ab.
Urteil: Kaufen. Bauen nur für benutzerdefinierte Routing-Regeln, die Off-the-shelf-Routing nicht ausdrücken kann.
Muster 2: Meeting Intelligence: Kaufen gewinnt, mit einem Integrations-Vorbehalt
Meeting Intelligence erfordert Audio-Verarbeitung, Speaker-Diarization (Trennung von "Sprecher A" von "Sprecher B"), Protokoll-Bereinigung und Themen-Extraktion. Das sind spezialisierte ML-Fähigkeiten, die Custom-Model-Entwicklung, Compute-Infrastruktur und laufende Qualitätsarbeit erfordern.
Speaker-Diarization allein ist ein forschungsschwieriges Problem. Die besten verfügbaren Modelle (von Google, AWS und spezialisierten Anbietern) machen noch immer Fehler bei schlechter Audioqualität, überlappender Sprache oder Anrufen mit mehr als drei Teilnehmern. Ihre eigene Diarization-Pipeline zu bauen bedeutet, Fehlerquoten zu akzeptieren, die kommerzielle Anbieter jahrelang reduziert haben.
Gong, Chorus (ZoomInfo), Fireflies und Clari Copilot haben alle stark in Protokoll-Qualität investiert. Sie haben auch in die Coaching-Analytics-Schicht darüber investiert: Talk-Time-Verhältnisse, Einwands-Erkennung, Frage-Häufigkeit, Themen-Tracking. Diese Analytik hat Jahre und erhebliche ML-Investitionen gekostet. Sie replizieren das nicht mit einem OpenAI-API-Aufruf und einem Wochenend-Projekt.
Die echte Frage bei Meeting Intelligence ist nicht Build vs. Buy. Es ist, welcher Anbieter sich am saubersten in Ihr CRM integriert. Gongs Salesforce-Integration ist tief und gut dokumentiert. Fireflies hat eine breitere Plattformabdeckung, aber flachere Analytik. Clari Copilot integriert sich eng in Claris Forecasting-Suite. Die Wahl hängt davon ab, was Sie downstream des Protokolls benötigen.
Urteil: Kaufen. Die Integrationstiefe zu Ihrem CRM und Coaching-Workflows ist die Entscheidungsvariable, nicht Build vs. Buy.
Muster 3: Generative Research: Hybrid ist wirklich durchführbar
Das ist das eine Muster, bei dem Bauen eine echte Option für ein Mid-Market-RevOps-Team mit Engineering-Ressourcen ist.
Account-Research-Briefings sind im Wesentlichen: Daten aus mehreren Quellen aufnehmen (LinkedIn, ZoomInfo, Bombora, Unternehmenswebsite, Nachrichten), mit einem LLM synthetisieren und ein strukturiertes Briefing generieren. Die Ingest- und Generate-Fähigkeiten hier erfordern keine spezialisierten ML-Modelle. Sie erfordern API-Integrationen und gutes Prompt-Engineering.
Ein Team mit einem RevOps-Engineer kann in 4-8 Wochen eine wettbewerbsfähige Account-Research-Pipeline bauen mit:
- OpenAI oder Anthropic API für Synthese
- ZoomInfo oder Apollo API für firmografische und Kontaktdaten
- LinkedIn Sales Navigator API für aktuelle Aktivitäten
- Einer Web-Scraping-Schicht für Nachrichten und Unternehmensupdates
- Einem Template-System für die Ausgabe-Formatierung
Die Wartungskosten sind niedriger als bei Scoring oder Meeting Intelligence, weil kein Modell neu trainiert werden muss. Wenn sich die Eingaben ändern (neue Datenquellen, neues Briefing-Format), bearbeiten Sie Prompts und Integrationslogik, keine ML-Modelle.
Clay.com hat sich als dominantes Tool für Teams herausgestellt, die den hybriden Weg wollen: ihre Plattform lässt Sie Datenquellen und LLM-Aufrufe kombinieren, ohne Infrastruktur-Code zu schreiben. Es ist näher an einem No-Code-Build als an einem Kauf. Apollo.ios Copilot und ZoomInfos Copilot sind näher an einem reinen Kauf.
Urteil: Hybrid ist durchführbar, wenn Sie einen RevOps-Engineer haben. Kaufen Sie Clay oder Apollo, wenn nicht. Reines Bauen nur, wenn Ihr Research-Workflow einzigartige Anforderungen hat, die kein Off-the-shelf-Tool handhabt.
Muster 4: Workflow Copilot: Kaufen für Multi-Tool, Bauen für CRM-nativ
Copilot-Features (Next-Best-Action-Vorschläge, Pipeline-Review-Briefings, CRM-Hygiene-Prompts, Draft-Follow-up-E-Mails) fallen in zwei Kategorien, die unterschiedliche Build-Wirtschaft haben.
CRM-native Copilot-Features (Aktionen, die innerhalb von Salesforce oder HubSpot stattfinden) sind mit CRM-APIs und einem LLM baubar. Wenn Sie bereits tief im Salesforce-Ökosystem sind, ist der Aufbau eines einfachen NBA-Vorschlags mit Salesforce Flow + OpenAI API ein legitimes 3-4-Wochen-Projekt. Die Daten bleiben im CRM, die Integration ist nativ und Sie behalten volle Kontrolle.
Multi-Tool-Copilot-Features (Aktionen, die CRM, Kalender, E-Mail, Slack und Anrufaufzeichnungen überspannen) werden schnell teuer zu bauen. Die Orchestrierung von Aktionen über fünf Systeme hinweg erfordert API-Zuverlässigkeits-Engineering für jede Integration, Fehlerbehandlung über System-Grenzen hinweg und sorgfältiges State-Management, wenn ein Write zu einem System erfolgreich ist, aber das nächste scheitert.
Outreach, Salesloft und Reworks KI-Sales-Schicht sind speziell für die Orchestrierung über den Vertriebs-Workflow-Stack gebaut. Ihre Multi-Tool-Integrationen stellen Jahre von Engineering-Investitionen dar. Eine vergleichbare Orchestrierungs-Schicht von Grund auf zu bauen ist ein 6-12-Monats-Engineering-Projekt.
Urteil: Bauen für einfache CRM-native Copilot-Features, wenn Sie Salesforce/HubSpot-Engineering-Erfahrung haben. Kaufen für Multi-Tool-Orchestrierung.
Das Pattern-By-Pattern-Buy-Build-Urteil
Das Pattern-By-Pattern Buy-Build Verdict ist das Entscheidungs-Framework, das Buy vs. Build als vier separate Fragen behandelt, eine pro KI-Sales-Operations-Muster. Scoring and Routing: kaufen (Anbieter-Trainingsdaten-Vorteil ist zu groß zum Replizieren). Meeting Intelligence: kaufen (Diarization- und Analytik-Infrastruktur-Investition ist zu tief zum Angleichen). Generative Research: hybrid (durchführbarer Build mit einem RevOps-Engineer über Clay oder LLM-APIs; kaufen Apollo oder ZoomInfo, wenn nicht). Workflow Copilot: hybrid (bauen für CRM-native Features, kaufen für Multi-Tool-Orchestrierung). Organisationen, die das Pattern-By-Pattern-Urteil vor der Budgetierung anwenden, kommen konsistent zu niedrigeren Jahr-1-Kosten als solche, die eine einzelne Buy-oder-Build-Entscheidung auf den gesamten KI-Sales-Ops-Stack anwenden.
Teams, die eine Muster-für-Muster-Buy/Build-Analyse durchführen, sparen durchschnittlich 30-40 % bei den KI-Sales-Ops-Investitionen im ersten Jahr im Vergleich zu Teams, die versuchen, alle vier Muster zu bauen oder eine Vollsuite zu kaufen, die unnötige Fähigkeiten enthält. (Forrester, 2025)
Entscheidungs-Framework: alle vier Muster
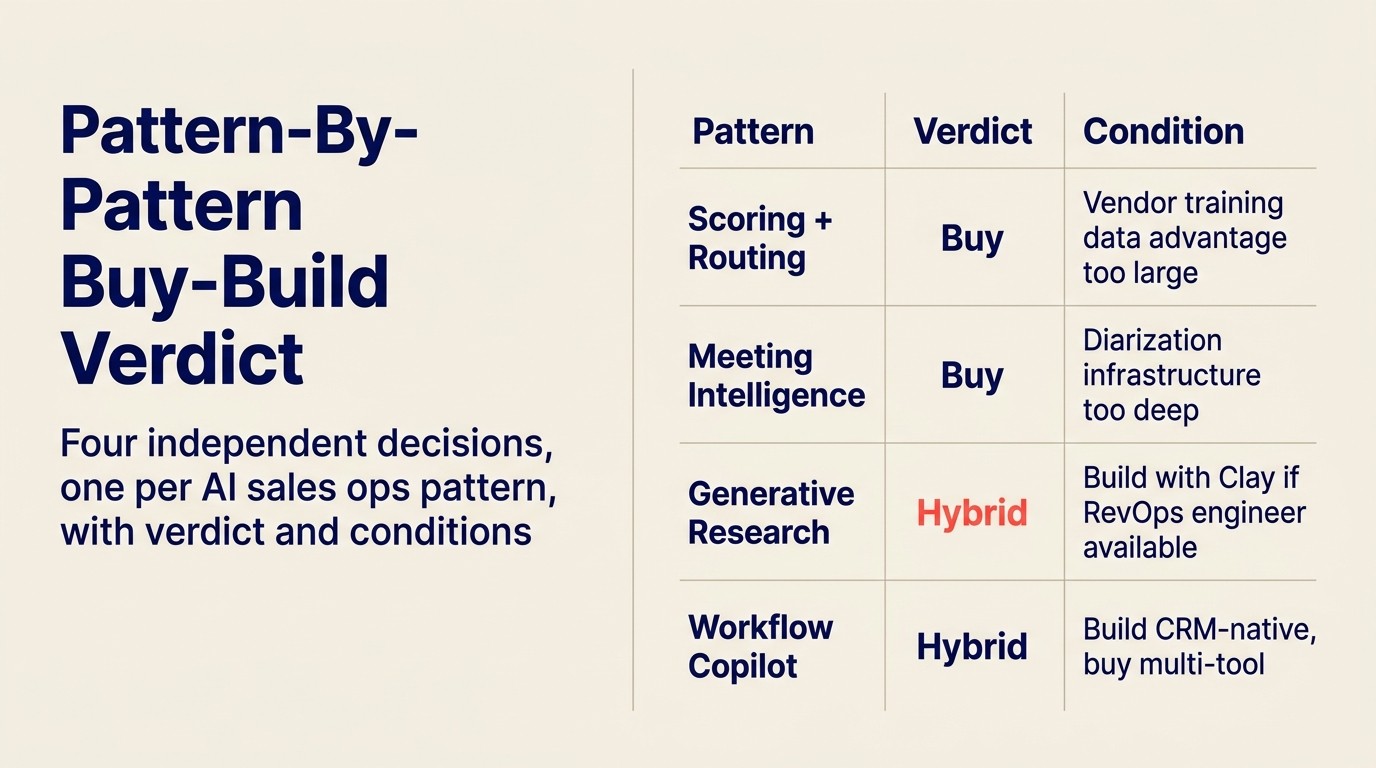
| Muster | Buy/Build | Bedingungen | Build-Kosten bei 50 Lizenzen |
|---|---|---|---|
| Scoring + Routing | Kaufen | Außer wenn Routing-Logik hochgradig benutzerdefiniert | 150.000 $+ um Anbieter-Modellqualität zu erreichen |
| Meeting Intelligence | Kaufen | Anbieter nach CRM-Integrationstiefe wählen | 200.000 $+ für Diarization + Analytik-Schicht |
| Generative Research | Hybrid | Bauen wenn RevOps-Engineer vorhanden; sonst Clay/Apollo kaufen | 50-80K $ durchführbar mit Engineer |
| Workflow Copilot | Hybrid | CRM-nativ bauen; für Multi-Tool kaufen | 80K \(für CRM-nativ; 200K\)+ für Multi-Tool |
Plattform vs. Point-Solution-Trade-offs
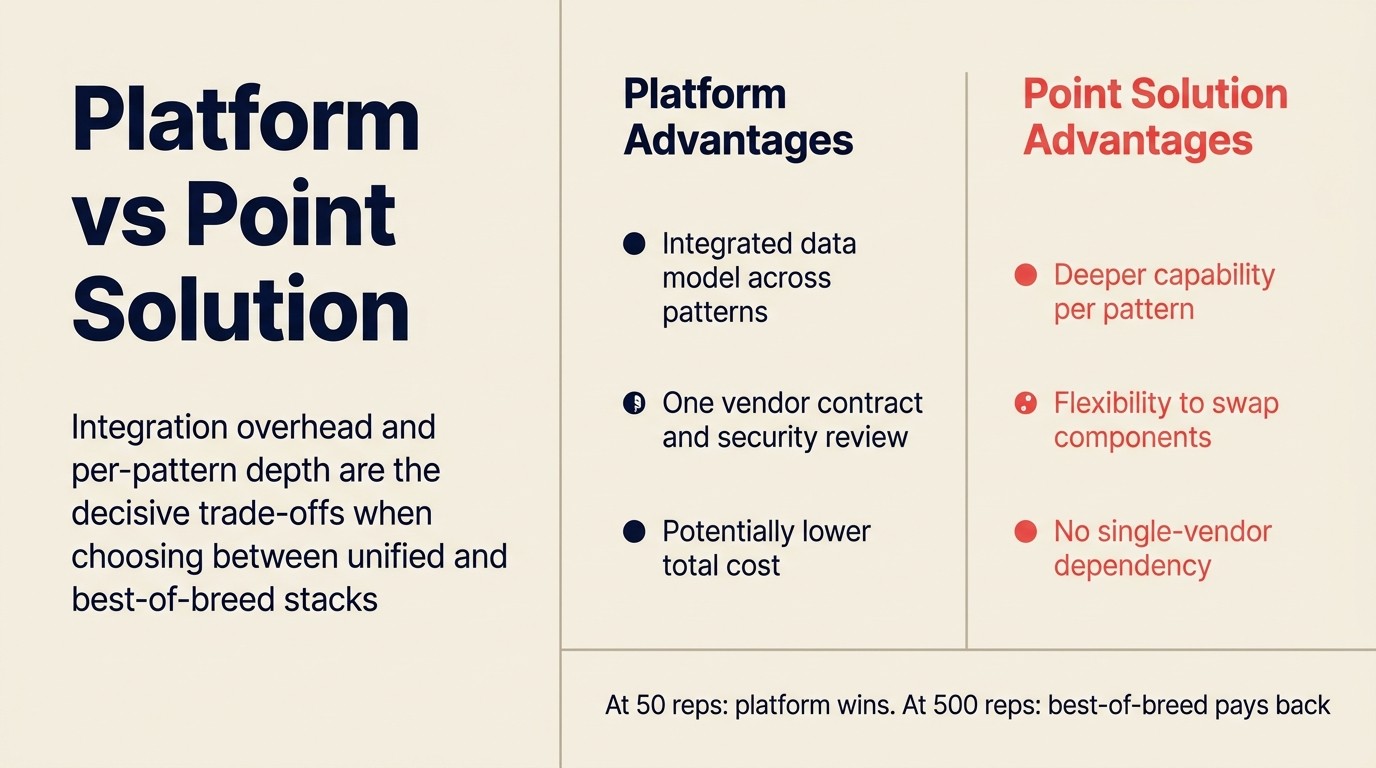
Sobald Sie sich zum Kaufen entschieden haben, ist die nächste Frage: Eine Plattform, die mehrere Muster abdeckt, oder Best-of-Breed-Tools pro Muster?
Plattform-Vorteile: Eine Anbieterbeziehung, ein Vertrag, integriertes Datenmodell über Muster hinweg (das Scoring-Modell sieht Protokolldaten, der Copilot sieht die Forecast-Daten), einfachere IT-Sicherheitsprüfung, potenziell niedrigere Gesamtkosten. Gartners Magic Quadrant für das CRM Customer Engagement Center kartiert die führenden Plattform-Anbieter und ihre KI-Fähigkeitstiefe über den Customer-Engagement-Lebenszyklus.
Point-Solution-Vorteile: Tiefere Fähigkeit pro Muster (der dedizierte Meeting-Intelligence-Anbieter schlägt in der Regel das im CRM integrierte), mehr Flexibilität zum Austauschen von Komponenten, keine Abhängigkeit von den Produktroadmap-Entscheidungen eines Anbieters für Ihren gesamten Sales-Ops-Stack.
Gong, Clari und Salesforce Einstein Suite positionieren sich als Multi-Muster-Plattformen. Rework Sales AI deckt Scoring, Meeting Intelligence und Workflow Copilot in einem einzigen Paket ab. MadKudu, Fireflies und Clay sind Point-Solutions, die sich miteinander integrieren.
Der Integrations-Cost ist der entscheidende Faktor. Wenn Sie einen dedizierten RevOps-Engineer haben, der Ihren Sales-Tech-Stack managt, geben Ihnen Point-Solutions mehr Kontrolle. Wenn Sie eine schlanke RevOps-Funktion betreiben und Integrations-Management eine Belastung ist, reduziert eine Plattform die Komplexität, auch wenn sie pro Muster leicht weniger leistungsfähig ist.
Bei 50 Reps ist der Integrations-Management-Overhead von 4-5 separaten KI-Tools erheblich. Bei 500 Reps mit einem 3-Personen-RevOps-Team können Sie sich in der Regel den Best-of-Breed-Ansatz leisten und die Fähigkeitsgewinne erzielen.
TCO-Vergleich: 50 Reps vs. 500 Reps
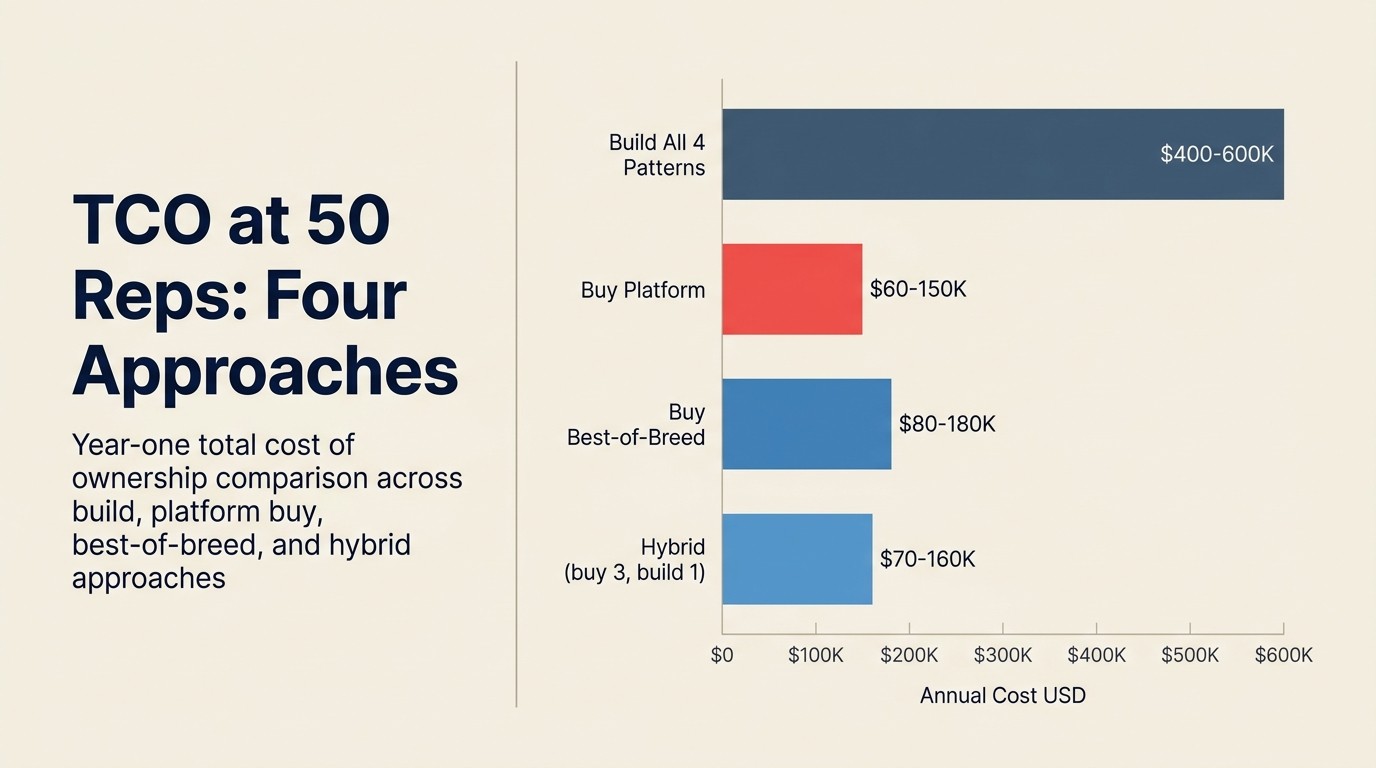
Bei 50 Reps:
| Ansatz | Jahreskosten | Notizen |
|---|---|---|
| Alle 4 Muster bauen | 400-600K \(Jahr 1; 150-200K\)/Jahr danach | Inkl. 2 Engineers, API-Kosten, Infrastruktur |
| Plattform kaufen (Rework/Clari/Gong) | 60-150K $/Jahr | Variiert erheblich je nach Anbieter und Tier |
| Best-of-Breed pro Muster kaufen | 80-180K $/Jahr | Scoring + MI + Research + Copilot-Tools kombiniert |
| Hybrid (3 kaufen, 1 Research-Layer bauen) | 60-130K $/Jahr + 1 Engineer |
Bei 50 Reps gewinnt Kaufen in fast allen Szenarien nach reiner Wirtschaft. Die einzige Ausnahme ist ein Unternehmen mit starker ML-Engineering-Kultur, das KI-Differenzierung als Produkt-Level-Anliegen betrachtet, nicht nur als Ops-Effizienzspiel.
Bei 500 Reps:
| Ansatz | Jahreskosten | Notizen |
|---|---|---|
| Scoring + Research bauen (MI + Copilot kaufen) | 300-500K $/Jahr | 3 Engineers; Gong + Plattform-Copilot kaufen |
| Plattform im Maßstab kaufen | 600K-1,5M $/Jahr | Enterprise-Tier-Preise bei 500 Lizenzen |
| Best-of-Breed pro Muster kaufen | 500K-900K $/Jahr | Verhandelte Enterprise-Verträge |
Bei 500 Reps ist die Build-vs.-Buy-Mathematik näher. Enterprise-Tier-Preise für KI-Plattformen bei 500 Lizenzen sind oft verhandelbar, können aber 1 Million Dollar jährlich übersteigen. Ein fähiges ML-Team, das Scoring- und Research-Schichten baut und wartet, während Meeting Intelligence und Copilot-Features gekauft werden, kann vergleichbare Fähigkeiten für weniger liefern.
Der ehrliche Hinweis: Bei 500 Reps haben Sie es auch mit komplexerer Data-Governance, Sicherheitsanforderungen und Model-Genauigkeits-Erwartungen zu tun, die das Bauen schwieriger machen. Die höhere Build-at-Scale-Kostenschätzung oben setzt Enterprise-Grade-Engineering voraus, keinen Startup-Build.
Die Governance-Frage, die für das Kaufen spricht
Es gibt einen Grund zum Kaufen, der nicht in Feature-Vergleichen oder TCO-Tabellen auftaucht: Audit-Trail-Anforderungen.
Wenn Ihr KI-Routing eine Entscheidung trifft, die das Territory oder die Vergütung eines einzelnen Reps beeinflusst, benötigen Sie einen dokumentierten Audit Trail. Wenn Ihr KI-Scoring beeinflusst, welche Leads bearbeitet werden und welche nicht, benötigen Sie Erklärbarkeit. DSGVO-Artikel 22 gilt potenziell für automatisierte Entscheidungen, die Einzelpersonen erheblich betreffen.
Kommerzielle KI-Sales-Ops-Anbieter haben Compliance-Teams, SOC-2-Zertifizierungen, Datenverarbeitungsvereinbarungen und dokumentierte Model-Governance-Prozesse. Eine Build-your-own-Lösung legt das alles auf Ihre Engineering- und Rechtsteams. Der Artikel zu KI-Sales-Ops-Governance und Audit Trails behandelt, was Audit Trails enthalten müssen. Das alles intern zu bauen ist machbar, wird aber fast universell unterschätzt. Für eine allgemeine Behandlung kartiert Governance-Anforderungen nach KI-Muster die Governance-Pflichten für jeden Mustertyp.
Das ehrliche Fazit
Kaufen, außer wenn Sie ein aktives ML-Team, saubere historische Daten und Zeit haben, was Sie bauen zu warten. Die Verlockung der LLM-API-Preisgestaltung ist real. Die Kosten der Infrastruktur um den LLM-Aufruf herum sind das, was die Mathematik fast immer übersieht.
Das eine Muster, bei dem Bauen wirklich wettbewerbsfähig ist, ist Generative Research, besonders wenn Sie Clay oder ein ähnliches No-Code-Orchestrierungstool haben, das die reine Engineering-Last reduziert. Beginnen Sie dort, wenn Sie mit dem Bauen experimentieren möchten.
Für alles andere: Kaufen Sie die Fähigkeit, verwenden Sie die freigegebene Engineering-Zeit für wettbewerbsmäßige Differenzierung, die wirklich für Ihr Produkt wichtig ist. Und bevor Sie irgendetwas kaufen, kartieren Sie zuerst die Anbieterlandschaft.
Sehen Sie sich die vollständige Anbieterlandschaft für KI-Sales-Operations für eine Karte an, welche Anbieter welche Muster zu welchen Preispunkten bedienen. Und für die musterweite Buy-vs.-Build-Behandlung, die alle Business-KI-Anwendungsfälle abdeckt, sehen Sie Buy vs. Build-Entscheidung für jedes KI-Muster.
Rework-Analyse: Der häufigste Buy-vs.-Build-Fehler, den wir in RevOps-Teams sehen, ist nicht das Bauen, wenn man kaufen sollte. Es ist das Kaufen einer Vollplattform, die Muster enthält, die sie noch nicht brauchen, und dann mit Adoption und Konfigurationskomplexität für Features zu kämpfen, die 12-18 Monate lang nicht relevant sein werden. Das Pattern-By-Pattern-Urteil verhindert das, indem es das Gespräch zu jedem Muster unabhängig zwingt. Ein Team bei 50 Reps, das mit Lead-Priorisierung (Scoring) kämpft, muss nicht gleichzeitig Meeting Intelligence und Workflow Copilot onboarden. Kaufen Sie, was den aktuellen Engpass löst. Fügen Sie Muster hinzu, wenn die operative Reife wächst.
Häufig gestellte Fragen
Ist es günstiger, KI-Sales-Ops-Tools zu bauen oder zu kaufen?
Für die meisten Teams unter 200 Reps gewinnt Kaufen nach Gesamtkosten. Ein Single-Pattern-KI-Sales-Ops-Build erfordert 1.000-2.000 Engineering-Stunden im ersten Jahr (100.000-200.000 Dollar bei typischen loaded Kosten), vor API-, Infrastruktur- oder Governance-Kosten. Kommerzielle Tools wie Gong kosten 120 Dollar pro Lizenz jährlich. Bei 50 Lizenzen sind das 6.000 Dollar vs. 100.000 Dollar+ für den äquivalenten Build. Bei 500 Lizenzen wird die Mathematik enger, und selektive Builds für Research- und Scoring-Schichten können wettbewerbsfähig sein.
Was ist das Pattern-By-Pattern Buy-Build Verdict?
Das Pattern-By-Pattern Buy-Build Verdict behandelt Buy vs. Build als vier unabhängige Entscheidungen, eine pro KI-Sales-Ops-Muster. Scoring and Routing: kaufen (Datenvorteil zu groß zum Replizieren). Meeting Intelligence: kaufen (Diarization-Infrastruktur zu tief zum Bauen). Generative Research: hybrid (durchführbar mit einem RevOps-Engineer über Clay; kaufen wenn keiner vorhanden). Workflow Copilot: hybrid (CRM-nativ bauen; Multi-Tool kaufen). Das Urteil pro Muster anzuwenden spart 30-40 % bei der Jahr-1-Investition gegenüber Alles-Bauen- oder Alles-Kaufen-Ansätzen.
Welches KI-Sales-Ops-Muster ist am meisten durchführbar intern zu bauen?
Generative Research (Account-Research-Briefings, Competitive-Intelligence-Synthese) ist der am meisten durchführbare interne Build. Es erfordert keine Custom-ML-Modelle, nur LLM-API-Integrationen und gutes Prompt-Engineering. Ein Team mit einem RevOps-Engineer kann in 4-8 Wochen eine wettbewerbsfähige Account-Research-Pipeline mit Clay.com plus OpenAI oder Anthropic API bauen. Clay ermöglicht speziell ein hybrides Modell: ihre Plattform übernimmt die Daten-Orchestrierung, Sie konfigurieren die Logik, ohne Infrastruktur-Code zu schreiben.
Warum bevorzugen Governance-Anforderungen das Kaufen von KI-Sales-Ops-Tools?
DSGVO-Artikel 22 gilt potenziell für automatisierte Lead-Routing- und Scoring-Entscheidungen. SOC-2-Compliance, Datenverarbeitungsvereinbarungen, Model-Erklärbarkeits-Dokumentation und Audit-Trail-Infrastruktur sind alle für ein konformes KI-Sales-Ops-Deployment erforderlich. Kommerzielle Anbieter haben Compliance-Teams, Zertifizierungen und dokumentierte Governance-Prozesse. Eine Build-your-own-Lösung legt das alles auf Ihre Engineering- und Rechtsteams, was in Buy-vs.-Build-Analysen konsistent unterschätzt wird.
Wann ändert sich die Buy-vs.-Build-Mathematik bei größeren Teamgrößen?
Bei 500+ Reps kann Enterprise-Plattform-Preisgestaltung (oft 600.000-1,5 Millionen Dollar jährlich) den selektiven Build für Scoring- und Research-Schichten wettbewerbsfähig machen. Ein fähiges 3-Personen-ML-Team, das zwei Muster baut und wartet, während Meeting Intelligence und Workflow Copilot gekauft werden, kann vergleichbare Fähigkeiten für 300-500.000 Dollar jährlich liefern. Aber der 500-Rep-Schwellenwert bringt auch komplexere Data-Governance, Sicherheitsanforderungen und Enterprise-Genauigkeits-Erwartungen, die Builds teurer machen. Die meisten Unternehmen erreichen den Build-wettbewerbsfähigen Schwellenwert später als erwartet.
Soll man eine Plattform oder Best-of-Breed-Tools pro KI-Sales-Ops-Muster kaufen?
Plattform-Vorteile: eine Anbieterbeziehung, integriertes Datenmodell über Muster hinweg, einfachere Sicherheitsprüfung, potenziell niedrigere Gesamtkosten. Best-of-Breed-Vorteile: tiefere Fähigkeit pro Muster, Flexibilität zum Austauschen von Komponenten, keine Single-Vendor-Abhängigkeit. Bei 50 Reps mit schlankem RevOps reduziert Plattform den Integrations-Overhead genug, um die Fähigkeitslücke zu überwiegen. Bei 500 Reps mit einem dedizierten RevOps-Team liefert Best-of-Breed in der Regel bessere Ergebnisse, weil Integrations-Management nachhaltig ist und jedes Muster im Maßstab mehr zählt.
Was als nächstes lesen
- Buy vs. Build-Entscheidung für jedes KI-Muster: der übergeordnete Artikel, der dieselbe Entscheidung über alle 10 KI-Muster abdeckt
- KI-Sales-Ops-Anbieterlandschaft 2026: die vollständige Anbieterkarte nach Muster und Preistier
- KI-Sales-Ops-Implementierungs-Roadmap: Ihre Buy-vs.-Build-Entscheidungen über die vier Muster sequenzieren
- KI-Sales-Ops-Governance und Audit Trails: die Compliance-Implikationen, die für die meisten Teams für das Kaufen sprechen

Co-Founder, Rework.com
On this page
- Die Build-Versuchung und ihre echten Kosten
- Muster 1: Scoring and Routing: Kaufen gewinnt fast immer
- Muster 2: Meeting Intelligence: Kaufen gewinnt, mit einem Integrations-Vorbehalt
- Muster 3: Generative Research: Hybrid ist wirklich durchführbar
- Muster 4: Workflow Copilot: Kaufen für Multi-Tool, Bauen für CRM-nativ
- Das Pattern-By-Pattern-Buy-Build-Urteil
- Entscheidungs-Framework: alle vier Muster
- Plattform vs. Point-Solution-Trade-offs
- TCO-Vergleich: 50 Reps vs. 500 Reps
- Die Governance-Frage, die für das Kaufen spricht
- Das ehrliche Fazit
- Was als nächstes lesen