Modos de Fallo: Cuando AI Sales Ops Sale Mal
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Los despliegues de AI sales ops que fallan generalmente no son fallos técnicos. El modelo funcionó bien. Las llamadas a la API retornaron a tiempo. La integración con el CRM se mantuvo. El problema fue organizacional: el equipo no confió en el sistema, o lo manipuló, o lo usó mal, o simplemente lo ignoró después de las primeras tres semanas.
Este es el artículo final de la colección. También es el más importante si está a punto de tomar una decisión de compra o de construcción. Porque si conoce lo que rompe estos sistemas antes de desplegarlos, tiene una probabilidad razonable de no romper el suyo. Para los modos de fallo a nivel de patrón en los 10 patrones de AI, consulte Anti Patrones: Combinaciones de AI que Fallan y Riesgo de Alucinación por Patrón de AI.
Siete modos de fallo. Cada uno ha ocurrido en empresas reales. Cada uno es prevenible.
Datos Clave: Riesgo de Despliegue de AI Sales Ops en 2026
- El 80.3% de los proyectos de AI no logran entregar su valor de negocio previsto, con el 33.8% abandonado antes de producción (RAND Corporation, 2025)
- El 76% de los despliegues de agentes de AI experimentaron fallos críticos dentro de los primeros 90 días en 847 implementaciones rastreadas
- El 70% de los equipos de ventas reportan resistencia activa a la adopción de AI, y solo el 20% de los vendedores usan herramientas de AI con frecuencia o diariamente
Los 7 Modos de Fallo de AI Sales Ops
Los siete modos de fallo descritos a continuación son el framework diagnóstico nombrado para los despliegues de AI sales ops. Cubren toda la superficie de fallo: resistencia humana (Modos 1 y 4), manipulación de datos (Modos 2 y 6), colapso de calidad del output (Modo 3), degradación del modelo (Modo 5), e inversión de la sobrecarga de gobernanza (Modo 7). Cada modo tiene un camino de prevención conocido y un camino de recuperación conocido.
Modo de Fallo 1: Rebelión de los Reps
Síntoma: Tasa de adopción por debajo del 40% a los 90 días. Los reps usan la herramienta cuando los managers están mirando, y no la usan cuando no lo están.
Causa raíz: El lanzamiento no involucró a los reps en la configuración, y la herramienta se enmarcó como monitoreo en lugar de asistencia. La meeting intelligence es el desencadenante más común. Un rep que se entera de que cada llamada está siendo grabada y de que su manager obtiene un dashboard de desempeño generado por AI no se inscribió para eso. Y si nadie le preguntó al respecto antes del lanzamiento, el resentimiento es inmediato.
Una empresa lanzó Gong a un equipo de 35 reps en 2024 sin una conversación previa al lanzamiento sobre qué datos revisarían y no revisarían los managers. En seis semanas, 12 reps estaban programando sus llamadas en teléfonos personales fuera del sistema. Ocho presentaron quejas a Recursos Humanos sobre vigilancia. El lanzamiento fue pausado. Cuatro meses de costo de suscripción desperdiciados, más el trabajo de implementación.
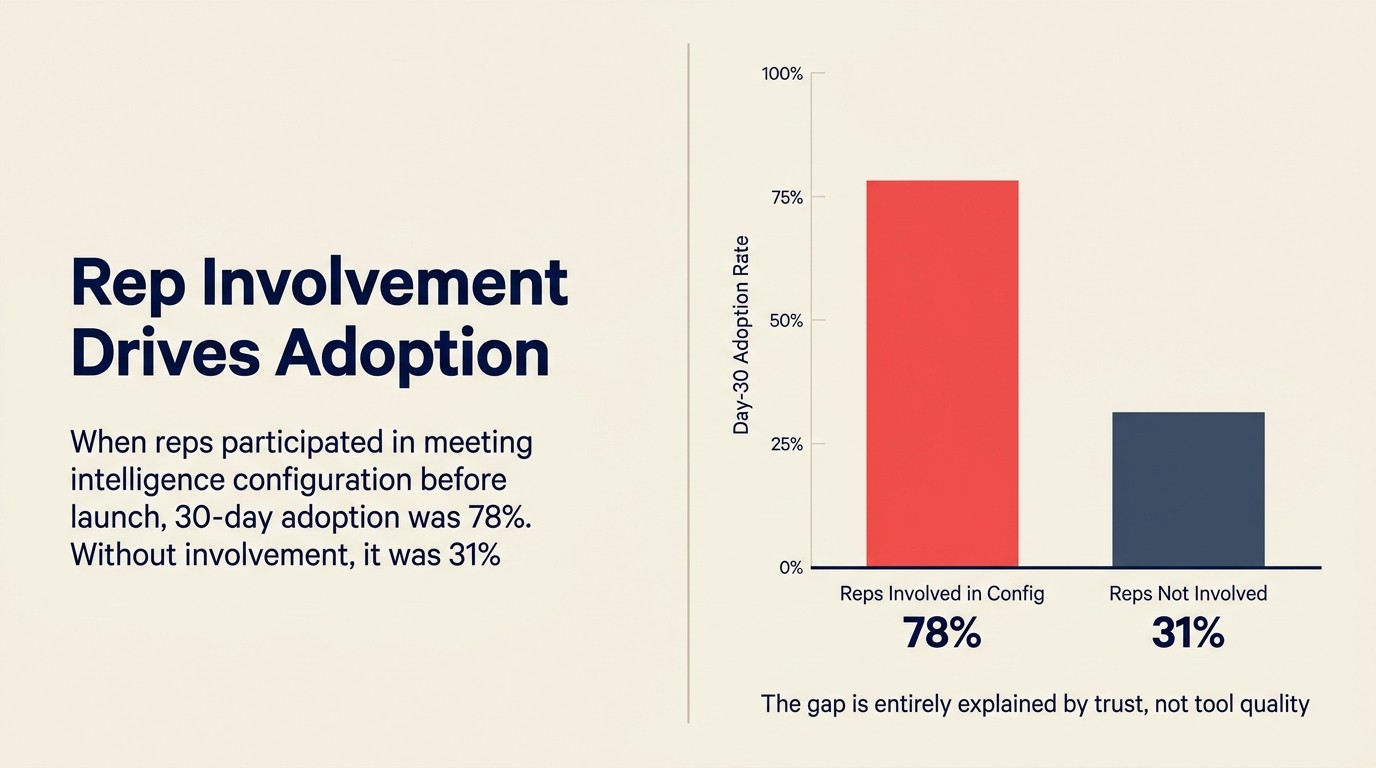
Cifras: Datos de uso interno de un equipo de RevOps de una empresa SaaS mid-market, compartidos en un panel de SaaStr 2025: cuando los reps estuvieron involucrados en las decisiones de configuración de meeting intelligence (qué campos se auto-rellenan, qué clips de llamadas podían acceder los managers, cómo se entregaría la retroalimentación de coaching), la adopción a 30 días fue del 78%. Cuando los reps no estuvieron involucrados, la adopción a 30 días fue del 31%. El AI Index 2025 de Stanford HAI encuentra consistentemente que la preparación organizacional y la confianza de los stakeholders, no el rendimiento del modelo, son los factores que separan los despliegues exitosos de AI enterprise de los fallidos.
Prevención: Ejecute una sesión de 2 semanas previa al lanzamiento con un grupo de muestra de reps. Déjeles ver la herramienta, preguntar qué querrían que hiciera, y presentar sus preocupaciones. Haga compromisos específicos: "Las grabaciones se usarán para coaching, no para evaluaciones de desempeño," y luego cúmplalos. Los reps que están ansiosos por la vigilancia se convierten en defensores cuando sienten que el sistema está diseñado para su beneficio, no en su contra.
Recuperación: Si la adopción ya ha colapsado, no presione. Pause, reconozca el problema, y comience el proceso de co-diseño con los reps que debería haber ocurrido antes del lanzamiento. Un relanzamiento enmarcado en torno a "escuchamos sus preocupaciones y hemos realizado estos cambios" recupera la confianza más rápido que cualquier otro enfoque.
Quotable Nugget: Cuando los reps están involucrados en las decisiones de configuración de meeting intelligence antes del lanzamiento, la adopción a 30 días alcanza el 78%. Cuando no están involucrados, cae al 31%. Esa brecha se explica completamente por la confianza, no por la calidad de la herramienta. (Datos de uso interno, equipo de RevOps SaaS mid-market, panel SaaStr 2025)
Modo de Fallo 2: Manipulación de las Puntuaciones de Leads
Síntoma: Las puntuaciones de leads tienden al alza en general durante 3-6 meses, incluso mientras las tasas de cierre se mantienen estables o disminuyen.
Causa raíz: Los reps aprendieron qué inputs impulsan puntuaciones altas y comenzaron a optimizar esos inputs manualmente. Si el modelo de scoring pondera "tamaño de empresa" significativamente y los reps pueden editar el tamaño de empresa en los registros de contactos, espere inflación. Si "visitas al sitio web" se correlaciona con la puntuación y los reps pueden desencadenar visitas al sitio web enviando un enlace por email, espere que enviar enlaces se convierta en un deporte.
Este es el problema de la Ley de Goodhart aplicado al lead scoring: una vez que una medida se convierte en un objetivo, deja de ser una buena medida. Los reps no hacen esto porque sean maliciosos. Lo hacen porque quieren más buenos leads, y descubrieron la palanca. El artículo sobre errores comunes en AI lead scoring cubre este y otros patrones de fallo de Scoring and Routing con profundidad.
Una empresa B2B SaaS que ejecutaba un modelo de scoring construido internamente vio las puntuaciones promedio de leads derivar de una media de 62 a una media de 79 en 8 meses. Las tasas de cierre cayeron del 22% al 14% en leads "con alta puntuación" en el mismo período. Cuando auditaron los datos, el 40% de los leads con alta puntuación tenían campos de tamaño de empresa que habían sido editados manualmente en los 30 días anteriores al scoring.
Prevención: No deje que los reps editen los campos con mayor peso en el modelo de scoring. Use campos poblados por el sistema (de su proveedor de datos, de logs de uso del producto, de analíticas web) para los inputs de scoring, no campos del CRM editables por los reps. Si debe usar campos editables por reps, incluya un log de auditoría de "última edición por" para que las anomalías de scoring sean visibles.
Recuperación: Audite las ponderaciones de características de su scoring contra sus datos reales de conversión. Si los leads con alta puntuación no están convirtiendo a tasas más altas que los leads con puntuación media, las puntuaciones han sido manipuladas o el modelo ha derivado. Vuelva a entrenar con datos fuente que los reps no puedan editar directamente, y refuerce los permisos de edición de campos en adelante.
Quotable Nugget: La Ley de Goodhart es el riesgo más subestimado en los despliegues de scoring de AI. En el momento en que una puntuación de lead se convierte en un input de cuota, los reps optimizan para la puntuación, no para la calidad del pipeline. La solución es usar inputs poblados por el sistema que los reps no puedan tocar, no más reentrenamiento del modelo.
Modo de Fallo 3: Los Emails Auto-Redactados Suenan Corporativos-AI
Síntoma: Las tasas de respuesta a emails caen después de implementar la redacción de emails asistida por AI. La forma más baja de este fallo: un rep envía un email redactado por AI a un prospecto con quien tiene una relación de larga data, quien responde "Esto no suena como tú. ¿Está todo bien?"
Causa raíz: Las herramientas de redacción de emails estándar entrenadas en corpus genéricos de emails de ventas producen emails genéricos de ventas. Son gramaticalmente correctos. Usan una estructura razonable. Y suenan exactamente como cualquier otro email de divulgación generado por AI que llega al mismo inbox.
Los patrones específicos que matan las tasas de respuesta:
- Aperturas que hacen referencia a "el panorama actual de [industria]" o "en el acelerado entorno de hoy"
- Oraciones que comienzan con "Quería comunicarme" (todas las AI escriben esto)
- Párrafos de propuesta de valor que enumeran características como viñetas ("Con nuestra plataforma, puede: [lista de cosas]")
- CTAs que dicen "¿Estaría abierto a una llamada rápida de 15 minutos?" (el cierre universal de AI)
Outreach personalizado generado por AI a escala cubre el enfoque basado en investigación que evita estos patrones.
Un equipo de ventas en una empresa SaaS de 200 reps rastreó las tasas de respuesta antes y después del lanzamiento de emails de AI. Antes: 8.2% de tasa de respuesta en outreach de primer contacto. Después de 60 días de redacción con AI con revisión del rep: 6.1%. Después de 90 días: 5.4%. Los reps estaban editando ligeramente los borradores de AI pero no reescribiéndolos fundamentalmente. La voz de AI había reemplazado la voz del rep.
Prevención: No use la redacción de emails con AI como atajo para escribir. Úsela como punto de partida que los reps reescriban genuinamente. El valor no está en el borrador; está en la estructura y los inputs de datos de personalización. Establezca un estándar de calidad simple: cualquier email redactado por AI que todavía contenga la frase "Quería comunicarme" o cualquier oración que comience con "Espero que este mensaje le encuentre bien" no sale.
Capacite a los reps sobre cómo se ven los patrones generados por AI y por qué los prospectos los reconocen. Un rep que entiende por qué el borrador de AI suena como AI es mucho más propenso a corregirlo que un rep que simplemente piensa que suena bien.
Recuperación: Si las tasas de respuesta han caído, tome una muestra de emails de AI enviados. Léalos en voz alta. Si alguno de ellos suena como un comunicado de prensa en lugar de un humano hablando con otro humano, ha encontrado el problema. Ejecute una prueba dividida: redactados por AI vs. escritos por el rep desde cero, mismos leads, misma semana. La brecha le dirá cuánto está perjudicando la voz de AI.
Quotable Nugget: Un equipo SaaS de 200 reps rastreó las tasas de respuesta antes y después del lanzamiento de emails de AI: 8.2% antes, 5.4% después de 90 días. Los reps no estaban omitiendo la revisión. Estaban editando ligeramente los borradores de AI y enviándolos. La voz de AI había reemplazado la voz del rep sin que nadie lo notara.
Modo de Fallo 4: Los Dashboards de Coaching Crean Ansiedad del Rep y Riesgo de Rotación
Síntoma: La rotación voluntaria aumenta entre los reps de nivel medio en los 6-12 meses posteriores al lanzamiento de meeting intelligence. Los temas de las entrevistas de salida se agrupan en torno a "sentirse micromanaged" o "estar siempre vigilado."
Causa raíz: Los dashboards de coaching de AI presentan métricas individuales del rep con una granularidad que se siente amenazante en lugar de formativa. Ratio de tiempo de habla. Cantidad de preguntas por llamada. Número de menciones de competidores manejadas. Duración del monólogo. Estas métricas están destinadas a ayudar a los reps a mejorar. Cuando se muestran en un dashboard visible para el manager con rankings, funcionan como un sistema de presión de desempeño.
Los reps de nivel medio (percentil 50 al 75) son los más vulnerables. Los que tienen el mejor desempeño se sienten seguros con sus números. Los que tienen el peor desempeño ya saben que están luchando. Los reps de nivel medio ven métricas que muestran que no están en la cima e interiorizan eso como "estoy fallando." Cuando los datos están siempre encendidos y siempre visibles, la presión no se libera entre las conversaciones de coaching.
Esto es real. Una encuesta de 2025 a 200 profesionales de ventas B2B realizada por la Sales Management Association encontró que el 34% de los reps en empresas que usan herramientas de coaching de AI reportaron un estrés laboral significativamente mayor que antes del lanzamiento. De esos, el 41% dijo que había comenzado a entrevistarse para otros puestos dentro de los 6 meses del lanzamiento.
Prevención: Separe las métricas de coaching de las métricas de desempeño en los dashboards visibles para los reps. Los reps deben ver sus propios datos de coaching y tendencias. No deben ver un ranking que los compare con sus pares en cada métrica todos los días. El dashboard de coaching es una herramienta de desarrollo, no un marcador.
Diseñe el flujo de trabajo de coaching alrededor de conversaciones, no de dashboards. El trabajo del manager es elegir una métrica por rep por semana, mostrar los datos, y discutir qué los impulsa. No compartir el dashboard completo y dejar que los reps saquen sus propias conclusiones.
Recuperación: Si los indicadores de riesgo de rotación están en aumento, audite cómo los managers están realmente usando los datos de coaching. El problema casi nunca es la tecnología. Es un manager que usa las métricas de AI como arma de desempeño en lugar de una herramienta de coaching. Capacitar a los managers en la entrega de retroalimentación con datos de AI importa más que cualquier cambio de configuración del dashboard.
Modo de Fallo 5: Los Modelos de Forecasting Se Sobre-Ajustan a Trimestres Recientes
Síntoma: La precisión del forecast es sólida durante 2-3 trimestres después del entrenamiento del modelo, luego comienza a degradarse. La precisión cae bruscamente cuando las condiciones del mercado cambian (entra un nuevo competidor, cambio de precios, vientos en contra macroeconómicos).
Causa raíz: Los modelos de forecasting de AI aprenden de los patrones históricos de deals. Son muy buenos prediciendo resultados que se parecen a los resultados pasados. Cuando el entorno cambia significativamente (diferentes dinámicas del comité de compra, nueva presión competitiva, desaceleración macro que reduce el gasto discrecional), los datos de entrenamiento del modelo ya no describen el entorno actual. El modelo no sabe que hay un cambio de régimen; sigue haciendo predicciones como si el pasado fuera todavía el presente.
Un ejemplo concreto: una empresa SaaS mid-market entrenó su modelo de forecasting de Clari en el Q3 2024 con 18 meses de datos de deals de un mercado en modo crecimiento. La investigación State of AI de McKinsey reporta que menos del 20% de las organizaciones monitorean sistemáticamente sus modelos de AI para detectar la deriva del rendimiento después del despliegue, lo cual es cómo la regresión por cambios de régimen pasa desapercibida hasta que un fallo al cierre del trimestre fuerza el problema. El modelo aprendió que los deals con engagement multi-hilo (3+ contactos activos en los últimos 30 días) tenían una tasa de cierre del 72% en la etapa de propuesta. En el Q2 2025, a medida que las condiciones económicas se endurecieron, los comités de compra comenzaron a ralentizarse incluso con contactos comprometidos. Los deals multi-hilo en la etapa de propuesta se cerraban al 51%. El modelo seguía prediciendo el 72%. El forecast fue un 28% superior al real durante dos trimestres antes de que alguien detectara la deriva.
Prevención: Establezca una cadencia de monitoreo de precisión del modelo antes del despliegue. Comparación mensual de tasas de cierre previstas vs. reales para los deals previstos del mes anterior. Si la brecha predicha vs. real crece más de 10 puntos porcentuales en meses consecutivos, señale para revisión de reentrenamiento. No espere el fallo al cierre del trimestre. Cuándo los patrones de AI se convierten en deuda técnica cubre el problema de deriva del modelo a nivel de patrón, incluyendo cómo reconocer cuándo un modelo ha derivado más allá de la recalibración.
Incluya un "protocolo de cambio de régimen" en su documentación de gobernanza. Si ocurre un evento de mercado importante (nuevo competidor, cambio de precios, cambio macroeconómico), desencadene una revisión de precisión fuera del ciclo. El juicio humano de forecasting debe ponderarse explícitamente contra el output del modelo después de un cambio de régimen, no tratarse como ruido que hay que superar.
Recuperación: Vuelva a entrenar con los 6-9 meses de datos más recientes ponderados más fuertemente que los datos más antiguos. Discuta explícitamente con su equipo de CS/Ventas qué cambió sobre el mercado, e identifique qué patrones históricos ya no son representativos.
Quotable Nugget: El 32% de los pipelines de scoring en producción experimentan cambios de distribución dentro de los primeros seis meses del despliegue. Los modelos sin monitoreo activo de precisión muestran una degradación del 14-19% en 18 meses, en comparación con dentro del 2.4% del rendimiento inicial para equipos que ejecutan revisiones mensuales de precisión. (IBM / Superwise AI, 2025)
Modo de Fallo 6: Los Modelos de Enrutamiento Refuerzan Sesgos Antiguos del ICP
Síntoma: Su scoring y enrutamiento de leads con AI prioriza consistentemente un segmento estrecho de leads. Otros segmentos (nuevas verticales hacia las que se está expandiendo, empresas más pequeñas que podrían ser buenos ajustes para PLG, cuentas internacionales) rara vez se trabajan y rara vez cierran. Eventualmente se da cuenta: la AI los ha estado filtrando sistemáticamente.
Causa raíz: Los modelos de scoring entrenados con datos históricos de ganancias aprenden qué leads se parecen a las ganancias pasadas. Si sus ganancias pasadas se concentraron en un segmento (digamos, empresas SaaS con sede en EE.UU. entre 100-500 empleados, VP o superior), el modelo aprende ese perfil como "alta puntuación" para su ICP. Los leads de nuevos segmentos de ICP que está apuntando activamente no coinciden con el patrón histórico y obtienen puntuaciones bajas. Se enrutan a nurture. No cierran, no porque sean malos leads, sino porque nunca se trabajaron. El modelo interpreta esto como confirmación de que el nuevo segmento es de baja calidad.
Este es un ciclo de retroalimentación que se compone. El modelo de scoring desprioriza los leads del nuevo segmento. Los reps no los trabajan. No cierran. El modelo ve tasas de cierre bajas de ese segmento. Las puntuaciones bajan más. El nuevo segmento es efectivamente excluido del pipeline por un modelo que nunca se ha actualizado para reflejar la estrategia actual.
Una empresa pasó 6 meses intentando entrar en manufactura mid-market (una nueva vertical) con una cadencia de GTM que incluía la contratación de un rep vertical dedicado. El rep se quejó de que los leads que recibía eran de baja calidad. Una auditoría reveló que sus leads obtenían consistentemente puntuaciones en el rango de 30-45 porque el modelo de scoring nunca había visto cerrar a una empresa manufacturera. Estaba siendo sistemáticamente perjudicada por el modelo. El patrón Scoring and Routing explica cómo el alcance de los datos de entrenamiento determina qué segmentos puede evaluar el modelo de manera confiable.
Prevención: Cuando agrega un nuevo segmento de ICP, anule explícitamente el scoring para ese segmento hasta que tenga 50-100 deals en el segmento para entrenar. Cree una regla de omisión de segmento: "Los leads que coincidan con los [nuevos criterios de ICP] obtienen enrutamiento de revisión manual independientemente de la puntuación."
Realice una auditoría trimestral de diversidad de segmentos en su población de leads puntuados. Si un segmento representa consistentemente el 80%+ de los leads con alta puntuación y tiene objetivos de expansión estratégica fuera de ese segmento, el modelo necesita calibración a nivel de segmento.
Recuperación: Vuelva a entrenar el modelo con muestreo estratificado por segmento. Asegúrese de que el conjunto de entrenamiento incluya suficientes ejemplos de segmentos subrepresentados para darle al modelo una señal justa. Hasta que el reentrenamiento esté completo, enrute los segmentos subrepresentados manualmente.
Modo de Fallo 7: La Sobrecarga de Auditoría Supera los Ahorros para Equipos Pequeños
Síntoma: El equipo de RevOps está pasando más tiempo gestionando la gobernanza de AI, revisando decisiones de AI, y respondiendo a disputas de reps de lo que la AI está ahorrando en tiempo de reps. La herramienta es neta negativa en eficiencia operacional.
Causa raíz: Frameworks de gobernanza de grado enterprise aplicados a despliegues de AI de equipos pequeños. Un equipo de ventas de 10 reps que ejecuta un modelo de lead scoring no necesita un comité de gobernanza del modelo, revisiones trimestrales de precisión, y un proceso estructurado de disputa de enrutamiento con SLAs de 48 horas. Pero si su líder de RevOps leyó una guía de gobernanza de AI enterprise e implementó el framework completo, ha creado una sobrecarga administrativa que escala mal para el tamaño de su equipo.
La versión específica de esto que es más común: meeting intelligence en 8-12 reps, con un flujo de trabajo de revisión de transcripciones completo, cadencia de análisis del dashboard de coaching, y proceso de revisión del brief del pipeline generado por AI superpuesto. Cada componente es defendible individualmente. Juntos, pueden agregar 4-6 horas semanales de sobrecarga de RevOps para un equipo que tiene una persona de Sales Ops.
Si esa persona estaba ahorrando 2 horas semanales de tiempo de reps en todo el equipo, ha creado una pérdida neta.
Prevención: Adapte la gobernanza al riesgo real y a la escala. Un modelo de gobernanza de startup (2-3 reglas, log en una hoja de cálculo, revisión mensual de 30 minutos) es el nivel correcto para un equipo de menos de 20 reps. La infraestructura de audit trail completa, los comités de gobernanza de modelos, y los dashboards de cumplimiento automatizados pertenecen a una escala de 100+ reps con un equipo de RevOps dedicado.
Antes de agregar cualquier requisito de gobernanza, pregúntese: ¿cuál es el peor caso si esto falla? Si la respuesta es "un rep disputa una decisión de enrutamiento una vez por trimestre," un log en una hoja de cálculo y un camino de disputa claro lo maneja. Si la respuesta es "violamos el GDPR y nos multan," construya la infraestructura adecuada. El NIST AI Risk Management Framework proporciona una estructura de gobernanza por niveles que se mapea directamente a la escala del despliegue, que es la plantilla correcta para calibrar el esfuerzo de gobernanza al nivel real de riesgo.
Recuperación: Audite honestamente su sobrecarga de gobernanza. Si algún proceso de gobernanza tarda más de 30 minutos por semana para un equipo de menos de 50 reps, probablemente está sobre-diseñado. Simplifique. El objetivo no es la gobernanza por sí misma; es la gobernanza que detecta problemas reales sin crear más carga de la que la AI ahorra.
Quotable Nugget: Los frameworks de gobernanza diseñados para equipos enterprise de 100 reps generan 4-6 horas semanales de sobrecarga de RevOps cuando se aplican a equipos de 8-12 reps. A esa escala, el costo de gobernanza supera los ahorros de tiempo de AI que se supone debe proteger. Adapte la gobernanza al riesgo real y al tamaño del equipo, no a la sofisticación de la documentación de cumplimiento de su vendor.
Resumen de riesgo de modos de fallo

Los siete modos de fallo no son igualmente probables ni igualmente costosos. Esta tabla mapea cada modo a su patrón desencadenante más común, el lag de detección, y el tiempo de recuperación típico para que pueda priorizar las inversiones previas al lanzamiento.
| Modo de Fallo | Desencadenante Principal | Lag Típico de Detección | Tiempo de Recuperación | Prevención Más Efectiva |
|---|---|---|---|---|
| Rebelión de Reps | Lanzamiento sin involucrar a los reps | 30-60 días | 3-4 meses | Sesión de co-diseño previa al lanzamiento |
| Manipulación de Puntuación de Leads | Inputs de scoring editables por reps | 90-180 días | 6-8 semanas (reentrenamiento) | Bloquear campos de scoring al lanzar |
| Emails Corporativos-AI | Revisión superficial del rep de los borradores | 60-90 días | 2-3 semanas (coaching) | Senior-Rep Voice Test antes de enviar |
| Ansiedad de Coaching / Riesgo de Rotación | Rankings visibles para todos los reps | 90-270 días | Variable; algunos reps no regresan | Separar datos de coaching de los de ranking |
| Deriva del Modelo (Forecasting) | Cambio de régimen del mercado | 60-90 días | 4-6 semanas (reentrenamiento) | Revisión mensual de predicho vs. real |
| Sesgo de ICP / Bloqueo de Segmento | Nueva vertical sin reglas de omisión | 90-180 días | 8-12 semanas (reentrenamiento + auditoría) | Regla de omisión de segmento al lanzar |
| Inversión de Sobrecarga de Gobernanza | Framework enterprise en escala SMB | 30-90 días | 1-2 semanas (simplificar) | Adaptar gobernanza al tamaño del equipo |
Fuentes: RAND Corporation, Sales Management Association, IBM, datos internos de equipos de RevOps (2025)
Lista de verificación previa al despliegue
Antes de lanzar en vivo cualquier patrón de AI sales ops, verifique lo siguiente:
Datos:
- 12+ meses de historial de deals limpio con etiquetas consistentes de ganado/perdido
- 70%+ de completitud en campos de contacto centrales (empresa, título, industria)
- Campos editables por reps bloqueados para inputs del modelo de scoring
- Anomalías de progresión de etapas auditadas y resueltas
Gobernanza:
- Lenguaje de consentimiento para grabación revisado por legal
- Revisión de GDPR/privacidad completada para el caso de uso de scoring
- Proceso de disputa de enrutamiento documentado y socializado
- Esquema del audit trail definido y configurado
- Rastreo de versiones del modelo en su lugar antes del despliegue del modelo
Change management:
- Grupo de muestra de reps involucrado en decisiones de configuración
- Compromisos específicos hechos sobre qué datos usarán y no usarán los managers
- Lanzamiento enmarcado como ahorro de tiempo para los reps, no como monitoreo para los managers
- Plan de adopción a 30 días (quién es responsable de la adopción del rep, cómo se mide)
- Capacitación del manager sobre el uso de datos de coaching de AI como herramienta de desarrollo
Monitoreo:
- Métricas de referencia capturadas antes del lanzamiento (tasas de respuesta, velocidad de enrutamiento, tasa de completitud del CRM)
- Revisión de adopción a 30 y 90 días programada en el calendario
- Cadencia de monitoreo de precisión del modelo definida (comparación mensual)
- Umbrales de alerta configurados para patrones de anomalías (inflación de puntuaciones, volumen de disputas de enrutamiento)
Framework de revisión de salud a 90 días

A los 90 días post-lanzamiento, revise estas métricas para cada patrón desplegado:
Scoring and Routing:
- Precisión de enrutamiento: ¿qué % de leads enrutados están siendo disputados o reasignados manualmente? (Objetivo: por debajo del 10%)
- Inflación de puntuaciones: ¿ha movido la puntuación promedio de leads más de 5 puntos desde la referencia? (Señalar si es así)
- Correlación de tasa de cierre: ¿los leads con alta puntuación están cerrando a una tasa más alta que los leads con baja puntuación? (Si no, el modelo puede estar siendo manipulado o derivando)
Meeting Intelligence:
- Tasa de participación en grabación: ¿qué % de las llamadas objetivo se están grabando? (Objetivo: por encima del 85%)
- Mejora de la tasa de completitud del CRM: ¿la escritura automática de AI mejoró el % de llamadas con notas completas del CRM?
- Pulso de satisfacción del rep: encuesta de una pregunta a los reps: "¿Meeting intelligence está haciendo su trabajo más fácil o más difícil?" (La puntuación neta debería ser positiva a los 90 días)
Generative Research:
- Adopción del brief de investigación: ¿qué % de los nuevos contactos de cuentas incluyen un brief generado por AI? (Objetivo: por encima del 60%)
- Tiempo de investigación pre-llamada: medido a los 90 días vs. referencia (Objetivo: reducción del 40%+)
- Autoevaluación de calidad del brief: calificación del rep sobre la calidad del brief (escala 1-5; objetivo por encima de 3.5)
Workflow Copilot:
- Tasa de aceptación de NBA: ¿qué % de las próximas acciones sugeridas se están actuando? (Objetivo: por encima del 30%)
- Reducción de tiempo administrativo: tiempo medido del rep en entrada de datos al CRM vs. referencia pre-AI
- Duración de las reuniones del pipeline review: antes y después del lanzamiento del brief de AI (Objetivo: reducción del 20%+)
Rework Analysis: En los siete modos de fallo, cinco tienen una raíz común: el despliegue fue enfocado como un proyecto tecnológico, no como un proyecto de change management. Los Modos 1, 3, 4, 6 y 7 todos involucran comportamiento humano y decisiones de diseño del equipo que se tomaron después de que el vendor fue seleccionado, no antes. El Modo 2 (manipulación) y el Modo 5 (deriva) son los dos modos de fallo genuinamente técnicos, y ambos tienen protocolos de prevención conocidos. Los equipos que evitan estos fallos típicamente hacen una cosa diferente: definen métricas de éxito antes del despliegue, no después de la primera revisión a 30 días. La plantilla de gobernanza previa al lanzamiento de Rework incluye la captura de métricas de referencia como un paso obligatorio en la Fase 0, que es por qué los equipos que la usan detectan los fallos de los Modos 2 y 5 un promedio de 6-8 semanas antes que los equipos que comienzan el monitoreo post-lanzamiento.
La conclusión honesta

Ninguno de estos modos de fallo es exclusivo de la AI. Los reps que no confían en una herramienta no la usan. Los sistemas que producen output de baja calidad se ignoran. Los procesos de gobernanza que crean más trabajo del que ahorran se abandonan. Estos son problemas de implementación tan antiguos como el software enterprise.
Lo que la AI agrega es escala y velocidad. Un modelo de AI que está derivando o es sesgado toma malas decisiones en cada lead del pipeline, no solo en los que un humano habría malcategorizado. Un dashboard de coaching de AI que crea ansiedad en los reps la crea para todos los reps del equipo simultáneamente. Los modos de fallo son los mismos; el radio de impacto es mayor.
Por eso la lista de verificación previa al despliegue y la revisión de salud a 90 días no son pasos opcionales. Son los hábitos operacionales que detectan los problemas antes de que se componen.
Las buenas noticias: cada modo de fallo documentado aquí es prevenible, y cada camino de recuperación es conocido. Las empresas que logran el AI sales ops no son más inteligentes que las que luchan. Son más pacientes con la Fase 0, más honestas con sus reps sobre lo que hacen las herramientas, y más disciplinadas en el monitoreo después del lanzamiento.
Comience con el roadmap de implementación. Construya gobernanza antes de necesitarla, no después de necesitarla y de que algo ya haya salido mal. Y lea este artículo de nuevo antes de su revisión a 90 días. Los modos de fallo de los que no se preocupó al lanzar son los que le van a encontrar.
Para la perspectiva a nivel de framework sobre por qué los despliegues de AI fallan antes de llegar siquiera a la capa de sales ops, Por Qué la Mayoría de los Frameworks de AI No Ayudan a los Operadores cubre los mismos problemas estructurales a nivel de ACE Foundation.
Qué leer a continuación
- Anti Patrones: Combinaciones de AI que Fallan: modos de fallo a nivel de patrón en el panorama completo de 10 patrones
- AI Sales Ops Governance y Audit Trails: el framework de gobernanza que previene la mayoría de estos modos de fallo
- AI Sales Ops Implementation Roadmap: el lanzamiento secuenciado que reduce el riesgo de despliegue
- Errores Comunes en AI Lead Scoring: tratamiento más profundo de los Modos de Fallo 2 y 6 aplicados al patrón de Scoring

Co-Founder, Rework.com
On this page
- Los 7 Modos de Fallo de AI Sales Ops
- Modo de Fallo 1: Rebelión de los Reps
- Modo de Fallo 2: Manipulación de las Puntuaciones de Leads
- Modo de Fallo 3: Los Emails Auto-Redactados Suenan Corporativos-AI
- Modo de Fallo 4: Los Dashboards de Coaching Crean Ansiedad del Rep y Riesgo de Rotación
- Modo de Fallo 5: Los Modelos de Forecasting Se Sobre-Ajustan a Trimestres Recientes
- Modo de Fallo 6: Los Modelos de Enrutamiento Refuerzan Sesgos Antiguos del ICP
- Modo de Fallo 7: La Sobrecarga de Auditoría Supera los Ahorros para Equipos Pequeños
- Resumen de riesgo de modos de fallo
- Lista de verificación previa al despliegue
- Framework de revisión de salud a 90 días
- La conclusión honesta
- Qué leer a continuación