AI Sales Ops Governance y Audit Trails

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
El ACE Framework traza una línea clara entre Generate y Execute. El artículo sobre la frontera Generate vs. Execute explica por qué esta distinción es fundamental para el despliegue seguro de AI. Generate produce un borrador que queda en revisión. Execute cambia el estado en el mundo: envía el email, actualiza el registro del CRM, enruta el lead. Esa línea importa porque Execute tiene consecuencias que no se revierten limpiamente.
En AI sales ops, las acciones de Execute ocurren docenas de veces al día sin ojos humanos en cada una: asignaciones de enrutamiento de leads, actualizaciones automáticas de campos del CRM, decisiones de scoring que determinan qué leads se priorizan, secuencias de seguimiento automático disparadas por transcripciones de llamadas. La mayoría de las veces, estas decisiones son correctas. Cuando no lo son, la organización necesita saber qué sucedió, por qué, y quién fue responsable.
La gobernanza en AI sales ops no es burocracia. Es la razón por la que la organización confía lo suficiente en la AI para darle más autonomía con el tiempo. Un equipo que no puede explicar por qué un lead fue enrutado a un rep particular eventualmente tendrá ese enrutamiento cuestionado en una disputa de compensación, una auditoría de sesgos, o una revisión de cumplimiento. Un equipo que puede mostrar el log de decisiones, la versión del modelo, y el estado de los datos de entrada tiene algo en qué apoyarse.
Qué necesita gobernanza en el stack de cuatro patrones
Datos Clave: Riesgo de Gobernanza de AI y Cumplimiento en 2026
- Las multas del GDPR ahora superan los €7.1 mil millones acumulados, con €1.2 mil millones emitidos solo en 2025. Más del 60% del total se ha emitido desde enero de 2023, reflejando la aceleración en la aplicación a medida que crece la adopción de AI. (Kiteworks, 2026)
- El 54% de las juntas directivas no están activamente involucradas en la gobernanza de AI, creando una exposición organizacional significativa para los despliegues de AI sales ops que afectan datos personales. (Improvado, 2025)
- La certificación SOC 2 Tipo II es ahora un requisito de facto para contratos de plataformas de AI por encima de $50,000, lo que significa que las herramientas de AI sin auditoría crean retrasos en la adquisición además del riesgo de cumplimiento. (MindStudio, 2025)
No todas las acciones de AI conllevan el mismo riesgo. Generar un borrador de sugerencia de email que un rep lee y descarta es de bajo riesgo. Enviar automáticamente un email de seguimiento a un prospecto sin revisión del rep es de alto riesgo. El modelo de gobernanza necesita distinguir entre ellos.
Esto es lo que cada patrón produce que potencialmente necesita gobernanza:
Scoring and Routing (Patrón 1):
- Puntuación del lead: un output numérico (por ejemplo, 87/100) que determina la priorización
- Asignación de enrutamiento: qué rep o equipo recibe el lead
- Decisiones de deprioritización: leads con puntuación suficientemente baja como para ser enrutados a nurture en lugar de ser trabajados
La decisión de enrutamiento tiene implicaciones directas en la compensación del rep si su equipo usa estructuras de compensación basadas en territorio o volumen de leads. También tiene posibles implicaciones del Artículo 22 del GDPR si el scoring involucra datos personales sobre el individuo que está siendo calificado. El artículo sobre requisitos de gobernanza por patrón de AI mapea estas obligaciones en los 10 patrones, no solo en Scoring and Routing.
Meeting Intelligence (Patrón 2):
- Log de consentimiento para grabación: ¿se obtuvo el consentimiento, por qué mecanismo, a qué hora?
- Escritura automática al CRM: ¿qué datos de transcripciones se escribieron automáticamente en qué campos?
- Acceso a datos de coaching: ¿qué managers han accedido a las grabaciones de llamadas de qué reps?
Grabar sin consentimiento es una violación legal en múltiples jurisdicciones. El log de consentimiento es un artefacto de cumplimiento, no solo un registro operacional.
Generative Research (Patrón 3):
- Atribución de fuentes del brief de investigación: ¿qué fuentes de datos se usaron para generar el brief?
- Cumplimiento de licencias de datos: ¿se siguieron los términos de servicio de los proveedores de fuentes?
Los briefs de investigación son acciones de Execute de menor riesgo porque típicamente informan decisiones humanas en lugar de desencadenar acciones automatizadas. El requisito de gobernanza es menor, pero la atribución de fuentes importa cuando un brief contiene información incorrecta que afecta una decisión de ventas.
Workflow Copilot (Patrón 4):
- Sugerencias de NBA mostradas a los reps: ¿qué se sugirió, se actuó sobre ello?
- Emails auto-redactados: ¿cuál fue el input del prompt, qué se generó, qué cambió el rep, qué se envió?
- Actualizaciones automáticas de higiene del CRM: ¿qué campos se cambiaron automáticamente, de qué valor a qué valor?
- Datos del pipeline review: ¿cómo se generaron las señales de riesgo, qué inputs de datos las desencadenaron?
Los tres modelos de gobernanza
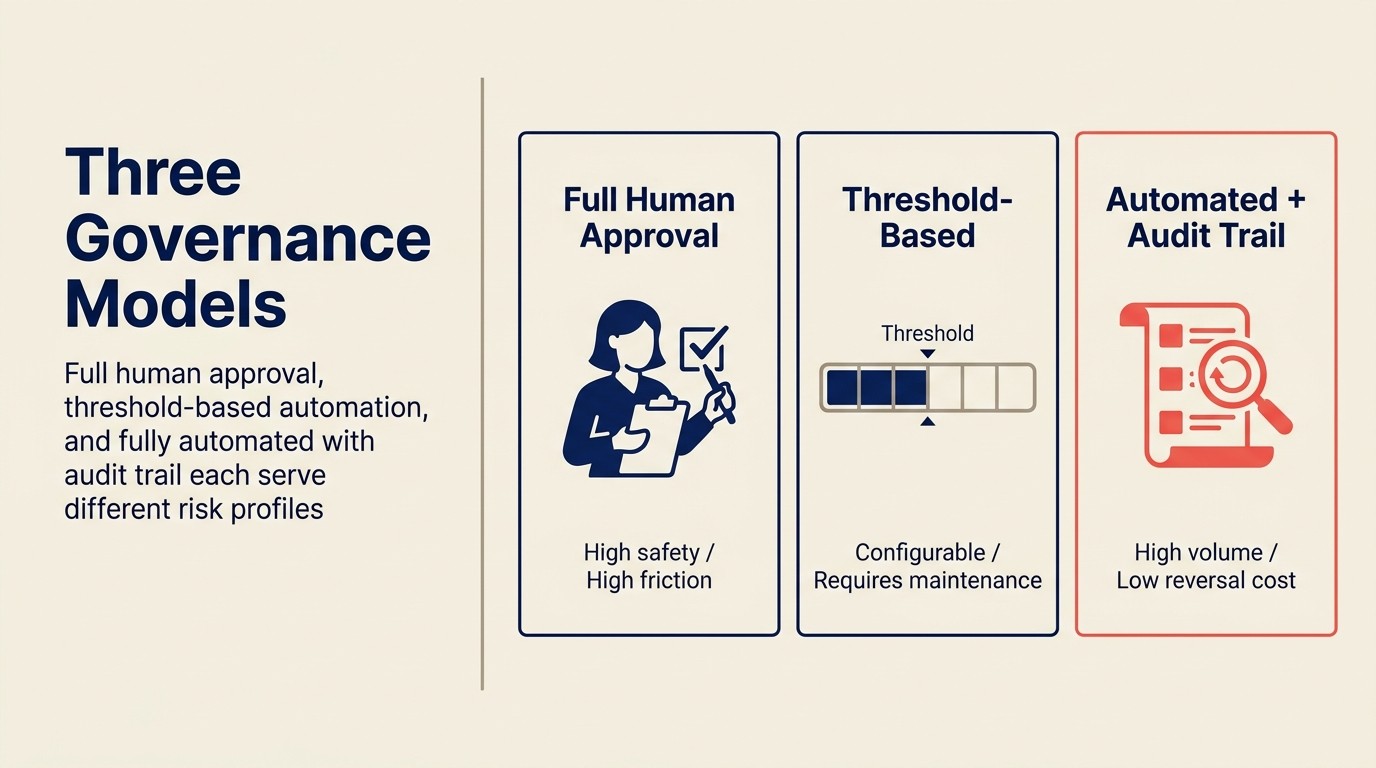
Para cada acción de Execute en su stack de AI, necesita elegir uno de tres modelos de gobernanza:
Aprobación humana completa
Cada acción generada por AI requiere aprobación humana explícita antes de la ejecución.
Cuándo usar: Acciones de alto riesgo (emails a prospectos enterprise, decisiones de enrutamiento que afectan la compensación), contextos legalmente sensibles, al inicio de un despliegue de AI cuando aún está construyendo confianza en el modelo.
Trade-off: Alta seguridad, alta fricción. Los reps se convierten en cuellos de botella. El ahorro de tiempo de la AI se compensa parcialmente por la carga de aprobación. Para un copilot que genera 20 borradores de email al día, requerir aprobación completa en cada uno convierte una herramienta que ahorra tiempo en una carga cognitiva.
Configuración práctica: Cola de aprobación en el CRM o la herramienta de email. La AI genera, el humano revisa, click para enviar/confirmar. Establezca un SLA de 24 horas en las aprobaciones para que las acciones generadas no queden en cola hasta quedar obsoletas.
Automatización basada en umbrales
Las acciones por debajo de un umbral de confianza (o por debajo de un umbral de riesgo) se ejecutan automáticamente. Las acciones por encima del umbral requieren aprobación humana.
Cuándo usar: La mayoría de los stacks maduros de AI sales ops. La calibración del umbral es la variable clave.
Ejemplo: Enrutamiento de leads. Leads puntuados por encima de 80 Y que coincidan con una regla de territorio única y clara: enrutamiento automático. Leads puntuados entre 40-80 O que involucren una regla de territorio compartida: en cola para revisión de Sales Ops. Leads puntuados por debajo de 40: enrutamiento automático a nurture. De esta manera, las decisiones claras se automatizan; las ambiguas obtienen juicio humano.
Trade-off: Requiere mantenimiento continuo de umbrales. A medida que mejora la precisión del modelo, puede elevar el umbral de auto-ejecución. A medida que cambia su negocio (nuevos territorios, nuevos productos), los umbrales necesitan revisión. Alguien tiene que ser responsable de esto.
Configuración práctica: Configuración de umbral en su plataforma de AI. Dashboard de monitoreo que muestra el volumen de la cola de aprobación (si la cola está persistentemente grande, los umbrales son demasiado conservadores; si la calidad de las aprobaciones se está degradando, los umbrales son demasiado agresivos).
Completamente automatizado con audit trail
Las acciones se ejecutan automáticamente. Todo se registra. La revisión humana ocurre después del hecho, mediante auditoría periódica en lugar de aprobación por acción.
Cuándo usar: Acciones de alta confianza, alto volumen y bajo costo de reversión. Completitud de campos del CRM desde transcripciones. Etiquetado de fuente de lead. Actualización de timestamps de "último contacto". Acciones donde el costo de ser incorrecto es bajo y la revisión manual crearía más carga que valor.
No apropiado para: Acciones que afectan la compensación, acciones que involucran decisiones de datos personales reguladas, comunicaciones de cara al cliente.
Configuración práctica: Log de auditoría completo con revisión semanal por el Sales Ops Manager. Reglas de alerta para patrones de anomalías (por ejemplo, si más del 5% de los leads auto-enrutados en una semana están siendo reasignados manualmente, eso es una señal de que el modelo está derivando).
La aplicación del GDPR contra las decisiones automatizadas impulsadas por AI se está acelerando. Un banco con sede en Berlín fue multado con €300,000 en 2023 por no informar de manera transparente a un candidato sobre el razonamiento detrás de un rechazo automatizado de solicitud de crédito. Los equipos de B2B sales ops que enrutan automáticamente leads basándose en scoring sin documentación de explicación son estructuralmente similares.
El 4-Pattern Audit Log Standard
El 4-Pattern Audit Log Standard especifica el conjunto mínimo de campos requeridos para un audit trail defendible para cada uno de los cuatro patrones de AI sales ops. Para Scoring and Routing: timestamp, tipo de acción, ID del lead, versión del modelo, características de entrada con valores, puntuación de output, rep asignado, alternativas consideradas, y bandera de anulación. Para Meeting Intelligence: timestamp de grabación, método y timestamp de consentimiento, campos del CRM escritos, valores antes y después, log de acceso del rep. Para Generative Research: timestamp de generación del brief, fuentes de datos usadas, hash del contenido del brief, canal de entrega. Para Workflow Copilot: tipo de sugerencia, condición de disparo, estado de entrada, contenido generado, acción del rep (aceptado/descartado/modificado), resultado final. Las organizaciones con estos cuatro logs de auditoría pueden responder a cualquier disputa de enrutamiento, consulta de cumplimiento, o revisión de precisión del modelo sin reconstruir decisiones desde la memoria.
Especificación de campos del audit trail
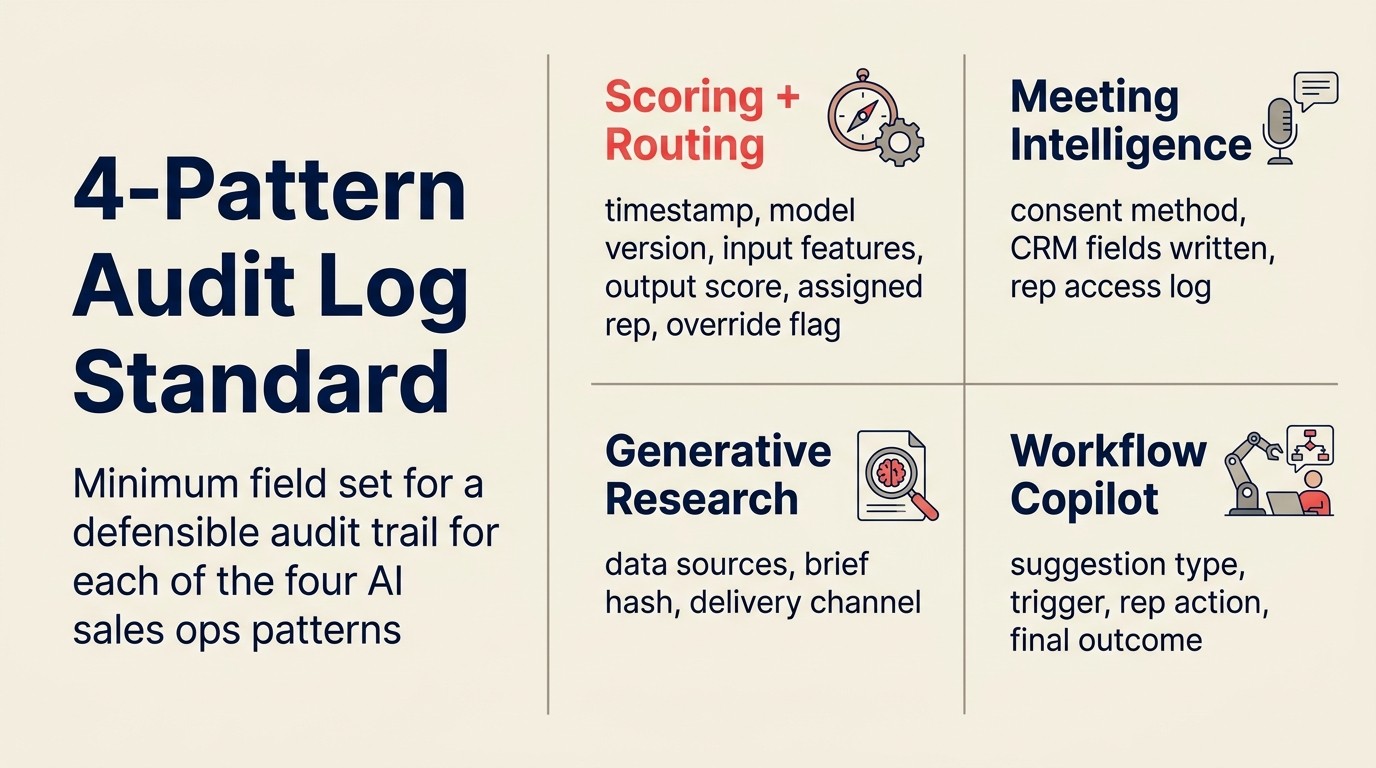
Un buen audit trail para una acción de AI sales ops contiene los siguientes campos. Este es el mínimo para una gobernanza defendible; el cumplimiento enterprise puede requerir campos adicionales:
Para una decisión de lead scoring:
timestamp: 2026-05-19T09:23:14Z
action_type: lead_score
lead_id: CRM-1234567
model_id: scoring-model-v2.3
model_version_date: 2026-03-01
input_features: {
company_size: "50-200",
industry: "SaaS",
title: "VP of Operations",
intent_score: 72,
website_visits_30d: 4,
email_opens_30d: 3
}
output_score: 87
confidence: 0.91
action_taken: routed_to_rep_sarah_jones
alternatives_considered: [rep_alex_chen (score 0.87), rep_michael_kim (score 0.84)]
human_reviewer: null
override: false
Para un email auto-redactado:
timestamp: 2026-05-19T14:11:02Z
action_type: email_draft
deal_id: CRM-DEAL-98765
prompt_inputs: {
contact_name: "Jennifer Wu",
last_call_summary: "discussed budget approval timeline",
days_since_last_contact: 5,
deal_stage: "Proposal Sent"
}
generated_text: "[texto completo del borrador]"
rep_edits: "[lo que el rep cambió antes de enviar]"
final_sent_text: "[texto real enviado]"
rep_id: REP-44
sent: true
sent_timestamp: 2026-05-19T14:38:22Z
Para una asignación de enrutamiento:
timestamp: 2026-05-19T10:05:33Z
action_type: lead_route
lead_id: CRM-9876543
routing_rule_applied: "territory_rule_northeast_enterprise"
input_state: {
lead_location: "Boston, MA",
company_size: "500-1000",
lead_score: 87,
product_interest: ["Sales Ops", "Work Ops"]
}
assigned_to: REP-12 (Sarah Jones)
alternatives_evaluated: [REP-15, REP-22]
reason: "territory match + highest capacity score"
human_override: false
override_by: null
Estos registros no necesitan vivir en un sistema propio. La mayoría de las plataformas de CRM pueden almacenar registros de log personalizados. Una tabla de auditoría dedicada en Salesforce o una arquitectura Webhook → servicio de registro funciona para la mayoría de los equipos mid-market.
Versionado de modelos y gestión del cambio
Cuando vuelve a entrenar o actualiza un modelo de scoring, el audit trail debe rastrear qué versión del modelo tomó qué decisión. Esto no es opcional.
He aquí por qué: suponga que su modelo de scoring de marzo de 2026 (v2.1) fue encontrado posteriormente con sobre-ajuste al tamaño de la empresa, subponderando las señales de intención. Vuelve a entrenar en mayo de 2026 (v2.3) con ponderaciones de características corregidas. Si un rep disputa una decisión de enrutamiento de leads de abril de 2026, necesita poder mostrar qué modelo tomó esa decisión, cuáles eran sus ponderaciones de características, y por qué la decisión era defendible dado la información disponible en ese momento.
Sin el versionado del modelo en el audit trail, no puede responder esa pregunta. Solo puede mostrar la lógica del modelo actual, que puede haber cambiado.
Requisitos mínimos de gobernanza del modelo:
- Cada despliegue del modelo recibe un identificador de versión y una fecha de despliegue
- Todas las decisiones de scoring se registran con la versión del modelo que las produjo
- Changelog del modelo que documenta qué cambió entre versiones y por qué
- Revisión trimestral de precisión que compara el rendimiento de la versión del modelo en deals de holdout
El proceso de disputa de enrutamiento
Cuando un rep cree que fue asignado (o no asignado) incorrectamente un lead, debe existir un proceso definido. Sin uno, las disputas se vuelven informales, sin rastreo, y propensas a escalada.
Un proceso de disputa de enrutamiento funcional de tres pasos:
Paso 1: El rep presenta una disputa de enrutamiento. Formulario estructurado en el CRM: ID del lead, fecha de la decisión de enrutamiento, motivo de la disputa (discrepancia de territorio, desequilibrio de capacidad, reclamación basada en preferencia). Una reclamación basada en preferencia ("yo quería ese lead") es una disputa débil. Una reclamación de discrepancia de territorio ("Este lead está en mi territorio según el mapa de territorios del Q1") es una disputa sólida.
Paso 2: El Sales Ops Manager revisa. Dentro de 48 horas. Revisa el audit trail: qué regla desencadenó el enrutamiento, qué inputs se usaron, si la regla se aplicó correctamente. Si la regla se aplicó correctamente y el mapa de territorios era preciso, la disputa se resuelve en contra del rep. Si hay una ambigüedad en la regla o una discrepancia en el mapa de territorios, la disputa puede ser confirmada.
Paso 3: La decisión se registra. Ya sea confirmada o denegada, el resultado va al audit trail vinculado al evento de enrutamiento original. Si se confirma, los inputs del modelo se señalan para revisión (¿fue este un caso límite que el modelo debería manejar diferente?). Si se deniega con una disputa de regla válida (por ejemplo, el mapa de territorios era ambiguo), el mapa de territorios se actualiza para prevenir recurrencia.
Este proceso protege tanto a la organización como al rep. Crea responsabilidad para las decisiones de enrutamiento y da a los reps un canal legítimo para disputas válidas sin abrir la puerta a manipulaciones.
Privacidad de datos en AI sales ops
Tres frameworks de cumplimiento aplican a AI sales ops en la mayoría de las empresas mid-market. Sepa cuáles aplican antes de desplegar.
GDPR Artículo 22 (sujetos de datos de la UE): Si su sistema de AI toma decisiones automatizadas que afectan significativamente a individuos, y esos individuos son sujetos de datos de la UE, el Artículo 22 puede aplicar. Las decisiones de enrutamiento de leads basadas en scoring automatizado podrían caer en el alcance si la decisión tiene un efecto material sobre el individuo (por ejemplo, afectando su acceso a servicios o su tratamiento por parte de una empresa). Las obligaciones relevantes incluyen: el derecho a revisión humana, una explicación de la lógica de la decisión, y el derecho a impugnar la decisión. El Artículo 22 del GDPR sobre toma de decisiones automatizada es la disposición específica a revisar con su equipo legal. Muchos equipos de B2B sales ops argumentan que su enrutamiento de leads no cumple el umbral de "efecto significativo" del Artículo 22. La revisión legal es obligatoria, no una suposición.
SOX (Sarbanes-Oxley, para empresas públicas de EE.UU.): Si el forecasting o la gestión del pipeline impulsados por AI afectan las decisiones de reconocimiento de ingresos materiales, los controles internos de SOX pueden aplicar. Específicamente, la Sección 302 (controles de divulgación) y la Sección 404 (controles internos sobre informes financieros) requieren que la dirección evalúe y atestigüe la efectividad de los controles sobre los informes financieros. Un sistema de AI que influye en los datos del forecast de ingresos sin documentación y prueba adecuadas de controles es una exposición potencial de SOX. Las empresas públicas que despliegan AI de forecasting deben involucrar a sus equipos de auditoría interna y externa con anticipación.
EU AI Act (todas las empresas con presencia en el mercado de la UE, 2026-2027): La Regulación (UE) 2024/1689, el EU AI Act, entró en vigor en agosto de 2024 y aplica plazos de cumplimiento escalonados hasta 2027. Los sistemas de AI utilizados en contratación, gestión de empleados, o acceso a servicios caen en categorías de mayor riesgo que requieren evaluaciones de conformidad y requisitos de documentación. Los equipos de B2B sales ops que operan en mercados de la UE deben evaluar qué disposiciones aplican a sus sistemas de scoring y enrutamiento de AI antes de la fecha de cumplimiento de agosto de 2026.
MAR / MiFID II (servicios financieros, UE): Para las empresas de servicios financieros que usan AI sales ops, la Regulación de Abuso de Mercado y MiFID II agregan requisitos de archivado de comunicaciones, requisitos de documentación de evaluación de idoneidad, y audit trails de mejor ejecución. Las grabaciones de llamadas en servicios financieros no son solo una herramienta de coaching; son un archivo regulatorio. Los períodos de retención (típicamente 5-7 años) y los requisitos de control de acceso son más estrictos que la gobernanza estándar de sales ops.
Para la mayoría de las empresas B2B mid-market no reguladas, el Artículo 22 del GDPR es el framework relevante principal para el lead scoring y enrutamiento, y requiere una revisión legal, no necesariamente una construcción de programa de cumplimiento. La acción clave: documentar que su equipo legal revisó el caso de uso de scoring de AI y concluyó si cumple o no el umbral de "efecto significativo" del Artículo 22, y retener esa documentación.
Niveles de madurez en gobernanza
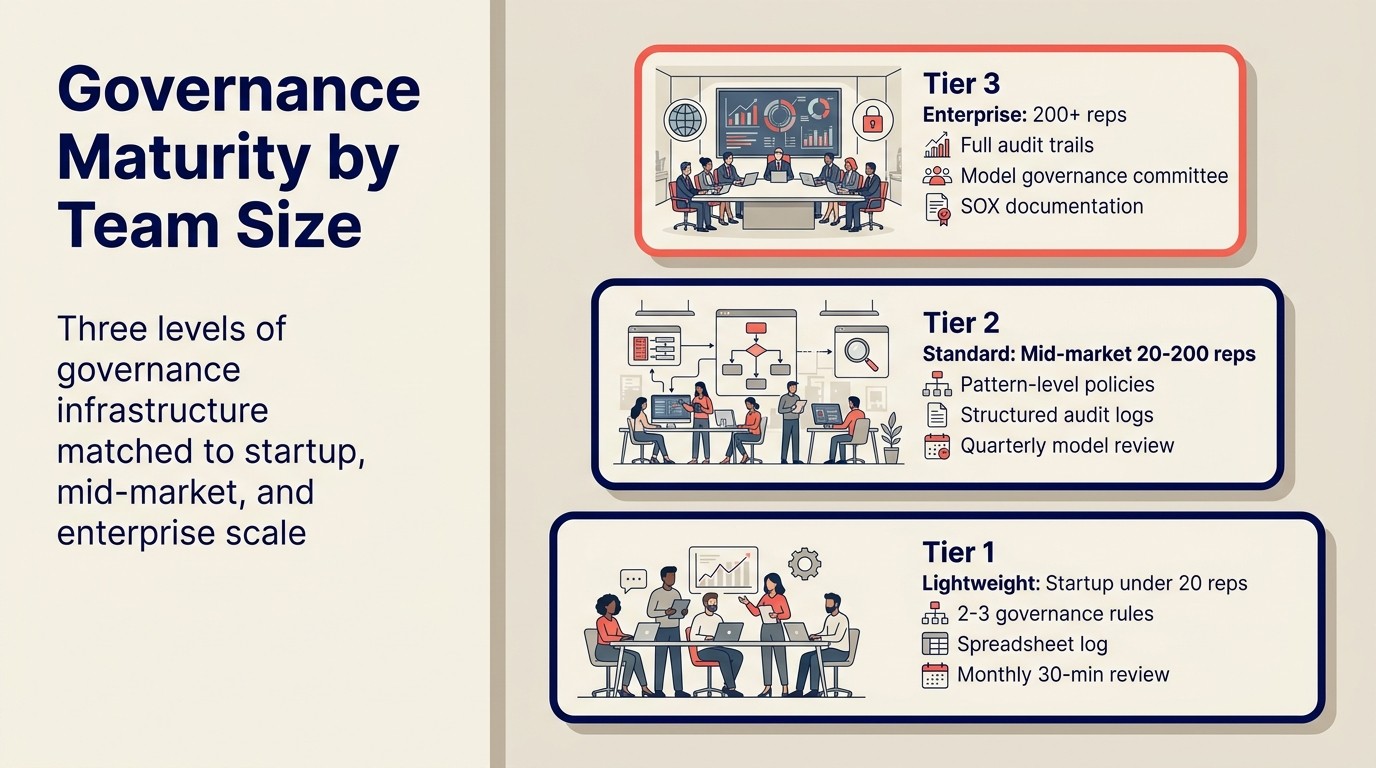
Los requisitos de gobernanza escalan con el tamaño de la empresa, la complejidad, y la exposición regulatoria. No construya infraestructura de gobernanza enterprise para un equipo de ventas de 10 personas.
Ligero (startup, menos de 20 reps):
- 2-3 reglas de gobernanza: proceso de consentimiento para grabación, camino de disputa de enrutamiento, aprobación de email para cuentas enterprise
- Audit trails en campos personalizados del CRM o una hoja de cálculo compartida
- Revisión mensual de 30 minutos por el líder de Sales Ops
- No se requieren herramientas de gobernanza dedicadas
Estándar (mid-market, 20-200 reps):
- Políticas a nivel de patrón documentadas por herramienta de AI
- Audit trails estructurados en el CRM o una tabla de log dedicada
- Revisión trimestral de precisión en el modelo de scoring
- Proceso de disputa de enrutamiento con SLA definido
- Revisión legal del GDPR completada y documentada
- Revisión anual de seguridad del vendor (informe SOC 2, acuerdo de procesamiento de datos vigente)
Enterprise (200+ reps, o industrias reguladas):
- Audit trails completos en los cuatro patrones, vinculados por deal y rep
- Comité de gobernanza del modelo (líder de RevOps, legal, ingeniería de datos)
- Revisiones trimestrales de precisión y sesgos del modelo
- Proceso de disputa de enrutamiento con camino de escalada al VP de RevOps
- Documentación de controles internos de SOX si es pública
- Verificación de residencia de datos por jurisdicción de operación
- Prueba anual de penetración de pipelines de datos de AI
Gobernanza y confianza: la razón real por la que importa
El argumento práctico para la gobernanza es el cumplimiento y la resolución de disputas. Pero el argumento estratégico es la confianza.
Un sistema de AI que toma decisiones invisibles, sin explicación, sin log, y sin camino de disputa, eventualmente perderá la confianza de los reps que viven con sus outputs. Los reps que no confían en el modelo de enrutamiento ignorarán sus asignaciones. Los reps que no confían en el modelo de scoring trabajarán los leads que quieren trabajar, no los que recomienda el modelo.
Cada mecanismo de gobernanza documentado aquí (el audit trail, el proceso de disputa, las puertas de aprobación) es también un mecanismo de confianza. Le dice al rep: "Sabemos que este sistema toma decisiones que le afectan. Tenemos un registro de esas decisiones. Si cree que una decisión fue incorrecta, aquí está cómo impugnarla." Eso no es burocracia. Es el contrato operativo que hace que AI sales ops sea realmente utilizado.
Consulte Modos de Fallo: Cuando AI Sales Ops Sale Mal para ver qué sucede cuando se omite la gobernanza, y De Llamada a Actualización Automática en CRM para ver cómo configurar la escritura automática al CRM con las puertas de revisión apropiadas.
Rework Analysis: La brecha de gobernanza que vemos más consistentemente no está en el análisis del Artículo 22 del GDPR (la mayoría de los equipos hacen esto) sino en el versionado de modelos. Los equipos generalmente pueden explicar sus reglas de enrutamiento actuales. No pueden explicar una decisión de enrutamiento de hace cuatro meses porque han actualizado el modelo de scoring dos veces desde entonces y no registraron qué versión tomó qué decisión. El versionado del modelo en el audit trail es la mejora de gobernanza de mayor valor para los equipos mid-market que tienen registro básico pero están empezando a volver a entrenar modelos a medida que se acumulan los datos.
Qué leer a continuación
- La Frontera Generate vs. Execute: Por Qué Importan las Salvaguardas: el principio ACE fundamental detrás de todo diseño de gobernanza
- Requisitos de Gobernanza por Patrón de AI: obligaciones de gobernanza a nivel de patrón en los 10 patrones de AI
- AI Sales Ops Implementation Roadmap: cómo la gobernanza encaja en el plan de despliegue por fases
- Modos de Fallo: Cuando AI Sales Ops Sale Mal: qué sale mal cuando la gobernanza se trata como opcional

Co-Founder, Rework.com
On this page
- Qué necesita gobernanza en el stack de cuatro patrones
- Los tres modelos de gobernanza
- Aprobación humana completa
- Automatización basada en umbrales
- Completamente automatizado con audit trail
- El 4-Pattern Audit Log Standard
- Especificación de campos del audit trail
- Versionado de modelos y gestión del cambio
- El proceso de disputa de enrutamiento
- Privacidad de datos en AI sales ops
- Niveles de madurez en gobernanza
- Gobernanza y confianza: la razón real por la que importa
- Qué leer a continuación