Failure Modes: Quando o AI Sales Ops Dá Errado
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Os deploys de AI sales ops que falham geralmente não são falhas técnicas. O modelo funcionou bem. As chamadas de API retornaram no prazo. A integração com o CRM se manteve. O problema foi organizacional: a equipe não confiou no sistema, ou o manipulou, ou o usou de forma errada, ou simplesmente o ignorou depois das primeiras três semanas.
Este é o artigo de encerramento da coleção. É também o mais importante se você está prestes a tomar uma decisão de compra ou de construção. Porque se você sabe o que quebra esses sistemas antes de fazer o deploy, tem uma chance razoável de não quebrar o seu. Para os failure modes no nível de padrão em todos os 10 padrões de AI, veja Anti Patterns: AI Combinations That Fail e Hallucination Risk by AI Pattern.
Sete failure modes. Cada um aconteceu em empresas reais. Cada um é evitável.
Key Facts: Risco de Deploy de AI Sales Ops em 2026
- 80,3% dos projetos de AI não entregam o valor de negócio pretendido, com 33,8% abandonados antes da produção (RAND Corporation, 2025)
- 76% dos deploys de AI agents apresentaram falhas críticas nos primeiros 90 dias em 847 implementações rastreadas
- 70% das equipes de vendas relatam resistência ativa à adoção de AI, e apenas 20% dos vendedores usam ferramentas de AI com frequência ou diariamente
The 7 AI Sales Ops Failure Modes
Os sete failure modes abaixo são o framework diagnóstico nomeado para deploys de AI sales ops. Eles cobrem toda a superfície de falhas: resistência humana (Modos 1 e 4), manipulação de dados (Modos 2 e 6), colapso de qualidade do output (Modo 3), degradação do modelo (Modo 5) e inversão de overhead de governança (Modo 7). Cada modo tem um caminho de prevenção conhecido e um caminho de recuperação conhecido.
Failure Mode 1: Rep Rebellion
Sintoma: Taxa de adoção abaixo de 40% aos 90 dias. Representantes usando a ferramenta quando os gestores estão observando, e não usando quando não estão.
Causa raiz: O rollout não envolveu os representantes na configuração, e a ferramenta foi enquadrada como monitoramento em vez de assistência. O Meeting Intelligence é o gatilho mais comum. Um representante que descobre que todas as suas chamadas estão sendo gravadas e que o gestor recebe um dashboard de desempenho gerado por AI não assinou para isso. E se ninguém o consultou antes do lançamento, o ressentimento é imediato.
Uma empresa fez o rollout do Gong para uma equipe de 35 representantes em 2024 sem uma conversa pré-lançamento sobre quais dados os gestores iriam ou não revisar. Em seis semanas, 12 representantes estavam agendando suas chamadas em telefones pessoais fora do sistema. Oito estavam registrando reclamações no RH sobre vigilância. O rollout foi pausado. Quatro meses de custo de assinatura desperdiçados, mais o trabalho de implementação.
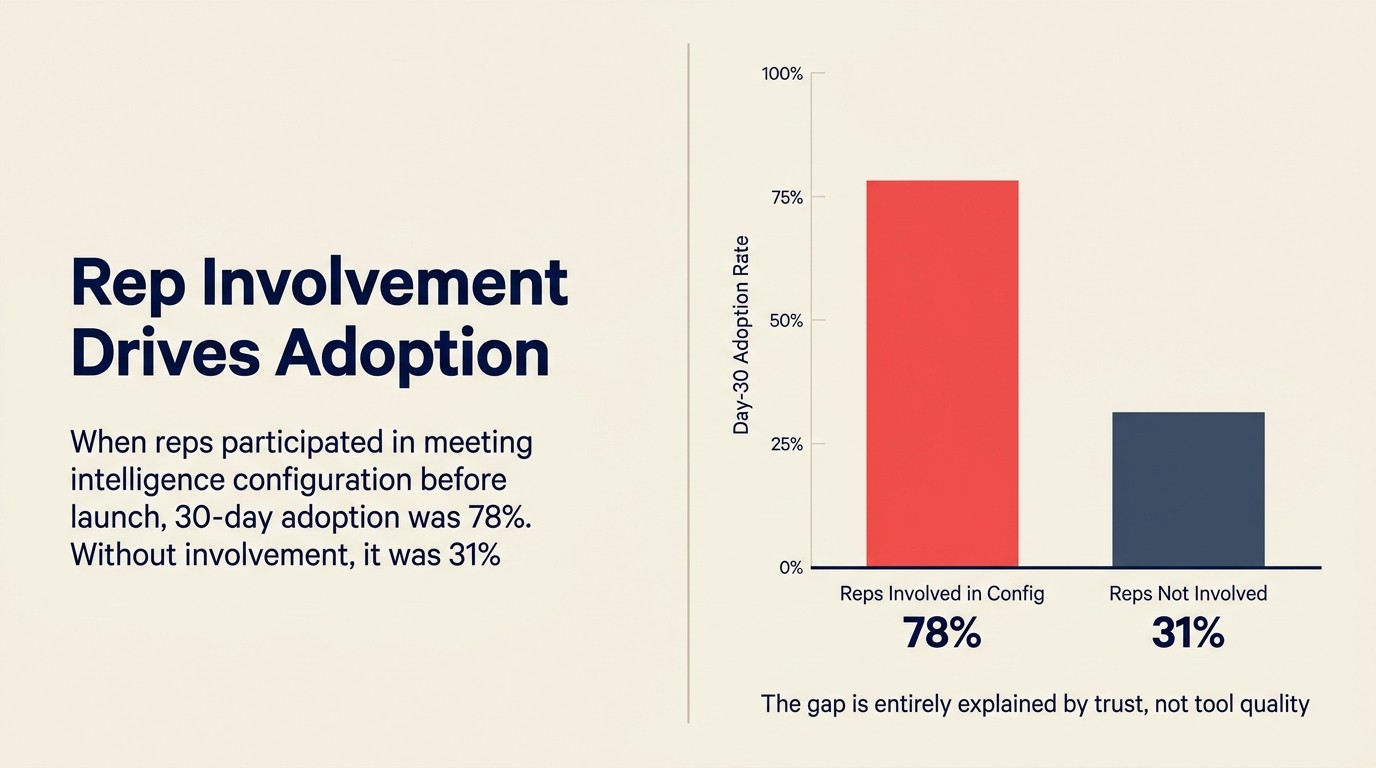
Números: Dados internos de uso de uma equipe de RevOps de SaaS de mid-market, compartilhados em um painel no SaaStr 2025: quando os representantes foram envolvidos nas decisões de configuração do meeting intelligence (quais campos são preenchidos automaticamente, quais clipes de chamada os gestores poderiam acessar, como o feedback de coaching seria entregue), a adoção em 30 dias foi de 78%. Quando os representantes não foram envolvidos, a adoção em 30 dias foi de 31%. O Stanford HAI AI Index 2025 constantemente constata que prontidão organizacional e confiança dos stakeholders, não desempenho do modelo, são os fatores que separam deploys enterprise de AI bem-sucedidos dos fracassados.
Prevenção: Realize uma sessão pré-lançamento de 2 semanas com uma amostra de representantes. Deixe-os ver a ferramenta, pergunte o que eles gostariam que ela fizesse e traga à tona o que os preocupa. Faça compromissos específicos: "As gravações serão usadas para coaching, não para avaliações de desempenho", e depois cumpra-os. Representantes ansiosos com vigilância se tornam defensores quando sentem que o sistema foi projetado em benefício deles, não contra eles.
Recuperação: Se a adoção já entrou em colapso, não force. Pause, reconheça o problema e inicie o processo de co-design com os representantes que deveria ter acontecido antes do lançamento. Um relançamento enquadrado como "ouvimos suas preocupações e fizemos estas mudanças" recupera a confiança mais rapidamente do que qualquer outra abordagem.
Quotable Nugget: Quando os representantes são envolvidos nas decisões de configuração do meeting intelligence antes do lançamento, a adoção em 30 dias chega a 78%. Quando não são envolvidos, cai para 31%. Essa diferença é explicada inteiramente pela confiança, não pela qualidade da ferramenta. (Dados internos de uso, equipe de RevOps de SaaS de mid-market, painel do SaaStr 2025)
Failure Mode 2: Lead Scores Getting Gamed
Sintoma: Os scores de lead sobem consistentemente ao longo de 3 a 6 meses mesmo com as taxas de fechamento estagnadas ou em queda.
Causa raiz: Os representantes descobriram quais inputs geram scores altos e começaram a otimizar esses inputs manualmente. Se o modelo de scoring pondera muito "tamanho de empresa" e os representantes podem editar o tamanho de empresa nos registros de contato, espere inflação. Se "visitas ao site" se correlaciona com score e os representantes podem disparar visitas enviando um link por e-mail, espere que o envio de links se torne um esporte.
Este é o problema da Lei de Goodhart aplicada ao scoring de leads: quando uma medida se torna um alvo, ela deixa de ser uma boa medida. Os representantes não fazem isso porque são mal-intencionados. Eles fazem porque querem mais leads bons e descobriram a alavanca. O artigo sobre armadilhas comuns de scoring de leads por AI cobre isso e outros padrões de falha de Scoring and Routing em profundidade.
Uma empresa de SaaS B2B rodando um modelo de scoring desenvolvido internamente viu os scores médios de leads derivarem de uma média de 62 para uma média de 79 ao longo de 8 meses. As taxas de fechamento caíram de 22% para 14% em leads de "alto score" no mesmo período. Quando fizeram a auditoria dos dados, 40% dos leads de alto score tinham campos de tamanho de empresa que foram editados manualmente nos 30 dias antes do scoring.
Prevenção: Não permita que os representantes editem os campos com maior peso no modelo de scoring. Use campos preenchidos pelo sistema (do seu provedor de dados, de logs de uso do produto, de analytics do site) para os inputs de scoring, não campos editáveis pelos representantes no CRM. Se você precisar usar campos editáveis pelos representantes, inclua um log de auditoria de "última edição por" para que as anomalias de scoring fiquem visíveis.
Recuperação: Audite os pesos das features do seu scoring em relação aos seus dados reais de conversão. Se os leads de alto score não estão convertendo a taxas maiores do que os leads de score médio, os scores foram manipulados ou o modelo sofreu drift. Retreine com dados de origem que os representantes não possam editar diretamente, e restrinja as permissões de edição de campos daqui para frente.
Quotable Nugget: A Lei de Goodhart é o risco mais subestimado nos deploys de scoring por AI. No momento em que um score de lead se torna um input de quota, os representantes otimizam para o score, não para a qualidade do pipeline. A solução é usar inputs preenchidos pelo sistema que os representantes não possam tocar, não mais retreinamento do modelo.
Failure Mode 3: Auto-Drafted Emails Sound Corporate-AI
Sintoma: As taxas de resposta de e-mail caem após o rollout de drafting de e-mails assistido por AI. A forma mais grave desse failure: um representante envia um e-mail rascunhado por AI para um prospect de relacionamento de longa data que responde: "Isso não soa como você. Está tudo bem?"
Causa raiz: Ferramentas de redação de e-mails prontas para uso, treinadas em corpora genéricos de e-mails de vendas, produzem e-mails de vendas genéricos. São gramaticalmente corretos. Usam uma estrutura razoável. E soam exatamente como qualquer outro e-mail frio gerado por AI que chega na mesma caixa de entrada.
Os padrões específicos que destroem as taxas de resposta:
- Aberturas que fazem referência a "o cenário atual de [setor]" ou "no ambiente acelerado de hoje"
- Frases que começam com "Queria entrar em contato" (toda AI escreve isso)
- Parágrafos de proposta de valor que listam recursos como bullets ("Com nossa plataforma, você pode: [lista de coisas]")
- CTAs que dizem "Você estaria aberto a uma ligação rápida de 15 minutos?" (o fechamento universal da AI)
O artigo sobre outreach personalizado gerado por AI em escala cobre a abordagem baseada em pesquisa que evita esses padrões.
Uma equipe de vendas em uma empresa SaaS de 200 representantes rastreou as taxas de resposta antes e depois do rollout de e-mails por AI. Antes: taxa de resposta de 8,2% no primeiro contato. Após 60 dias de drafting por AI com revisão do representante: 6,1%. Após 90 dias: 5,4%. Os representantes estavam editando levemente os rascunhos da AI, mas não os reescrevendo fundamentalmente. A voz da AI havia substituído a voz do representante.
Prevenção: Não use drafting de e-mails por AI como atalho para a escrita. Use como ponto de partida que os representantes genuinamente reescrevem. O valor não está no rascunho; está na estrutura e nos inputs de dados de personalização. Estabeleça uma barra de qualidade simples: qualquer e-mail rascunhado por AI que ainda contenha a frase "Queria entrar em contato" ou qualquer frase começando com "Espero que este e-mail o encontre bem" não é enviado.
Treine os representantes sobre como são os padrões gerados por AI e por que os prospects os reconhecem. Um representante que entende por que o rascunho da AI soa como AI tem muito mais probabilidade de corrigi-lo do que um representante que simplesmente acha que está bom.
Recuperação: Se as taxas de resposta caíram, puxe uma amostra dos e-mails rascunhados por AI que foram enviados. Leia-os em voz alta. Se algum deles soa como um comunicado de imprensa em vez de um humano falando com outro humano, você encontrou o problema. Faça um teste dividido: rascunhado por AI vs. escrito do zero pelo representante, mesmos leads, mesma semana. A diferença vai mostrar o quanto a voz da AI está prejudicando os resultados.
Quotable Nugget: Uma equipe de SaaS de 200 representantes rastreou as taxas de resposta antes e depois do rollout de e-mails por AI: 8,2% antes, 5,4% após 90 dias. Os representantes não estavam pulando a revisão. Estavam editando levemente os rascunhos da AI e os enviando. A voz da AI havia substituído a voz do representante sem que ninguém percebesse.
Failure Mode 4: Coaching Dashboards Create Rep Anxiety and Flight Risk
Sintoma: O turnover voluntário aumenta entre representantes de nível médio nos 6 a 12 meses após o rollout do meeting intelligence. Os temas das entrevistas de saída se concentram em "sentir-se microgerenciado" ou "estar sempre sendo observado."
Causa raiz: Os dashboards de coaching por AI expõem métricas individuais de representantes em um nível de granularidade que parece ameaçador em vez de desenvolvimentista. Proporção de tempo de fala. Contagem de perguntas por chamada. Número de menções de concorrentes tratadas. Duração de monólogos. Essas métricas pretendem ajudar os representantes a melhorar. Quando são exibidas em um dashboard visível para gestores com rankings, funcionam como um sistema de pressão de desempenho.
Representantes de nível médio (do percentil 50 ao 75) são os mais vulneráveis. Os top performers se sentem confiantes em seus números. Os de baixo desempenho já sabem que estão com dificuldades. Os de nível médio veem métricas que mostram que não estão no topo e internalizam isso como "estou falhando." Quando os dados estão sempre ativos e sempre visíveis, a pressão não se dissipa entre as conversas de coaching.
Isso é real. Uma pesquisa de 2025 com 200 profissionais de vendas B2B realizada pela Sales Management Association constatou que 34% dos representantes em empresas que usam ferramentas de coaching por AI relataram um estresse no trabalho significativamente maior do que antes do rollout. Desses, 41% disseram ter começado a se candidatar a outras posições nos 6 meses seguintes ao rollout.
Prevenção: Separe as métricas de coaching das métricas de desempenho nos dashboards visíveis aos representantes. Os representantes devem ver seus próprios dados de coaching e tendências. Eles não devem ver um ranking que os compare com os colegas em cada métrica todos os dias. O dashboard de coaching é uma ferramenta de desenvolvimento, não um placar.
Projete o fluxo de coaching em torno de conversas, não de dashboards. O trabalho do gestor é escolher uma métrica por representante por semana, mostrar os dados e discutir o que a está impulsionando. Não é compartilhar o dashboard completo e deixar os representantes tirarem suas próprias conclusões.
Recuperação: Se os indicadores de risco de saída estão subindo, audite como os gestores estão realmente usando os dados de coaching. O problema quase nunca é a tecnologia. É um gestor usando métricas de AI como arma de desempenho em vez de ferramenta de coaching. Treinar gestores na entrega de feedback com dados de AI importa mais do que qualquer mudança de configuração do dashboard.
Failure Mode 5: Forecasting Models Over-Fit to Recent Quarters
Sintoma: A precisão da previsão é forte por 2 a 3 trimestres após o treinamento do modelo, então começa a degradar. A precisão cai bruscamente quando as condições de mercado mudam (novo concorrente entra, mudança de preços, ventos macro contrários).
Causa raiz: Os modelos de previsão por AI aprendem a partir de padrões históricos de deals. São muito bons em prever resultados que se parecem com resultados passados. Quando o ambiente muda significativamente (dinâmica diferente do comitê de compras, nova pressão competitiva, desaceleração macro reduzindo gastos discricionários), os dados de treinamento do modelo não descrevem mais o ambiente atual. O modelo não sabe que houve uma mudança de regime; continua fazendo previsões como se o passado ainda fosse o presente.
Um exemplo concreto: uma empresa SaaS de mid-market treinou seu modelo de previsão do Clari no Q3 2024 com 18 meses de dados de deals de um mercado em modo de crescimento. A pesquisa State of AI da McKinsey relata que menos de 20% das organizações monitoram sistematicamente seus modelos de AI para detectar drift de desempenho após o deploy, o que faz com que a regressão por mudanças de regime passe despercebida até que uma falha no fechamento do trimestre force o tema. O modelo aprendeu que deals com engajamento multi-threaded (3+ contatos ativos nos últimos 30 dias) tinham uma taxa de fechamento de 72% na fase de proposta. No Q2 2025, com o aperto das condições econômicas, os comitês de compras começaram a desacelerar mesmo com contatos engajados. Deals multi-threaded na fase de proposta estavam fechando a 51%. O modelo continuou prevendo 72%. A previsão ficou 28% acima do real por dois trimestres antes que alguém detectasse o drift.
Prevenção: Defina uma cadência de monitoramento de precisão do modelo antes do deploy. Comparação mensal das taxas de fechamento previstas vs. reais para os deals previstos no mês anterior. Se a diferença entre previsto e real crescer mais de 10 pontos percentuais em meses consecutivos, sinalize para revisão de retreinamento. Não espere pela falha no fechamento do trimestre. O artigo sobre quando padrões de AI se tornam dívida técnica cobre o problema de drift do modelo no nível do padrão, incluindo como reconhecer quando um modelo sofreu drift além da recalibração.
Inclua um "protocolo de mudança de regime" na sua documentação de governança. Se um grande evento de mercado acontece (novo concorrente, mudança de preço, mudança macro), dispare uma revisão de precisão fora do ciclo. O julgamento humano de previsão deve ser explicitamente ponderado em relação ao output do modelo após uma mudança de regime, não tratado como ruído que deve ser sobreposto.
Recuperação: Retreine com os 6 a 9 meses mais recentes de dados ponderados com maior peso do que os dados mais antigos. Discuta explicitamente com a sua equipe de CS/Vendas o que mudou no mercado e identifique quais padrões históricos não são mais representativos.
Quotable Nugget: 32% dos pipelines de scoring em produção experienciam shifts de distribuição nos primeiros seis meses após o deploy. Modelos sem monitoramento ativo de precisão mostram degradação de 14 a 19% ao longo de 18 meses, em comparação com desempenho dentro de 2,4% do nível inicial para equipes que realizam revisões mensais de precisão. (IBM / Superwise AI, 2025)
Failure Mode 6: Routing Models Lock In Old ICP Biases
Sintoma: O scoring e o roteamento de leads por AI priorizam consistentemente um segmento estreito de leads. Outros segmentos (novos verticais nos quais você está se expandindo, empresas menores que podem ser fortes candidatas ao PLG, contas internacionais) raramente são trabalhados e raramente fecham. Você eventualmente percebe: a AI tem os filtrado sistematicamente.
Causa raiz: Modelos de scoring treinados em dados históricos de vitórias aprendem como eram os leads que levaram a vitórias passadas. Se suas vitórias passadas estavam concentradas em um segmento (digamos, empresas SaaS americanas com 100 a 500 funcionários, VP ou acima), o modelo aprende esse perfil como "alto score" para o seu ICP. Leads de novos segmentos de ICP que você está ativamente mirando não correspondem ao padrão histórico e recebem scores baixos. São roteados para nutrição. Não fecham, não porque são leads ruins, mas porque nunca foram trabalhados. O modelo interpreta isso como confirmação de que o novo segmento é de baixa qualidade.
Este é um loop de feedback que se compõe. O modelo de scoring desprioriza leads do novo segmento. Os representantes não os trabalham. Eles não fecham. O modelo vê taxas de fechamento baixas nesse segmento. Os scores ficam mais baixos. O novo segmento é efetivamente bloqueado do pipeline por um modelo que nunca foi atualizado para refletir a estratégia atual.
Uma empresa passou 6 meses tentando entrar no mid-market de manufatura (um novo vertical) com um GTM motion que incluía a contratação de um representante dedicado ao vertical. A representante reclamou que os leads que recebia eram de baixa qualidade. Uma auditoria revelou que seus leads estavam consistentemente marcando entre 30 e 45 porque o modelo de scoring nunca havia visto uma empresa de manufatura fechar. Ela estava sendo sistematicamente prejudicada pelo modelo. O artigo sobre o padrão Scoring and Routing explica como o escopo dos dados de treinamento determina quais segmentos o modelo pode avaliar de forma confiável.
Prevenção: Quando você adiciona um novo segmento de ICP, faça override explícito do scoring para esse segmento até ter 50 a 100 deals no segmento para treinar. Crie uma regra de bypass por segmento: "Leads que correspondem aos [critérios do novo ICP] recebem roteamento por revisão manual, independentemente do score."
Realize uma auditoria trimestral de diversidade de segmentos na sua população de leads com score. Se um segmento representa consistentemente mais de 80% dos leads de alto score e você tem metas estratégicas de expansão fora desse segmento, o modelo precisa de calibração por segmento.
Recuperação: Retreine o modelo com amostragem estratificada por segmento. Certifique-se de que o conjunto de treinamento inclua exemplos suficientes de segmentos sub-representados para dar ao modelo um sinal justo. Até que o retreinamento esteja completo, roteia segmentos sub-representados manualmente.
Failure Mode 7: Audit Overhead Exceeds Savings for Small Teams
Sintoma: A equipe de RevOps está gastando mais tempo gerenciando governança de AI, revisando decisões de AI e respondendo a disputas de representantes do que a AI está economizando em tempo dos representantes. A ferramenta tem eficiência operacional líquida negativa.
Causa raiz: Frameworks de governança de nível enterprise aplicados a deploys de AI para equipes pequenas. Uma equipe de 10 representantes rodando um modelo de scoring de leads não precisa de um comitê de governança de modelos, revisões trimestrais de precisão e um processo estruturado de disputa de roteamento com SLAs de 48 horas. Mas se o líder de RevOps leu um guia de governança de AI enterprise e implementou o framework completo, criou overhead administrativo que escala mal para o tamanho de equipe.
A versão específica desse problema que é mais comum: meeting intelligence com 8 a 12 representantes, com um fluxo completo de revisão de transcrições, cadência de análise do dashboard de coaching e processo de revisão de briefings de pipeline gerados por AI empilhados por cima. Cada componente é defensável individualmente. Juntos, podem adicionar 4 a 6 horas por semana de overhead de RevOps para uma equipe que tem uma pessoa de Sales Ops.
Se essa pessoa estava economizando 2 horas por semana de tempo dos representantes em toda a equipe, criou um prejuízo líquido.
Prevenção: Calibre a governança para o risco real e a escala. Um modelo de governança para startup (2 a 3 regras, log em planilha, revisão mensal de 30 minutos) é o nível certo para uma equipe com menos de 20 representantes. Infraestrutura completa de trilha de auditoria, comitês de governança de modelos e dashboards automatizados de conformidade pertencem à escala de 100+ representantes com uma equipe dedicada de RevOps.
Antes de adicionar qualquer requisito de governança, pergunte: qual é o pior caso se isso falhar? Se a resposta for "um representante contesta uma decisão de roteamento uma vez por trimestre", um log em planilha e um caminho claro de disputa resolve. Se a resposta for "violamos o GDPR e somos multados", construa a infraestrutura adequada. O NIST AI Risk Management Framework fornece uma estrutura de governança em camadas que mapeia diretamente para a escala do deploy, que é o template certo para calibrar o esforço de governança ao nível real de risco.
Recuperação: Audite honestamente o custo de overhead da sua governança. Se qualquer processo de governança estiver tomando mais de 30 minutos por semana para uma equipe com menos de 50 representantes, provavelmente está superprojetado para a sua escala. Simplifique. O objetivo não é governança pela governança em si; é governança que detecta problemas reais sem criar mais ônus do que a AI economiza.
Quotable Nugget: Frameworks de governança projetados para equipes enterprise de 100 representantes geram de 4 a 6 horas por semana de overhead de RevOps quando aplicados a equipes de 8 a 12 representantes. Nessa escala, o custo de governança supera a economia de tempo da AI que deveria proteger. Calibre a governança para o risco real e o tamanho da equipe, não para a sofisticação da documentação de conformidade do seu fornecedor.
Resumo de risco dos failure modes

Os sete failure modes não são igualmente prováveis ou igualmente custosos. Esta tabela mapeia cada modo para o seu padrão de gatilho mais comum, o tempo de detecção típico e o tempo de recuperação típico para que você possa priorizar os investimentos pré-lançamento.
| Failure Mode | Gatilho Principal | Tempo Típico de Detecção | Tempo de Recuperação | Prevenção Mais Eficaz |
|---|---|---|---|---|
| Rep Rebellion | Rollout sem envolvimento dos representantes | 30 a 60 dias | 3 a 4 meses | Sessão de co-design pré-lançamento |
| Lead Score Gaming | Inputs de scoring editáveis pelos representantes | 90 a 180 dias | 6 a 8 semanas (retreinamento) | Bloquear campos de scoring no lançamento |
| Corporate-AI Emails | Revisão superficial dos rascunhos pelos representantes | 60 a 90 dias | 2 a 3 semanas (coaching) | Senior-Rep Voice Test antes do envio |
| Coaching Anxiety / Flight Risk | Rankings visíveis para todos os representantes | 90 a 270 dias | Variável; alguns representantes não voltam | Separar dados de coaching dos dados de ranking |
| Model Drift (Forecasting) | Mudança de regime de mercado | 60 a 90 dias | 4 a 6 semanas (retreinamento) | Revisão mensal previsto vs. real |
| ICP Bias / Segment Lockout | Novo vertical sem regras de override | 90 a 180 dias | 8 a 12 semanas (retreinamento + auditoria) | Regra de bypass de segmento no lançamento |
| Governance Overhead Inversion | Framework enterprise em escala SMB | 30 a 90 dias | 1 a 2 semanas (simplificação) | Calibrar governança ao tamanho da equipe |
Fontes: RAND Corporation, Sales Management Association, IBM, dados internos de equipes de RevOps (2025)
Checklist pré-deploy
Antes de ir ao vivo com qualquer padrão de AI sales ops, verifique estes itens:
Dados:
- 12+ meses de histórico de deals limpo com labels consistentes de ganho/perda
- 70%+ de completude nos campos de contato principais (empresa, cargo, setor)
- Campos editáveis pelos representantes bloqueados para inputs do modelo de scoring
- Anomalias de progressão de estágio auditadas e resolvidas
Governança:
- Linguagem de consentimento de gravação revisada pelo jurídico
- Revisão de GDPR/privacidade concluída para o caso de uso de scoring
- Processo de disputa de roteamento documentado e socializado
- Schema do log de auditoria definido e configurado
- Rastreamento de versão do modelo implantado antes do deploy do modelo
Gestão de mudanças:
- Amostra de representantes envolvida nas decisões de configuração
- Compromissos específicos feitos sobre quais dados os gestores usarão e não usarão
- Lançamento enquadrado como economia de tempo para os representantes, não monitoramento para os gestores
- Plano de adoção de 30 dias (quem é responsável pela adoção dos representantes, como é medida)
- Treinamento de gestores sobre como usar dados de coaching por AI como ferramenta de desenvolvimento
Monitoramento:
- Métricas de baseline capturadas pré-lançamento (taxas de resposta, velocidade de roteamento, taxa de completude do CRM)
- Revisão de adoção em 30 e 90 dias agendada no calendário
- Cadência de monitoramento de precisão do modelo definida (comparação mensal)
- Thresholds de alerta configurados para padrões de anomalia (inflação de score, volume de disputas de roteamento)
Framework de verificação de saúde em 90 dias

Aos 90 dias após o lançamento, revise estas métricas para cada padrão implantado:
Scoring and Routing:
- Precisão de roteamento: qual % dos leads roteados está sendo disputado ou reatribuído manualmente? (Meta: abaixo de 10%)
- Inflação de score: o score médio de leads se moveu mais de 5 pontos do baseline? (Sinalize se sim)
- Correlação de taxa de fechamento: leads de alto score estão fechando a uma taxa maior do que leads de baixo score? (Se não, o modelo pode estar sendo manipulado ou sofrendo drift)
Meeting Intelligence:
- Taxa de participação em gravação: qual % das chamadas-alvo está sendo gravada? (Meta: acima de 85%)
- Melhora na taxa de completude do CRM: o auto-write por AI melhorou o % de chamadas com notas completas no CRM?
- Pulse de satisfação dos representantes: pesquisa de uma pergunta para os representantes: "O meeting intelligence está tornando seu trabalho mais fácil ou mais difícil?" (Net score deve ser positivo aos 90 dias)
Generative Research:
- Adoção de briefings de pesquisa: qual % de novos contatos com contas inclui um briefing gerado por AI? (Meta: acima de 60%)
- Tempo de pesquisa pré-chamada: medido aos 90 dias vs. baseline (Meta: redução de 40%+)
- Auto-avaliação de qualidade do briefing: avaliação dos representantes sobre a qualidade do briefing (escala de 1 a 5; meta acima de 3,5)
Workflow Copilot:
- Taxa de aceitação de NBA: qual % das próximas ações sugeridas está sendo acatada? (Meta: acima de 30%)
- Redução de tempo administrativo: tempo medido dos representantes na entrada de dados do CRM vs. baseline pré-AI
- Duração da reunião de revisão de pipeline: antes e depois do rollout do briefing por AI (Meta: redução de 20%+)
Rework Analysis: Dos sete failure modes, cinco têm uma raiz comum: o deploy foi tratado como um projeto de tecnologia, não como um projeto de gestão de mudanças. Os Modos 1, 3, 4, 6 e 7 envolvem comportamento humano e escolhas de design de equipe feitas depois que o fornecedor foi selecionado, não antes. O Modo 2 (manipulação) e o Modo 5 (drift) são os dois failure modes genuinamente técnicos, e ambos têm protocolos de prevenção conhecidos. As equipes que evitam essas falhas tipicamente fazem uma coisa diferente: definem métricas de sucesso antes do deploy, não após a primeira revisão de 30 dias. O template de governança pré-lançamento do Rework inclui a captura de métricas de baseline como uma etapa obrigatória na Fase 0, e é por isso que as equipes que o utilizam detectam as falhas do Modo 2 e do Modo 5 em média 6 a 8 semanas antes do que as equipes que começam o monitoramento após o lançamento.
A conclusão honesta

Nenhum desses failure modes é exclusivo da AI. Representantes que não confiam em uma ferramenta não a usam. Sistemas que produzem output de baixa qualidade são ignorados. Processos de governança que criam mais trabalho do que economizam são abandonados. Esses são problemas de implementação tão antigos quanto o software enterprise.
O que a AI adiciona é escala e velocidade. Um modelo de AI com drift ou com viés toma decisões ruins em cada lead do pipeline, não apenas nos que um humano teria categorizado erroneamente. Um dashboard de coaching por AI que cria ansiedade nos representantes a cria para todos os representantes da equipe simultaneamente. Os failure modes são os mesmos; o raio de impacto é maior.
É por isso que o checklist pré-deploy e a verificação de saúde em 90 dias não são etapas opcionais. São os hábitos operacionais que detectam problemas antes que se agravem.
A boa notícia: cada failure mode documentado aqui é evitável, e cada caminho de recuperação é conhecido. As empresas que acertam no AI sales ops não são mais inteligentes do que as que têm dificuldades. São mais pacientes com a Fase 0, mais honestas com seus representantes sobre o que as ferramentas fazem, e mais disciplinadas no monitoramento após o lançamento.
Comece com o roteiro de implementação. Construa governança antes de precisar dela, não depois que algo já deu errado. E releia este artigo antes da sua revisão de 90 dias. Os failure modes com os quais você não se preocupou no lançamento são os que vão te encontrar.
Para a perspectiva no nível do framework sobre por que deploys de AI falham antes mesmo de chegar à camada de sales ops, o artigo sobre por que a maioria dos frameworks de AI falha em ajudar os operadores cobre os mesmos problemas estruturais no nível da ACE Foundation.
O que ler a seguir
- Anti Patterns: AI Combinations That Fail: failure modes no nível do padrão em todo o panorama de 10 padrões
- Governança e Trilhas de Auditoria em AI Sales Ops: o framework de governança que previne a maioria desses failure modes
- Roteiro de Implementação de AI Sales Ops: o rollout sequenciado que reduz o risco de deploy
- Armadilhas Comuns de Scoring de Leads por AI: tratamento mais profundo dos Failure Modes 2 e 6 aplicados ao padrão Scoring

Co-Founder, Rework.com
On this page
- The 7 AI Sales Ops Failure Modes
- Failure Mode 1: Rep Rebellion
- Failure Mode 2: Lead Scores Getting Gamed
- Failure Mode 3: Auto-Drafted Emails Sound Corporate-AI
- Failure Mode 4: Coaching Dashboards Create Rep Anxiety and Flight Risk
- Failure Mode 5: Forecasting Models Over-Fit to Recent Quarters
- Failure Mode 6: Routing Models Lock In Old ICP Biases
- Failure Mode 7: Audit Overhead Exceeds Savings for Small Teams
- Resumo de risco dos failure modes
- Checklist pré-deploy
- Framework de verificação de saúde em 90 dias
- A conclusão honesta
- O que ler a seguir