失敗パターン:AI Sales Opsが裏目に出るとき
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AI Sales Opsのデプロイメントが失敗するのは、たいてい技術的な問題ではありません。モデルは正常に動作していました。APIコールも時間通りに返ってきた。CRM連携も安定していた。問題は組織的なものです。チームがシステムを信頼しなかった、あるいは操作した、あるいは間違った使い方をした、あるいは最初の3週間が過ぎたら単純に無視した。
これはこのコレクションの最後の記事です。そして、購入の意思決定やBuild判断をしようとしているなら、最も重要な記事でもあります。デプロイ前にどこで壊れるかを知っていれば、自分のシステムを壊さないで済む可能性が高まるからです。10のAIパターン全体にわたるパターンレベルの失敗パターンについては、Anti Patterns: AIの組み合わせが失敗するときとパターン別の幻覚リスクを参照してください。
7つの失敗パターン。それぞれが実際の企業で起きました。それぞれに防止策があります。
Key Facts:2026年のAI Sales Opsデプロイメントリスク
- AIプロジェクトの80.3%が意図したビジネス価値の提供に失敗しており、33.8%は本番前に断念されている(RAND Corporation、2025年)
- 追跡した847の実装において、AIエージェントデプロイメントの76%が最初の90日以内に重大な障害を経験した
- 営業チームの70%がAI導入への積極的な抵抗を報告しており、AIツールを頻繁または毎日使用している営業担当者はわずか20%
7つのAI Sales Ops失敗パターン
以下の7つの失敗パターンは、AI Sales Opsデプロイメントの診断フレームワークです。全体の失敗面をカバーしています。人間の抵抗(パターン1と4)、データ操作(パターン2と6)、出力品質の崩壊(パターン3)、モデルの劣化(パターン5)、ガバナンスオーバーヘッドの逆転(パターン7)。すべてのパターンには、既知の防止策と既知の回復策があります。
失敗パターン1:担当者の反発
症状: 90日時点でのAdoptionレートが40%未満。マネージャーが見ているときはツールを使い、見ていないときは使わない。
根本原因: ロールアウトに担当者が設定に関与しておらず、ツールが支援ではなく監視として位置づけられた。Meeting intelligenceが最も一般的なトリガーです。すべての通話が録音されていて、マネージャーがAI生成のパフォーマンスダッシュボードを見られると知った担当者は、そんな契約をした覚えはありません。もし誰も事前に確認しなかったなら、反発は即座に起きます。
ある企業は2024年に35人の担当者チームにGongを展開しましたが、マネージャーがどのデータをレビューするかについての事前の会話がありませんでした。6週間以内に、12人の担当者がシステム外の個人の電話でスケジュールを組み始めました。8人は監視についてHRへの苦情を申し立てました。ロールアウトは一時停止されました。4ヶ月分のサブスクリプションコストと実装労力の無駄。
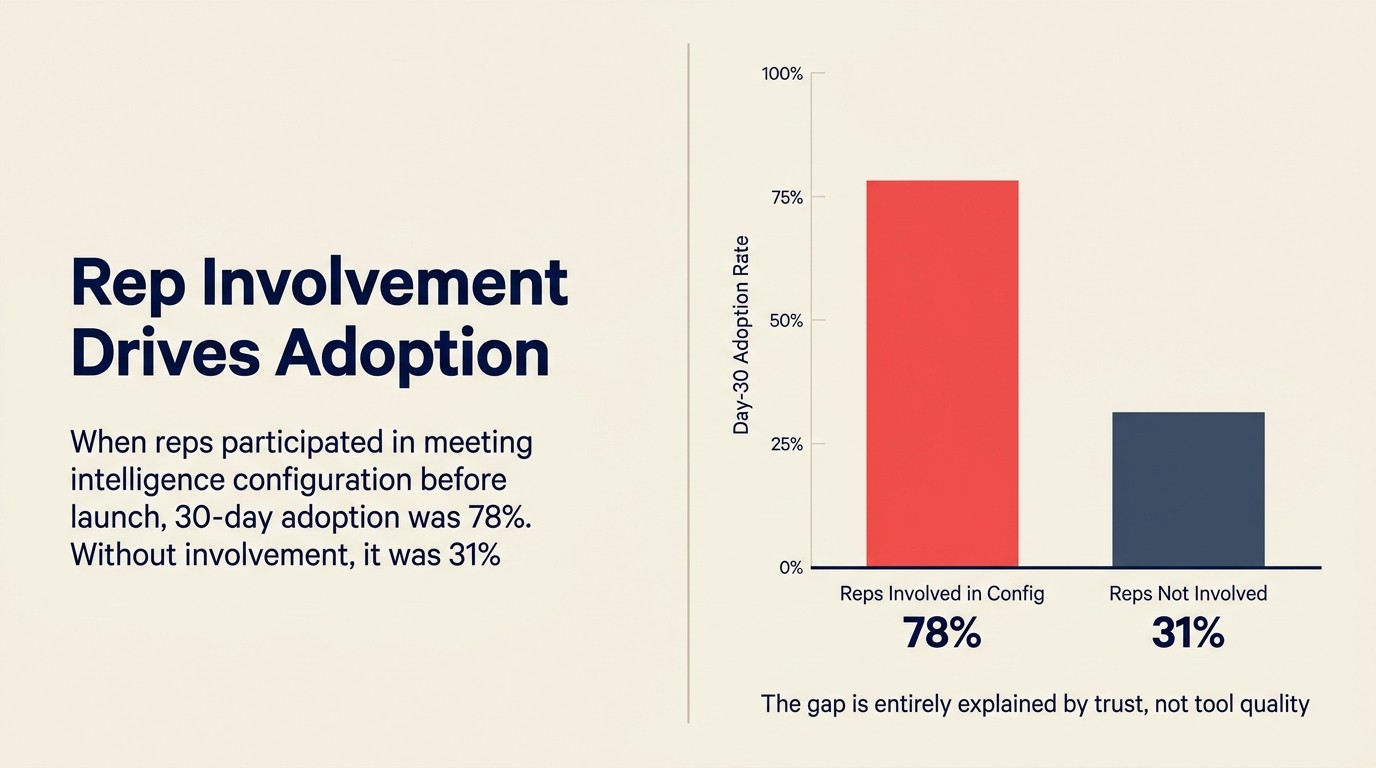
数値: 中堅市場SaaS RevOpsチームの内部使用データ(2025年SaaStrパネルで共有):担当者がMeeting intelligenceの設定決定(どのフィールドが自動入力されるか、マネージャーがどの通話クリップにアクセスできるか、コーチングフィードバックがどのように提供されるか)に関与した場合、30日Adoptionは78%でした。関与しなかった場合、30日Adoptionは31%でした。Stanford HAI AI Index 2025は一貫して、組織の準備状況とステークホルダーの信頼が、成功した企業AIデプロイメントと失敗したものを区別する要因であり、モデルのパフォーマンスではないと示しています。
防止策: 担当者のサンプルグループと2週間のローンチ前セッションを実施します。ツールを見てもらい、何をしてほしいか聞き、心配していることを表面化させます。具体的なコミットメントをします。「録音はコーチングに使用され、パフォーマンスレビューには使用しません」と伝え、それを守ります。監視に不安を感じている担当者は、システムが自分たちのために設計されていると感じたとき、支持者になります。
回復策: Adoptionがすでに崩壊している場合、押し付けないこと。一時停止し、問題を認め、ローンチ前に行うべきだった担当者の共同設計プロセスを始めます。「あなたの懸念を聞き、これらの変更を加えました」というフレームでの再ローンチは、他のどのアプローチよりも早く信頼を回復します。
Quotable Nugget: ローンチ前にMeeting intelligenceの設定決定に担当者が関与すると、30日Adoptionは78%に達します。関与しない場合、31%に落ちます。このギャップは完全にツールの品質ではなく、信頼によって説明されます。(内部使用データ、中堅市場SaaS RevOpsチーム、2025年SaaStrパネル)
失敗パターン2:Lead Scoreの操作
症状: CloseレートがフラットまたはDeclineしているにもかかわらず、Lead scoreが3〜6ヶ月にわたって全体的に上昇傾向にある。
根本原因: 担当者は高いスコアを生む入力を学習し、それらの入力を手動で最適化し始めました。スコアリングモデルが「会社規模」を重要視していて、担当者がコンタクトレコードの会社規模を編集できる場合、インフレを期待してください。「ウェブサイト訪問数」がスコアと相関していて、担当者がリンクをメールで送ることでウェブサイト訪問を誘発できる場合、リンク送信がゲームになることを期待してください。
これはLead scoringに適用されたグッドハートの法則の問題です。測定値が目標になった瞬間、良い測定値ではなくなります。担当者がこれをするのは悪意があるからではありません。より良いLeadを望んでいて、レバーを発見したからです。よくあるAI Lead scoringの落とし穴の記事では、このパターンと他のScoringおよびRoutingの失敗パターンを詳細に扱っています。
あるB2B SaaS企業では、自社構築のスコアリングモデルを使って8ヶ月間でLead scoreの平均が62から79に移行しました。同期間に「高スコア」Leadのclose rateは22%から14%に低下しました。データを監査したところ、高スコアLeadの40%は、スコアリングの30日前に会社規模フィールドが手動編集されていました。
防止策: スコアリングモデルで最も重みの大きいフィールドを担当者が編集できないようにします。担当者が編集可能なCRMフィールドではなく、データプロバイダー、製品使用ログ、ウェブサイト分析からのシステム入力フィールドをスコアリング入力に使用します。担当者が編集可能なフィールドを使用しなければならない場合は、「最終編集者」監査ログを含めて、スコアリングの異常が見えるようにします。
回復策: 実際のコンバージョンデータに対するスコアリング特徴の重みを監査します。高スコアLeadが中スコアLeadよりも高いレートでコンバートしていない場合、スコアが操作されているかモデルがドリフトしています。担当者が直接編集できないソースデータで再トレーニングし、今後のフィールド編集権限を厳しくします。
Quotable Nugget: グッドハートの法則は、AIスコアリングデプロイメントで最も過小評価されているリスクです。Lead scoreがクォータの入力になった瞬間、担当者はPipeline品質ではなくスコアを最適化します。解決策は、担当者が触れられないシステム入力を使用することであり、より多くのモデル再トレーニングではありません。
失敗パターン3:自動生成メールがコーポレートAI臭い
症状: AIアシストメール下書き展開後にメール返信率が低下する。この失敗の最悪の形:担当者が長期的な関係のProspectにAI生成メールを送ると、相手から「これはあなたらしくないですね。大丈夫ですか?」と返信される。
根本原因: 一般的なSalesメールコーパスでトレーニングされた既成のメール下書きツールは、一般的なSalesメールを生成します。文法的には正しい。合理的な構造を使っている。そして、同じ受信箱に届く他のすべてのAI生成コールドメールとまったく同じに聞こえます。
返信率を下げる具体的なパターン:
- 「[業界]の現在の状況」や「今日の急速に変化する環境において」で始まる書き出し
- 「ご連絡差し上げたく」で始まる文(すべてのAIがこれを書く)
- 機能を箇条書きでリストアップする価値提案の段落(「私たちのプラットフォームでできること:[リスト]」)
- 「15分のお時間をいただけますでしょうか?」というCTA(ユニバーサルAIのクロージング)
大規模なAI生成パーソナライズアウトリーチでは、これらのパターンを回避する研究に基づいたアプローチを扱っています。
200人担当者のSaaS企業のあるSalesチームは、AIメール展開前後の返信率を追跡しました。展開前:ファーストタッチアウトリーチの返信率8.2%。担当者レビューありのAI下書きを60日使用後:6.1%。90日後:5.4%。担当者はAI下書きを軽く編集していましたが、根本的に書き直してはいませんでした。AI的な声が担当者の声に取って代わっていました。
防止策: AIメール下書きを執筆の近道として使わないこと。本当に書き直すべき出発点として使います。価値は下書きではなく、構造とパーソナライズデータの入力にあります。シンプルな品質基準を設けます。「ご連絡差し上げたく」というフレーズや「いつもお世話になっております」で始まる文を含むAI生成メールは送らない。
担当者に、AI生成パターンがどのように見えるか、そしてなぜProspectがそれを認識するかをトレーニングします。AI下書きがなぜAIのように聞こえるかを理解している担当者は、単に良さそうだと思っている担当者よりも修正する可能性がはるかに高い。
回復策: 返信率が低下している場合、送信したAI下書きメールのサンプルを取り出して声に出して読みます。プレスリリースのように聞こえるものがあれば、問題を発見しました。スプリットテストを実施します。AI下書きvs担当者が最初から書いたもの、同じLead、同じ週。ギャップがAIの声がどれだけ影響しているかを示します。
Quotable Nugget: 200人担当者のSaaS企業がAIメール展開前後の返信率を追跡しました。展開前8.2%、90日後5.4%。担当者はレビューをスキップしていませんでした。AI下書きを軽く編集して送信していました。誰も気づかないうちにAIの声が担当者の声に取って代わっていました。
失敗パターン4:コーチングダッシュボードが担当者の不安と離職リスクを生む
症状: Meeting intelligence展開後6〜12ヶ月で中堅担当者の自発的な退職が増加する。退職面談のテーマが「マイクロマネジメントされている感覚」や「常に監視されている感覚」に集中している。
根本原因: AIコーチングダッシュボードは、発展的というよりも脅威に感じられる細かさで個別担当者のメトリクスを表示します。話す時間の比率。通話あたりの質問数。処理した競合他社への言及の数。モノローグの長さ。これらのメトリクスは担当者の改善を助けるためのものです。マネージャーが見えるダッシュボードにランキングとして表示されると、パフォーマンスプレッシャーシステムとして機能します。
中堅担当者(50〜75パーセンタイルのパフォーマー)が最も脆弱です。トップパフォーマーは自分の数字に自信があります。ボトムパフォーマーはすでに自分が苦労していることを知っています。中堅担当者は自分がトップにいないことを示すメトリクスを見て、「失敗している」と内面化します。データが常にオンで常に見えている場合、コーチング会話の間もプレッシャーが解放されません。
これは現実の問題です。2025年のSales Management Associationによる200人のB2B Sales専門家の調査では、AIコーチングツールを使用している企業の担当者の34%が、展開前よりも仕事上のストレスが大幅に高いと報告しました。そのうち41%は、展開から6ヶ月以内に他の職を探し始めたと答えています。
防止策: 担当者に見えるダッシュボードで、コーチングメトリクスとパフォーマンスメトリクスを分離します。担当者は自分のコーチングデータとトレンドを見るべきです。毎日すべてのメトリクスでPeerと比較するランキングを見るべきではありません。コーチングダッシュボードは開発ツールであり、スコアボードではありません。
ダッシュボードではなく会話を中心にコーチングワークフローを設計します。マネージャーの仕事は、担当者ごとに週1つのメトリクスを選び、データを示し、何がそれを引き起こしているかを議論することです。完全なダッシュボードを共有して、担当者が自分で結論を導き出すようにすることではありません。
回復策: 離職リスクの指標が上昇している場合、マネージャーがコーチングデータを実際にどのように使用しているかを監査します。問題はほとんどの場合、テクノロジーではありません。マネージャーがAIメトリクスをコーチングツールではなくパフォーマンスの武器として使用しています。AIデータを使ったフィードバック提供についてのマネージャートレーニングは、あらゆるダッシュボード設定の変更よりも重要です。
失敗パターン5:予測モデルが直近のクォーターに過学習する
症状: モデルトレーニング後2〜3クォーターは予測精度が高いが、その後劣化し始める。市場環境が変化したとき(新しい競合他社の参入、価格変更、マクロ環境の逆風)に精度が急落する。
根本原因: AI予測モデルは過去のDealパターンから学習します。過去の結果に似た結果を予測するのが得意です。環境が大幅に変化したとき(異なる購買委員会のダイナミクス、新しい競争圧力、裁量支出を減らすマクロ後退)、モデルのトレーニングデータが現在の環境を説明しなくなります。モデルはレジームチェンジがあったことを知らず、過去が現在と同じであるかのように予測し続けます。
具体的な例:中堅市場のSaaS企業が2024年Q3に、成長モードの市場から18ヶ月のDealデータでClari予測モデルをトレーニングしました。McKinseyのAI調査は、組織の20%未満が展開後のAIモデルのパフォーマンスドリフトを系統的に監視していることを示しており、クォーター末のミスが問題を顕在化させるまでレジームチェンジによる回帰が検出されないままになる仕組みがここにあります。モデルは、マルチスレッドエンゲージメント(過去30日間に3人以上のコンタクトがアクティブ)があるDealが、プロポーザルステージで72%のclose rateを持つことを学習しました。2025年Q2、経済状況が厳しくなるにつれ、エンゲージメントのあるコンタクトがいても購買委員会の動きが遅くなり始めました。プロポーザルステージでのマルチスレッドDealのcloseが51%になっていました。モデルは72%を予測し続けました。誰かがドリフトに気づく前の2クォーター、予測は実際より28%高かった。
防止策: デプロイ前にモデル精度の監視ケイデンスを設定します。前月の予測DealについてのPredicted close rateと実際の月次比較。連続する月で予測と実際のギャップが10パーセンタイルポイント以上拡大する場合、再トレーニングレビューのフラグを立てます。クォーター末のミスを待ちません。AIパターンがTech Debtになるときでは、パターンレベルでのモデルドリフト問題を扱っており、モデルが再調整を超えてドリフトしたときをどのように認識するかも含まれています。
ガバナンスドキュメントに「レジームチェンジプロトコル」を含めます。主要な市場イベント(新競合他社、価格変更、マクロ変化)が発生した場合、サイクル外の精度レビューをトリガーします。レジームチェンジ後は、人間の予測判断をモデル出力に対して明示的に重み付けし、オーバーライドするノイズとして扱わないようにします。
回復策: 最近の6〜9ヶ月のデータにより高い重みをつけて再トレーニングします。CS/Salesチームと何が市場で変わったかを明示的に議論し、どの過去のパターンがもはや代表的でないかを特定します。
Quotable Nugget: 本番スコアリングパイプラインの32%が展開後6ヶ月以内に分布シフトを経験します。能動的な精度監視なしのモデルは18ヶ月で14〜19%の劣化を示しますが、月次精度レビューを実施しているチームは初期パフォーマンスの2.4%以内に抑えられます。(IBM / Superwise AI、2025年)
失敗パターン6:RoutingモデルがICPバイアスを固定化する
症状: AIのLead scoringとRoutingが一貫してLeadの狭いセグメントを優先する。他のセグメント(拡大中の新しい業種、PLGに適した小規模企業、海外企業)はほとんど対応されずcloseしない。やがて気づきます。AIが系統的にそれらを排除していたことを。
根本原因: 過去のWinデータでトレーニングされたスコアリングモデルは、過去のWinに似たLeadを学習します。過去のWinが1つのセグメントに集中していた場合(例:従業員100〜500人の米国SaaS企業、VP以上)、モデルはそのプロファイルを「高スコア」のICP(理想的な顧客プロファイル)として学習します。積極的にターゲットにしている新しいICPセグメントのLeadは過去のパターンと一致せず、低スコアになります。Nurtureにルーティングされます。Closeしません。Leadが悪いからではなく、一度も対応されなかったからです。モデルはこれを、そのセグメントが低品質であるという確認として解釈します。
これは複合するフィードバックループです。スコアリングモデルが新セグメントのLeadを優先度を下げる。担当者が対応しない。Closeしない。モデルはそのセグメントからのlow close rateを確認する。スコアが低くなる。新セグメントは、更新されたことのないモデルによってPipelineから事実上締め出されます。
ある企業は6ヶ月かけて中堅市場の製造業(新しい業種)にGTMモーションで参入しようとし、専任の業種担当者を採用しました。その担当者は割り当てられたLeadの質が低いと不満を言いました。監査の結果、彼女のLeadはスコアリングモデルが製造業のcloseを見たことがなかったため、一貫して30〜45の範囲でスコアリングされていたことが判明しました。彼女はモデルによって系統的に不利な状況に置かれていました。ScoringおよびRoutingパターンでは、トレーニングデータのスコープがモデルが信頼できる評価ができるセグメントをどのように制限するかを説明しています。
防止策: 新しいICPセグメントを追加するとき、そのセグメントで50〜100のDealのトレーニングデータが得られるまで、明示的にそのセグメントのスコアリングをオーバーライドします。セグメントバイパスルールを作成します。「[新ICPの基準]に一致するLeadは、スコアにかかわらず手動レビューRoutingを受ける」。
スコアされたLeadの母集団に対して四半期ごとのセグメント多様性監査を実施します。1つのセグメントが一貫して高スコアLeadの80%以上を占めていて、そのセグメント外に戦略的な拡大目標がある場合、モデルにはセグメントレベルの調整が必要です。
回復策: セグメント層化サンプリングでモデルを再トレーニングします。トレーニングセットに、過少代表されているセグメントからの十分な例が含まれていることを確認し、モデルに公平なシグナルを与えます。再トレーニングが完了するまで、過少代表されているセグメントを手動でルーティングします。
失敗パターン7:監査オーバーヘッドが小規模チームでの節約を上回る
症状: RevOpsチームが、AIが担当者の時間を節約しているよりも、AIガバナンスの管理、AI判断のレビュー、担当者からの異議への対応に多くの時間を費やしている。ツールが運用効率にとってネット負になっている。
根本原因: 小規模チームのAIデプロイメントに適用されたエンタープライズグレードのガバナンスフレームワーク。10人の担当者チームでLead scoringモデルを実行している場合、モデルガバナンス委員会、四半期精度レビュー、48時間SLAの構造化されたルーティング異議処理プロセスは必要ありません。しかし、RevOpsリードがエンタープライズAIガバナンスガイドを読んでフレームワーク全体を実装した場合、チームの規模にはうまくスケールしない管理オーバーヘッドが生まれます。
最も一般的なバージョン:8〜12人担当者でのMeeting intelligence、その上に完全なトランスクリプトレビューワークフロー、コーチングダッシュボード分析ケイデンス、AI生成Pipelineブリーフレビュープロセスが重なっている。各コンポーネントは個別に正当化できます。合わせると、Sales Ops担当者が1人しかいないチームで週4〜6時間のRevOpsオーバーヘッドになる可能性があります。
そのRevOps担当者がチーム全体で週2時間の担当者時間を節約していたとすれば、ネットロスが生まれます。
防止策: 実際のリスクとスケールにガバナンスを合わせます。スタートアップのガバナンスモデル(2〜3のルール、スプレッドシートのログ、月次30分のレビュー)が20人以下の担当者チームには適切です。完全な監査証跡インフラ、モデルガバナンス委員会、自動コンプライアンスダッシュボードは、専任のRevOpsチームを持つ100人以上の担当者規模に属します。
ガバナンス要件を追加する前に問います。これが失敗した場合の最悪のシナリオは何か?答えが「担当者が四半期に一度Routingの決定に異議を唱える」なら、スプレッドシートのログと明確な異議処理パスで対処できます。答えが「GDPRに違反して罰金を受ける」なら、適切なインフラを構築します。NIST AI Risk Management Frameworkは展開規模に直接対応する階層型ガバナンス構造を提供しており、実際のリスクレベルにガバナンス努力を調整するための正しいテンプレートです。
回復策: ガバナンスオーバーヘッドを正直に監査します。50人未満の担当者チームで、どれかのガバナンスプロセスが週30分以上かかっているなら、おそらく過剰設計されています。シンプルにします。目標はガバナンスそのものではなく、AIが節約する以上の負担を作らずに実際の問題を捕捉するガバナンスです。
Quotable Nugget: 100人担当者のエンタープライズチーム向けに設計されたガバナンスフレームワークは、8〜12人のチームに適用すると週4〜6時間のRevOpsオーバーヘッドを生成します。その規模では、ガバナンスコストが保護しようとするAIの時間節約を超えます。ベンダーのコンプライアンスドキュメントの洗練度ではなく、実際のリスクとチームの規模にガバナンスを合わせます。
失敗パターンのリスクサマリー

7つの失敗パターンは、同等の確率や同等のコストではありません。この表は、各パターンを最も一般的なトリガーパターン、検出ラグ、典型的な回復時間にマッピングして、ローンチ前の投資を優先順位付けできるようにします。
| 失敗パターン | 主なトリガー | 典型的な検出ラグ | 回復時間 | 最も効果的な防止策 |
|---|---|---|---|---|
| 担当者の反発 | 担当者が関与しないロールアウト | 30〜60日 | 3〜4ヶ月 | ローンチ前の共同設計セッション |
| Lead Scoreの操作 | 担当者が編集できるスコアリング入力 | 90〜180日 | 6〜8週間(再トレーニング) | ローンチ時にスコアリングフィールドをロック |
| コーポレートAIメール | 浅い担当者による下書きレビュー | 60〜90日 | 2〜3週間(コーチング) | 送信前のシニア担当者ボイステスト |
| コーチング不安/離職リスク | 全担当者に見えるランキング | 90〜270日 | 様々;一部の担当者は戻らない | コーチングデータとランキングデータの分離 |
| モデルドリフト(予測) | 市場のレジームチェンジ | 60〜90日 | 4〜6週間(再トレーニング) | 月次予測対実際のレビュー |
| ICPバイアス/セグメント排除 | オーバーライドルールなしの新業種 | 90〜180日 | 8〜12週間(再トレーニング+監査) | ローンチ時のセグメントバイパスルール |
| ガバナンスオーバーヘッドの逆転 | SMB規模でのエンタープライズフレームワーク | 30〜90日 | 1〜2週間(シンプル化) | チームの規模にガバナンスを合わせる |
出典:RAND Corporation、Sales Management Association、IBM、内部RevOpsチームデータ(2025年)
デプロイ前チェックリスト
AIのSales Opsパターンを稼働させる前に、これらを確認します。
データ:
- 一貫したWon/Lostラベルを持つ12ヶ月以上のクリーンなDeal履歴
- コアコンタクトフィールド(会社、肩書き、業種)で70%以上の完全性
- スコアリングモデル入力のために担当者が編集できるフィールドをロック済み
- ステージ進行の異常を監査して解決済み
ガバナンス:
- 法務が録音同意の言語をレビュー済み
- スコアリングのユースケースについてGDPR/プライバシーレビュー完了
- Routingの異議処理プロセスを文書化し周知済み
- 監査ログスキーマを定義して設定済み
- モデルデプロイ前にモデルバージョントラッキング実施中
変更管理:
- 担当者サンプルグループが設定決定に関与済み
- マネージャーが使用する/しないデータについての具体的なコミットメント済み
- ローンチをマネージャーのための監視ではなく担当者のための時間節約としてフレーム済み
- 30日間Adoptionプラン(担当者のAdoptionを担当する人、測定方法)
- AIコーチングデータを開発ツールとして使うためのマネージャートレーニング済み
監視:
- ローンチ前にベースラインメトリクスを取得済み(返信率、Routingスピード、CRM完了率)
- 30日と90日のAdoptionレビューをカレンダーにスケジュール済み
- モデル精度の監視ケイデンスを定義済み(月次比較)
- 異常パターン(スコアインフレ、Routing異議量)のアラートしきい値を設定済み
90日健全性チェックフレームワーク

ローンチ後90日で、展開した各パターンのメトリクスをレビューします。
ScoringおよびRouting:
- Routing精度:ルーティングされたLeadの何%が異議申し立てや手動再割り当てされているか?(目標:10%未満)
- スコアインフレ:平均Lead scoreがベースラインから5ポイント以上動いたか?(Yesならフラグ)
- Close rateの相関:高スコアLeadは低スコアLeadよりも高いレートでCloseしているか?(そうでない場合、モデルが操作されているかドリフトしている可能性)
Meeting intelligence:
- 録音参加率:ターゲット通話の何%が録音されているか?(目標:85%以上)
- CRM完了率の改善:AI自動書き込みはCRMノートが完全な通話の%を改善したか?
- 担当者満足度パルス:担当者への1問アンケート:「Meeting intelligenceは仕事を楽にしていますか、それとも難しくしていますか?」(ネットスコアは90日までにポジティブであるべき)
Generative Research:
- リサーチブリーフのAdoption:新規アカウントタッチの何%にAI生成ブリーフが含まれているか?(目標:60%以上)
- 通話前リサーチ時間:90日時点のベースラインとの比較(目標:40%以上の短縮)
- ブリーフ品質の自己評価:ブリーフ品質の担当者評価(1〜5のスケール;目標3.5以上)
Workflow Copilot:
- NBA承諾率:提案されたネクストアクションの何%が実行されているか?(目標:30%以上)
- 管理時間の削減:AI前のベースラインと比較したCRMデータ入力の担当者時間
- Pipelineレビュー会議の長さ:AIブリーフ展開の前後(目標:20%以上の短縮)
Rework Analysis: 7つの失敗パターンのうち5つには共通の根本原因があります。デプロイメントがテクノロジープロジェクトとしてスコープされ、変更管理プロジェクトとしてスコープされなかったことです。パターン1、3、4、6、7はすべて、ベンダー選定後ではなく前に行うべきだった人間の行動とチーム設計の選択に関わっています。パターン2(操作)とパターン5(ドリフト)は、既知の防止プロトコルを持つ2つの真に技術的な失敗パターンです。これらの失敗を避けているチームは、通常1つのことを違うやり方でやっています。最初の30日レビューの後ではなく、デプロイ前に成功メトリクスを定義します。ReworkのPre-launch Governance Templateはフェーズ0の必須ステップとしてベースラインメトリクスの取得を含んでいます。これが、それを使うチームがパターン2とパターン5の失敗を、ローンチ後から監視を始めるチームより平均6〜8週間早く検出する理由です。
正直な結論

これらの失敗パターンはAIに固有のものではありません。信頼しないツールを使わない担当者。低品質なアウトプットを生成するシステムは無視される。節約以上に仕事を作るガバナンスプロセスは廃棄される。これらはエンタープライズソフトウェアと同じくらい古い実装の問題です。
AIが加えるのは、スケールとスピードです。ドリフトしているかバイアスのあるAIモデルは、人間が誤分類したであろうLeadだけでなく、Pipeline内のすべてのLeadに対して悪い決定を下します。担当者の不安を生むAIコーチングダッシュボードは、チームのすべての担当者に同時に不安を生みます。失敗パターンは同じですが、影響範囲が大きい。
だからこそ、デプロイ前チェックリストと90日健全性チェックは省略できないステップです。問題が複合する前に捕捉する運用習慣です。
良いニュースは:ここに記録されたすべての失敗パターンは防止可能で、すべての回復策は既知です。AI Sales Opsをうまくやっている企業は、苦労している企業より賢いわけではありません。フェーズ0に対してより忍耐強く、ツールの内容についてより正直に担当者と向き合い、ローンチ後の監視についてより規律ある姿勢を持っています。
実装ロードマップから始めます。必要になってからではなく、何かが既に間違ってから必要になる前にガバナンスを構築します。そして90日レビューの前にこの記事をもう一度読んでください。ローンチ時に心配しなかった失敗パターンが、あなたを見つけに来ます。
AIデプロイメントがSales Opsレイヤーに達する前に失敗する理由についてのフレームワークレベルの視点については、なぜほとんどのAIフレームワークがオペレーターを助けることができないのかが、ACE Foundationレベルで同じ構造的問題を扱っています。
よくある質問
AI Sales Opsデプロイメントが失敗する最も一般的な理由は何ですか?
技術的な品質ではなく、組織的な抵抗です。RAND Corporationの2025年の分析では、AIプロジェクトの80.3%が意図したビジネス価値の提供に失敗しており、成功と失敗したデプロイメントを区別する主要な要因は変更管理であり、モデルのパフォーマンスではないことが示されました。Sales Opsで最も一般的な2つの組織的失敗パターンは、担当者の反発(パターン1)とコーチングダッシュボードへの不安による離職リスク(パターン4)です。どちらも、ローンチ前の共同設計セッションと、AIデータをマネージャーがどのように使用するか、使用しないかについての意図的な決定によって防止できます。
営業担当者によるLead scoreの操作をどう防ぐか?
スコアリングモデルで最も重みが大きいフィールドをロックして、担当者が直接編集できないようにします。データプロバイダーのファーモグラフィックス、製品使用ログ、ウェブサイト分析などのシステム入力フィールドを使用し、担当者が編集可能なCRMフィールドは使いません。スコアリングに担当者が編集可能なフィールドを含める必要がある場合は、「最終編集者」監査ログを追加し、スコアのインフレを時間をかけて追跡します。close rateがフラットまたはDeclineしている一方でスコアが上昇傾向にある場合、入力が操作されているシグナルです。Lead品質が改善しているわけではありません。
AI予測モデルはどの時点で崩壊し始めますか?
過去のDealデータでトレーニングされたモデルは、通常2〜3クォーターはうまく機能しますが、市場環境が大幅に変化すると劣化し始めます。IBMの2025年の研究では、本番スコアリングパイプラインの32%が最初の6ヶ月以内に分布シフトを経験することが示されました。具体的なリスクはレジームチェンジです。新しい競合他社、価格調整、またはマクロ後退。モデルはレジームチェンジを自動検出しません。月次の予測対実際の比較と、主要な市場イベントが発生したときにサイクル外の精度レビューをトリガーするプロトコルが必要です。
AIコーチングダッシュボードが担当者の離職リスクを生む仕組みは?
コーチングメトリクスが個別の開発データではなくPeerランキングとして表示されると、中堅担当者(50〜75パーセンタイル)が最もプレッシャーを感じます。トップパフォーマーは自分の数字に自信があります。ボトムパフォーマーはすでに苦労していることを知っています。中堅担当者は自分がトップにいないことを見て、失敗していると内面化します。2025年のSales Management Associationの調査では、AIコーチングツールを使用している企業の担当者の34%がより高い仕事上のストレスを報告し、そのうち41%がロールアウトから6ヶ月以内に転職活動を始めていたことが示されました。修正策は、担当者に見えるダッシュボードでコーチングデータとランキングデータを分離することです。
「Routing モデルのICPバイアス」とは実際にどういう意味ですか?
過去のWinでトレーニングされたスコアリングモデルは、過去のWinに似たLeadを学習します。過去のWinが1つのセグメントに集中していた場合、モデルは新セグメントのLeadを低スコアにします。それらのLeadは対応されず、Closeせず、モデルはこれをそのセグメントが低品質であるという確認として解釈します。誰もモデルが原因であることに気づかないまま、新業種全体がPipelineから締め出される自己強化フィードバックループです。防止策はローンチ前にセグメントバイパスルールを作成することです。新ICPの基準に一致するLeadは、そのセグメントでトレーニングするための50〜100のDealが得られるまでスコアにかかわらず手動レビューRoutingを受けます。
AIガバナンスのオーバーヘッドが大きすぎるとどうわかりますか?
各ガバナンスプロセスの時間コストを監査します。50人未満の担当者チームで、どれかのプロセスが週30分以上かかっているなら、スケールに対して過剰設計されています。この問題の最も一般的なバージョンは、エンタープライズグレードのガバナンスフレームワーク(モデルガバナンス委員会、48時間のRouting異議SLA、完全な監査証跡インフラ)を小規模チームに適用し、ガバナンスオーバーヘッドがAIの時間節約を超える場合です。NIST AI Risk Management Frameworkは展開規模にマッピングされた階層型ガバナンス構造を提供しており、実際のリスクレベルへの取り組みを調整するための正しいテンプレートです。
チームが省略する最も重要なデプロイ前ステップは何ですか?
ゴーライブ前にベースラインメトリクスを取得すること。ベースラインなしでは、クォーター末のミスが問題を強制的に顕在化させるまでパターン2(スコア操作)またはパターン5(モデルドリフト)を検出できません。最小限のベースラインセットは:ファーストタッチアウトリーチの返信率、Lead scoreの分布、Routingの異議率、CRMデータ入力の現在の担当者時間です。これらをローンチ前に文書化するには2〜3時間かかります。それなしでは、90日健全性チェックに比較対象がありません。
「AI Sales Ops 7つの失敗パターン」フレームワークとは何ですか?
AI Sales Opsデプロイメントが失敗する最も一般的な7つの方法を、全失敗面にわたってマッピングした診断フレームワークです。人間の抵抗(担当者の反発、コーチング不安)、データ操作(Lead Scoreの操作、ICPバイアス)、出力品質の崩壊(コーポレートAIメール)、モデルの劣化(予測ドリフト)、ガバナンスオーバーヘッドの逆転(監査オーバーヘッド)。このフレームワークが存在するのは、失敗パターンが対称的でないからです。7つのうち5つは主に組織的で、2つ(操作、ドリフト)は主に技術的です。どちらのタイプに対処しているかを知ることで、RevOpsリードを呼ぶべきかモデルチームを呼ぶべきかが決まります。
次に読む記事
- Anti Patterns: AIの組み合わせが失敗するとき:10パターン全体にわたるパターンレベルの失敗パターン
- AI Sales Opsのガバナンスと監査証跡:これらの失敗パターンのほとんどを防ぐガバナンスフレームワーク
- AI Sales Ops実装ロードマップ:デプロイメントリスクを減らす順序化されたロールアウト
- よくあるAI Lead Scoringの落とし穴:Scoringパターンに適用した失敗パターン2と6のより深い扱い

Co-Founder, Rework.com