Mod Kegagalan: Apabila AI Sales Ops Membawa Mudarat
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Pelaksanaan AI sales ops yang gagal biasanya bukan kegagalan teknikal. Model berfungsi dengan baik. Panggilan API dikembalikan tepat pada masanya. Integrasi CRM terpelihara. Masalahnya adalah organisasi: pasukan tidak mempercayai sistem, atau mempermainkannya, atau menggunakannya dengan cara yang salah, atau sekadar mengabaikannya selepas tiga minggu pertama.
Ini adalah artikel penutup koleksi. Ia juga yang paling penting jika Anda akan membuat keputusan pembelian atau keputusan pembinaan. Kerana jika Anda tahu apa yang memecahkan sistem ini sebelum Anda menggunakannya, Anda mempunyai peluang yang munasabah untuk tidak memecahkan sistem Anda sendiri. Untuk mod kegagalan peringkat corak yang lebih luas merentasi semua 10 corak AI, lihat Anti Patterns: AI Combinations That Fail dan Hallucination Risk by AI Pattern.
Tujuh mod kegagalan. Setiap satunya berlaku dalam syarikat sebenar. Setiap satunya boleh dicegah.
Fakta Utama: Risiko Penggunaan AI Sales Ops pada 2026
- 80.3% projek AI gagal menyampaikan nilai perniagaan yang dimaksudkan, dengan 33.8% ditinggalkan sebelum produksi (RAND Corporation, 2025)
- 76% penggunaan ejen AI mengalami kegagalan kritikal dalam 90 hari pertama merentasi 847 pelaksanaan yang dijejaki
- 70% pasukan jualan melaporkan penentangan aktif terhadap penerimaan AI, dan hanya 20% jurujual menggunakan alat AI secara kerap atau harian
The 7 AI Sales Ops Failure Modes
Tujuh mod kegagalan di bawah adalah rangka kerja diagnostik bernama untuk pelaksanaan AI sales ops. Ia merangkumi seluruh permukaan kegagalan: penentangan manusia (Mod 1 dan 4), permainan data (Mod 2 dan 6), keruntuhan kualiti output (Mod 3), pereputan model (Mod 5), dan penyongsangan overhead tadbir urus (Mod 7). Setiap mod mempunyai laluan pencegahan yang diketahui dan laluan pemulihan yang diketahui.
Mod Kegagalan 1: Pemberontakan Rep
Gejala: Kadar penerimaan di bawah 40% pada 90 hari. Rep menggunakan alat apabila pengurus memerhati, tidak menggunakannya apabila mereka tidak.
Punca: Pelancaran tidak melibatkan rep dalam konfigurasi, dan alat dibingkai sebagai pemantauan dan bukannya bantuan. Meeting intelligence adalah pencetus yang paling biasa. Rep yang mengetahui bahawa setiap panggilan dirakam dan pengurus mereka mendapat dashboard prestasi yang dijana AI tidak mendaftar untuk itu. Dan jika tiada siapa yang bertanya kepada mereka sebelum pelancaran, kebenciannya adalah segera.
Satu syarikat melancarkan Gong kepada pasukan 35 rep pada 2024 tanpa perbualan pra-pelancaran tentang data apa yang akan dan tidak akan disemak pengurus. Dalam masa enam minggu, 12 rep menjadualkan panggilan mereka pada telefon peribadi di luar sistem. Lapan sedang memfailkan aduan kepada HR tentang pengawasan. Pelancaran itu dijeda. Empat bulan kos langganan terbuang, ditambah dengan buruh pelaksanaan.
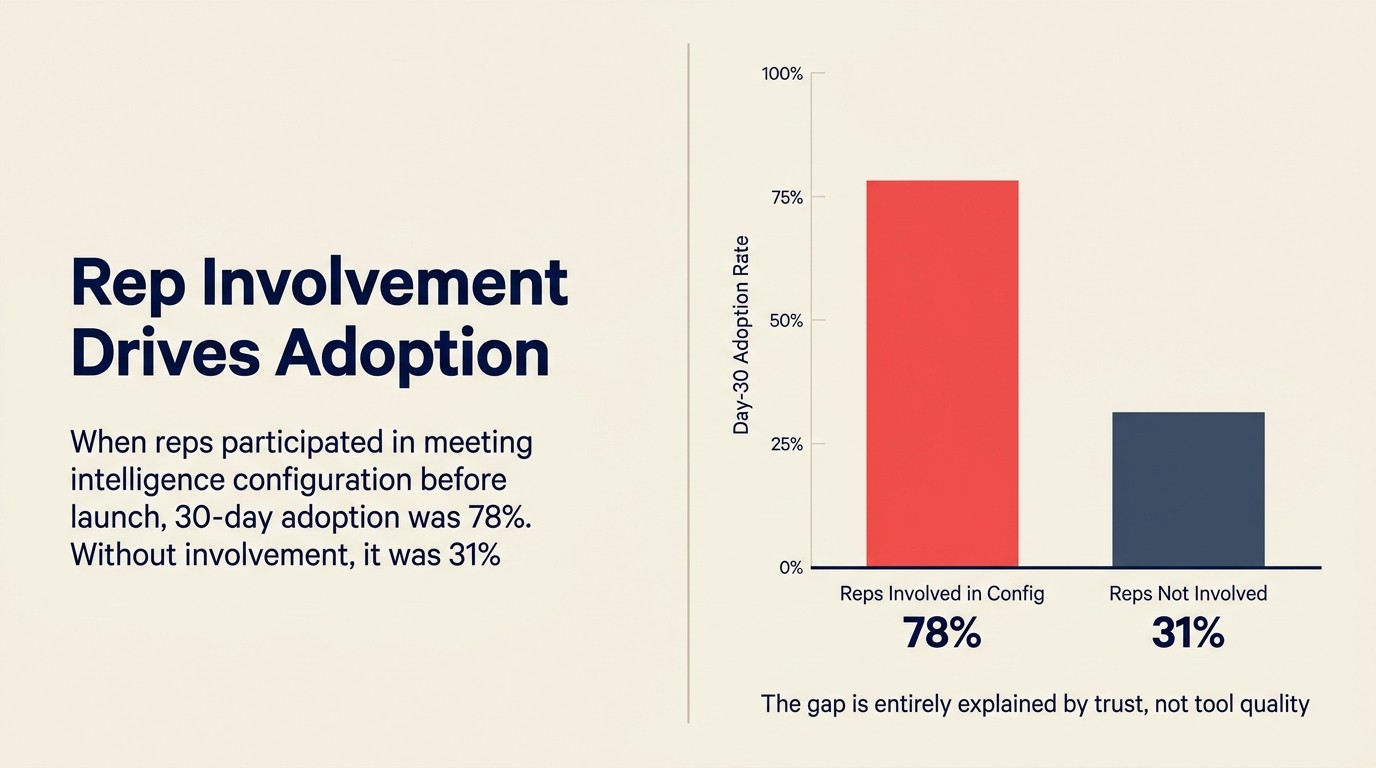
Angka: Data penggunaan dalaman dari pasukan RevOps SaaS mid-market, dikongsi dalam panel SaaStr 2025: apabila rep terlibat dalam keputusan konfigurasi meeting intelligence (medan mana yang auto-mengisi, klip panggilan mana yang boleh diakses pengurus, bagaimana maklum balas kejurulatihan akan disampaikan), penerimaan 30 hari adalah 78%. Apabila rep tidak terlibat, penerimaan 30 hari adalah 31%. Stanford HAI AI Index 2025 secara konsisten mendapati bahawa kesediaan organisasi dan kepercayaan pemegang kepentingan, bukan prestasi model, adalah faktor yang memisahkan penggunaan AI perusahaan yang berjaya daripada yang gagal.
Pencegahan: Jalankan sesi pra-pelancaran 2 minggu dengan kumpulan sampel rep. Biarkan mereka melihat alat itu, tanya apa yang mereka mahu lakukan, dan tunjukkan apa yang mereka bimbangkan. Buat komitmen khusus: "Rakaman akan digunakan untuk kejurulatihan, bukan ulasan prestasi," kemudian hormatinya. Rep yang bimbang tentang pengawasan menjadi penyokong apabila mereka merasakan sistem direka bentuk untuk kepentingan mereka, bukan menentang mereka.
Pemulihan: Jika penerimaan sudah runtuh, jangan tolak. Henti, akui masalah, dan mulakan proses reka bentuk bersama rep yang sepatutnya berlaku sebelum pelancaran. Pelancaran semula yang dibingkai sekitar "kami mendengar kebimbangan Anda dan kami telah membuat perubahan ini" memulihkan kepercayaan lebih cepat daripada sebarang pendekatan lain.
Quotable Nugget: Apabila rep terlibat dalam keputusan konfigurasi meeting intelligence sebelum pelancaran, penerimaan 30 hari mencapai 78%. Apabila mereka tidak terlibat, ia jatuh kepada 31%. Jurang itu dijelaskan sepenuhnya oleh kepercayaan, bukan oleh kualiti alat. (Data penggunaan dalaman, pasukan RevOps SaaS mid-market, panel SaaStr 2025)
Mod Kegagalan 2: Skor Lead Dipermainkan
Gejala: Skor lead meningkat secara meluas dalam 3-6 bulan walaupun kadar tutup kekal rata atau menurun.
Punca: Rep mempelajari input mana yang memacu skor tinggi dan mula mengoptimumkan input tersebut secara manual. Jika model scoring memberi berat tinggi kepada "saiz syarikat" dan rep boleh mengedit saiz syarikat pada rekod kenalan, jangkakan inflasi. Jika "lawatan laman web" berkorelasi dengan skor dan rep boleh mencetuskan lawatan laman web dengan menghantar pautan melalui e-mel, jangkakan penghantaran pautan menjadi satu sukan.
Ini adalah masalah Goodhart's Law yang diterapkan kepada lead scoring: apabila ukuran menjadi sasaran, ia tidak lagi menjadi ukuran yang baik. Rep tidak melakukan ini kerana mereka berniat jahat. Mereka melakukannya kerana mereka mahu lebih banyak lead yang baik, dan mereka menemui tuas tersebut. Artikel perangkap biasa AI lead scoring merangkumi ini dan corak kegagalan Scoring and Routing lain secara mendalam.
Satu syarikat B2B SaaS yang menjalankan model scoring yang dibina sendiri melihat purata skor lead menyimpang dari purata 62 ke purata 79 dalam masa 8 bulan. Kadar tutup jatuh dari 22% ke 14% pada lead "berskor tinggi" dalam tempoh yang sama. Apabila mereka mengaudit data, 40% lead berskor tinggi mempunyai medan saiz syarikat yang telah diedit secara manual dalam 30 hari sebelum scoring.
Pencegahan: Jangan biarkan rep mengedit medan yang paling berat dalam model scoring. Gunakan medan yang diisi sistem (dari pembekal data Anda, dari log penggunaan produk, dari analitik laman web) untuk input scoring, bukan medan CRM yang boleh diedit rep. Jika Anda mesti menggunakan medan yang boleh diedit rep, sertakan log audit "terakhir diedit oleh" supaya anomali scoring kelihatan.
Pemulihan: Audit berat ciri scoring Anda berbanding data penukaran sebenar Anda. Jika lead berskor tinggi tidak menukar pada kadar lebih tinggi berbanding lead berskor sederhana, skor telah dipermainkan atau model telah menyimpang. Latih semula dengan data sumber yang tidak boleh diedit rep secara langsung, dan ketatkan kebenaran edit medan ke hadapan.
Quotable Nugget: Goodhart's Law adalah risiko yang paling tidak dihargai dalam penggunaan AI scoring. Saat skor lead menjadi input kuota, rep mengoptimumkan skor, bukan kualiti pipeline. Penyelesaiannya adalah menggunakan input yang diisi sistem yang tidak boleh disentuh rep, bukan latihan semula model yang lebih banyak.
Mod Kegagalan 3: E-mel Auto-Draf Kedengaran Seperti AI Korporat
Gejala: Kadar balasan e-mel jatuh selepas melancarkan penyusunan e-mel berbantuan AI. Bentuk paling rendah kegagalan ini: rep menghantar e-mel yang di-draf AI kepada prospek hubungan jangka panjang yang membalas "Ini tidak kedengaran seperti Anda. Adakah semua baik-baik sahaja?"
Punca: Alat penyusunan e-mel siap pakai yang dilatih pada korpus e-mel jualan generik menghasilkan e-mel jualan generik. Ia betul secara tatabahasa. Ia menggunakan struktur yang munasabah. Dan ia kedengaran persis seperti setiap e-mel sejuk yang dijana AI lain yang menyentuh peti masuk yang sama.
Corak khusus yang membunuh kadar balasan:
- Pembuka yang merujuk "landskap semasa [industri]" atau "dalam persekitaran serba pantas hari ini"
- Ayat yang bermula dengan "I wanted to reach out" (setiap AI menulis ini)
- Perenggan cadangan nilai yang menyenaraikan ciri sebagai titik peluru ("With our platform, you can: [senarai perkara]")
- CTA yang berkata "Would you be open to a quick 15-minute call?" (penutup AI universal)
Outreach yang diperibadikan AI pada skala merangkumi pendekatan berasaskan penyelidikan yang mengelakkan corak ini.
Satu pasukan jualan di syarikat SaaS 200 rep menjejaki kadar balasan sebelum dan selepas pelancaran e-mel AI. Sebelum: kadar balasan 8.2% pada outreach sentuhan pertama. Selepas 60 hari penyusunan AI dengan semakan rep: 6.1%. Selepas 90 hari: 5.4%. Rep hanya mengedit sedikit draf AI tetapi tidak menulis semula secara asas. Suara AI telah menggantikan suara rep.
Pencegahan: Jangan gunakan penyusunan e-mel AI sebagai jalan pintas untuk menulis. Gunakan ia sebagai titik permulaan yang rep benar-benar tulis semula. Nilainya bukan draf itu; ia adalah struktur dan input data pemperibadian. Bina bar kualiti mudah: sebarang e-mel yang di-draf AI yang masih mengandungi frasa "I wanted to reach out" atau sebarang ayat yang bermula dengan "I hope this finds you well" tidak boleh dihantar.
Latih rep tentang rupa corak yang dijana AI dan mengapa prospek mengenalinya. Rep yang memahami mengapa draf AI kedengaran seperti AI lebih berkemungkinan untuk membetulkannya berbanding rep yang hanya fikir ia kedengaran baik.
Pemulihan: Jika kadar balasan telah jatuh, tarik sampel e-mel yang di-draf AI yang telah dihantar. Baca dengan kuat. Jika mana-mana daripadanya kedengaran seperti siaran akhbar dan bukannya manusia yang bercakap dengan manusia lain, Anda telah menemui masalah. Jalankan ujian terpisah: yang di-draf AI berbanding yang ditulis rep dari awal, lead yang sama, minggu yang sama. Jurang tersebut akan memberitahu Anda berapa banyak suara AI menyakitkan.
Quotable Nugget: Pasukan SaaS 200 rep menjejaki kadar balasan sebelum dan selepas pelancaran e-mel AI: 8.2% sebelum, 5.4% selepas 90 hari. Rep tidak melangkau semakan. Mereka mengedit sedikit draf AI dan menghantarnya. Suara AI telah menggantikan suara rep tanpa sesiapa menyedari.
Mod Kegagalan 4: Dashboard Kejurulatihan Mewujudkan Kebimbangan Rep dan Risiko Pemergian
Gejala: Pusing ganti sukarela meningkat dalam kalangan rep peringkat pertengahan dalam 6-12 bulan selepas pelancaran meeting intelligence. Tema temu bual keluar berkisar sekitar "rasa diawasi secara ketat" atau "sentiasa dipantau."
Punca: Dashboard kejurulatihan AI mendedahkan metrik rep individu pada butiran yang terasa mengancam dan bukannya untuk pembangunan. Nisbah masa bercakap. Bilangan soalan setiap panggilan. Bilangan sebutan pesaing yang ditangani. Panjang monolog. Metrik ini bertujuan untuk membantu rep meningkatkan diri. Apabila ia dipaparkan pada dashboard yang kelihatan kepada pengurus dengan kedudukan, ia berfungsi sebagai sistem tekanan prestasi.
Rep peringkat pertengahan (pengurus prestasi persentil ke-50 hingga ke-75) adalah yang paling terdedah. Pemenang teratas berasa yakin dengan nombor mereka. Pemenang bawah sudah tahu mereka sedang berjuang. Rep peringkat pertengahan melihat metrik yang menunjukkan mereka tidak berada di atas dan menginternalisasikannya sebagai "Saya gagal." Apabila data sentiasa aktif dan sentiasa kelihatan, tekanan tidak dilepaskan antara perbualan kejurulatihan.
Ini adalah nyata. Satu tinjauan 2025 terhadap 200 profesional jualan B2B oleh Sales Management Association mendapati bahawa 34% rep di syarikat yang menggunakan alat kejurulatihan AI melaporkan tekanan kerja yang jauh lebih tinggi berbanding sebelum pelancaran. Daripada jumlah tersebut, 41% berkata mereka telah mula menemu ramah untuk jawatan lain dalam 6 bulan selepas pelancaran.
Pencegahan: Asingkan metrik kejurulatihan daripada metrik prestasi dalam dashboard yang kelihatan kepada rep. Rep sepatutnya melihat data dan trend kejurulatihan mereka sendiri. Mereka sepatutnya tidak melihat kedudukan yang membandingkan mereka dengan rakan sebaya pada setiap metrik setiap hari. Dashboard kejurulatihan adalah alat pembangunan, bukan papan skor.
Reka bentuk aliran kerja kejurulatihan sekitar perbualan, bukan dashboard. Tugas pengurus adalah memilih satu metrik setiap rep setiap minggu, tunjukkan data, dan bincangkan apa yang mendorongnya. Bukan untuk berkongsi dashboard penuh dan biarkan rep membuat kesimpulan sendiri.
Pemulihan: Jika penunjuk risiko pemergian meningkat, audit bagaimana pengurus sebenarnya menggunakan data kejurulatihan. Masalahnya hampir tidak pernah pada teknologi. Ia adalah pengurus yang menggunakan metrik AI sebagai senjata prestasi dan bukannya alat kejurulatihan. Melatih pengurus tentang penyampaian maklum balas dengan data AI lebih penting daripada sebarang perubahan konfigurasi dashboard.
Mod Kegagalan 5: Model Ramalan Over-Fit kepada Suku Terkini
Gejala: Ketepatan ramalan kukuh untuk 2-3 suku selepas latihan model, kemudian mula merosot. Ketepatan jatuh mendadak apabila keadaan pasaran berubah (pesaing baharu masuk, perubahan harga, angin sakal makro).
Punca: Model ramalan AI belajar dari corak tawaran sejarah. Ia sangat baik dalam meramalkan hasil yang kelihatan seperti hasil masa lalu. Apabila persekitaran berubah dengan ketara (dinamik jawatankuasa pembelian berbeza, tekanan persaingan baharu, perlambatan makro mengurangkan perbelanjaan budi bicara), data latihan model tidak lagi menggambarkan persekitaran semasa. Model tidak tahu ada perubahan rejim; ia terus membuat ramalan seolah-olah masa lalu masih masa kini.
Contoh konkrit: syarikat SaaS mid-market melatih model ramalan Clari mereka dalam S3 2024 pada 18 bulan data tawaran dari pasaran mod pertumbuhan. Penyelidikan State of AI McKinsey melaporkan bahawa kurang daripada 20% organisasi secara sistematik memantau model AI mereka untuk pereputan prestasi pasca-penggunaan, itulah sebabnya kemunduran daripada perubahan rejim tidak dikesan sehingga kelewatan akhir suku memaksa isu tersebut. Model belajar bahawa tawaran dengan penglibatan berbilang-benang (3+ kenalan aktif dalam 30 hari terakhir) mempunyai kadar tutup 72% pada peringkat cadangan. Dalam S2 2025, apabila keadaan ekonomi mengetat, jawatankuasa pembelian mula melambatkan walaupun dengan kenalan yang terlibat. Tawaran berbilang-benang pada peringkat cadangan ditutup pada 51%. Model terus meramalkan 72%. Ramalan adalah 28% melebihi aktual untuk dua suku sebelum sesiapa menyedari penyimpangan.
Pencegahan: Tetapkan kadens pemantauan ketepatan model sebelum penggunaan. Perbandingan bulanan kadar tutup yang diramalkan berbanding aktual untuk tawaran yang diramalkan bulan sebelumnya. Jika jurang yang diramalkan berbanding aktual berkembang lebih daripada 10 mata peratusan dalam bulan berturut-turut, tandakan untuk semakan latihan semula. Jangan tunggu kelewatan akhir suku. Apabila corak AI menjadi hutang teknikal merangkumi masalah pereputan model pada peringkat corak, termasuk cara mengenali apabila model telah menyimpang melebihi penentukuran semula.
Sertakan "protokol perubahan rejim" dalam dokumentasi tadbir urus Anda. Jika peristiwa pasaran besar berlaku (pesaing baharu, perubahan harga, peralihan makro), cetuskan semakan ketepatan luar kitaran. Pertimbangan ramalan manusia sepatutnya diberi berat secara eksplisit berbanding output model selepas perubahan rejim, bukan dianggap sebagai bunyi penggantian.
Pemulihan: Latih semula dengan 6-9 bulan data terkini yang diberi berat lebih tinggi berbanding data yang lebih lama. Bincangkan secara eksplisit apa yang berubah tentang pasaran dengan pasukan CS/Jualan Anda, dan kenal pasti corak sejarah mana yang tidak lagi mewakili.
Quotable Nugget: 32% saluran paip scoring produksi mengalami peralihan pengedaran dalam enam bulan pertama penggunaan. Model tanpa pemantauan ketepatan aktif menunjukkan kemerosotan 14-19% dalam masa 18 bulan, berbanding dalam 2.4% prestasi awal untuk pasukan yang menjalankan semakan ketepatan bulanan. (IBM / Superwise AI, 2025)
Mod Kegagalan 6: Model Routing Mengunci Berat Sebelah ICP Lama
Gejala: AI lead scoring dan routing Anda secara konsisten mengutamakan segmen lead yang sempit. Segmen lain (vertikal baharu yang Anda berkembang ke dalam, syarikat lebih kecil yang mungkin sesuai sebagai PLG, akaun antarabangsa) jarang dikerjakan dan jarang ditutup. Anda akhirnya menyedari: AI telah menyaringnya secara sistematik.
Punca: Model scoring yang dilatih pada data kemenangan sejarah belajar lead mana yang kelihatan seperti kemenangan masa lalu. Jika kemenangan masa lalu Anda tertumpu dalam satu segmen (katakan, syarikat SaaS berasaskan AS antara 100-500 pekerja, VP ke atas), model belajar profil tersebut sebagai "skor tinggi" untuk ICP Anda. Lead dari segmen ICP baharu yang sedang Anda sasarkan secara aktif tidak sepadan dengan corak sejarah dan berskor rendah. Mereka di-route ke nurture. Mereka tidak ditutup, bukan kerana mereka lead yang buruk, tetapi kerana mereka tidak pernah dikerjakan. Model mentafsir ini sebagai pengesahan bahawa segmen baharu berkualiti rendah.
Ini adalah gelung maklum balas yang berganda. Model scoring mengutamakan lead segmen baharu ke bawah. Rep tidak mengerjakan mereka. Mereka tidak ditutup. Model melihat kadar tutup rendah dari segmen tersebut. Skor semakin rendah. Segmen baharu secara berkesan terkunci keluar dari pipeline oleh model yang tidak pernah dikemas kini untuk mencerminkan strategi semasa.
Satu syarikat menghabiskan 6 bulan untuk menembusi pembuatan mid-market (vertikal baharu) dengan gerakan GTM yang termasuk mengupah rep vertikal khusus. Rep itu mengadu lead yang diterimanya berkualiti rendah. Audit mendedahkan lead-nya secara konsisten berskor dalam julat 30-45 kerana model scoring tidak pernah melihat syarikat pembuatan ditutup. Dia secara sistematik dirugi oleh model. Corak Scoring and Routing menerangkan bagaimana skop data latihan menentukan segmen mana yang boleh dinilaikan model dengan boleh dipercayai.
Pencegahan: Apabila Anda menambah segmen ICP baharu, gantikan scoring secara eksplisit untuk segmen tersebut sehingga Anda mempunyai 50-100 tawaran dalam segmen untuk dilatih. Cipta peraturan bypass segmen: "Lead yang sepadan dengan [kriteria ICP baharu] mendapat routing semakan manual tanpa mengira skor."
Jalankan audit kepelbagaian segmen suku tahunan pada populasi lead yang diskor Anda. Jika satu segmen secara konsisten mewakili 80%+ lead berskor tinggi dan Anda mempunyai matlamat pengembangan strategik di luar segmen tersebut, model memerlukan penentukuran peringkat segmen.
Pemulihan: Latih semula model dengan pensampelan berstratifikasi segmen. Pastikan set latihan memasukkan contoh yang mencukupi dari segmen yang kurang terwakili untuk memberikan model isyarat yang adil. Sehingga latihan semula selesai, route segmen yang kurang terwakili secara manual.
Mod Kegagalan 7: Overhead Audit Melebihi Penjimatan untuk Pasukan Kecil
Gejala: Pasukan RevOps menghabiskan lebih banyak masa mengurus tadbir urus AI, menyemak keputusan AI, dan bertindak balas kepada pertikaian rep berbanding penjimatan AI dalam masa rep. Alat tersebut bersih negatif pada kecekapan operasi.
Punca: Rangka kerja tadbir urus gred perusahaan diterapkan kepada penggunaan AI pasukan kecil. Pasukan jualan 10 rep yang menjalankan model lead scoring tidak memerlukan jawatankuasa tadbir urus model, semakan ketepatan suku tahunan, dan proses pertikaian routing berstruktur dengan SLA 48 jam. Tetapi jika ketua RevOps mereka membaca panduan tadbir urus AI perusahaan dan melaksanakan rangka kerja penuh, mereka telah mewujudkan overhead pentadbiran yang berskala buruk pada saiz pasukan mereka.
Versi khusus yang paling biasa: meeting intelligence pada 8-12 rep, dengan aliran kerja semakan transkrip penuh, kadens analisis dashboard kejurulatihan, dan proses semakan ringkasan pipeline yang dijana AI dilapis di atas. Setiap komponen boleh dipertahankan secara individu. Bersama-sama, mereka boleh menambah 4-6 jam overhead RevOps per minggu untuk pasukan yang mempunyai satu orang Sales Ops.
Jika orang itu menjimatkan 2 jam per minggu masa rep merentasi pasukan, mereka telah mewujudkan kerugian bersih.
Pencegahan: Padankan tadbir urus dengan risiko dan skala sebenar. Model tadbir urus syarikat permulaan (2-3 peraturan, log dalam hamparan, semakan 30 minit bulanan) adalah tahap yang betul untuk pasukan di bawah 20 rep. Infrastruktur jejak audit penuh, jawatankuasa tadbir urus model, dan dashboard pematuhan automatik adalah milik skala 100+ rep dengan pasukan RevOps khusus.
Sebelum menambah sebarang keperluan tadbir urus, tanya: apakah kes terburuk jika ini gagal? Jika jawapannya adalah "rep mempertikaikan keputusan routing sekali dalam satu suku," log hamparan dan laluan pertikaian yang jelas mengendalikannya. Jika jawapannya adalah "kami melanggar GDPR dan didenda," bina infrastruktur yang betul. NIST AI Risk Management Framework menyediakan struktur tadbir urus berjenjang yang memetakan terus kepada skala penggunaan, yang merupakan templat yang betul untuk menentukur usaha tadbir urus kepada tahap risiko sebenar.
Pemulihan: Audit overhead tadbir urus Anda dengan jujur. Jika mana-mana proses tadbir urus tunggal mengambil masa lebih daripada 30 minit per minggu untuk pasukan di bawah 50 rep, ia mungkin terlalu direkayasa. Sederhanakan. Matlamatnya bukan tadbir urus untuk kepentingannya sendiri; ia adalah tadbir urus yang menangkap masalah sebenar tanpa mewujudkan lebih banyak beban daripada penjimatan AI.
Quotable Nugget: Rangka kerja tadbir urus yang direka bentuk untuk pasukan perusahaan 100 rep menjana overhead RevOps 4-6 jam per minggu apabila diterapkan kepada pasukan 8-12 rep. Pada skala tersebut, kos tadbir urus melebihi penjimatan masa AI yang sepatutnya dilindungi. Padankan tadbir urus dengan risiko dan saiz pasukan sebenar, bukan dengan kecanggihan dokumentasi pematuhan vendor Anda.
Ringkasan risiko mod kegagalan

Tujuh mod kegagalan tidak sama kemungkinan atau sama kosnya. Jadual ini memetakan setiap mod kepada corak pencetus paling biasa, lag pengesanan, dan masa pemulihan biasa supaya Anda boleh mengutamakan pelaburan pra-pelancaran.
| Mod Kegagalan | Pencetus Utama | Lag Pengesanan Biasa | Masa Pemulihan | Pencegahan Paling Berkesan |
|---|---|---|---|---|
| Pemberontakan Rep | Pelancaran tanpa penglibatan rep | 30-60 hari | 3-4 bulan | Sesi reka bentuk bersama pra-pelancaran |
| Permainan Skor Lead | Input scoring yang boleh diedit rep | 90-180 hari | 6-8 minggu (latihan semula) | Kunci medan scoring pada pelancaran |
| E-mel AI Korporat | Semakan rep yang cetek terhadap draf | 60-90 hari | 2-3 minggu (kejurulatihan) | Senior-Rep Voice Test sebelum hantar |
| Kebimbangan Kejurulatihan / Risiko Pemergian | Kedudukan kelihatan kepada semua rep | 90-270 hari | Berbeza; sesetengah rep tidak kembali | Asingkan data kejurulatihan dari data kedudukan |
| Pereputan Model (Ramalan) | Perubahan rejim pasaran | 60-90 hari | 4-6 minggu (latihan semula) | Semakan yang diramalkan berbanding aktual bulanan |
| Berat Sebelah ICP / Penguncian Segmen | Vertikal baharu tanpa peraturan bypass | 90-180 hari | 8-12 minggu (latihan semula + audit) | Peraturan bypass segmen pada pelancaran |
| Penyongsangan Overhead Tadbir Urus | Rangka kerja perusahaan pada skala PKS | 30-90 hari | 1-2 minggu (sederhanakan) | Padankan tadbir urus dengan saiz pasukan |
Sumber: RAND Corporation, Sales Management Association, IBM, data pasukan RevOps dalaman (2025)
Senarai semak pra-penggunaan
Sebelum pergi hidup dengan mana-mana corak AI sales ops, semak ini:
Data:
- 12+ bulan sejarah tawaran bersih dengan label menang/kalah yang konsisten
- 70%+ kelengkapan pada medan kenalan teras (syarikat, jawatan, industri)
- Medan yang boleh diedit rep dikunci untuk input model scoring
- Anomali perkembangan peringkat diaudit dan diselesaikan
Tadbir urus:
- Bahasa persetujuan rakaman disemak oleh pihak undang-undang
- Semakan GDPR/privasi selesai untuk kes penggunaan scoring
- Proses pertikaian routing didokumentasikan dan disosialisasikan
- Skema log audit ditentukan dan dikonfigurasi
- Penjejakan versi model tersedia sebelum penggunaan model
Change management:
- Kumpulan sampel rep terlibat dalam keputusan konfigurasi
- Komitmen khusus dibuat tentang data apa yang akan dan tidak akan digunakan pengurus
- Pelancaran dibingkai sebagai penjimatan masa untuk rep, bukan pemantauan untuk pengurus
- Pelan penerimaan 30 hari (siapa yang bertanggungjawab untuk penerimaan rep, bagaimana diukur)
- Latihan pengurus tentang menggunakan data kejurulatihan AI sebagai alat pembangunan
Pemantauan:
- Metrik asas diambil pra-pelancaran (kadar balasan, kelajuan routing, kadar kelengkapan CRM)
- Semakan penerimaan 30 hari dan 90 hari dijadualkan dalam kalendar
- Kadens pemantauan ketepatan model ditentukan (perbandingan bulanan)
- Ambang amaran dikonfigurasi untuk corak anomali (inflasi skor, jumlah pertikaian routing)
Rangka kerja pemeriksaan kesihatan 90 hari

Pada 90 hari selepas pelancaran, semak metrik ini untuk setiap corak yang digunakan:
Scoring and Routing:
- Ketepatan routing: berapa % lead yang di-route sedang dipertikaikan atau ditugaskan semula secara manual? (Sasaran: di bawah 10%)
- Inflasi skor: adakah purata skor lead bergerak lebih daripada 5 mata dari asas? (Tandakan jika ya)
- Korelasi kadar tutup: adakah lead berskor tinggi ditutup pada kadar lebih tinggi berbanding lead berskor rendah? (Jika tidak, model mungkin sedang dipermainkan atau menyimpang)
Meeting Intelligence:
- Kadar penyertaan rakaman: berapa % panggilan sasaran sedang dirakam? (Sasaran: melebihi 85%)
- Peningkatan kadar kelengkapan CRM: adakah AI auto-write meningkatkan % panggilan dengan nota CRM lengkap?
- Denyut kepuasan rep: tinjauan satu soalan kepada rep: "Adakah meeting intelligence menjadikan kerja Anda lebih mudah atau lebih sukar?" (Skor bersih sepatutnya positif menjelang 90 hari)
Generative Research:
- Penerimaan ringkasan penyelidikan: berapa % sentuhan akaun baharu menyertakan ringkasan yang dijana AI? (Sasaran: melebihi 60%)
- Masa penyelidikan pra-panggilan: diukur pada 90 hari berbanding asas (Sasaran: pengurangan 40%+)
- Penilaian diri kualiti ringkasan: penilaian rep terhadap kualiti ringkasan (skala 1-5; sasaran melebihi 3.5)
Workflow Copilot:
- Kadar penerimaan NBA: berapa % tindakan seterusnya yang dicadangkan sedang ditindaklanjuti? (Sasaran: melebihi 30%)
- Pengurangan masa pentadbiran: masa rep yang diukur pada kemasukan data CRM berbanding asas pra-AI
- Panjang mesyuarat semakan pipeline: sebelum dan selepas pelancaran ringkasan AI (Sasaran: pengurangan 20%+)
Rework Analysis: Merentasi tujuh mod kegagalan, lima mempunyai akar yang sama: penggunaan dibentuk sebagai projek teknologi, bukan sebagai projek change management. Mod 1, 3, 4, 6, dan 7 semuanya melibatkan tingkah laku manusia dan pilihan reka bentuk pasukan yang dibuat selepas vendor dipilih, bukan sebelumnya. Mod 2 (permainan) dan Mod 5 (pereputan) adalah dua mod kegagalan teknikal yang tulen, dan kedua-duanya mempunyai protokol pencegahan yang diketahui. Pasukan yang mengelakkan kegagalan ini biasanya melakukan satu perkara secara berbeza: mereka menentukan metrik kejayaan sebelum penggunaan, bukan selepas semakan 30 hari pertama. Templat tadbir urus pra-pelancaran Rework menyertakan pengambilan metrik asas sebagai langkah yang diperlukan dalam Fasa 0, itulah sebabnya pasukan yang menggunakannya mengesan kegagalan Mod 2 dan Mod 5 purata 6-8 minggu lebih awal berbanding pasukan yang mula memantau selepas pelancaran.
Kesimpulan yang jujur

Tiada satu pun daripada mod kegagalan ini adalah unik kepada AI. Rep yang tidak mempercayai alat tidak menggunakannya. Sistem yang menghasilkan output berkualiti rendah diabaikan. Proses tadbir urus yang mewujudkan lebih banyak kerja berbanding penjimatan ditinggalkan. Ini adalah masalah pelaksanaan yang setua perisian perusahaan.
Apa yang ditambahkan AI adalah skala dan kelajuan. Model AI yang menyimpang atau berat sebelah membuat keputusan buruk pada setiap lead dalam pipeline, bukan hanya yang akan disalah kategorikan manusia. Dashboard kejurulatihan AI yang mewujudkan kebimbangan rep mewujudkannya untuk setiap rep dalam pasukan secara serentak. Mod kegagalan adalah sama; jejari letupannya lebih besar.
Itulah sebabnya senarai semak pra-penggunaan dan pemeriksaan kesihatan 90 hari bukan langkah pilihan. Ia adalah tabiat operasi yang menangkap masalah sebelum ia berganda.
Berita baiknya: setiap mod kegagalan yang didokumentasikan di sini boleh dicegah, dan setiap laluan pemulihan diketahui. Syarikat yang mendapat AI sales ops dengan betul bukan lebih bijak daripada yang bergelut. Mereka lebih sabar dengan Fasa 0, lebih jujur dengan rep mereka tentang apa yang dilakukan alat itu, dan lebih berdisiplin tentang pemantauan selepas pelancaran.
Mulakan dengan pelan hala tuju pelaksanaan. Bina tadbir urus sebelum Anda memerlukannya, bukan selepas Anda memerlukannya dan sesuatu telah pun salah. Dan baca artikel ini lagi sebelum semakan 90 hari Anda. Mod kegagalan yang tidak Anda bimbangkan pada pelancaran adalah yang akan menemui Anda.
Untuk perspektif peringkat rangka kerja tentang mengapa penggunaan AI gagal sebelum mencapai lapisan sales ops, Mengapa Kebanyakan Rangka Kerja AI Gagal Membantu Operator merangkumi masalah struktural yang sama pada peringkat ACE Foundation.
Apa yang perlu dibaca seterusnya
- Anti Patterns: AI Combinations That Fail: mod kegagalan peringkat corak merentasi landskap 10 corak penuh
- AI Sales Ops Governance dan Jejak Audit: rangka kerja tadbir urus yang mencegah kebanyakan mod kegagalan ini
- Pelan Hala Tuju Pelaksanaan AI Sales Ops: pelancaran berjujukan yang mengurangkan risiko penggunaan
- Perangkap Biasa AI Lead Scoring: rawatan lebih mendalam Mod Kegagalan 2 dan 6 yang diterapkan kepada corak Scoring

Co-Founder, Rework.com
On this page
- The 7 AI Sales Ops Failure Modes
- Mod Kegagalan 1: Pemberontakan Rep
- Mod Kegagalan 2: Skor Lead Dipermainkan
- Mod Kegagalan 3: E-mel Auto-Draf Kedengaran Seperti AI Korporat
- Mod Kegagalan 4: Dashboard Kejurulatihan Mewujudkan Kebimbangan Rep dan Risiko Pemergian
- Mod Kegagalan 5: Model Ramalan Over-Fit kepada Suku Terkini
- Mod Kegagalan 6: Model Routing Mengunci Berat Sebelah ICP Lama
- Mod Kegagalan 7: Overhead Audit Melebihi Penjimatan untuk Pasukan Kecil
- Ringkasan risiko mod kegagalan
- Senarai semak pra-penggunaan
- Rangka kerja pemeriksaan kesihatan 90 hari
- Kesimpulan yang jujur
- Apa yang perlu dibaca seterusnya