Failure Modes: Khi AI Sales Ops Phản Tác Dụng
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AI sales ops deployment thất bại thường không phải là thất bại kỹ thuật. Model chạy tốt. API call trả về đúng giờ. CRM integration ổn định. Vấn đề là về tổ chức: đội không tin hệ thống, hoặc gaming nó, hoặc dùng sai, hoặc đơn giản là bỏ qua nó sau ba tuần đầu.
Đây là bài viết kết thúc collection. Cũng là bài quan trọng nhất nếu bạn sắp đưa ra quyết định mua hoặc quyết định build. Vì nếu bạn biết điều gì phá vỡ các hệ thống này trước khi triển khai, bạn có cơ hội hợp lý để không phá vỡ hệ thống của mình. Với pattern-level failure mode trên tất cả 10 AI pattern, xem Anti Patterns: Các Kết Hợp AI Thất Bại và Hallucination Risk theo AI Pattern.
Bảy failure mode. Mỗi cái đã xảy ra ở công ty thực. Mỗi cái đều có thể ngăn chặn.
Key Facts: Rủi Ro Triển Khai AI Sales Ops 2026
- 80,3% AI project thất bại trong việc cung cấp giá trị kinh doanh dự kiến, với 33,8% bị từ bỏ trước khi đưa vào production. (RAND Corporation, 2025)
- 76% AI agent deployment gặp critical failure trong 90 ngày đầu trên 847 implementation được theo dõi
- 70% sales team báo cáo chủ động resistance với AI adoption, và chỉ 20% salesperson dùng AI tool thường xuyên hoặc hàng ngày

7 AI Sales Ops Failure Mode
Bảy failure mode dưới đây là framework chẩn đoán được đặt tên cho AI sales ops deployment. Chúng bao phủ toàn bộ failure surface: human resistance (Mode 1 và 4), data gaming (Mode 2 và 6), output quality collapse (Mode 3), model decay (Mode 5), và governance overhead inversion (Mode 7). Mỗi mode có prevention path đã biết và recovery path đã biết.
Failure Mode 1: Rep Rebellion
Triệu chứng: Adoption rate dưới 40% ở ngày 90. Rep dùng tool khi manager đang xem, không dùng khi không có.
Root cause: Rollout không có rep tham gia vào configuration, và tool được đóng khung như monitoring thay vì assistance. Meeting intelligence là trigger phổ biến nhất. Rep biết mọi call đang được ghi âm và manager nhận AI-generated performance dashboard thì không đăng ký điều đó. Nếu không ai hỏi họ trước khi ra mắt, sự bực bội là ngay lập tức.
Một công ty roll out Gong cho đội 35 rep năm 2024 không có cuộc trò chuyện pre-launch về dữ liệu gì manager sẽ và không review. Trong sáu tuần, 12 rep lên lịch call trên điện thoại cá nhân ngoài hệ thống. Tám người nộp đơn khiếu nại HR về surveillance. Rollout bị tạm dừng. Bốn tháng chi phí subscription lãng phí, cộng với implementation labor.
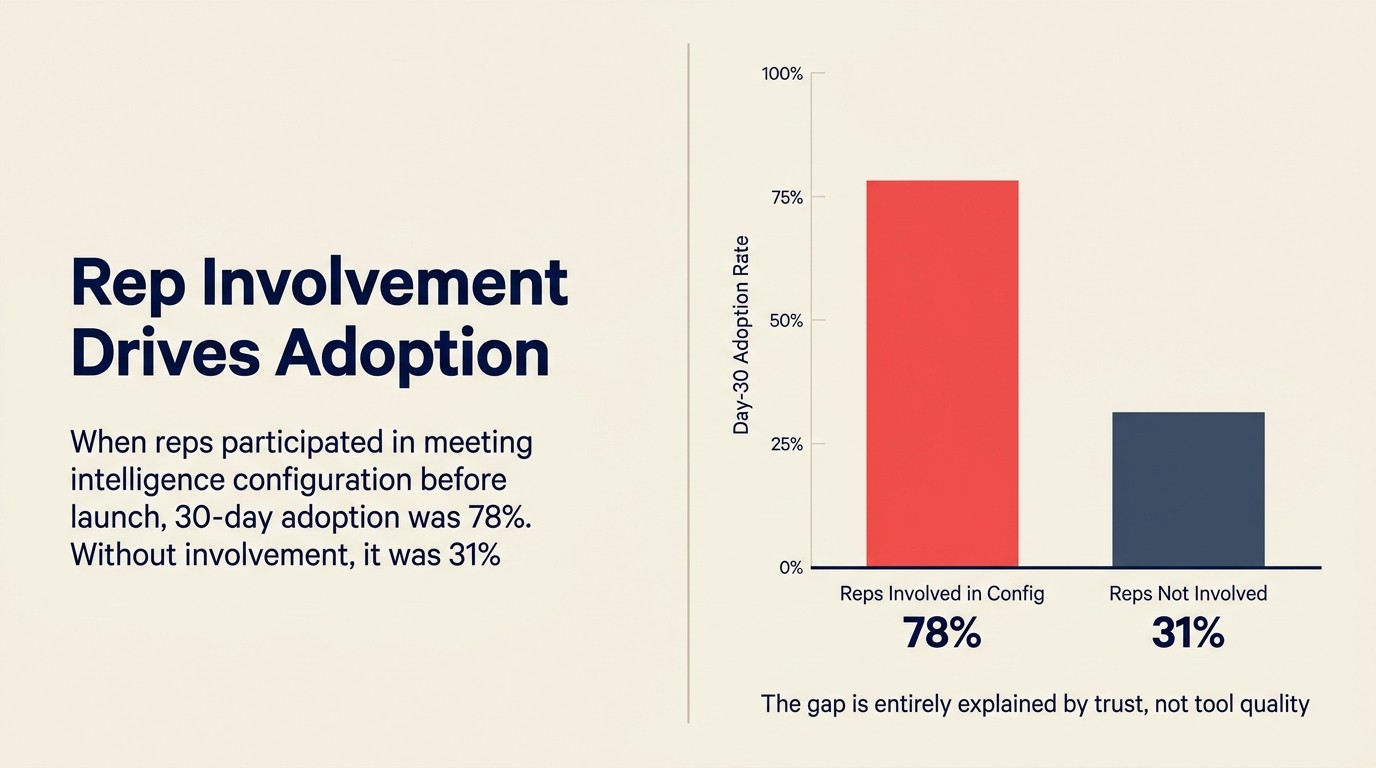
Số liệu: Internal usage data từ mid-market SaaS RevOps team, chia sẻ tại panel SaaStr 2025: khi rep tham gia vào quyết định meeting intelligence configuration (field nào tự động điền, manager truy cập call clip nào, coaching feedback được phân phối thế nào), 30-day adoption là 78%. Khi rep không tham gia, 30-day adoption là 31%. Stanford HAI AI Index 2025 nhất quán thấy organizational readiness và stakeholder trust, không phải model performance, là yếu tố phân biệt deployment thành công với thất bại.
Phòng ngừa: Chạy pre-launch session 2 tuần với nhóm mẫu rep. Để họ xem tool, hỏi họ muốn nó làm gì, và tìm hiểu họ lo ngại gì. Đưa ra cam kết cụ thể: "Recording dùng để coaching, không phải performance review," rồi thực hiện. Rep lo lắng về surveillance trở thành advocate khi họ cảm thấy hệ thống thiết kế vì lợi ích của họ, không phải chống lại.
Phục hồi: Nếu adoption đã sụp đổ, đừng ép. Tạm dừng, thừa nhận vấn đề, và bắt đầu quá trình rep co-design đáng lẽ phải xảy ra trước launch. Re-launch đóng khung xung quanh "chúng tôi đã nghe mối quan tâm của bạn và đã thực hiện những thay đổi này" phục hồi tin tưởng nhanh hơn bất kỳ cách nào khác.
Trích Dẫn Đáng Nhớ: Khi rep tham gia vào quyết định meeting intelligence configuration trước launch, 30-day adoption đạt 78%. Khi không tham gia, nó giảm xuống 31%. Khoảng cách đó hoàn toàn do trust, không phải chất lượng của tool. (Internal usage data, mid-market SaaS RevOps team, panel SaaStr 2025)
Failure Mode 2: Lead Score Bị Gaming
Triệu chứng: Lead score xu hướng tăng toàn bộ trong 3-6 tháng dù close rate giữ nguyên hoặc giảm.
Root cause: Rep học được input nào thúc đẩy điểm cao và bắt đầu tối ưu những input đó thủ công. Nếu scoring model đặt trọng số "company size" cao và rep có thể sửa company size trên contact record, hãy kỳ vọng lạm phát. Nếu "website visit" tương quan với điểm và rep có thể trigger website visit bằng cách email link, hãy kỳ vọng việc gửi link trở thành môn thể thao.
Đây là Goodhart's Law áp dụng cho lead scoring: một khi đo lường trở thành mục tiêu, nó ngừng là đo lường tốt. Rep không làm điều này vì độc ác. Họ làm vì muốn nhiều lead tốt hơn, và họ đã phát hiện ra đòn bẩy. Bài viết những pitfall phổ biến trong AI lead scoring nói chi tiết về điều này và các Scoring và Routing failure pattern khác.
Một công ty B2B SaaS chạy home-built scoring model thấy average lead score trôi từ trung bình 62 lên 79 trong 8 tháng. Close rate giảm từ 22% xuống 14% trên "high-scored" lead trong cùng kỳ. Khi audit dữ liệu, 40% high-scored lead có company size field được sửa thủ công trong 30 ngày trước khi scoring.
Phòng ngừa: Đừng để rep sửa field có trọng số cao nhất trong scoring model. Dùng system-populated field (từ data provider, product usage log, website analytics) cho scoring input, không phải rep-editable CRM field. Nếu phải dùng rep-editable field, thêm "last edited by" audit log để scoring anomaly có thể nhìn thấy.
Phục hồi: Audit scoring feature weight dựa trên conversion data thực tế. Nếu high-scored lead không chuyển đổi tỷ lệ cao hơn mid-scored lead, điểm đã bị gaming hoặc model đã drift. Retrain với source data mà rep không thể trực tiếp sửa, và siết chặt field edit permission.
Trích Dẫn Đáng Nhớ: Goodhart's Law là rủi ro bị đánh giá thấp nhất trong AI scoring deployment. Khoảnh khắc lead score trở thành quota input, rep tối ưu cho điểm số, không phải chất lượng pipeline. Giải pháp là dùng system-populated input mà rep không thể chạm vào, không phải retrain model nhiều hơn.
Failure Mode 3: Auto-Drafted Email Nghe Như Corporate-AI
Triệu chứng: Email reply rate giảm sau khi roll out AI-assisted email drafting. Dạng tệ nhất: rep gửi AI-drafted email cho prospect quan hệ lâu dài và nhận được câu trả lời "Đây không giống bạn. Mọi chuyện có ổn không?"
Root cause: Off-the-shelf email drafting tool train trên generic sales email corpus tạo ra generic sales email. Đúng ngữ pháp. Cấu trúc hợp lý. Và nghe như mọi AI-generated cold email khác đang đến cùng inbox.
Các pattern cụ thể giết reply rate:
- Opener tham chiếu "the current landscape of [industry]" hay "in today's fast-paced environment"
- Câu bắt đầu bằng "I wanted to reach out" (mọi AI đều viết thế này)
- Value proposition paragraph liệt kê feature dưới dạng bullet
- CTA nói "Would you be open to a quick 15-minute call?" (universal AI closer)
AI-generated personalized outreach at scale nói về cách tiếp cận dựa trên nghiên cứu tránh các pattern này.
Một đội sales tại công ty SaaS 200 rep theo dõi reply rate trước và sau khi roll out AI email. Trước: 8,2% reply rate trên first-touch outreach. Sau 60 ngày AI drafting với rep review: 6,1%. Sau 90 ngày: 5,4%. Rep nhẹ nhàng sửa AI draft nhưng không viết lại cơ bản. AI voice đã thay thế rep voice.
Phòng ngừa: Đừng dùng AI email drafting như shortcut để viết. Dùng nó như điểm khởi đầu mà rep thực sự viết lại. Giá trị không phải ở draft, mà ở structure và personalization data input. Xây quality bar đơn giản: bất kỳ AI-drafted email nào vẫn chứa cụm "I wanted to reach out" hoặc câu bắt đầu "I hope this finds you well" thì không được gửi.
Train rep về cách AI-generated pattern trông như thế nào và tại sao prospect nhận ra chúng. Rep hiểu tại sao AI draft nghe như AI sẽ có nhiều khả năng sửa nó hơn rep chỉ nghĩ nó nghe ổn.
Phục hồi: Nếu reply rate đã giảm, lấy mẫu AI-drafted email đã gửi. Đọc to. Nếu bất kỳ cái nào nghe như press release hơn là người nói chuyện với người, bạn đã tìm ra vấn đề. Chạy split test: AI-drafted vs. rep-written từ đầu, cùng lead, cùng tuần. Khoảng cách sẽ cho thấy AI voice đang gây hại bao nhiêu.
Trích Dẫn Đáng Nhớ: Đội 200 rep theo dõi reply rate trước và sau khi roll out AI email: 8,2% trước, 5,4% sau 90 ngày. Rep không bỏ qua review. Họ nhẹ nhàng sửa AI draft và gửi. AI voice đã thay thế rep voice mà không ai nhận ra.
Failure Mode 4: Coaching Dashboard Tạo Anxiety và Rủi Ro Nhân Viên Nghỉ
Triệu chứng: Voluntary turnover tăng trong số mid-tier rep trong 6-12 tháng sau khi roll out meeting intelligence. Chủ đề exit interview xoay quanh "cảm giác bị micromanage" hay "luôn bị theo dõi."
Root cause: AI coaching dashboard hiển thị individual rep metric ở mức độ chi tiết cảm thấy đe dọa thay vì phát triển. Talk time ratio. Question count mỗi call. Số lần đề cập đến đối thủ được xử lý. Monologue length. Các metric này nhằm giúp rep cải thiện. Khi hiển thị trên manager-visible dashboard với ranking, chúng hoạt động như performance pressure system.
Mid-tier rep (50th đến 75th percentile) dễ bị tổn thương nhất. Top performer tự tin với con số của mình. Bottom performer đã biết mình đang gặp khó khăn. Mid-tier rep thấy metric cho thấy không ở trên cùng và nội tâm hóa thành "Tôi đang thất bại." Khi dữ liệu luôn bật và luôn hiển thị, áp lực không giải phóng giữa các coaching conversation.
Điều này có thật. Khảo sát 2025 của Sales Management Association trên 200 B2B sales professional cho thấy 34% rep tại công ty dùng AI coaching tool báo cáo job stress cao hơn đáng kể. Trong số đó, 41% nói đã bắt đầu phỏng vấn nơi khác trong 6 tháng kể từ khi roll out.
Phòng ngừa: Tách coaching metric khỏi performance metric trong rep-visible dashboard. Rep thấy coaching data và trend của mình. Không thấy ranking so sánh với peer trên mọi metric mỗi ngày. Coaching dashboard là development tool, không phải scoreboard.
Thiết kế coaching workflow xung quanh conversation, không phải dashboard. Việc của manager là chọn một metric mỗi rep mỗi tuần, cho thấy dữ liệu, và thảo luận điều gì thúc đẩy nó. Không phải chia sẻ toàn bộ dashboard và để rep tự rút ra kết luận.
Phục hồi: Nếu flight risk indicator đang tăng, audit cách manager thực sự đang dùng coaching data. Vấn đề hầu như không bao giờ là công nghệ. Đó là manager dùng AI metric như performance weapon thay vì coaching tool. Train manager về cách phân phối feedback với AI data quan trọng hơn bất kỳ thay đổi cấu hình dashboard nào.
Failure Mode 5: Forecasting Model Overfit với Các Quý Gần Đây
Triệu chứng: Forecast accuracy mạnh trong 2-3 quý sau khi train model, rồi bắt đầu suy giảm. Accuracy giảm mạnh khi điều kiện thị trường thay đổi (đối thủ mới, thay đổi pricing, macro headwind).
Root cause: AI forecasting model học từ historical deal pattern. Rất giỏi dự đoán outcome trông giống past outcome. Khi môi trường thay đổi đáng kể (buying committee dynamic khác, competitive pressure mới, macro slowdown giảm discretionary spend), training data của model không còn mô tả môi trường hiện tại. Model không biết có regime change. Nó tiếp tục dự đoán như thể quá khứ vẫn là hiện tại.
Ví dụ cụ thể: một công ty mid-market SaaS train Clari forecasting model vào Q3 2024 trên 18 tháng deal data từ thị trường growth-mode. Nghiên cứu McKinsey về State of AI báo cáo ít hơn 20% tổ chức hệ thống theo dõi AI model để phát hiện performance drift sau deployment, đó là cách regression từ regime change không được phát hiện cho đến khi quarter-end miss buộc vấn đề ra ánh sáng. Model học rằng deal với multi-threaded engagement (3+ contact active trong 30 ngày) có close rate 72% ở proposal stage. Vào Q2 2025, khi điều kiện kinh tế thắt chặt, buying committee bắt đầu chậm lại dù contact vẫn engaged. Multi-threaded deal ở proposal stage đóng với tỷ lệ 51%. Model tiếp tục dự đoán 72%. Forecast cao hơn thực tế 28% trong hai quý trước khi ai đó phát hiện drift.
Phòng ngừa: Đặt model accuracy monitoring cadence trước khi deploy. So sánh hàng tháng predicted close rate với actual cho deal được forecast tháng trước. Nếu khoảng cách predicted-vs-actual tăng hơn 10 percentage point trong các tháng liên tiếp, flag để xem xét retraining. Đừng đợi đến quarter-end miss. Khi AI pattern trở thành tech debt nói về vấn đề model drift ở cấp độ pattern.
Thêm "regime change protocol" vào governance documentation. Nếu một sự kiện thị trường lớn xảy ra (đối thủ mới, thay đổi pricing, macro shift), trigger accuracy review ngoài chu kỳ. Human forecasting judgment phải được đặt trọng số rõ ràng so với model output sau regime change, không phải coi như override noise.
Phục hồi: Retrain với dữ liệu 6-9 tháng gần nhất được đặt trọng số nặng hơn dữ liệu cũ. Thảo luận rõ ràng điều gì đã thay đổi về thị trường với CS/Sales team, và xác định historical pattern nào không còn đại diện.
Trích Dẫn Đáng Nhớ: 32% production scoring pipeline gặp distributional shift trong sáu tháng đầu deployment. Model không có active accuracy monitoring cho thấy degradation 14-19% trong 18 tháng, so với trong vòng 2,4% của performance ban đầu với đội chạy monthly accuracy review. (IBM / Superwise AI, 2025)
Failure Mode 6: Routing Model Khóa Chặt Old ICP Bias
Triệu chứng: AI lead scoring và routing nhất quán ưu tiên một phân khúc hẹp. Các phân khúc khác (vertical mới đang mở rộng, công ty nhỏ hơn có thể là PLG fit tốt, account quốc tế) hiếm khi được làm việc và hiếm khi đóng. Bạn cuối cùng nhận ra: AI đã hệ thống lọc bỏ họ.
Root cause: Scoring model train trên historical win data học lead nào trông giống past win. Nếu past win tập trung trong một phân khúc (ví dụ US-based SaaS company 100-500 nhân viên, VP trở lên), model học profile đó là "điểm cao" cho ICP. Lead từ ICP segment mới đang tích cực nhắm không khớp historical pattern và bị chấm thấp. Chúng được routing đến nurture. Không đóng, không phải vì là lead tệ, mà vì không bao giờ được làm việc. Model hiểu đây là xác nhận phân khúc mới có chất lượng thấp.
Đây là feedback loop compound theo thời gian. Scoring model giảm ưu tiên new-segment lead. Rep không làm việc với chúng. Chúng không đóng. Model thấy close rate thấp từ phân khúc đó. Điểm thấp hơn. Phân khúc mới bị loại khỏi pipeline bởi model chưa bao giờ được cập nhật để phản ánh chiến lược hiện tại.
Một công ty dành 6 tháng cố thâm nhập mid-market manufacturing (vertical mới) với GTM motion gồm tuyển vertical rep chuyên dụng. Rep phàn nàn lead cô nhận được chất lượng thấp. Audit tiết lộ lead của cô nhất quán được chấm trong khoảng 30-45 vì scoring model chưa bao giờ thấy manufacturing company đóng. Cô đang bị model disadvantaged có hệ thống. Scoring và Routing pattern giải thích cách training data scope limit xác định phân khúc nào model có thể đánh giá đáng tin cậy.
Phòng ngừa: Khi thêm new ICP segment, explicitly override scoring cho phân khúc đó cho đến khi có 50-100 deal trong phân khúc để train. Tạo segment bypass rule: "Lead khớp [tiêu chí ICP mới] nhận manual review routing bất kể điểm số."
Thực hiện quarterly segment diversity audit trên scored lead population. Nếu một phân khúc nhất quán đại diện 80%+ high-scored lead và bạn có mục tiêu mở rộng chiến lược ngoài phân khúc đó, model cần segment-level calibration.
Phục hồi: Retrain model với segment-stratified sampling. Đảm bảo training set có đủ ví dụ từ phân khúc dưới đại diện để model nhận signal công bằng. Cho đến khi retraining hoàn tất, route phân khúc dưới đại diện thủ công.
Failure Mode 7: Audit Overhead Vượt Quá Tiết Kiệm Với Đội Nhỏ
Triệu chứng: RevOps team dành nhiều thời gian quản lý AI governance, review AI decision, và phản hồi rep dispute hơn là AI đang tiết kiệm rep time. Tool là net-negative về operational efficiency.
Root cause: Enterprise-grade governance framework áp dụng cho AI deployment quy mô nhỏ. Đội sales 10 rep chạy lead scoring model không cần model governance committee, quarterly accuracy review, và structured routing dispute process với 48 giờ SLA. Nhưng nếu RevOps lead của họ đọc enterprise AI governance guide và triển khai toàn bộ framework, họ đã tạo administrative overhead mở rộng kém ở quy mô đội mình.
Phiên bản cụ thể phổ biến nhất: meeting intelligence ở 8-12 rep, với full transcript review workflow, coaching dashboard analysis cadence, và AI-generated pipeline brief review process layer lên trên. Mỗi thành phần có thể bảo vệ được riêng lẻ. Cùng nhau, chúng thêm 4-6 giờ mỗi tuần RevOps overhead cho đội chỉ có một Sales Ops person.
Nếu người đó đang tiết kiệm 2 giờ mỗi tuần rep time trên toàn đội, họ đã tạo ra net loss.
Phòng ngừa: Match governance với rủi ro thực tế và quy mô. Startup governance model (2-3 quy tắc, log trong spreadsheet, monthly 30-minute review) là cấp độ phù hợp cho đội dưới 20 rep. Full audit trail infrastructure, model governance committee, và automated compliance dashboard thuộc về quy mô 100+ rep với đội RevOps chuyên dụng.
Trước khi thêm bất kỳ yêu cầu governance nào, hỏi: trường hợp xấu nhất nếu cái này thất bại là gì? Nếu câu trả lời là "rep tranh chấp routing decision một lần mỗi quý," spreadsheet log và clear dispute path xử lý được. Nếu câu trả lời là "vi phạm GDPR và bị phạt," xây infrastructure thích hợp. NIST AI Risk Management Framework cung cấp tiered governance structure map đến deployment scale, đó là template đúng để calibrate governance effort với actual risk level.
Phục hồi: Audit governance overhead trung thực. Nếu bất kỳ governance process đơn lẻ nào mất hơn 30 phút mỗi tuần cho đội dưới 50 rep, nó có thể over-engineered. Đơn giản hóa. Mục tiêu không phải là governance vì lợi ích riêng của nó. Đó là governance bắt được vấn đề thực sự mà không tạo ra gánh nặng nhiều hơn AI tiết kiệm.
Trích Dẫn Đáng Nhớ: Governance framework thiết kế cho enterprise team 100 rep tạo ra 4-6 giờ mỗi tuần RevOps overhead khi áp dụng cho đội 8-12 rep. Ở quy mô đó, governance cost vượt AI time-saving nó được thiết kế để bảo vệ. Match governance với rủi ro thực tế và quy mô đội, không phải sự tinh vi của compliance documentation của vendor.
Tóm tắt rủi ro failure mode

Bảy failure mode không đồng đều về khả năng xảy ra hay chi phí. Bảng này map mỗi mode sang trigger pattern phổ biến nhất, detection lag, và recovery time điển hình để bạn ưu tiên pre-launch investment.
| Failure Mode | Trigger Chính | Detection Lag Điển Hình | Thời Gian Phục Hồi | Phòng Ngừa Hiệu Quả Nhất |
|---|---|---|---|---|
| Rep Rebellion | Rollout không có rep tham gia | 30-60 ngày | 3-4 tháng | Phiên co-design pre-launch |
| Lead Score Gaming | Rep-editable scoring input | 90-180 ngày | 6-8 tuần (retrain) | Khóa scoring field lúc launch |
| Corporate-AI Email | Rep review không đủ sâu | 60-90 ngày | 2-3 tuần (coaching) | Senior-Rep Voice Test trước khi gửi |
| Coaching Anxiety / Flight Risk | Ranking hiển thị cho tất cả rep | 90-270 ngày | Tùy; một số rep không quay lại | Tách coaching khỏi ranking data |
| Model Drift (Forecasting) | Thay đổi market regime | 60-90 ngày | 4-6 tuần (retrain) | Monthly predicted-vs-actual review |
| ICP Bias / Segment Lockout | Vertical mới không có override rule | 90-180 ngày | 8-12 tuần (retrain + audit) | Segment bypass rule lúc launch |
| Governance Overhead Inversion | Enterprise framework ở SMB scale | 30-90 ngày | 1-2 tuần (đơn giản hóa) | Scale governance với quy mô đội |
Nguồn: RAND Corporation, Sales Management Association, IBM, internal RevOps team data (2025)
Pre-deployment checklist
Trước khi go-live với bất kỳ AI sales ops pattern nào, kiểm tra những điều này:
Dữ liệu:
- 12+ tháng clean deal history với nhãn won/lost nhất quán
- 70%+ completeness trên core contact field (company, title, industry)
- Rep-editable field đã bị khóa cho scoring model input
- Stage progression anomaly đã được audit và giải quyết
Governance:
- Recording consent language đã được legal review
- GDPR/privacy review đã hoàn thành cho scoring use case
- Routing dispute process đã được ghi lại và phổ biến
- Audit log schema đã được xác định và cấu hình
- Model version tracking đã có trước khi deploy model
Change management:
- Nhóm mẫu rep đã tham gia vào configuration decision
- Cam kết cụ thể đã được đưa ra về dữ liệu gì manager sẽ và không sử dụng
- Launch được đóng khung như tiết kiệm thời gian cho rep, không phải monitoring cho manager
- Kế hoạch adoption 30 ngày (ai chịu trách nhiệm về rep adoption, cách đo lường)
- Manager đã được train về cách dùng AI coaching data như công cụ phát triển
Giám sát:
- Baseline metric đã được thu thập trước launch (reply rate, routing speed, CRM completion rate)
- 30-day và 90-day adoption review đã được lên lịch
- Model accuracy monitoring cadence đã được xác định (monthly comparison)
- Alert threshold đã được cấu hình cho anomaly pattern (score inflation, routing dispute volume)
90-day health check framework

Ở ngày 90 sau launch, review các metric này cho mỗi deployed pattern:
Scoring và Routing:
- Routing accuracy: bao nhiêu % routed lead đang bị tranh chấp hoặc reassign thủ công? (Mục tiêu: dưới 10%)
- Score inflation: average lead score có di chuyển hơn 5 điểm từ baseline không? (Flag nếu có)
- Close rate correlation: high-scored lead có đóng tỷ lệ cao hơn low-scored lead không? (Nếu không, model có thể bị gaming hoặc drift)
Meeting Intelligence:
- Recording participation rate: bao nhiêu % target call đang được ghi âm? (Mục tiêu: trên 85%)
- CRM completion rate improvement: AI auto-write có cải thiện % call với complete CRM note không?
- Rep satisfaction pulse: one-question survey với rep: "Meeting intelligence có giúp công việc bạn dễ hơn hay khó hơn không?" (Net score phải positive ở ngày 90)
Generative Research:
- Research brief adoption: bao nhiêu % new account touch có AI-generated brief? (Mục tiêu: trên 60%)
- Pre-call research time: đo ở ngày 90 so với baseline (Mục tiêu: giảm 40%+)
- Brief quality self-assessment: rep rating chất lượng brief (thang 1-5; mục tiêu trên 3,5)
Workflow Copilot:
- NBA acceptance rate: bao nhiêu % suggested next action được thực hiện? (Mục tiêu: trên 30%)
- Admin time reduction: rep time đo được trên CRM data entry so với pre-AI baseline
- Pipeline review meeting length: trước và sau khi roll out AI brief (Mục tiêu: giảm 20%+)
Phân Tích Rework: Trên bảy failure mode, năm cái có root chung: deployment được scope như technology project, không phải change management project. Mode 1, 3, 4, 6, và 7 đều liên quan đến hành vi con người và team design choice được đưa ra sau khi chọn vendor, không phải trước. Mode 2 (gaming) và Mode 5 (drift) là hai failure mode genuinely technical, và cả hai đều có prevention protocol đã biết. Đội tránh được thất bại này thường làm một điều khác biệt: họ xác định success metric trước khi deploy, không phải sau first 30-day review. Pre-launch governance template của Rework bao gồm baseline metric capture là bước bắt buộc trong Phase 0, đó là lý do đội sử dụng nó phát hiện Mode 2 và Mode 5 failure trung bình 6-8 tuần sớm hơn đội bắt đầu monitoring sau launch.
Kết luận thực tế

Không có failure mode nào trong số này là duy nhất với AI. Rep không tin tool thì không dùng. Hệ thống tạo output chất lượng thấp bị bỏ qua. Governance process tạo ra nhiều việc hơn tiết kiệm thì bị từ bỏ. Đây là vấn đề triển khai cổ xưa như enterprise software.
Điều AI thêm vào là quy mô và tốc độ. AI model đang drift hoặc biased đưa ra quyết định tệ trên mọi lead trong pipeline, không chỉ những cái người sẽ phân loại sai. AI coaching dashboard tạo rep anxiety tạo ra nó cho mọi rep trong đội đồng thời. Failure mode là như nhau. Blast radius lớn hơn.
Đó là lý do pre-deployment checklist và 90-day health check không phải bước tùy chọn. Chúng là thói quen vận hành bắt được vấn đề trước khi compound.
Tin tốt: mọi failure mode ở đây đều có thể ngăn chặn, và mọi recovery path đều đã biết. Công ty làm đúng AI sales ops không thông minh hơn những công ty đang gặp khó khăn. Họ kiên nhẫn hơn với Phase 0, trung thực hơn với rep về những gì tool làm, và kỷ luật hơn về monitoring sau launch.
Bắt đầu với implementation roadmap. Xây governance trước khi cần, không phải sau khi cần và có gì đó đã xảy ra sai. Và đọc lại bài này trước 90-day review. Failure mode bạn không lo lúc launch là những cái sẽ tìm thấy bạn.
Với góc nhìn framework-level về lý do AI deployment thất bại trước khi đến sales ops layer, Tại Sao Hầu Hết AI Framework Thất Bại Trong Việc Giúp Operator nói về cùng vấn đề cấu trúc ở cấp độ ACE Foundation.
Đọc Tiếp Theo
- Anti Patterns: Các Kết Hợp AI Thất Bại: pattern-level failure mode trên toàn bộ 10-pattern landscape
- AI Sales Ops Governance và Audit Trail: governance framework ngăn ngừa hầu hết failure mode này
- AI Sales Ops Implementation Roadmap: sequenced rollout giảm deployment risk
- Những Pitfall Phổ Biến Trong AI Lead Scoring: điều trị sâu hơn Failure Mode 2 và 6 áp dụng cho Scoring pattern

Co-Founder, Rework.com
On this page
- 7 AI Sales Ops Failure Mode
- Failure Mode 1: Rep Rebellion
- Failure Mode 2: Lead Score Bị Gaming
- Failure Mode 3: Auto-Drafted Email Nghe Như Corporate-AI
- Failure Mode 4: Coaching Dashboard Tạo Anxiety và Rủi Ro Nhân Viên Nghỉ
- Failure Mode 5: Forecasting Model Overfit với Các Quý Gần Đây
- Failure Mode 6: Routing Model Khóa Chặt Old ICP Bias
- Failure Mode 7: Audit Overhead Vượt Quá Tiết Kiệm Với Đội Nhỏ
- Tóm tắt rủi ro failure mode
- Pre-deployment checklist
- 90-day health check framework
- Kết luận thực tế
- Đọc Tiếp Theo