Mode Kegagalan: Ketika AI Sales Ops Berbalik Merugikan
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Deployment AI sales ops yang gagal biasanya bukan kegagalan teknis. Modelnya bekerja dengan baik. Panggilan API dikembalikan tepat waktu. Integrasi CRM bertahan. Masalahnya bersifat organisasional: tim tidak mempercayai sistem, atau memanipulasinya, atau menggunakannya dengan cara yang salah, atau hanya mengabaikannya setelah tiga minggu pertama.
Ini adalah artikel penutup koleksi. Ini juga yang paling penting jika Anda akan mengambil keputusan pembelian atau keputusan build. Karena jika Anda mengetahui apa yang merusak sistem ini sebelum Anda mendeploy-nya, Anda memiliki peluang yang wajar untuk tidak merusak sistem Anda. Untuk mode kegagalan tingkat pola yang lebih luas di semua 10 pola AI, lihat Anti Pattern: Kombinasi AI yang Gagal dan Risiko Halusinasi berdasarkan Pola AI.
Tujuh mode kegagalan. Masing-masing telah terjadi di perusahaan nyata. Masing-masing dapat dicegah.
Key Facts: Risiko Deployment AI Sales Ops 2026
- 80,3% proyek AI gagal memberikan nilai bisnis yang dimaksudkan, dengan 33,8% ditinggalkan sebelum produksi (RAND Corporation, 2025)
- 76% deployment agen AI mengalami kegagalan kritis dalam 90 hari pertama di 847 implementasi yang dilacak
- 70% tim penjualan melaporkan resistensi aktif terhadap adopsi AI, dan hanya 20% tenaga penjualan yang menggunakan alat AI secara sering atau harian
7 Mode Kegagalan AI Sales Ops
Tujuh mode kegagalan di bawah ini adalah framework diagnostik yang dinamai untuk deployment AI sales ops. Mereka mencakup seluruh permukaan kegagalan: resistensi manusia (Mode 1 dan 4), manipulasi data (Mode 2 dan 6), keruntuhan kualitas output (Mode 3), pembusukan model (Mode 5), dan inversi overhead governance (Mode 7). Setiap mode memiliki jalur pencegahan yang diketahui dan jalur pemulihan yang diketahui.
Mode Kegagalan 1: Pemberontakan Rep
Gejala: Tingkat adopsi di bawah 40% pada 90 hari. Rep menggunakan alat ketika manajer mengawasi, tidak menggunakannya ketika tidak.
Akar penyebab: Rollout tidak melibatkan rep dalam konfigurasi, dan alat tersebut dibingkai sebagai pemantauan daripada bantuan. Meeting intelligence adalah pemicu yang paling umum. Rep yang mengetahui bahwa setiap panggilan direkam dan bahwa manajer mereka mendapatkan Dashboard kinerja yang dibuat AI tidak mendaftar untuk itu. Dan jika tidak ada yang menanyakannya sebelum peluncuran, kebenciannya langsung terasa.
Satu perusahaan meluncurkan Gong ke tim 35 rep pada 2024 tanpa percakapan pra-peluncuran tentang data apa yang akan dan tidak akan ditinjau oleh manajer. Dalam enam minggu, 12 rep menjadwalkan panggilan mereka di ponsel pribadi di luar sistem. Delapan mengajukan keluhan ke HR tentang pengawasan. Rollout dihentikan. Empat bulan biaya langganan terbuang sia-sia, ditambah tenaga kerja implementasi.
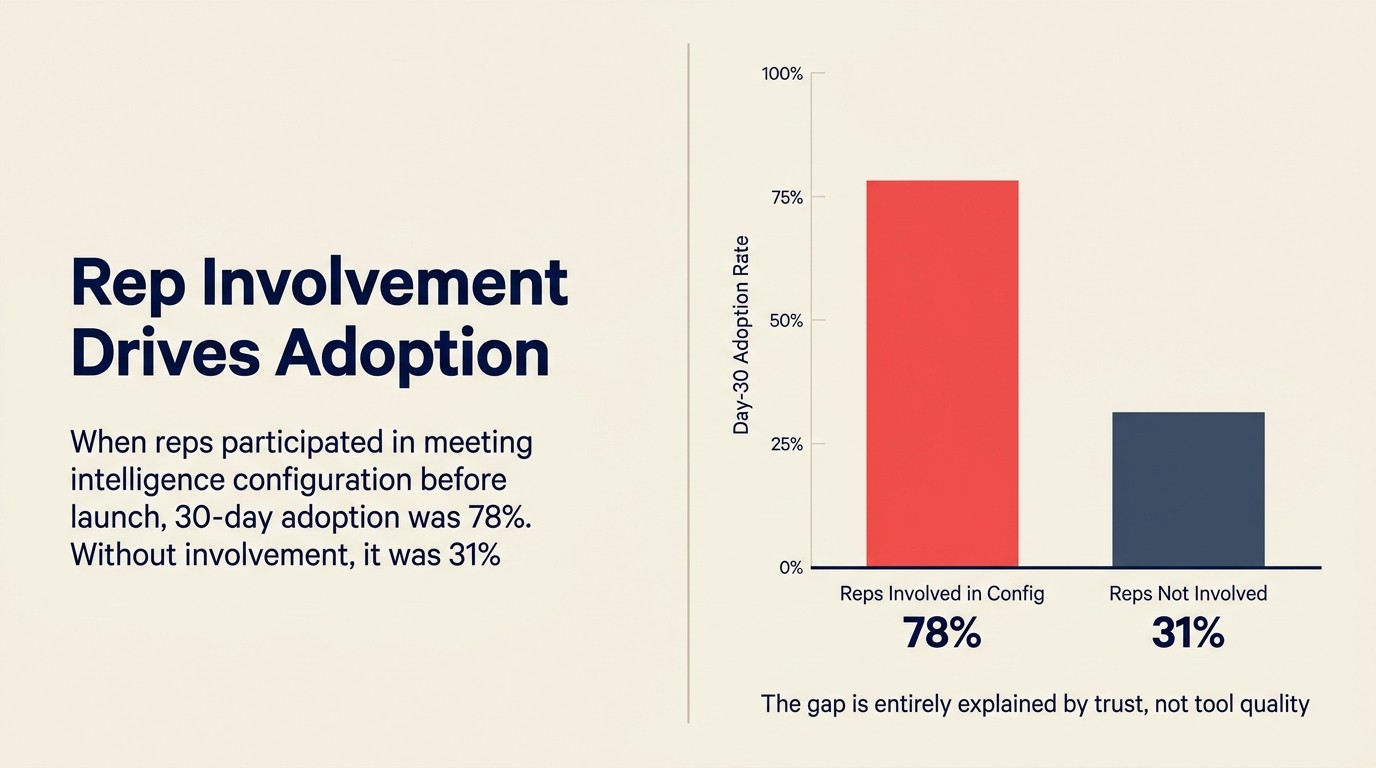
Angka: Data penggunaan internal dari tim RevOps mid-market SaaS, dibagikan di panel SaaStr 2025: ketika rep dilibatkan dalam keputusan konfigurasi meeting intelligence (field mana yang auto-populate, klip panggilan mana yang bisa diakses manajer, bagaimana umpan balik coaching akan disampaikan), adopsi 30 hari adalah 78%. Ketika rep tidak dilibatkan, adopsi 30 hari adalah 31%. Stanford HAI AI Index 2025 secara konsisten menemukan bahwa kesiapan organisasi dan kepercayaan pemangku kepentingan, bukan kinerja model, adalah faktor yang memisahkan deployment AI enterprise yang berhasil dari yang gagal.
Pencegahan: Jalankan sesi pra-peluncuran 2 minggu dengan kelompok sampel rep. Biarkan mereka melihat alat, tanyakan apa yang mereka inginkan, dan munculkan apa yang mereka khawatirkan. Buat komitmen spesifik: "Rekaman akan digunakan untuk coaching, bukan tinjauan kinerja," dan kemudian tepati. Rep yang cemas tentang pengawasan menjadi pendukung ketika mereka merasa sistem dirancang untuk keuntungan mereka, bukan melawan mereka.
Pemulihan: Jika adopsi sudah runtuh, jangan paksakan. Hentikan sementara, akui masalahnya, dan mulai proses co-design rep yang seharusnya terjadi sebelum peluncuran. Re-launch yang dibingkai di sekitar "kami mendengar kekhawatiran Anda dan kami telah melakukan perubahan ini" memulihkan kepercayaan lebih cepat dari pendekatan lain manapun.
Quotable Nugget: Ketika rep dilibatkan dalam keputusan konfigurasi meeting intelligence sebelum peluncuran, adopsi 30 hari mencapai 78%. Ketika mereka tidak dilibatkan, itu turun menjadi 31%. Kesenjangan itu sepenuhnya dijelaskan oleh kepercayaan, bukan oleh kualitas alat. (Data penggunaan internal, tim RevOps mid-market SaaS, panel SaaStr 2025)
Mode Kegagalan 2: Skor Lead yang Dimanipulasi
Gejala: Skor lead cenderung naik secara keseluruhan selama 3-6 bulan bahkan saat tingkat penutupan stagnan atau menurun.
Akar penyebab: Rep mempelajari input mana yang mendorong skor tinggi dan mulai mengoptimalkan input tersebut secara manual. Jika model scoring memberikan bobot besar pada "ukuran perusahaan" dan rep dapat mengedit ukuran perusahaan pada catatan kontak, perkirakan inflasi. Jika "kunjungan website" berkorelasi dengan skor dan rep dapat memicu kunjungan website dengan mengirim email berisi tautan, perkirakan pengiriman tautan menjadi olahraga.
Ini adalah masalah Hukum Goodhart yang diterapkan pada lead scoring: begitu sebuah ukuran menjadi target, ia berhenti menjadi ukuran yang baik. Rep tidak melakukan ini karena mereka jahat. Mereka melakukannya karena mereka menginginkan lebih banyak lead yang bagus, dan mereka menemukan tuas tersebut. Artikel jebakan umum AI lead scoring mencakup ini dan pola kegagalan Scoring and Routing lainnya secara mendalam.
Satu perusahaan B2B SaaS yang menjalankan model scoring buatan sendiri melihat rata-rata skor lead melayang dari rata-rata 62 ke rata-rata 79 selama 8 bulan. Tingkat penutupan turun dari 22% ke 14% pada lead "skor tinggi" dalam periode yang sama. Ketika mereka mengaudit data, 40% dari lead skor tinggi memiliki field ukuran perusahaan yang telah diedit secara manual dalam 30 hari sebelum scoring.
Pencegahan: Jangan biarkan rep mengedit field yang memiliki bobot tertinggi dalam model scoring. Gunakan field yang diisi sistem (dari penyedia data Anda, dari log penggunaan produk, dari analitik website) untuk input scoring, bukan field CRM yang dapat diedit rep. Jika Anda harus menggunakan field yang dapat diedit rep, sertakan log audit "terakhir diedit oleh" sehingga anomali scoring terlihat.
Pemulihan: Audit bobot fitur scoring Anda terhadap data konversi aktual Anda. Jika lead skor tinggi tidak berkonversi dengan tingkat lebih tinggi dari lead skor menengah, skor telah dimanipulasi atau model telah melayang. Latih ulang dengan data sumber yang tidak bisa langsung diedit rep, dan perketat izin pengeditan field ke depannya.
Quotable Nugget: Hukum Goodhart adalah risiko yang paling diremehkan dalam deployment AI scoring. Saat skor lead menjadi input kuota, rep mengoptimalkan untuk skor, bukan untuk kualitas pipeline. Solusinya adalah menggunakan input yang diisi sistem yang tidak bisa disentuh rep, bukan lebih banyak pelatihan ulang model.
Mode Kegagalan 3: Email yang Dibuat Otomatis Terdengar Corporate-AI
Gejala: Tingkat balasan email turun setelah meluncurkan pembuatan email berbantuan AI. Bentuk paling rendah dari kegagalan ini: seorang rep mengirim email yang dibuat AI ke prospek yang sudah lama mengenal mereka, yang membalas "Ini tidak terdengar seperti Anda. Apakah semuanya baik-baik saja?"
Akar penyebab: Alat pembuatan email off-the-shelf yang dilatih pada korpus email penjualan generik menghasilkan email penjualan generik. Secara tata bahasa benar. Mereka menggunakan struktur yang masuk akal. Dan mereka terdengar persis seperti setiap email dingin yang dibuat AI lainnya yang menyentuh kotak masuk yang sama.
Pola spesifik yang membunuh tingkat balasan:
- Pembuka yang mereferensikan "lanskap saat ini di [industri]" atau "di lingkungan yang serba cepat saat ini"
- Kalimat yang dimulai dengan "I wanted to reach out" (setiap AI menulis ini)
- Paragraf proposisi nilai yang mencantumkan fitur sebagai poin-poin ("Dengan platform kami, Anda dapat: [daftar hal-hal]")
- CTA yang mengatakan "Would you be open to a quick 15-minute call?" (penutup AI yang universal)
Outreach yang dipersonalisasi AI dalam skala besar mencakup pendekatan berbasis riset yang menghindari pola-pola ini.
Satu tim penjualan di perusahaan SaaS 200-rep melacak tingkat balasan sebelum dan sesudah rollout email AI. Sebelum: tingkat balasan 8,2% pada first-touch outreach. Setelah 60 hari pembuatan AI dengan tinjauan rep: 6,1%. Setelah 90 hari: 5,4%. Rep sedang sedikit mengedit draft AI tetapi tidak secara mendasar menulis ulang mereka. Suara AI telah menggantikan suara rep.
Pencegahan: Jangan gunakan pembuatan email AI sebagai jalan pintas untuk menulis. Gunakan sebagai titik awal yang benar-benar ditulis ulang rep. Nilainya bukan pada draft; ini pada struktur dan input data personalisasi. Bangun standar kualitas sederhana: email yang dibuat AI yang masih mengandung frasa "I wanted to reach out" atau kalimat apa pun yang dimulai dengan "I hope this finds you well" tidak boleh dikirim.
Latih rep tentang seperti apa pola yang dibuat AI dan mengapa prospek mengenali mereka. Rep yang memahami mengapa draft AI terdengar seperti AI jauh lebih mungkin untuk memperbaikinya daripada rep yang hanya berpikir itu terdengar baik.
Pemulihan: Jika tingkat balasan telah turun, ambil sampel email yang dibuat AI yang dikirim. Baca mereka dengan keras. Jika ada yang terdengar seperti siaran pers daripada manusia yang berbicara dengan manusia lain, Anda telah menemukan masalahnya. Jalankan split test: yang dibuat AI vs. yang ditulis rep dari awal, lead yang sama, minggu yang sama. Kesenjangan akan memberi tahu Anda seberapa besar suara AI yang merugikan.
Quotable Nugget: Tim SaaS 200-rep melacak tingkat balasan sebelum dan sesudah rollout email AI: 8,2% sebelum, 5,4% setelah 90 hari. Rep tidak melewati tinjauan. Mereka sedikit mengedit draft AI dan mengirimnya. Suara AI telah menggantikan suara rep tanpa ada yang menyadari.
Mode Kegagalan 4: Dashboard Coaching Menciptakan Kecemasan Rep dan Risiko Turnover
Gejala: Pergantian sukarela meningkat di antara rep tier menengah dalam 6-12 bulan setelah rollout meeting intelligence. Tema wawancara keluar berkumpul di sekitar "merasa terlalu dikendalikan" atau "selalu diawasi."
Akar penyebab: Dashboard coaching AI memunculkan metrik rep individual pada tingkat granularitas yang terasa mengancam daripada mengembangkan. Rasio waktu bicara. Jumlah pertanyaan per panggilan. Jumlah penyebutan kompetitor yang ditangani. Panjang monolog. Metrik ini dimaksudkan untuk membantu rep berkembang. Ketika ditampilkan di Dashboard yang terlihat oleh manajer dengan peringkat, mereka berfungsi sebagai sistem tekanan kinerja.
Rep tier menengah (persentil ke-50 hingga ke-75) paling rentan. Pemain terbaik merasa percaya diri dengan angka mereka. Pemain terbawah sudah tahu mereka berjuang. Rep tier menengah melihat metrik yang menunjukkan mereka tidak di urutan teratas dan menginternalisasinya sebagai "Saya gagal." Ketika data selalu aktif dan selalu terlihat, tekanan tidak mereda di antara percakapan coaching.
Ini nyata. Survei 2025 terhadap 200 profesional penjualan B2B oleh Sales Management Association menemukan bahwa 34% rep di perusahaan yang menggunakan alat coaching AI melaporkan stres kerja yang jauh lebih tinggi dari sebelum rollout. Dari mereka, 41% mengatakan mereka telah mulai wawancara untuk posisi lain dalam 6 bulan setelah rollout.
Pencegahan: Pisahkan metrik coaching dari metrik kinerja di Dashboard yang terlihat oleh rep. Rep seharusnya melihat data coaching dan tren mereka sendiri. Mereka tidak seharusnya melihat peringkat yang membandingkan mereka dengan rekan-rekan pada setiap metrik setiap hari. Dashboard coaching adalah alat pengembangan, bukan papan skor.
Desain workflow coaching di sekitar percakapan, bukan Dashboard. Tugas manajer adalah memilih satu metrik per rep per minggu, menampilkan data, dan mendiskusikan apa yang mendorongnya. Bukan membagikan Dashboard penuh dan membiarkan rep menarik kesimpulan sendiri.
Pemulihan: Jika indikator risiko turnover meningkat, audit bagaimana manajer sebenarnya menggunakan data coaching. Masalahnya hampir tidak pernah pada teknologi. Itu manajer yang menggunakan metrik AI sebagai senjata kinerja daripada alat coaching. Melatih manajer tentang pengiriman umpan balik dengan data AI lebih penting dari perubahan konfigurasi Dashboard mana pun.
Mode Kegagalan 5: Model Forecasting yang Over-Fit pada Kuartal Terkini
Gejala: Akurasi forecast kuat selama 2-3 kuartal setelah pelatihan model, kemudian mulai menurun. Akurasi turun tajam ketika kondisi pasar bergeser (kompetitor baru masuk, perubahan harga, angin kepala makro).
Akar penyebab: Model forecasting AI belajar dari pola deal historis. Mereka sangat baik dalam memprediksi hasil yang terlihat seperti hasil masa lalu. Ketika lingkungan berubah secara signifikan (dinamika komite pembelian yang berbeda, tekanan kompetitif baru, perlambatan makro yang mengurangi pengeluaran diskresioner), data pelatihan model tidak lagi menggambarkan lingkungan saat ini. Model tidak tahu ada perubahan rezim; ia terus membuat prediksi seolah masa lalu masih masa kini.
Contoh konkret: sebuah perusahaan SaaS mid-market melatih model forecasting Clari mereka di Q3 2024 pada 18 bulan data deal dari pasar mode pertumbuhan. Penelitian State of AI McKinsey melaporkan bahwa kurang dari 20% organisasi secara sistematis memantau model AI mereka untuk pergeseran kinerja pasca-deployment, itulah cara regresi dari perubahan rezim tidak terdeteksi sampai miss akhir kuartal memaksanya. Model belajar bahwa deal dengan keterlibatan multi-threaded (3+ kontak aktif dalam 30 hari terakhir) memiliki tingkat penutupan 72% di tahap proposal. Pada Q2 2025, seiring kondisi ekonomi memperketat, komite pembelian mulai melambat bahkan dengan kontak yang terlibat. Deal multi-threaded di tahap proposal ditutup pada 51%. Model terus memprediksi 72%. Forecast 28% di atas aktual selama dua kuartal sebelum ada yang menangkap pergeseran.
Pencegahan: Tetapkan kadensa pemantauan akurasi model sebelum deployment. Perbandingan bulanan tingkat penutupan yang diprediksi vs. aktual untuk deal bulan sebelumnya yang diforecast. Jika kesenjangan prediksi-vs-aktual tumbuh lebih dari 10 poin persentase dalam bulan-bulan berturut-turut, tandai untuk tinjauan pelatihan ulang. Jangan tunggu miss akhir kuartal. Ketika pola AI menjadi tech debt mencakup masalah model drift di tingkat pola, termasuk cara mengenali kapan sebuah model telah melayang melampaui rekalibrasi.
Sertakan "protokol perubahan rezim" dalam dokumentasi governance Anda. Jika peristiwa pasar besar terjadi (kompetitor baru, perubahan harga, pergeseran makro), picu tinjauan akurasi di luar siklus. Penilaian forecasting manusia harus secara eksplisit diberi bobot terhadap output model setelah perubahan rezim, tidak diperlakukan sebagai noise yang menggantikan.
Pemulihan: Latih ulang dengan data 6-9 bulan terkini yang diberi bobot lebih besar dari data yang lebih lama. Diskusikan secara eksplisit apa yang berubah tentang pasar dengan tim CS/Sales Anda, dan identifikasi pola historis mana yang tidak lagi representatif.
Quotable Nugget: 32% pipeline scoring produksi mengalami pergeseran distribusional dalam enam bulan pertama deployment. Model tanpa pemantauan akurasi aktif menunjukkan degradasi 14-19% selama 18 bulan, dibandingkan dalam 2,4% dari kinerja awal untuk tim yang menjalankan tinjauan akurasi bulanan. (IBM / Superwise AI, 2025)
Mode Kegagalan 6: Model Routing yang Mengunci Bias ICP Lama
Gejala: AI lead scoring dan routing Anda secara konsisten memprioritaskan segmen lead yang sempit. Segmen lain (vertikal baru yang Anda ekspansi, perusahaan lebih kecil yang mungkin cocok untuk PLG, akun internasional) jarang dikerjakan dan jarang ditutup. Anda akhirnya menyadari: AI telah secara sistematis menyaringnya.
Akar penyebab: Model scoring yang dilatih pada data kemenangan historis belajar lead mana yang terlihat seperti kemenangan masa lalu. Jika kemenangan masa lalu Anda terkonsentrasi di satu segmen (misalnya, perusahaan SaaS berbasis AS antara 100-500 karyawan, VP ke atas), model belajar profil itu sebagai "skor tinggi" untuk ICP Anda. Lead dari segmen ICP baru yang secara aktif Anda targetkan tidak cocok dengan pola historis dan mendapat skor rendah. Mereka di-route ke nurture. Mereka tidak ditutup, bukan karena mereka lead yang buruk, tetapi karena mereka tidak pernah dikerjakan. Model menginterpretasikan ini sebagai konfirmasi bahwa segmen baru memiliki kualitas rendah.
Ini adalah feedback loop yang bertambah besar. Model scoring mendeprioritaskan lead segmen baru. Rep tidak mengerjakan mereka. Mereka tidak ditutup. Model melihat tingkat penutupan rendah dari segmen itu. Skor menjadi lebih rendah. Segmen baru secara efektif dikunci dari pipeline oleh model yang tidak pernah diperbarui untuk mencerminkan strategi saat ini.
Satu perusahaan menghabiskan 6 bulan mencoba masuk ke manufaktur mid-market (vertikal baru) dengan gerakan GTM yang mencakup mempekerjakan rep vertikal khusus. Rep tersebut mengeluh bahwa lead yang ia terima memiliki kualitas rendah. Audit mengungkapkan bahwa lead-nya secara konsisten mendapat skor 30-45 karena model scoring tidak pernah melihat perusahaan manufaktur ditutup. Ia secara sistematis dirugikan oleh model. Pola Scoring and Routing menjelaskan bagaimana ruang lingkup data pelatihan menentukan segmen mana yang dapat dievaluasi model secara andal.
Pencegahan: Ketika Anda menambahkan segmen ICP baru, secara eksplisit override scoring untuk segmen tersebut sampai Anda memiliki 50-100 deal dalam segmen untuk dilatih. Buat aturan bypass segmen: "Lead yang cocok dengan [kriteria ICP baru] mendapatkan routing tinjauan manual terlepas dari skor."
Lakukan audit keragaman segmen triwulanan pada populasi lead yang diberi skor Anda. Jika satu segmen secara konsisten mewakili 80%+ lead skor tinggi dan Anda memiliki tujuan ekspansi strategis di luar segmen tersebut, model memerlukan kalibrasi tingkat segmen.
Pemulihan: Latih ulang model dengan sampling bertingkat segmen. Pastikan set pelatihan mencakup cukup contoh dari segmen yang kurang terwakili untuk memberi model sinyal yang adil. Sampai pelatihan ulang selesai, route segmen yang kurang terwakili secara manual.
Mode Kegagalan 7: Overhead Audit yang Melebihi Penghematan untuk Tim Kecil
Gejala: Tim RevOps menghabiskan lebih banyak waktu mengelola governance AI, meninjau keputusan AI, dan merespons sengketa rep daripada yang dihemat AI dalam waktu rep. Alat tersebut menghasilkan efisiensi operasional yang negatif secara bersih.
Akar penyebab: Framework governance kelas enterprise yang diterapkan pada deployment AI tim kecil. Tim penjualan 10-rep yang menjalankan model lead scoring tidak memerlukan komite governance model, tinjauan akurasi triwulanan, dan proses sengketa routing terstruktur dengan SLA 48 jam. Tetapi jika pemimpin RevOps mereka membaca panduan governance AI enterprise dan mengimplementasikan framework penuh, mereka telah menciptakan overhead administratif yang menskalakan dengan buruk pada ukuran tim mereka.
Versi spesifik yang paling umum: meeting intelligence pada 8-12 rep, dengan workflow tinjauan transkrip penuh, kadensa analisis Dashboard coaching, dan proses tinjauan brief pipeline yang dibuat AI berlapis di atasnya. Setiap komponen dapat dibenarkan secara individual. Bersama-sama, mereka dapat menambahkan 4-6 jam per minggu overhead RevOps untuk tim yang memiliki satu orang Sales Ops.
Jika orang itu menghemat 2 jam per minggu waktu rep di seluruh tim, mereka telah menciptakan kerugian bersih.
Pencegahan: Sesuaikan governance dengan risiko dan skala yang sebenarnya. Model governance startup (2-3 aturan, catat dalam spreadsheet, tinjauan bulanan 30 menit) adalah tingkat yang tepat untuk tim sub-20-rep. Infrastruktur audit trail penuh, komite governance model, dan Dashboard kepatuhan otomatis ada di skala 100+ rep dengan tim RevOps khusus.
Sebelum menambahkan persyaratan governance apa pun, tanyakan: apa yang terburuk jika ini gagal? Jika jawabannya adalah "rep mempermasalahkan keputusan routing sekali per kuartal," log spreadsheet dan jalur sengketa yang jelas menanganinya. Jika jawabannya adalah "kami melanggar GDPR dan didenda," bangun infrastruktur yang tepat. NIST AI Risk Management Framework menyediakan struktur governance bertingkat yang memetakan langsung ke skala deployment, yang merupakan template yang tepat untuk mengkalibrasi upaya governance terhadap tingkat risiko yang sebenarnya.
Pemulihan: Audit overhead governance Anda dengan jujur. Jika satu proses governance menghabiskan lebih dari 30 menit per minggu untuk tim sub-50-rep, itu kemungkinan terlalu direkayasa untuk skala Anda. Sederhanakan. Tujuannya bukan governance demi governance itu sendiri; itu governance yang menangkap masalah nyata tanpa menciptakan lebih banyak beban daripada yang dihemat AI.
Quotable Nugget: Framework governance yang dirancang untuk tim enterprise 100-rep menghasilkan 4-6 jam per minggu overhead RevOps ketika diterapkan pada tim 8-12-rep. Pada skala itu, biaya governance melebihi penghematan waktu AI yang seharusnya dilindungi. Sesuaikan governance dengan risiko dan ukuran tim yang sebenarnya, bukan dengan kecanggihan dokumentasi kepatuhan vendor Anda.
Ringkasan risiko mode kegagalan

Tujuh mode kegagalan tidak sama kemungkinan atau sama biayanya. Tabel ini memetakan setiap mode ke pola pemicu yang paling umum, lag deteksi, dan waktu pemulihan tipikal sehingga Anda dapat memprioritaskan investasi pra-peluncuran.
| Mode Kegagalan | Pemicu Utama | Lag Deteksi Tipikal | Waktu Pemulihan | Pencegahan Paling Efektif |
|---|---|---|---|---|
| Pemberontakan Rep | Rollout tanpa keterlibatan rep | 30-60 hari | 3-4 bulan | Sesi co-design pra-peluncuran |
| Manipulasi Skor Lead | Input scoring yang dapat diedit rep | 90-180 hari | 6-8 minggu (pelatihan ulang) | Kunci field scoring saat peluncuran |
| Email Corporate-AI | Tinjauan rep yang dangkal terhadap draft | 60-90 hari | 2-3 minggu (coaching) | Senior-Rep Voice Test sebelum dikirim |
| Kecemasan Coaching / Risiko Turnover | Peringkat terlihat oleh semua rep | 90-270 hari | Bervariasi; beberapa rep tidak kembali | Pisahkan data coaching dari data peringkat |
| Model Drift (Forecasting) | Perubahan rezim pasar | 60-90 hari | 4-6 minggu (pelatihan ulang) | Tinjauan bulanan prediksi-vs-aktual |
| Bias ICP / Penguncian Segmen | Vertikal baru tanpa aturan override | 90-180 hari | 8-12 minggu (pelatihan ulang + audit) | Aturan bypass segmen saat peluncuran |
| Inversi Overhead Governance | Framework enterprise pada skala SMB | 30-90 hari | 1-2 minggu (sederhanakan) | Sesuaikan governance dengan ukuran tim |
Sumber: RAND Corporation, Sales Management Association, IBM, data tim RevOps internal (2025)
Daftar periksa pra-deployment
Sebelum go-live dengan pola AI sales ops mana pun, periksa hal-hal ini:
Data:
- Riwayat deal 12+ bulan yang bersih dengan label menang/kalah yang konsisten
- Kelengkapan 70%+ pada field kontak inti (perusahaan, jabatan, industri)
- Field yang dapat diedit rep dikunci untuk input model scoring
- Anomali kemajuan tahap diaudit dan diselesaikan
Governance:
- Bahasa persetujuan perekaman ditinjau oleh legal
- Tinjauan GDPR/privasi selesai untuk use case scoring
- Proses sengketa routing terdokumentasi dan disosialisasikan
- Skema log audit ditentukan dan dikonfigurasi
- Pelacakan versi model tersedia sebelum deployment model
Change management:
- Kelompok sampel rep dilibatkan dalam keputusan konfigurasi
- Komitmen spesifik dibuat tentang data apa yang akan dan tidak akan digunakan manajer
- Peluncuran dibingkai sebagai penghematan waktu untuk rep, bukan pemantauan untuk manajer
- Rencana adopsi 30 hari (siapa yang bertanggung jawab untuk adopsi rep, bagaimana diukur)
- Pelatihan manajer tentang penggunaan data coaching AI sebagai alat pengembangan
Pemantauan:
- Metrik baseline ditangkap pra-peluncuran (tingkat balasan, kecepatan routing, tingkat penyelesaian CRM)
- Tinjauan adopsi 30 hari dan 90 hari dijadwalkan dalam kalender
- Kadensa pemantauan akurasi model ditentukan (perbandingan bulanan)
- Ambang batas peringatan dikonfigurasi untuk pola anomali (inflasi skor, volume sengketa routing)
Framework pemeriksaan kesehatan 90 hari

Pada 90 hari pasca-peluncuran, tinjau metrik ini untuk setiap pola yang dideploy:
Scoring and Routing:
- Akurasi routing: berapa % lead yang di-route sedang disengketakan atau ditugaskan ulang secara manual? (Target: di bawah 10%)
- Inflasi skor: apakah rata-rata skor lead bergerak lebih dari 5 poin dari baseline? (Tandai jika ya)
- Korelasi tingkat penutupan: apakah lead skor tinggi ditutup dengan tingkat lebih tinggi dari lead skor rendah? (Jika tidak, model mungkin sedang dimanipulasi atau melayang)
Meeting Intelligence:
- Tingkat partisipasi perekaman: berapa % panggilan target yang direkam? (Target: di atas 85%)
- Peningkatan tingkat penyelesaian CRM: apakah AI auto-write meningkatkan % panggilan dengan catatan CRM yang lengkap?
- Survei kepuasan rep: satu pertanyaan untuk rep: "Apakah meeting intelligence membuat pekerjaan Anda lebih mudah atau lebih sulit?" (Skor bersih harus positif pada 90 hari)
Generative Research:
- Adopsi brief riset: berapa % sentuhan akun baru yang menyertakan brief yang dibuat AI? (Target: di atas 60%)
- Waktu riset sebelum panggilan: diukur pada 90 hari vs. baseline (Target: pengurangan 40%+)
- Penilaian diri kualitas brief: penilaian rep terhadap kualitas brief (skala 1-5; target di atas 3,5)
Workflow Copilot:
- Tingkat penerimaan NBA: berapa % tindakan berikutnya yang disarankan yang ditindaklanjuti? (Target: di atas 30%)
- Pengurangan waktu admin: waktu rep yang diukur pada entri data CRM vs. baseline pra-AI
- Panjang meeting pipeline review: sebelum dan sesudah rollout brief AI (Target: pengurangan 20%+)
Rework Analysis: Di tujuh mode kegagalan, lima memiliki akar yang sama: deployment dicakupkan sebagai proyek teknologi, bukan sebagai proyek change management. Mode 1, 3, 4, 6, dan 7 semuanya melibatkan perilaku manusia dan pilihan desain tim yang dibuat setelah vendor dipilih, bukan sebelumnya. Mode 2 (manipulasi) dan Mode 5 (drift) adalah dua mode kegagalan yang benar-benar teknis, dan keduanya memiliki protokol pencegahan yang diketahui. Tim yang menghindari kegagalan ini biasanya melakukan satu hal berbeda: mereka mendefinisikan metrik keberhasilan sebelum deployment, bukan setelah tinjauan 30 hari pertama. Template governance pra-peluncuran Rework menyertakan penangkapan metrik baseline sebagai langkah wajib di Fase 0, itulah mengapa tim yang menggunakannya mendeteksi kegagalan Mode 2 dan Mode 5 rata-rata 6-8 minggu lebih awal dari tim yang mulai memantau pasca-peluncuran.
Kesimpulan yang jujur

Tidak satu pun dari mode kegagalan ini yang unik untuk AI. Rep yang tidak mempercayai alat tidak menggunakannya. Sistem yang menghasilkan output berkualitas rendah diabaikan. Proses governance yang menciptakan lebih banyak pekerjaan daripada yang mereka hemat ditinggalkan. Ini adalah masalah implementasi setua perangkat lunak enterprise.
Yang ditambahkan AI adalah skala dan kecepatan. Model AI yang melayang atau bias membuat keputusan buruk pada setiap lead dalam pipeline, bukan hanya yang salah dikategorikan manusia. Dashboard coaching AI yang menciptakan kecemasan rep menciptakannya untuk setiap rep di tim secara bersamaan. Mode kegagalannya sama; radius ledakannya lebih besar.
Itulah mengapa daftar periksa pra-deployment dan pemeriksaan kesehatan 90 hari bukan langkah opsional. Mereka adalah kebiasaan operasional yang menangkap masalah sebelum bertambah besar.
Kabar baiknya: setiap mode kegagalan yang didokumentasikan di sini dapat dicegah, dan setiap jalur pemulihan diketahui. Perusahaan yang berhasil dengan AI sales ops tidak lebih cerdas dari yang berjuang. Mereka lebih sabar dengan Fase 0, lebih jujur kepada rep mereka tentang apa yang dilakukan alat tersebut, dan lebih disiplin dalam pemantauan setelah peluncuran.
Mulailah dengan roadmap implementasi. Bangun governance sebelum Anda membutuhkannya, bukan setelah Anda membutuhkannya dan sesuatu telah berjalan salah. Dan baca artikel ini lagi sebelum tinjauan 90 hari Anda. Mode kegagalan yang tidak Anda khawatirkan saat peluncuran adalah yang akan menemukan Anda.
Untuk perspektif tingkat framework tentang mengapa deployment AI gagal bahkan sebelum mencapai lapisan sales ops, Mengapa Sebagian Besar Framework AI Gagal Membantu Operator mencakup masalah struktural yang sama di tingkat ACE Foundation.
Baca selanjutnya
- Anti Pattern: Kombinasi AI yang Gagal: mode kegagalan tingkat pola di seluruh lanskap 10 pola
- AI Sales Ops Governance dan Audit Trails: framework governance yang mencegah sebagian besar mode kegagalan ini
- Roadmap Implementasi AI Sales Ops: rollout terurut yang mengurangi risiko deployment
- Jebakan Umum AI Lead Scoring: perlakuan lebih mendalam tentang Mode Kegagalan 2 dan 6 yang diterapkan pada pola Scoring

Co-Founder, Rework.com
On this page
- 7 Mode Kegagalan AI Sales Ops
- Mode Kegagalan 1: Pemberontakan Rep
- Mode Kegagalan 2: Skor Lead yang Dimanipulasi
- Mode Kegagalan 3: Email yang Dibuat Otomatis Terdengar Corporate-AI
- Mode Kegagalan 4: Dashboard Coaching Menciptakan Kecemasan Rep dan Risiko Turnover
- Mode Kegagalan 5: Model Forecasting yang Over-Fit pada Kuartal Terkini
- Mode Kegagalan 6: Model Routing yang Mengunci Bias ICP Lama
- Mode Kegagalan 7: Overhead Audit yang Melebihi Penghematan untuk Tim Kecil
- Ringkasan risiko mode kegagalan
- Daftar periksa pra-deployment
- Framework pemeriksaan kesehatan 90 hari
- Kesimpulan yang jujur
- Baca selanjutnya