Higiene de Datos CRM con un AI Copilot

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Basura entra, basura sale.
Lo ha escuchado suficientes veces como para que parezca un lugar común. Pero en las sales operations asistidas por AI, es la ecuación que lo rige todo. Su modelo de lead scoring está entrenado con datos del CRM. Sus asignaciones de nivel de cuenta se extraen de los datos firmográficos del CRM. Su pronóstico de pipeline se calcula a partir de los datos de etapa del deal. Su routing de señales de intención se activa en función de los registros de cuenta del CRM.
Cada función AI en su stack de ventas está corriente abajo de la calidad de los datos del CRM. Cuando esos datos son sucios, sus salidas AI están confiadamente equivocadas. Y confiadamente equivocado es peor que admitidamente incierto porque los representantes actúan sobre ello. Gartner estima que la mala calidad de datos le cuesta a las organizaciones un promedio de $15 millones anuales, siendo los problemas de calidad de datos del CRM una de las fuentes de mayor impacto de ese costo para los equipos comerciales.
La higiene del CRM no es un trabajo glamoroso. Los líderes de RevOps lo saben. La mayoría ha lanzado un proyecto de limpieza de datos, lo ha ejecutado durante un trimestre, declarado la victoria y visto cómo la calidad de los datos se degradaba nuevamente en 6 meses. El modelo de limpieza trimestral no funciona porque los datos no se deterioran trimestralmente. Se degradan continuamente, a una tasa impulsada por su volumen de deals, la disciplina de sus representantes y el ritmo de cambio en sus cuentas.
El patrón Workflow Copilot aplicado a la higiene del CRM es un modelo diferente: detección y corrección automatizada continua, con una capa de gobernanza que mantiene a los humanos en la cadena de decisiones para todo lo que supera un umbral de confianza. Este artículo cubre cómo funciona, los cuatro tipos de problemas que maneja y por qué es la inversión en infraestructura que hace que todo lo demás en su stack AI sea más confiable.
Qué significa operativamente la higiene de datos del CRM
Datos Clave: El Costo de los Malos Datos CRM
- La mala calidad de datos CRM le cuesta a la empresa B2B promedio entre $12.9 y $15 millones anuales a través de gasto de marketing desperdiciado, oportunidades de ventas perdidas e ineficiencias operativas. (Gartner / ZoomInfo, 2025)
- Los representantes de ventas desperdician el 27% de su tiempo lidiando con datos deficientes, con un costo estimado de $32,000 por representante anuales en productividad perdida. (Validity, 2025)
- Los datos de contacto B2B se deterioran aproximadamente un 2.1% mensual, lo que significa que el 22-30% de los registros de contacto del CRM se vuelven inexactos en un año sin higiene activa. (Salesgenie, 2025)
"Higiene de datos" es un término general. Para los propósitos de RevOps, cubre cuatro tipos distintos de problemas:
Duplicados. La misma empresa existe como dos registros ("Acme Corp" y "Acme Corporation Inc"). El mismo contacto está en el sistema tres veces de tres eventos de importación diferentes. Los duplicados dividen el historial de actividad, fragmentan el contexto de la relación y producen recuentos de contactos inflados que estropean sus asignaciones de territorio.
Completitud de campos. Los campos requeridos están vacíos. Sin vertical de la industria. Sin conteo de empleados. Sin última ronda de financiación. Sin contacto principal en la cuenta. Estas brechas rompen los modelos de scoring que usan esos campos como inputs y producen celdas en blanco en los informes que deberían ser superficies de decisión.
Registros obsoletos. Sin actividad registrada en 180 días, pero el deal todavía está abierto en su pipeline. La empresa del contacto fue adquirida hace 8 meses pero el registro de la cuenta no se ha actualizado. El champion principal dejó la empresa pero sigue listado como el contacto principal. Los registros obsoletos generan una falsa confianza en el pipeline y producen outreach perdido a oportunidades activas.
Drift de enriquecimiento. Los datos eran precisos cuando se ingresaron y desde entonces se han vuelto incorrectos por cambios externos. Las empresas se mudan. Los contactos cambian de trabajo. Los números de teléfono quedan inactivos. Las rondas de financiación ocurren. Los recuentos de personal cambian. El CRM no sabe; solo almacena lo que se ingresó. Con el tiempo, la brecha entre los registros del CRM y la realidad se expande.
Los cuatro tipos de problemas degradan la calidad de la salida AI de formas específicas. Los duplicados confunden a los modelos de scoring con datos de señal divididos. Los campos faltantes reducen la precisión del modelo y producen registros sin puntuar. Los registros obsoletos inflan los números del pipeline y distorsionan el pronóstico. El drift de enriquecimiento produce outreach a contactos incorrectos y criterios de calificación equivocados.
Cómo el Workflow Copilot maneja la higiene
El patrón Workflow Copilot en el ACE Framework describe un bucle de asistencia continua: Ingest el contexto actual, Analyze para identificar qué necesita atención, Generate una sugerencia, Execute con aprobación humana (o acción automatizada para casos de alta confianza), luego repetir.
Aplicado a la higiene del CRM:
Ingest lee el estado actual del CRM. Todos los registros, todos los logs de actividad, todos los valores de campos. Esto ocurre de forma continua (los nuevos registros activan verificaciones inmediatas) y de forma programada por lotes (escaneado completo de la base de datos semanalmente).
Analyze identifica problemas de datos en los cuatro tipos de problemas:
- Detección de duplicados: matching en nombre de empresa, dominio, número de teléfono y similitud de dirección
- Verificación de completitud: puntuando cada registro frente a las definiciones de campos requeridos
- Evaluación de actualidad: marcando registros sin actividad registrada pasados umbrales configurables
- Detección de drift de enriquecimiento: comparando datos del CRM con fuentes de datos externas (bases de datos de empresas, LinkedIn, búsqueda de dominio)
Generate produce una corrección sugerida para cada problema identificado:
- Para duplicados: una recomendación de fusión que especifica qué registro mantener como principal y qué campos tomar de cada registro
- Para campos faltantes: valores auto-completados de fuentes de enriquecimiento, con puntuaciones de confianza
- Para registros obsoletos: cambio de estado sugerido (marcar inactivo, recalificar, archivar) con contexto
- Para drift: valores de campo actualizados del enriquecimiento, claramente originados
Execute enruta la corrección sugerida a través de uno de dos caminos, dependiendo de la confianza:
- Alta confianza (por encima del umbral): ejecutar automáticamente la corrección y registrar la acción
- Por debajo del umbral: poner en cola para revisión del representante o RevOps con la corrección sugerida presentada
La capa de gobernanza es lo que separa esto del caos. La ejecución automatizada de todo produce un tipo diferente de problema de calidad de datos: las correcciones aplicadas a escala sin revisión pueden propagar errores tan eficientemente como los corrigen. Para los principios de gobernanza más amplios que se aplican a todos los sistemas AI, AI sales ops governance and audit trails cubre el marco en detalle.
Los datos de contacto B2B se deterioran un 2.1% mensual, y el 30% de todos los registros del CRM se vuelven obsoletos anualmente. Una campaña de limpieza trimestral significa que la organización promedio opera con un 5-7% de datos degradados durante la mayor parte del año.
La Regla de Auto-Corrección por Umbral de Confianza
La Regla de Auto-Corrección por Umbral de Confianza es el principio de gobernanza que determina qué correcciones de higiene del CRM se ejecutan automáticamente y cuáles requieren revisión humana. Tiene tres niveles: por encima del 90% de confianza en una fuente de enriquecimiento conocida activa la auto-corrección con una entrada en el log de auditoría; entre el 50-90% de confianza genera una sugerencia en cola para aprobación de RevOps o del representante; por debajo del 50% de confianza produce solo una marca, sin corrección sugerida. La regla previene dos modos de fallo: la sub-automatización (un backlog que nadie procesa) y la sobre-automatización (errores confiados propagados a escala). Los porcentajes de umbral deben calibrarse trimestralmente basándose en revisiones de auditoría muestral de las auto-correcciones.
Umbrales de auto-corrección vs. revisión del representante
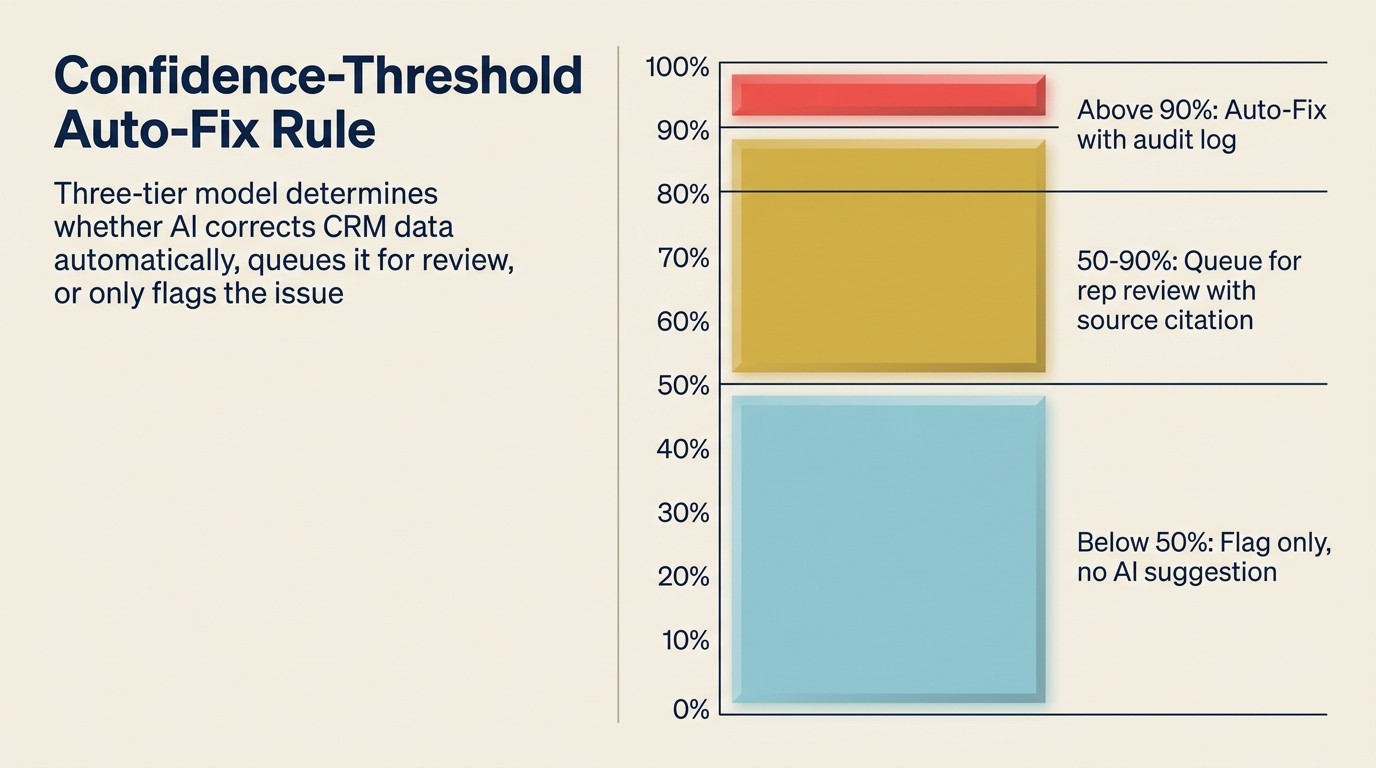
El modelo de gobernanza es la decisión de diseño más importante en un sistema AI de higiene del CRM.
Lo que se auto-corrige:
- Registros duplicados de coincidencia exacta (misma dirección de correo, mismo dominio, misma empresa confirmada) sin datos de campo conflictivos: fusionar automáticamente, registrar la fusión
- Campos faltantes donde la confianza de la fuente de enriquecimiento es alta (mayor del 90%): completar automáticamente
- Registros con cero actividad y cero historial de deals de más de 365 días: auto-archivar con una ventana de recuperación de 30 días
Lo que va a la cola de revisión:
- Duplicados de coincidencia aproximada (mismo nombre de empresa, dominios diferentes): presentar una sugerencia de fusión, requerir confirmación humana
- Campos faltantes donde la confianza de enriquecimiento es moderada (50% a 90%): sugerir el completado con cita de la fuente, requerir confirmación
- Deals activos obsoletos (sin actividad en 90 días, estado del deal todavía abierto): alertar al propietario del deal, no auto-cerrar
- Drift de enriquecimiento en campos clave como nombre de empresa o contacto principal: marcar para revisión del representante, no sobrescribir silenciosamente
Lo que solo se marca:
- Posible drift de enriquecimiento con baja confianza: mostrar como "esto puede estar desactualizado" sin sugerir una corrección específica
- Registros que parecen tener datos no coincidentes en varios campos sin una corrección clara
La calibración del umbral requiere ajuste basado en su entorno de datos. Comience de forma conservadora (más revisión, menos automatización) y avance hacia la automatización a medida que construye confianza en la precisión del modelo para sus patrones de datos específicos.
Una forma útil de pensarlo: si el AI comete un error en este nivel de confianza, ¿qué tan grave es la consecuencia? Para duplicados de coincidencia exacta, el costo de una fusión incorrecta es recuperable. Para sobrescribir la información de un contacto clave con datos de enriquecimiento incorrectos, la consecuencia es un representante llamando a la persona equivocada sobre un deal activo. Los diferentes perfiles de riesgo requieren diferentes umbrales.
Los cuatro tipos de problemas de higiene en profundidad

Duplicados
Los registros duplicados son el problema de datos CRM más común y el más computacionalmente interesante de detectar. Las coincidencias exactas en correo electrónico o dominio son fáciles. Los casos difíciles son:
- "Acme Corp" y "Acme Corporation" (misma empresa, cadenas de nombre diferentes)
- Dos registros de contacto para "John Smith" con el mismo número de teléfono pero diferentes empresas listadas (cambio de trabajo, no una persona diferente)
- Una empresa que fue adquirida y ahora existe tanto como una cuenta por derecho propio como como una subsidiaria bajo el adquirente
La deduplicación AI usa múltiples señales de matching: similitud de cadena en el nombre de la empresa, matching de dominio, matching de dirección, matching de teléfono y análisis de grafo de red (contactos vinculados a la misma empresa a través de diferentes rutas). Combinar señales produce una puntuación de confianza para cada posible fusión.
La decisión operativa clave: ¿deben ser automáticas las fusiones, o debe cada fusión requerir revisión humana? Para organizaciones de alto volumen que gestionan más de 50,000 registros, requerir revisión humana en cada fusión crea un backlog que nadie procesará. Defina su umbral de automatización y audite una muestra de auto-fusiones mensualmente para verificar la precisión.
Completitud de campos
Las definiciones de campos requeridos varían según la organización. Pero un estándar mínimo para las sales operations asistidas por AI incluye: vertical de la industria de la empresa, rango de plantilla, fecha y ronda de última financiación, contacto principal con correo electrónico verificado y estado de lead calificado por ventas.
El AI completa los campos faltantes de fuentes de enriquecimiento: Clearbit, ZoomInfo, LinkedIn, Crunchbase y datos del sitio web de la empresa. La calidad varía según el tipo de campo. La plantilla de la empresa y la financiación son generalmente confiables. La clasificación de la industria puede derivar (algunos proveedores de enriquecimiento usan diferentes sistemas de taxonomía). Los datos de contacto individuales se degradan rápidamente cuando las personas cambian de trabajo.
Rastree las tasas de completitud como una métrica de RevOps permanente. Objetivo: 90%+ de completitud en campos requeridos para cuentas activas. La investigación de MIT Sloan sobre calidad de datos encuentra que las organizaciones que tratan la calidad de datos como un proceso continuo en lugar de un proyecto periódico ven resultados tres a cuatro veces mejores de sus iniciativas basadas en datos. Cuando la completitud cae por debajo del umbral, investigue si el problema está en el workflow de entrada de datos (representantes que omiten campos) o en la cobertura de enriquecimiento (su proveedor de enriquecimiento no tiene datos para empresas pequeñas en su vertical objetivo).
Registros obsoletos
Los registros obsoletos en el pipeline son el problema de higiene más peligroso porque producen una falsa confianza en los ingresos. Un informe de pipeline que muestra $2.4M en deals abiertos es engañoso si $800K de eso está en deals que no han tenido ninguna actividad en 6 meses.
La detección de registros obsoletos con AI usa datos de marca de tiempo de actividad: último correo, última llamada, última reunión, última nota del CRM. Los registros que cruzan umbrales configurables (90 días para deals en etapa temprana, 180 días para deals en etapa avanzada) se marcan.
La acción apropiada depende del tipo de registro. Para deals abiertos: alertar al propietario del deal para que registre actividad o marque el deal como inactivo. No auto-cerrar deals activos. Para contactos sin actividad: verificar si todavía trabajan en la empresa antes de decidir qué hacer. Para cuentas sin actividad: diferenciar entre cuentas sin secuencia activa (bien) y cuentas que deberían estar en una secuencia de nutrición pero no lo están.
Drift de enriquecimiento
Este es el problema más silencioso y uno de los más dañinos. Los datos eran correctos cuando se ingresaron. La realidad externa cambió. El CRM no se actualizó.
Los cambios de trabajo de los contactos son los más comunes: el champion que ha estado cultivando dejó la empresa hace 3 meses y su representante todavía envía correos a la dirección antigua. Adquisiciones de empresas: la cuenta que está persiguiendo fue comprada y ahora es una subsidiaria con un proceso de adquisición diferente. Eventos de financiación: la empresa acaba de recaudar una Serie B, lo que cambia su poder adquisitivo y probablemente su calendario para decisiones tecnológicas.
La detección de drift AI compara los registros del CRM con señales externas: cambios en LinkedIn (cambios en el cargo o empresa del contacto), eventos de noticias (anuncios de adquisición, rondas de financiación), cambios en el sitio web de la empresa. Cuando se detecta una discrepancia, aparece como una marca en lugar de una corrección automática, porque el contexto importa. "El LinkedIn de este contacto ahora muestra una empresa diferente" es una señal, no una corrección definitiva.
Higiene continua vs. limpieza trimestral
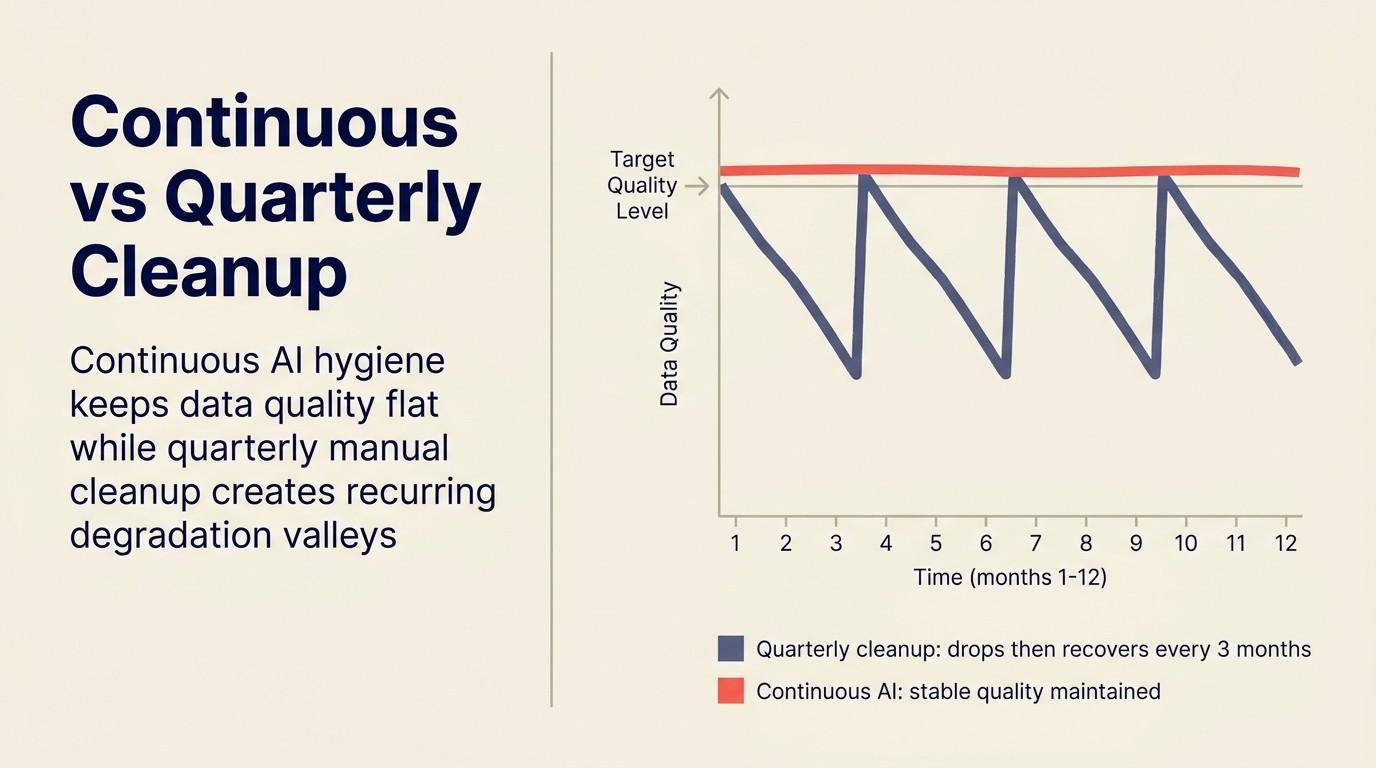
La mayoría de las organizaciones abordan la higiene del CRM como un proyecto: campañas de limpieza trimestrales, generalmente activadas por una revisión del pronóstico donde los números parecen incorrectos o una auditoría donde la calidad de los datos parece degradada.
El problema con las campañas trimestrales es la curva de degradación de datos. Para una organización con flujo de deals activo, aquí está una estimación aproximada de la rapidez con que se acumula cada tipo de problema:
- Nuevos duplicados: 5 a 15 por semana de eventos de importación, entrada manual e integraciones del sistema
- Brechas de completitud de campos: cada nuevo registro creado sin un proceso de ingesta completo
- Registros obsoletos: cada deal que se estanca, cada contacto que se enfría
- Drift de enriquecimiento: 2 a 3% de los registros de contacto activos se vuelven inexactos por mes solo por cambios de trabajo
Para cuando se ejecuta una campaña de limpieza trimestral, se han acumulado meses de degradación. La limpieza es un proyecto más grande cada vez. Y no previene la degradación; simplemente restaura a la línea base antes del próximo ciclo de deterioro.
La higiene AI continua cambia la economía. En lugar de corregir por lotes meses de problemas acumulados, el AI se ejecuta continuamente y detecta los problemas cerca del momento en que ocurren. La carga de mantenimiento por problema es menor. El piso de calidad de datos es más alto. Y las funciones downstream asistidas por AI, scoring, routing, pronóstico, todas operan con datos más limpios a lo largo del trimestre, no solo en las dos semanas después de un proyecto de limpieza.
Dependencia upstream: por qué los datos limpios no son solo una preocupación de higiene
Cada función AI en su stack de ventas está corriente abajo de la calidad de los datos del CRM. Esta cadena de dependencia hace que la higiene de datos sea una inversión estratégica, no solo una operacional.
AI Lead Scoring Beyond Rules-Based Models depende de la completitud de los campos del CRM para los inputs de scoring. Los campos faltantes de industria o plantilla producen registros sin puntuar o mal puntuados.
From Call to CRM Update Automatically produce datos CRM más limpios como salidas, pero depende de que los registros de cuenta y contacto estén correctamente estructurados para saber dónde escribir las actualizaciones.
Next Best Action for Each Open Deal usa datos de etapa del deal, fechas de última actividad y completitud de contactos para generar recomendaciones. Los datos de deals obsoletos y la información de contacto faltante degradan directamente la calidad de las recomendaciones.
El efecto compuesto: los problemas de higiene del CRM no producen errores aislados. Se propagan. Un registro de cuenta duplicado significa que las señales de scoring se dividen en dos registros, reduciendo la intención aparente de ambos. Un deal obsoleto infla el pronóstico del pipeline, lo que lleva a una planificación de recursos demasiado optimista. Un contacto desactualizado significa que el outreach va a la persona incorrecta, lo que no genera respuesta, lo que el modelo de scoring AI interpreta como baja participación, lo que reduce la puntuación de prioridad de la cuenta.
Los datos limpios mejoran cada salida AI downstream. No se trata de tener registros ordenados. Se trata de la calidad de cada decisión generada por AI que su organización toma a partir de esos registros.
Herramientas de implementación
Rework CRM incluye higiene de datos asistida por AI como parte de su capa de sales operations. La detección de duplicados, el completado de campos desde fuentes de enriquecimiento y el marcado de obsolescencia están integrados en el workflow de gestión de cuentas y contactos. El modelo de gobernanza (auto-corrección vs. cola de revisión) es configurable por tipo de campo y umbral de confianza.
Salesforce duplicate management proporciona reglas de duplicados y reglas de matching nativas, con detección y fusión automatizada. Las herramientas de terceros (Cloudingo, DemandTools) extienden esto con lógica de matching más sofisticada y operaciones por lotes. El enriquecimiento AI se añade típicamente a través de la integración con Clearbit o ZoomInfo.
Las herramientas de calidad de datos de HubSpot incluyen gestión de duplicados para contactos y empresas, con una cola de revisión dedicada. Los informes de salud de datos a nivel de campo muestran tasas de completitud en toda la base de datos. El enriquecimiento nativo de HubSpot (a través de su función de enriquecimiento de datos) completa automáticamente los campos básicos de la empresa para los registros identificados.
Clay es una opción más componible para equipos que quieren construir workflows de enriquecimiento personalizados. Conecte múltiples fuentes de datos (Clearbit, Apollo, LinkedIn, datos de dominio), defina cascadas de enriquecimiento (intente la fuente A, recurra a la fuente B) y envíe datos limpios de vuelta a su CRM. Requiere más configuración que las herramientas nativas del CRM pero ofrece más flexibilidad para casos de uso no estándar.
La capacidad Analyze cubre la lógica de detección y clasificación que subyace al análisis de higiene. El artículo data readiness prerequisite explica por qué los datos limpios del CRM son el requisito que abre paso para cada sistema AI en su stack. Las 12 acciones de Gartner para mejorar la calidad de datos es un recurso complementario práctico para líderes de RevOps que construyen un programa formal de calidad de datos junto a sus herramientas de higiene AI.
El argumento de la infraestructura
La higiene del CRM es la línea presupuestaria menos glamorosa en un presupuesto de RevOps. No genera ingresos directamente, no añade una nueva capacidad y no produce una métrica que aparezca en un informe de la junta directiva.
Pero es la infraestructura que hace que todo lo demás sea preciso. La precisión del lead scoring, la precisión del routing, la fiabilidad del pronóstico del pipeline, la calidad de la siguiente acción del representante: todo ello depende de la calidad de los datos.
El modelo de higiene continua asistida por AI cambia la ecuación de recursos. En lugar de un gran proyecto de limpieza por trimestre que consume de 40 a 80 horas de tiempo de RevOps, tiene un sistema siempre activo que detecta y corrige problemas en la fuente. El tiempo humano total requerido es menor. La calidad de los datos es consistentemente más alta.
Y cuando añade una nueva capacidad AI a su stack de ventas, no empieza desde un problema de datos. Está construyendo sobre datos limpios. Ese es el retorno compuesto de la inversión en infraestructura.
La higiene de datos no es un producto que compra una vez. Es un proceso que ejecuta continuamente. El AI hace posible ejecutar ese proceso sin un crecimiento proporcional del personal. Ese es el argumento para ello. Y es la razón por la que todas las demás herramientas AI en su stack funcionan mejor cuando hace bien esta.
Rework Analysis: En los despliegues de RevOps, la decisión de calibración inicial más importante es el umbral de auto-corrección para las fusiones de duplicados. Establecerlo demasiado bajo (auto-fusionando coincidencias aproximadas por debajo del 85% de confianza) crea un problema diferente de calidad de datos: empresas legítimas con nombres similares fusionadas incorrectamente, produciendo una contaminación del historial de actividad que es más difícil de desenredar que los duplicados originales. Comience al 95% de confianza para la auto-fusión, verifique 50 auto-fusiones aleatorias en el primer mes, luego ajuste el umbral basándose en la tasa de error. La mayoría de los equipos puede pasar al 90% después del primer ciclo de calibración.
Las organizaciones con programas de higiene de datos AI continua mantienen el 90%+ de completitud de campos en los campos requeridos del CRM. Las organizaciones que dependen de la limpieza manual trimestral promedian el 65-75% de completitud, con la precisión más baja en las seis semanas antes de cada ciclo de limpieza. (Investigación de calidad de datos de MIT Sloan)
Preguntas Frecuentes
¿Cuánto cuesta realmente la mala calidad de datos del CRM?
La mala calidad de datos le cuesta a la empresa B2B promedio entre $12.9 y $15 millones anuales a través de gasto de marketing desperdiciado, oportunidades de ventas perdidas e ineficiencias operativas, según estimaciones de Gartner. A nivel del representante individual, los representantes de ventas desperdician el 27% de su tiempo lidiando con datos deficientes, con un costo de aproximadamente $32,000 por representante anuales. El costo organizacional se compone porque cada función AI downstream del CRM (lead scoring, pronóstico de pipeline, siguiente mejor acción) está produciendo salidas confiadamente incorrectas desde inputs sucios.
¿Con qué rapidez se deterioran los datos del CRM?
Los datos de contacto B2B se deterioran aproximadamente un 2.1% mensual, lo que se traduce en que el 22-30% de todos los registros de contacto se vuelven inexactos en un año sin higiene activa. Los cambios de trabajo son el principal motor: los contactos cambian empleadores, cargos y direcciones de correo electrónico continuamente. Los datos a nivel de empresa (firmográficos, etapa de financiación, tech stack) cambian más lentamente pero tienen un impacto igualmente significativo cuando lo hacen, porque afectan los inputs del modelo de scoring y los criterios de calificación.
¿Qué es la Regla de Auto-Corrección por Umbral de Confianza?
La Regla de Auto-Corrección por Umbral de Confianza es un modelo de gobernanza de tres niveles para las correcciones AI del CRM: por encima del 90% de confianza en una fuente de enriquecimiento conocida activa la auto-corrección con un log de auditoría; entre el 50-90% de confianza pone en cola una sugerencia para revisión humana; por debajo del 50% produce solo una marca. La regla previene la sub-automatización (backlog que nadie procesa) y la sobre-automatización (errores confiados a escala). Los umbrales deben calibrarse trimestralmente mediante revisiones de auditoría de muestra de las auto-correcciones. La mayoría de los equipos comienza al 95% para el nivel de auto-corrección y pasa al 90% después del primer ciclo de calibración.
¿Qué cuatro tipos de problemas de datos CRM aborda la higiene AI?
La higiene AI del CRM aborda duplicados (misma empresa o contacto en múltiples registros), brechas de completitud de campos (campos requeridos vacíos), registros obsoletos (deals abiertos o contactos sin actividad durante 90-180+ días) y drift de enriquecimiento (datos que eran precisos cuando se ingresaron pero que desde entonces se han vuelto incorrectos por cambios externos). Cada tipo de problema degrada diferentes funciones AI downstream: los duplicados dividen las señales de scoring, los campos faltantes reducen la precisión del modelo, los registros obsoletos inflan los pronósticos de pipeline y el drift produce outreach a contactos incorrectos.
¿Por qué es insuficiente la limpieza trimestral del CRM?
La limpieza trimestral trata la calidad de datos como un proyecto en lugar de un proceso. Para una organización con flujo de deals activo, los nuevos duplicados se acumulan a 5-15 por semana, las brechas de completitud de campos aparecen con cada nuevo registro, los deals obsoletos se acumulan constantemente y el 2.1% de los contactos deriva por mes. Para cuando se ejecuta una campaña trimestral, se han acumulado meses de degradación. La higiene AI continua detecta los problemas cerca de cuando ocurren, reduciendo tanto el backlog como las consecuencias de los errores que persisten durante 90 días antes de corregirse.
¿Cómo afecta la calidad de datos del CRM al lead scoring AI?
Los modelos de lead scoring AI se entrenan y ejecutan contra los datos del CRM. Los campos faltantes (sin vertical de la industria, sin plantilla) producen registros sin puntuar o con puntuaciones inexactas. Los registros duplicados dividen las señales de intención en dos cuentas, haciendo que cada una parezca menos comprometida de lo que realmente está. Los datos de deals obsoletos distorsionan los conjuntos de entrenamiento al incluir deals inactivos como si fueran prospectos activos. Las organizaciones con tasas de completitud del CRM del 90%+ ven una precisión de lead scoring significativamente más alta que las organizaciones con el 65-75% de completitud, porque el modelo tiene datos de señal más completos con los que trabajar.
Qué leer a continuación
- Workflow Copilot: AI as Peer-Level Assistant: el patrón ACE detrás de la asistencia AI continua en los workflows de ventas
- AI Lead Scoring Beyond Rules-Based Models: cómo la calidad de los datos del CRM afecta directamente la precisión del modelo de scoring
- Next Best Action for Each Open Deal: la función AI downstream más dependiente de los datos limpios del deal
- AI Sales Ops Governance and Audit Trails: marcos de gobernanza para operaciones de datos automatizadas

Co-Founder, Rework.com
On this page
- Qué significa operativamente la higiene de datos del CRM
- Cómo el Workflow Copilot maneja la higiene
- La Regla de Auto-Corrección por Umbral de Confianza
- Umbrales de auto-corrección vs. revisión del representante
- Los cuatro tipos de problemas de higiene en profundidad
- Duplicados
- Completitud de campos
- Registros obsoletos
- Drift de enriquecimiento
- Higiene continua vs. limpieza trimestral
- Dependencia upstream: por qué los datos limpios no son solo una preocupación de higiene
- Herramientas de implementación
- El argumento de la infraestructura
- Qué leer a continuación