AI Lead Scoring Vượt Qua Mô Hình Rules-Based

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Hầu hết "lead scoring" đang được deploy hiện nay là manual weighting được ngụy trang thành intelligence.
Logic như sau: gửi form có giá trị 10 điểm, chức danh VP thêm 20 điểm, công ty có 200+ nhân viên thêm 15 điểm, truy cập pricing page thêm 25 điểm. Cộng lại và bất kỳ thứ gì trên 70 là "hot lead." Sales team làm việc với hot lead trước.
Vấn đề rõ ràng khi nói thành lời: một người đã quyết định những weight đó. Họ đưa ra phán đoán, có thể dựa trên một số trực giác và vài câu chuyện từ sales team, rồi encode nó thành static rule. Các weight không update khi thị trường thay đổi. Chúng không recalibrate khi ICP của bạn thay đổi sau khi raise Series B. Và chúng chắc chắn không capture sự tương tác giữa các tín hiệu.
Chức danh VP từ công ty 50 người lúc 2 giờ sáng Thứ Bảy convert ở rate hoàn toàn khác so với cùng chức danh từ công ty 300 người lúc 10 giờ sáng Thứ Ba.
Machine learning (ML) lead scoring để dữ liệu chọn weight thay vì người. Đó là toàn bộ sự khác biệt về mặt khái niệm. Nhưng execute tốt đòi hỏi phải hiểu model hoạt động thế nào, cần data gì, và deployment thất bại ở đâu. Đây là Pattern 1 trong kiến trúc AI Sales Operator, và là nền tảng mọi thứ khác xây dựng trên.
Rules-based scoring bỏ lỡ điều gì
Rule là categorical. ML model là probabilistic. Nghiên cứu McKinsey về AI trong B2B sales xác định lead qualification là một trong những AI use case tác động cao nhất cho sales team, chính xác vì cải thiện compound: scoring tốt hơn có nghĩa rep làm việc với lead tốt hơn, dẫn đến nhiều close hơn, dẫn đến training data tốt hơn cho lần model iteration tiếp theo. Sự phân biệt đó tạo ra tập hợp systematic blind spot trong rules-based approach:
Field sparsity. Hầu hết lead form capture 4-6 field. Hầu hết CRM record có hàng chục field tiềm năng liên quan, nhiều field trống. Rule xử lý field trống là neutral. ML model có thể học rằng thiếu LinkedIn URL trong một company-size band cụ thể tương quan với close rate thấp hơn, vì đó là những gì historical data cho thấy. Sự vắng mặt của thông tin tự nó là tín hiệu.
Timing và sequence. Lead truy cập pricing page ngày một và điền demo form cùng ngày convert khác so với lead truy cập pricing page ba tuần trước khi submit form, rồi truy cập lại ngày hôm trước. Rule có thể detect "pricing page visit = 25 điểm," nhưng không capture recency curve hay behavioral sequence. ML model thì có.
Firmographic change signal. Công ty vừa hire VP of Sales là prospect hoàn toàn khác so với cùng công ty sáu tháng trước. Funding round gần đây thay đổi buying capacity. Product launch mới tạo ra technology need. Static rule không pick up các dynamic signal này. ML model được feed với recent firmographic data (từ LinkedIn, Clearbit, hoặc 6sense) có thể factor chúng vào.
Multi-touch interaction. Sự kết hợp "VP title + pricing page + referral source = partner channel" có thể convert ở 40%. Mỗi element đơn lẻ có thể đáng giá 10%. Rule score chúng độc lập; ML capture interaction effect.
Key Facts: AI Lead Scoring
- McKinsey xác định lead qualification là một trong những AI use case tác động cao nhất cho B2B sales team, vì scoring tốt hơn compound: lead tốt hơn close thường xuyên hơn, generating training data tốt hơn cho model iteration tiếp theo
- Tối thiểu 200 closed-won deal là cần thiết cho ML lead scoring model đáng tin cậy; dưới 100, hầu hết commercial tool produce output không thể phân biệt thống kê với random assignment
- Công ty dùng AI-assisted lead scoring báo cáo lead-to-opportunity conversion rate cao hơn 10-20% so với static rules-based model, theo customer data của MadKudu và 6sense (2022-2024)
ML lead scoring hoạt động thế nào (không cần bằng tiến sĩ)
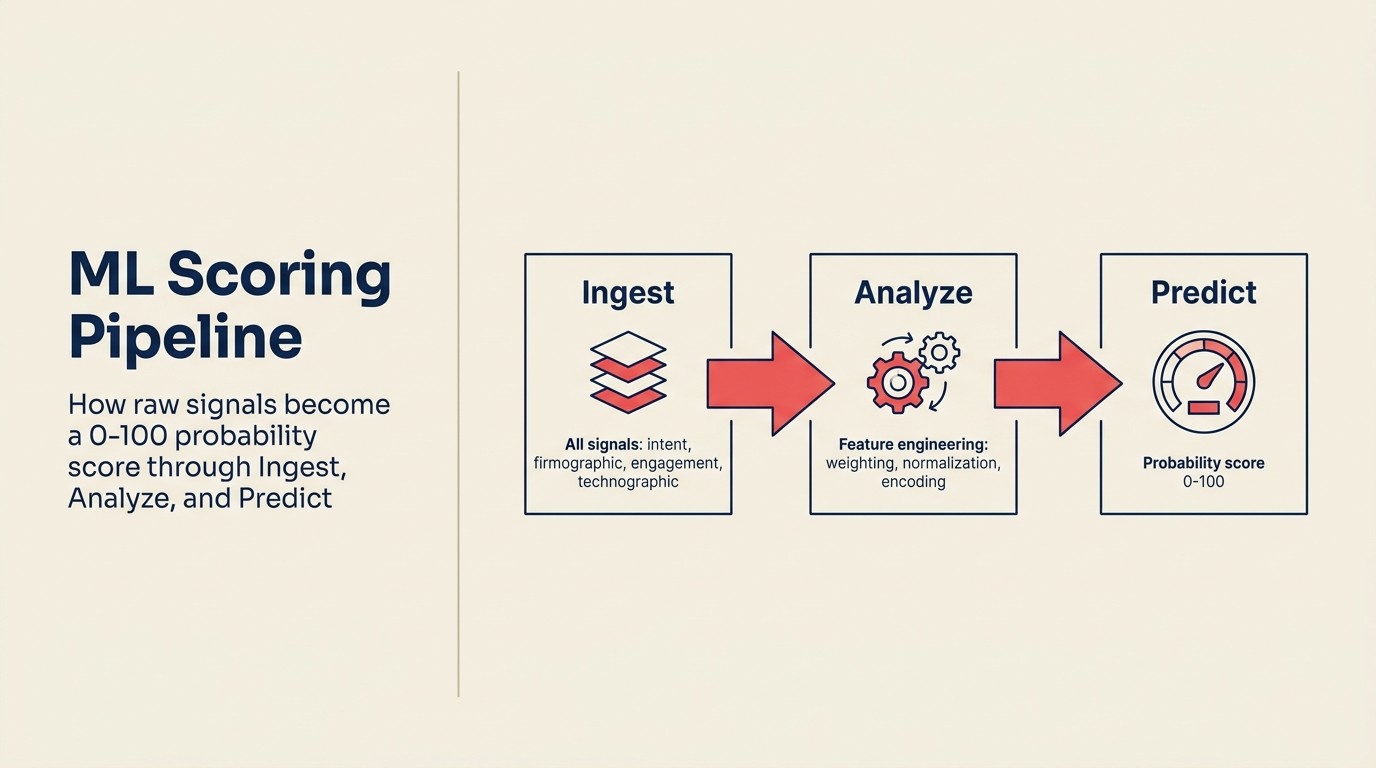
Cơ chế đơn giản hơn hầu hết vendor làm nó nghe có vẻ phức tạp. Đây là operational logic, dùng từ vựng ACE Framework:
Ingest pull vào tất cả signal có sẵn cho mỗi lead: CRM field (title, company size, industry, source), behavioral data (trang đã truy cập, email đã mở, webinar đã tham dự), firmographic enrichment (revenue band, headcount, funding stage, tech stack), và time-based data (khi activity xảy ra, khoảng cách giữa chúng).
Analyze extract feature từ raw data đó. Feature là input variable model thực sự train trên. Một số là trực tiếp (title = "VP" là binary feature). Một số được engineer (số ngày giữa first visit và form submission là numeric feature). Một số là interaction term (company size x engagement frequency là composite signal). Feature engineering là nơi hầu hết công việc xảy ra, và nơi ops team hiểu data của chính họ có lợi thế so với generic out-of-box model.
Predict train model trên historical labeled data: deal đã close (won) và deal không close (lost), cùng với tất cả feature ở trên. Bên dưới, hầu hết commercial lead scoring tool dùng logistic regression hoặc gradient boosting, cả hai là ML technique được hiểu rõ tạo ra probability giữa 0 và 1. Model học combination feature nào correlate với closed-won outcome trong customer base cụ thể của bạn và áp dụng learned weight đó cho mỗi lead mới, producing probability output: lead này có 73% cơ hội convert, dựa trên những gì chúng ta biết về nó.
Chỉ vậy thôi. Một probability number từ 0 đến 100, grounded trong lịch sử win/loss của chính bạn, updated khi deal mới close. Recalibration loop là thứ tách biệt working model với model từ từ drift.
Probabilistic Lead Score Standard
Probabilistic Lead Score Standard định nghĩa những gì một defensible AI lead score phải bao gồm: probability output giữa 0 và 1 grounded trong lịch sử win/loss của chính công ty, trained trên ít nhất 200 closed-won outcome, recalibrated không ít hơn quarterly so với deal outcome mới, và exposed với rep có feature attribution (tín hiệu nào drove score này). Bất kỳ scoring system nào fail một trong bốn criteria này tốt hơn được classify là enhanced rules-based scoring thay vì true ML scoring, vì output không được grounded thống kê trong measured conversion pattern.
Xếp hạng loại tín hiệu theo conversion lift

Không phải tất cả signal đều có ích như nhau. Dựa trên pattern từ nghiên cứu MadKudu và 6sense buyer intent data công bố 2022-2024, đây là cách signal category thường xếp hạng về lift contribution cho B2B SaaS:
| Loại tín hiệu | Ví dụ | Lift Contribution | Ghi chú |
|---|---|---|---|
| Intent signal | Pricing page visit, competitor comparison page, G2 category view | Rất cao | Late-stage buying signal; recency quan trọng (7 ngày qua >> 30 ngày qua) |
| Engagement recency | Email open, website visit trong 14 ngày qua, tham dự webinar | Cao | Recency curve quan trọng: exponential decay sau 30 ngày |
| Firmographic fit | Company size, industry vertical, funding stage | Cao | Định nghĩa ICP của bạn được encode toán học |
| Technographic fit | CRM type (Salesforce vs. HubSpot), integration đã biết, current tech stack | Trung bình-Cao | Lift mạnh nhất khi sản phẩm của bạn replace hoặc complement một tool cụ thể |
| News trigger | Recent funding, new hire announcement, product launch | Trung bình | Tín hiệu mạnh cho cold outbound; ít predictive hơn cho inbound |
| Contact-level fit | Title, seniority, department | Trung bình | Mạnh nhất khi kết hợp với company-level fit, yếu hơn khi tách biệt |
| Lead source | Organic search, partner referral, content download | Thấp-Trung bình | Thay đổi đáng kể theo công ty; luôn test thay vì assume |
| Form behavior | Time on form, field đã điền, device type | Thấp | Hữu ích như tiebreaker; không phải primary signal |
Thứ tự thay đổi dựa trên sản phẩm và thị trường của bạn. Với developer tool, technographic fit có thể là signal mạnh nhất. Với financial services product, firmographic band và regulatory context có thể dominate. Model học ranking cụ thể của công ty bạn từ data; bảng trên là starting hypothesis.
Checklist data readiness trước khi deploy
Đây là bước hầu hết công ty bỏ qua. AI lead scoring không produce kết quả tốt trên data xấu. Trước khi mua hoặc configure bất kỳ ML scoring tool nào, chạy qua checklist này:
Requirement tối thiểu:
- Ít nhất 6 tháng closed deal với consistent won/lost label (ưu tiên 12 tháng)
- Ít nhất 200 closed-won deal tổng cộng (nhiều hơn tốt hơn; dưới 100 produce model không đáng tin cậy)
- CRM deal stage nhất quán trên toàn team (không có biến thể "Closed Won" vs. "Won" vs. "Closed")
- First-touch source được capture trên ít nhất 70% record
- Company name và domain được điền trên 80%+ record
Strong-to-have (cải thiện model quality đáng kể):
- Contact title và seniority được capture trên ít nhất 60% lead
- Company size (employee count) được capture hoặc enrichable cho 70%+ record
- Website behavioral data (HubSpot tracking, Segment, hoặc equivalent) gửi event đến CRM
- Ít nhất một firmographic enrichment source (Clearbit, Apollo, ZoomInfo) feed CRM
Warning sign gợi ý cần làm data work trước khi scoring:
- Hơn 20% deal close mà không có outcome label
- Ba hoặc nhiều tên stage khác nhau cho cùng lifecycle position
- Dưới 6 tháng deal history sau CRM migration (pre-migration data thường không đáng tin cậy)
- Không có behavioral tracking data (không có page visit history, không có email open tracking)
Nếu bạn thiếu nhiều item trong minimum list, dành bốn đến sáu tuần clean data trước khi deploy scoring. Model sẽ được xây dựng trên bất cứ thứ gì bạn feed vào nó.
Từ model output đến routing threshold
Model cho bạn probability. Bạn vẫn cần quyết định phải làm gì với nó.
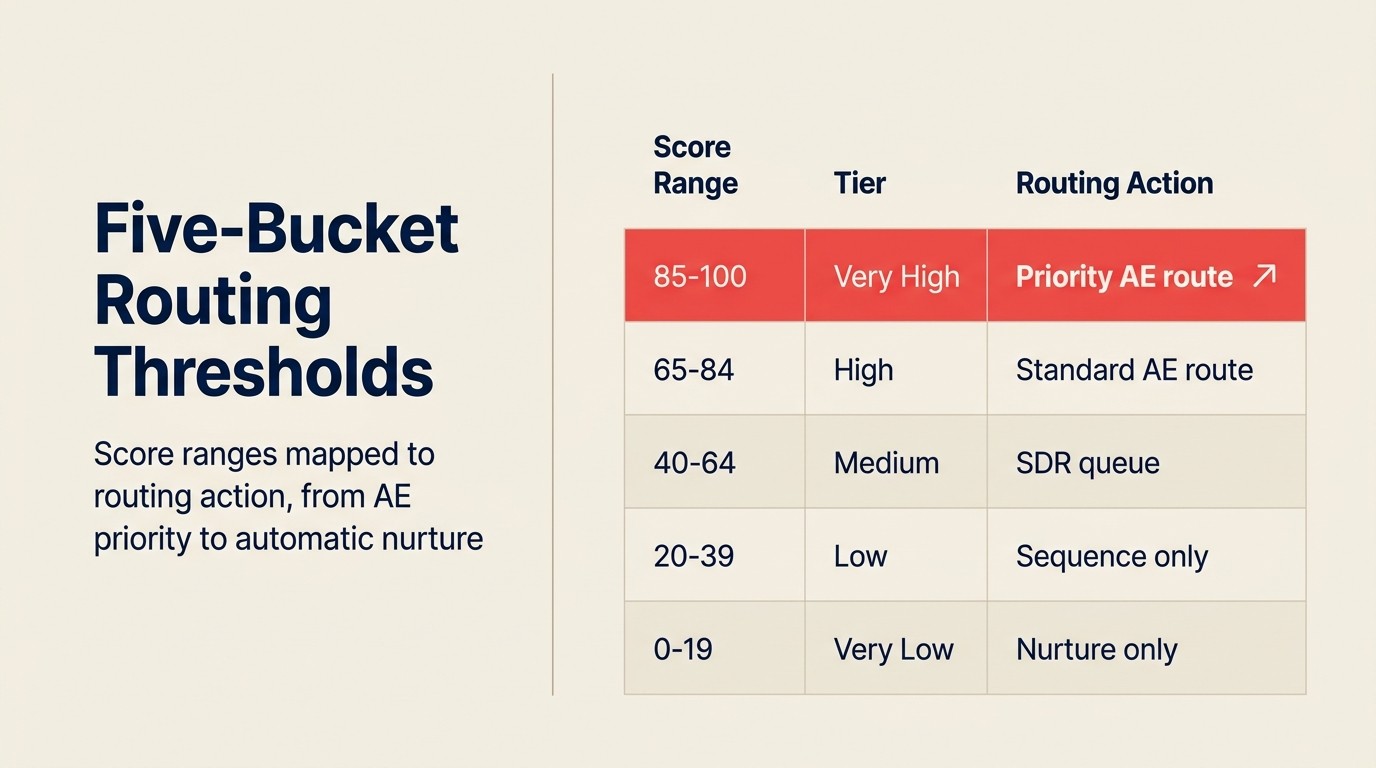
Hầu hết deployment xác định ba đến năm bucket với routing logic đính kèm:
| Score Range | Label | Routing Action |
|---|---|---|
| 85-100% | Rất cao | Route đến senior AE, immediate Slack notification, không có SDR filter |
| 65-84% | Cao | Route đến AE queue, SLA: liên hệ trong 2 tiếng |
| 40-64% | Trung bình | Route đến SDR để qualification, enroll vào mid-touch sequence |
| 20-39% | Thấp | Auto-enroll vào nurture sequence, không có rep assignment |
| 0-19% | Rất thấp | Không action; chỉ thêm vào newsletter list |
Các threshold number là của bạn để set, không phải của vendor. Chúng nên reflect: bạn có bao nhiêu rep capacity (nhiều rep hơn = threshold thấp hơn cho direct assignment), bạn có thể tolerate false positive bao thường (high-scored lead hóa ra sai = wasted rep time), và các contact SLA commitment hiện tại của bạn là gì.
Setting threshold đúng là calibration exercise, không phải one-time configuration. Chạy với initial threshold trong 60 ngày, sau đó compare: với mỗi bucket, actual conversion rate là bao nhiêu? Nếu "High" bucket của bạn đang convert ở 8% và "Medium" bucket đang convert ở 12%, threshold của bạn bị miscalibrate. Adjust và observe lại. Và luôn theo dõi queue volume: threshold drift đột ngột gửi 40% lead đến "High" bucket sẽ destroy rep trust trong vài tuần.
Common failure mode
Model được train trên biased historical data. Nếu historical win của bạn skew về một channel cụ thể (ví dụ: 70% closed deal đến từ partner referral), model sẽ học score partner-sourced lead cao. Khi bạn expand sang channel mới, model sẽ score những lead đó kém. Không phải vì chúng là lead xấu, mà vì không có training data cho pattern đó. Fix: retrain với broader data, hoặc segment model theo source.
Score không được surface cho rep. Model produce output tốt, nhưng nó nằm trong CRM field không ai nhìn. Rep tiếp tục làm việc với lead theo arrival order. Đây là adoption failure, không phải model failure. Fix: surface score trong daily workflow của rep (Slack notification, CRM queue sorted by score) và train rep về ý nghĩa của score trước khi go-live.
Không có feedback loop để retrain. Model được configure vào tháng Một và không bao giờ được động vào lại. Mười hai tháng sau, thị trường đã thay đổi, ICP đã evolve, và model vẫn đang optimize cho pattern từ 18 tháng trước. Fix: xây dựng quarterly recalibration process. RevOps lead review model performance metric (accuracy, precision, recall by bucket) và trigger retrain khi accuracy giảm hơn 5 percentage point.
Threshold set-and-forget. Initial threshold được set khi go-live và không bao giờ được review. 90 ngày sau, 40% tất cả lead đang score "High" vì model học quá broadly. "High" queue đang overwhelm rep và trust sụp đổ. Fix: review threshold distribution monthly và adjust để maintain queue volume phù hợp với rep capacity.
Xử lý đầy đủ các common AI lead scoring pitfall.
Vendor snapshot
Salesforce Einstein Lead Scoring được include trong Sales Cloud Enterprise trở lên. Nó train trực tiếp trên Salesforce data của bạn mà không cần export hoặc connect với third-party tool. Model tự recalibrate theo periodic schedule. Quality mạnh cho công ty có clean Salesforce data và 12+ tháng lịch sử. Config hạn chế cho advanced feature engineering hoặc custom data source.
HubSpot Predictive Lead Scoring có sẵn trên Marketing Hub Professional/Enterprise và Sales Hub Enterprise. Architecture tương tự Einstein: train trên HubSpot data, produce score visible trong HubSpot pipeline. Yếu hơn cho công ty có significant behavioral data ngoài HubSpot hoặc complex firmographic segmentation need.
MadKudu là purpose-built B2B scoring platform connect với Salesforce, HubSpot, và nhiều data enrichment source. Nó surface feature importance (tín hiệu nào drove score cụ thể), giúp RevOps dễ audit và calibrate hơn. Best fit cho công ty muốn transparency vào model logic và sẵn sàng làm data integration work.
6sense tập trung vào intent signal (buying committee identification, anonymous visitor tracking) hơn là conversion probability. Điểm mạnh là mid-funnel account prioritization, đặc biệt cho account-based selling. Thường được layer trên CRM-native scoring model thay vì replace nó.
Rework Sales AI bao gồm Scoring+Routing được built into CRM như phần của full AI Sales Operator architecture. Score recalibrate từ deal outcome, route đến rep queue tự động, và feed trực tiếp vào Workflow Copilot cho draft follow-up. Best fit cho team muốn integrated scoring mà không quản lý separate vendor relationship.
Rework Analysis: ML lead scoring failure phổ biến nhất chúng tôi thấy không phải là model xấu. Đó là model tốt mà không ai recalibrate. Team deploy trong Q1, thấy kết quả mạnh trong Q2, và đến Q4 họ tự hỏi tại sao các "hot" lead không còn close nữa. Model đã được train trên thị trường tồn tại 9 tháng trước. ICP của họ thay đổi sau pricing change, competitor mới vào, hoặc use case mới nổi lên. Quarterly recalibration không phải optional maintenance; đó là cơ chế giữ probability output kết nối với current reality. Team build recalibration review vào ops calendar từ ngày đầu tiên sustain ROI 12-18 tháng. Những team coi model là one-time install thường thấy performance plateau trong 6 tháng.
Feedback loop là toàn bộ trò chơi
Rules-based scoring là giả thuyết: những attribute này nên predict conversion. Bạn set nó một lần và hy vọng nó già theo thời gian tốt.
ML scoring là phép đo: những attribute này đã predict conversion, dựa trên actual outcome, được update khi có outcome mới.
Nhưng "ML scoring là phép đo" chỉ đúng khi measurement system có feedback loop. Không có recalibration, model cũng là giả thuyết, chỉ là giả thuyết được train trên data thay vì intuition. Một giả thuyết drift khi market condition thay đổi.
Deployment deliver sustained ROI là những deployment nơi RevOps own feedback loop. Họ track model accuracy quarterly. Họ retrain khi accuracy giảm. Họ audit threshold performance monthly. Họ coi scoring model là infrastructure, không phải one-time project.
Operational ownership đó là điều tách biệt AI lead scoring deployment tiếp tục improve khỏi deployment produce kết quả tốt ba tháng rồi trở thành background noise. Khi scoring model được calibrate và feed đúng lead đến đúng rep, câu hỏi tiếp theo là điều gì xảy ra với những lead đó khi chúng arrive.
Câu hỏi thường gặp
AI lead scoring là gì?
AI lead scoring dùng ML model được train trên historical CRM data để assign cho mỗi inbound lead một probability score giữa 0 và 100. Thay vì human-assigned point weight (rules-based scoring), model học signal combination nào thực sự correlate với closed-won outcome trong customer base cụ thể của bạn và áp dụng learned weight đó cho mỗi lead mới. Score update khi deal mới close, làm nó self-calibrating thay vì static.
AI lead scoring khác rules-based lead scoring thế nào?
Rules-based scoring encode giả thuyết của người: "VP title thêm 20 điểm, pricing page visit thêm 25 điểm." AI scoring đo những gì thực sự convert: model tìm signal combination correlate với won deal trong historical data của bạn và weight chúng theo đó. Sự khác biệt thực tế là rule không adapt khi ICP thay đổi, không capture interaction effect giữa signal, và không improve theo thời gian. AI model làm cả ba khi được recalibrate đúng cách.
ML lead scoring model cần data gì để hoạt động?
Requirement tối thiểu là ít nhất 6 tháng closed deal với consistent won/lost label (ưu tiên 12 tháng), ít nhất 200 closed-won deal tổng cộng, consistent CRM stage definition, first-touch source được capture trên 70%+ record, và company name/domain được điền trên 80%+ record. Model được train trên dưới 100 won deal produce output không thể phân biệt thống kê với random assignment.
Signal nào quan trọng nhất cho B2B lead scoring?
Intent signal (pricing page visit, competitor comparison page, G2 category view) carry highest conversion lift vì chúng indicate late-stage buying behavior. Engagement recency theo sau, với exponential decay sau 30 ngày. Firmographic fit (company size, industry, funding stage) là third most predictive category cho hầu hết B2B SaaS product. Ranking cụ thể thay đổi theo sản phẩm; model học ranking thực tế của công ty bạn từ data của bạn.
ML lead scoring model nên được recalibrate bao thường?
Quarterly recalibration là minimum standard. RevOps owner nên review model accuracy (precision và recall by score bucket) mỗi quý và trigger retrain khi accuracy giảm hơn 5 percentage point từ baseline. ICP thay đổi, channel mới nổi lên, và pricing change làm thay đổi lead nào convert. Model được train 9-12 tháng trước mà không recalibrate có thể đang optimize cho pattern không còn reflect current buyer.
Common failure mode nhất trong AI lead scoring là gì?
Bốn failure phổ biến nhất: (1) model được train trên biased historical data (ví dụ: 70% win từ một channel, làm model kém ở việc score channel khác); (2) score không được surface trong daily workflow của rep, nên rep ignore chúng; (3) không có recalibration process, khiến accuracy drift khi thị trường thay đổi; và (4) threshold miscalibration, nơi quá nhiều lead score "High" và overwhelm rep capacity cho đến khi trust vào system sụp đổ.
Routing action nào nên trigger với score range khác nhau?
Standard five-bucket routing model map đến: 85-100% (direct đến senior AE, immediate Slack notification), 65-84% (AE queue, 2-hour contact SLA), 40-64% (SDR qualification, enroll vào mid-touch sequence), 20-39% (automated nurture, không có rep assignment), và 0-19% (newsletter only). Threshold cụ thể nên được calibrate theo rep capacity của team bạn và review monthly để maintain queue volume phù hợp với current headcount.
Tìm hiểu thêm

Co-Founder, Rework.com
On this page
- Rules-based scoring bỏ lỡ điều gì
- ML lead scoring hoạt động thế nào (không cần bằng tiến sĩ)
- Probabilistic Lead Score Standard
- Xếp hạng loại tín hiệu theo conversion lift
- Checklist data readiness trước khi deploy
- Từ model output đến routing threshold
- Common failure mode
- Vendor snapshot
- Feedback loop là toàn bộ trò chơi
- Tìm hiểu thêm