AI Lead Scoring Melampaui Model Berbasis Aturan

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Sebagian besar "lead scoring" yang diterapkan saat ini adalah pembobotan manual yang dihias sebagai kecerdasan.
Logikanya: pengajuan formulir bernilai 10 poin, jabatan VP menambahkan 20, perusahaan dengan 200+ karyawan menambahkan 15, mengunjungi halaman harga menambahkan 25. Jumlahkan dan apa pun di atas 70 adalah "hot lead." Tim penjualan mengerjakan hot lead terlebih dahulu.
Masalahnya jelas begitu Anda mengatakannya dengan lantang: seorang manusia memutuskan bobot tersebut. Mereka membuat penilaian, mungkin berdasarkan intuisi dan beberapa anekdot dari tim penjualan, dan mengkodekannya sebagai aturan statis. Bobot tidak diperbarui saat pasar bergeser. Mereka tidak dikalibrasi ulang ketika ICP Anda berubah setelah Anda mengumpulkan Seri B. Dan mereka pasti tidak menangkap interaksi antar sinyal.
Jabatan VP dari perusahaan 50 orang pada pukul 2 pagi hari Sabtu dikonversi dengan tingkat yang sangat berbeda dari jabatan yang sama dari perusahaan 300 orang pada pukul 10 pagi hari Selasa.
Machine learning (ML) lead scoring membiarkan data memilih bobot, bukan manusia. Itulah perbedaan konseptual seluruhnya. Tetapi melaksanakannya dengan baik membutuhkan pemahaman tentang cara kerja model, data apa yang dibutuhkan, dan di mana penerapan gagal. Ini adalah Pola 1 dalam arsitektur AI Sales Operator, dan fondasi yang dibangun oleh semua hal lainnya.
Apa yang terlewatkan oleh penilaian berbasis aturan
Aturan bersifat kategoris. Model ML bersifat probabilistik. Penelitian McKinsey tentang AI dalam penjualan B2B mengidentifikasi kualifikasi lead sebagai salah satu use case AI dengan dampak tertinggi untuk tim penjualan, justru karena peningkatan tersebut majemuk: penilaian yang lebih baik berarti rep mengerjakan lead yang lebih baik, yang berarti lebih banyak penutupan, yang berarti data pelatihan yang lebih baik untuk iterasi model berikutnya. Perbedaan tersebut menghasilkan serangkaian blind spot sistematis dalam pendekatan berbasis aturan:
Kelangkaan field. Sebagian besar formulir lead menangkap 4-6 field. Sebagian besar record CRM memiliki lusinan field yang berpotensi relevan, banyak di antaranya kosong. Aturan memperlakukan field kosong sebagai netral. Model ML dapat belajar bahwa URL LinkedIn yang hilang dalam band ukuran perusahaan tertentu berkorelasi dengan close rate yang lebih rendah, karena itulah yang ditunjukkan data historis. Ketiadaan informasi itu sendiri adalah sinyal.
Waktu dan urutan. Lead yang mengunjungi halaman harga pada hari pertama dan mengisi formulir demo pada hari yang sama dikonversi secara berbeda dari lead yang mengunjungi halaman harga tiga minggu sebelum mengajukan formulir, lalu mengunjungi lagi sehari sebelumnya. Aturan dapat mendeteksi "kunjungan halaman harga = 25 poin," tetapi tidak menangkap kurva recency atau urutan perilaku. Model ML melakukannya.
Sinyal perubahan firmografis. Perusahaan yang baru saja merekrut VP of Sales adalah prospek yang secara fundamental berbeda dari perusahaan yang sama enam bulan lalu. Putaran pendanaan terbaru mengubah kapasitas pembelian. Peluncuran produk baru menciptakan kebutuhan teknologi. Aturan statis tidak menangkap sinyal dinamis ini. Model ML yang diberi makan data firmografis terbaru (dari sumber seperti LinkedIn, Clearbit, atau 6sense) dapat memperhitungkannya.
Interaksi multi-touch. Kombinasi "jabatan VP + halaman harga + sumber referral = saluran mitra" mungkin dikonversi pada tingkat 40%. Setiap elemen saja mungkin bernilai 10%. Aturan menilainya secara independen; ML menangkap efek interaksi.
Key Facts: AI Lead Scoring
- McKinsey mengidentifikasi kualifikasi lead sebagai salah satu use case AI dengan dampak tertinggi untuk tim penjualan B2B, karena penilaian yang lebih baik bersifat majemuk: lead yang lebih baik ditutup lebih sering, menghasilkan data pelatihan yang lebih baik untuk iterasi model berikutnya
- Minimum 200 deal closed-won diperlukan untuk model ML lead scoring yang dapat diandalkan; di bawah 100, sebagian besar alat komersial menghasilkan output yang secara statistik tidak dapat dibedakan dari penugasan acak
- Perusahaan yang menggunakan AI-assisted lead scoring melaporkan tingkat konversi lead ke peluang 10-20% lebih tinggi dibandingkan model berbasis aturan statis, menurut data pelanggan MadKudu dan 6sense (2022-2024)
Cara kerja ML lead scoring (tanpa gelar PhD)
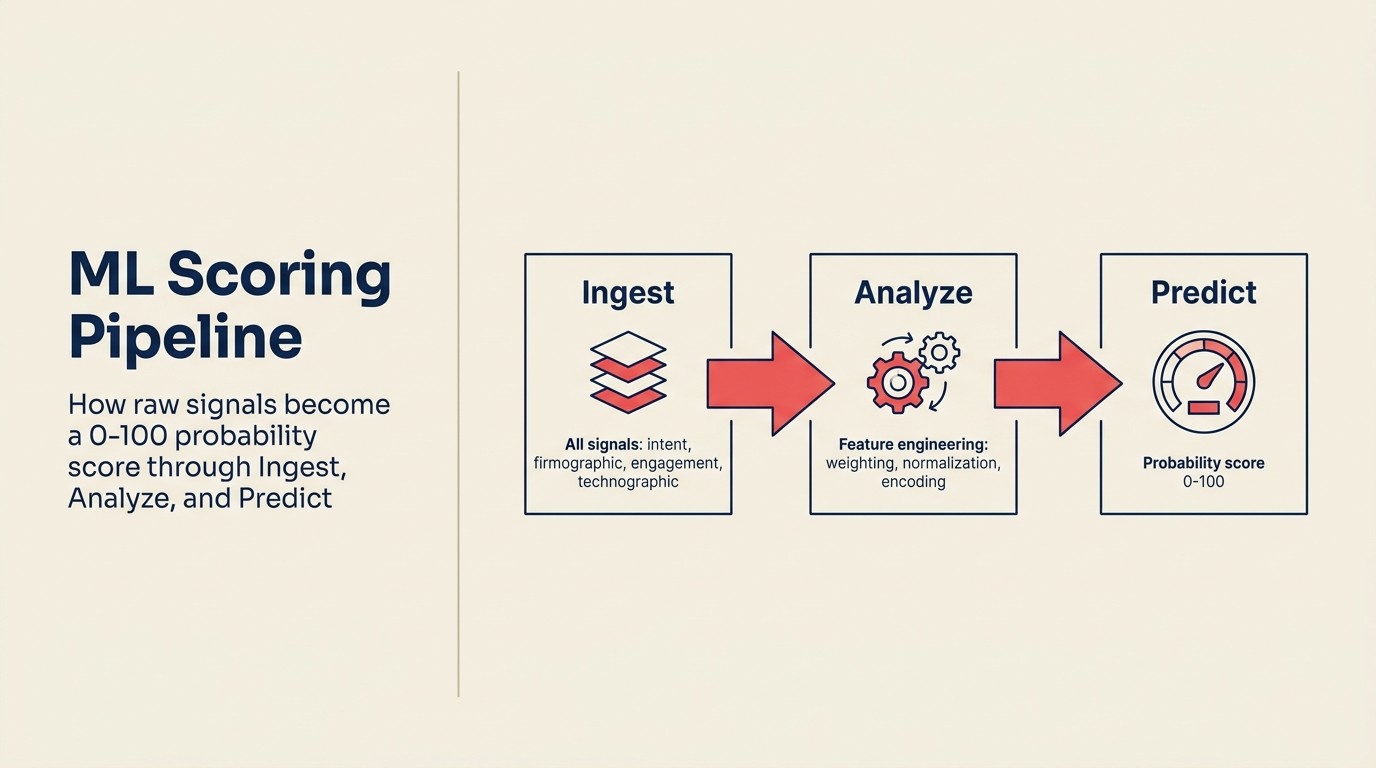
Mekanismenya lebih sederhana dari yang dibuat vendor terdengar. Inilah logika operasionalnya, menggunakan kosakata ACE Framework:
Ingest mengambil semua sinyal yang tersedia untuk setiap lead: field CRM (jabatan, ukuran perusahaan, industri, sumber), data perilaku (halaman yang dikunjungi, email yang dibuka, webinar yang dihadiri), pengayaan firmografis (band pendapatan, jumlah karyawan, tahap pendanaan, tech stack), dan data berbasis waktu (kapan aktivitas terjadi, kesenjangan di antaranya).
Analyze mengekstrak fitur dari data mentah tersebut. Fitur adalah variabel input yang sebenarnya dilatih model. Beberapa bersifat langsung (jabatan = "VP" → fitur biner). Beberapa direkayasa (hari antara kunjungan pertama dan pengajuan formulir → fitur numerik). Beberapa adalah term interaksi (ukuran perusahaan × frekuensi keterlibatan → sinyal komposit). Rekayasa fitur adalah tempat sebagian besar pekerjaan terjadi, dan tempat tim ops yang memahami data mereka sendiri memiliki keunggulan atas model out-of-box generik.
Predict melatih model pada data berlabel historis: deal yang ditutup (won) dan deal yang tidak (lost), bersama dengan semua fitur di atas. Di balik layar, sebagian besar alat penilaian lead komersial menggunakan regresi logistik atau gradient boosting, keduanya teknik ML yang dipahami dengan baik yang menghasilkan probabilitas antara 0 dan 1. Model mempelajari kombinasi fitur mana yang berkorelasi dengan hasil closed-won dalam basis pelanggan spesifik Anda dan menerapkan bobot yang dipelajari tersebut ke setiap lead baru, menghasilkan output probabilitas: lead ini memiliki 73% kemungkinan untuk dikonversi, berdasarkan apa yang kita ketahui tentangnya.
Hanya itu. Angka probabilitas dari 0 hingga 100, berdasarkan riwayat win/loss Anda sendiri, diperbarui saat deal baru ditutup. Loop rekalibrasi adalah yang memisahkan model yang bekerja dari yang perlahan menyimpang.
Standar Probabilistic Lead Score
Standar Probabilistic Lead Score mendefinisikan apa yang harus disertakan oleh AI lead score yang dapat dipertahankan: output probabilitas antara 0 dan 1 berdasarkan riwayat win/loss perusahaan sendiri, dilatih pada setidaknya 200 hasil closed-won, dikalibrasi ulang tidak kurang dari setiap kuartal terhadap hasil deal baru, dan diekspos ke rep dengan atribusi fitur (sinyal mana yang mendorong skor ini). Sistem penilaian mana pun yang gagal memenuhi salah satu dari empat kriteria ini lebih baik diklasifikasikan sebagai penilaian berbasis aturan yang ditingkatkan daripada penilaian ML sejati, karena outputnya tidak berdasarkan secara statistis pada pola konversi terukur.
Jenis sinyal yang diurutkan berdasarkan conversion lift

Tidak semua sinyal sama berguna. Berdasarkan pola dari penelitian MadKudu dan data buyer intent 6sense yang diterbitkan antara 2022 dan 2024, inilah cara kategori sinyal umumnya diurutkan dalam kontribusi lift untuk B2B SaaS:
| Jenis Sinyal | Contoh | Kontribusi Lift | Catatan |
|---|---|---|---|
| Sinyal intent | Kunjungan halaman harga, halaman perbandingan kompetitor, tampilan kategori G2 | Sangat Tinggi | Sinyal pembelian tahap akhir; recency penting (7 hari terakhir >> 30 hari terakhir) |
| Recency keterlibatan | Pembukaan email, kunjungan situs web dalam 14 hari terakhir, menghadiri webinar | Tinggi | Kurva recency penting: peluruhan eksponensial melewati 30 hari |
| Kecocokan firmografis | Ukuran perusahaan, vertikal industri, tahap pendanaan | Tinggi | Definisi ICP Anda yang dikodekan secara matematis |
| Kecocokan teknografis | Jenis CRM (Salesforce vs. HubSpot), integrasi yang diketahui, tech stack saat ini | Sedang-Tinggi | Lift terkuat ketika produk Anda menggantikan atau melengkapi alat tertentu |
| Pemicu berita | Pendanaan terbaru, pengumuman karyawan baru, peluncuran produk | Sedang | Sinyal kuat untuk cold outbound; kurang prediktif untuk inbound |
| Kecocokan tingkat kontak | Jabatan, senioritas, departemen | Sedang | Terkuat ketika digabungkan dengan kecocokan tingkat perusahaan, lebih lemah sendiri |
| Sumber lead | Pencarian organik, referral mitra, unduhan konten | Rendah-Sedang | Bervariasi secara dramatis per perusahaan; selalu uji daripada berasumsi |
| Perilaku formulir | Waktu pada formulir, field yang diisi, jenis perangkat | Rendah | Berguna sebagai tiebreaker; bukan sinyal utama |
Urutan bergeser berdasarkan produk dan pasar Anda. Untuk alat developer, kecocokan teknografis mungkin sinyal terkuat. Untuk produk layanan keuangan, band firmografis dan konteks regulasi mungkin mendominasi. Model mempelajari urutan spesifik perusahaan Anda dari data Anda; tabel di atas adalah hipotesis awal.
Daftar periksa kesiapan data sebelum menerapkan
Ini adalah langkah yang dilewati sebagian besar perusahaan. AI lead scoring tidak menghasilkan hasil yang baik dari data yang buruk. Sebelum membeli atau mengkonfigurasi alat penilaian ML apa pun, jalankan daftar periksa ini:
Persyaratan minimum:
- Setidaknya 6 bulan deal tertutup dengan pelabelan won/lost yang konsisten (12 bulan lebih baik)
- Setidaknya 200 deal closed-won total (lebih banyak lebih baik; di bawah 100 menghasilkan model yang tidak dapat diandalkan)
- Tahap deal CRM konsisten di seluruh tim (tidak ada variasi "Closed Won" vs. "Won" vs. "Closed")
- Sumber first-touch ditangkap pada setidaknya 70% record
- Nama perusahaan dan domain diisi pada 80%+ record
Sangat disarankan (meningkatkan kualitas model secara signifikan):
- Jabatan dan senioritas kontak ditangkap pada setidaknya 60% lead
- Ukuran perusahaan (jumlah karyawan) ditangkap atau dapat diperkaya untuk 70%+ record
- Data perilaku situs web (pelacakan HubSpot, Segment, atau setara) mengirimkan event ke CRM
- Setidaknya satu sumber pengayaan firmografis (Clearbit, Apollo, ZoomInfo) memberi makan CRM
Tanda peringatan yang menunjukkan pekerjaan data sebelum penilaian:
- Lebih dari 20% deal ditutup tanpa label hasil
- Tiga atau lebih nama tahap berbeda untuk posisi siklus hidup yang sama
- Kurang dari 6 bulan riwayat deal sejak migrasi CRM (data pra-migrasi sering tidak dapat diandalkan)
- Nol data pelacakan perilaku (tidak ada riwayat kunjungan halaman, tidak ada pelacakan pembukaan email)
Jika Anda tidak memiliki beberapa item dalam daftar minimum, habiskan empat hingga enam minggu untuk membersihkan data sebelum menerapkan penilaian. Model akan dibangun dari apa pun yang Anda masukkan.
Dari output model ke threshold routing
Model memberi Anda probabilitas. Anda masih perlu memutuskan apa yang harus dilakukan dengannya.
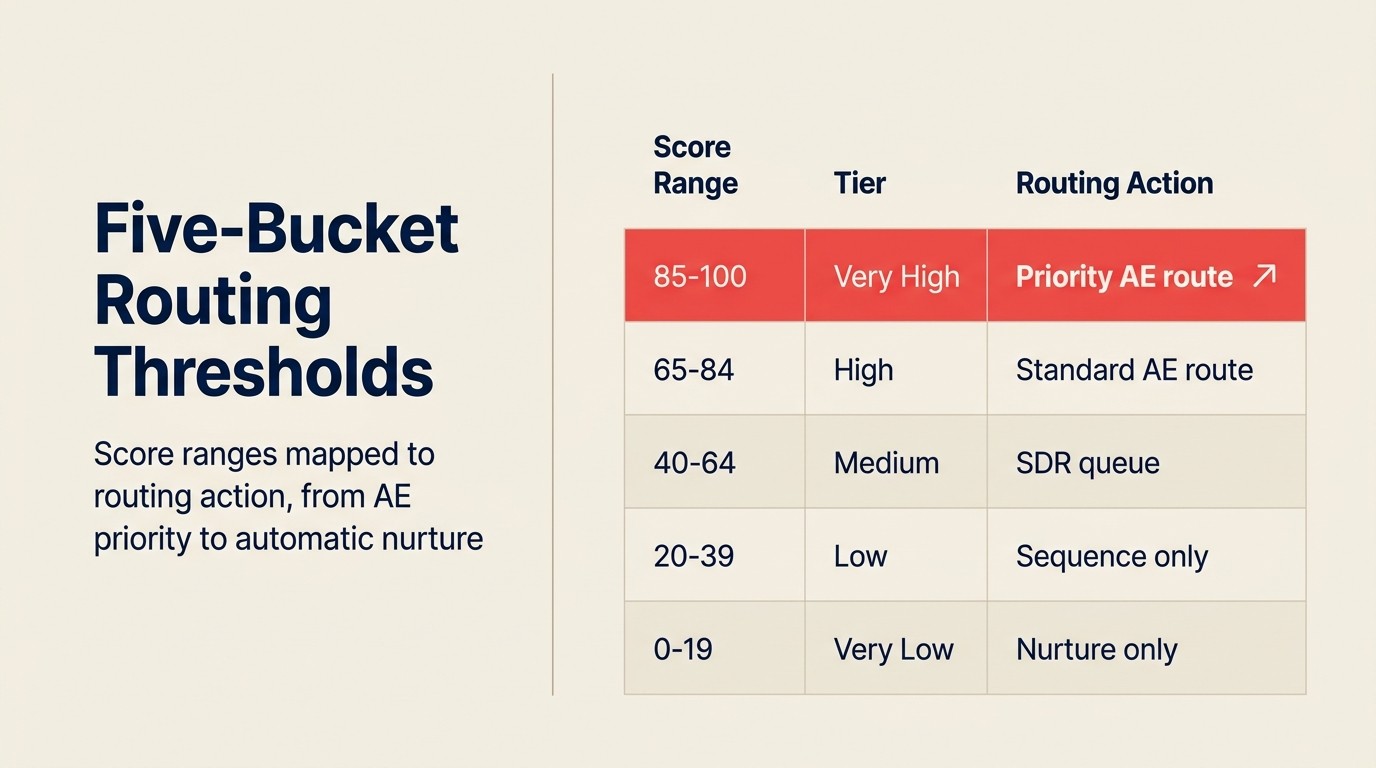
Sebagian besar penerapan mendefinisikan tiga hingga lima bucket dengan logika routing yang terlampir:
| Rentang Skor | Label | Tindakan Routing |
|---|---|---|
| 85-100% | Sangat Tinggi | Arahkan ke AE senior, notifikasi Slack segera, tanpa filter SDR |
| 65-84% | Tinggi | Arahkan ke antrian AE, SLA: hubungi dalam 2 jam |
| 40-64% | Sedang | Arahkan ke SDR untuk kualifikasi, daftarkan dalam urutan mid-touch |
| 20-39% | Rendah | Auto-enroll dalam urutan nurture, tidak ada penugasan rep |
| 0-19% | Sangat Rendah | Tidak ada tindakan; tambahkan ke daftar newsletter saja |
Angka threshold adalah milik Anda untuk ditetapkan, bukan milik vendor. Mereka harus mencerminkan: berapa banyak kapasitas rep yang Anda miliki (lebih banyak rep = threshold lebih rendah untuk penugasan langsung), seberapa sering Anda dapat mentolerir false positive (lead yang diberi skor tinggi yang ternyata salah = waktu rep yang terbuang), dan komitmen SLA kontak Anda saat ini.
Mendapatkan threshold yang tepat adalah latihan kalibrasi, bukan konfigurasi satu kali. Jalankan dengan threshold awal selama 60 hari, kemudian bandingkan: untuk setiap bucket, berapa tingkat konversi aktual? Jika bucket "Tinggi" Anda dikonversi pada 8% dan bucket "Sedang" dikonversi pada 12%, threshold Anda salah dikalibrasi. Sesuaikan dan amati lagi. Dan selalu awasi volume antrian: pergeseran threshold yang tiba-tiba mengirim 40% lead ke bucket "Tinggi" akan menghancurkan kepercayaan rep dalam beberapa minggu.
Mode kegagalan yang umum
Model yang dilatih pada data historis yang bias. Jika kemenangan historis Anda condong ke saluran tertentu (misalnya, 70% deal tertutup Anda berasal dari referral mitra), model akan belajar memberi skor lead yang bersumber dari mitra dengan tinggi. Ketika Anda berkembang ke saluran baru, model akan memberi skor lead tersebut dengan buruk. Bukan karena mereka lead yang buruk, tetapi karena tidak memiliki data pelatihan untuk pola tersebut. Perbaikan: latih ulang dengan data yang lebih luas, atau segmentasi model berdasarkan sumber.
Skor yang tidak ditampilkan kepada rep. Model menghasilkan output yang baik, tetapi itu berada di field CRM yang tidak dilihat siapa pun. Rep terus mengerjakan lead dalam urutan kedatangan. Ini adalah kegagalan adopsi, bukan kegagalan model. Perbaikan: tampilkan skor dalam alur kerja harian rep (notifikasi Slack, antrian CRM yang diurutkan berdasarkan skor) dan latih rep tentang arti skor sebelum go-live.
Tidak ada loop umpan balik untuk melatih ulang. Model dikonfigurasi pada bulan Januari dan tidak pernah disentuh lagi. Dua belas bulan kemudian, pasar telah bergeser, ICP telah berkembang, dan model masih mengoptimalkan untuk pola dari 18 bulan lalu. Perbaikan: bangun proses rekalibrasi kuartalan. RevOps lead meninjau metrik kinerja model (akurasi, presisi, recall per bucket) dan memicu pelatihan ulang ketika akurasi turun lebih dari 5 persentase poin.
Threshold yang ditetapkan dan dilupakan. Threshold awal ditetapkan saat go-live dan tidak pernah ditinjau. 90 hari kemudian, 40% dari semua lead mendapat skor "Tinggi" karena model belajar terlalu luas. Antrian "Tinggi" membanjiri rep dan kepercayaan runtuh. Perbaikan: tinjau distribusi threshold setiap bulan dan sesuaikan untuk mempertahankan volume antrian yang tepat untuk kapasitas rep.
Pembahasan lengkap tentang jebakan umum AI lead scoring.
Cuplikan vendor
Salesforce Einstein Lead Scoring termasuk dalam Sales Cloud Enterprise ke atas. Ia melatih pada data Salesforce Anda secara langsung, tanpa perlu mengekspor atau terhubung ke alat pihak ketiga. Model dikalibrasi ulang secara otomatis pada jadwal berkala. Kualitasnya kuat untuk perusahaan dengan data Salesforce yang bersih dan 12+ bulan riwayat. Konfigurasi terbatas untuk rekayasa fitur lanjutan atau sumber data khusus.
HubSpot Predictive Lead Scoring tersedia di Marketing Hub Professional/Enterprise dan Sales Hub Enterprise. Arsitektur serupa dengan Einstein: melatih pada data HubSpot, menghasilkan skor yang terlihat di pipeline HubSpot. Lebih lemah untuk perusahaan dengan data perilaku signifikan di luar HubSpot atau kebutuhan segmentasi firmografis yang kompleks.
MadKudu adalah platform penilaian B2B yang dibuat khusus yang terhubung ke Salesforce, HubSpot, dan beberapa sumber pengayaan data. Ia menampilkan kepentingan fitur (sinyal mana yang mendorong skor tertentu), membuatnya lebih mudah bagi RevOps untuk mengaudit dan mengkalibrasi. Terbaik untuk perusahaan yang menginginkan transparansi ke dalam logika model dan bersedia melakukan pekerjaan integrasi data.
6sense berfokus pada sinyal intent (identifikasi komite pembeli, pelacakan pengunjung anonim) lebih dari probabilitas konversi. Kekuatannya adalah prioritisasi akun mid-funnel, terutama untuk penjualan berbasis akun. Sering dilapisi di atas model penilaian CRM-native daripada menggantikannya.
Rework Sales AI menyertakan Scoring+Routing yang dibangun ke dalam CRM sebagai bagian dari arsitektur AI Sales Operator penuh. Skor dikalibrasi ulang dari hasil deal, diarahkan ke antrian rep secara otomatis, dan langsung masuk ke Workflow Copilot untuk draf tindak lanjut. Paling cocok untuk tim yang menginginkan penilaian terintegrasi tanpa mengelola hubungan vendor terpisah.
Rework Analysis: Kegagalan ML lead scoring yang paling umum kami lihat bukan model yang buruk. Ini adalah model yang baik yang tidak dikalibrasi ulang oleh siapa pun. Tim menerapkan pada Q1, melihat hasil yang kuat pada Q2, dan pada Q4 mereka bertanya-tanya mengapa lead "panas" tidak lagi ditutup. Model dilatih pada pasar yang ada 9 bulan lalu. ICP mereka bergeser setelah perubahan harga, kompetitor baru masuk, atau kasus penggunaan baru muncul. Rekalibrasi kuartalan bukan pemeliharaan opsional; ini adalah mekanisme yang menjaga output probabilitas terhubung dengan realitas saat ini. Tim yang membangun tinjauan rekalibrasi ke dalam kalender ops mereka dari hari pertama mempertahankan ROI 12-18 bulan. Mereka yang memperlakukan model sebagai instalasi satu kali biasanya melihat kinerja stagnan dalam 6 bulan.
Loop umpan balik adalah segalanya
Penilaian berbasis aturan adalah hipotesis: atribut ini harus memprediksi konversi. Anda menetapkannya sekali dan berharap itu bertahan dengan baik.
Penilaian ML adalah pengukuran: atribut ini memang memprediksi konversi, berdasarkan hasil aktual, diperbarui saat hasil baru tiba.
Tetapi "penilaian ML adalah pengukuran" hanya berlaku jika sistem pengukuran memiliki loop umpan balik. Tanpa rekalibrasi, model juga adalah hipotesis, hanya satu yang dilatih pada data alih-alih intuisi. Hipotesis yang menyimpang seiring perubahan kondisi pasar.
Penerapan yang menghasilkan ROI berkelanjutan adalah yang di mana RevOps memiliki loop umpan balik. Mereka melacak akurasi model setiap kuartal. Mereka melatih ulang ketika akurasi turun. Mereka mengaudit kinerja threshold setiap bulan. Mereka memperlakukan model penilaian sebagai infrastruktur, bukan proyek satu kali.
Kepemilikan operasional itulah yang memisahkan penerapan AI lead scoring yang terus meningkat dari yang menghasilkan hasil yang baik selama tiga bulan dan kemudian menjadi kebisingan latar belakang. Setelah model penilaian dikalibrasi dan memberi makan lead yang tepat ke rep yang tepat, pertanyaan selanjutnya adalah apa yang terjadi pada lead tersebut ketika mereka tiba.
Pertanyaan yang Sering Diajukan
Apa itu AI lead scoring?
AI lead scoring menggunakan model machine learning yang dilatih pada data CRM historis untuk memberikan setiap lead masuk skor probabilitas antara 0 dan 100. Alih-alih bobot poin yang ditetapkan manusia (penilaian berbasis aturan), model mempelajari kombinasi sinyal mana yang sebenarnya berkorelasi dengan hasil closed-won dalam basis pelanggan spesifik Anda dan menerapkan bobot yang dipelajari tersebut ke setiap lead baru. Skor diperbarui saat deal baru ditutup, membuatnya self-calibrating daripada statis.
Bagaimana AI lead scoring berbeda dari lead scoring berbasis aturan?
Penilaian berbasis aturan mengkodekan hipotesis manusia: "jabatan VP menambahkan 20 poin, kunjungan halaman harga menambahkan 25." AI scoring mengukur apa yang sebenarnya dikonversi: model menemukan kombinasi sinyal yang berkorelasi dengan deal yang dimenangkan dalam data historis Anda dan memberikan bobot yang sesuai. Perbedaan praktisnya adalah aturan tidak beradaptasi ketika ICP Anda berubah, tidak menangkap efek interaksi antar sinyal, dan tidak meningkat seiring waktu. Model AI melakukan ketiganya ketika dikalibrasi ulang dengan benar.
Data apa yang dibutuhkan model AI lead scoring untuk bekerja?
Persyaratan minimum adalah setidaknya 6 bulan deal tertutup dengan pelabelan won/lost yang konsisten (12 bulan lebih baik), setidaknya 200 deal closed-won total, definisi tahap CRM yang konsisten, sumber first-touch yang ditangkap pada 70%+ record, dan nama perusahaan/domain yang diisi pada 80%+ record. Model yang dilatih pada kurang dari 100 deal yang dimenangkan menghasilkan output yang secara statistik tidak dapat dibedakan dari penugasan acak.
Sinyal mana yang paling penting untuk B2B lead scoring?
Sinyal intent (kunjungan halaman harga, halaman perbandingan kompetitor, tampilan kategori G2) membawa conversion lift tertinggi karena menunjukkan perilaku pembelian tahap akhir. Recency keterlibatan mengikuti, dengan peluruhan eksponensial melewati 30 hari. Kecocokan firmografis (ukuran perusahaan, industri, tahap pendanaan) adalah kategori ketiga yang paling prediktif untuk sebagian besar produk B2B SaaS. Urutan spesifik bervariasi berdasarkan produk; model mempelajari urutan aktual perusahaan Anda dari data Anda.
Seberapa sering model AI lead scoring harus dikalibrasi ulang?
Rekalibrasi kuartalan adalah standar minimum. Pemilik RevOps harus meninjau akurasi model (presisi dan recall per bucket skor) setiap kuartal dan memicu pelatihan ulang ketika akurasi turun lebih dari 5 persentase poin dari baseline. ICP bergeser, saluran baru muncul, dan perubahan harga mengubah lead mana yang dikonversi. Model yang dilatih 9-12 bulan lalu tanpa rekalibrasi mungkin mengoptimalkan untuk pola yang tidak lagi mencerminkan pembeli saat ini.
Apa mode kegagalan AI lead scoring yang paling umum?
Empat kegagalan paling umum adalah: (1) model yang dilatih pada data historis yang bias (misalnya, 70% kemenangan dari satu saluran, membuat model buruk dalam menilai saluran lain); (2) skor yang tidak ditampilkan dalam alur kerja harian rep, sehingga rep mengabaikannya; (3) tidak ada proses rekalibrasi, menyebabkan akurasi menyimpang seiring perubahan pasar; dan (4) kesalahan kalibrasi threshold, di mana terlalu banyak lead mendapat skor "Tinggi" dan membanjiri kapasitas rep hingga kepercayaan pada sistem runtuh.
Tindakan routing apa yang harus dipicu oleh rentang skor yang berbeda?
Model routing lima bucket standar memetakan ke: 85-100% (langsung ke AE senior, notifikasi Slack segera), 65-84% (antrian AE, SLA kontak 2 jam), 40-64% (kualifikasi SDR, daftarkan dalam urutan mid-touch), 20-39% (nurture otomatis, tidak ada penugasan rep), dan 0-19% (newsletter saja). Threshold spesifik harus dikalibrasi ke kapasitas rep tim Anda dan ditinjau setiap bulan untuk mempertahankan volume antrian yang tepat untuk headcount Anda saat ini.
Pelajari Lebih Lanjut
- Apa Itu AI Sales Operator?
- Automated Lead Routing: Round Robin vs. AI-Driven
- Penyeimbangan Beban Kerja SDR dengan AI
- Jebakan Umum AI Lead Scoring
- Triase Lead Masuk dalam Skala Besar
- Mode Kegagalan: Ketika AI Sales Ops Berbalik
- Pola Scoring and Routing: Triase AI dalam Skala Besar
- Predict: Bagaimana AI Memprakirakan Hasil Bisnis

Co-Founder, Rework.com
On this page
- Apa yang terlewatkan oleh penilaian berbasis aturan
- Cara kerja ML lead scoring (tanpa gelar PhD)
- Standar Probabilistic Lead Score
- Jenis sinyal yang diurutkan berdasarkan conversion lift
- Daftar periksa kesiapan data sebelum menerapkan
- Dari output model ke threshold routing
- Mode kegagalan yang umum
- Cuplikan vendor
- Loop umpan balik adalah segalanya
- Pelajari Lebih Lanjut