Modos de Falha de AI em SaaS: O que Realmente Dá Errado (E o que Custa)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A maioria das falhas de AI em SaaS não é dramática. Não há indisponibilidade. Sem manchetes. O produto é lançado, a entrada no changelog é enviada, o comunicado de imprensa diz "estamos investindo muito em AI," e então nada óbvio acontece.
O que realmente acontece é mais silencioso. Os logs da funcionalidade de AI mostram 3% de uso ativo semanal no terceiro mês. Os CSMs (Customer Success Managers) param de abrir o dashboard de pontuação de saúde porque ela classificou muitas contas como "em risco" que não fizeram churn. O chatbot de suporte é silenciosamente desativado pelo cliente corporativo que foi prejudicado por uma resposta errada e escalou para o VP de CS. O conteúdo de SEO gerado por AI que parecia uma vitória de produtividade agora está acionando as políticas de spam do Google em páginas que antes ranqueavam.
A falha silenciosa é o modo dominante. E é mais cara do que a falha dramática porque você não sabe que está acontecendo até medir os efeitos downstream, o que a maioria das equipes não está fazendo.
Este artigo cobre seis modos específicos de falha em AI para SaaS, com o que realmente custam e o que os previne. Não é um framework genérico de risco de AI. É específico para as dinâmicas de receita do SaaS, as relações com compradores de SaaS e as ferramentas de AI que as empresas SaaS realmente implantam.
Os 6 SaaS AI Failure Modes
Os 6 SaaS AI Failure Modes é um framework diagnóstico que mapeia as formas mais comuns pelas quais as iniciativas de AI em SaaS falham em toda a superfície de falha. Mode 1 (Features Nobody Uses): ponto de inserção errado, qualidade abaixo do limiar de confiança ou falha de descoberta. Mode 2 (AI Content Hurts SEO): sem camada de contribuição original no conteúdo gerado por AI, conteúdo ralo acionando penalidades de qualidade do Google. Mode 3 (Wrong Outputs Drive Churn): outputs voltados para o cliente gerados por AI sem gates de revisão para cenários de alto risco. Mode 4 (Token-Cost Runaway): bundles de AI a preço fixo sem arquitetura de consumo, cauda de usuários avançados destruindo a economia unitária. Mode 5 (No-Moat Feature Match): funcionalidades de AI replicáveis pelos concorrentes em 4-8 semanas sem um telemetry loop criando durabilidade. Mode 6 (Support Burden AI): recomendações de AI abaixo do limiar de precisão, criando ruído que CSMs e agentes de suporte aprendem a ignorar. Os seis modos não têm igualmente a mesma probabilidade ou custo, mas todos os seis são evitáveis com medição antecipada.
Modo de Falha 1: Funcionalidades de AI que os clientes não usam
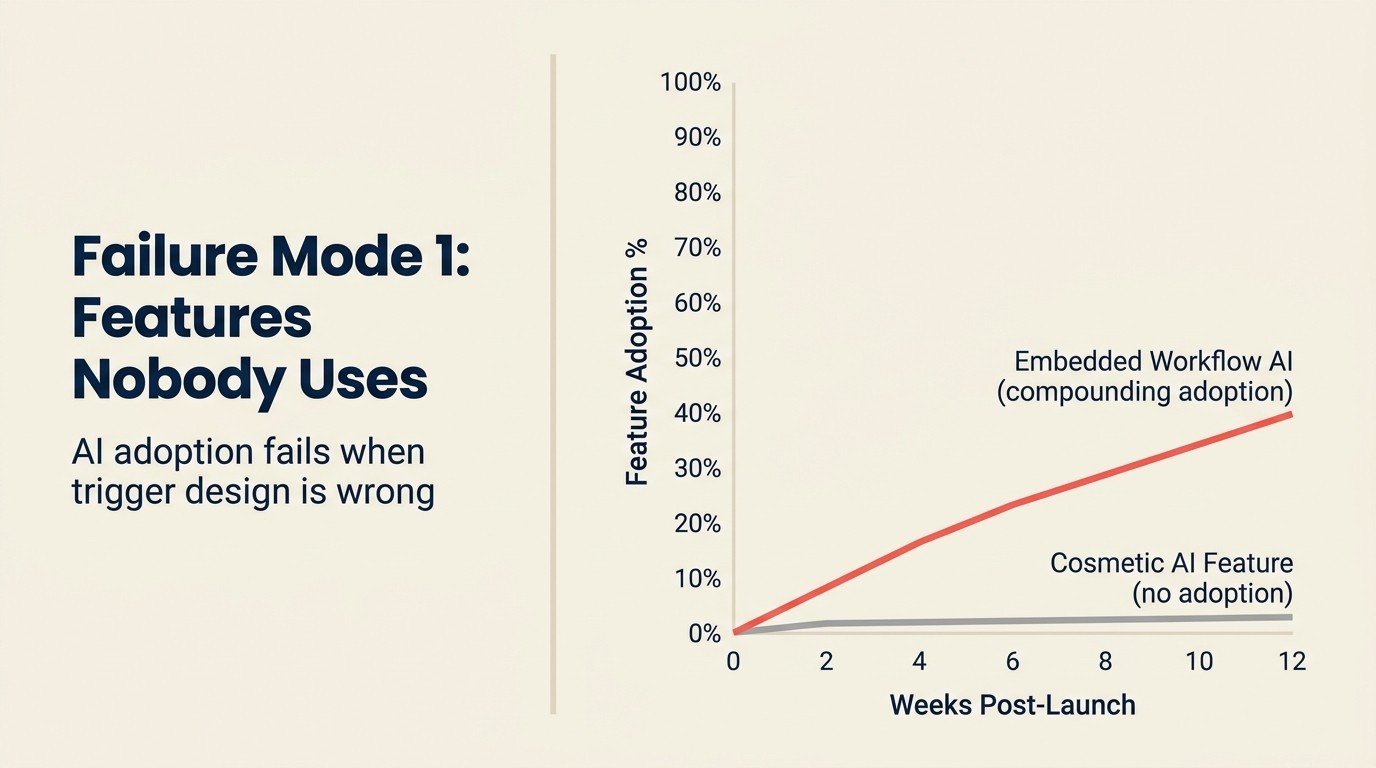
Você construiu. Você lançou. 3% dos usuários tocaram nela nos primeiros 30 dias, e agora é um item de linha no seu relatório anual sob "capacidades de AI" que nenhum cliente pagante realmente menciona.
Este é o modo de falha de AI em SaaS mais comum e o mais caro em termos de custo de oportunidade. Uma funcionalidade típica de copilot de AI no produto leva 3-4 meses de tempo de engenharia para construir adequadamente: integração de API, design de prompt, telemetria, interface. Com um custo combinado de engenharia de $250.000/ano, isso é $60.000-80.000 de investimento em engenharia. Se 3% dos usuários a usam, e nenhum deles a cita como motivo de renovação, você queimou $75.000 para adicionar uma funcionalidade à sua página de preços.
As causas raiz são específicas e diagnosticáveis. O Gartner descobriu que pelo menos 50% dos projetos de AI generativa são abandonados após a prova de conceito devido a baixa qualidade de dados, controles de risco inadequados, custos crescentes ou valor de negócio pouco claro, o que significa que a funcionalidade com adoção zero é a norma do setor, não a exceção.
Ponto de inserção errado: A AI apareceu em uma parte do fluxo de trabalho que o usuário visita duas vezes por semana, não dez vezes por dia. As sugestões de AI em fluxos de trabalho de baixa frequência não constroem o hábito necessário para a adoção. Os pontos de inserção de AI de maior valor estão nos fluxos de trabalho de maior frequência, não nos que parecem mais impressionantes. Funcionalidades de AI como produto: onde adicioná-las fornece o framework de seleção de três filtros para identificar os pontos de inserção corretos antes de construir.
Qualidade abaixo do limiar de confiança: A precisão das sugestões era de 60-70% nos testes internos, mas para os usuários parecia 40% porque as falhas eram mais memoráveis do que os sucessos. A qualidade de AI precisa exceder um limiar de confiança antes que os usuários confiem nela. Abaixo desse limiar, os usuários a experimentam uma vez, vivenciam uma falha e param. O limiar de confiança é mais alto do que a maioria das equipes de produto estima durante o desenvolvimento.
Falha de descoberta: Os usuários não sabem que a funcionalidade existe ou como acessá-la. Isso parece um problema de marketing, mas na verdade é um problema de design de produto. As funcionalidades de AI no produto que exigem que os usuários naveguem para uma seção separada, ou que aparecem apenas nos menus de configurações, serão invisíveis para a maioria dos usuários. A funcionalidade precisa surgir em contexto, no momento em que é relevante, sem exigir que o usuário a procure.
Prevenção: Meça os três indicadores líderes antes que a funcionalidade seja lançada: frequência esperada do ponto de inserção, limiar de qualidade de referência dos testes com usuários (não dos testes internos) e posicionamento de descoberta no fluxo do usuário. Se algum dos três for fraco, corrija-o antes do lançamento. Lançar mais rápido não ajuda se a funcionalidade nunca for adotada.
Key Facts: Taxas de Falha de AI em SaaS
- Pelo menos 50% dos projetos de AI generativa são abandonados após a prova de conceito devido a baixa qualidade de dados, controles de risco inadequados, custos crescentes ou valor de negócio pouco claro (Gartner, 2025)
- 60-70% das empresas enfrentam falha de pilot na implementação de AI; apenas 10-20% dos experimentos isolados de AI nos últimos dois anos escalaram para criar valor (MIT/McKinsey, 2025)
- Até 2028, os investimentos em observabilidade de LLM atingirão 50% das implantações de AI generativa especificamente porque alucinações, vieses e falhas de confiança exigirão infraestrutura de monitoramento que a maioria das empresas SaaS não está construindo hoje (Gartner, 2026)
Modo de Falha 2: Conteúdo gerado por AI que prejudica o SEO

Uma empresa SaaS descobre que pode multiplicar por 10 sua produção de conteúdo fazendo a AI escrever posts de blog, artigos da base de conhecimento e landing pages. Eles publicam 200 artigos gerados por AI em seis meses. Três meses depois, o tráfego orgânico de busca cai 35%.
Isso aconteceu. Continua acontecendo. E o custo não é apenas a queda no tráfego. É o prazo de recuperação: 12-18 meses para reconstruir a autoridade de domínio após uma penalidade de sinal de qualidade do Google, assumindo que você também removeu ou reformulou substancialmente o conteúdo que a acionou.
O mecanismo específico: o sistema de conteúdo útil do Google e as equipes de revisão manual sinalizam conteúdo ralo, gerado por AI, com baixo valor original. Páginas que não demonstram pesquisa original, expertise específica ou informações genuinamente úteis que não existem em outros lugares são desindexadas ou significativamente desvalorizadas. Um lote de 200 artigos gerados por AI sem pesquisa original, sem sinais de expertise do autor e sem dados únicos é exatamente o que esses sistemas foram projetados para penalizar.
O impacto em dólares: uma empresa SaaS com $5M de ARR rodando 30% da aquisição de clientes por busca orgânica pode estar gerando $500.000-700.000/ano em pipeline desse canal. Uma queda de 35% no tráfego orgânico se traduz em $175.000-245.000 de impacto anual no pipeline, além do custo do investimento na criação de conteúdo que produziu o problema.
Prevenção: O conteúdo gerado por AI requer uma camada editorial genuína antes da publicação. Não uma revisão gramatical. Uma camada de contribuição original: uma opinião específica de especialista adicionada, dados originais incluídos ou um exemplo concreto da experiência real do cliente. O conteúdo que não passa no teste "isso contém algo que não existia nos dados de treinamento?" não está pronto para publicar. Hallucination risk by pattern cobre as condições técnicas que tornam o conteúdo de AI não confiável e quais padrões são mais propensos a erros confiantes.
Para conteúdo técnico de base de conhecimento, o risco é menor porque a precisão importa mais do que a originalidade. Para conteúdo de blog no topo do funil competindo por palavras-chave competitivas, o conteúdo gerado por AI sem editorial é um passivo, não um ativo.
Modo de Falha 3: Churn impulsionado por AI devido a outputs errados
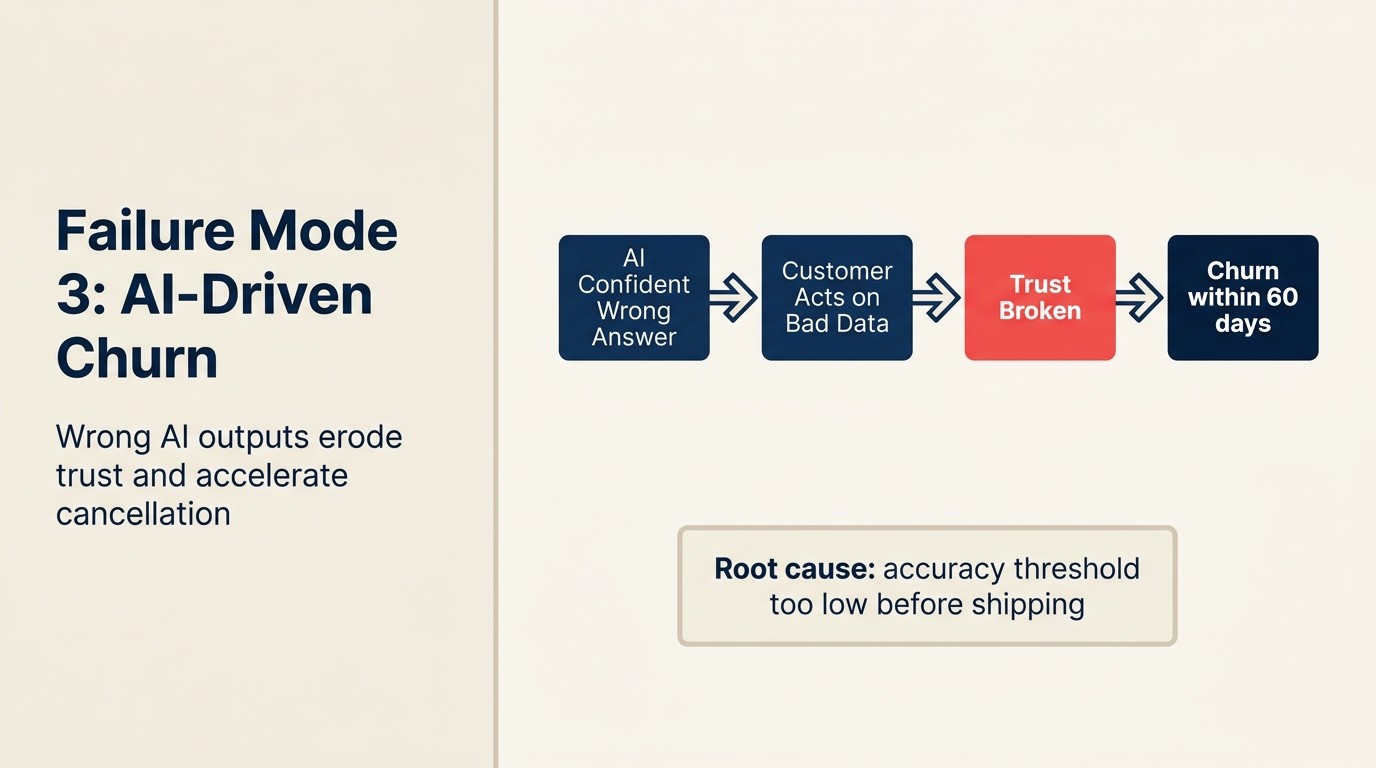
Uma empresa SaaS de mercado médio implanta um fluxo de onboarding impulsionado por AI para reduzir o tempo até o valor. A AI recomenda seções do produto com base no caso de uso declarado do usuário durante o cadastro. Durante três meses, isso funciona bem.
Então um lote de cadastros corporativos aciona um bug na lógica de segmentação. A AI encaminha 40 sessões de onboarding corporativo para um fluxo de trabalho projetado para pequenas equipes. Esses usuários experimentam um onboarding que parece irrelevante e confuso. Os tickets de suporte disparam. 11 das 40 contas solicitam reembolsos ou não convertem do trial. O impacto de receita é $180.000 em ARR que não fechou.
Este é o churn impulsionado por AI: um caso em que o output da AI prejudicou ativamente um relacionamento com o cliente em vez de ajudá-lo. É diferente de um bug de software padrão porque o dano não é "a funcionalidade não funcionou." É "a AI forneceu ao cliente informações erradas ou uma experiência errada, e o cliente agora duvida se o seu produto entende o caso de uso dele."
O padrão de falha se repete na pontuação de saúde. A pontuação de saúde de AI de uma ferramenta de CS classifica uma conta corporativa que está fazendo churn como "verde" por três meses. O CSM, confiando na pontuação, não intervém com a frequência normal de check-ins. A conta faz churn na renovação. A autópsia mostra que a pontuação de saúde estava ponderando o uso do produto acima do sentimento dos tickets de suporte, e a conta tinha alto uso e alta frustração simultaneamente.
A versão do chatbot de suporte: um chatbot de AI fornece uma resposta errada sobre capacidades de exportação de dados para um prospecto em trial, que estava especificamente avaliando o produto para essa funcionalidade. O prospecto seleciona um concorrente. Ninguém sabe que isso aconteceu porque a conversa do chatbot não é revisada. A McKinsey identifica preocupações com riscos e excedentes de custos como as principais razões pelas quais as iniciativas de AI falham em cruzar do protótipo para a produção, e apenas 10 a 20% dos experimentos isolados de AI nos últimos dois anos escalaram para criar valor, que é o contexto em que esses modos de falha específicos de SaaS ocorrem.
Prevenção: Toda funcionalidade de AI que gera outputs voltados para o cliente precisa de um gate de revisão humana para cenários de alto risco. Não um gate em todo output, mas um gate definido por nível de impacto. Os outputs de AI de baixo risco (sugestões de rascunho, resumos internos) podem ser aplicados automaticamente. Os outputs de alto risco (roteamento de onboarding, cotações de preços, afirmações de disponibilidade de funcionalidades, alertas de pontuação de saúde que acionam mudanças de comportamento dos CSMs) precisam de um mecanismo de revisão antes de afetar os clientes.
Defina "alto risco" explicitamente antes de implantar. É uma decisão de produto, não uma decisão de infraestrutura. The generate vs. execute boundary explica o princípio do ACE Framework para quando o output de AI deve requerer aprovação humana antes de executar.
Modo de Falha 4: Explosão de custos de tokens
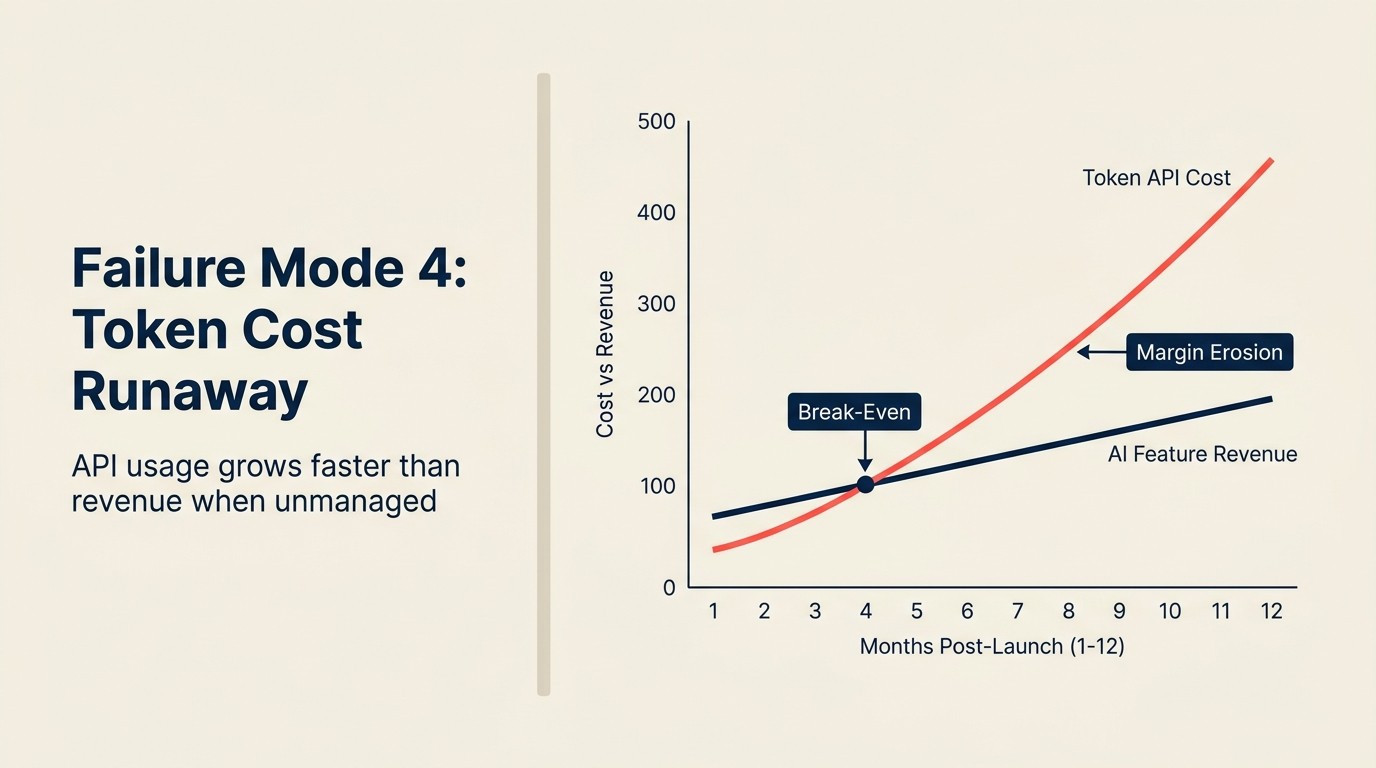
Uma empresa SaaS lança um assistente de escrita com AI como parte de um plano de $49/mês com geração de AI ilimitada. Os testes internos mostram que 95% dos usuários geram 50-100 outputs por mês. A modelagem diz que os custos de API rodarão a $0,80-1,20 por usuário por mês. A funcionalidade é lançada.
Seis meses depois, três clientes corporativos usando o produto para operações de conteúdo em larga escala estão cada um executando 8.000-12.000 solicitações de geração de AI por mês. A $0,80/solicitação em média, isso é $6.400-9.600 por cliente por mês em custos de API, para clientes pagando $49/mês. A equipe de produto não modelou o usuário no percentil 99. Modelou o usuário mediano.
O impacto trimestral total: três clientes criando uma responsabilidade de custo de API de $72.000-84.000 contra $441 em MRR (monthly recurring revenue) combinado. A empresa agora está pagando para ter esses clientes usando o produto.
Isso não é hipotético. Esse padrão ocorreu em múltiplos produtos SaaS durante 2023-2024, quando as equipes precificaram funcionalidades de AI de forma plana sem arquitetura de consumo. A modelagem do usuário mediano parece boa. A cauda de usuários avançados destrói a economia unitária.
A matemática: o GPT-4o da OpenAI cobra $2,50/M de tokens de entrada e $10/M de tokens de saída. Uma única solicitação de escrita de AI com 3.000 tokens de contexto e 800 tokens de saída custa $0,0155. Isso é barato por solicitação. Mas um usuário executando 500 solicitações por dia custa $7,75/dia, ou $232/mês em custos de API. Se esse usuário está em um plano de $99/mês, você está pagando $133/mês para ele usar seu produto.
Prevenção: Três decisões de arquitetura necessárias antes de lançar qualquer funcionalidade de AI em um plano de preço fixo:
- Limites de consumo por usuário por tier: O tier gratuito recebe 100 ações de AI/mês. O Starter recebe 500. O Professional recebe 2.000. O Enterprise negocia personalizadamente. Limites rígidos, não limites suaves.
- Monitoramento de uso com alertas automáticos: Quando qualquer conta exceder 150% do consumo modelado do tier, o sistema gera um alerta para revisão. Não apenas por razões de faturamento, mas porque padrões de uso anômalos frequentemente indicam um problema de qualidade de dados ou comportamento do usuário que está usando a AI de forma não intencional.
- Precificação baseada em custo para corporativo: Clientes corporativos com alto uso esperado devem ter precificação baseada em consumo ou precificação em tiers com custos claros de excedente. Um cliente que gerará $2.000/mês em custos de API não deve estar em um contrato fixo de $500/mês.
Modo de Falha 5: Funcionalidade de AI igualada por um concorrente em 30 dias
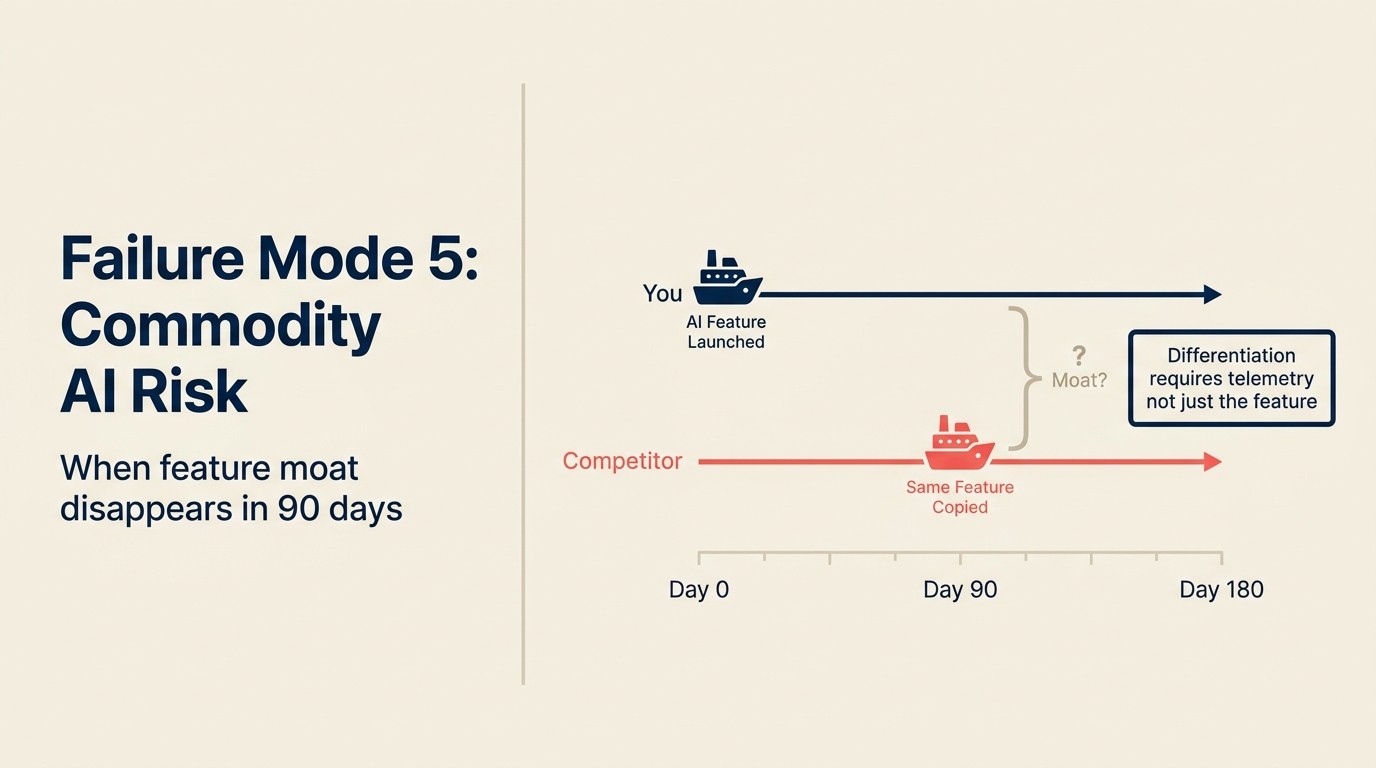
Uma empresa SaaS lança uma funcionalidade de AI de sumarização de contratos que sua equipe de vendas usa para acelerar as revisões de negócios. Leva 4 meses para construir. No lançamento, é um diferenciador: nenhum concorrente oferece isso no produto. A equipe o comercializa com destaque.
Seis semanas após o lançamento, dois concorrentes lançam funcionalidades equivalentes. Um faz wrap diretamente do Claude. O outro integra uma ferramenta de AI de contratos de terceiros. Ambos estão ativos em 30 dias um do outro. O fosso competitivo que a empresa construiu ao longo de 4 meses tem uma vida útil de 8 semanas.
Este é o modo de falha sem fosso: lançar uma funcionalidade de AI que cria um diferenciador temporário, mas não cria uma vantagem estrutural porque é replicável por qualquer concorrente com uma assinatura de API de LLM e algumas semanas de tempo de engenharia.
A maioria das funcionalidades de AI construídas em APIs de LLM genéricas é replicável em 4-8 semanas por uma equipe de engenharia concorrente competente. A diferenciação da própria funcionalidade é real, mas temporária. A única diferenciação durável é (a) dados: sua versão é melhor porque é treinada no comportamento real dos seus usuários, ou (b) profundidade de integração: sua versão é melhor porque está tão profundamente incorporada no fluxo de trabalho que a migração exige reaprender tudo. Telemetry loops para AI no produto explica como construir o flywheel de dados que cria a opção (a).
O custo: 4 meses de tempo de engenharia para construir uma funcionalidade que diferencia por 8 semanas. Com um custo de engenharia carregado de $250.000/ano, são aproximadamente $83.000 investidos por 2 meses de diferenciação competitiva. A matemática de ROI requer que as 8 semanas de diferenciação tenham impulsionado taxas de vitória significativamente melhores, o que tipicamente não é mensurável.
Prevenção: Antes de construir qualquer funcionalidade de AI que levará mais de 6 semanas de engenharia, responda à pergunta: "Em 90 dias, quando dois concorrentes tiverem lançado funcionalidade equivalente, o que torna nossa versão significativamente melhor?" Se a resposta não for uma de (fosso de dados, profundidade de integração, qualidade do telemetry loop), você deveria fazer wrap da funcionalidade de forma mais rápida e barata, ou investir o tempo de engenharia em funcionalidades que criam fossos duráveis.
Modo de Falha 6: Funcionalidade de AI cria um ônus de suporte
Uma empresa SaaS lança uma funcionalidade de pontuação de prioridade de AI para sua ferramenta de gestão de projetos. A AI atribui pontuações de prioridade às tarefas e surfaceia os itens de maior prioridade em um email de resumo diário. Isso parece útil e nos testes internos, a equipe adora.
Em produção, 40% dos usuários acham as sugestões de prioridade da AI erradas para seu contexto. A AI não entende a definição de prioridade da equipe, que é influenciada por prazos, relações com as partes interessadas e contexto que não é capturado nos metadados das tarefas. Os usuários começam a criar tickets de suporte: "Por que a AI está dizendo que X é alta prioridade quando claramente não é?" A equipe de suporte agora está gastando tempo explicando o comportamento da AI que não compreende totalmente.
O volume de tickets de suporte para a funcionalidade de AI no primeiro mês: 180 tickets. O custo de suporte a $12/ticket totalmente carregado: $2.160. Mensalmente. Para uma funcionalidade que deveria reduzir a carga cognitiva.
A falha se compõe: usuários que abrem tickets de suporte de AI têm mais probabilidade de fazer churn do que usuários que não abrem. Não porque a funcionalidade de AI falhou, mas porque a interação de suporte criou uma narrativa: "A AI deste produto não entende o meu contexto." Essa narrativa se anexa ao produto, não apenas à funcionalidade.
O mesmo padrão aparece nas ferramentas de AI de CS. Um sistema de pontuação de saúde dispara 50 alertas de "em risco" por semana, 60% dos quais acabam sendo falsos positivos após investigação do CSM. Após quatro semanas, os CSMs começam a ignorar os alertas sem verificar. Quando contas realmente em risco aparecem na fila, são ignoradas junto com os falsos positivos. Você pagou por um sistema de pontuação de saúde que sua equipe de CS depreciou mentalmente.
Prevenção: Duas métricas que devem estar no verde antes que qualquer recomendação gerada por AI seja lançada para os clientes:
- Precisão: Das vezes que a AI sinaliza algo (em risco, alta prioridade, ação recomendada), qual porcentagem está correta? Se a precisão for abaixo de 70%, a funcionalidade cria mais ruído do que sinal. A maioria dos usuários aprenderá a ignorá-la.
- Loop de feedback para correções: Os usuários precisam ser capazes de dizer à AI que ela estava errada, e esse feedback precisa realmente mudar o comportamento da AI. Uma funcionalidade de AI sem mecanismo de correção treina os usuários a ver a AI como uma caixa preta com a qual não se pode raciocinar. Essa percepção mata a confiança mais rápido do que qualquer resposta errada individual.
A versão de pontuação de saúde de CS disso: não alerte em toda conta que cai abaixo de um limiar. Alerte em contas que caem inesperadamente em relação à sua trajetória recente. Menos alertas, maior precisão, confiança do CSM mantida.
"A falha silenciosa é o modo dominante em AI para SaaS. O produto é lançado, o changelog é enviado, o comunicado de imprensa diz 'estamos investindo muito em AI,' e então nada óbvio acontece. Os logs da funcionalidade de AI mostram 3% de uso ativo semanal no terceiro mês. O chatbot de suporte é silenciosamente desativado pelo cliente corporativo que foi prejudicado por uma resposta errada. A AI de pontuação de saúde está sendo ignorada pelos CSMs que viram alertas falsos positivos demais." (Rework Analysis, 2025)
"Uma funcionalidade típica de copilot de AI no produto leva 3-4 meses de tempo de engenharia para construir adequadamente. Com um custo combinado de engenharia de $250.000/ano, isso é $60.000-80.000 de investimento. Se 3% dos usuários a usam e nenhum a cita como motivo de renovação, a equipe queimou $75.000 para adicionar uma funcionalidade à página de preços." (Rework Analysis, baseado na análise de custo de projeto de AI generativa do Gartner, 2025)
"O volume de tickets de suporte para uma funcionalidade de AI com precisão abaixo do limiar: 180 tickets por mês, a $12/ticket totalmente carregado, é $2.160 por mês em custos de suporte para uma funcionalidade que deveria reduzir a carga cognitiva. A falha se compõe: usuários que abrem tickets de suporte de AI têm mais probabilidade de fazer churn do que usuários que não abrem, porque a interação de suporte cria uma narrativa do produto que se anexa ao produto inteiro." (Rework Analysis, 2025)
"Três clientes corporativos usando um assistente de escrita com AI a preço fixo em 8.000-12.000 solicitações de geração por mês cada, pagando $49/mês, criam uma responsabilidade de custo de API de $72.000-84.000 por trimestre contra $441 em MRR combinado. A empresa agora está pagando para ter esses clientes usando o produto. Isso não é hipotético." (Rework Analysis, baseado em preços da OpenAI e incidentes documentados de custo de tokens em SaaS, 2025)
Checklist de Prevenção dos Modos de Falha de AI em SaaS

| Modo de Falha | Sinal de Alerta Precoce | Janela de Detecção | Prevenção |
|---|---|---|---|
| Funcionalidades que ninguém usa | WAU (usuários ativos semanais) de 90 dias abaixo de 10% | Dia 30-60 | Validar ponto de inserção antes de construir |
| Conteúdo de AI prejudica SEO | Queda de tráfego orgânico 3 meses após publicação | 90-120 dias | Camada de contribuição original em todo conteúdo de AI |
| Outputs errados impulsionam churn | Pico de suporte ou solicitações de reembolso de usuários afetados por AI | 30-90 dias | Gate de revisão humana para outputs de AI de alto risco |
| Explosão de custos de tokens | Custo de API mensal excede 50% da receita do plano para qualquer conta | 30-60 dias | Caps de consumo por usuário antes do lançamento |
| Funcionalidade igualada sem fosso | Concorrente lança equivalente em 60 dias | 6-12 semanas | Telemetry loop no lançamento; profundidade de integração |
| AI que cria ônus de suporte | Tickets de suporte para funcionalidade de AI; taxa de ignorar alertas do CSM acima de 30% | 30-60 dias | Limiar de precisão acima de 70% antes de lançar |
Fontes: Gartner GenAI Project Failure Analysis 2025, McKinsey AI Risk and Cost Research 2025, Gartner LLM Observability Predictions 2026
"Até 2028, os investimentos em observabilidade de LLM atingirão 50% das implantações de AI generativa especificamente porque alucinações, vieses e falhas de confiança exigirão infraestrutura de monitoramento que a maioria das empresas SaaS não está construindo hoje. Equipes que começam essa instrumentação agora estarão à frente da curva de conformidade e de expectativas dos clientes." (Gartner, 2026)
Rework Analysis: O padrão em todos os seis modos de falha é disciplina de medição, não sofisticação tecnológica. Todo modo de falha documentado aqui é visível nos dados antes de se tornar caro, se você estiver olhando. As equipes que implantam AI, declaram vitória com base no anúncio do lançamento e não medem nada por seis meses são as que descobrem o Mode 1 no mês 6 quando os dados de uso contam uma história que o changelog não contou. O checklist de prevenção de falhas não é governança opcional. É o hábito operacional que separa os investimentos em AI que se compõem dos que se depreciam.
Como é a prevenção de falhas na prática
O padrão em todos os seis modos de falha é disciplina de medição, não sofisticação tecnológica. Todo modo de falha descrito aqui é visível nos dados antes de se tornar caro, se você estiver olhando.
Um checklist de prevenção de falhas antes de implantar qualquer funcionalidade de AI:
A medição de linha de base está implementada: Você conhece a métrica que essa funcionalidade deveria melhorar, e tem a linha de base pré-AI documentada. Se você implantar coaching de chamadas de AI sem registrar como é "boa qualidade de descoberta" antes da AI, você não consegue medir se funcionou.
O rastreamento de adoção está ativo: Usuários ativos semanais, taxa de aceitação e taxa de modificação estão em um dashboard que alguém revisa semanalmente. 3% de adoção no dia 30 é recuperável. 3% de adoção no dia 90 é uma funcionalidade que você está pagando para manter.
As proteções de consumo estão construídas: Toda funcionalidade de AI em um plano de preço fixo tem limites por usuário e monitoramento de uso antes de ser lançada, não após o primeiro ciclo de faturamento anômalo.
Os caminhos de escalação existem: Toda funcionalidade de AI que toca um output voltado para o cliente tem um caminho definido para o cliente escalar quando a AI está errada. Preferencialmente, essa escalação é tratada por um humano, não por outra AI.
A precisão é medida e tem limiar definido: Para qualquer funcionalidade de AI que gera alertas ou recomendações, a precisão é rastreada. A funcionalidade não é lançada sem um limiar mínimo de precisão definido e testado.
O sinal de confiança é rastreado: Mensalmente, verifique se os usuários que se engajam com suas funcionalidades de AI têm NPS (Net Promoter Score) e taxas de churn mais altos ou mais baixos do que usuários que não se engajam. Se o engajamento com funcionalidades de AI se correlaciona com churn mais alto, você tem um problema de confiança, e ele precisa ser diagnosticado antes que a funcionalidade escale.
A falha de AI em SaaS é sobrevivível se detectada cedo. Os seis modos de falha descritos aqui são todos mensuráveis nos primeiros 60-90 dias se você estiver rastreando os sinais certos. As empresas que entram em sérios problemas são as que implantam AI, declaram vitória com base no anúncio do lançamento e não medem nada por seis meses. O Gartner prevê que até 2028, os investimentos em observabilidade de LLM atingirão 50% das implantações de AI generativa especificamente porque alucinações, vieses e falhas de confiança exigirão infraestrutura de monitoramento que a maioria das empresas SaaS não está construindo hoje, e as equipes que iniciam essa instrumentação cedo estarão à frente da curva de conformidade e de expectativas dos clientes.
Não declare vitória antes que a telemetria comprove.
Saiba Mais:
- Por que a Maioria das Transformações de AI Falha: os padrões de falha em nível de estratégia que criam as condições para todos os seis modos
- Hallucination Risk by Pattern: as condições técnicas que produzem erros confiantes de AI por tipo de padrão
- Generate vs. Execute Boundary: o princípio do ACE Framework para quando a AI precisa de aprovação humana antes de agir
- AI Anti-Patterns: o catálogo mais amplo de falhas em nível de padrão que complementa os modos de falha específicos de SaaS
- Telemetry Loops para AI no Produto: infraestrutura de medição que captura falhas no dia 30, não no mês 6
- A Corrida Armamentista de AI em SaaS: Velocidade para Lançar: pressão competitiva que cria as condições para lançar sem gates de qualidade
- Os Estágios de Maturidade de AI em SaaS: onde esses modos de falha se agrupam por estágio de maturidade
- Por que os Frameworks de AI Falham: os padrões de falha fundamentais que as falhas de AI em SaaS frequentemente remontam a

Co-Founder, Rework.com
On this page
- Os 6 SaaS AI Failure Modes
- Modo de Falha 1: Funcionalidades de AI que os clientes não usam
- Modo de Falha 2: Conteúdo gerado por AI que prejudica o SEO
- Modo de Falha 3: Churn impulsionado por AI devido a outputs errados
- Modo de Falha 4: Explosão de custos de tokens
- Modo de Falha 5: Funcionalidade de AI igualada por um concorrente em 30 dias
- Modo de Falha 6: Funcionalidade de AI cria um ônus de suporte
- Checklist de Prevenção dos Modos de Falha de AI em SaaS
- Como é a prevenção de falhas na prática