SaaS-KI-Misserfolgsmodi: Was wirklich schiefläuft (und was es kostet)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die meisten SaaS-KI-Misserfolge sind nicht dramatisch. Es gibt keinen Ausfall. Keine Schlagzeile. Das Produkt wird geshippt, der Changelog-Eintrag geht raus, die Pressemitteilung sagt „wir investieren stark in KI", und dann passiert nichts Offensichtliches.
Was tatsächlich passiert, ist stiller. Die KI-Feature-Protokolle zeigen 3 % wöchentliche aktive Nutzung in Monat drei. CSMs (Customer Success Manager) hören auf, das Health-Score-Dashboard zu öffnen, weil es zu viele Konten als „at-risk" bezeichnet hat, die nicht gewandert sind. Der Support-Chatbot wurde vom Enterprise-Kunden still deaktiviert, der von einer falschen Antwort verbrannt wurde und zu Ihrem VP of CS eskaliert hat. Der KI-generierte SEO-Content, der wie eine Produktivitätsverbesserung aussah, löst jetzt Googles Spam-Richtlinien auf Seiten aus, die früher rankten.
Stilles Scheitern ist der dominante Modus. Und es ist teurer als dramatisches Scheitern, weil Sie nicht wissen, dass es passiert, bis Sie die nachgelagerten Effekte messen, was die meisten Teams nicht tun.
Dieser Artikel behandelt sechs spezifische Misserfolgsmodi in SaaS-KI, mit dem, was sie tatsächlich kosten und was sie verhindert. Es ist kein generisches KI-Risikoframework. Es ist spezifisch für SaaS-Umsatzdynamik, SaaS-Käuferbeziehungen und die KI-Tools, die SaaS-Unternehmen tatsächlich einsetzen.
Die 6 SaaS-KI-Misserfolgsmodi
Die 6 SaaS-KI-Misserfolgsmodi sind ein diagnostisches Framework, das die häufigsten Arten kartiert, wie SaaS-KI-Initiativen über die gesamte Misserfolgsoberfläche hinweg scheitern. Modus 1 (Features, die niemand nutzt): falscher Einfügepunkt, Qualität unter Vertrauensschwelle oder Discovery-Fehler. Modus 2 (KI-Content schadet SEO): keine Original-Beitrags-Schicht auf KI-generiertem Content, dünner Content löst Googles Qualitätsstrafen aus. Modus 3 (Falsche Outputs treiben Churn): KI-generierte kundenzugewandte Outputs ohne Review-Gates für hochriskante Szenarien. Modus 4 (Token-Kosten-Runaway): Pauschalpreis-KI-Bundles ohne Verbrauchsarchitektur, Power-User-Tail zerstört Unit-Economics. Modus 5 (No-Moat Feature Match): KI-Features, die von Wettbewerbern in 4-8 Wochen ohne Telemetrie-Loop replizierbar sind. Modus 6 (Support-Burden-KI): KI-Empfehlungen unter Präzisionsschwelle, erzeugen Rauschen, das CSMs und Support-Agenten lernen zu ignorieren. Die sechs Modi sind nicht gleich wahrscheinlich oder gleich kostspielig, aber alle sechs sind mit früher Messung vermeidbar.
Misserfolgsmodus 1: KI-Features, die Kunden nicht nutzen
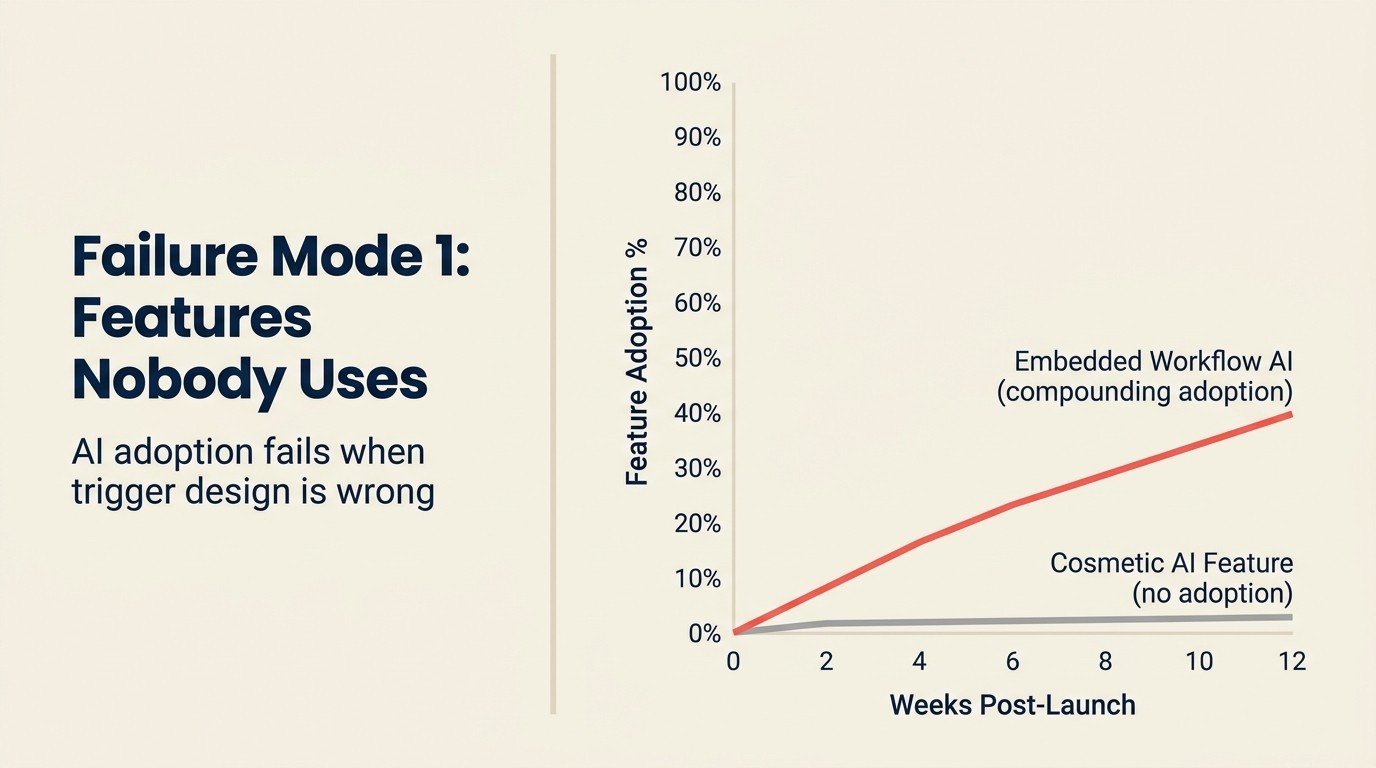
Sie haben es gebaut. Sie haben es geshippt. 3 % der Nutzer haben es in den ersten 30 Tagen berührt, und jetzt ist es eine Zeile in Ihrem Jahresbericht unter „KI-Fähigkeiten", die kein zahlender Kunde tatsächlich erwähnt.
Das ist der häufigste SaaS-KI-Misserfolg und der teuerste in Opportunitätskostenrechnung. Ein typisches In-Produkt-KI-Copilot-Feature braucht 3-4 Monate Engineering-Zeit, um es richtig zu bauen: API-Integration, Prompt-Design, Telemetrie, UI. Bei 250.000 $/Jahr gemischter Engineering-Kosten sind das 60.000-80.000 $ Engineering-Investition. Wenn 3 % der Nutzer es nutzen und keiner es als Grund für die Verlängerung angibt, haben Sie $75,000 verbrannt, um ein Feature auf Ihrer Preisseite hinzuzufügen.
Die Ursachen sind spezifisch und diagnostizierbar. Gartner stellte fest, dass mindestens 50 % der generativen KI-Projekte nach dem Proof of Concept aufgegeben werden aufgrund schlechter Datenqualität, unzureichender Risikokontrolle, eskalierender Kosten oder unklarem Geschäftswert, was bedeutet, dass das Zero-Adoption-Feature die Branchennorm ist, nicht die Ausnahme.
Falscher Einfügepunkt: Die KI erschien in einem Teil des Workflows, den der Nutzer zweimal pro Woche besucht, nicht zehnmal täglich. KI-Vorschläge in Workflows mit geringer Häufigkeit bauen nicht die für Adoption erforderliche Gewohnheit auf. Die hochwertigsten KI-Einfügepunkte sind in den hochfrequentesten Workflows, nicht in den eindrucksvollsten. KI-Features als Produkt: Wo man sie hinzufügt bietet das Drei-Filter-Auswahlframework zur Identifizierung der richtigen Einfügepunkte vor dem Bauen.
Qualität unter der Vertrauensschwelle: Die Vorschlags-Genauigkeit war in internen Tests 60-70 %, fühlte sich aber für Nutzer wie 40 % an, weil die Fehler einprägsamer waren als die Erfolge. KI-Qualität muss eine Vertrauensschwelle überschreiten, bevor Nutzer sich darauf verlassen. Unter dieser Schwelle probieren Nutzer es einmal aus, erleben einen Fehler und hören auf. Die Vertrauensschwelle ist höher als die meisten Produktteams während der Entwicklung schätzen.
Discovery-Fehler: Nutzer wissen nicht, dass das Feature existiert oder wie sie darauf zugreifen. Das klingt wie ein Marketing-Problem, ist aber eigentlich ein Produktdesign-Problem. In-Produkt-KI-Features, die Nutzer zu einem separaten Bereich navigieren lassen müssen oder nur in Einstellungsmenüs erscheinen, werden für die meisten Nutzer unsichtbar sein.
Prävention: Messen Sie die drei Frühindikatoren, bevor das Feature geshippt wird: erwartete Einfügepunkt-Frequenz, Benchmark-Qualitätsschwelle aus Nutzer-Tests (nicht internen Tests) und Discovery-Platzierung im Nutzer-Flow. Wenn einer der drei schwach ist, beheben Sie ihn vor dem Launch.
Key Facts: SaaS-KI-Misserfolgsraten
- Mindestens 50 % der generativen KI-Projekte werden nach dem Proof of Concept aufgegeben aufgrund schlechter Datenqualität, unzureichender Risikokontrolle, eskalierender Kosten oder unklarem Geschäftswert (Gartner, 2025)
- 60-70 % der Unternehmen stehen bei der KI-Implementierung vor Pilot-Misserfolg; nur 10-20 % der isolierten KI-Experimente in den vergangenen zwei Jahren haben tatsächlich skaliert, um Mehrwert zu schaffen (MIT/McKinsey, 2025)
- Bis 2028 werden LLM-Observability-Investitionen 50 % der generativen KI-Deployments erreichen, speziell weil Halluzinationen, Bias und Vertrauensfehler Monitoring-Infrastruktur erfordern, die die meisten SaaS-Unternehmen heute nicht aufbauen (Gartner, 2026)
Misserfolgsmodus 2: KI-generierter Content, der SEO schadet

Ein SaaS-Unternehmen entdeckt, dass es seinen Content-Output durch KI-geschriebene Blog-Posts, Knowledge-Base-Artikel und Landing-Pages verzehnfachen kann. Sie veröffentlichen in sechs Monaten 200 KI-generierte Artikel. Drei Monate später fällt ihr organischer Suchtraffic um 35 %.
Das ist passiert. Es passiert weiterhin. Und die Kosten sind nicht nur der Traffic-Rückgang. Es sind die Erholungszeitraum: 12-18 Monate, um Domain Authority nach einer Google-Qualitätssignal-Strafe wieder aufzubauen, vorausgesetzt, Sie haben auch den Content entfernt oder wesentlich überarbeitet, der ihn ausgelöst hat.
Der spezifische Mechanismus: Googles Helpful-Content-System und manuelle Review-Teams kennzeichnen dünnen, KI-generierten Content mit geringem Originalwert. Seiten, die keine Originalrecherche, spezifische Expertise oder wirklich nützliche Informationen demonstrieren, die anderswo nicht existieren, werden de-indiziert oder stark abgewertet. Ein 200-Artikel-Batch KI-generiertem Content ohne Originalrecherche, ohne Autor-Expertise-Signale und ohne einzigartige Daten ist genau das, wofür diese Systeme designed sind, Strafen zu verhängen.
Der Dollar-Effekt: Ein SaaS-Unternehmen mit 5 Mio. \(ARR, das 30 % der Kundenakquise durch organische Suche betreibt, könnte 500.000-700.000\)/Jahr Pipeline aus diesem Kanal generieren. Ein 35 % organischer Traffic-Rückgang bedeutet 175.000-245.000 $ jährlichen Pipeline-Effekt, plus die Kosten der Content-Erstellungsinvestition, die das Problem erzeugte.
Prävention: KI-generierter Content erfordert eine echte redaktionelle Schicht vor der Veröffentlichung. Nicht einen Grammatik-Durchgang. Eine Original-Beitrags-Schicht: eine spezifische Experten-Meinung hinzugefügt, Originaldaten eingeschlossen oder ein konkretes Beispiel aus echter Kundenerfahrung. Content, der den Test nicht bestehen kann „enthält das etwas, das nicht in den Trainingsdaten existierte?", ist nicht bereit zur Veröffentlichung.
Misserfolgsmodus 3: KI-getriebener Churn durch falsche Outputs
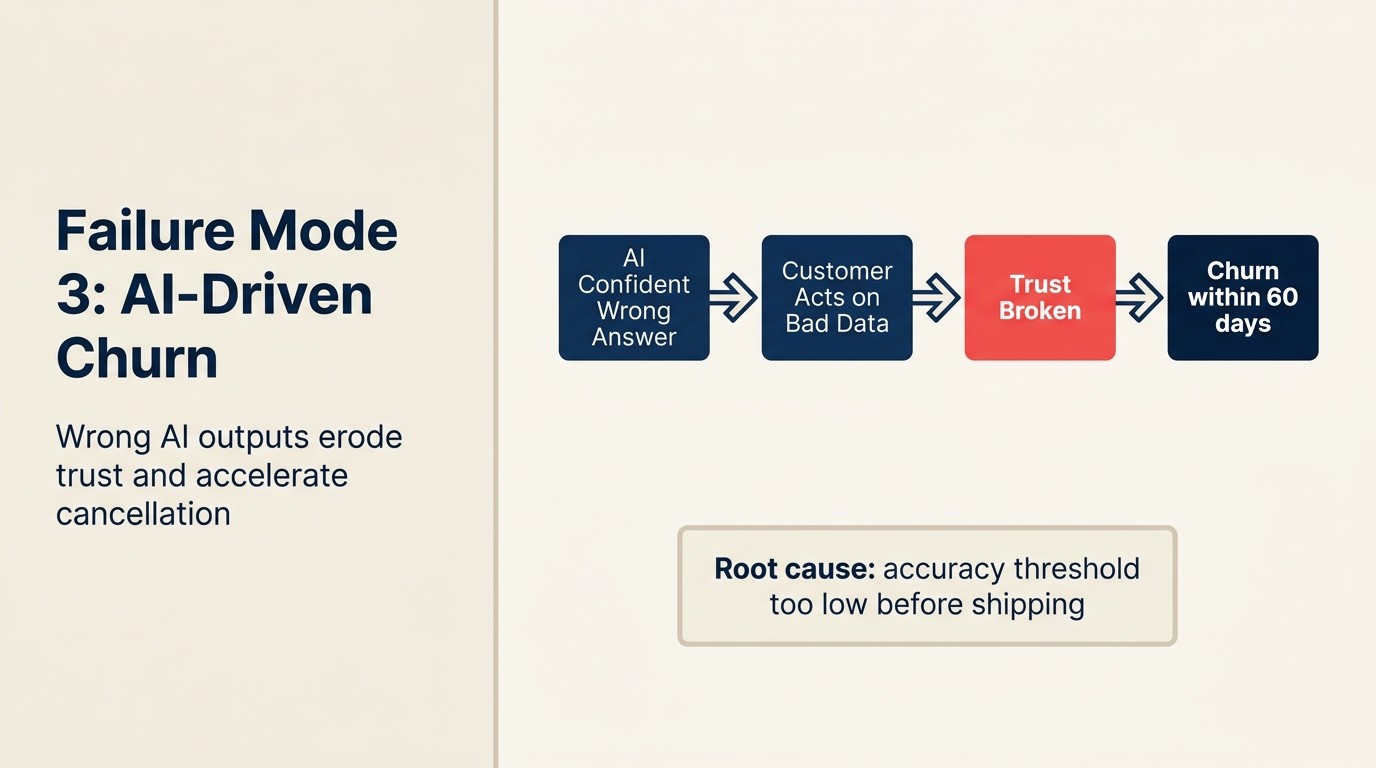
Ein Mid-Market-SaaS-Unternehmen stellt einen KI-gestützten Onboarding-Flow bereit, um die Time-to-Value zu reduzieren. Die KI empfiehlt Produktbereiche basierend auf dem während des Signups angegebenen Use Case des Nutzers. Drei Monate lang funktioniert das gut.
Dann löst ein Batch von Enterprise-Signups einen Bug in der Segmentierungslogik aus. Die KI routet 40 Enterprise-Onboarding-Sitzungen zu einem Workflow, der für kleine Teams designed ist. Diese Nutzer erleben ein Onboarding, das sich irrelevant und verwirrend anfühlt. Support-Tickets steigen. 11 der 40 Konten beantragen Erstattungen oder konvertieren nicht aus dem Trial. Der Umsatzeffekt ist $180,000 in ARR, der nicht schloss.
Das ist KI-getriebener Churn: ein Fall, in dem der Output der KI eine Kundenbeziehung aktiv geschädigt hat, statt sie zu helfen. Er unterscheidet sich von einem Standard-Software-Bug, weil der Schaden nicht „Feature hat nicht funktioniert" ist. Es ist „die KI hat dem Kunden falsche Informationen oder eine falsche Erfahrung gegeben, und der Kunde zweifelt jetzt, ob Ihr Produkt seinen Use Case versteht."
Das Misserfolgsmuster wiederholt sich beim Health Scoring. Das Health-Score-KI eines CS-Tools nennt ein abwanderndes Enterprise-Konto drei Monate lang „grün". Der CSM, der dem Score vertraut, interveniert nicht mit der normalen Häufigkeit von Check-ins. Das Konto wandert bei der Verlängerung. Die Nachanalyse zeigt, dass der Health Score Produktnutzung über Support-Ticket-Sentiment gewichtete, und das Konto hatte gleichzeitig hohe Nutzung und hohe Frustration.
Die Support-Chatbot-Version: Ein KI-Chatbot gibt einem Prospect im Trial eine falsche Antwort über Datenexport-Fähigkeiten, der das Produkt speziell für dieses Feature evaluierte. Der Prospect wählt einen Wettbewerber. Niemand weiß, dass das passiert ist, weil das Chatbot-Gespräch nicht überprüft wird. McKinsey identifiziert Risikobedenken und Kostenüberschreitungen als die primären Gründe, warum KI-Initiativen scheitern, von Prototyp zu Produktion zu kommen, und nur 10-20 % der isolierten KI-Experimente in den vergangenen zwei Jahren haben tatsächlich skaliert, um Mehrwert zu schaffen.
Prävention: Jedes KI-Feature, das kundenzugewandte Outputs generiert, braucht ein menschliches Review-Gate für hochriskante Szenarien. Nicht ein Gate für jeden Output, sondern ein Gate, das durch Auswirkungsniveau definiert ist. Niedrigriskante KI-Outputs (Entwurfsvorschläge, interne Zusammenfassungen) können auto-angewendet werden. Hochriskante Outputs (Onboarding-Routing, Preisangebote, Feature-Verfügbarkeits-Ansprüche, Health-Score-Alerts, die CSM-Verhaltensänderungen auslösen) brauchen einen Review-Mechanismus, bevor sie Kunden beeinflussen.
Misserfolgsmodus 4: Token-Kosten-Runaway
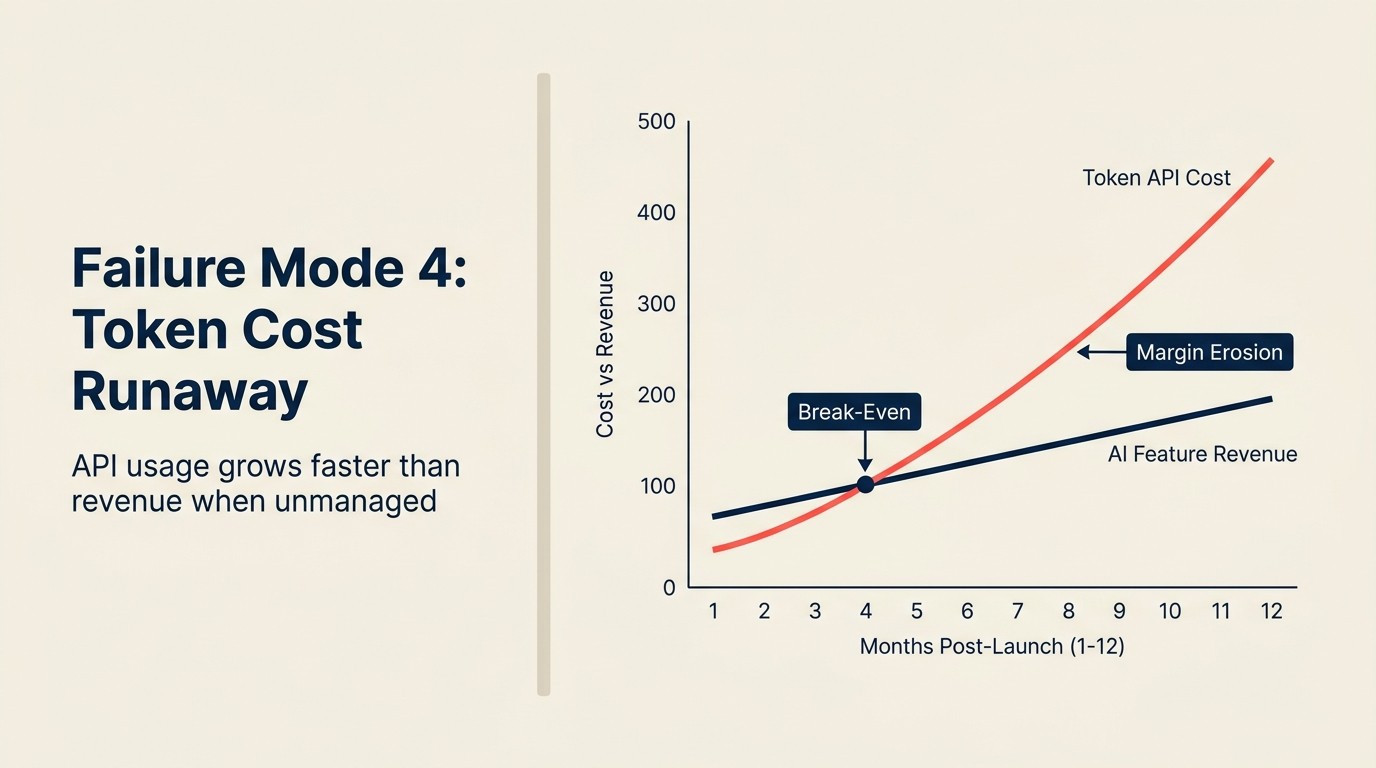
Ein SaaS-Unternehmen shippt einen KI-Schreib-Assistenten als Teil eines 49 $/Monat-Plans mit unbegrenzter KI-Generierung. Interne Tests zeigen, dass 95 % der Nutzer 50-100 Outputs pro Monat generieren. Die Modellierung sagt, API-Kosten werden bei 0,80-1,20 $ pro Nutzer pro Monat liegen. Das Feature wird geshippt.
Sechs Monate später führen drei Enterprise-Kunden, die das Produkt für groß angelegte Content-Operationen nutzen, jeweils 8.000-12.000 KI-Generierungsanfragen pro Monat durch. Bei 0,80 $/Anfrage Durchschnitt sind das 6.400-9.600 \(pro Kunde pro Monat an API-Kosten, für Kunden, die 49\)/Monat zahlen. Das Produktteam hat den 99. Perzentil-Nutzer nicht modelliert. Sie haben den Median-Nutzer modelliert.
Der gesamte vierteljährliche Effekt: drei Kunden, die eine $72,000-84,000 API-Kostenverbindlichkeit gegenüber 441 $ in kombiniertem MRR (monthly recurring revenue) erzeugen. Das Unternehmen zahlt jetzt dafür, dass diese Kunden das Produkt nutzen.
Das ist nicht hypothetisch. Dieses Muster trat in mehreren SaaS-Produkten während 2023-2024 auf, als Teams KI-Features pauschal ohne Verbrauchsarchitektur bepreisten.
Die Rechnung: OpenAI GPT-4o berechnet 2,50 $/M Input-Token und 10 $/M Output-Token. Eine einzelne KI-Schreib-Anfrage mit 3.000 Token Kontext und 800 Token Output kostet 0,0155 $. Das ist günstig pro Anfrage. Aber ein Nutzer, der 500 Anfragen pro Tag ausführt, kostet 7,75 $/Tag oder 232 $/Monat an API-Kosten. Wenn dieser Nutzer in einem 99 $/Monat-Plan ist, zahlen Sie ihm 133 $/Monat, um Ihr Produkt zu nutzen.
Prävention: Drei erforderliche Architekturentscheidungen vor dem Shippen eines KI-Features zu Pauschalpreis:
- Nutzerspezifische Verbrauchslimits nach Tier: Free-Tier bekommt 100 KI-Aktionen/Monat. Starter bekommt 500. Professional bekommt 2.000. Enterprise verhandelt individuell. Harte Limits, keine weichen.
- Nutzungsmonitoring mit automatischen Alerts: Wenn ein Konto 150 % seines Tier-modellierten Verbrauchs überschreitet, generiert das System einen Alert zur Überprüfung. Nicht nur aus Abrechnungsgründen, sondern weil anomale Nutzungsmuster oft auf ein Datenqualitätsproblem oder Nutzerverhalten hinweisen, das die KI auf unbeabsichtigte Weise nutzt.
- Kostenbasierte Preisgestaltung für Enterprise: Enterprise-Kunden mit hohem erwarteten Nutzungsvolumen sollten zu verbrauchsbasierter Preisgestaltung oder Tier-Preisgestaltung mit klaren Überverbrauchskosten sein. Ein Kunde, der 2.000 $/Monat an API-Kosten generieren wird, sollte nicht in einem 500 $/Monat-Pauschalvertrag sein.
Misserfolgsmodus 5: KI-Feature wird in 30 Tagen von einem Wettbewerber nachgeahmt
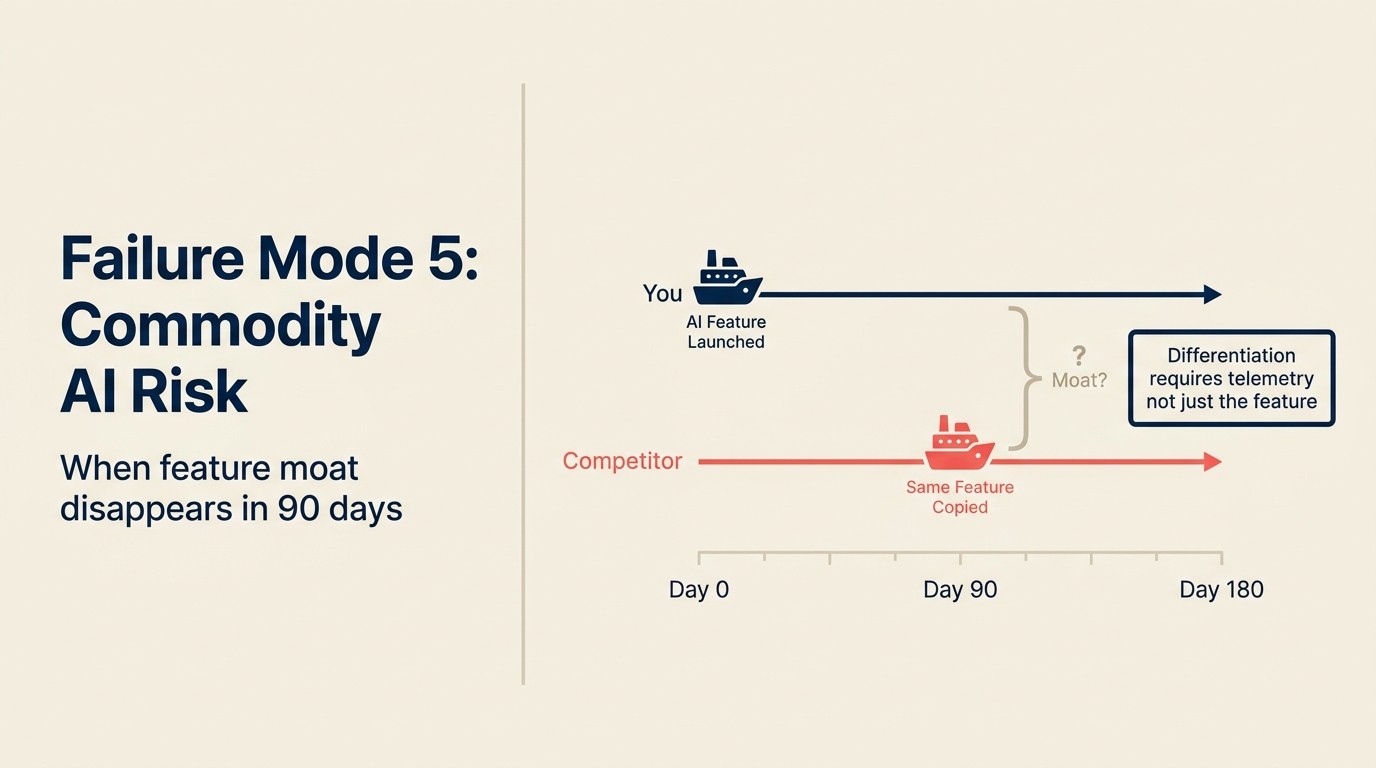
Ein SaaS-Unternehmen shippt ein KI-Vertragszusammenfassungs-Feature, das sein Sales-Team nutzt, um Deal-Reviews zu beschleunigen. Es dauert 4 Monate zu bauen. Beim Launch ist es ein Unterscheidungsmerkmal: kein Wettbewerber bietet das im Produkt an. Das Team vermarktet es prominent.
Sechs Wochen nach dem Launch shippen zwei Wettbewerber gleichwertige Features. Einer wrappt Claude direkt. Der andere integriert ein Drittanbieter-Vertrags-KI-Tool. Beide sind innerhalb von 30 Tagen live. Der Wettbewerbsvorteil, den das Unternehmen in 4 Monaten aufgebaut hat, hat eine 8-wöchige Haltbarkeit.
Das ist der No-Moat-Misserfolg: ein KI-Feature zu shippen, das ein temporäres Unterscheidungsmerkmal schafft, aber keinen strukturellen Vorteil, weil es von jedem Wettbewerber mit einem LLM-API-Abonnement und ein paar Wochen Engineering-Zeit replizierbar ist.
Die meisten KI-Features, die auf generischen LLM-APIs basieren, sind in 4-8 Wochen von einem kompetenten konkurrierenden Engineering-Team replizierbar. Die Differenzierung durch das Feature selbst ist real, aber temporär. Die einzige dauerhafte Differenzierung ist entweder (a) Daten: Ihre Version ist besser, weil sie auf dem tatsächlichen Verhalten Ihrer Nutzer trainiert ist, oder (b) Integrationstiefe: Ihre Version ist besser, weil sie so tief in den Workflow eingebettet ist, dass der Wechsel bedeutet, alles neu zu lernen.
Die Kosten: 4 Monate Engineering-Zeit, um ein Feature zu bauen, das für 8 Wochen differenziert. Bei 250.000 $/Jahr belastetem Engineering-Kosten sind das ungefähr $83,000 investiert für 2 Monate Wettbewerbsdifferenzierung.
Prävention: Bevor Sie ein KI-Feature bauen, das mehr als 6 Wochen Engineering benötigt, beantworten Sie die Frage: „In 90 Tagen, wenn zwei Wettbewerber gleichwertige Funktionalität geshippt haben, was macht unsere Version bedeutend besser?" Wenn die Antwort nicht eines von (Datenvorteil, Integrationstiefe, Qualität durch Telemetrie-Loop) ist, sollten Sie das Feature entweder schneller und günstiger wrappen oder die Engineering-Zeit in Features investieren, die dauerhafte Vorteile schaffen.
Misserfolgsmodus 6: KI-Feature erzeugt Support-Last
Ein SaaS-Unternehmen shippt ein KI-Prioritäts-Scoring-Feature für sein Projektmanagement-Tool. Die KI weist Aufgaben Prioritäts-Scores zu und zeigt die Top-Prioritäts-Items in einer täglichen Digest-E-Mail an. Das klingt nützlich, und in internen Tests liebt das Team es.
In Produktion stellen 40 % der Nutzer fest, dass die KI-Prioritäts-Vorschläge für ihren Kontext falsch sind. Die KI versteht nicht die Definition von Priorität ihres Teams, die von Deadlines, Stakeholder-Beziehungen und Kontext beeinflusst wird, der in Task-Metadaten nicht erfasst ist. Nutzer beginnen, Support-Tickets zu erstellen: „Warum sagt die KI, X hat hohe Priorität, wenn es offensichtlich nicht hat?" Das Support-Team verbringt jetzt Zeit damit, KI-Verhalten zu erklären, das sie selbst nicht vollständig verstehen.
Das Support-Ticket-Volumen für das KI-Feature in Monat eins: 180 Tickets. Die Support-Kosten bei 12 $/Ticket voll belastet: $2,160. Monatlich. Für ein Feature, das kognitive Last reduzieren sollte.
Der Misserfolg kumuliert: Nutzer, die KI-Support-Tickets einreichen, wandern häufiger ab als Nutzer, die es nicht tun. Nicht weil das KI-Feature versagt hat, sondern weil die Support-Interaktion eine Erzählung schuf: „Das KI dieses Produkts versteht meinen Kontext nicht." Diese Erzählung haftet am Produkt, nicht nur am Feature.
Dasselbe Muster erscheint in CS-KI-Tools. Ein Health-Scoring-System löst 50 „at-risk"-Alerts pro Woche aus, von denen sich nach CSM-Untersuchung 60 % als falsch-positiv erweisen. Nach vier Wochen beginnen CSMs, die Alerts ohne Überprüfung zu ignorieren. Wenn echte At-Risk-Konten in der Queue erscheinen, werden sie zusammen mit den Falsch-Positiven ignoriert. Sie haben für ein Health-Scoring-System bezahlt, das Ihr CS-Team mental abgeschrieben hat.
Prävention: Zwei Metriken, die grün sein müssen, bevor KI-generierte Empfehlungen an Kunden geshippt werden:
- Präzision: Von den Malen, bei denen die KI etwas kennzeichnet (at-risk, hohe Priorität, empfohlene Aktion), welcher Prozentsatz ist korrekt? Wenn die Präzision unter 70 % liegt, erzeugt das Feature mehr Rauschen als Signal. Die meisten Nutzer werden lernen, es zu ignorieren.
- Feedback-Loop für Korrekturen: Nutzer müssen in der Lage sein, der KI zu sagen, dass sie falsch lag, und dieses Feedback muss das Verhalten der KI tatsächlich verändern. Ein KI-Feature ohne Korrekturmechanismus trainiert Nutzer, die KI als Black Box zu sehen, die nicht argumentiert werden kann. Diese Wahrnehmung tötet Vertrauen schneller als jede individuelle falsche Antwort.
„Stilles Scheitern ist der dominante Modus in SaaS-KI. Das Produkt wird geshippt, der Changelog geht raus, die Pressemitteilung sagt 'wir investieren stark in KI', und dann passiert nichts Offensichtliches. Die KI-Feature-Protokolle zeigen 3 % wöchentliche aktive Nutzung in Monat drei. Der Support-Chatbot wurde vom Enterprise-Kunden still deaktiviert, der von einer falschen Antwort verbrannt wurde. Die Health-Scoring-KI wird von CSMs ignoriert, die zu viele Falsch-Positiv-Alerts gesehen haben." (Rework Analysis, 2025)
„Ein typisches In-Produkt-KI-Copilot-Feature braucht 3-4 Monate Engineering-Zeit, um es richtig zu bauen. Bei 250.000 $/Jahr gemischten Engineering-Kosten sind das 60.000-80.000 $ Investition. Wenn 3 % der Nutzer es nutzen und keiner es als Verlängerungsgrund angibt, hat das Team $75,000 verbrannt, um ein Feature auf der Preisseite hinzuzufügen." (Rework Analysis, basierend auf Gartner GenAI-Projektkostenanalyse, 2025)
„Das Support-Ticket-Volumen für ein KI-Feature mit unter-Schwellenwert-Präzision: 180 Tickets pro Monat, bei 12 $/Ticket voll belastet, sind $2,160 pro Monat an Support-Kosten für ein Feature, das kognitive Last reduzieren sollte. Der Misserfolg kumuliert: Nutzer, die KI-Support-Tickets einreichen, wandern häufiger ab als Nutzer, die es nicht tun, weil die Support-Interaktion eine Produkterzählung schafft, die am gesamten Produkt haftet." (Rework Analysis, 2025)
„Drei Enterprise-Kunden, die einen pauschalbepreisten KI-Schreib-Assistenten bei 8.000-12.000 Generierungsanfragen pro Monat jeweils nutzen, zahlend 49 $/Monat, erzeugen $72,000-84,000 in vierteljährlicher API-Kostenverbindlichkeit gegenüber 441 $ in kombiniertem MRR. Das Unternehmen zahlt jetzt dafür, dass diese Kunden das Produkt nutzen. Das ist nicht hypothetisch." (Rework Analysis, basierend auf OpenAI-Preisgestaltung und dokumentierten SaaS-Token-Kosten-Vorfällen, 2025)
SaaS-KI-Misserfolgsmodus-Präventions-Checkliste

| Misserfolgsmodus | Frühwarnsignal | Erkennungsfenster | Prävention |
|---|---|---|---|
| Features, die niemand nutzt | 90-Tage-WAU unter 10 % | Tag 30-60 | Einfügepunkt validieren vor dem Bauen |
| KI-Content schadet SEO | Organischer Traffic-Rückgang 3 Monate nach Veröffentlichung | 90-120 Tage | Original-Beitrags-Schicht in jedem KI-Stück |
| Falsche Outputs treiben Churn | Support-Spike oder Erstattungsanfragen von KI-berührten Nutzern | 30-90 Tage | Menschliches Review-Gate für hochriskante KI-Outputs |
| Token-Kosten-Runaway | Monatliche API-Kosten überschreiten 50 % des Plan-Umsatzes für ein Konto | 30-60 Tage | Nutzerspezifische Verbrauchsobergrenzen vor dem Launch |
| No-Moat Feature Match | Wettbewerber shippt Äquivalent innerhalb von 60 Tagen | 6-12 Wochen | Telemetrie-Loop beim Launch; Integrationstiefe |
| Support-Burden-KI | Support-Tickets für KI-Feature; CSM-Alert-Ignorier-Rate über 30 % | 30-60 Tage | Präzisionsschwelle über 70 % vor dem Shippen |
Quellen: Gartner GenAI Project Failure Analysis 2025, McKinsey AI Risk and Cost Research 2025, Gartner LLM Observability Predictions 2026
„Bis 2028 werden LLM-Observability-Investitionen 50 % der generativen KI-Deployments erreichen, speziell weil Halluzinationen, Bias und Vertrauensfehler Monitoring-Infrastruktur erfordern, die die meisten SaaS-Unternehmen heute nicht aufbauen. Teams, die diese Instrumentierung jetzt beginnen, werden der Compliance- und Kundenerwartungskurve voraus sein." (Gartner, 2026)
Rework Analysis: Das Muster über alle sechs Misserfolgsmodi hinweg ist Messdisziplin, keine Technologieanspruchsvollheit. Jeder hier dokumentierte Misserfolgsmodus ist in den Daten sichtbar, bevor er teuer wird, wenn Sie schauen. Teams, die KI einsetzen, Erfolg basierend auf der Launch-Ankündigung erklären und sechs Monate lang nichts messen, sind die, die Modus 1 in Monat 6 entdecken, wenn die Nutzungsdaten eine Geschichte erzählen, die der Changelog nicht tat. Die Misserfolgspräventions-Checkliste ist keine optionale Governance. Es ist die operative Gewohnheit, die KI-Investitionen, die sich kumulieren, von KI-Investitionen, die sich abschreiben, trennt.
Wie Misserfolgsprävention tatsächlich aussieht
Das Muster über alle sechs Misserfolgsmodi hinweg ist Messdisziplin, keine Technologieanspruchsvollheit. Jeder hier beschriebene Misserfolgsmodus ist in den Daten sichtbar, bevor er teuer wird, wenn Sie schauen.
Eine Misserfolgspräventions-Checkliste vor dem Bereitstellen eines KI-Features:
Baseline-Messung ist vorhanden: Sie kennen die Metrik, die dieses Feature verbessern soll, und haben die Vor-KI-Baseline dokumentiert. Wenn Sie KI-Call-Coaching bereitstellen, ohne aufzuzeichnen, wie „gute Discovery-Qualität" vor KI aussieht, können Sie nicht messen, ob es funktioniert hat.
Adoptions-Tracking ist live: Wöchentlich aktive Nutzer, Akzeptanzrate und Modifikationsrate sind auf einem Dashboard, das jemand wöchentlich überprüft. 3 % Adoption bei Tag 30 ist erholbar. 3 % Adoption bei Tag 90 ist ein Feature, für dessen Wartung Sie bezahlen.
Verbrauchsbeschränkungen sind gebaut: Jedes KI-Feature auf einem Pauschalpreis-Plan hat Nutzerlimits und Nutzungsmonitoring, bevor es geshippt wird, nicht nach dem ersten anomalen Abrechnungszyklus.
Eskalationspfade existieren: Jedes KI-Feature, das einen kundenzugewandten Output berührt, hat einen definierten Pfad für den Kunden, zu eskalieren, wenn die KI falsch liegt. Vorzugsweise wird diese Eskalation von einem Menschen behandelt, nicht einer weiteren KI.
Präzision ist gemessen und mit Schwellenwert versehen: Für jedes KI-Feature, das Alerts oder Empfehlungen generiert, wird Präzision verfolgt. Das Feature wird nicht ohne eine definierte und getestete minimale Präzisionsschwelle geshippt.
Vertrauenssignal wird verfolgt: Monatlich prüfen, ob Nutzer, die mit Ihren KI-Features interagieren, höhere oder niedrigere NPS- und Churn-Raten haben als Nutzer, die es nicht tun. Wenn KI-Feature-Engagement mit höherem Churn korreliert, haben Sie ein Vertrauensproblem, das diagnostiziert werden muss, bevor das Feature skaliert.
SaaS-KI-Misserfolg ist überlebbar, wenn er frühzeitig erkannt wird. Die sechs hier beschriebenen Misserfolgsmodi sind alle in den ersten 60-90 Tagen messbar, wenn Sie die richtigen Signale verfolgen. Die Unternehmen, die in ernsthafte Schwierigkeiten geraten, sind die, die KI einsetzen, Erfolg basierend auf der Launch-Ankündigung erklären und sechs Monate lang nichts messen. Gartner sagt voraus, dass bis 2028 LLM-Observability-Investitionen 50 % der generativen KI-Deployments erreichen werden, speziell weil Halluzinationen, Bias und Vertrauensfehler Monitoring-Infrastruktur erfordern, und die Teams, die diese Instrumentierung frühzeitig beginnen, werden der Compliance- und Kundenerwartungskurve voraus sein.
Erklären Sie keinen Erfolg, bevor die Telemetrie ihn beweist.
Mehr erfahren:
- Why Most AI Transformations Fail: die Strategie-Level-Misserfolgsmuster, die die Bedingungen für alle sechs Modi schaffen
- Hallucination Risk by Pattern: die technischen Bedingungen, die konfidente KI-Fehler nach Mustertyp erzeugen
- Generate vs. Execute Boundary: das ACE-Framework-Prinzip für den Fall, dass KI menschliche Zustimmung braucht, bevor sie handelt
- AI Anti-Patterns: der breitere Muster-Level-Misserfolgskatalog, der SaaS-spezifische Misserfolgsmodi ergänzt
- Telemetry Loops for In-Product AI: Mess-Infrastruktur, die Misserfolge bei Tag 30 erkennt, nicht in Monat 6
- Der KI-Wettlauf im SaaS: Speed to Ship: Wettbewerbsdruck, der die Bedingungen für das Shippen ohne Quality Gates schafft
- Die SaaS-KI-Reifegrade: wo sich diese Misserfolgsmodi nach Reifestufe häufen
- Why AI Frameworks Fail: die grundlegenden Misserfolgsmuster, auf die SaaS-KI-Misserfolge oft zurückzuführen sind

Co-Founder, Rework.com
On this page
- Die 6 SaaS-KI-Misserfolgsmodi
- Misserfolgsmodus 1: KI-Features, die Kunden nicht nutzen
- Misserfolgsmodus 2: KI-generierter Content, der SEO schadet
- Misserfolgsmodus 3: KI-getriebener Churn durch falsche Outputs
- Misserfolgsmodus 4: Token-Kosten-Runaway
- Misserfolgsmodus 5: KI-Feature wird in 30 Tagen von einem Wettbewerber nachgeahmt
- Misserfolgsmodus 6: KI-Feature erzeugt Support-Last
- SaaS-KI-Misserfolgsmodus-Präventions-Checkliste
- Wie Misserfolgsprävention tatsächlich aussieht