Deflexão de Tickets com RAG no Suporte SaaS
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
A taxa de deflexão é a métrica que a maioria das equipes de suporte SaaS acompanha quando avalia AI. Também é a métrica errada para otimizar sozinha.
Uma taxa de deflexão de 60% parece impressionante. Mas se 40% desses clientes deflectidos receberam uma resposta incorreta ou incompleta, desistiram sem resolver seu problema e silenciosamente reduziram o uso do produto ou abriram um ticket três dias depois com um tom mais frustrado, você não melhorou sua operação de suporte. Você escondeu um problema atrás de uma métrica.
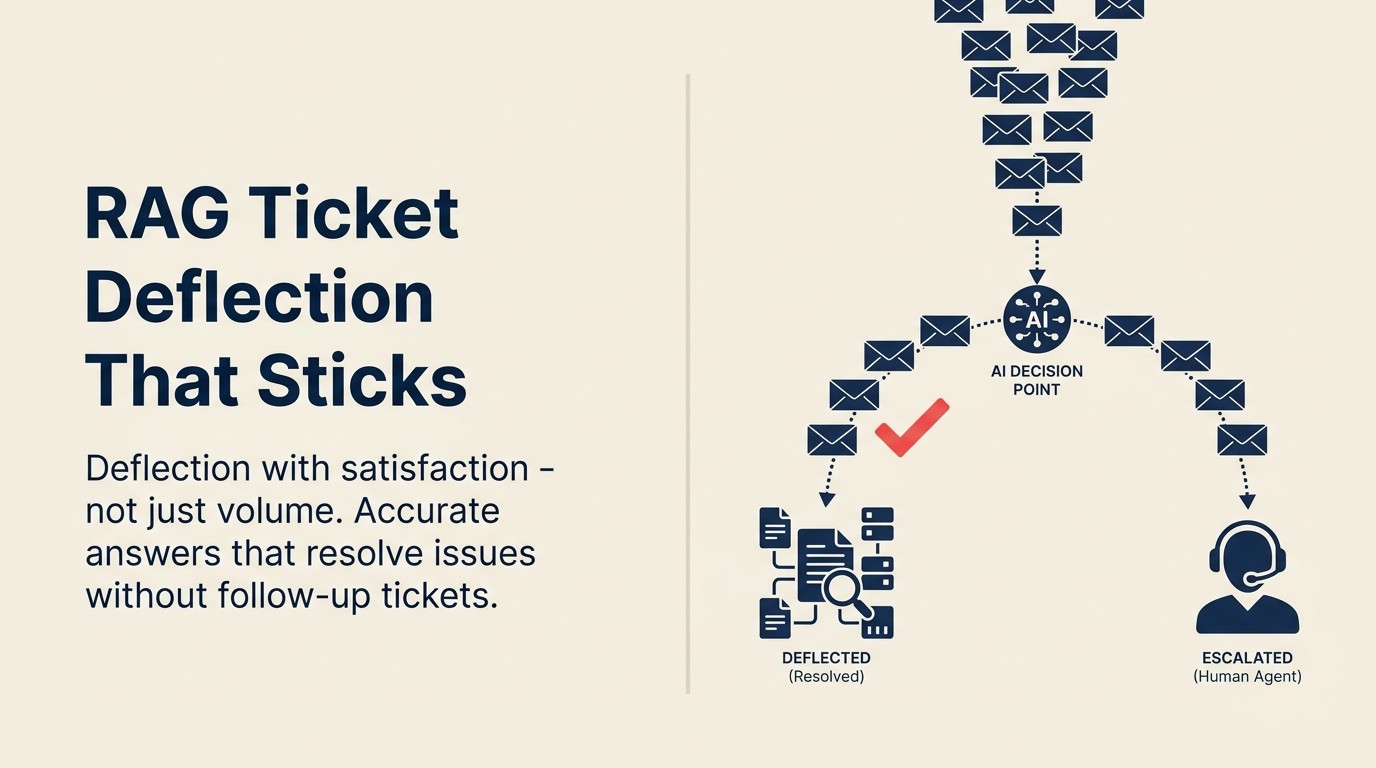
O objetivo é deflexão com satisfação: clientes que recebem respostas precisas, resolvem seu problema e não precisam abrir um ticket de acompanhamento. Esse objetivo exige uma abordagem de design diferente da simples otimização de volume de deflexão, e começa com a compreensão de como a deflexão de Retrieval-Augmented Generation (RAG) realmente funciona.
Como a Deflexão RAG Funciona
Quando um cliente envia uma mensagem de suporte, um sistema baseado em RAG faz o seguinte: pega a pergunta, executa uma busca semântica no corpus da base de conhecimento, recupera os chunks de documentação mais relevantes e gera uma resposta que se baseia diretamente nesse conteúdo recuperado. A resposta inclui links para as fontes para que o cliente possa ler a documentação original se quiser mais detalhes.
A etapa de recuperação é o que separa o RAG de um chatbot genérico. Um chatbot genérico gera uma resposta a partir de seus dados de treinamento. Ele pode saber aproximadamente como sistemas de ticketing SaaS funcionam, mas não sabe seus códigos de erro específicos da API, seu modelo de permissão específico ou a mudança de workflow que você lançou há três semanas. O RAG recupera do seu conteúdo real, então a resposta é ancorada na verdade do seu produto, não na aproximação do modelo. O RAG Assistant Pattern explica a arquitetura técnica completa por trás dessa abordagem de recuperação.
É por isso que a qualidade da recuperação importa mais do que a qualidade da geração para o suporte SaaS. Uma resposta ligeiramente imprecisa gerada a partir de documentação recuperada com precisão é melhor do que uma resposta polida gerada com o melhor palpite do modelo. Os clientes querem a resposta certa, não a incorreta mais fluente.
Key Facts: Qualidade de Deflexão de Tickets RAG
- O RAG com grafos de conhecimento alcançou uma melhoria de 77,6% na precisão de recuperação (medida por mean reciprocal rank, uma pontuação padrão de qualidade de busca) e uma redução de 28,6% no tempo de resolução na equipe de atendimento ao cliente do LinkedIn (pesquisa LinkedIn/MIT, 2024)
- Apenas 14% dos problemas de atendimento ao cliente são totalmente resolvidos no self-service hoje, com 43% dos clientes relatando que não conseguem encontrar conteúdo de self-service relevante (Gartner, 2025)
- Empresas SaaS B2B que usam plataformas de suporte com AI em primeiro lugar veem 60% mais deflexão de tickets em comparação com software de help desk tradicional, com a lacuna de desempenho explicada quase inteiramente pela qualidade da base de conhecimento, não pela qualidade do modelo de AI (Pylon, 2025)
O RAG Quality Gate
O RAG Quality Gate é uma avaliação de três limiares que é executada antes que qualquer resposta de AI seja entregue a um cliente. Limiar de qualidade do corpus: o documento recuperado deve ter sido atualizado dentro de uma janela de atualização definida (recomendado: 90 dias para SaaS com rápida evolução). Limiar de confiança de recuperação: a pontuação de similaridade semântica entre a pergunta do cliente e o conteúdo recuperado deve exceder um valor mínimo antes de gerar uma resposta. Limiar de precisão da resposta: se a recuperação retornar vários documentos potencialmente conflitantes, o sistema sinaliza para revisão humana em vez de gerar uma resposta mesclada que pode aluci. Tickets que não passam em qualquer limiar são encaminhados para atendimento humano com o sinal de baixa confiança anexado.
O que Vai no Corpus RAG
O corpus é tudo a que a AI tem acesso para recuperar. Para suporte SaaS, um corpus bem projetado inclui cinco tipos de conteúdo.
Documentação de ajuda. Sua central de ajuda principal: guias de procedimentos, explicações de funcionalidades, walkthroughs de solução de problemas, guias de configuração de integração. Esta é a fundação. Precisa ser específica (nível de artigo, não apenas nível de categoria), atual e organizada de forma consistente o suficiente para que a busca semântica possa distinguir entre uma pergunta sobre permissões de usuário e uma sobre permissões de API.
Documentação de API e para desenvolvedores. Para ferramentas SaaS voltadas a desenvolvedores, documentação de API, guias de webhook, referências de SDK e definições de código de erro são conteúdo valioso do corpus. Os tickets de desenvolvedores tendem a ser precisos e técnicos, e as respostas geralmente estão na documentação. O desafio é manter esses atualizados à medida que as APIs evoluem.
Notas de release do produto. Este é o componente de corpus mais comumente negligenciado. Cada lançamento de funcionalidade, mudança de API e correção de bug cria novas perguntas de suporte. Clientes que fizeram upgrade na semana passada estão perguntando sobre comportamentos que não existiam antes do upgrade. Se as notas de release não estão no corpus, a AI responde com informações desatualizadas.
Tickets resolvidos anteriormente. Tickets resolvidos categorizados e desidentificados são conteúdo de corpus de alto sinal, especialmente para casos extremos que não estão explicitamente cobertos nos documentos de ajuda. Quando um cliente descreve um comportamento de erro incomum, um ticket resolvido de um cliente anterior com o mesmo problema pode produzir uma resposta mais precisa do que um artigo de documentação que cobre apenas o caso comum. Data readiness by pattern aborda como são os dados limpos e prontos para corpus para implantações RAG.
FAQ e orientação dentro do produto. Respostas de formato curto para as perguntas mais comuns, dicas de onboarding e orientação contextual vinculada de dentro do próprio produto. Esses costumam ser o conteúdo mais semanticamente similar às perguntas que os clientes realmente fazem, o que os torna candidatos de alta recuperação.
Detecção de Lacunas de Conhecimento
O output mais valioso de um sistema de suporte RAG não são as deflexões bem-sucedidas. São os sinais de lacunas de conhecimento de recuperações com falha. A análise da Forrester sobre gestão de conhecimento em atendimento ao cliente constatou que organizações com bases de conhecimento maduras e bem estruturadas alcançam taxas de resolução e economias de custo substancialmente maiores do que aquelas que tratam a documentação como infraestrutura secundária.
Quando a AI tenta recuperar conteúdo relevante para uma pergunta e os documentos com melhor correspondência têm pontuações de similaridade baixas, esse é um sinal de que o corpus não tem boa cobertura para esse tipo de pergunta. Alguns sistemas respondem com uma resposta confiante de qualquer forma (usando o conhecimento geral do modelo para preencher a lacuna). Sistemas melhores escalam o ticket com um sinal indicando recuperação de baixa confiança.
Rastreie essas escaladas de baixa confiança como um backlog de documentação. Cada uma representa uma pergunta que seus clientes estão fazendo e que seus documentos não respondem bem. Resolver o ticket humano subjacente e depois escrever um artigo de ajuda a partir dessa resolução é a forma mais rápida de expandir sua cobertura efetiva de deflexão.
O Intercom Fin rastreia isso por meio de seu recurso "Sources", que mostra quais documentos estão sendo citados nas respostas de AI e quais tipos de perguntas estão gerando escaladas sem boas correspondências de fonte. O Zendesk AI apresenta sinais de lacuna similares por meio de sua análise de conversas. Esses relatórios de lacunas, executados mensalmente, se tornam o input para seu sprint de documentação. A pergunta é: como você sabe quando a qualidade de deflexão está realmente funcionando?
Medição da Qualidade de Deflexão
O volume de deflexão como métrica única é enganoso. Você precisa de quatro medições juntas.
Taxa de resolução. Que percentual dos tickets deflectidos por AI fecham sem uma interação de acompanhamento do cliente? Um ticket deflectido que é reaberto em 48 horas não é um ticket resolvido. Acompanhe a taxa de reabertura como sinal de qualidade.
CSAT em tickets deflectidos. Quando os clientes avaliam sua experiência de suporte após uma deflexão de AI, o que dizem? A maioria das plataformas permite que você solicite uma avaliação de polegar para cima/baixo ou de 1 a 5 estrelas no encerramento do ticket. O CSAT em tickets deflectidos por AI versus tickets tratados por humanos informa se os clientes acham a resolução AI satisfatória ou apenas minimamente aceitável.
Taxa de deflexão falsa. Tickets marcados como resolvidos pela AI, mas onde o cliente abriu um novo ticket em 7 dias descrevendo o mesmo problema. Esta é a medida mais clara de deflexão ruim: a AI disse que resolveu o problema, mas não resolveu. Risco de alucinação por padrão explica as condições em que até sistemas baseados em RAG produzem respostas incorretas confiantes.
Taxa de escalada após tentativa de AI. Dos tickets em que a AI tentou uma resposta antes de um humano pegar, quantos exigiram que o humano corrigisse ou substituísse completamente a resposta da AI? Isso mede se a AI está ajudando os agentes humanos ou criando mais trabalho para eles.
Uma operação de suporte com 40% de deflexão, 4,2/5 de CSAT em tickets deflectidos, 8% de taxa de deflexão falsa e 15% de taxa de escalada após tentativa de AI está tendo bom desempenho. Uma operação de suporte com 55% de deflexão, 3,1/5 de CSAT, 22% de taxa de deflexão falsa e 35% de escaladas com correção necessária não está. Maior deflexão com piores métricas de qualidade representa uma experiência líquida negativa para o cliente.
"As empresas que alcançam deflexão sustentada de 40-50% com alto CSAT não estão usando AI melhor. Estão tratando a documentação como um ativo de produto com o mesmo rigor que aplicam ao próprio produto. A defasagem de atualização da base de conhecimento é a métrica certa para acompanhar: a idade média dos artigos em relação à última mudança de produto que eles cobrem." (Rework Analysis, 2025)
Benchmarks de Qualidade de Deflexão
| Métrica | Limiar Bom | Sinal de Alerta | Ação Necessária |
|---|---|---|---|
| Taxa de resolução (sem acompanhamento em 48h) | Acima de 85% | 70-85% | Revisar tópicos comuns de reabertura |
| CSAT em tickets deflectidos | 4,0/5 ou acima | 3,5-4,0/5 | Auditar respostas de AI recentes para precisão |
| Taxa de deflexão falsa (mesmo problema, novo ticket em 7 dias) | Abaixo de 8% | 8-15% | Identificar tipos de documentos com falhas |
| Taxa de escalada com correção de AI | Abaixo de 15% | 15-25% | Investigar qualidade de resposta de AI por categoria |
Fontes: Zendesk CX Trends 2026, Intercom Fin Performance Data 2025, Gartner Customer Service AI Benchmark 2025
O Problema da Cadência de Release SaaS
SaaS lança rapidamente. A documentação fica defasada. Essa é a causa mais comum de degradação da qualidade de suporte AI ao longo do tempo.
Quando você lança uma nova funcionalidade, a AI ainda conhece o comportamento antigo. Clientes que usam a nova funcionalidade fazem perguntas sobre comportamentos que não existiam quando os documentos foram escritos. A AI recupera a partir desses documentos antigos e produz uma resposta que estava correta há três meses e está errada hoje.
A solução é conectar seu processo de atualização de documentação ao seu processo de release. Cada release deve ter uma tarefa correspondente de documentação: quais artigos de ajuda precisam de atualização, quais novos artigos precisam ser criados, quais documentos de API precisam de notas de versão adicionadas. O release não é lançado sem que as atualizações de documentação estejam em fila.
Para perguntas orientadas por notas de release (clientes perguntando "isso mudou no último release?"), as próprias notas de release se tornam a fonte primária do corpus. Certifique-se de que as notas de release sejam publicadas em um formato que o sistema RAG possa recuperar, não apenas enviadas por e-mail aos assinantes e depois esquecidas.
Algumas equipes executam uma auditoria mensal do corpus: extraem as 30 deflexões de AI bem-sucedidas mais recentes e revisam os documentos-fonte. Eles ainda estão corretos? Alguma das funcionalidades que descrevem mudou? Esse exercício mensal de 2 horas evita um declínio gradual em direção a respostas incorretas confiantes.
Suporte em Vários Idiomas
Empresas SaaS B2B com bases de clientes globais enfrentam um desafio de deflexão multilíngue. Seus documentos podem estar principalmente em inglês. Seus clientes podem estar fazendo perguntas em alemão, espanhol ou japonês.
O Intercom Fin e o Zendesk AI lidam com recuperação em vários idiomas, seja por meio de busca semântica multilíngue (encontrando documentos relevantes em inglês em resposta a uma pergunta feita em outro idioma) ou por recuperação direta de documentação traduzida quando disponível.
A diferença de qualidade é significativa. Um cliente que faz uma pergunta em espanhol e recebe uma resposta gerada a partir de documentos em inglês com tradução automática em tempo real terá uma experiência diferente de um cliente cuja pergunta é respondida a partir de um artigo de ajuda traduzido com a terminologia correta para seu idioma e região.
Para idiomas de clientes de alto volume, traduza primeiro os 50 artigos de ajuda mais importantes. Isso cobre a maioria dos tipos de perguntas deflectíveis com conteúdo-fonte em idioma nativo, e a melhoria de qualidade nos tickets deflectidos é imediata.
Corpora Específicos por Segmento
Clientes enterprise e SMB fazem perguntas diferentes. Um cliente enterprise perguntando sobre provisionamento de usuários via SCIM está fazendo uma pergunta diferente de um cliente SMB perguntando como adicionar um novo membro da equipe.
Quando sua base de clientes tem segmentos distintos com necessidades de suporte significativamente diferentes, considere recuperação com consciência de segmento. O Zendesk AI suporta isso por meio de marcação de clientes que influencia qual corpus é pesquisado primeiro. O Intercom Fin usa lógica de roteamento de conversa que pode enviesar a recuperação em direção a documentação específica por segmento.
A implementação prática: marque seus artigos de ajuda por tier de cliente (SMB, Mid-Market, Enterprise) e encaminhe os tickets recebidos com marcações de cliente enterprise em direção a documentação de tier enterprise primeiro. Um artigo de ajuda genérico sobre gerenciamento de usuários é adequado para perguntas de SMB. Um cliente enterprise perguntando sobre provisionamento SCIM deve estar recuperando da sua documentação de integração enterprise, não do seu guia geral "como adicionar um usuário".
Loop de Melhoria Contínua
A deflexão de tickets com RAG não é um sistema de implantar e esquecer. Ela melhora continuamente com investimento deliberado.
O loop de melhoria é executado em um ciclo mensal. Extraia os sinais de lacunas de conhecimento do mês passado: quais tipos de tickets geraram recuperações de baixa confiança, quais perguntas tiveram altas taxas de deflexão falsa, quais áreas do produto viram mais escaladas após tentativas de AI. Converta esses em tarefas de documentação. Escreva os artigos, atualize os desatualizados, adicione as notas de release que não estavam no corpus.
Acompanhe a qualidade de deflexão mês a mês. Se o CSAT em tickets deflectidos está subindo, o loop de melhoria está funcionando. Se está estável ou caindo, a documentação está ficando atrás das mudanças do produto.
As empresas que alcançam deflexão sustentada de 40-50% com alto CSAT não estão usando AI melhor. Estão tratando a documentação como um ativo de produto com o mesmo rigor que aplicam ao próprio produto. A Gartner prevê que a AI agêntica resolverá autonomamente 80% dos problemas comuns de atendimento ao cliente sem intervenção humana até 2029, e as organizações mais bem posicionadas para alcançar esse teto são as que estão construindo disciplina de documentação agora. O sprint de documentação está no roadmap. A auditoria do corpus está no calendário de ops de suporte. Os relatórios de lacunas de conhecimento vão para a equipe de documentação, não apenas para a equipe de suporte. Product telemetry advantage in SaaS AI explica como dados de uso dentro do produto podem alimentar seu corpus de suporte e trazer perguntas à superfície antes mesmo que os clientes as façam.
AI Support Agent for SaaS Self-Service aborda a estrutura completa de tiers: como a deflexão RAG se conecta à assistência a agentes humanos e à escalada para especialistas como um sistema de suporte completo.
AI Knowledge Base Maintenance for SaaS Docs aprofunda o ciclo de vida da documentação: como auditar a cobertura, manter documentos atualizados com releases e usar a própria AI para manter o corpus.
Multi-Tier AI Routing in SaaS Help Desk aborda o que acontece depois que o RAG tenta a deflexão: como os tickets que precisam de atendimento humano são encaminhados ao agente certo sem triagem manual.
As equipes de suporte que ganham com RAG são as que acompanham qualidade de deflexão junto com volume de deflexão. Clientes satisfeitos que se auto-serviram é o objetivo. Clientes que desistiram e saíram silenciosamente não é. Projete para o primeiro desde o início.
Rework Analysis: A taxa de deflexão falsa é a métrica mais subacompanhada no suporte AI SaaS. Equipes otimizam pelo volume bruto de deflexão, celebram uma taxa de deflexão de 50% e perdem que 18% desses clientes "deflectidos" abriram um novo ticket em 7 dias com o mesmo problema e frustração adicional. A taxa real de deflexão não é o que o sistema relata. É o que acontece 7 dias depois. Equipes que acompanham a taxa de reabertura de 7 dias junto com o volume de deflexão descobrem que sua taxa efetiva de deflexão é tipicamente 10-15 pontos percentuais mais baixa do que o número principal, e esse é o número para otimizar.
Perguntas Frequentes
Qual é a diferença entre taxa de deflexão e taxa de resolução no suporte RAG?
A taxa de deflexão mede quantos tickets a AI trata sem escalar para um humano. A taxa de resolução mede quantos desses tickets tratados por AI foram realmente resolvidos, ou seja, o cliente obteve uma resposta precisa e não reabriu o problema. Uma taxa de deflexão de 60% onde 20% dos clientes reabrem o mesmo ticket em 7 dias representa uma taxa de resolução real mais próxima de 48%. Otimizar pela taxa de resolução em vez da taxa de deflexão produz melhor experiência do cliente e maior CSAT.
O que deve ir em um corpus RAG para suporte SaaS?
Cinco tipos de conteúdo: documentação de ajuda, documentação de API e para desenvolvedores, notas de release do produto, tickets resolvidos desidentificados e FAQ ou orientação dentro do produto. Notas de release são as mais comumente negligenciadas. Cada lançamento de funcionalidade cria novas perguntas, e se as notas de release estão ausentes do corpus, a AI responde com informações desatualizadas. Uma meta prática de prontidão de documentação: os 50 tipos de tickets mais comuns devem ter artigos de ajuda dedicados e específicos atualizados nos últimos 90 dias.
Como detectar quando a qualidade de deflexão RAG está degradando?
Três sinais indicam degradação. Primeiro, o CSAT em tickets deflectidos cai abaixo de 3,8/5 em um período de 30 dias. Segundo, a taxa de deflexão falsa (mesmo problema, novo ticket em 7 dias) sobe acima de 10%. Terceiro, a taxa de correção de AI na escalada (agente humano deve corrigir ou substituir a resposta de AI) ultrapassa 20%. Qualquer um desses sinais aciona uma auditoria de documentação para as categorias de tickets afetadas.
Como a cadência de lançamento SaaS afeta a precisão do RAG ao longo do tempo?
SaaS evolui continuamente. Quando uma funcionalidade muda, a documentação descrevendo seu comportamento antigo permanece no corpus e é retornada como resultado de recuperação para novas perguntas. A AI gera respostas confiantes com base em material-fonte desatualizado. A solução é conectar as atualizações de documentação ao processo de release. Cada release deve produzir uma tarefa de documentação: quais artigos precisam de atualização, quais novos artigos precisam ser criados. O release não é lançado sem que as tarefas de documentação estejam em fila.
O que é detecção de lacunas de conhecimento no suporte RAG?
A detecção de lacunas de conhecimento é o uso de sinais de recuperação de baixa confiança para identificar documentação que não existe. Quando a AI tenta a recuperação e os documentos com melhor correspondência têm pontuações de similaridade baixas, o tipo de ticket é registrado como uma lacuna. Esses registros de lacunas, revisados mensalmente, se tornam o backlog de documentação. Cada lacuna representa uma pergunta de cliente que seus documentos não respondem bem. Resolver o ticket humano e escrever um artigo de ajuda a partir dele é a forma mais rápida de expandir a cobertura de deflexão.
Saiba Mais:
- RAG Assistant Pattern: arquitetura técnica completa para AI de suporte por recuperação aumentada
- Hallucination Risk by Pattern: onde o AI baseado em RAG ainda falha e como calibrar limiares de escalada
- Data Readiness by Pattern: como são os dados limpos e prontos para corpus para implantações RAG
- AI Support Agent for SaaS Self-Service: a estrutura completa de tiers para AI de suporte SaaS
- Multi-Tier AI Routing in SaaS Help Desk: roteamento inteligente após tentativas de deflexão
- AI Knowledge Base Maintenance for SaaS Docs: mantendo o corpus atualizado com o produto

Co-Founder, Rework.com