A Corrida Armamentista de AI em SaaS: Velocidade para Lançar, e Quando a Velocidade Está Errada

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Quando a Intercom lançou o Fin em março de 2023, todo líder de suporte em uma empresa SaaS concorrente teve a mesma experiência: uma pergunta do conselho chegou em duas semanas. "O que estamos fazendo em relação à AI?" Não "devemos pensar sobre AI?" mas "o que estamos fazendo?" O enquadramento assumia que a resposta já era sim. A pergunta era apenas sobre execução.
Quando o GitHub lançou o Copilot em disponibilidade geral em junho de 2022, IDEs (integrated development environments) que haviam sido produtos estáveis por anos subitamente enfrentaram uma questão de categoria que não tinham planejado. JetBrains, extensões do VS Code, Sublime Text, todos tiveram que decidir como responder a uma funcionalidade de produto que seus usuários agora estavam comparando ativamente.
É assim que a corrida armamentista de AI parece por dentro. Não uma mudança competitiva lenta. Um evento pontuado que força uma decisão de resposta imediata.
A corrida armamentista é real. Mas "lance funcionalidades de AI rápido" não é uma estratégia. É uma direção. As empresas que navegaram bem por isso não apenas lançaram rápido. Lançaram funcionalidades específicas, em fluxos de trabalho específicos, com telemetria específica implementada para aprender o que estava funcionando. As que não navegaram bem lançaram wrappers de GPT-4 sem diferenciação e estão vendo clientes migrarem para produtos que fizeram o trabalho direito.
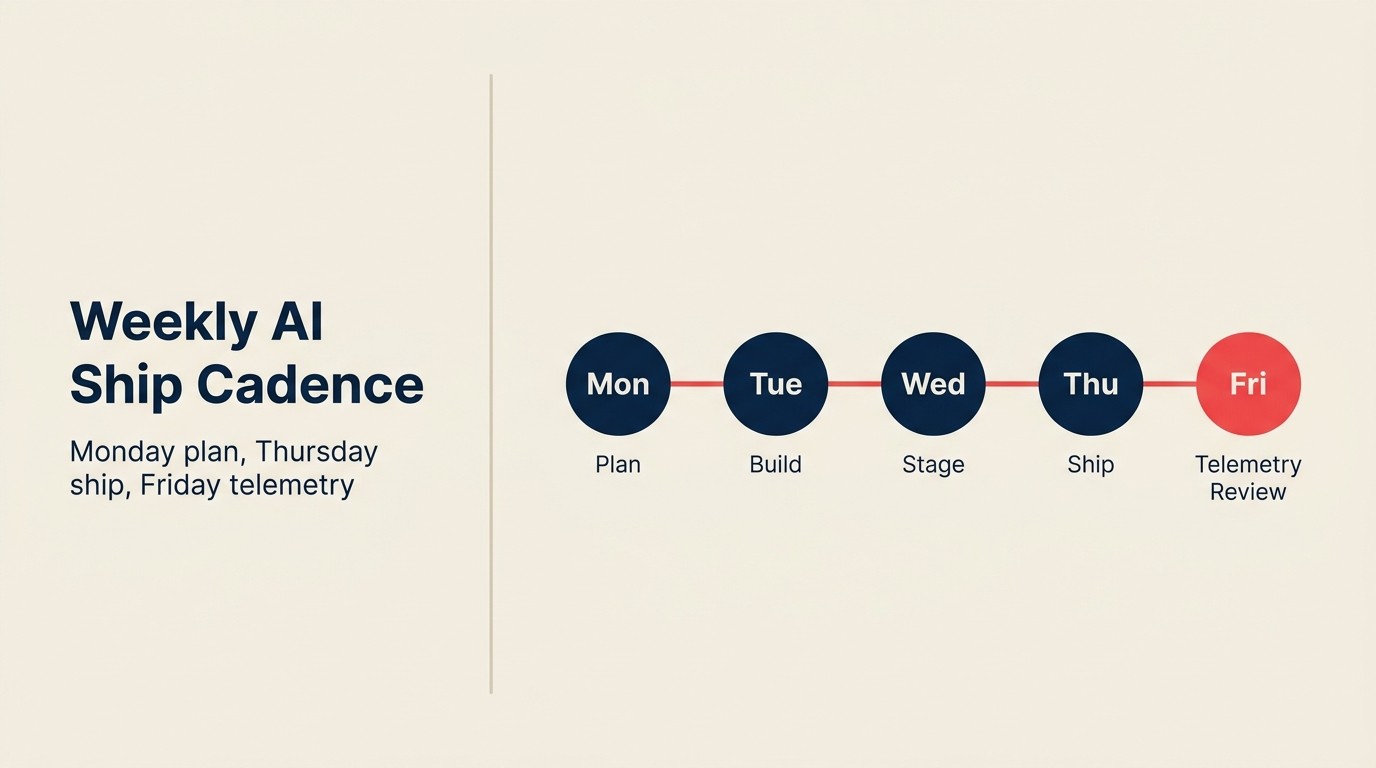
O Weekly AI Ship Cadence
O Weekly AI Ship Cadence é um framework operacional que define a infraestrutura, o processo e as condições culturais necessárias para lançar melhorias de funcionalidades de AI em um ciclo semanal em vez de trimestral. Infraestrutura: uma camada de abstração de API de LLM, controle de versão de prompt e um pipeline de telemetria. Processo: uma revisão semanal de métricas de AI onde os dados de taxa de aceitação e modificação são lidos e analisados; mudanças de prompt lançando na mesma semana em que são identificadas. Cultura: um entendimento compartilhado entre produto e engenharia de que a melhoria de AI é uma tarefa operacional contínua, não um projeto de engenharia periódico. Equipes que executam o Weekly AI Ship Cadence produzem funcionalidades de AI que melhoram conforme os usuários interagem. Equipes sem ele produzem funcionalidades estáticas que atingem um platô na qualidade do lançamento.
Por que a corrida armamentista é real
A corrida armamentista não é hype. É comportamento do comprador que mudou em 2024-2025 e não voltou.
As avaliações no G2 agora incluem avaliações de funcionalidades de AI como categoria. Compradores pesquisando ferramentas SaaS filtram por "essa ferramenta tem AI?" antes de chegar às comparações de preços. Os comitês de procurement corporativo em 2026 incluem capacidade de AI como critério de avaliação explícito em RFPs que nem a mencionariam em 2022.
De forma mais concreta: as pesquisas de NPS de SaaS mudaram. As pesquisas de NPS de equipes de suporte em 2023-2024 começaram a incluir perguntas sobre assistência de AI. As pesquisas de NPS de ferramentas de CS começaram a perguntar sobre pontuação de saúde por AI. O sinal dos clientes para os fornecedores SaaS foi claro: estamos avaliando sua AI e continuaremos avaliando.
Conforme a análise de Nível 4.1 do ACE Framework, a velocidade de iteração de funcionalidades de AI tornou-se um sinal de nível de categoria para a qualidade do produto. Os compradores não avaliam apenas se você tem AI. Eles analisam a cadência: com que frequência você está lançando melhorias de AI? Um changelog com lançamentos mensais de funcionalidades de AI sinaliza uma equipe com infraestrutura real de AI. Uma página de AI no seu site com funcionalidades que não mudaram em 6 meses sinaliza uma caixa marcada. A análise da McKinsey sobre modelos de negócios de SaaS na era de AI observa que a vantagem competitiva em software está migrando de funcionalidades para acesso a dados proprietários e velocidade de iteração, o que torna a cadência de lançamento de AI um proxy para posição estratégica, não apenas uma métrica de produto. Por que o SaaS é o adotante de AI de mais alta velocidade explica as razões estruturais pelas quais essa expectativa se formou mais rápido em SaaS do que em qualquer outra indústria.
Key Facts: Dinâmicas Competitivas de AI em SaaS
- Negócios SaaS com referência a AI compreenderam 72% de todas as transações SaaS em 2025, um aumento de 12x desde 2018; os compradores estão avaliando a capacidade de AI antes da comparação de preços (Software Equity Group, 2025)
- 64% dos CEOs de SaaS acreditam que a AI generativa está diminuindo as barreiras de entrada; funcionalidades básicas de AI construídas em APIs de LLM podem ser replicadas por um concorrente em 4-8 semanas (G2/Vendasta, 2025)
- Velocidade é necessária, mas não suficiente: narrativas de AI orientadas a funcionalidades não criam mais vantagem a menos que mudem como o trabalho é feito; funcionalidades de AI que são lançadas sem telemetry loops atingem um platô na qualidade de lançamento enquanto concorrentes com loops compõem melhorias semanalmente (Wing VC/McKinsey, 2025)
Como é a vantagem do pioneiro de verdade
O GitHub Copilot teve aproximadamente 18 meses de liderança de mercado antes do JetBrains AI Assistant, Cursor e outras ferramentas de codificação com AI alcançarem adoção significativa. Durante esses 18 meses, o GitHub construiu telemetry loops, refinou a qualidade das sugestões com dados de aceitação dos usuários e estabeleceu "Copilot" como o modelo mental padrão para assistência de codificação com AI. Os 18 meses importaram.
O Intercom Fin teve uma janela de liderança similar para deflexão de suporte com AI em primeiro lugar. Quando os concorrentes lançaram suas próprias ferramentas de suporte com AI em 2024, a Intercom já tinha resolvido a complexidade de integração, ajustado o comportamento de fallback e construído a confiança do cliente. O playbook estava visível. A diferença era real.
Mas a vantagem do pioneiro em funcionalidades de AI em SaaS não dura para sempre. Dura até que os concorrentes lançam uma alternativa viável, que é uma janela mais curta do que para funcionalidades sem AI, porque fazer wrap de uma API de LLM é genuinamente rápido. Você pode lançar uma funcionalidade de AI em MVP em 6-8 semanas. Seus concorrentes também podem.
O que torna a vantagem do pioneiro durável não é apenas ser o primeiro. É construir o telemetry loop durante a janela de liderança para que sua funcionalidade melhore mais rápido do que os concorrentes conseguem alcançar. A vantagem do Copilot do GitHub em 2026 não é ter lançado primeiro em 2022. São quatro anos de dados de aceitação que moldaram um modelo que uma empresa lançando hoje não consegue replicar no primeiro dia.
A velocidade importa mais quando você está criando uma nova categoria de funcionalidade de AI no seu mercado, não quando está alcançando uma funcionalidade que os concorrentes já têm.
O que a corrida armamentista pune
Lançar funcionalidades de AI que não funcionam é pior do que lançar tarde. Esta é a verdade contraintuitiva que se perde na pressão competitiva.
Funcionalidades sem AI que são lançadas com bugs são corrigidas. Os usuários estão acostumados com a iteração de software. Um filtro de lista quebrado é corrigido no próximo sprint. O modelo mental do usuário é "a funcionalidade tinha bugs, agora está corrigida."
Funcionalidades de AI que são lançadas com problemas de qualidade recebem uma resposta diferente. "A AI estava errada sobre o status da minha conta" não significa apenas que uma funcionalidade não funcionou. Significa que a AI não pode ser confiável. E uma vez que uma funcionalidade de AI perde a confiança de um usuário, reconstruir essa confiança é ordens de magnitude mais difícil do que corrigir um bug.
O chatbot de suporte que direciona um cliente para a documentação errada não apenas cria uma má interação de suporte. Cria um usuário que desativa ativamente o chatbot de AI e diz aos colegas para evitá-lo. Isso é um colapso de confiança que segue a funcionalidade por anos.
A AI de pontuação de saúde que classifica uma conta que está fazendo churn como "verde" não apenas produz uma pontuação errada. Treina seus CSMs a desconsiderar a AI. Uma vez que os CSMs param de confiar na pontuação de saúde, param de usá-la, e você gastou US$ 80.000/ano em uma assinatura do Gainsight que sua equipe depreciou mentalmente.
A confiança na funcionalidade de AI é o ativo. Velocidade sem qualidade a queima. Modos de falha de AI em SaaS documenta exatamente como a erosão de confiança se manifesta em diferentes tipos de funcionalidades de AI e quanto tempo a recuperação leva.
O cemitério de wrappers
Entre o início de 2023 e meados de 2024, centenas de produtos SaaS lançaram "funcionalidades de AI" que eram wrappers da API do GPT-4 com diferenciação mínima: uma interface de chat, um botão de sumarização, um campo de redação de email. Algumas dessas funcionalidades foram genuinamente úteis. A maioria não.
Os clientes que experimentaram essas funcionalidades em 2023 e as acharam de baixa qualidade em sua maioria seguiram em frente. Eles experimentaram a AI, não era boa o suficiente para justificar a mudança no fluxo de trabalho, e voltaram a fazer a tarefa manualmente. Fazer esses clientes tentarem a funcionalidade de AI novamente requer uma experiência materialmente melhor ou uma intervenção direta da equipe de produto.
Este é o cemitério de wrappers: funcionalidades de AI que foram lançadas para marcar uma caixa, foram adotadas brevemente, falharam em demonstrar valor acima da linha de base manual, e agora têm taxas de usuários ativos semanais de 3-5% enquanto a funcionalidade fica no changelog do produto como uma capacidade de AI.
O problema não é que fazer wrap do GPT-4 seja uma escolha técnica ruim. É que lançar um wrapper sem diferenciação e sem um telemetry loop para melhorá-lo não produz uma funcionalidade que se compõe. Produz uma funcionalidade que atinge um platô na qualidade de lançamento enquanto os concorrentes lançam funcionalidades de AI mais precisas e específicas ao fluxo de trabalho, ajustadas ao fluxo de trabalho exato.
O Notion AI sobreviveu à era dos wrappers não porque suas funcionalidades iniciais de escrita de AI eram dramaticamente melhores do que uma sessão do ChatGPT. Sobreviveram porque incorporaram a AI diretamente no fluxo de edição (zero fricção para usar), construíram telemetria sobre como os usuários aceitavam ou modificavam as sugestões, e iteraram semanalmente. A diferenciação está na integração com o fluxo de trabalho e na velocidade de melhoria, não no modelo subjacente. A próxima pergunta é qual infraestrutura torna essa velocidade possível.
O que velocidade para lançar realmente requer

"Lançar AI mais rápido" é frequentemente dito como se fosse uma decisão cultural. Não é. Velocidade é um resultado de infraestrutura.
A infraestrutura necessária para lançar funcionalidades de AI em cadência semanal:
Camada de integração de API de LLM: Um serviço backend que lida com chamadas de API, gerencia limites de taxa, registra solicitações e respostas, e pode trocar modelos subjacentes sem mudanças no frontend. Equipes sem essa camada arquitetural gastam tempo de engenharia em cada funcionalidade de AI reinventando a integração da API. Equipes com ela adicionam novas funcionalidades de AI escrevendo especificações de prompt, não código de infraestrutura.
Controle de versão de prompt: Mudanças de prompt são mudanças de código. Precisam de controle de versão, ambientes de teste e capacidade de rollback. Equipes que armazenam prompts em variáveis de ambiente e os implantam com mudanças de código de produção não conseguem iterar semanalmente. Equipes com uma camada de gerenciamento de prompt (LangSmith, Helicone ou um sistema personalizado) conseguem.
Pipeline de telemetria: Como coberto em Telemetry Loops para AI no Produto, o loop que captura eventos de sugestão, ações do usuário e feedback de resultado. Sem isso, lançar mais rápido apenas produz mais funcionalidades estáticas. Com ele, cada funcionalidade lançada começa a gerar sinal de melhoria desde o primeiro dia.
Capacidade de product manager de AI: PMs que conseguem escrever especificações de funcionalidades de AI tecnicamente precisas. "Adicionar AI para ajudar os usuários a escrever emails melhores" não é uma especificação de funcionalidade. "Adicionar uma sugestão de reescrita que dispara quando o usuário faz uma pausa por 3 segundos no campo de corpo do email, passa o contexto completo do email e dados de CRM do destinatário para o Claude 3.5 Sonnet com um prompt de refinamento de tom, e registra eventos de aceitar/editar/dispensar com o Segment" é uma especificação de funcionalidade. A diferença em tempo da especificação para o lançamento é de semanas.
Equipes que têm essa infraestrutura lançam funcionalidades de AI em 4-6 semanas. Equipes sem ela levam 12-16 semanas e produzem resultados de menor qualidade.
"Lançar funcionalidades de AI que não funcionam é pior do que lançar tarde. Funcionalidades sem AI que são lançadas com bugs são corrigidas. Funcionalidades de AI que são lançadas com problemas de qualidade perdem a confiança do usuário. E uma vez que uma funcionalidade de AI perde a confiança de um usuário, reconstruir essa confiança é ordens de magnitude mais difícil do que corrigir um bug. A confiança na funcionalidade de AI é o ativo. Velocidade sem qualidade a queima." (Rework Analysis, 2025)
"Fazer wrap do GPT-4 não é uma escolha técnica ruim. Lançar um wrapper sem diferenciação e sem um telemetry loop para melhorá-lo não produz uma funcionalidade que se compõe. Produz uma funcionalidade que atinge um platô na qualidade de lançamento enquanto os concorrentes lançam funcionalidades de AI mais precisas e específicas ao fluxo de trabalho. O cemitério de wrappers está cheio de funcionalidades tecnicamente corretas com zero adoção no sexto mês." (Rework Analysis, 2025)
Lançamento de Funcionalidades de AI: Matriz de Trade-off Velocidade-Qualidade
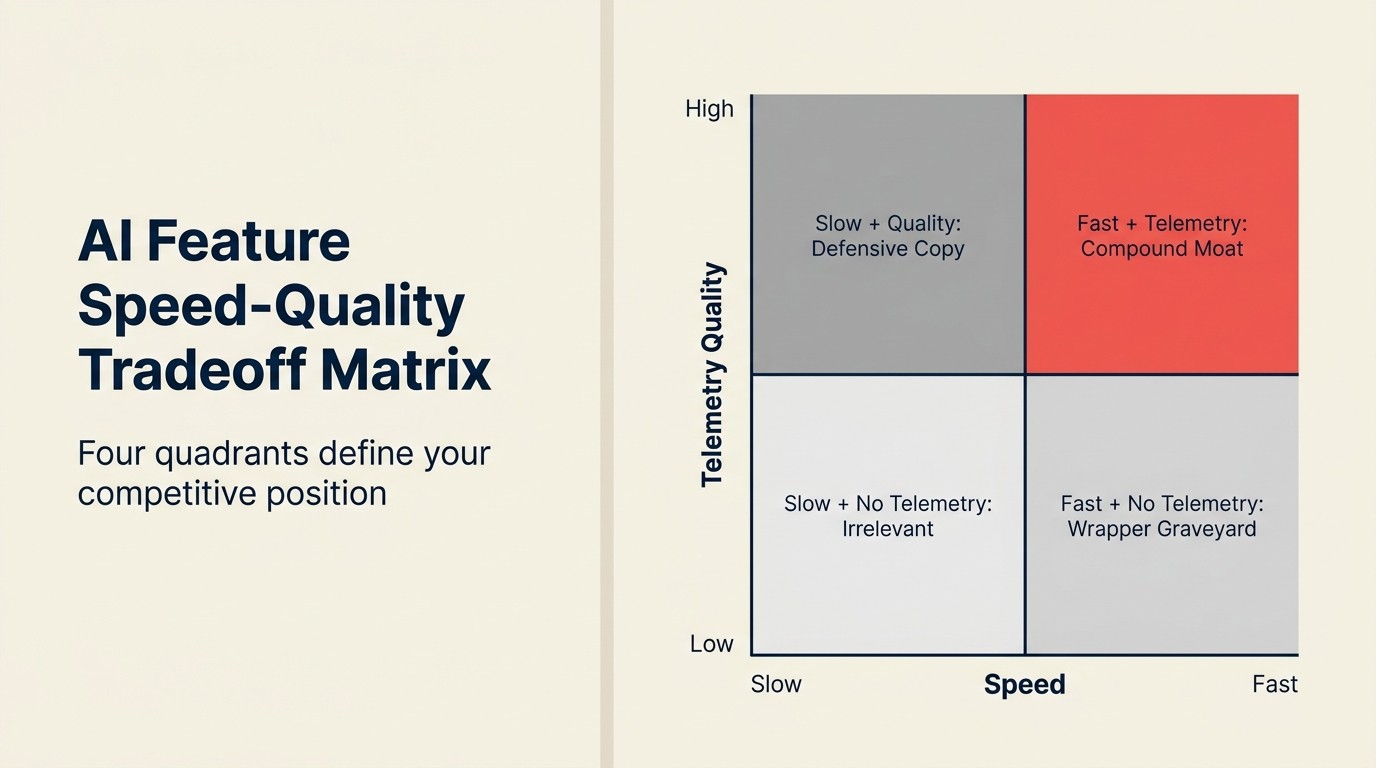
| Abordagem de Lançamento | Tempo para o Mercado | Adoção da Funcionalidade (90 dias) | Fosso Competitivo | Perfil de Risco |
|---|---|---|---|---|
| Rápido com telemetry loop | 4-6 semanas | 40-70% WAU | Constrói conforme o loop se compõe | Baixo: funcionalidades melhoram após o lançamento |
| Rápido sem telemetry loop | 4-6 semanas | 3-10% WAU | Nenhum; replicável em 4-8 semanas | Alto: paralisa na qualidade de lançamento |
| Lento com gate de qualidade | 12-16 semanas | 30-55% WAU | Moderado no lançamento | Médio: concorrentes podem lançar primeiro |
| Cópia defensiva (seguindo concorrente) | 6-10 semanas | Equipara adoção do concorrente | Apenas paridade | Médio: paridade, não vantagem |
Fontes: Wing VC AI Arms Race Analysis 2025, McKinsey AI-Era SaaS Business Models Research 2025, dados de adoção do GitHub Copilot 2025
Rework Analysis: O teste de calibração para saber se uma funcionalidade de AI está pronta para ser comercializada como diferenciadora: sua funcionalidade de AI é mencionada espontaneamente em pesquisas de NPS? Se sim, lance e a comercialize. Se você precisa procurá-la em respostas marcadas, ainda não está diferenciando. A pontuação de prioridade de AI do Linear é mencionada espontaneamente em pesquisas de NPS de equipes de engenharia. O Notion AI é mencionado espontaneamente em pesquisas de equipes de marketing. Ambas as equipes ganharam esse posicionamento lançando com um loop de aprendizado implementado, não por serem as primeiras no mercado.
Lançamento defensivo vs. ofensivo de AI
A corrida armamentista cria duas pressões estratégicas diferentes que requerem respostas diferentes.
O lançamento defensivo de AI é igualar uma funcionalidade que seus concorrentes acabaram de lançar porque os compradores estão perguntando sobre ela. Isso é reativo e necessário. Quando o Intercom Fin foi lançado, todo SaaS de suporte teve que lançar uma história credível de deflexão por AI em 12-18 meses ou aceitar a evasão de clientes para a Intercom. O lançamento defensivo é sobre paridade de funcionalidades.
O erro com o lançamento defensivo é tratá-lo como uma estratégia de produto. Igualar as funcionalidades de AI dos concorrentes mantém você no jogo. Não cria um fosso. Se você lançou um AI de coaching de chamadas porque o Gong tem um, você precisa que o Gong continue tendo um como razão para ficar. Sua funcionalidade de AI precisa eventualmente ganhar sua própria diferenciação.
O lançamento ofensivo de AI é lançar uma categoria de funcionalidade antes que os concorrentes façam. Isso requer uma vantagem de dados proprietários (sua plataforma gera dados que habilitam uma funcionalidade de AI que outros não conseguem construir) ou um insight genuíno de fluxo de trabalho (um fluxo de trabalho onde a AI cria valor que os concorrentes ainda não identificaram). Funcionalidades de AI como produto: onde adicioná-las é o framework para encontrar esses insights de fluxo de trabalho antes que os concorrentes o façam.
A priorização de issues por AI do Linear é um exemplo de lançamento ofensivo: eles identificaram que a priorização de tickets de equipes de engenharia era um caso de uso de AI genuinamente mal atendido em gestão de projetos, construíram a funcionalidade antes que o Jira e o Asana tivessem equivalentes, e estabeleceram um padrão de qualidade com dados de telemetria que agora é um custo real de migração para equipes de engenharia que a usaram.
O lançamento ofensivo cria vantagem do pioneiro. O lançamento defensivo previne a desvantagem do pioneiro. Você precisa de ambos, mas são investimentos diferentes.
O risco de posicionamento AI-native
Um número crescente de empresas SaaS está se comercializando como "AI-native." Algumas são. A maioria não é.
AI-native significa que a AI está no fluxo central do produto, não acoplada a ele. Significa que a proposta de valor do produto depende parcialmente da qualidade da AI, e as melhorias na qualidade da AI melhoram diretamente os resultados do cliente. Não significa que você tem um botão de AI na interface.
O risco de reivindicar posicionamento AI-native antes de merecê-lo: os clientes avaliam. Um comprador que escolhe seu produto em parte por causa do posicionamento AI-native e depois descobre que as funcionalidades de AI são superficiais vai se sentir vendido. Isso é churn com uma história anexada, e histórias viajam. A pesquisa da McKinsey sobre o imperativo de software centrado em AI descreve essa lacuna de credibilidade diretamente: à medida que os produtos AI+SaaS cada vez mais executam trabalho em vez de apenas apoiá-lo, os clientes conseguem medir a diferença entre a capacidade de AI declarada e a real, e o desalinhamento nisso colapsa a confiança mais rápido do que quase qualquer outro modo de falha de produto.
O teste de calibração: sua funcionalidade de AI é algo que um cliente menciona espontaneamente em uma pesquisa de NPS? Se sim, é diferenciadora o suficiente para comercializar. Se você precisa procurá-la em respostas marcadas, ainda não chegou lá.
O Linear é mencionado espontaneamente em pesquisas de NPS de equipes de engenharia por suas funcionalidades de AI. O Notion AI é mencionado em pesquisas de NPS de equipes de marketing. Esses são os produtos que ganharam o posicionamento AI-native. Eles ganharam lançando qualidade, medindo adoção e iterando semanalmente com base em telemetria.
Lance rápido com um loop de aprendizado
As empresas que estão vencendo a corrida armamentista de AI em 2026 não são as que lançaram mais funcionalidades de AI. São as cujas funcionalidades de AI foram realmente usadas, geraram telemetria e melhoraram.
O Coda lança funcionalidades de AI a cada duas semanas. O Linear tem melhorias de AI na maioria dos changelogs mensais. As funcionalidades de escrita do Notion AI em 2026 se comportam de forma significativamente diferente do seu lançamento de 2023 porque 3 anos de dados de aceitação as moldaram. Essas não são coincidências. São o resultado de lançar com um loop implementado.
Velocidade sem aprendizado é como você acaba no cemitério de wrappers. Velocidade com aprendizado é como você constrói um fosso que se compõe.
A postura competitiva certa: lance rápido o suficiente para manter-se relevante nas comparações dos compradores, mas nunca mais rápido do que sua infraestrutura permite aprender. Se você está lançando funcionalidades de AI sem telemetria, não está vencendo a corrida armamentista. Está apenas queimando recursos de engenharia sem compor.
Construa o loop primeiro. Depois lance o mais rápido que o loop permitir.
Perguntas Frequentes
Por que a corrida armamentista de AI em SaaS é real e não apenas hype?
O comportamento do comprador mudou em 2024-2025 e não voltou. As avaliações no G2 agora incluem avaliações de funcionalidades de AI como categoria. Os comitês de procurement corporativo incluem capacidade de AI como critério de avaliação explícito nos RFPs. As pesquisas de NPS de SaaS começaram a perguntar sobre assistência de AI. O sinal dos clientes para os fornecedores SaaS é claro: estamos avaliando sua AI e continuaremos avaliando. Negócios referenciados por AI compreenderam 72% de todas as transações SaaS em 2025, um aumento de 12x desde 2018.
Quanto tempo dura a vantagem do pioneiro nas funcionalidades de AI em SaaS?
Até que os concorrentes lançam uma alternativa viável, que é uma janela mais curta do que para funcionalidades sem AI. Uma funcionalidade de AI em MVP construída em uma API de LLM pode ser lançada em 6-8 semanas. A vantagem do pioneiro só se torna durável se a equipe líder construir um telemetry loop durante a janela de liderança. A vantagem do Copilot do GitHub em 2026 não é de ter lançado primeiro em 2022. São quatro anos de dados de aceitação que moldaram um modelo que um novo entrante não consegue replicar no primeiro dia.
O que é o cemitério de wrappers?
Funcionalidades de AI construídas como wrappers genéricos de API de LLM com diferenciação mínima e sem telemetry loop. Essas funcionalidades foram adotadas brevemente em 2023-2024, falharam em demonstrar valor acima da linha de base manual, e agora têm taxas de usuários ativos semanais de 3-5%. O problema não é a escolha técnica. É lançar sem diferenciação e sem um loop. Wrappers genéricos atingem um platô na qualidade de lançamento enquanto os concorrentes lançam funcionalidades mais precisas e específicas ao fluxo de trabalho que se compõem a partir dos dados do usuário.
Qual infraestrutura é necessária para lançar funcionalidades de AI em cadência semanal?
Três componentes. Camada de integração de API de LLM: um serviço backend que lida com chamadas de API, gerencia limites de taxa e pode trocar modelos subjacentes sem mudanças no frontend. Controle de versão de prompt: mudanças de prompt tratadas como mudanças de código com controle de versão, ambientes de teste e capacidade de rollback. Pipeline de telemetria: captura de eventos estruturados para aceitação de sugestão, modificação e resultados. Equipes com essa infraestrutura lançam melhorias de AI em 4-6 semanas. Equipes sem ela levam 12-16 semanas e produzem resultados de menor qualidade.
Qual é a diferença entre o lançamento defensivo e ofensivo de AI?
O lançamento defensivo iguala uma funcionalidade que os concorrentes acabaram de lançar. É reativo e necessário para manter a paridade. O lançamento ofensivo lança uma categoria de funcionalidade antes que os concorrentes o façam, requerendo uma vantagem de dados proprietários ou um insight de fluxo de trabalho que os concorrentes não identificaram. O lançamento defensivo mantém você no jogo, mas não cria um fosso. O lançamento ofensivo cria vantagem do pioneiro. Você precisa de ambos, mas requerem investimentos e métricas de sucesso diferentes.
Como você sabe quando uma funcionalidade de AI está diferenciando o suficiente para comercializar?
O teste de calibração: a funcionalidade é mencionada espontaneamente em pesquisas de NPS? Se sim, comercialize. Se você precisa pesquisar em respostas marcadas, a funcionalidade ainda não está diferenciando. A pontuação de prioridade de AI do Linear e o Notion AI ambos recebem menções espontâneas de NPS. Ambas as equipes ganharam esse posicionamento lançando com gates de qualidade e loops de aprendizado, não por serem as primeiras no mercado.
Saiba Mais:
- Telemetry Loops para AI no Produto: a infraestrutura que torna "lançar rápido com um loop de aprendizado" real
- Modos de Falha de AI em SaaS: como a erosão de confiança se manifesta e quanto tempo a recuperação leva
- Funcionalidades de AI como Produto: Onde Adicioná-las: o framework para identificar oportunidades de lançamento ofensivo
- Buy vs. Build para Funcionalidades de AI em SaaS: a decisão que determina a rapidez com que você pode lançar
- Por que a Maioria das Transformações de AI Falha: o contexto estratégico para por que velocidade sem qualidade destrói valor

Co-Founder, Rework.com
On this page
- O Weekly AI Ship Cadence
- Por que a corrida armamentista é real
- Como é a vantagem do pioneiro de verdade
- O que a corrida armamentista pune
- O cemitério de wrappers
- O que velocidade para lançar realmente requer
- Lançamento de Funcionalidades de AI: Matriz de Trade-off Velocidade-Qualidade
- Lançamento defensivo vs. ofensivo de AI
- O risco de posicionamento AI-native
- Lance rápido com um loop de aprendizado