Roteamento AI Multi-Tier no Help Desk SaaS
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
O modelo clássico de atribuição de help desk é round-robin ou primeiro disponível. Quem estiver livre pega o próximo ticket na fila.
O resultado é previsível. Uma disputa de cobrança vai para um novo contratado que não tem visibilidade da conta. Uma pergunta complexa de integração de API vai para um desenvolvedor sênior que não deveria estar gastando tempo na fila de suporte geral. A preocupação com renovação de um cliente enterprise cai com um agente júnior que não conhece o histórico da conta. E um bot de AI que poderia ter tratado uma simples pergunta de como fazer encaminha para um humano porque a lógica de roteamento não sabe a diferença.
O roteamento AI multi-tier resolve isso. A AI classifica cada ticket antes que qualquer humano o veja, pontua sua complexidade, verifica o tier de conta do cliente e o atribui ao atendente certo no tier certo. O ganho de eficiência é real, mas só se sustenta se o modelo operacional por trás do roteamento for projetado corretamente.
O que Significa Roteamento Multi-Tier
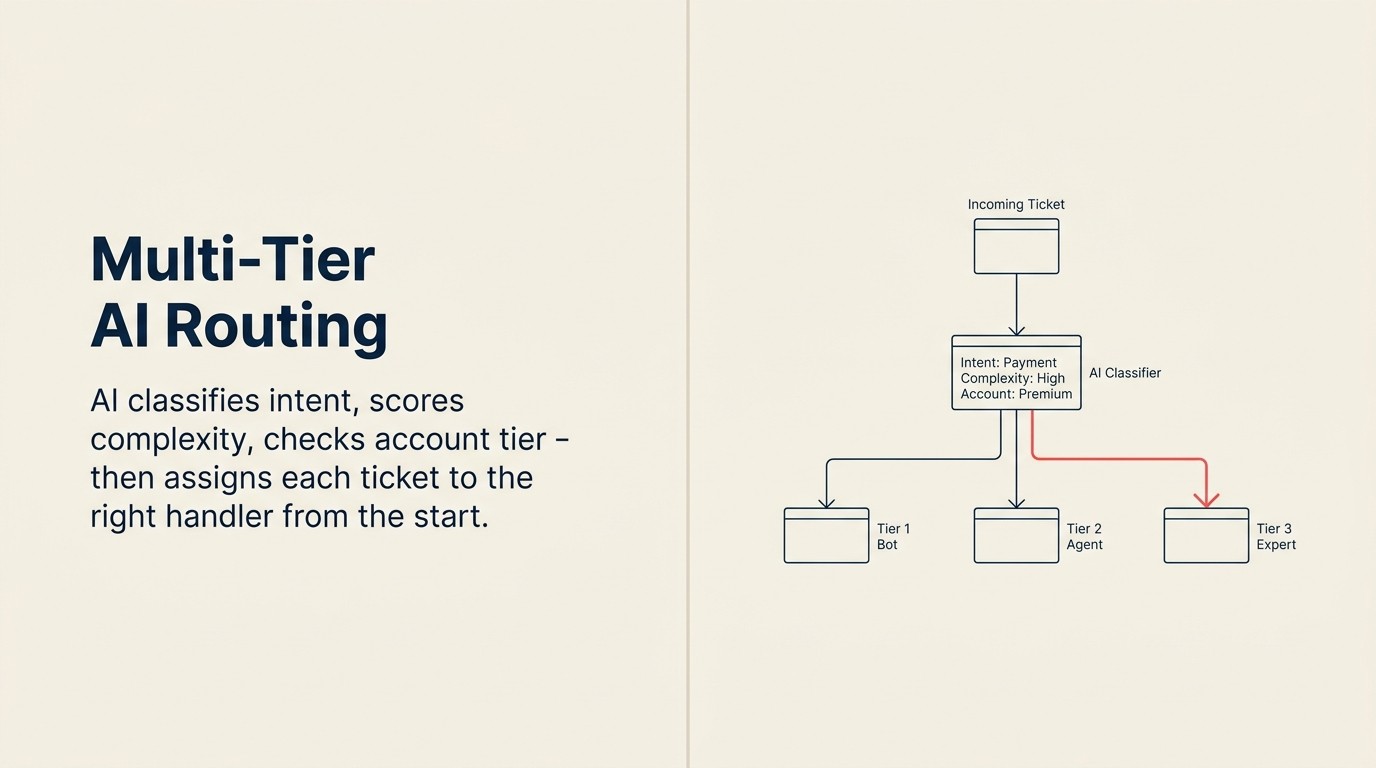
Um modelo de três tiers é a estrutura padrão para operações de suporte SaaS que executam roteamento AI.
Tier 1 (L1): Self-service AI. O RAG Assistant tenta resolver o ticket completamente. Se bem-sucedido, o ticket é encerrado sem envolvimento humano. São perguntas de como fazer, buscas de documentação, resoluções de código de erro conhecidas, perguntas de comparação de planos e guias de configuração de integração. A deflexão de L1 é a taxa de deflexão que você reporta.
Tier 2 (L2): Agente humano aumentado por AI. Um humano pega o ticket com assistência de AI: uma resposta sugerida da base de conhecimento, um resumo do histórico de conta do cliente e links de documentação relevantes já trazidos à superfície. O agente revisa, edita se necessário e responde. São problemas moderadamente complexos que precisam de julgamento humano, mas se beneficiam da preparação de AI. A maioria das perguntas técnicas de suporte padrão cai aqui.
Tier 3 (L3): Atendimento humano especializado. Agentes sêniors, desenvolvedores ou gerentes de conta que tratam tickets complexos, sensíveis ou de alto valor. Problemas escalados de conta, bugs que requerem investigação de engenharia, solicitações de privacidade de dados, disputas de cobrança, conversas de churn potencial. Sem tentativa de self-service AI; roteamento direto para especialista com contexto completo.
O trabalho do sistema de roteamento é determinar qual tier trata qual ticket, e fazê-lo com precisão suficiente para que o atendente certo receba cada ticket sem criar gargalos em nenhum tier.
Key Facts: Precisão e Eficiência do Roteamento AI
- Agentes de suporte com AI generativa alcançam 92% de precisão na compreensão da intenção do cliente, em comparação com 65-70% para bots mais antigos baseados em palavras-chave (AI Business Weekly, 2026)
- O roteamento com AI reduz o tempo médio de atendimento em 40% ao garantir que os tickets cheguem ao agente ou sistema certo na primeira tentativa (Unthread, 2026)
- A precisão da classificação em ambientes maduros de ticketing com AI reduz erros de roteamento incorreto em 50-60% em comparação com a atribuição round-robin ou pelo primeiro disponível (Fini Labs, 2026)
O Modelo de Triagem Intent-Tier-Context
O Modelo de Triagem Intent-Tier-Context é um framework de decisão de roteamento de três fatores para help desks SaaS. Intent determina a atribuição base de tier: uma pergunta de como fazer vai para AI L1, um relatório de bug vai para L2, uma preocupação de segurança vai para L3 imediatamente. Tier aplica sobreposições no nível de conta: a pergunta de como fazer de um cliente enterprise vai para L2 no mínimo, independentemente da classificação de intenção. Context aplica ajustes dinâmicos: um ticket de um cliente na janela de renovação de 60 dias com pontuações de saúde em declínio vai para a fila do gerente de conta independentemente do tipo de problema declarado. Os três fatores são executados em sequência, com cada camada capaz de substituir a atribuição anterior.
O Padrão de Scoring e Roteamento Aplicado
O Scoring and Routing Pattern do ACE Framework descreve exatamente como isso funciona: Ingest do ticket recebido, Analyze suas características (intenção, complexidade, dados do cliente), Predict o tier apropriado e Execute a atribuição de roteamento.
A classificação de intenção é o input primário. A AI lê o texto do ticket e o classifica em uma das várias categorias de intenção: solicitação de como fazer, relatório de bug, pergunta de cobrança, solicitação de funcionalidade, escalada ou reclamação, preocupação de segurança, pergunta de API ou desenvolvedor, ajuda de onboarding. Cada categoria tem uma atribuição de tier padrão, que é então ajustada com base na complexidade e no tier do cliente.
O scoring de complexidade adiciona nuance à classificação de intenção. Uma pergunta de como fazer de um cliente enterprise que está esperando uma resposta há três dias sobre um workflow técnico de múltiplas etapas não é o mesmo ticket que uma pergunta de como fazer de um usuário de teste SMB sobre uma configuração básica. A intenção diz a mesma coisa; o scoring de complexidade os encaminha de forma diferente.
A combinação de intenção mais complexidade mais tier de cliente é o que torna o roteamento inteligente em vez de apenas categórico. Uma vez que o sistema classifica, a precisão se torna o próximo desafio.
Classificação de Intenção na Prática
O Zendesk AI classifica tickets recebidos em buckets de intenção usando um modelo treinado em dados históricos de tickets. Você fornece as categorias e o modelo aprende a partir de tickets que agentes humanos categorizaram anteriormente. Os dados de treinamento são seu próprio histórico de tickets, o que torna o modelo cada vez mais preciso em refletir como sua equipe historicamente roteou tickets.
O Freshdesk Freddy opera de forma similar: classificação de intenção com base em categorização histórica, com propriedades do ticket (linha de assunto, texto do corpo, presença de anexo) como características. Ambos os sistemas permitem que você defina limiares de confiança: se a confiança da classificação estiver abaixo de um nível definido, o ticket vai para uma fila de revisão humana em vez de ser atribuído automaticamente.
O Intercom Fin usa lógica de roteamento de conversa que fica em cima da intenção: tenta resolução AI primeiro para tipos de tickets qualificados e passa para agentes humanos com contexto completo quando a AI não consegue resolver.
O passe de treinamento inicial geralmente é executado em 90 dias de tickets históricos. A maioria das equipes descobre que a precisão de classificação de intenção atinge 80-85% no primeiro deploy com seis a doze meses de dados históricos, e melhora para mais de 90% após três a quatro meses de roteamento em produção onde erros de classificação são corrigidos e realimentados ao modelo. A Gartner identifica maior precisão de triagem e identificação de especialistas como drivers centrais de valor AI em atendimento ao cliente, o que se mapeia diretamente para a qualidade de classificação de roteamento que você está construindo.
Regras de Roteamento por Tier de Conta
O tier de cliente é o override mais importante na roteamento baseado em intenção para negócios SaaS com tiers de clientes diferenciados.
A regra é simples e deve ser codificada explicitamente, não aprendida: clientes enterprise não passam pelo self-service AI L1 como primeiro ponto de contato, a menos que optem proativamente por isso. Eles são encaminhados para L2 no mínimo, com disponibilidade de L3 com base no tipo de ticket.
O motivo é comercial, não técnico. Clientes enterprise estão pagando um annual recurring revenue (ARR) significativo por um nível de serviço mais alto. Um cliente enterprise que envia um ticket de suporte e recebe uma resposta de chatbot de AI antes de qualquer reconhecimento humano tem uma expectativa de serviço diferente de um usuário de teste SMB. Atender a essa expectativa faz parte do produto para contas de alto tier.
Usuários de teste SMB e clientes mensais de baixo ARR são os alvos corretos de self-service AI L1. Eles se beneficiam de respostas rápidas e 24/7 de AI, e a economia de tratar seus tickets via AI em vez de agentes humanos é favorável. Mas aplique self-service AI ao seu cliente enterprise de $200.000 e você cometeu um erro de posicionamento independentemente de a AI ter respondido corretamente.
Configure essas regras explicitamente em sua lógica de roteamento. O Zendesk AI permite regras de roteamento baseadas em tier de cliente. O Intercom suporta isso por meio de condições de roteamento de conversa com base em atributos do cliente. O Freshdesk usa regras de atribuição baseadas em segmento. A ferramenta de roteamento é um detalhe. A regra em si deve ser uma decisão de política tomada pela liderança de suporte, não deixada para a inferência de um algoritmo.
Sinais de Roteamento Específicos para SaaS
Além da intenção e do tier do cliente, certas características de ticket devem acionar decisões de roteamento imediato, independentemente de outros fatores.
Erros de autenticação de API são encaminhados para suporte a desenvolvedores ou a um agente humano qualificado para desenvolvedores. Não são perguntas de suporte geral. Requerem alguém que possa investigar problemas de token OAuth, configuração de chave de API e debug específico de integração. Encaminhar um erro de auth de API para um agente de suporte geral desperdiça o tempo de todos e aumenta o tempo de resolução significativamente.
Perguntas de cobrança durante a janela de renovação. Quando uma conta está na janela de renovação de 60 dias, perguntas de cobrança são encaminhadas para gestão de conta, não para suporte de cobrança geral. O gerente de conta precisa de visibilidade, e a conversa é tanto uma conversa de retenção quanto uma consulta de cobrança. Previsão de churn com AI em modelos de assinatura aborda como os dados de health score alimentam essa lógica de roteamento na janela de renovação.
Palavras-chave relacionadas à segurança. Tickets contendo termos relacionados a acesso não autorizado, suspeita de violação de dados, comprometimento de conta ou atividade de login incomum são encaminhados diretamente para L3 e geram um alerta imediato. Sem tentativa de self-service AI, sem espera em L2. Preocupações de segurança vão para um humano sênior imediatamente.
Sinais explícitos de "cancelar" ou "churn". Tickets contendo linguagem sobre cancelamento, comparação com concorrentes ou expressões de insatisfação significativa são encaminhados para um humano com contexto de CS trazido à superfície, não para suporte geral. A conversa passou de suporte para retenção.
Esses overrides baseados em sinal são configurados como regras de roteamento, não como comportamentos aprendidos. Devem ser determinísticos: se um ticket contém uma palavra-chave relacionada à segurança, vai para L3. Sempre.
Qualidade de Escalada: Handoff de Contexto
O roteamento determina para onde vai um ticket. Mas roteamento sem contexto cria uma experiência pior do que roteamento com ele.
Quando a AI passa para um agente humano, o agente deve receber: o histórico completo de conversa do cliente, o que a AI tentou (se tentou uma resposta), por que a AI não conseguiu resolver (baixa confiança, palavra-chave sinalizada, tier de cliente), os dados da conta do cliente (tempo como cliente, ARR, health score, histórico recente de suporte) e links de documentação relevantes sugeridos pela recuperação RAG.
Um handoff frio é quando o cliente repete toda a sua pergunta ao agente humano porque o agente não tem contexto da interação com a AI. Handoffs frios prejudicam significativamente a satisfação do cliente (CSAT). A experiência do cliente é: já expliquei isso para um bot, agora tenho que explicar de novo para uma pessoa. Essa não é uma experiência perfeita. São duas conversas separadas e desconectadas.
O Intercom Fin preserva explicitamente o contexto da conversa por meio de handoffs. O agente humano vê o thread completo, o que o Fin tentou e por que a conversa chegou até ele. O Zendesk AI passa o contexto da conversa junto com o ticket. Isso é um requisito mínimo para um sistema de roteamento bem implementado: handoffs devem ser invisíveis para o cliente à medida que o contexto é transferido.
Prevenindo Gargalos de Escalada
O modo de falha do roteamento mal ajustado é um gargalo de escalada. Se o modelo de roteamento for muito conservador, muitos tickets são atribuídos a L2 ou L3 que a AI ou um agente L2 júnior deveria ter tratado. Engenheiros sêniors passam seu tempo em tickets que não precisam de sua expertise. O tempo de resolução aumenta em geral.
É por isso que a otimização de roteamento é uma tarefa operacional contínua, não uma configuração única.
Execute uma auditoria de roteamento mensal. Extraia os tickets L3 do mês passado. Que percentual deles foi categorizado como L3 corretamente? Dos que poderiam ter sido tratados em L2, por que foram escalados? Foi uma intenção mal classificada? Um limiar de complexidade excessivamente conservador? Uma regra de tier de conta muito ampla?
Da mesma forma, audite as tentativas de deflexão de AI L1 que foram escaladas. Dessas, que percentual foi escalado porque o cliente indicou que a resposta da AI estava incorreta versus porque o cliente queria um humano independentemente da qualidade da AI? A primeira categoria é uma lacuna de documentação. A segunda é comportamento de escalada aceitável.
Construa capacidade de L2 proativamente. O gargalo de escalada mais comum é capacidade insuficiente de L2. Quando a deflexão de AI está funcionando (digamos, 40% dos tickets deflectidos em L1), os tickets restantes são mais inclinados à complexidade. O ticket L2 médio é mais difícil do que o ticket médio era antes do roteamento AI, porque os fáceis agora estão sendo deflectidos. Se você mantiver L2 com o mesmo número de pessoas de antes da implantação de AI, os agentes estão tratando tickets mais difíceis no mesmo volume e se esgotando mais rápido.
Planeje para isso. O roteamento AI aumenta a eficiência em L1. Concentra complexidade em L2 e L3. O planejamento de headcount e especialização precisa se ajustar de acordo. A Gartner relata que 91% dos líderes de atendimento ao cliente estão sob pressão executiva para implementar AI não apenas por eficiência, mas para melhorar a satisfação, o que significa que as decisões de planejamento de capacidade afetam diretamente se o roteamento AI é visto como sucesso ou responsabilidade pela liderança. Como a AI reformula o modelo operacional SaaS aborda o que essa concentração de função significa para a estrutura da equipe em escala.
"Sistemas de roteamento AI treinados em 6-12 meses de dados históricos de tickets atingem 80-85% de precisão de classificação de intenção no primeiro deploy. Com 3-4 meses de correções de produção realimentadas ao modelo, a precisão melhora para mais de 90%. A melhoria não é automática. Requer uma auditoria mensal de roteamento onde tickets mal classificados são rotulados e resubmetidos ao treinamento." (Zendesk AI Classification Documentation, 2025)
"O roteamento AI concentra complexidade em L2 e L3 após a deflexão. Se a deflexão L1 está funcionando a 40%, o ticket L2 médio é mais difícil do que o ticket médio antes do roteamento AI ser implantado, porque os fáceis agora estão deflectidos. Manter L2 com os níveis de pré-AI enquanto se espera taxas de deflexão pós-AI é o caminho mais rápido para burnout de L2 e colapso de CSAT." (Rework Analysis, baseado em pesquisa de AI de atendimento ao cliente da Gartner, 2025)
Benchmarks de Desempenho de Roteamento
| Métrica de Roteamento | Alvo | Limiar de Alerta | Ação |
|---|---|---|---|
| Precisão de classificação de intenção | 85-92% | Abaixo de 80% | Retreinar com erros de classificação corrigidos |
| Taxa de redirecionamento incorreto L1 (re-escalada imediata) | Abaixo de 12% | Acima de 15% | Restringir critérios de elegibilidade L1 |
| Primeiro tempo de resposta em L2 vs. linha de base pré-AI | Mais rápido | Mais lento | Verificar staffing de L2 e adoção de assistência AI |
| Tickets L3 classificados corretamente | Acima de 90% | Abaixo de 85% | Auditar regras de gatilho de escalada L2-L3 |
Fontes: Zendesk AI Ticket Classification Documentation 2025, Gartner Customer Service AI Benchmark 2025, Fini Labs Routing Analysis 2026
Rework Analysis: O número de precisão do modelo de roteamento (85-92%) é frequentemente tratado como a métrica de resultado. Não é. O roteamento está correto quando o especialista certo recebe o ticket na primeira atribuição, não apenas quando o sistema o categorizou corretamente. Uma disputa de cobrança corretamente classificada como "cobrança", mas encaminhada a um agente júnior de cobrança sem contexto de conta, está tecnicamente classificada, mas operacionalmente incorreta. A medição real é a taxa de resolução na primeira atribuição: que percentual dos tickets foi resolvido pelo primeiro humano que os recebeu, sem re-escalada? Esse número, acompanhado por tier e tipo de ticket, informa se o roteamento está funcionando operacionalmente ou apenas categoricamente.
Métricas para Qualidade de Roteamento
Quatro métricas dizem se seu modelo de roteamento está funcionando.
Primeiro tempo de resposta por tier. A resposta de AI L1 deve ser quase instantânea (segundos). L2 humano-assistido deve ser mais rápido do que a linha de base sem assistência, porque os agentes não estão começando do zero. L3 deve refletir tempo até o especialista, não tempo até a fila. Se o tempo de resposta de L2 é pior do que a linha de base pré-AI, o roteamento está criando atrito, não eficiência.
Taxa de resolução por tier. Que percentual dos tickets L1 fecham sem escalada? Que percentual dos tickets L2 fecham sem escalada L3? Taxas de resolução em declínio em um tier indicam que o roteamento está enviando tickets para aquele tier que ele não deveria estar tratando.
Taxa de redirecionamento incorreto. Tickets atribuídos a L1 e depois escalados imediatamente para L2 ou L3, ou tickets atribuídos a L2 que um agente júnior escalou imediatamente sem tentar resolução. Esses são erros de roteamento. Uma taxa de redirecionamento incorreto acima de 15% em L1 ou L2 sinaliza que o modelo de roteamento precisa de retreinamento.
Relação taxa de escalada vs. taxa de deflexão. À medida que sua taxa de deflexão aumenta, sua taxa de escalada para o pool de tickets restante naturalmente também aumenta (porque os tickets restantes são mais difíceis). Se as escaladas estão crescendo mais rápido do que a taxa de deflexão, o modelo de roteamento está falhando em conter a complexidade no tier certo.
Conectando ao Stack de Suporte AI
O roteamento multi-tier é o modelo operacional que permite que a deflexão AI escale. Sem ele, adicionar self-service AI a um help desk mal roteado cria filas de escalada em vez de eficiência. Os tickets que a AI não consegue tratar se acumulam nos agentes humanos sem contexto, sem priorização e sem o especialista certo recebendo o ticket certo.
AI Support Agent for SaaS Self-Service aborda a camada AI L1 em profundidade, incluindo quais tipos de tickets o RAG trata bem e onde a escalada deve acontecer imediatamente.
Ticket Deflection with RAG in SaaS Support aborda o lado da qualidade de deflexão: como medir se os tickets deflectidos são realmente resolvidos de forma satisfatória, não apenas se foram deflectidos.
AI Knowledge Base Maintenance for SaaS Docs aborda como manter a base de conhecimento atual, o que determina se o AI L1 consegue realmente tratar os tickets encaminhados a ele.
O roteamento AI multi-tier é a diferença entre self-service AI que melhora sua operação de suporte e self-service AI que cria novos problemas. A lógica de roteamento é simples. O design organizacional por trás dela, o planejamento de capacidade, as políticas de escalada e o ajuste contínuo são onde o trabalho real está. Acerte o modelo de roteamento, e a deflexão AI escala à medida que seu produto cresce.
Perguntas Frequentes
O que é roteamento AI multi-tier em um help desk SaaS?
O roteamento AI multi-tier é um sistema que classifica cada ticket de suporte recebido por intenção, complexidade e tier de conta do cliente antes de atribuí-lo a um atendente. O self-service AI L1 trata solicitações simples e documentáveis. Agentes humanos aumentados por AI L2 tratam problemas moderadamente complexos. Especialistas L3 tratam tickets complexos, sensíveis ou de alto valor. A decisão de roteamento acontece em milissegundos, substituindo a atribuição round-robin ou pelo primeiro disponível por correspondência inteligente.
Que precisão pode se esperar da classificação de intenção AI?
A precisão de classificação de intenção atinge 80-85% no primeiro deploy com 6-12 meses de dados históricos de tickets. Após 3-4 meses de ciclos de correção em produção, a precisão melhora para mais de 90%. A melhoria não é automática. Requer auditorias mensais de roteamento onde tickets mal classificados são rotulados e resubmetidos ao treinamento.
Por que clientes enterprise não devem passar pelo self-service AI L1?
Clientes enterprise têm uma expectativa de nível de serviço contratual. Um cliente enterprise que envia um ticket de suporte e recebe uma resposta de chatbot de AI antes de qualquer reconhecimento humano experimenta uma incompatibilidade de nível de serviço. A solução é uma regra de roteamento explícita: contas enterprise (ou acima de um limiar de ARR definido) são encaminhadas para L2 no mínimo, independentemente da classificação de intenção. Essa regra deve ser configurada explicitamente, não deixada para o algoritmo.
O que é um handoff frio e por que prejudica o CSAT?
Um handoff frio é quando um cliente precisa reexplicar seu problema a um agente humano porque a AI não passou o contexto da conversa para o humano. A experiência do cliente são duas conversas desconectadas: uma com um bot, uma com uma pessoa que não sabe nada do que o bot aprendeu. As pontuações de CSAT para handoffs frios são consistentemente 15-25% mais baixas do que para handoffs quentes onde o contexto completo é transferido.
Como evitar gargalos de escalada após implantar o roteamento AI?
O roteamento AI aumenta a deflexão L1, o que concentra tickets mais difíceis em L2 e L3. Se você mantiver L2 com os níveis pré-AI, os agentes enfrentam tickets mais difíceis no mesmo volume. Planeje a capacidade de L2 proativamente. Uma taxa de deflexão L1 de 40% significa que seu pool de tickets restante é mais difícil em média. Construa staff e especialização de L2 para corresponder a essa mudança, não ao modelo de headcount pré-AI.
Quais sinais devem acionar roteamento imediato L3 independentemente da classificação de intenção?
Quatro tipos de sinal requerem roteamento determinístico L3: palavras-chave relacionadas à segurança (acesso não autorizado, violação de dados, comprometimento de conta), linguagem explícita de cancelamento ou churn, disputas de cobrança durante a janela de renovação (60 dias antes da renovação) e qualquer conta em uma pontuação de saúde crítica de risco. São regras de política, não comportamentos aprendidos. Devem ser configuradas explicitamente e devem substituir toda a outra lógica de roteamento.
Saiba Mais:
- Scoring and Routing Pattern: o padrão do ACE Framework por trás da inteligência de roteamento
- RAG Assistant Pattern: a camada de self-service L1 que o roteamento alimenta
- AI Support Agent for SaaS Self-Service: estrutura completa de tiers para AI de suporte SaaS
- Ticket Deflection with RAG in SaaS Support: métricas de qualidade de deflexão para tickets roteados
- AI Churn Prediction in Subscription Models: como dados de health score da janela de renovação informam as regras de roteamento
- AI Knowledge Base Maintenance for SaaS Docs: mantendo a base de conhecimento atual para resolução L1

Co-Founder, Rework.com
On this page
- O que Significa Roteamento Multi-Tier
- O Modelo de Triagem Intent-Tier-Context
- O Padrão de Scoring e Roteamento Aplicado
- Classificação de Intenção na Prática
- Regras de Roteamento por Tier de Conta
- Sinais de Roteamento Específicos para SaaS
- Qualidade de Escalada: Handoff de Contexto
- Prevenindo Gargalos de Escalada
- Benchmarks de Desempenho de Roteamento
- Métricas para Qualidade de Roteamento
- Conectando ao Stack de Suporte AI