Mode Kegagalan AI SaaS: Apa yang Sebenarnya Salah (Dan Berapa Biayanya)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Sebagian besar kegagalan AI SaaS tidak dramatis. Tidak ada gangguan layanan. Tidak ada berita utama. Produk dikirim, entri changelog keluar, siaran pers menyatakan "kami berinvestasi besar dalam AI," dan kemudian tidak ada yang jelas terjadi.
Yang sebenarnya terjadi jauh lebih senyap. Log fitur AI menunjukkan 3% weekly active usage pada bulan ketiga. CSM (Customer Success Manager) berhenti membuka dashboard health score karena terlalu banyak akun yang disebut "berisiko" yang ternyata tidak churn. Bot chat support secara diam-diam dinonaktifkan oleh pelanggan enterprise yang terbakar oleh jawaban yang salah dan eskalasi ke VP CS Anda. Konten SEO yang dibuat AI yang tampaknya menjadi kemenangan produktivitas sekarang memicu kebijakan spam Google pada halaman yang biasanya mendapat peringkat tinggi.
Kegagalan senyap adalah mode yang dominan. Dan lebih mahal daripada kegagalan dramatis karena Anda tidak tahu itu terjadi sampai Anda mengukur efek hilir, yang tidak dilakukan sebagian besar tim.
Artikel ini mencakup enam mode kegagalan spesifik dalam AI SaaS, dengan apa yang sebenarnya mereka biayai dan apa yang mencegahnya. Ini bukan kerangka risiko AI generik. Ini spesifik untuk dinamika pendapatan SaaS, hubungan pembeli SaaS, dan alat AI yang sebenarnya di-deploy perusahaan SaaS.
The 6 SaaS AI Failure Modes
The 6 SaaS AI Failure Modes adalah kerangka diagnostik yang memetakan cara paling umum inisiatif AI SaaS gagal di seluruh permukaan kegagalan. Mode 1 (Fitur Yang Tidak Ada Yang Menggunakan): titik insertion yang salah, kualitas di bawah ambang kepercayaan, atau kegagalan penemuan. Mode 2 (Konten AI Merusak SEO): tidak ada lapisan kontribusi orisinal pada konten yang dibuat AI, konten tipis yang memicu penalti kualitas Google. Mode 3 (Output Salah Mendorong Churn): output yang menghadap pelanggan yang dibuat AI tanpa review gate untuk skenario berisiko tinggi. Mode 4 (Token-Cost Runaway): bundel AI harga flat tanpa consumption architecture, ekor power user yang merusak unit economics. Mode 5 (Feature Match Tanpa Moat): fitur AI yang dapat direplikasi kompetitor dalam 4-8 minggu tanpa telemetry loop yang menciptakan daya tahan. Mode 6 (Support Burden AI): rekomendasi AI di bawah ambang presisi, menciptakan kebisingan yang belajar diabaikan oleh CSM dan agen support. Keenam mode tidak sama-sama mungkin atau sama-sama mahal, tetapi semua enam dapat dicegah dengan pengukuran awal.
Mode Kegagalan 1: Fitur AI yang tidak digunakan pelanggan
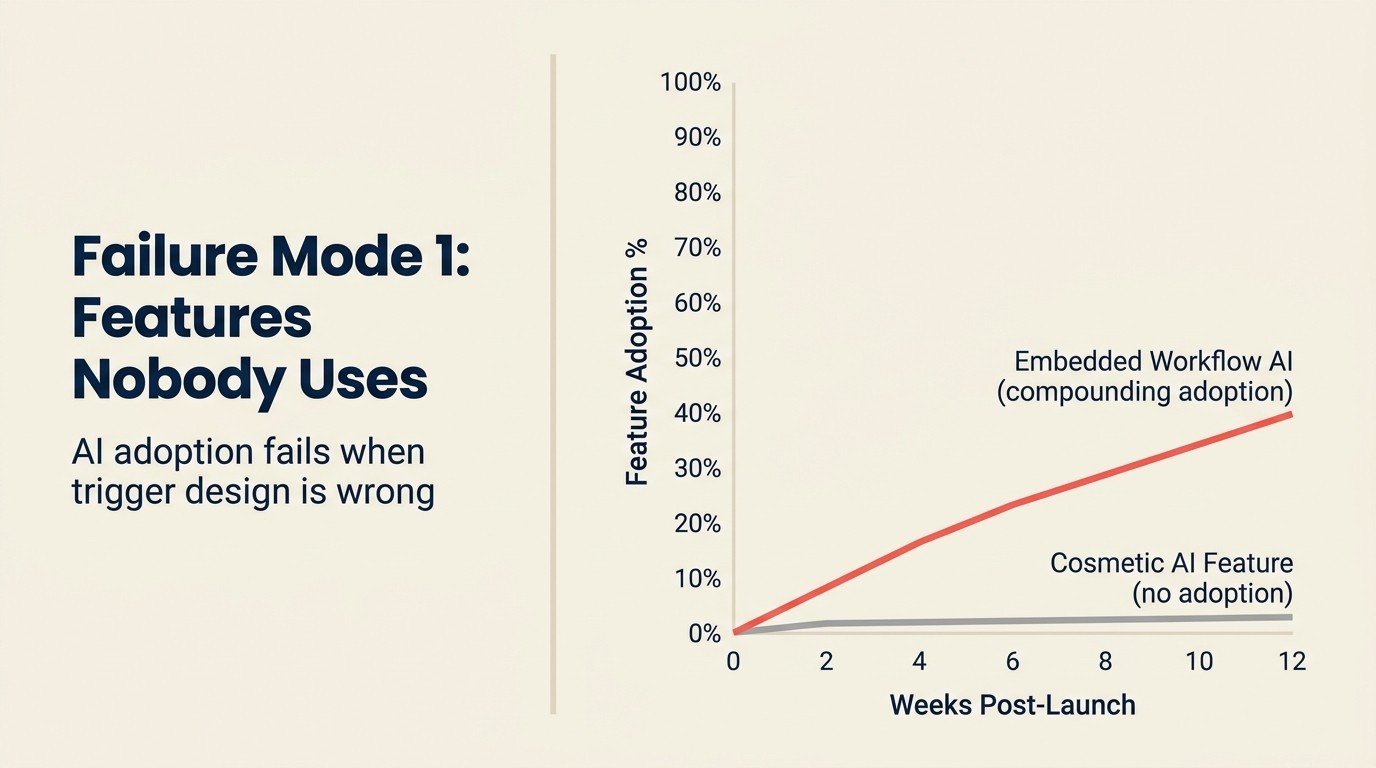
Anda membangunnya. Anda mengirimkannya. 3% pengguna menyentuhnya dalam 30 hari pertama, dan sekarang ini adalah item baris dalam laporan tahunan Anda di bawah "kapabilitas AI" yang tidak disebutkan oleh pelanggan yang membayar.
Ini adalah kegagalan AI SaaS yang paling umum dan paling mahal dalam hal biaya peluang. Fitur AI copilot dalam produk yang tipikal membutuhkan 3-4 bulan waktu engineering untuk dibangun dengan benar: integrasi API, desain prompt, telemetri, UI. Dengan biaya engineering blended $250.000/tahun, itu adalah investasi engineering senilai $60.000-80.000. Jika 3% pengguna menggunakannya, dan tidak ada yang menyebutnya sebagai alasan mereka memperbarui, Anda telah membakar $75.000 untuk menambahkan fitur ke halaman penetapan harga Anda.
Akar penyebabnya spesifik dan dapat didiagnosis. Gartner menemukan bahwa setidaknya 50% proyek AI generatif ditinggalkan setelah proof of concept karena kualitas data yang buruk, kontrol risiko yang tidak memadai, biaya yang meningkat, atau nilai bisnis yang tidak jelas, yang berarti fitur dengan adopsi nol adalah norma industri, bukan pengecualian.
Titik insertion yang salah: AI muncul di bagian workflow yang dikunjungi pengguna dua kali seminggu, bukan sepuluh kali sehari. Saran AI dalam workflow frekuensi rendah tidak membangun kebiasaan yang diperlukan untuk adopsi. Titik insertion AI dengan nilai tertinggi ada dalam workflow frekuensi tertinggi, bukan yang terlihat paling mengesankan. Fitur AI sebagai produk: di mana menambahkannya menyediakan kerangka seleksi tiga filter untuk mengidentifikasi titik insertion yang tepat sebelum membangun.
Kualitas di bawah ambang kepercayaan: Akurasi saran adalah 60-70% dalam pengujian internal tetapi terasa seperti 40% bagi pengguna karena kegagalan lebih berkesan daripada keberhasilan. Kualitas AI perlu melampaui ambang kepercayaan sebelum pengguna mengandalkannya. Di bawah ambang tersebut, pengguna mencobanya sekali, mengalami kegagalan, dan berhenti. Ambang kepercayaan lebih tinggi dari yang diperkirakan sebagian besar tim produk selama pengembangan.
Kegagalan penemuan: Pengguna tidak tahu fitur tersebut ada atau cara mengaksesnya. Ini terdengar seperti masalah marketing tetapi sebenarnya adalah masalah desain produk. Fitur AI dalam produk yang mengharuskan pengguna menavigasi ke bagian terpisah, atau yang hanya muncul di menu pengaturan, akan tidak terlihat oleh sebagian besar pengguna. Fitur perlu muncul dalam konteks, pada saat relevan, tanpa mengharuskan pengguna mencarinya.
Pencegahan: Ukur tiga indikator utama sebelum fitur dikirimkan: frekuensi titik insertion yang diharapkan, ambang kualitas benchmark dari pengujian pengguna (bukan pengujian internal), dan penempatan penemuan dalam alur pengguna. Jika salah satu dari tiga lemah, perbaiki sebelum peluncuran. Mengirimkan lebih cepat tidak membantu jika fitur tidak pernah diadopsi.
Key Facts: Tingkat Kegagalan AI SaaS
- Setidaknya 50% proyek AI generatif ditinggalkan setelah proof of concept karena kualitas data yang buruk, kontrol risiko yang tidak memadai, biaya yang meningkat, atau nilai bisnis yang tidak jelas (Gartner, 2025)
- 60-70% enterprise menghadapi kegagalan pilot dalam implementasi AI; hanya 10-20% eksperimen AI yang terisolasi dalam dua tahun terakhir yang benar-benar diskalakan untuk menciptakan nilai (MIT/McKinsey, 2025)
- Pada 2028, investasi LLM (large language model) observability akan mencapai 50% dari deployment AI generatif khusus karena halusinasi, bias, dan kegagalan kepercayaan akan membutuhkan infrastruktur pemantauan yang tidak dibangun sebagian besar perusahaan SaaS saat ini (Gartner, 2026)
Mode Kegagalan 2: Konten yang dibuat AI yang merusak SEO

Sebuah perusahaan SaaS menemukan bahwa mereka dapat 10x output konten mereka dengan meminta AI menulis posting blog, artikel knowledge base, dan halaman landing. Mereka menerbitkan 200 artikel yang dibuat AI dalam enam bulan. Tiga bulan kemudian, traffic pencarian organik mereka turun 35%.
Ini terjadi. Ini terus terjadi. Dan biayanya bukan hanya penurunan traffic. Ini adalah timeline pemulihan: 12-18 bulan untuk membangun kembali otoritas domain setelah penalti sinyal kualitas Google, dengan asumsi Anda juga telah menghapus atau secara substansial mengerjakan ulang konten yang memicunya.
Mekanisme spesifik: sistem konten helpful Google dan tim tinjauan manual menandai konten tipis yang dibuat AI dengan nilai orisinal rendah. Halaman yang tidak menunjukkan penelitian orisinal, keahlian spesifik, atau informasi yang benar-benar berguna yang tidak ada di tempat lain mendapat de-indeks atau sangat dikurangi bobotnya. Batch 200 artikel konten yang dibuat AI tanpa penelitian orisinal, sinyal keahlian penulis, dan data unik adalah persis apa yang dirancang sistem ini untuk menghukum.
Dampak dolar: perusahaan SaaS dengan ARR $5 juta yang menjalankan 30% akuisisi pelanggan melalui pencarian organik mungkin menghasilkan $500.000-700.000/tahun dalam pipeline dari saluran tersebut. Penurunan traffic organik 35% diterjemahkan menjadi dampak pipeline tahunan $175.000-245.000, ditambah biaya investasi pembuatan konten yang menciptakan masalah tersebut.
Pencegahan: Konten yang dibuat AI membutuhkan lapisan editorial yang tulus sebelum dipublikasikan. Bukan pemeriksaan tata bahasa. Lapisan kontribusi orisinal: opini ahli spesifik ditambahkan, data orisinal disertakan, atau contoh konkret dari pengalaman pelanggan nyata. Konten yang tidak dapat lulus uji "apakah ini berisi sesuatu yang tidak ada dalam data pelatihan?" tidak siap untuk dipublikasikan. Risiko halusinasi berdasarkan pattern mencakup kondisi teknis yang membuat konten AI tidak dapat diandalkan dan pattern mana yang paling rentan terhadap kesalahan yang percaya diri.
Untuk konten knowledge base teknis, risikonya lebih rendah karena akurasi lebih penting daripada orisinalitas. Untuk konten blog top-of-funnel yang bersaing untuk kata kunci kompetitif, konten yang dibuat AI tanpa editorial adalah kewajiban, bukan aset.
Mode Kegagalan 3: Churn yang didorong AI dari output yang salah
Sebuah perusahaan SaaS menengah men-deploy alur onboarding yang didukung AI untuk mengurangi time-to-value. AI merekomendasikan bagian produk berdasarkan use case pengguna yang dinyatakan selama pendaftaran. Selama tiga bulan, ini berhasil dengan baik.
Kemudian sekelompok pendaftaran enterprise memicu bug dalam logika segmentasi. AI merutekan 40 sesi onboarding enterprise ke workflow yang dirancang untuk tim kecil. Pengguna tersebut mengalami onboarding yang terasa tidak relevan dan membingungkan. Tiket support melonjak. 11 dari 40 akun meminta pengembalian dana atau tidak mengkonversi dari trial. Dampak pendapatannya adalah $180.000 dalam ARR yang tidak berhasil ditutup.
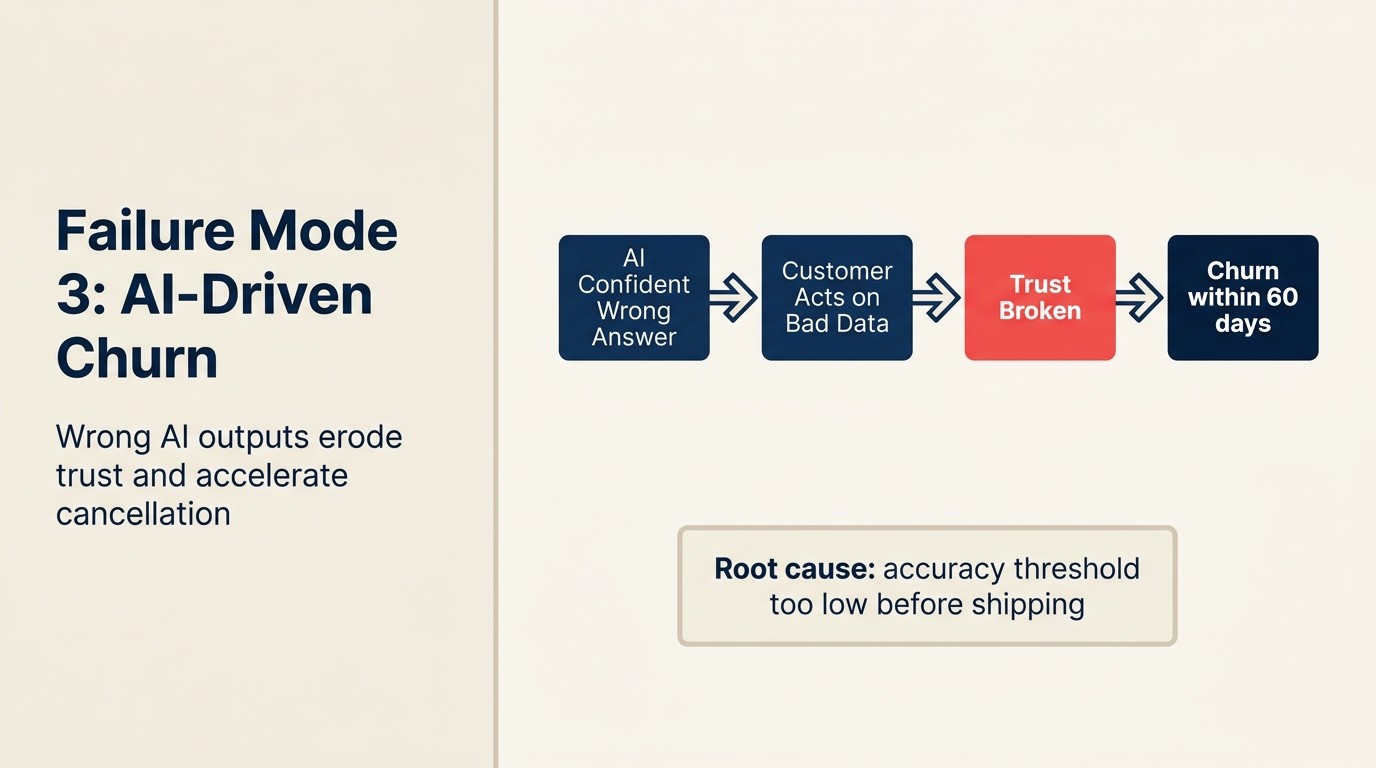
Ini adalah AI-driven churn: kasus di mana output AI secara aktif merusak hubungan pelanggan daripada membantunya. Ini berbeda dari bug perangkat lunak standar karena kerugiannya bukan "fitur tidak bekerja." Ini "AI memberi pelanggan informasi atau pengalaman yang salah, dan pelanggan sekarang meragukan apakah produk Anda memahami use case mereka."
Pola kegagalan berulang dalam health scoring. Health score AI alat CS menyebut akun enterprise yang akan churn sebagai "hijau" selama tiga bulan. CSM, mempercayai skor tersebut, tidak melakukan intervensi dengan frekuensi normal check-in. Akun tersebut churn pada saat pembaruan. Otopsi menunjukkan health score memberikan bobot penggunaan produk atas sentimen tiket support, dan akun tersebut memiliki penggunaan tinggi dan frustrasi tinggi secara bersamaan.
Versi bot chat support: AI chatbot memberikan jawaban yang salah tentang kemampuan ekspor data kepada prospek dalam percobaan, yang secara khusus mengevaluasi produk untuk fitur tersebut. Prospek memilih kompetitor. Tidak ada yang tahu ini terjadi karena percakapan chatbot tidak ditinjau. McKinsey mengidentifikasi kekhawatiran risiko dan pembengkakan biaya sebagai alasan utama inisiatif AI gagal untuk berpindah dari prototipe ke produksi, dan hanya 10 hingga 20% eksperimen AI yang terisolasi dalam dua tahun terakhir yang benar-benar diskalakan untuk menciptakan nilai, yang merupakan latar belakang di mana mode kegagalan khusus SaaS ini terjadi.
Pencegahan: Setiap fitur AI yang menghasilkan output yang menghadap pelanggan membutuhkan human review gate untuk skenario berisiko tinggi. Bukan gate pada setiap output, tetapi gate yang ditentukan oleh tingkat dampak. Output AI berisiko rendah (saran penyusunan, ringkasan internal) dapat diterapkan secara otomatis. Output berisiko tinggi (routing onboarding, penawaran harga, klaim ketersediaan fitur, peringatan health score yang memicu perubahan perilaku CSM) membutuhkan mekanisme tinjauan sebelum mempengaruhi pelanggan.
Tentukan "berisiko tinggi" secara eksplisit sebelum di-deploy. Ini adalah keputusan produk, bukan keputusan infrastruktur. Batas generate vs. execute menjelaskan prinsip ACE Framework tentang kapan output AI harus membutuhkan persetujuan manusia sebelum dijalankan.
Mode Kegagalan 4: Token-cost runaway
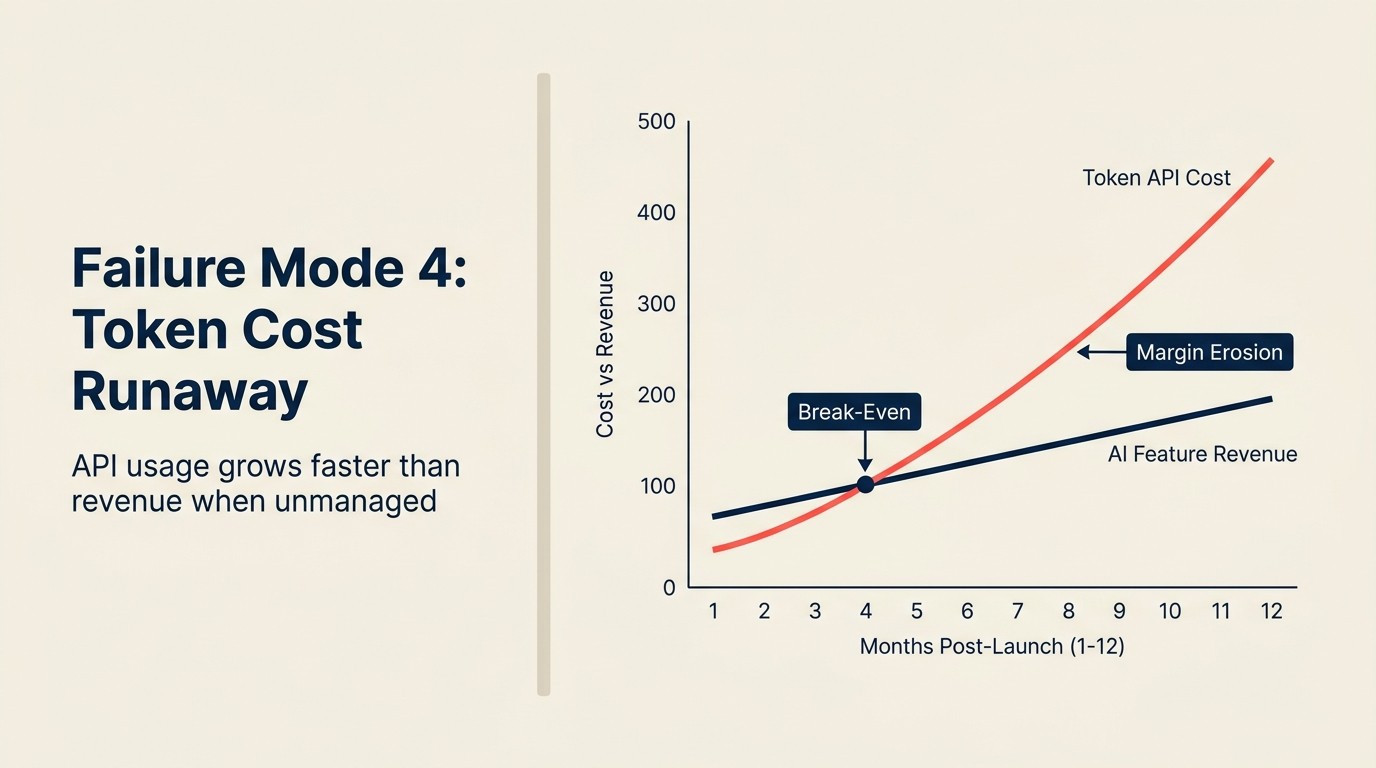
Sebuah perusahaan SaaS mengirimkan asisten penulisan AI sebagai bagian dari paket $49/bulan dengan pembuatan AI tanpa batas. Pengujian internal menunjukkan 95% pengguna menghasilkan 50-100 output per bulan. Pemodelan mengatakan biaya API akan berjalan pada $0,80-1,20 per pengguna per bulan. Fitur dikirimkan.
Enam bulan kemudian, tiga pelanggan enterprise yang menggunakan produk untuk operasi konten skala besar masing-masing menjalankan 8.000-12.000 permintaan pembuatan AI per bulan. Dengan rata-rata $0,80/permintaan, itu adalah $6.400-9.600 per pelanggan per bulan dalam biaya API, untuk pelanggan yang membayar $49/bulan. Tim produk tidak memodelkan pengguna persentil ke-99. Mereka memodelkan pengguna median.
Total dampak kuartalan: tiga pelanggan menciptakan kewajiban biaya API $72.000-84.000 terhadap $441 dalam MRR (monthly recurring revenue) gabungan. Perusahaan sekarang membayar untuk memiliki pelanggan tersebut menggunakan produk.
Ini bukan hipotesis. Pola ini terjadi di beberapa produk SaaS selama 2023-2024 ketika tim menetapkan harga fitur AI secara flat tanpa consumption architecture. Pemodelan pengguna median terlihat baik. Ekor power user menghancurkan unit economics.
Matematikanya: OpenAI GPT-4o mengenakan biaya $2,50/M input token dan $10/M output token. Satu permintaan penulisan AI dengan 3.000 token konteks dan 800 token output biayanya $0,0155. Itu murah per permintaan. Tetapi pengguna yang menjalankan 500 permintaan per hari biayanya $7,75/hari, atau $232/bulan dalam biaya API. Jika pengguna tersebut berada dalam paket $99/bulan, Anda membayar mereka $133/bulan untuk menggunakan produk Anda.
Pencegahan: Tiga keputusan arsitektur yang diperlukan sebelum mengirimkan fitur AI apa pun pada paket harga flat:
- Batas konsumsi per pengguna berdasarkan tier: Tier gratis mendapatkan 100 tindakan AI/bulan. Starter mendapatkan 500. Professional mendapatkan 2.000. Enterprise bernegosiasi kustom. Batas keras, bukan batas lunak.
- Pemantauan penggunaan dengan peringatan otomatis: Ketika akun mana pun melebihi 150% konsumsi yang dimodelkan tier mereka, sistem menghasilkan peringatan untuk ditinjau. Bukan hanya untuk alasan penagihan, tetapi karena pola penggunaan yang anomali sering kali mengindikasikan masalah kualitas data atau perilaku pengguna yang menggunakan AI dengan cara yang tidak dimaksudkan.
- Penetapan harga berbasis biaya untuk enterprise: Pelanggan enterprise dengan penggunaan tinggi yang diharapkan harus berada pada penetapan harga berbasis konsumsi atau penetapan harga berjenjang dengan biaya kelebihan yang jelas. Pelanggan yang akan menghasilkan biaya API $2.000/bulan tidak boleh berada dalam kontrak flat $500/bulan.
Mode Kegagalan 5: Fitur AI dicocokkan oleh kompetitor dalam 30 hari
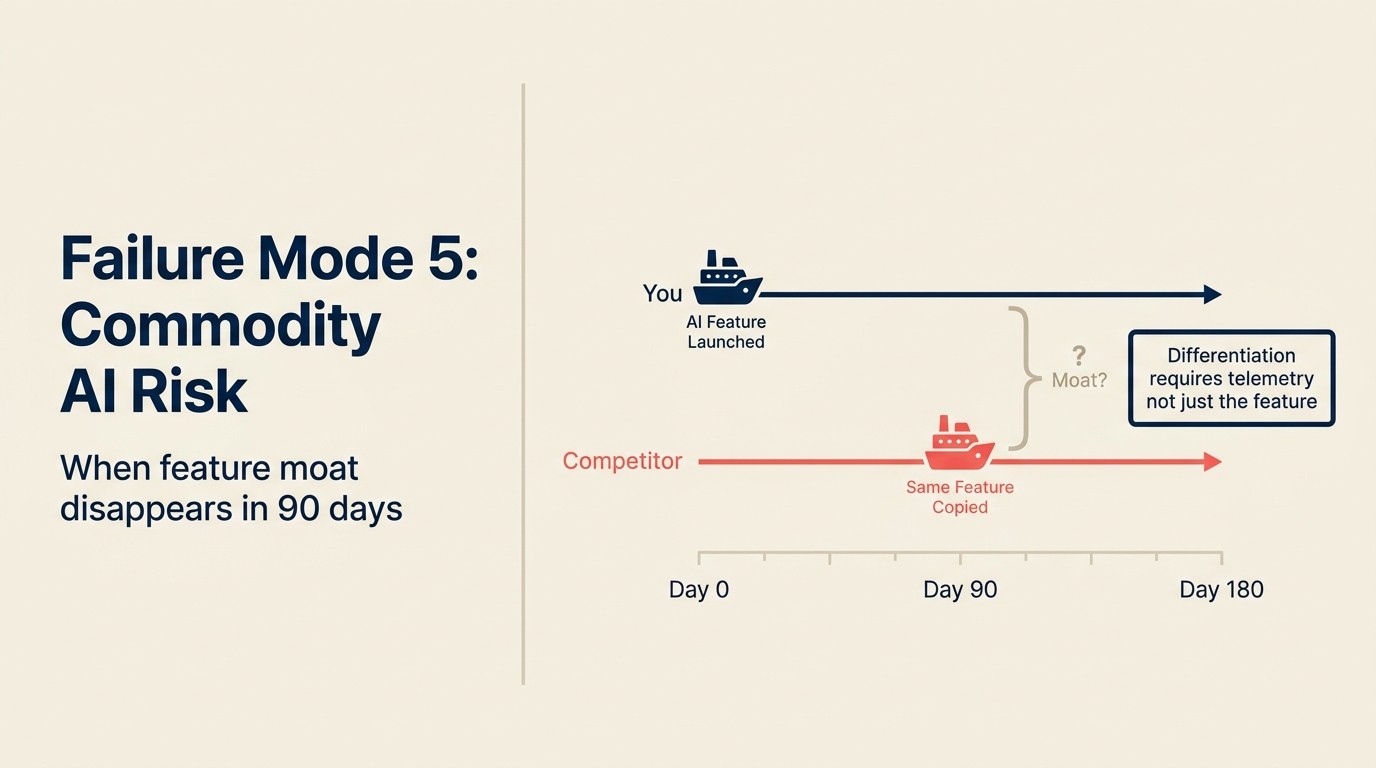
Sebuah perusahaan SaaS mengirimkan fitur AI ringkasan kontrak yang digunakan tim sales mereka untuk mempercepat tinjauan kesepakatan. Membutuhkan 4 bulan untuk dibangun. Saat peluncuran, ini adalah diferensiator: tidak ada kompetitor yang menawarkan ini dalam produk. Tim memasarkannya secara menonjol.
Enam minggu setelah peluncuran, dua kompetitor mengirimkan fitur yang setara. Satu membungkus Claude secara langsung. Yang lain mengintegrasikan alat AI kontrak pihak ketiga. Keduanya live dalam 30 hari satu sama lain. Moat kompetitif yang dibangun perusahaan selama 4 bulan memiliki umur simpan 8 minggu.
Ini adalah kegagalan tanpa moat: mengirimkan fitur AI yang menciptakan diferensiator sementara tetapi tidak menciptakan keunggulan struktural karena dapat direplikasi oleh kompetitor mana pun dengan langganan LLM API dan beberapa minggu waktu engineering.
Sebagian besar fitur AI yang dibangun pada LLM API generik dapat direplikasi dalam 4-8 minggu oleh tim engineering kompetitor yang kompeten. Diferensiasi dari fitur itu sendiri nyata tetapi sementara. Satu-satunya diferensiasi yang tahan lama adalah (a) data: versi Anda lebih baik karena dilatih pada perilaku aktual pengguna Anda, atau (b) kedalaman integrasi: versi Anda lebih baik karena sangat tertanam dalam workflow sehingga pergantian membutuhkan pembelajaran ulang segalanya. Telemetry loop untuk in-product AI menjelaskan cara membangun data flywheel yang menciptakan opsi (a).
Biayanya: 4 bulan waktu engineering untuk membangun fitur yang mendiferensiasikan selama 8 minggu. Dengan biaya engineering loaded $250.000/tahun, itu kira-kira $83.000 yang diinvestasikan untuk 2 bulan diferensiasi kompetitif. Matematika ROI mengharuskan 8 minggu diferensiasi telah mendorong win rate yang secara bermakna lebih baik, yang biasanya tidak dapat diukur.
Pencegahan: Sebelum membangun fitur AI apa pun yang akan membutuhkan lebih dari 6 minggu engineering, jawab pertanyaan: "Dalam 90 hari, ketika dua kompetitor telah mengirimkan fungsionalitas yang setara, apa yang membuat versi kami secara bermakna lebih baik?" Jika jawabannya bukan salah satu dari (data moat, kedalaman integrasi, kualitas dari telemetry loop), Anda seharusnya membungkus fitur lebih cepat dan lebih murah, atau menginvestasikan waktu engineering dalam fitur yang menciptakan moat yang tahan lama.
Mode Kegagalan 6: Fitur AI menciptakan beban support
Sebuah perusahaan SaaS mengirimkan fitur AI priority scoring untuk alat manajemen proyek mereka. AI memberikan skor prioritas ke tugas dan memunculkan item prioritas teratas dalam email digest harian. Ini terdengar berguna dan dalam pengujian internal, tim menyukainya.
Dalam produksi, 40% pengguna menemukan saran prioritas AI salah untuk konteks mereka. AI tidak memahami definisi prioritas tim mereka, yang dipengaruhi oleh tenggat waktu, hubungan pemangku kepentingan, dan konteks yang tidak tertangkap dalam metadata tugas. Pengguna mulai membuat tiket support: "Mengapa AI mengatakan X adalah prioritas tinggi padahal jelas bukan?" Tim support kini menghabiskan waktu menjelaskan perilaku AI yang tidak sepenuhnya mereka pahami.
Volume tiket support untuk fitur AI pada bulan pertama: 180 tiket. Biaya support dengan $12/tiket fully loaded: $2.160. Setiap bulan. Untuk fitur yang seharusnya mengurangi beban kognitif.
Kegagalan ini berlipat ganda: pengguna yang mengajukan tiket support AI lebih cenderung churn daripada pengguna yang tidak. Bukan karena fitur AI gagal, tetapi karena interaksi support menciptakan narasi: "AI produk ini tidak memahami konteks saya." Narasi tersebut melekat pada produk, bukan hanya fitur.
Pola yang sama muncul dalam alat CS AI. Sistem health scoring mengirimkan 50 peringatan "berisiko" per minggu, 60% di antaranya ternyata adalah false positive setelah investigasi CSM. Setelah empat minggu, CSM mulai mengabaikan peringatan tanpa memeriksa. Ketika akun yang benar-benar berisiko muncul dalam antrean, mereka diabaikan bersama false positive. Anda telah membayar untuk sistem health scoring yang tim CS Anda secara mental telah depreciate.
Pencegahan: Dua metrik yang harus hijau sebelum rekomendasi yang dihasilkan AI dikirimkan ke pelanggan:
- Presisi: Dari berapa kali AI menandai sesuatu (berisiko, prioritas tinggi, tindakan yang direkomendasikan), berapa persentase yang benar? Jika presisi di bawah 70%, fitur menciptakan lebih banyak kebisingan daripada sinyal. Sebagian besar pengguna akan belajar untuk mengabaikannya.
- Feedback loop untuk koreksi: Pengguna perlu dapat memberi tahu AI bahwa ia salah, dan feedback tersebut perlu benar-benar mengubah perilaku AI. Fitur AI tanpa mekanisme koreksi melatih pengguna untuk melihat AI sebagai kotak hitam yang tidak bisa dinalar. Persepsi tersebut menghancurkan kepercayaan lebih cepat dari jawaban yang salah manapun.
Versi CS health scoring dari ini: jangan peringatkan setiap akun yang turun di bawah ambang batas. Peringatkan akun yang turun secara tak terduga relatif terhadap trajektori terkini mereka. Lebih sedikit peringatan, presisi lebih tinggi, kepercayaan CSM dipertahankan.
"Kegagalan senyap adalah mode yang dominan dalam AI SaaS. Produk dikirim, changelog keluar, siaran pers menyatakan 'kami berinvestasi besar dalam AI,' dan kemudian tidak ada yang jelas terjadi. Log fitur AI menunjukkan 3% weekly active usage pada bulan ketiga. Bot chat support secara diam-diam dinonaktifkan oleh pelanggan enterprise yang terbakar oleh jawaban yang salah. AI health scoring diabaikan oleh CSM yang telah melihat terlalu banyak peringatan false-positive." (Rework Analysis, 2025)
"Fitur AI copilot dalam produk yang tipikal membutuhkan 3-4 bulan waktu engineering untuk dibangun dengan benar. Dengan biaya engineering blended $250.000/tahun, itu adalah investasi $60.000-80.000. Jika 3% pengguna menggunakannya dan tidak ada yang menyebutnya sebagai alasan pembaruan, tim membakar $75.000 untuk menambahkan fitur ke halaman penetapan harga." (Rework Analysis, berdasarkan analisis biaya proyek GenAI Gartner, 2025)
"Volume tiket support untuk fitur AI dengan presisi di bawah ambang: 180 tiket per bulan, dengan $12/tiket fully loaded, adalah $2.160 per bulan dalam biaya support untuk fitur yang seharusnya mengurangi beban kognitif. Kegagalan berlipat ganda: pengguna yang mengajukan tiket support AI lebih cenderung churn daripada yang tidak, karena interaksi support menciptakan narasi produk yang melekat pada seluruh produk." (Rework Analysis, 2025)
"Tiga pelanggan enterprise yang menggunakan asisten penulisan AI dengan harga flat pada 8.000-12.000 permintaan pembuatan per bulan masing-masing, membayar $49/bulan, menciptakan kewajiban biaya API kuartalan $72.000-84.000 terhadap $441 dalam MRR gabungan. Perusahaan sekarang membayar untuk memiliki pelanggan tersebut menggunakan produk. Ini bukan hipotesis." (Rework Analysis, berdasarkan harga OpenAI dan insiden token-cost SaaS yang terdokumentasi, 2025)
Daftar Periksa Pencegahan Mode Kegagalan AI SaaS

| Mode Kegagalan | Sinyal Peringatan Dini | Jendela Deteksi | Pencegahan |
|---|---|---|---|
| Fitur yang tidak digunakan | 90 hari WAU (weekly active users) di bawah 10% | Hari 30-60 | Validasi titik insertion sebelum membangun |
| Konten AI merusak SEO | Penurunan traffic organik 3 bulan setelah publikasi | 90-120 hari | Lapisan kontribusi orisinal di setiap konten AI |
| Output salah mendorong churn | Lonjakan support atau permintaan pengembalian dana dari pengguna yang tersentuh AI | 30-90 hari | Human review gate untuk output AI berisiko tinggi |
| Token-cost runaway | Biaya API bulanan melebihi 50% pendapatan paket untuk akun mana pun | 30-60 hari | Batas konsumsi per pengguna sebelum peluncuran |
| Feature match tanpa moat | Kompetitor mengirimkan yang setara dalam 60 hari | 6-12 minggu | Telemetry loop saat peluncuran; kedalaman integrasi |
| Support burden AI | Tiket support untuk fitur AI; tingkat pengabaian peringatan CSM di atas 30% | 30-60 hari | Ambang presisi di atas 70% sebelum dikirimkan |
Sumber: Gartner GenAI Project Failure Analysis 2025, McKinsey AI Risk and Cost Research 2025, Gartner LLM Observability Predictions 2026
"Pada 2028, investasi LLM observability akan mencapai 50% dari deployment AI generatif khusus karena halusinasi, bias, dan kegagalan kepercayaan akan membutuhkan infrastruktur pemantauan yang tidak dibangun sebagian besar perusahaan SaaS saat ini. Tim yang memulai instrumentasi tersebut sekarang akan berada di depan kurva kepatuhan dan ekspektasi pelanggan." (Gartner, 2026)
Rework Analysis: Pola di semua enam mode kegagalan adalah disiplin pengukuran, bukan kecanggihan teknologi. Setiap mode kegagalan yang didokumentasikan di sini terlihat dalam data sebelum menjadi mahal, jika Anda melihatnya. Tim yang men-deploy AI, menyatakan kemenangan berdasarkan pengumuman peluncuran, dan tidak mengukur apa pun selama enam bulan adalah mereka yang menemukan Mode 1 pada bulan ke-6 ketika data penggunaan menceritakan kisah yang tidak diceritakan oleh changelog. Daftar periksa pencegahan kegagalan bukan tata kelola opsional. Ini adalah kebiasaan operasional yang memisahkan investasi AI yang terus berkembang dari investasi AI yang terdepresiasi.
Seperti apa pencegahan kegagalan sebenarnya
Pola di semua enam mode kegagalan adalah disiplin pengukuran, bukan kecanggihan teknologi. Setiap mode kegagalan yang dijelaskan di sini terlihat dalam data sebelum menjadi mahal, jika Anda melihatnya.
Daftar periksa pencegahan kegagalan sebelum men-deploy fitur AI apa pun:
Pengukuran baseline sudah ada: Anda mengetahui metrik yang seharusnya ditingkatkan fitur ini, dan Anda memiliki baseline sebelum AI yang terdokumentasi. Jika Anda men-deploy AI call coaching tanpa mencatat seperti apa "kualitas discovery yang baik" sebelum AI, Anda tidak bisa mengukur apakah berhasil.
Pelacakan adopsi sudah aktif: Weekly active user, acceptance rate, dan modification rate ada di dashboard yang ditinjau seseorang setiap minggu. Adopsi 3% pada hari ke-30 masih bisa dipulihkan. Adopsi 3% pada hari ke-90 adalah fitur yang Anda bayar untuk dipelihara.
Consumption guardrail sudah dibangun: Setiap fitur AI pada paket harga flat memiliki batas per pengguna dan pemantauan penggunaan sebelum dikirimkan, bukan setelah siklus penagihan yang anomali pertama.
Jalur eskalasi ada: Setiap fitur AI yang menyentuh output yang menghadap pelanggan memiliki jalur yang ditentukan bagi pelanggan untuk eskalasi ketika AI salah. Sebaiknya, eskalasi tersebut ditangani oleh manusia, bukan AI lain.
Presisi diukur dan memiliki ambang: Untuk fitur AI apa pun yang menghasilkan peringatan atau rekomendasi, presisi dilacak. Fitur tidak dikirimkan tanpa ambang presisi minimum yang ditentukan dan diuji.
Sinyal kepercayaan dilacak: Setiap bulan, periksa apakah pengguna yang terlibat dengan fitur AI Anda memiliki NPS (Net Promoter Score) dan tingkat churn yang lebih tinggi atau lebih rendah daripada pengguna yang tidak. Jika keterlibatan fitur AI berkorelasi dengan churn yang lebih tinggi, Anda memiliki masalah kepercayaan, dan itu perlu didiagnosis sebelum fitur tersebut diskalakan.
Kegagalan AI SaaS dapat diatasi jika ditangkap lebih awal. Keenam mode kegagalan yang dijelaskan di sini semuanya dapat diukur dalam 60-90 hari pertama jika Anda melacak sinyal yang tepat. Perusahaan yang mengalami masalah serius adalah mereka yang men-deploy AI, menyatakan kemenangan berdasarkan pengumuman peluncuran, dan tidak mengukur apa pun selama enam bulan. Gartner memperkirakan bahwa pada 2028, investasi LLM observability akan mencapai 50% dari deployment AI generatif khusus karena halusinasi, bias, dan kegagalan kepercayaan akan membutuhkan infrastruktur pemantauan yang tidak dibangun sebagian besar perusahaan SaaS saat ini, dan tim yang memulai instrumentasi tersebut lebih awal akan berada di depan kurva kepatuhan dan ekspektasi pelanggan.
Jangan nyatakan kemenangan sebelum telemetri membuktikannya.
Pelajari Lebih Lanjut:
- Mengapa Sebagian Besar Transformasi AI Gagal: pola kegagalan tingkat strategi yang menciptakan kondisi untuk semua enam mode
- Risiko Halusinasi berdasarkan Pattern: kondisi teknis yang menghasilkan kesalahan AI yang percaya diri berdasarkan jenis pattern
- Batas Generate vs. Execute: prinsip ACE Framework tentang kapan AI membutuhkan persetujuan manusia sebelum bertindak
- AI Anti-Pattern: katalog kegagalan tingkat pattern yang melengkapi mode kegagalan khusus SaaS
- Telemetry Loop untuk In-Product AI: infrastruktur pengukuran yang menangkap kegagalan pada hari ke-30, bukan bulan ke-6
- Arms Race AI dalam SaaS: Kecepatan Pengiriman: tekanan kompetitif yang menciptakan kondisi untuk mengirimkan tanpa quality gate
- Tahap Kematangan AI SaaS: di mana mode kegagalan ini mengelompok berdasarkan tahap kematangan
- Mengapa AI Framework Gagal: pola kegagalan fundamental yang sering dilacak oleh kegagalan AI SaaS

Co-Founder, Rework.com
On this page
- The 6 SaaS AI Failure Modes
- Mode Kegagalan 1: Fitur AI yang tidak digunakan pelanggan
- Mode Kegagalan 2: Konten yang dibuat AI yang merusak SEO
- Mode Kegagalan 3: Churn yang didorong AI dari output yang salah
- Mode Kegagalan 4: Token-cost runaway
- Mode Kegagalan 5: Fitur AI dicocokkan oleh kompetitor dalam 30 hari
- Mode Kegagalan 6: Fitur AI menciptakan beban support
- Daftar Periksa Pencegahan Mode Kegagalan AI SaaS
- Seperti apa pencegahan kegagalan sebenarnya