Telemetry Loops para AI no Produto: Construindo Feedback que se Compõe
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
O GitHub Copilot melhora de forma mensurável a cada poucos meses. Essa melhoria não vem de engenheiros do GitHub trabalhando mais no modelo. Vem de milhões de desenvolvedores aceitando, modificando e rejeitando sugestões do Copilot todos os dias. Cada interação é um ponto de dados. Cada ponto de dados alimenta a próxima versão do modelo. O produto melhora porque as pessoas o usam.
Este é um telemetry loop: um sistema estruturado que captura o que uma funcionalidade de AI sugeriu, o que um usuário fez em seguida e qual resultado se seguiu. É a diferença entre uma funcionalidade de AI que atinge um platô na qualidade do lançamento e uma funcionalidade de AI que se compõe.
A maioria das equipes SaaS que constroem funcionalidades de AI pula isso. Lançam a funcionalidade. Observam os números de adoção. Declaram sucesso se a adoção está crescendo. E então, seis meses depois, se perguntam por que as sugestões de AI ainda parecem genéricas e por que o churn entre usuários de funcionalidades de AI não é nada melhor do que o churn entre não-usuários.
O loop é o ponto central. O modelo inicial é apenas a condição de partida.
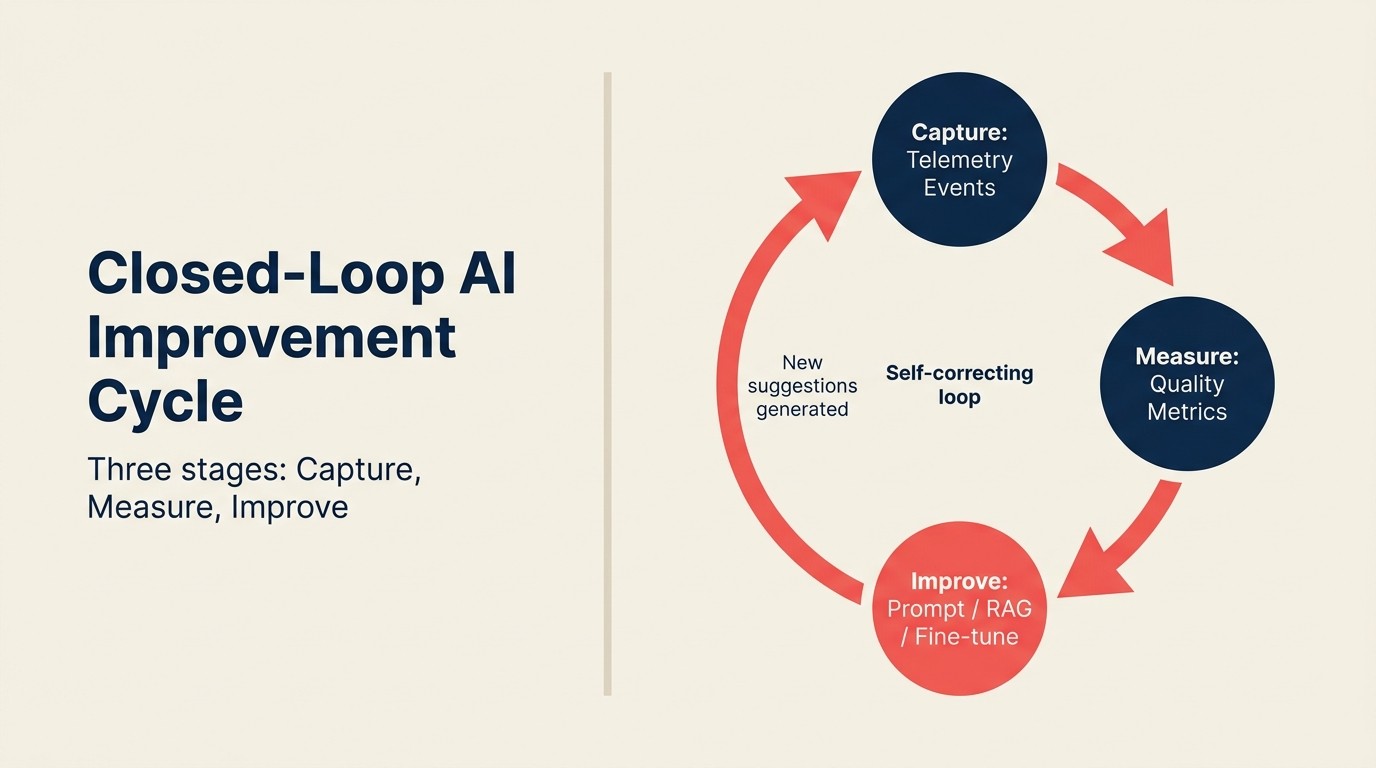
O Closed-Loop AI Improvement Cycle
O Closed-Loop AI Improvement Cycle é um sistema de feedback em três estágios que converte o uso de AI no produto em melhoria contínua do modelo. Capture: eventos de telemetria estruturados registram o que a AI sugeriu, o que o usuário fez em seguida e o resultado downstream. Measure: sinais agregados calculam métricas de qualidade por tipo de sugestão (taxa de aceitação, taxa de modificação, correlação de resultado). Improve: as métricas de qualidade são encaminhadas para o mecanismo de melhoria apropriado (engenharia de prompt para funcionalidades baseadas em API, ajuste de parâmetros de recuperação para funcionalidades RAG, ou dados de fine-tuning para modelos personalizados). O ciclo se fecha quando as melhorias geram novas sugestões que produzem novos eventos de captura. Um loop que para na Captura (registrando eventos sem medir ou melhorar) não é um loop. É um arquivo.
O que é um telemetry loop de fato
Um telemetry loop tem três estágios, mapeados para a capacidade Ingest do ACE Framework:
Capture: Coleta sinais estruturados de cada interação de funcionalidade de AI. O que foi sugerido, o que foi mostrado, qual era o contexto. Isso mapeia diretamente para a capacidade Ingest do ACE Framework.
Measure: Agrega esses sinais em métricas de qualidade. Taxa de aceitação de sugestões, taxa de modificação, correlação de resultado.
Improve: Encaminha os sinais medidos de volta para melhoria do modelo, refinamento de prompt ou ajuste de parâmetro de recuperação.
Sem todos os três estágios, você não tem um loop. A maioria das equipes tem o primeiro estágio (registram eventos em algum lugar), pula o segundo (não têm métricas de qualidade) e nunca chega ao terceiro (os dados ficam em um data warehouse e ninguém age sobre eles).
Um loop real se fecha. O output de Improve retroalimenta o comportamento da funcionalidade de AI, que gera novos dados de Capture. O sistema se autocorrige ao longo do tempo.
Key Facts: Telemetry Loops e Melhoria de AI
- Os experimentos de sinal comportamental do LinkedIn descobriram que sinais comportamentais previam a qualidade do conteúdo 4-6x melhor do que classificações explícitas, razão pela qual o feedback implícito (aceitar/modificar/rejeitar) é o sinal de alto valor nos telemetry loops de AI
- O GitHub Copilot escreve quase metade do código de um desenvolvedor, e testes controlados mostram que os desenvolvedores completam tarefas 55% mais rápido; essa qualidade atingiu os níveis atuais por meio de milhões de sinais de aceitação e rejeição de mais de 15 milhões de usuários, não por meio de melhoria estática do modelo (Second Talent, 2025)
- A McKinsey descreve a dinâmica de composição explicitamente: experimentação mais rápida gera mais dados, mais dados melhoram a qualidade do modelo, melhor desempenho atrai mais usuários, e a diferença entre organizações que executam esses loops e as que não o fazem torna-se estrutural ao longo do tempo (McKinsey State of AI, 2025)
Os três tipos de sinal da AI no produto

Nem todo feedback é igual. Os três tipos variam enormemente em volume, precisão e dificuldade de coleta.
Feedback explícito é o mais fácil de entender e o menos útil na prática. Curtir, não curtir, prompts de "isso foi útil?". Os usuários raramente e de forma inconsistente dão feedback explícito. Alguém que clica em "não curtir" uma vez e nunca mais não parou de ter opiniões. Parou de clicar. O LinkedIn realizou experimentos sobre mecanismos de feedback explícito e descobriu que sinais comportamentais previam a qualidade do conteúdo 4-6x melhor do que classificações explícitas. O mesmo padrão se aplica em contextos de produto.
Feedback implícito é onde o sinal vive. Os usuários não clicam em "não curtir", mas se comportam honestamente. Aceitam uma sugestão, editam uma sugestão, ignoram uma sugestão, ou desfazem o resultado e fazem a tarefa manualmente. Essas ações dizem mais sobre qualidade do que qualquer sistema de avaliação.
As duas métricas implícitas que mais importam são:
- Taxa de aceitação de sugestões: Qual porcentagem das sugestões de AI o usuário usa sem modificação?
- Taxa de modificação: Das sugestões que os usuários aceitam, quantas eles editam antes de finalizar?
Uma alta taxa de modificação indica que a direção da AI está correta, mas os detalhes estão errados. Uma baixa taxa de aceitação com alta taxa de conclusão manual indica que o ponto de inserção da sugestão está errado ou o limiar de qualidade está muito baixo. Estes são problemas diferentes com soluções diferentes.
Feedback de resultado é o mais difícil de coletar e o mais valioso. A tarefa assistida por AI produziu um resultado melhor do que o equivalente manual? O email redigido por AI recebeu resposta? A resposta de suporte gerada por AI resolveu o ticket sem escalação? A próxima ação sugerida por AI no CRM levou a uma reunião agendada?
O feedback de resultado exige conectar sua telemetria de AI a seus resultados de negócio downstream, o que geralmente significa unir dados de evento com dados de CRM ou de ticket de suporte. É um investimento de engenharia. Mas uma vez que você tem isso, pode responder à pergunta que todo líder de produto realmente se preocupa: nossa AI torna os clientes mais bem-sucedidos, ou apenas gera atividade?
Por que o feedback implícito supera o explícito
A economia comportamental aqui é consistente em todos os produtos. As pessoas não relatam com precisão suas preferências. Dizem que querem uma coisa e fazem outra. Isso é verdade para feedback de funcionalidades de AI da mesma forma que é verdade para respostas de pesquisa sobre funcionalidades de produto.
Mas mais praticamente: a proporção de feedback implícito para explícito na maioria dos produtos é de aproximadamente 50 para 1 ou mais. Para cada usuário que clica em "não curtir", cinquenta usuários fizeram um sinal comportamental de qualidade equivalente ou maior. Otimizar apenas para feedback explícito significa ignorar 98% do sinal que você poderia estar usando.
O Notion AI aprendeu isso cedo. Suas sugestões de escrita com AI são refinadas com base em como os usuários aceitam, modificam ou substituem o texto sugerido, não principalmente em avaliações explícitas. Os engenheiros de produto podem ver em agregado quais tipos de sugestão são usados como estão versus reescritos versus ignorados. Essa visão agregada molda as decisões de engenharia de prompt e seleção de modelo para a próxima versão.
O mesmo padrão é visível no desenvolvimento de funcionalidades de AI do Linear. Suas sugestões de triagem de bugs e prioridade são refinadas pela combinação de quais prioridades sugeridas por AI os engenheiros substituem e com que frequência as prioridades substituídas manualmente acabam correspondendo à urgência real de resolução. O modelo não é apenas treinado em dados rotulados. É treinado na diferença entre o que sugeriu e o que realmente aconteceu.
"A proporção de feedback implícito para explícito na maioria dos produtos é de 50 para 1 ou mais. Para cada usuário que clica em 'não curtir', cinquenta usuários fizeram um sinal comportamental de qualidade equivalente ou maior. Otimizar apenas para feedback explícito significa ignorar 98% do sinal disponível." (Rework Analysis, baseado em pesquisa de economia comportamental do LinkedIn)
"Funcionalidades de AI estáticas não são neutras. São um custo sem valor composto. A cada mês que uma funcionalidade não melhora por meio de telemetria, a diferença entre sua qualidade de AI e um concorrente que está executando um loop real cresce mais. A decisão de construir o loop é a decisão de infraestrutura de AI. A escolha do modelo importa menos." (Rework Analysis, 2025)
Comparação de Qualidade e Volume de Sinal
| Tipo de Sinal | Dificuldade de Coleta | Volume | Qualidade/Precisão | Uso Principal |
|---|---|---|---|---|
| Explícito (curtir/não curtir) | Fácil | Muito baixo (2-3% das interações) | Fraco (auto-relato inconsistente) | Sinalização rara de casos extremos |
| Aceitação implícita | Médio | Alto (toda sugestão mostrada) | Bom (sinal comportamental honesto) | Taxa de aceitação, melhoria do modelo |
| Modificação implícita | Médio | Alto (toda sugestão aceita) | Muito bom (mostra lacuna de preferência) | Engenharia de prompt, ajuste de especificidade |
| Feedback de resultado | Difícil (requer join de dados) | Baixo (subconjunto de sessões) | Excelente (mede valor real) | Medição de ROI, sinal de treinamento |
Fontes: pesquisa de sinal comportamental de AI do LinkedIn, documentação de telemetria do Notion AI, pesquisa McKinsey AI Software Development 2025
Rework Analysis: A maioria das equipes SaaS tem o Estágio 1 do telemetry loop (registro de eventos) e pula os Estágios 2 e 3 (medir métricas de qualidade e agir sobre elas). Os dados ficam em um data warehouse e ninguém os analisa semanalmente. O telemetry loop mínimo viável tem quatro componentes: eventos suggestion_shown, suggestion_accepted e suggestion_modified no Segment ou Amplitude; um dashboard semanal com taxa de aceitação e modificação por funcionalidade; uma reunião de revisão de prompt a cada duas semanas onde alguém realmente lê os dados; e um compromisso de enviar mudanças de prompt para os tipos de sugestão com pior desempenho. Esse é o loop inteiro.
Design de esquema para telemetria de AI

O esquema de evento importa. Eventos vagos criam sinais vagos. Se a sua telemetria parece com ai_feature_used: true, você não pode calcular a taxa de modificação, não pode segmentar por tipo de sugestão e não pode correlacionar com resultados.
Um esquema mínimo de telemetria de AI se parece com isto:
suggestion_id: UUID (vincula a sugestão ao longo de seu ciclo de vida)
feature_id: string (qual funcionalidade de AI gerou isso)
session_id: string (conecta ao contexto de sessão do usuário)
context_hash: string (impressão digital do contexto que a AI recebeu)
suggestion_type: enum (rascunho, autocompletar, classificação, recomendação)
suggestion_shown_at: timestamp
suggestion_accepted_at: timestamp ou null
suggestion_modified: boolean
modification_delta: integer (distância de edição de caracteres da sugestão ao final)
user_dismissed: boolean
manual_completion: boolean (usuário concluiu a tarefa sem usar a sugestão)
outcome_event_id: string ou null (FK para resultado downstream, se capturado)
Esse esquema permite calcular cada métrica que importa para a qualidade do telemetry loop. O context_hash é particularmente importante: permite identificar se contextos similares estão recebendo sugestões consistentemente melhores ou piores ao longo do tempo, que é a medição central para melhoria do modelo.
Para equipes que usam Segment ou Amplitude como pipeline de eventos, esse esquema mapeia de forma limpa para um evento personalizado com propriedades padrão. O join de outcome_event_id requer uma etapa de enriquecimento no servidor ou um join downstream em seu data warehouse. Uma vez que você tem o esquema capturando os eventos certos, o que você faz com esses sinais depende inteiramente de como sua funcionalidade de AI foi construída.
Usando o loop para melhoria do modelo
O que você faz com os dados de telemetria depende de como sua funcionalidade de AI foi construída.
Para funcionalidades baseadas em API GPT-4 ou Claude (o caso mais comum para AI em SaaS em 2026), o mecanismo de melhoria é engenharia de prompt. Alta taxa de modificação em um tipo específico de sugestão indica que o prompt não é específico o suficiente. Conclusão manual consistente após sugestão de AI indica que a sugestão está aparecendo no momento errado do fluxo de trabalho. Você pode iterar em prompts semanalmente sem tocar no modelo subjacente.
Para funcionalidades RAG (Retrieval-Augmented Generation) (AI que recupera de uma base de conhecimento antes de gerar), a telemetria alimenta o ajuste de parâmetros de recuperação. Se os usuários consistentemente ignoram sugestões de AI que citam uma seção específica da base de conhecimento, essa seção está desatualizada ou é irrelevante. A telemetria diz quais fontes de recuperação estão realmente produzindo sugestões usadas versus ruído. Manutenção de base de conhecimento com AI para SaaS cobre como agir sobre esses sinais para manter o corpus de recuperação atualizado.
Para modelos fine-tuned ou personalizados (raro para SaaS Série A-C), o feedback implícito de alta qualidade com rótulos de resultado torna-se dado de treinamento. Os dados de taxa de modificação são efetivamente um conjunto de dados de preferência. Os dados de correlação de resultado são um sinal de reforço. Essa é a abordagem que o GitHub adota com o Copilot em escala, mas requer infraestrutura de ML que a maioria das equipes SaaS não deve construir antes da maturidade do Estágio 4.
O fosso de dados composto
Após 12 meses executando um telemetry loop real, algo muda em sua posição competitiva.
Suas funcionalidades de AI foram treinadas no comportamento real de seus usuários reais fazendo seus casos de uso reais. Não em texto genérico da internet. Não em conjuntos de dados de benchmark. Os padrões dos seus usuários, as preferências dos seus usuários, as definições dos seus usuários de "boa sugestão."
Um concorrente lançando a mesma funcionalidade com o mesmo modelo subjacente começa do zero. Ele tem o mesmo acesso de API que você tinha no lançamento. Mas não tem seus 12 meses de dados de comportamento do usuário. Não pode comprar esses dados. Precisa ganhá-los executando seu próprio loop por 12 meses.
É assim que os telemetry loops se tornam uma vantagem competitiva durável. Não da tecnologia, que está disponível para todos, mas dos dados comportamentais acumulados que moldam como a tecnologia se comporta para seus usuários específicos.
O efeito de composição se acelera nos Estágios 4 e 5 de maturidade, onde as funcionalidades de AI começam a compartilhar sinais entre funções. Se os dados de resultado da AI no produto alimentam a pontuação de saúde da AI de customer success, e a precisão da AI de pontuação de saúde retroalimenta quais funcionalidades a AI no produto prioriza, você está construindo um sistema de aprendizado integrado. Isso é genuinamente difícil de replicar. A McKinsey descreve essa dinâmica de composição explicitamente: experimentação mais rápida gera mais dados, mais dados melhoram a qualidade do modelo, melhor desempenho atrai mais usuários, e com o tempo a diferença entre organizações que executam esses loops e as que não o fazem torna-se estrutural. Estágios de maturidade de AI em SaaS mapeia como essa integração entre funções se parece em cada estágio.
Requisitos de privacidade e consentimento
O feedback do usuário coletado e usado para treinamento de modelos não é gratuito de uma perspectiva de conformidade. O RGPD (Regulamento Geral sobre a Proteção de Dados), Artigo 22, e a CCPA (Lei de Privacidade do Consumidor da Califórnia) têm requisitos sobre tomada de decisão automatizada e uso de dados. Usar dados comportamentais para melhorar funcionalidades de AI que então fazem sugestões aos usuários possivelmente se enquadra na tomada de decisão automatizada em algumas interpretações.
O requisito prático para a maioria das empresas SaaS é este: seus termos de serviço e política de privacidade precisam declarar explicitamente que você coleta dados de uso do produto para melhorar funcionalidades de AI, e os usuários precisam de um caminho claro de opt-out. O AI Risk Management Framework do NIST fornece uma estrutura útil para documentar como os dados de feedback comportamental fluem pelos pipelines de melhoria de AI, o que importa cada vez mais à medida que as equipes de procurement corporativo realizam suas próprias revisões de governança de AI antes de aprovar ferramentas SaaS. Isso é diferente do treinamento de AI em conteúdo do usuário, que tem um requisito de consentimento mais rígido.
A preocupação com fricção de UX é real, mas solucionável. O Notion, o Linear e a maioria dos principais produtos de AI SaaS lidam com isso por meio de uma seção de configurações de privacidade que explica o que é coletado, para que é usado e como fazer opt-out. A maioria dos usuários não faz opt-out. Mas ter o mecanismo importa para conformidade e confiança.
A regra mais importante: não use dados específicos do cliente para melhorar a AI para outros clientes sem consentimento explícito. Padrões comportamentais agregados são geralmente adequados. Conteúdo específico gerado pelo usuário usado como exemplos de treinamento requer uma arquitetura de consentimento mais robusta.
O antipadrão: funcionalidades de AI que nunca aprendem
O oposto de um telemetry loop é uma funcionalidade de AI que é estática desde o primeiro dia. Mesmo modelo, mesmos prompts, mesmas sugestões, independentemente do que os usuários façam com ela. Essas funcionalidades existem em muitos produtos SaaS agora. Foram construídas por equipes que trataram AI como uma caixa de seleção: "lançar, é AI."
Os sinais de uma funcionalidade de AI estática:
- A qualidade das sugestões não melhora em intervalos de 6 meses
- A equipe não tem uma revisão semanal de métricas de funcionalidades de AI
- A equipe de dados não tem um dashboard acompanhando a taxa de aceitação ou modificação
- As mudanças de prompt requerem um ciclo de sprint e acontecem trimestralmente no melhor caso
Funcionalidades de AI estáticas não são neutras. São um custo sem valor composto. A cada mês que não melhoram, a diferença entre a qualidade da sua AI e a de um concorrente que está executando um loop cresce mais.
A decisão de construir o loop é a decisão de infraestrutura de AI. A escolha do modelo importa menos.
Como é um "loop fechado" na prática
Um telemetry loop fechado produz um ritual semanal: a revisão das métricas de funcionalidades de AI. Taxa de aceitação subindo ou descendo. Taxa de modificação por tipo de sugestão. Quaisquer correlações de resultado em movimento. Prompts ajustados com base no sinal. Nova versão lançada.
A equipe de engenharia do GitHub Copilot publica posts periódicos sobre como usam dados de aceitação e métricas de distância de edição para avaliar mudanças de modelo. O changelog do Linear mostra melhorias de pontuação de prioridade de AI na maioria dos lançamentos mensais, impulsionadas pela forma como os engenheiros realmente respondem às sugestões. Essas não são coincidências. São loops.
Para a sua equipe, o telemetry loop mínimo viável é:
- Eventos
suggestion_shown,suggestion_accepted,suggestion_modifiedrastreados no Segment ou Amplitude - Um dashboard semanal com taxa de aceitação e modificação por funcionalidade
- Uma reunião de revisão de prompt a cada duas semanas onde alguém realmente lê os dados
- Um compromisso com mudanças de prompt que melhoram os tipos de sugestão com pior desempenho
É isso. Esse é o loop. Não é engenharia de ML. É disciplina de produto.
As empresas que vão dominar a qualidade de funcionalidades de AI em 2027 e 2028 não são as que escolheram o melhor modelo em 2025. São as que construíram o loop em 2025 e o deixaram rodar.
Perguntas Frequentes
O que é um telemetry loop para AI no produto?
Um telemetry loop é um sistema estruturado que captura o que uma funcionalidade de AI sugeriu, o que um usuário fez em seguida e qual resultado se seguiu, depois encaminha esses sinais de volta para melhoria do modelo ou do prompt. Os três estágios são Capture (coleta de eventos estruturados), Measure (métricas de qualidade de sinais agregados) e Improve (engenharia de prompt, ajuste de recuperação ou dados de treinamento). Sem todos os três estágios, você tem um arquivo, não um loop.
Por que o feedback implícito é mais valioso do que as avaliações explícitas na telemetria de AI?
Avaliações explícitas (curtir/não curtir) são dadas por 2-3% dos usuários e não refletem com precisão a preferência. Os usuários não fazem auto-relato consistente. Sinais implícitos (aceitar, modificar ou ignorar uma sugestão) são gerados por 100% das interações e refletem comportamento honesto. A proporção é de aproximadamente 50 para 1. Otimizar apenas para feedback explícito ignora 98% do sinal disponível.
Quais são as duas métricas implícitas-chave na telemetria de AI?
Taxa de aceitação de sugestões (qual porcentagem das sugestões de AI o usuário usa sem modificação?) e taxa de modificação (das sugestões que os usuários aceitam, quantas eles editam antes de finalizar?). Alta taxa de modificação significa que a direção da AI está correta, mas os detalhes estão errados. Baixa taxa de aceitação com alta conclusão manual significa que o ponto de gatilho ou o limiar de qualidade está errado. Métricas diferentes, soluções diferentes.
Como um telemetry loop cria um fosso competitivo?
Após 12 meses executando um telemetry loop real, suas funcionalidades de AI são treinadas no comportamento real de seus usuários reais fazendo seus casos de uso reais. Um concorrente lançando a mesma funcionalidade com o mesmo modelo subjacente começa do zero. Ele tem o mesmo acesso de API que você tinha no lançamento, mas não tem 12 meses de dados comportamentais dos seus usuários. Não pode comprar esses dados. Precisa ganhá-los executando seu próprio loop por 12 meses.
Qual é o telemetry loop mínimo viável?
Quatro componentes: eventos suggestion_shown, suggestion_accepted e suggestion_modified rastreados no Segment ou Amplitude; um dashboard semanal com taxa de aceitação e modificação por funcionalidade; uma reunião de revisão de prompt a cada duas semanas onde alguém lê os dados; e um compromisso de enviar mudanças de prompt para os tipos de sugestão com pior desempenho. Sem necessidade de engenharia de ML nesta fase. Pura disciplina de produto.
Quais requisitos de conformidade se aplicam à telemetria comportamental para treinamento de AI?
O RGPD Artigo 22 e a CCPA têm requisitos sobre tomada de decisão automatizada e uso de dados. Seus termos de serviço e política de privacidade devem declarar explicitamente que você coleta dados de uso do produto para melhorar funcionalidades de AI, com um caminho claro de opt-out. Não use conteúdo específico do cliente para melhorar a AI para outros clientes sem consentimento explícito. Padrões comportamentais agregados (taxas de aceitação, taxas de modificação) são geralmente adequados. Conteúdo específico gerado pelo usuário usado como exemplos de treinamento requer uma arquitetura de consentimento mais robusta.
Saiba Mais:
- O que é a Capacidade Ingest de AI: a camada Ingest do ACE sobre a qual os telemetry loops são construídos
- Como os Padrões de AI Combinam Capacidades: como os dados de telemetria se compõem em múltiplos padrões de AI
- Funcionalidades de AI como Produto: Onde Adicioná-las: como identificar as funcionalidades que valem a construção de um telemetry loop
- AI Copilots Incorporados na Interface de Produtos SaaS: as funcionalidades de AI incorporadas que geram os sinais de telemetria mais ricos
- Estágios de Maturidade de AI em SaaS: como a integração de telemetria entre funções evolui nos estágios de maturidade
- A Vantagem da Telemetria de Produto em AI SaaS: como a telemetria SaaS cria um fosso estrutural sobre concorrentes puramente de AI

Co-Founder, Rework.com
On this page
- O Closed-Loop AI Improvement Cycle
- O que é um telemetry loop de fato
- Os três tipos de sinal da AI no produto
- Por que o feedback implícito supera o explícito
- Comparação de Qualidade e Volume de Sinal
- Design de esquema para telemetria de AI
- Usando o loop para melhoria do modelo
- O fosso de dados composto
- Requisitos de privacidade e consentimento
- O antipadrão: funcionalidades de AI que nunca aprendem
- Como é um "loop fechado" na prática