Modos de Fallo de IA en SaaS: Qué Sale Realmente Mal (Y Cuánto Cuesta)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La mayoría de los fallos de IA en SaaS no son dramáticos. No hay interrupciones. No hay titulares. El producto se lanza, sale la entrada del changelog, el comunicado de prensa dice "estamos invirtiendo fuertemente en IA," y luego no ocurre nada obvio.
Lo que realmente ocurre es más silencioso. Los registros de la función de IA muestran un 3% de uso activo semanal en el mes tres. Los CSMs (Customer Success Managers) dejan de abrir el dashboard de puntuación de salud porque ha llamado "en riesgo" a demasiadas cuentas que no abandonaron. El chatbot de soporte es silenciosamente deshabilitado por el cliente empresarial que fue perjudicado por una respuesta incorrecta y escaló al VP de CS. El contenido SEO generado por IA que parecía una victoria de productividad ahora está activando las políticas de spam de Google en páginas que solían posicionarse bien.
El fallo silencioso es el modo dominante. Y es más caro que el fallo dramático porque no se sabe que está ocurriendo hasta que se miden los efectos posteriores, lo que la mayoría de los equipos no hace.
Este artículo cubre seis modos de fallo específicos en la IA SaaS, con lo que realmente cuestan y qué los previene. No es un marco genérico de riesgo de IA. Es específico para las dinámicas de ingresos SaaS, las relaciones con compradores SaaS y las herramientas de IA que las empresas SaaS realmente despliegan.
Los 6 Modos de Fallo de IA en SaaS
Los 6 Modos de Fallo de IA en SaaS es un marco diagnóstico que mapea las formas más comunes en que las iniciativas de IA en SaaS fracasan en toda la superficie de fallos. Modo 1 (Funciones que Nadie Usa): punto de inserción incorrecto, calidad por debajo del umbral de confianza, o fallo en el descubrimiento. Modo 2 (Contenido de IA que Daña el SEO): sin capa de contribución original en el contenido generado por IA, contenido delgado que activa las penalizaciones de calidad de Google. Modo 3 (Resultados Incorrectos Impulsan el Churn): resultados generados por IA orientados al cliente sin gates de revisión humana para escenarios de alto impacto. Modo 4 (Desbordamiento del Costo de Tokens): paquetes de IA a precio plano sin arquitectura de consumo, la cola de usuarios avanzados destruye la economía unitaria. Modo 5 (Función Sin Moat Igualada por Competidores): funciones de IA replicables por competidores en 4-8 semanas sin un telemetry loop que cree durabilidad. Modo 6 (IA que Crea Carga de Soporte): recomendaciones de IA por debajo del umbral de precisión, creando ruido que los CSMs y agentes de soporte aprenden a ignorar. Los seis modos no son igualmente probables ni igualmente costosos, pero todos son prevenibles con medición temprana.
Modo de Fallo 1: Funciones de IA que los clientes no usan
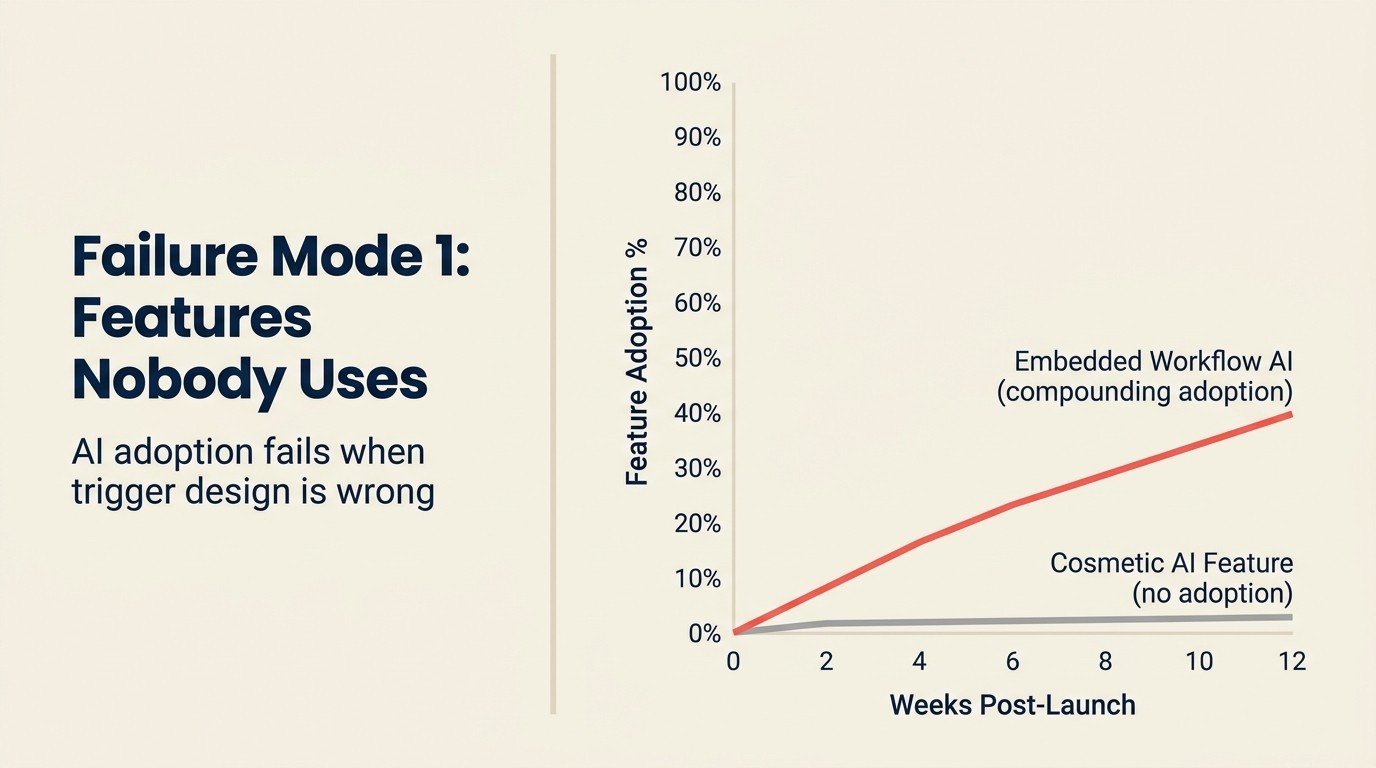
Se construyó. Se lanzó. El 3% de los usuarios lo tocó en los primeros 30 días, y ahora es una línea en el informe anual bajo "capacidades de IA" que ningún cliente que paga menciona realmente.
Este es el fallo de IA en SaaS más común y el más caro en términos de costo de oportunidad. Una función típica de AI copilot en producto tarda 3-4 meses de tiempo de ingeniería en construirse correctamente: integración de API, diseño de prompts, telemetría, UI. Con un costo combinado de ingeniería de $250,000/año, eso son $60,000-80,000 de inversión en ingeniería. Si el 3% de los usuarios la usa, y ninguno la cita como razón para renovar, se han quemado $75,000 para añadir una función a la página de precios.
Las causas raíz son específicas y diagnosticables. Gartner encontró que al menos el 50% de los proyectos de IA generativa se abandonan después de la prueba de concepto debido a mala calidad de datos, controles de riesgo inadecuados, costos en aumento o valor de negocio poco claro, lo que significa que la función de cero adopción es la norma del sector, no la excepción.
Punto de inserción incorrecto: La IA apareció en una parte del flujo de trabajo que el usuario visita dos veces por semana, no diez veces al día. Las sugerencias de IA en flujos de trabajo de baja frecuencia no construyen el hábito necesario para la adopción. Los puntos de inserción de IA de mayor valor están en los flujos de trabajo de mayor frecuencia, no en los de apariencia más impresionante. El artículo sobre funciones de IA como producto: dónde añadirlas proporciona el marco de selección de tres filtros para identificar los puntos de inserción correctos antes de construir.
Calidad por debajo del umbral de confianza: La precisión de las sugerencias era del 60-70% en las pruebas internas, pero los usuarios la sentían como del 40% porque los fallos eran más memorables que los éxitos. La calidad de la IA necesita superar un umbral de confianza antes de que los usuarios la utilicen. Por debajo de ese umbral, los usuarios la prueban una vez, experimentan un fallo y se detienen. El umbral de confianza es más alto de lo que la mayoría de los equipos de producto estiman durante el desarrollo.
Fallo en el descubrimiento: Los usuarios no saben que la función existe o cómo acceder a ella. Esto suena como un problema de marketing pero en realidad es un problema de diseño de producto. Las funciones de IA en producto que requieren que los usuarios naveguen a una sección separada, o que solo aparecen en menús de configuración, serán invisibles para la mayoría de los usuarios. La función necesita surgir en contexto, en el momento en que es relevante, sin requerir que el usuario la busque.
Prevención: Medir los tres indicadores principales antes de que se lance la función: frecuencia esperada del punto de inserción, umbral de calidad de referencia de las pruebas de usuario (no pruebas internas) y posicionamiento del descubrimiento en el flujo del usuario. Si alguno de los tres es débil, corregirlo antes del lanzamiento. Lanzar más rápido no ayuda si la función nunca se adopta.
Key Facts: Tasas de Fallo de IA en SaaS
- Al menos el 50% de los proyectos de IA generativa se abandonan después de la prueba de concepto debido a mala calidad de datos, controles de riesgo inadecuados, costos en aumento o valor de negocio poco claro (Gartner, 2025)
- El 60-70% de las empresas enfrentan fallo de pilot en la implementación de IA; solo el 10-20% de los experimentos de IA aislados de los últimos dos años realmente escalaron para crear valor (MIT/McKinsey, 2025)
- Para 2028, las inversiones en observabilidad de LLM alcanzarán el 50% de los despliegues de IA generativa específicamente porque las alucinaciones, los sesgos y los fallos de confianza requerirán infraestructura de monitoreo que la mayoría de las empresas SaaS no están construyendo hoy (Gartner, 2026)
Modo de Fallo 2: Contenido generado por IA que daña el SEO

Una empresa SaaS descubre que puede multiplicar por 10 su producción de contenido haciendo que la IA escriba entradas de blog, artículos de base de conocimiento y páginas de destino. Publican 200 artículos generados por IA en seis meses. Tres meses después, su tráfico de búsqueda orgánica cae un 35%.
Esto ha ocurrido. Sigue ocurriendo. Y el costo no es solo la caída del tráfico. Es el período de recuperación: 12-18 meses para reconstruir la autoridad del dominio después de una penalización de la señal de calidad de Google, asumiendo que también se ha eliminado o reelaborado sustancialmente el contenido que la desencadenó.
El mecanismo específico: el sistema de contenido útil de Google y los equipos de revisión manual marcan el contenido delgado generado por IA con bajo valor original. Las páginas que no demuestran investigación original, experiencia específica o información genuinamente útil que no existe en otro lugar se desindexan o se reducen significativamente de peso. Un lote de 200 artículos generados por IA sin investigación original, sin señales de experiencia del autor y sin datos únicos es exactamente lo que estos sistemas están diseñados para penalizar.
El impacto en dólares: una empresa SaaS con $5M de ARR que ejecuta el 30% de la adquisición de clientes a través de búsqueda orgánica podría estar generando $500,000-700,000/año en pipeline desde ese canal. Una caída del 35% en el tráfico orgánico se traduce en un impacto de pipeline anual de $175,000-245,000, más el costo de la inversión en creación de contenido que produjo el problema.
Prevención: El contenido generado por IA requiere una capa editorial genuina antes de su publicación. No una revisión de gramática. Una capa de contribución original: una opinión experta específica añadida, datos originales incluidos, o un ejemplo concreto de la experiencia real del cliente. El contenido que no pasa el test "¿contiene esto algo que no existía en los datos de entrenamiento?" no está listo para publicar. El artículo sobre riesgo de alucinación por patrón cubre las condiciones técnicas que hacen que el contenido de IA sea poco confiable y qué patrones son más propensos a errores con confianza.
Para el contenido técnico de la base de conocimiento, el riesgo es menor porque la precisión importa más que la originalidad. Para el contenido de blog de la parte superior del funnel que compite por palabras clave competitivas, la generación por IA sin capa editorial es un pasivo, no un activo.
Modo de Fallo 3: Churn impulsado por la IA debido a resultados incorrectos
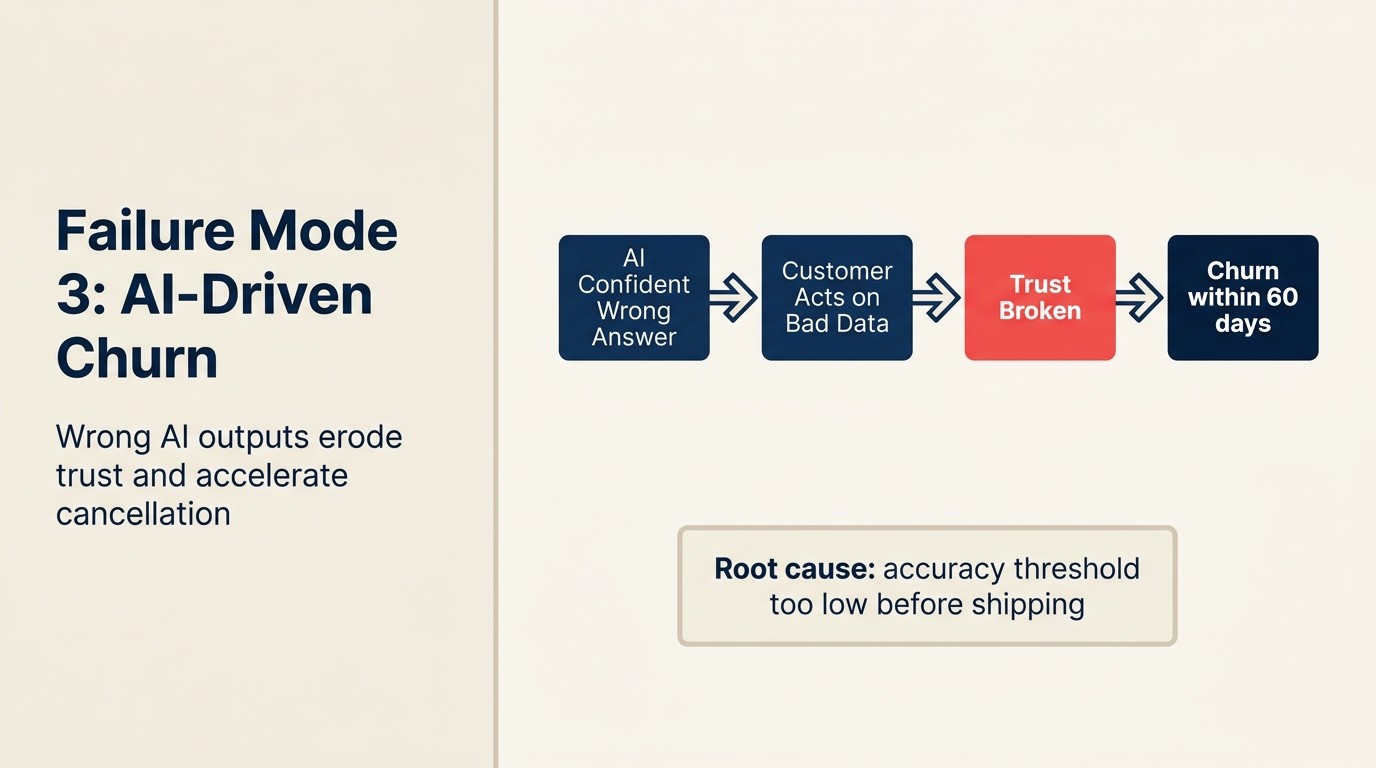
Una empresa SaaS de mercado medio despliega un flujo de onboarding impulsado por IA para reducir el tiempo hasta la obtención de valor. La IA recomienda secciones del producto basándose en el caso de uso declarado por el usuario durante el registro. Durante tres meses, esto funciona bien.
Luego un lote de registros empresariales activa un bug en la lógica de segmentación. La IA enruta 40 sesiones de onboarding empresarial a un flujo de trabajo diseñado para equipos pequeños. Esos usuarios experimentan un onboarding que se siente irrelevante y confuso. Los tickets de soporte se disparan. 11 de las 40 cuentas solicitan reembolsos o no convierten desde el período de prueba. El impacto en ingresos es $180,000 en ARR que no se cerró.
Este es el churn impulsado por la IA: un caso en que la salida de la IA dañó activamente una relación con el cliente en lugar de ayudarla. Es diferente a un bug de software estándar porque el daño no es "la función no funcionó." Es "la IA dio al cliente información incorrecta o una experiencia incorrecta, y el cliente ahora duda de que el producto entienda su caso de uso."
El patrón de fallo se repite en la puntuación de salud. La puntuación de salud de la IA de una herramienta de CS llama "verde" a una cuenta empresarial que está por abandonar durante tres meses. El CSM, confiando en la puntuación, no interviene con la frecuencia normal de check-ins. La cuenta abandona al renovar. La autopsia muestra que la puntuación de salud estaba ponderando el uso del producto sobre el sentimiento de los tickets de soporte, y la cuenta tenía alto uso y alta frustración simultáneamente.
La versión del chatbot de soporte: un chatbot de IA da una respuesta incorrecta sobre las capacidades de exportación de datos a un prospecto en período de prueba, que estaba evaluando específicamente el producto para esa función. El prospecto elige a un competidor. Nadie sabe que esto ocurrió porque la conversación del chatbot no se revisa. McKinsey identifica las preocupaciones de riesgo y los excesos de costo como las razones principales por las que las iniciativas de IA no logran cruzar del prototipo a la producción, y solo el 10-20% de los experimentos de IA aislados de los últimos dos años realmente escalaron para crear valor, que es el telón de fondo contra el que ocurren estos modos de fallo específicos de SaaS.
Prevención: Cada función de IA que genera resultados orientados al cliente necesita un gate de revisión humana para los escenarios de alto impacto. No un gate en cada resultado, sino un gate definido por el nivel de impacto. Los resultados de IA de bajo impacto (sugerencias de redacción, resúmenes internos) pueden aplicarse automáticamente. Los resultados de alto impacto (enrutamiento del onboarding, cotizaciones de precios, afirmaciones sobre disponibilidad de funciones, alertas de puntuación de salud que desencadenan cambios de comportamiento del CSM) necesitan un mecanismo de revisión antes de que afecten a los clientes.
Definir "alto impacto" explícitamente antes de desplegar. Es una decisión de producto, no de infraestructura. El artículo sobre el límite de generar vs. ejecutar explica el principio del ACE Framework para cuándo el resultado de la IA debe requerir aprobación humana antes de ejecutarse.
Modo de Fallo 4: Desbordamiento del costo de tokens
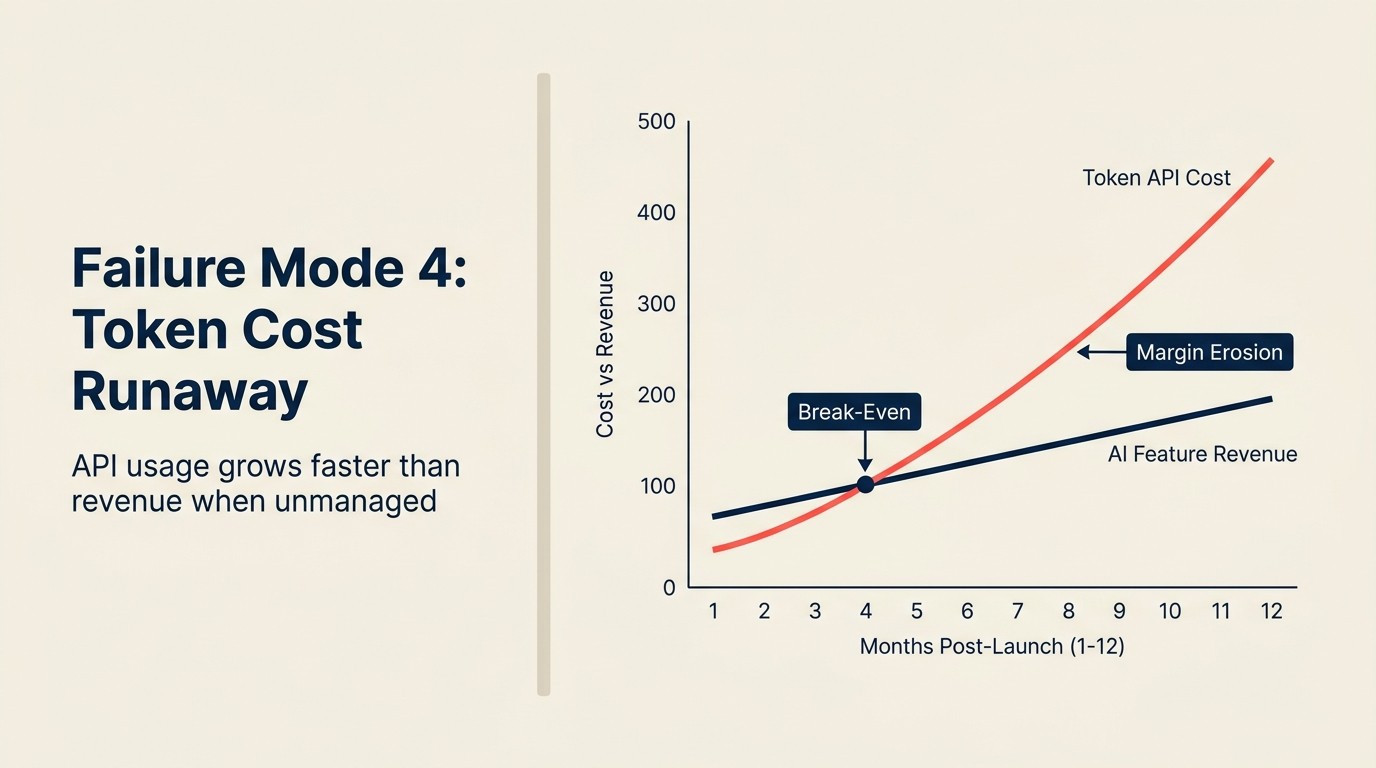
Una empresa SaaS lanza un asistente de escritura de IA como parte de un plan de $49/mes con generación de IA ilimitada. Las pruebas internas muestran que el 95% de los usuarios generan 50-100 resultados por mes. El modelado dice que los costos de API se ejecutarán a $0.80-1.20 por usuario por mes. La función se lanza.
Seis meses después, tres clientes empresariales que usan el producto para operaciones de contenido a gran escala ejecutan cada uno 8,000-12,000 solicitudes de generación de IA por mes. A $0.80/solicitud en promedio, eso es $6,400-9,600 por cliente por mes en costos de API, para clientes que pagan $49/mes. El equipo de producto no modeló al usuario del percentil 99. Modeló al usuario mediano.
El impacto trimestral total: tres clientes creando una responsabilidad de costo de API de $72,000-84,000 contra $441 en MRR (monthly recurring revenue) combinado. La empresa ahora está pagando para que esos clientes usen el producto.
Esto no es hipotético. Este patrón ocurrió en múltiples productos SaaS durante 2023-2024 cuando los equipos fijaron precios planos para funciones de IA sin arquitectura de consumo. El modelado del usuario mediano parece bien. La cola de usuarios avanzados destruye la economía unitaria.
Los cálculos: OpenAI GPT-4o cobra $2.50/M tokens de entrada y $10/M tokens de salida. Una sola solicitud de escritura de IA con 3,000 tokens de contexto y 800 tokens de salida cuesta $0.0155. Eso es barato por solicitud. Pero un usuario ejecutando 500 solicitudes al día cuesta $7.75/día, o $232/mes en costos de API. Si ese usuario tiene un plan de $99/mes, se le está pagando $133/mes para que use el producto.
Prevención: Tres decisiones de arquitectura requeridas antes de lanzar cualquier función de IA en un plan de precio plano:
- Límites de consumo por usuario por tier: El tier gratuito obtiene 100 acciones de IA/mes. Starter obtiene 500. Professional obtiene 2,000. Enterprise negocia personalizadamente. Límites duros, no límites blandos.
- Monitoreo de uso con alertas automáticas: Cuando alguna cuenta supere el 150% del consumo modelado de su tier, el sistema genera una alerta para revisión. No solo por razones de facturación, sino porque los patrones de uso anómalos a menudo indican un problema de calidad de datos o un comportamiento del usuario que usa la IA de manera no prevista.
- Precios basados en costo para empresas: Los clientes empresariales con alto uso esperado deben tener precios basados en consumo o precios por niveles con costos de exceso claros. Un cliente que generará $2,000/mes en costos de API no debería tener un contrato plano de $500/mes.
Modo de Fallo 5: Función de IA igualada por un competidor en 30 días
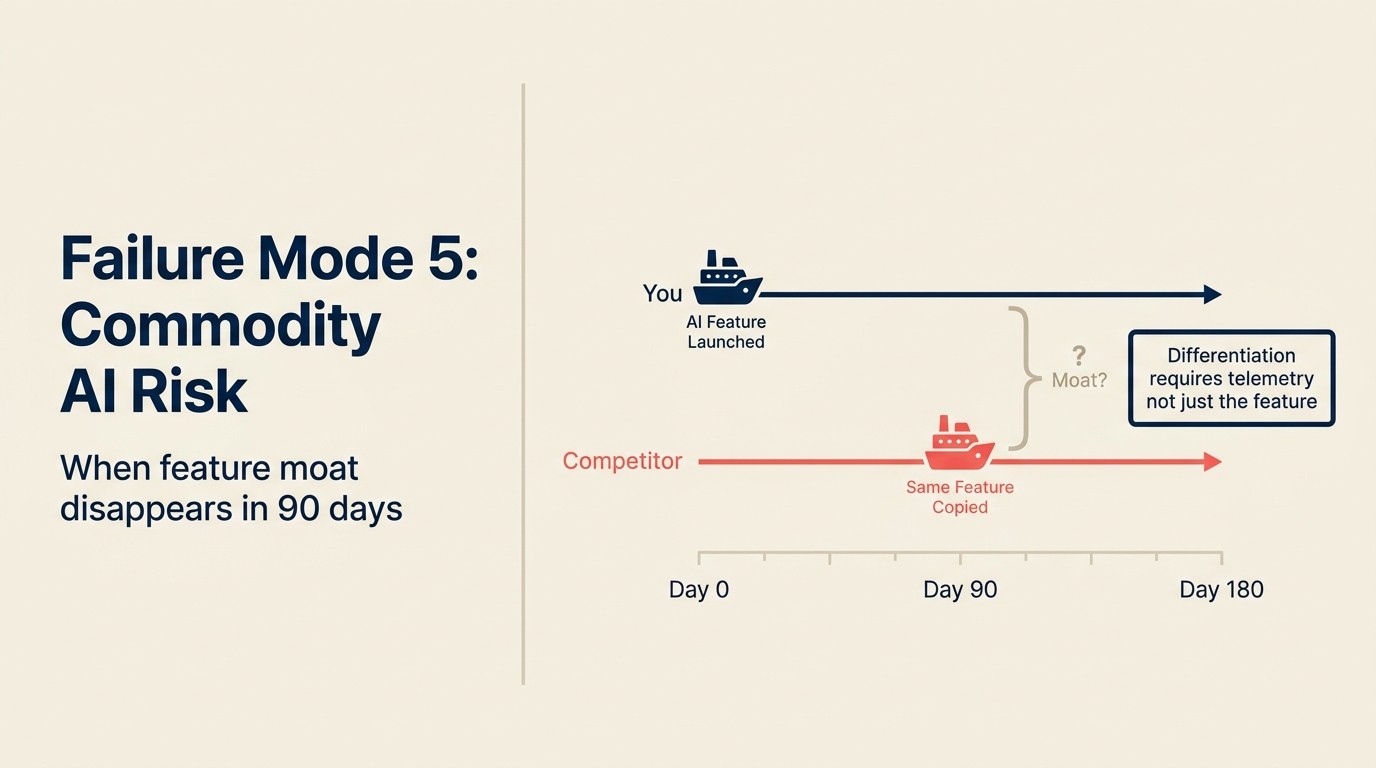
Una empresa SaaS lanza una función de IA de resumen de contratos que su equipo de ventas usa para acelerar las revisiones de acuerdos. Tarda 4 meses en construirse. En el lanzamiento, es un diferenciador: ningún competidor ofrece esto en producto. El equipo lo comercializa prominentemente.
Seis semanas después del lanzamiento, dos competidores lanzan funciones equivalentes. Uno hace wrap de Claude directamente. El otro integra una herramienta de IA de contratos de terceros. Ambos están activos en el plazo de 30 días del otro. El moat competitivo que la empresa construyó durante 4 meses tiene una vida útil de 8 semanas.
Este es el fallo sin moat: lanzar una función de IA que crea un diferenciador temporal pero no crea una ventaja estructural porque es replicable por cualquier competidor con una suscripción a API de LLM y unas pocas semanas de tiempo de ingeniería.
La mayoría de las funciones de IA construidas sobre APIs de LLM genéricas son replicables en 4-8 semanas por un equipo de ingeniería competidor competente. La diferenciación de la función en sí es real pero temporal. La única diferenciación duradera es (a) datos: la propia versión es mejor porque está entrenada en el comportamiento real de los propios usuarios, o (b) profundidad de integración: la propia versión es mejor porque está tan profundamente integrada en el flujo de trabajo que cambiar requiere reaprender todo. El artículo sobre telemetry loops para IA en producto explica cómo construir el flywheel de datos que crea la opción (a).
El costo: 4 meses de tiempo de ingeniería para construir una función que diferencia durante 8 semanas. Con un costo de ingeniería cargado de $250,000/año, eso son aproximadamente $83,000 invertidos por 2 meses de diferenciación competitiva. Los cálculos del ROI requieren que las 8 semanas de diferenciación hayan impulsado tasas de éxito en acuerdos significativamente mejores, lo que típicamente no es medible.
Prevención: Antes de construir cualquier función de IA que tome más de 6 semanas de ingeniería, responder a la pregunta: "En 90 días, cuando dos competidores hayan lanzado funcionalidad equivalente, ¿qué hace que la nuestra sea significativamente mejor?" Si la respuesta no es una de (moat de datos, profundidad de integración, calidad del telemetry loop), hay que o bien hacer wrap de la función más rápido y barato, o invertir el tiempo de ingeniería en funciones que crean moats duraderos.
Modo de Fallo 6: Función de IA que crea una carga de soporte
Una empresa SaaS lanza una función de puntuación de prioridades de IA para su herramienta de gestión de proyectos. La IA asigna puntuaciones de prioridad a las tareas y muestra los elementos de mayor prioridad en un email de resumen diario. Esto suena útil y en las pruebas internas, el equipo lo adora.
En producción, el 40% de los usuarios encuentra que las sugerencias de prioridad de la IA son incorrectas para su contexto. La IA no entiende la definición de prioridad de su equipo, que está influenciada por plazos, relaciones con los stakeholders y contexto que no está capturado en los metadatos de las tareas. Los usuarios empiezan a crear tickets de soporte: "¿Por qué la IA dice que X es de alta prioridad cuando claramente no lo es?" El equipo de soporte ahora dedica tiempo a explicar el comportamiento de la IA que no entiende completamente.
El volumen de tickets de soporte para la función de IA en el mes uno: 180 tickets. El costo de soporte a $12/ticket totalmente cargado: $2,160. Mensual. Para una función que se suponía iba a reducir la carga cognitiva.
El fallo se compone: los usuarios que presentan tickets de soporte de IA tienen más probabilidades de abandonar que los usuarios que no lo hacen. No porque la función de IA haya fallado, sino porque la interacción de soporte creó una narrativa: "La IA de este producto no entiende mi contexto." Esa narrativa se adjunta al producto, no solo a la función.
El mismo patrón aparece en las herramientas de CS con IA. Un sistema de puntuación de salud genera 50 alertas de "en riesgo" por semana, el 60% de las cuales resultan ser falsos positivos después de la investigación del CSM. Después de cuatro semanas, los CSMs empiezan a ignorar las alertas sin comprobarlas. Cuando las cuentas realmente en riesgo aparecen en la cola, se ignoran junto con los falsos positivos. Se ha pagado por un sistema de puntuación de salud que el equipo de CS ha depreciado mentalmente.
Prevención: Dos métricas que deben estar en verde antes de que cualquier recomendación generada por IA llegue a los clientes:
- Precisión: De las veces que la IA señala algo (en riesgo, alta prioridad, acción recomendada), ¿qué porcentaje es correcto? Si la precisión está por debajo del 70%, la función crea más ruido que señal. La mayoría de los usuarios aprenderán a ignorarla.
- Loop de feedback para correcciones: Los usuarios necesitan poder decirle a la IA que estaba equivocada, y ese feedback necesita cambiar realmente el comportamiento de la IA. Una función de IA sin mecanismo de corrección entrena a los usuarios a ver la IA como una caja negra con la que no se puede razonar. Esa percepción destruye la confianza más rápido que cualquier respuesta incorrecta individual.
La versión de puntuación de salud de CS de esto: no alertar sobre cada cuenta que caiga por debajo de un umbral. Alertar sobre las cuentas que caen inesperadamente en relación con su trayectoria reciente. Menos alertas, mayor precisión, confianza del CSM mantenida.
"El fallo silencioso es el modo dominante en la IA SaaS. El producto se lanza, sale el changelog, el comunicado de prensa dice 'estamos invirtiendo fuertemente en IA,' y luego no ocurre nada obvio. Los registros de la función de IA muestran un 3% de uso activo semanal en el mes tres. El chatbot de soporte es silenciosamente deshabilitado por el cliente empresarial que fue perjudicado por una respuesta incorrecta. La IA de puntuación de salud está siendo ignorada por los CSMs que han visto demasiadas alertas de falsos positivos." (Rework Analysis, 2025)
"Una función típica de AI copilot en producto tarda 3-4 meses de tiempo de ingeniería en construirse correctamente. Con un costo combinado de ingeniería de $250,000/año, eso son $60,000-80,000 de inversión. Si el 3% de los usuarios la usa y ninguno la cita como razón de renovación, el equipo quemó $75,000 para añadir una función a la página de precios." (Rework Analysis, basado en análisis de costos de proyectos GenAI de Gartner, 2025)
"El volumen de tickets de soporte para una función de IA con precisión por debajo del umbral: 180 tickets por mes, a $12/ticket totalmente cargado, son $2,160 por mes en costos de soporte para una función que se suponía iba a reducir la carga cognitiva. El fallo se compone: los usuarios que presentan tickets de soporte de IA tienen más probabilidades de abandonar que los que no lo hacen, porque la interacción de soporte crea una narrativa del producto que se adjunta a todo el producto." (Rework Analysis, 2025)
"Tres clientes empresariales usando un asistente de escritura de IA a precio plano con 8,000-12,000 solicitudes de generación por mes cada uno, pagando $49/mes, crean una responsabilidad de costo de API trimestral de $72,000-84,000 contra $441 en MRR combinado. La empresa ahora está pagando para que esos clientes usen el producto. Esto no es hipotético." (Rework Analysis, basado en precios de OpenAI e incidentes documentados de costo de tokens en SaaS, 2025)
Lista de Verificación para la Prevención de Modos de Fallo de IA en SaaS

| Modo de Fallo | Señal de Alerta Temprana | Ventana de Detección | Prevención |
|---|---|---|---|
| Funciones que nadie usa | WAU (weekly active users) del 90 días por debajo del 10% | Días 30-60 | Validar el punto de inserción antes de construir |
| Contenido de IA daña el SEO | Caída del tráfico orgánico 3 meses después de publicar | 90-120 días | Capa de contribución original en cada pieza de IA |
| Resultados incorrectos impulsan el churn | Pico de soporte o solicitudes de reembolso de usuarios afectados por IA | 30-90 días | Gate de revisión humana para resultados de IA de alto impacto |
| Desbordamiento del costo de tokens | El costo mensual de API supera el 50% de los ingresos del plan para cualquier cuenta | 30-60 días | Caps de consumo por usuario antes del lanzamiento |
| Función sin moat igualada | Un competidor lanza el equivalente en 60 días | 6-12 semanas | Telemetry loop en el lanzamiento; profundidad de integración |
| IA que crea carga de soporte | Tickets de soporte para la función de IA; tasa de ignorar alertas del CSM por encima del 30% | 30-60 días | Umbral de precisión por encima del 70% antes de lanzar |
Fuentes: Gartner GenAI Project Failure Analysis 2025, McKinsey AI Risk and Cost Research 2025, Gartner LLM Observability Predictions 2026
"Para 2028, las inversiones en observabilidad de LLM alcanzarán el 50% de los despliegues de IA generativa específicamente porque las alucinaciones, los sesgos y los fallos de confianza requerirán infraestructura de monitoreo que la mayoría de las empresas SaaS no están construyendo hoy. Los equipos que empiecen esa instrumentación ahora estarán por delante de la curva de cumplimiento y expectativas del cliente." (Gartner, 2026)
Rework Analysis: El patrón en los seis modos de fallo es la disciplina de medición, no la sofisticación tecnológica. Todos los modos de fallo documentados aquí son visibles en los datos antes de que se vuelvan costosos, si se está mirando. Los equipos que despliegan IA, declaran victoria basándose en el anuncio de lanzamiento y no miden nada durante seis meses son los que descubren el Modo 1 en el mes 6 cuando los datos de uso cuentan una historia que el changelog no contaba. La lista de verificación de prevención de fallos no es gobernanza opcional. Es el hábito operativo que separa las inversiones de IA que componen de las que deprecian.
Cómo se ve realmente la prevención de fallos
El patrón en los seis modos de fallo es la disciplina de medición, no la sofisticación tecnológica. Todos los modos de fallo descritos aquí son visibles en los datos antes de que se vuelvan costosos, si se está mirando.
Una lista de verificación de prevención de fallos antes de desplegar cualquier función de IA:
La medición de línea base está en su lugar: Se conoce la métrica que esta función se supone debe mejorar, y se tiene la línea base pre-IA documentada. Si se despliega coaching de llamadas de IA sin registrar cómo se ve "buena calidad de discovery" antes de la IA, no se puede medir si funcionó.
El seguimiento de adopción está activo: Los usuarios activos semanales, la tasa de aceptación y la tasa de modificación están en un dashboard que alguien revisa semanalmente. El 3% de adopción en el día 30 es recuperable. El 3% de adopción en el día 90 es una función que se está pagando para mantener.
Las guardas de consumo están construidas: Cada función de IA en un plan de precio plano tiene límites por usuario y monitoreo de uso antes de que se lance, no después del primer ciclo de facturación anómalo.
Existen rutas de escalación: Cada función de IA que toca un resultado orientado al cliente tiene una ruta definida para que el cliente escale cuando la IA esté equivocada. Preferiblemente, esa escalación la gestiona un ser humano, no otra IA.
La precisión se mide y tiene umbral: Para cualquier función de IA que genera alertas o recomendaciones, se rastrea la precisión. La función no se lanza sin un umbral mínimo de precisión viable definido y probado.
Se rastrea la señal de confianza: Mensualmente, comprobar si los usuarios que se relacionan con las funciones de IA tienen tasas de NPS (Net Promoter Score) y churn más altas o más bajas que los usuarios que no lo hacen. Si el engagement con la función de IA se correlaciona con un mayor churn, se tiene un problema de confianza, y necesita diagnosticarse antes de que la función escale.
El fallo de la IA SaaS es recuperable si se detecta temprano. Los seis modos de fallo descritos aquí son todos medibles en los primeros 60-90 días si se están rastreando las señales correctas. Las empresas que se meten en problemas serios son las que despliegan IA, declaran victoria basándose en el anuncio de lanzamiento y no miden nada durante seis meses. Gartner predice que para 2028, las inversiones en observabilidad de LLM alcanzarán el 50% de los despliegues de IA generativa específicamente porque las alucinaciones, los sesgos y los fallos de confianza requerirán infraestructura de monitoreo que la mayoría de las empresas SaaS no están construyendo hoy, y los equipos que empiecen esa instrumentación temprano estarán por delante de la curva de cumplimiento y expectativas del cliente.
No declarar victoria antes de que la telemetría lo pruebe.
Aprenda Más:
- Why Most AI Transformations Fail: los patrones de fallo a nivel estratégico que crean las condiciones para los seis modos
- Hallucination Risk by Pattern: las condiciones técnicas que producen errores de IA con confianza por tipo de patrón
- Generate vs. Execute Boundary: el principio del ACE Framework para cuándo la IA necesita aprobación humana antes de actuar
- AI Anti-Patterns: el catálogo de fallos a nivel de patrón que complementa los modos de fallo específicos de SaaS
- Telemetry Loops para IA en Producto: infraestructura de medición que detecta los fallos en el día 30, no en el mes 6
- La Carrera Armamentista de IA en SaaS: Velocidad para Lanzar: la presión competitiva que crea las condiciones para lanzar sin gates de calidad
- Las Etapas de Madurez de IA en SaaS: dónde se agrupan estos modos de fallo por etapa de madurez
- Why AI Frameworks Fail: los patrones de fallo fundamentales a los que los fallos de IA en SaaS a menudo se remontan

Co-Founder, Rework.com
On this page
- Los 6 Modos de Fallo de IA en SaaS
- Modo de Fallo 1: Funciones de IA que los clientes no usan
- Modo de Fallo 2: Contenido generado por IA que daña el SEO
- Modo de Fallo 3: Churn impulsado por la IA debido a resultados incorrectos
- Modo de Fallo 4: Desbordamiento del costo de tokens
- Modo de Fallo 5: Función de IA igualada por un competidor en 30 días
- Modo de Fallo 6: Función de IA que crea una carga de soporte
- Lista de Verificación para la Prevención de Modos de Fallo de IA en SaaS
- Cómo se ve realmente la prevención de fallos