Mod Kegagalan AI SaaS: Apa yang Sebenarnya Berlaku Salah (Dan Kos Sebenarnya)

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Kebanyakan kegagalan AI SaaS bukan dramatik. Tiada gangguan. Tiada tajuk berita. Produk dihantar, entri log perubahan keluar, siaran akhbar berkata "kami melabur banyak dalam AI," dan kemudian tiada yang jelas berlaku.
Apa yang sebenarnya berlaku adalah lebih senyap. Log ciri AI menunjukkan 3% penggunaan aktif mingguan pada bulan tiga. CSM berhenti membuka papan pemuka skor kesihatan kerana ia telah memanggil terlalu banyak akaun sebagai "berisiko" yang tidak melakukan churn. Chatbot sokongan dilumpuhkan secara senyap oleh pelanggan perusahaan yang terkena jawapan yang salah dan meningkatkan kes ke VP CS Anda. Kandungan SEO yang dijana AI yang kelihatan seperti kemenangan produktiviti kini mencetuskan dasar spam Google pada halaman yang sebelumnya mendapat kedudukan baik.
Kegagalan senyap adalah mod dominan. Dan ia lebih mahal daripada kegagalan dramatik kerana Anda tidak tahu ia berlaku sehingga Anda mengukur kesan hiliran, yang kebanyakan pasukan tidak lakukan.
Artikel ini merangkumi enam mod kegagalan khusus dalam AI SaaS, dengan apa yang sebenarnya kos dan apa yang mencegahnya. Ia bukan rangka kerja risiko AI generik. Ia khusus untuk dinamik hasil SaaS, hubungan pembeli SaaS, dan alat AI yang syarikat SaaS sebenarnya gunakan.
6 Mod Kegagalan AI SaaS
6 Mod Kegagalan AI SaaS adalah rangka kerja diagnostik yang memetakan cara paling biasa inisiatif AI SaaS gagal merentasi seluruh permukaan kegagalan. Mod 1 (Ciri yang Tiada Siapa Menggunakan): titik insertion yang salah, kualiti di bawah ambang kepercayaan, atau kegagalan penemuan. Mod 2 (Kandungan AI Merosakkan SEO): tiada lapisan sumbangan asal pada kandungan yang dijana AI, kandungan nipis yang mencetuskan penalti kualiti Google. Mod 3 (Output Salah Memacu Churn): output yang menghadap pelanggan yang dijana AI tanpa gerbang semakan untuk senario berisiko tinggi. Mod 4 (Kos Token Lari): pakej AI harga rata tanpa seni bina penggunaan, pengguna kuasa yang memusnahkan ekonomi unit. Mod 5 (Padanan Ciri Tanpa Parit): ciri AI yang boleh ditiru oleh pesaing dalam 4-8 minggu tanpa gelung telemetri yang mencipta ketahanan. Mod 6 (AI Beban Sokongan): cadangan AI di bawah ambang ketepatan, mencipta bunyi yang dipelajari CSM dan ejen sokongan untuk diabaikan. Keenam mod tidak sama kemungkinannya atau sama kosnya, tetapi kesemua enam boleh dicegah dengan pengukuran awal.
Mod Kegagalan 1: Ciri AI yang pelanggan tidak gunakan
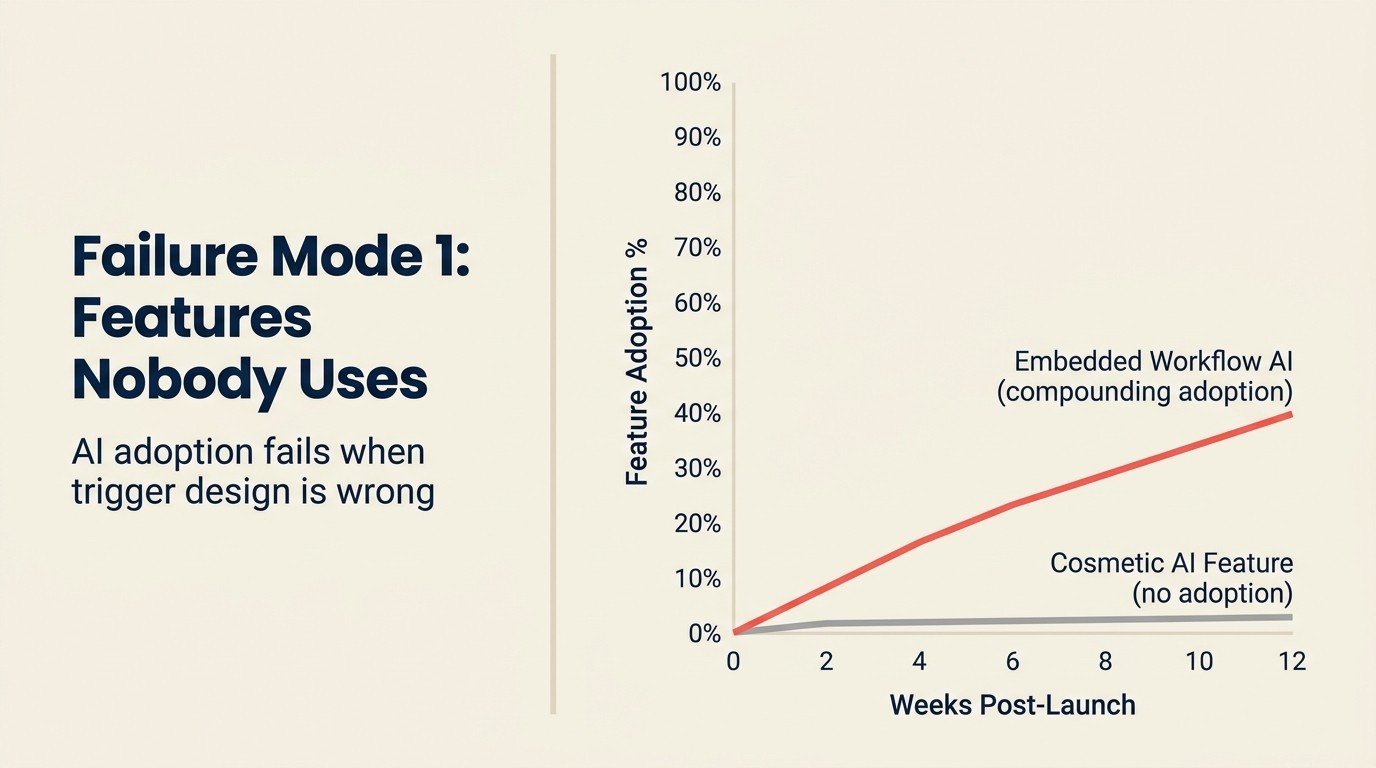
Anda membinakannya. Anda menghantarnya. 3% pengguna menyentuhnya dalam 30 hari pertama, dan kini ia adalah item baris dalam laporan tahunan Anda di bawah "keupayaan AI" yang tiada pelanggan yang membayar sebenarnya menyebutnya.
Ini adalah kegagalan AI SaaS yang paling biasa dan paling mahal dari segi kos peluang. Ciri copilot AI dalam produk yang tipikal mengambil masa 3-4 bulan masa kejuruteraan untuk dibina dengan betul: integrasi API, reka bentuk prompt, telemetri, UI. Pada kos kejuruteraan campuran $250,000/tahun, itu adalah $60,000-80,000 pelaburan kejuruteraan. Jika 3% pengguna menggunakannya, dan tiada seorang pun menyebutnya sebagai sebab mereka memperbarui, Anda telah membakar $75,000 untuk menambah ciri pada halaman harga Anda.
Punca akar adalah khusus dan boleh didiagnosis. Gartner mendapati bahawa sekurang-kurangnya 50% projek AI generatif ditinggalkan selepas bukti konsep disebabkan kualiti data yang lemah, kawalan risiko yang tidak mencukupi, kos yang meningkat, atau nilai perniagaan yang tidak jelas, yang bermaksud ciri dengan kadar pengambilalihan sifar adalah norma industri, bukan pengecualian.
Titik insertion yang salah: AI muncul dalam bahagian aliran kerja yang dikunjungi pengguna dua kali seminggu, bukan sepuluh kali sehari. Cadangan AI dalam aliran kerja frekuensi rendah tidak membina tabiat yang diperlukan untuk pengambilalihan. Titik insertion AI yang paling bernilai berada dalam aliran kerja frekuensi tertinggi, bukan yang kelihatan paling mengagumkan. Ciri AI sebagai produk: di mana menambahnya menyediakan rangka kerja tiga penapis untuk mengenal pasti titik insertion yang betul sebelum membina.
Kualiti di bawah ambang kepercayaan: Ketepatan cadangan adalah 60-70% dalam ujian dalaman tetapi terasa seperti 40% kepada pengguna kerana kegagalan lebih diingati berbanding kejayaan. Kualiti AI perlu melebihi ambang kepercayaan sebelum pengguna bergantung padanya. Di bawah ambang itu, pengguna mencubanya sekali, mengalami kegagalan, dan berhenti. Ambang kepercayaan adalah lebih tinggi daripada yang dianggarkan oleh kebanyakan pasukan produk semasa pembangunan.
Kegagalan penemuan: Pengguna tidak tahu ciri itu wujud atau cara mengaksesnya. Ini kelihatan seperti masalah pemasaran tetapi ia sebenarnya adalah masalah reka bentuk produk. Ciri AI dalam produk yang memerlukan pengguna menavigasi ke bahagian berasingan, atau yang hanya muncul dalam menu tetapan, akan tidak kelihatan kepada kebanyakan pengguna. Ciri itu perlu muncul dalam konteks, pada masa ia relevan, tanpa memerlukan pengguna pergi mencarinya.
Pencegahan: Ukur tiga penunjuk utama sebelum ciri dihantar: frekuensi titik insertion yang dijangka, ambang kualiti penanda aras dari ujian pengguna (bukan ujian dalaman), dan penempatan penemuan dalam aliran pengguna. Jika mana-mana daripada tiga adalah lemah, perbaiki sebelum pelancaran. Menghantar dengan lebih cepat tidak membantu jika ciri itu tidak pernah diadaptasi.
Fakta Utama: Kadar Kegagalan AI SaaS
- Sekurang-kurangnya 50% projek AI generatif ditinggalkan selepas bukti konsep disebabkan kualiti data yang lemah, kawalan risiko yang tidak mencukupi, kos yang meningkat, atau nilai perniagaan yang tidak jelas (Gartner, 2025)
- 60-70% perusahaan menghadapi kegagalan pilot dalam pelaksanaan AI; hanya 10-20% eksperimen AI terpencil dalam dua tahun lalu sebenarnya berskala untuk mencipta nilai (MIT/McKinsey, 2025)
- Menjelang 2028, pelaburan pemerhati LLM akan mencapai 50% daripada penggunaan AI generatif khususnya kerana halusinasi, berat sebelah, dan kegagalan kepercayaan akan memerlukan infrastruktur pemantauan yang kebanyakan syarikat SaaS tidak sedang bina hari ini (Gartner, 2026)
Mod Kegagalan 2: Kandungan yang dijana AI yang merosakkan SEO

Syarikat SaaS mendapati mereka boleh melipatgandakan 10x output kandungan mereka dengan meminta AI menulis siaran blog, artikel pangkalan pengetahuan, dan halaman pendaratan. Mereka menerbitkan 200 artikel yang dijana AI dalam masa enam bulan. Tiga bulan kemudian, trafik carian organik mereka jatuh 35%.
Ini berlaku. Ia terus berlaku. Dan kos bukan hanya penurunan trafik. Ini adalah garis masa pemulihan: 12-18 bulan untuk membina semula autoriti domain selepas penalti isyarat kualiti Google, dengan mengandaikan Anda juga telah mengeluarkan atau mengerjakan semula secara substansial kandungan yang mencetuskannya.
Mekanisme khusus: sistem kandungan berguna Google dan pasukan semakan manual menandakan kandungan nipis yang dijana AI dengan nilai asal yang rendah. Halaman yang tidak menunjukkan penyelidikan asal, kepakaran khusus, atau maklumat yang benar-benar berguna yang tidak wujud di tempat lain mendapat de-index atau diturunkan secara ketara. Kelompok 200 artikel yang dijana AI tanpa penyelidikan asal, tanpa isyarat kepakaran pengarang, dan tanpa data unik adalah tepat apa yang sistem ini direka untuk menghukum.
Impak dolar: syarikat SaaS dengan ARR $5 juta yang menjalankan 30% pemerolehan pelanggan melalui carian organik mungkin menjana $500,000-700,000/tahun dalam pipeline daripada saluran tersebut. Penurunan trafik organik 35% diterjemahkan kepada impak pipeline tahunan $175,000-245,000, ditambah kos pelaburan penciptaan kandungan yang menghasilkan masalah.
Pencegahan: Kandungan yang dijana AI memerlukan lapisan editorial yang tulen sebelum penerbitan. Bukan pas tatabahasa. Lapisan sumbangan asal: pendapat pakar khusus yang ditambah, data asal yang disertakan, atau contoh konkrit dari pengalaman pelanggan sebenar. Kandungan yang tidak boleh lulus ujian "adakah ini mengandungi sesuatu yang tidak wujud dalam data latihan?" tidak sedia untuk diterbitkan. Risiko halusinasi mengikut corak merangkumi syarat teknikal yang menjadikan kandungan AI tidak boleh dipercayai dan corak mana yang paling terdedah kepada ralat yang yakin.
Untuk kandungan pangkalan pengetahuan teknikal, risiko adalah lebih rendah kerana ketepatan lebih penting daripada keaslian. Untuk kandungan blog bahagian atas corong yang bersaing untuk kata kunci kompetitif, AI yang dijana tanpa editorial adalah liabiliti, bukan aset.
Mod Kegagalan 3: Churn yang dipacu AI daripada output yang salah
Syarikat SaaS peringkat pertengahan menggunakan aliran onboarding berkuasa AI untuk mengurangkan masa-ke-nilai. AI mengesyorkan bahagian produk berdasarkan kes penggunaan yang dinyatakan pengguna semasa pendaftaran. Selama tiga bulan, ini berfungsi dengan baik.
Kemudian kelompok pendaftaran perusahaan mencetuskan pepijat dalam logik pembahagian. AI menghala 40 sesi onboarding perusahaan ke aliran kerja yang direka untuk pasukan kecil. Pengguna tersebut mengalami onboarding yang terasa tidak relevan dan mengelirukan. Tiket sokongan melonjak. 11 daripada 40 akaun meminta bayaran balik atau tidak menukar dari percubaan. Impak hasil adalah $180,000 dalam ARR yang tidak ditutup.
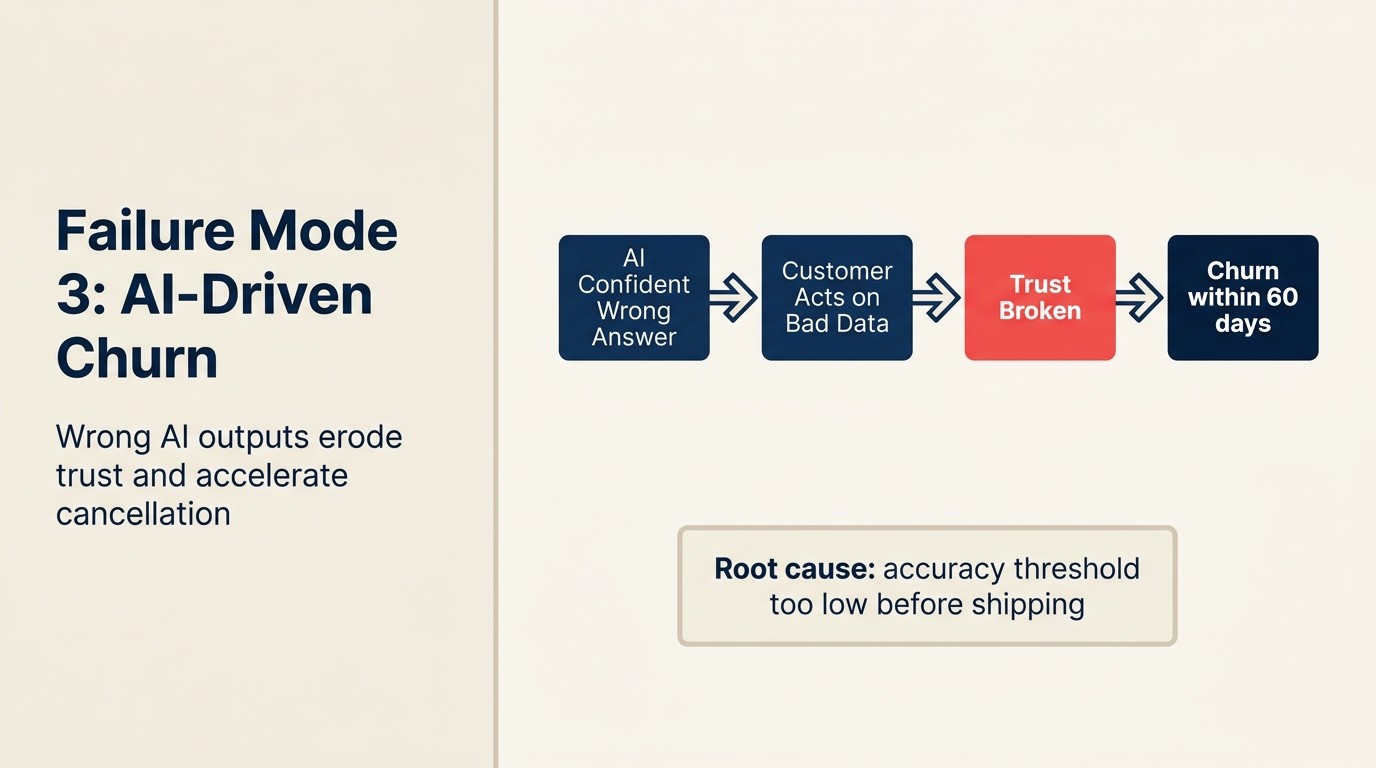
Inilah churn yang dipacu AI: kes di mana output AI secara aktif merosakkan hubungan pelanggan berbanding membantukannya. Ia berbeza daripada pepijat perisian standard kerana bahayanya bukan "ciri tidak berfungsi." Ia "AI memberi pelanggan maklumat yang salah atau pengalaman yang salah, dan pelanggan kini meragui sama ada produk Anda memahami kes penggunaan mereka."
Corak kegagalan berulang dalam pemarkahan kesihatan. Skor kesihatan AI alat CS memanggil akaun perusahaan yang sedang churn sebagai "hijau" selama tiga bulan. CSM, yang mempercayai skor, tidak campur tangan dengan kekerapan biasa pemeriksaan. Akaun melakukan churn semasa pembaruan. Autopsi menunjukkan skor kesihatan memberikan berat kepada penggunaan produk berbanding sentimen tiket sokongan, dan akaun mempunyai penggunaan yang tinggi dan kekecewaan yang tinggi secara serentak.
Versi chatbot sokongan: chatbot AI memberikan jawapan yang salah tentang keupayaan eksport data kepada prospek dalam percubaan, yang secara khusus menilai produk untuk ciri tersebut. Prospek memilih pesaing. Tiada siapa yang tahu ini berlaku kerana perbualan chatbot tidak disemak. McKinsey mengenal pasti kebimbangan risiko dan kelebihan kos sebagai sebab utama inisiatif AI gagal untuk melintas dari prototaip ke pengeluaran, dan hanya 10 hingga 20% eksperimen AI terpencil dalam dua tahun lalu sebenarnya berskala untuk mencipta nilai, yang merupakan latar belakang di mana mod kegagalan khusus SaaS ini berlaku.
Pencegahan: Setiap ciri AI yang menjana output menghadap pelanggan memerlukan gerbang semakan manusia untuk senario berisiko tinggi. Bukan gerbang pada setiap output, tetapi gerbang yang ditentukan oleh tahap impak. Output AI berisiko rendah (cadangan draf, ringkasan dalaman) boleh digunakan secara automatik. Output berisiko tinggi (penghalaan onboarding, sebut harga harga, dakwaan ketersediaan ciri, amaran skor kesihatan yang mencetuskan perubahan tingkah laku CSM) memerlukan mekanisme semakan sebelum ia mempengaruhi pelanggan.
Tentukan "berisiko tinggi" secara eksplisit sebelum menggunakan. Ia adalah keputusan produk, bukan keputusan infrastruktur. Sempadan jana berbanding laksana menerangkan prinsip ACE Framework untuk bila output AI memerlukan kelulusan manusia sebelum dilaksanakan.
Mod Kegagalan 4: Kos token yang lari
Syarikat SaaS menghantar pembantu penulisan AI sebagai sebahagian daripada pelan $49/bulan dengan penjanaan AI tanpa had. Ujian dalaman menunjukkan 95% pengguna menjana 50-100 output sebulan. Pemodelan mengatakan kos API akan berjalan pada $0.80-1.20 setiap pengguna sebulan. Ciri itu dihantar.
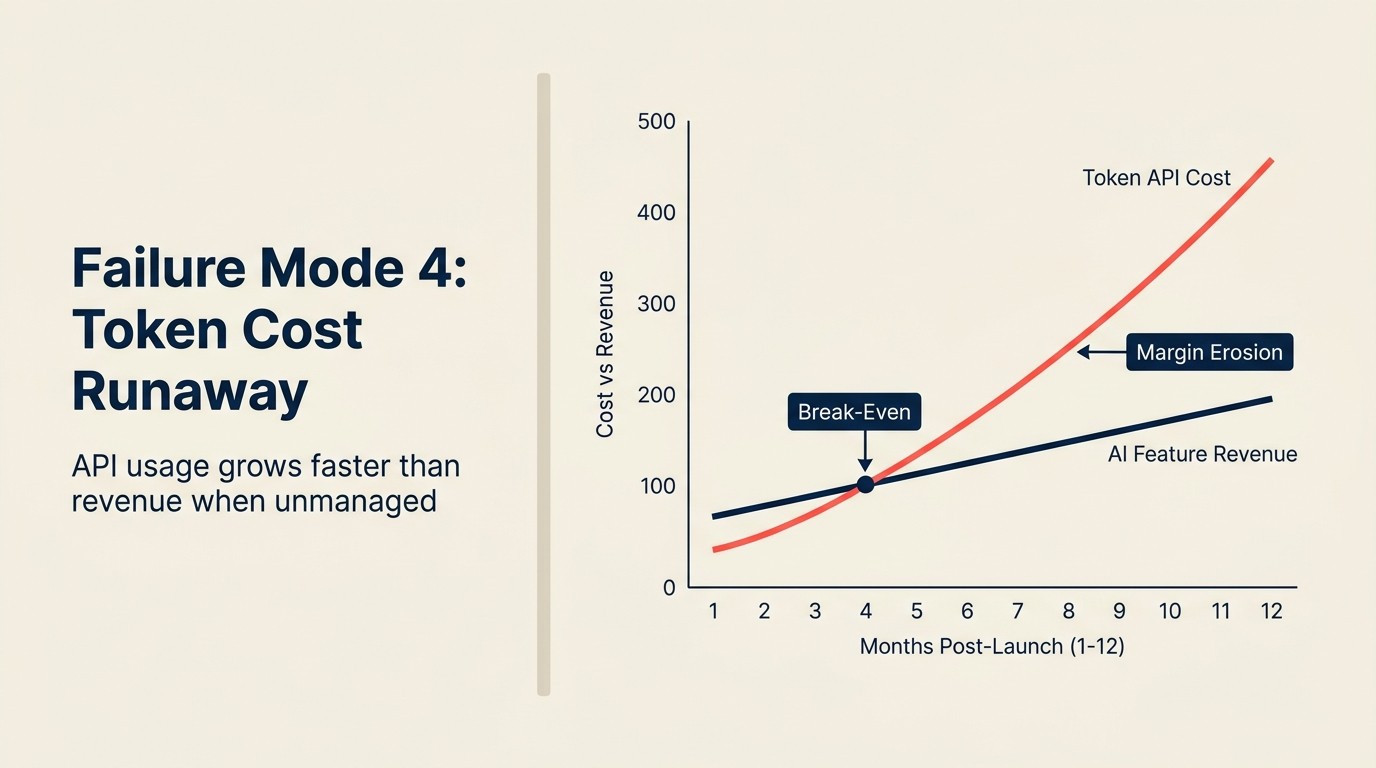
Enam bulan kemudian, tiga pelanggan perusahaan yang menggunakan produk untuk operasi kandungan berskala besar masing-masing menjalankan 8,000-12,000 permintaan penjanaan AI sebulan. Pada purata $0.80/permintaan, itu adalah $6,400-9,600 setiap pelanggan sebulan dalam kos API, untuk pelanggan yang membayar $49/bulan. Pasukan produk tidak memodelkan pengguna persentil ke-99. Mereka memodelkan pengguna median.
Jumlah impak suku tahunan: tiga pelanggan mencipta liabiliti kos API $72,000-84,000 terhadap MRR gabungan $441. Syarikat kini membayar untuk pelanggan tersebut menggunakan produk.
Ini bukan hipotetikal. Corak ini berlaku dalam pelbagai produk SaaS semasa 2023-2024 apabila pasukan menetapkan harga ciri AI secara rata tanpa seni bina penggunaan. Pemodelan pengguna median kelihatan baik. Pengguna kuasa memusnahkan ekonomi unit.
Pengiraan: OpenAI GPT-4o mengenakan caj $2.50/juta token input dan $10/juta token output. Satu permintaan penulisan AI dengan 3,000 token konteks dan 800 token output berharga $0.0155. Itu murah setiap permintaan. Tetapi pengguna yang menjalankan 500 permintaan sehari menelan belanja $7.75/hari, atau $232/bulan dalam kos API. Jika pengguna tersebut berada pada pelan $99/bulan, Anda membayar mereka $133/bulan untuk menggunakan produk Anda.
Pencegahan: Tiga keputusan seni bina yang diperlukan sebelum menghantar sebarang ciri AI pada pelan harga rata:
- Had penggunaan setiap pengguna mengikut peringkat: Peringkat percuma mendapat 100 tindakan AI/bulan. Starter mendapat 500. Professional mendapat 2,000. Perusahaan berunding secara khusus. Had keras, bukan had lembut.
- Pemantauan penggunaan dengan amaran automatik: Apabila mana-mana akaun melebihi 150% penggunaan yang dimodelkan untuk peringkat mereka, sistem menjana amaran untuk semakan. Bukan hanya untuk sebab pengebilan, tetapi kerana corak penggunaan yang luar biasa sering menunjukkan masalah kualiti data atau tingkah laku pengguna yang menggunakan AI dengan cara yang tidak dimaksudkan.
- Harga berasaskan kos untuk perusahaan: Pelanggan perusahaan dengan penggunaan yang dijangka tinggi harus berada pada harga berasaskan penggunaan atau harga bertingkat dengan kos lebihan yang jelas. Pelanggan yang akan menjana $2,000/bulan dalam kos API tidak seharusnya berada pada kontrak rata $500/bulan.
Mod Kegagalan 5: Ciri AI dipadankan oleh pesaing dalam 30 hari
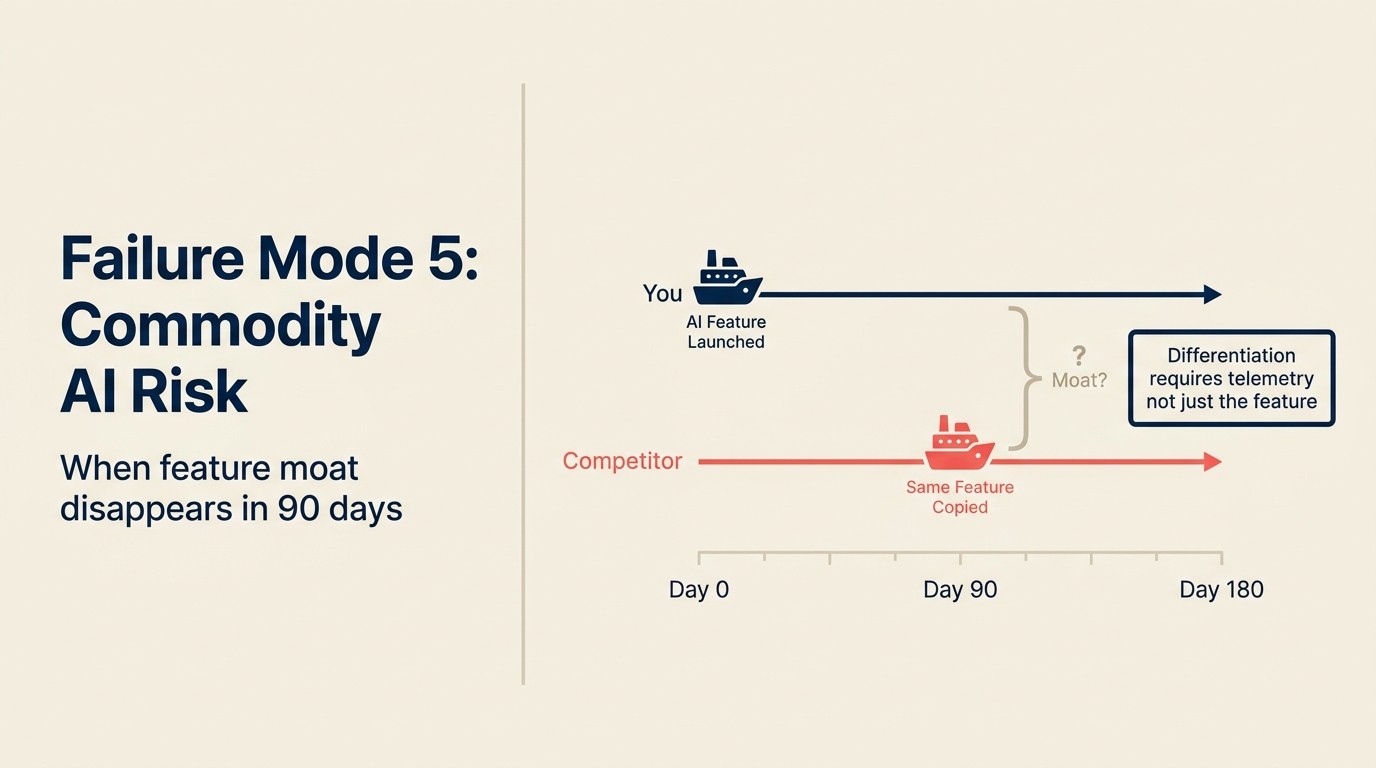
Syarikat SaaS menghantar ciri AI ringkasan kontrak yang pasukan jualan mereka gunakan untuk mempercepatkan semakan tawaran. Ia mengambil masa 4 bulan untuk dibina. Semasa pelancaran, ia adalah pembeza: tiada pesaing menawarkan ini dalam produk. Pasukan memasarkannya dengan menonjol.
Enam minggu selepas pelancaran, dua pesaing menghantar ciri yang setara. Satu membungkus Claude secara langsung. Yang lain mengintegrasikan alat AI kontrak pihak ketiga. Kedua-duanya aktif dalam masa 30 hari antara satu sama lain. Parit persaingan yang dibina syarikat selama 4 bulan mempunyai jangka hayat 8 minggu.
Inilah kegagalan tanpa parit: menghantar ciri AI yang mencipta pembeza sementara tetapi tidak mencipta kelebihan struktur kerana ia boleh ditiru oleh mana-mana pesaing dengan langganan API LLM dan beberapa minggu masa kejuruteraan.
Kebanyakan ciri AI yang dibina pada API LLM generik boleh ditiru dalam 4-8 minggu oleh pasukan kejuruteraan pesaing yang cekap. Diferensiasi dari ciri itu sendiri adalah nyata tetapi sementara. Satu-satunya diferensiasi yang tahan lama adalah sama ada (a) data: versi Anda lebih baik kerana dilatih pada tingkah laku sebenar pengguna Anda, atau (b) kedalaman integrasi: versi Anda lebih baik kerana ia begitu tertanam dalam aliran kerja sehingga penukaran memerlukan pembelajaran semula segalanya. Gelung telemetri untuk AI dalam produk menerangkan cara membina roda data yang mencipta pilihan (a).
Kos: 4 bulan masa kejuruteraan untuk membina ciri yang membezakan selama 8 minggu. Pada kos kejuruteraan yang dimuat $250,000/tahun, itu adalah lebih kurang $83,000 yang dilaburkan untuk 2 bulan diferensiasi persaingan. Pengiraan ROI memerlukan 8 minggu diferensiasi telah mendorong kadar kemenangan yang lebih baik secara bermakna, yang biasanya tidak boleh diukur.
Pencegahan: Sebelum membina sebarang ciri AI yang akan mengambil lebih daripada 6 minggu kejuruteraan, jawab soalan: "Dalam 90 hari, apabila dua pesaing telah menghantar fungsi yang setara, apa yang menjadikan versi kami lebih baik secara bermakna?" Jika jawapannya bukan salah satu daripada (parit data, kedalaman integrasi, kualiti dari gelung telemetri), Anda harus sama ada membungkus ciri dengan lebih cepat dan lebih murah, atau melabur masa kejuruteraan dalam ciri yang mencipta parit yang tahan lama.
Mod Kegagalan 6: Ciri AI mencipta beban sokongan
Syarikat SaaS menghantar ciri pemarkahan keutamaan AI untuk alat pengurusan projek mereka. AI menetapkan skor keutamaan kepada tugas dan memaparkan item keutamaan tertinggi dalam e-mel digest harian. Ini kelihatan berguna dan dalam ujian dalaman, pasukan menyukainya.
Dalam pengeluaran, 40% pengguna mendapati cadangan keutamaan AI salah untuk konteks mereka. AI tidak memahami definisi keutamaan pasukan mereka, yang dipengaruhi oleh tarikh akhir, hubungan pihak berkepentingan, dan konteks yang tidak ditangkap dalam metadata tugas. Pengguna mula mencipta tiket sokongan: "Mengapa AI mengatakan X adalah keutamaan tinggi apabila ia jelas tidak?" Pasukan sokongan kini membelanjakan masa menerangkan tingkah laku AI yang mereka tidak faham sepenuhnya.
Jumlah tiket sokongan untuk ciri AI pada bulan satu: 180 tiket. Kos sokongan pada $12/tiket dimuat penuh: $2,160. Sebulan. Untuk ciri yang sepatutnya mengurangkan beban kognitif.
Kegagalan berganda: pengguna yang memfailkan tiket sokongan AI lebih cenderung untuk melakukan churn berbanding pengguna yang tidak. Bukan kerana ciri AI gagal, tetapi kerana interaksi sokongan mencipta naratif: "AI produk ini tidak memahami konteks saya." Naratif itu melekat pada produk, bukan hanya ciri.
Corak yang sama muncul dalam alat CS AI. Sistem pemarkahan kesihatan menembak 50 amaran "berisiko" setiap minggu, 60% daripada mana-mana yang ternyata adalah positif palsu selepas siasatan CSM. Selepas empat minggu, CSM mula mengabaikan amaran tanpa memeriksa. Apabila akaun berisiko sebenar muncul dalam barisan gilir, ia diabaikan bersama-sama positif palsu. Anda telah membayar untuk sistem pemarkahan kesihatan yang pasukan CS Anda telah susut nilai secara mental.
Pencegahan: Dua metrik yang mesti hijau sebelum sebarang cadangan yang dijana AI dihantar kepada pelanggan:
- Ketepatan: Daripada kali AI menandai sesuatu (berisiko, keutamaan tinggi, tindakan yang disyorkan), berapa peratusan yang betul? Jika ketepatan adalah di bawah 70%, ciri mencipta lebih banyak bunyi daripada isyarat. Kebanyakan pengguna akan belajar untuk mengabaikannya.
- Gelung maklum balas untuk pembetulan: Pengguna perlu dapat memberitahu AI bahawa ia salah, dan maklum balas tersebut perlu sebenarnya mengubah tingkah laku AI. Ciri AI tanpa mekanisme pembetulan melatih pengguna untuk melihat AI sebagai kotak hitam yang tidak boleh dipengaruhi. Persepsi itu membunuh kepercayaan lebih cepat daripada mana-mana jawapan yang salah secara individu.
Versi CS pemarkahan kesihatan ini: jangan beri amaran pada setiap akaun yang jatuh di bawah ambang. Beri amaran pada akaun yang jatuh secara tidak dijangka berbanding trajektori terkini mereka. Amaran yang lebih sedikit, ketepatan lebih tinggi, kepercayaan CSM dikekalkan.
"Kegagalan senyap adalah mod dominan dalam AI SaaS. Produk dihantar, log perubahan keluar, siaran akhbar berkata 'kami melabur banyak dalam AI,' dan kemudian tiada yang jelas berlaku. Log ciri AI menunjukkan 3% penggunaan aktif mingguan pada bulan tiga. Chatbot sokongan dilumpuhkan secara senyap oleh pelanggan perusahaan yang terkena jawapan yang salah. AI pemarkahan kesihatan sedang diabaikan oleh CSM yang telah melihat terlalu banyak amaran positif palsu." (Analisis Rework, 2025)
"Ciri copilot AI dalam produk yang tipikal mengambil masa 3-4 bulan masa kejuruteraan untuk dibina dengan betul. Pada kos kejuruteraan campuran $250,000/tahun, itu adalah $60,000-80,000 pelaburan. Jika 3% pengguna menggunakannya dan tiada seorang pun menyebutnya sebagai sebab pembaruan, pasukan telah membakar $75,000 untuk menambah ciri pada halaman harga." (Analisis Rework, berdasarkan analisis kos projek GenAI Gartner, 2025)
"Jumlah tiket sokongan untuk ciri AI dengan ketepatan di bawah ambang: 180 tiket sebulan, pada $12/tiket dimuat penuh, adalah $2,160 sebulan dalam kos sokongan untuk ciri yang sepatutnya mengurangkan beban kognitif. Kegagalan berganda: pengguna yang memfailkan tiket sokongan AI lebih cenderung untuk melakukan churn berbanding pengguna yang tidak, kerana interaksi sokongan mencipta naratif produk yang melekat pada keseluruhan produk." (Analisis Rework, 2025)
"Tiga pelanggan perusahaan yang menggunakan pembantu penulisan AI harga rata pada 8,000-12,000 permintaan penjanaan sebulan masing-masing, membayar $49/bulan, mencipta liabiliti kos API $72,000-84,000 suku tahunan terhadap MRR gabungan $441. Syarikat kini membayar untuk pelanggan tersebut menggunakan produk. Ini bukan hipotetikal." (Analisis Rework, berdasarkan harga OpenAI dan insiden kos token SaaS yang didokumentasikan, 2025)
Senarai Semak Pencegahan Mod Kegagalan AI SaaS

| Mod Kegagalan | Isyarat Amaran Awal | Tetingkap Pengesanan | Pencegahan |
|---|---|---|---|
| Ciri yang tiada siapa menggunakan | WAU 90 hari di bawah 10% | Hari 30-60 | Sahkan titik insertion sebelum membina |
| Kandungan AI merosakkan SEO | Penurunan trafik organik 3 bulan selepas penerbitan | 90-120 hari | Lapisan sumbangan asal dalam setiap kandungan AI |
| Output salah memacu churn | Lonjakan sokongan atau permintaan bayaran balik dari pengguna yang disentuh AI | 30-90 hari | Gerbang semakan manusia untuk output AI berisiko tinggi |
| Kos token lari | Kos API bulanan melebihi 50% hasil pelan untuk mana-mana akaun | 30-60 hari | Had penggunaan setiap pengguna sebelum pelancaran |
| Padanan ciri tanpa parit | Pesaing menghantar yang setara dalam 60 hari | 6-12 minggu | Gelung telemetri semasa pelancaran; kedalaman integrasi |
| AI beban sokongan | Tiket sokongan untuk ciri AI; kadar abaian amaran CSM di atas 30% | 30-60 hari | Ambang ketepatan di atas 70% sebelum menghantar |
Sumber: Analisis Kegagalan Projek GenAI Gartner 2025, Penyelidikan Risiko dan Kos AI McKinsey 2025, Ramalan Pemerhati LLM Gartner 2026
"Menjelang 2028, pelaburan pemerhati LLM akan mencapai 50% daripada penggunaan AI generatif khususnya kerana halusinasi, berat sebelah, dan kegagalan kepercayaan akan memerlukan infrastruktur pemantauan yang kebanyakan syarikat tidak sedang bina hari ini. Pasukan yang memulakan instrumentasi tersebut sekarang akan berada di hadapan keluk pematuhan dan jangkaan pelanggan." (Gartner, 2026)
Analisis Rework: Corak merentasi semua enam mod kegagalan adalah disiplin pengukuran, bukan kecanggihan teknologi. Setiap mod kegagalan yang didokumentasikan di sini kelihatan dalam data sebelum ia menjadi mahal, jika Anda sedang melihat. Pasukan yang menggunakan AI, mengisytiharkan kemenangan berdasarkan pengumuman pelancaran, dan tidak mengukur apa-apa selama enam bulan adalah yang mendapati Mod 1 pada bulan 6 apabila data penggunaan menceritakan kisah yang tidak dilakukan oleh log perubahan. Senarai semak pencegahan kegagalan bukan tadbir urus pilihan. Ia adalah tabiat operasi yang memisahkan pelaburan AI yang berganda daripada pelaburan AI yang susut nilai.
Apa yang pencegahan kegagalan sebenarnya kelihatan seperti
Corak merentasi semua enam mod kegagalan adalah disiplin pengukuran, bukan kecanggihan teknologi. Setiap mod kegagalan yang diterangkan di sini kelihatan dalam data sebelum ia menjadi mahal, jika Anda sedang melihat.
Senarai semak pencegahan kegagalan sebelum menggunakan sebarang ciri AI:
Pengukuran garis asas siap: Anda tahu metrik yang ciri ini sepatutnya bertambah baik, dan Anda mempunyai garis asas pra-AI yang didokumentasikan. Jika Anda menggunakan bimbingan panggilan AI tanpa merekod apa yang "kualiti penemuan yang baik" kelihatan seperti sebelum AI, Anda tidak boleh mengukur sama ada ia berfungsi.
Penjejakan pengambilalihan aktif: Pengguna aktif mingguan, kadar penerimaan, dan kadar pengubahsuaian berada pada papan pemuka yang seseorang semak setiap minggu. Kadar pengambilalihan 3% pada hari 30 boleh dipulihkan. Kadar pengambilalihan 3% pada hari 90 adalah ciri yang Anda bayar untuk diselenggara.
Penjagaan penggunaan dibina: Setiap ciri AI pada pelan harga rata mempunyai had setiap pengguna dan pemantauan penggunaan sebelum ia dihantar, bukan selepas kitaran pengebilan yang luar biasa yang pertama.
Laluan eskalasi wujud: Setiap ciri AI yang menyentuh output menghadap pelanggan mempunyai laluan yang ditentukan bagi pelanggan untuk meningkatkan kes apabila AI salah. Sebaik mungkin, eskalasi tersebut dikendalikan oleh manusia, bukan AI yang lain.
Ketepatan diukur dan diberi ambang: Untuk sebarang ciri AI yang menjana amaran atau cadangan, ketepatan dijejak. Ciri itu tidak dihantar tanpa ambang ketepatan minimum yang layak yang ditentukan dan diuji.
Isyarat kepercayaan dijejak: Setiap bulan, periksa sama ada pengguna yang terlibat dengan ciri AI Anda mempunyai NPS dan kadar churn yang lebih tinggi atau lebih rendah berbanding pengguna yang tidak. Jika penglibatan ciri AI berkorelasi dengan churn yang lebih tinggi, Anda mempunyai masalah kepercayaan, dan ia perlu didiagnosis sebelum ciri berskala.
Kegagalan AI SaaS boleh selamat jika dikesan awal. Keenam mod kegagalan yang diterangkan di sini boleh diukur dalam 60-90 hari pertama jika Anda menjejak isyarat yang betul. Syarikat yang menghadapi masalah serius adalah yang menggunakan AI, mengisytiharkan kemenangan berdasarkan pengumuman pelancaran, dan tidak mengukur apa-apa selama enam bulan. Gartner meramalkan bahawa menjelang 2028, pelaburan pemerhati LLM akan mencapai 50% daripada penggunaan AI generatif khususnya kerana halusinasi, berat sebelah, dan kegagalan kepercayaan akan memerlukan infrastruktur pemantauan yang kebanyakan syarikat tidak sedang bina hari ini, dan pasukan yang memulakan instrumentasi tersebut awal akan berada di hadapan keluk pematuhan dan jangkaan pelanggan.
Jangan isytiharkan kemenangan sebelum telemetri membuktikannya.
Ketahui Lebih Lanjut:
- Mengapa Kebanyakan Transformasi AI Gagal: corak kegagalan peringkat strategi yang mencipta syarat untuk semua enam mod
- Risiko Halusinasi mengikut Corak: syarat teknikal yang menghasilkan ralat AI yang yakin mengikut jenis corak
- Sempadan Jana berbanding Laksana: prinsip ACE Framework untuk bila AI memerlukan kelulusan manusia sebelum bertindak
- Anti-Corak AI: katalog kegagalan peringkat corak yang melengkapi mod kegagalan khusus SaaS
- Gelung Telemetri untuk AI dalam Produk: infrastruktur pengukuran yang menangkap kegagalan pada hari 30, bukan bulan 6
- Perlumbaan Senjata AI dalam SaaS: Kelajuan Penghantaran: tekanan persaingan yang mencipta syarat untuk menghantar tanpa gerbang kualiti
- Peringkat Kematangan AI SaaS: di mana mod kegagalan ini berkelompok mengikut peringkat kematangan
- Mengapa Rangka Kerja AI Gagal: corak kegagalan asas yang sering dapat dikesan oleh kegagalan AI SaaS

Co-Founder, Rework.com
On this page
- 6 Mod Kegagalan AI SaaS
- Mod Kegagalan 1: Ciri AI yang pelanggan tidak gunakan
- Mod Kegagalan 2: Kandungan yang dijana AI yang merosakkan SEO
- Mod Kegagalan 3: Churn yang dipacu AI daripada output yang salah
- Mod Kegagalan 4: Kos token yang lari
- Mod Kegagalan 5: Ciri AI dipadankan oleh pesaing dalam 30 hari
- Mod Kegagalan 6: Ciri AI mencipta beban sokongan
- Senarai Semak Pencegahan Mod Kegagalan AI SaaS
- Apa yang pencegahan kegagalan sebenarnya kelihatan seperti