Health Scoring com IA para Clientes SaaS

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Quase toda empresa SaaS na Série B e além tem um health score de cliente. Pergunte aos CSMs se eles confiam nele, e a maioria dirá que verifica quando precisa justificar algo ao gestor, depois volta ao instinto.
Esse é o modo de falha do health scoring baseado em regras. Não é que o conceito esteja errado. É que regras aplicadas uniformemente a todas as contas, com pesos definidos por um comitê em vez de derivados de resultados reais de churn, produzem scores que são tecnicamente preenchidos e praticamente inúteis.
O health scoring com IA é diferente. Não porque IA seja mágica, mas porque o modelo é treinado no que realmente aconteceu com contas como essa, não no que um gerente de produto adivinhou que importaria.
Scoring Baseado em Regras vs. Health Scoring com IA
Um health score baseado em regras tipicamente funciona assim: se NPS está acima de 8 e frequência de login está acima de quatro vezes por semana e a conta respondeu aos últimos três emails do CSM, marque verde. Caso contrário, amarelo. Se submeteram uma solicitação de cancelamento, vermelho.
Essa abordagem tem dois problemas.
Key Facts: Health Scoring com IA para SaaS
- Empresas que implementam modelos de CS baseados em exceção (onde IA sinaliza contas em risco e CSMs lidam apenas com contas sinalizadas) reportam taxas de retenção 25-40% maiores e ROI 3-5x no headcount de Customer Success vs. monitoramento manual (Benchmarkit 2025 SaaS Performance Metrics)
- Modelos de churn com IA treinados em 80+ sinais comportamentais atingem 75-82% de precisão; os maiores ganhos de precisão de 2025-2026 vieram da adição de embeddings de sentimento baseados em LLM que detectam frases como "estamos avaliando opções" como 4-6x mais prováveis de fazer churn em 90 dias (Arete SaaS Research, 2025)
- 70% das empresas SaaS acreditam que IA é crucial para sua estratégia de retenção, e o mercado passou da fase piloto para implementação em escala completa de IA de CS, tornando o health scoring com IA uma baseline operacional dentro de 18 meses (EverAfter customer churn research, 2025)
Primeiro, os pesos são arbitrários. Alguém decidiu que NPS vale 30 pontos e frequência de login vale 20 pontos. Esses pesos não foram derivados de nenhum histórico de churn. Refletem as crenças da equipe sobre o que importa, que podem ou não corresponder à realidade.
Segundo, as regras tratam todas as contas da mesma forma. Uma conta enterprise com 500 usuários fazendo login duas vezes por semana pode estar profundamente incorporada no produto como ferramenta de workflow diário. Uma startup com 10 usuários fazendo login todo dia pode estar avaliando o produto em relação a um concorrente. O sinal bruto parece o oposto do que o risco realmente é.
O health scoring com IA treina no seu histórico real de churn. O modelo aprende quais sinais, em quais combinações, em quais contas, precederam resultados de churn. Os pesos são derivados de dados, não de opiniões internas sobre o que deveria importar.
O resultado é um score que os CSMs podem realmente interrogar: não apenas uma flag verde ou vermelha, mas um código de razão que diz "o sentimento dos tickets de suporte desta conta deteriorou ao longo dos últimos 45 dias, e historicamente esse padrão em contas de tamanho similar precedeu churn 68% das vezes."
O mecanismo que torna isso possível é o Anomaly Agent rodando continuamente por baixo do score.
O Padrão Anomaly Agent por Baixo
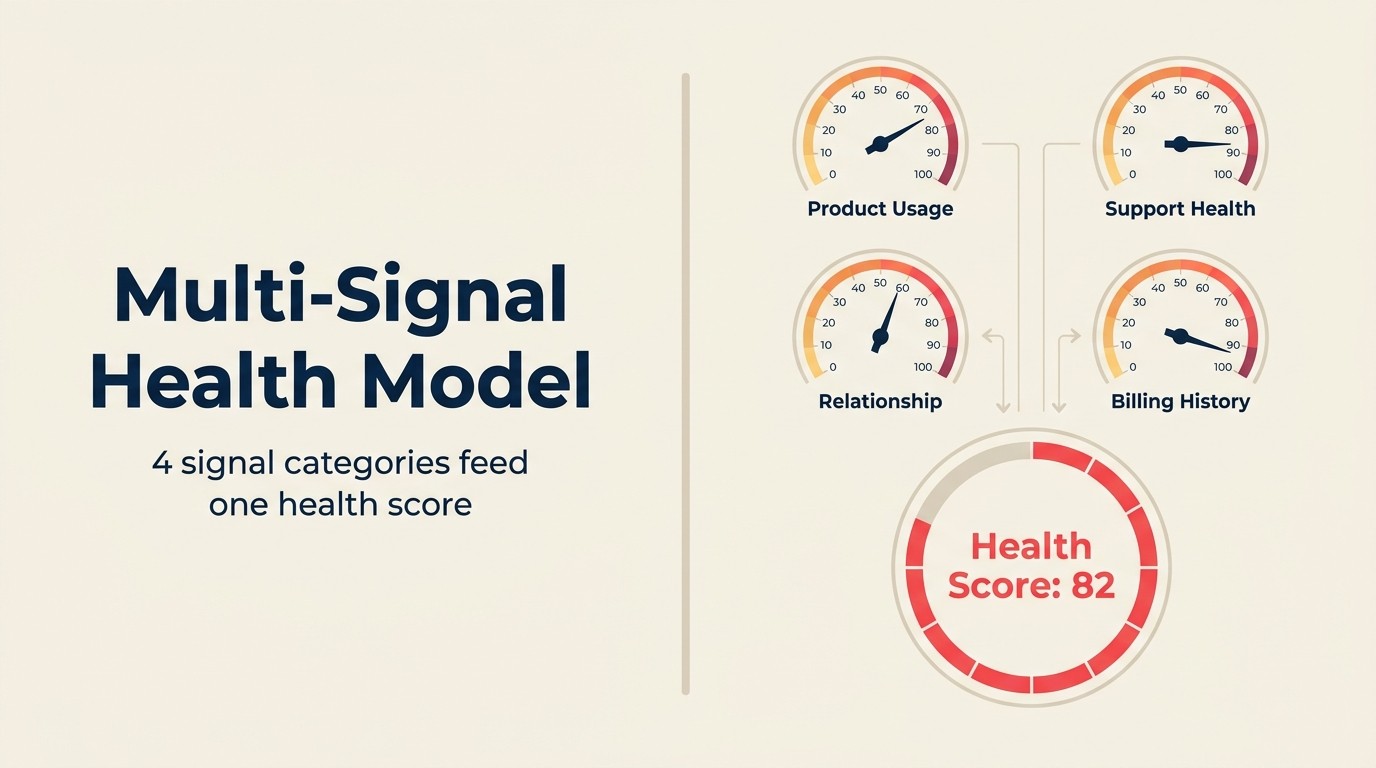
A forma correta de pensar sobre health scoring com IA no ACE Framework é como um Anomaly Agent contínuo. O modelo não pontua contas uma vez por mês e atualiza um Dashboard. Ele ingere um fluxo contínuo de sinais, estabelece baselines para comportamento normal em cada conta, e sinaliza quando o comportamento desvia desse baseline de formas que historicamente correlacionam com risco de churn.
O padrão Anomaly Agent roda: Ingest (sinais contínuos) depois Analyze (desvio do baseline específico da conta) depois Predict (mudança de risco de churn) depois Execute (acionar workflow ou alerta). Isso é diferente de alertas baseados em threshold porque o baseline é específico à conta. Uma queda de 20% na frequência de login em uma conta que tipicamente tem alto engajamento diário é um sinal mais forte do que a mesma queda em uma conta que sempre teve baixa frequência.
Essa especificidade por conta é o que torna o health scoring com IA mais preciso do que regras. E é o que o torna mais difícil de implementar: você precisa de dados históricos suficientes por tipo de conta para estabelecer baselines significativos.
Os sinais que você alimenta nesse modelo determinam quão precisa e acionável é a saída.
O Framework "Multi-Signal Health Model"
O Multi-Signal Health Model é o framework para health scoring com IA que produz scores nos quais os CSMs realmente confiam: combine sinais de uso (tendências de comportamento do produto em relação ao baseline específico da conta), sinais de relacionamento (sentimento de chamada, taxas de resposta do CSM, estabilidade do champion), sinais comerciais (timing de fatura, utilização do contrato, fit do tier de precificação), e sinais de sentimento de suporte (tendência de volume de tickets, taxa de escalação, satisfação) em um score composto com códigos de razão visíveis. Cada categoria de sinal contribui independentemente e os pesos são derivados de resultados reais de churn no histórico de contas, não de suposições de comitê. O modelo roda como um Anomaly Agent contínuo: detectando desvio de baselines específicos da conta em tempo real em vez de recalcular scores semanais de Dashboard. O teste prático de um bom Multi-Signal Health Model: os CSMs devem conseguir ler os códigos de razão e entender imediatamente por que uma conta mudou de cor e qual ação tomar.
Categorias de Sinal e o Que Realmente Preveem
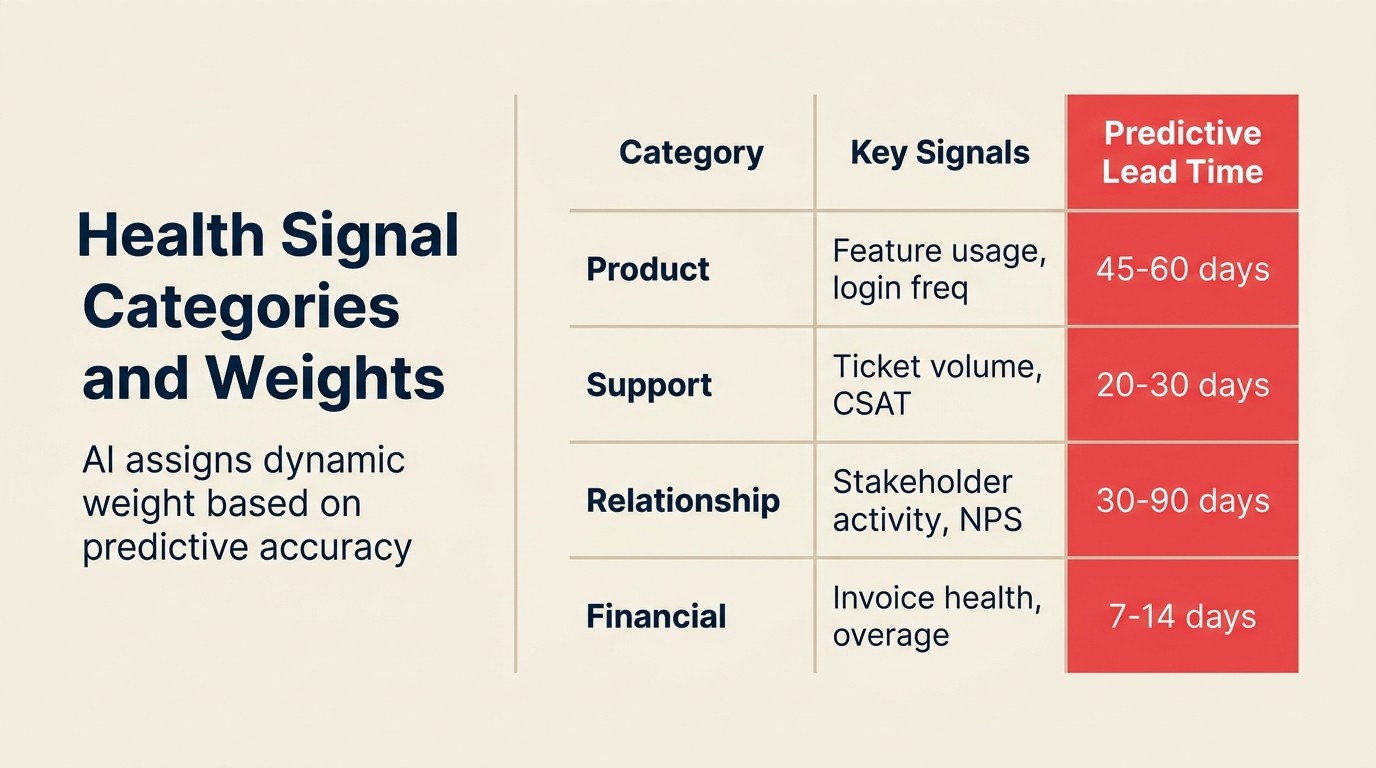
Nem todos os sinais têm igual peso, e os pesos variam por tipo de produto e segmento de cliente. Veja como pensar sobre as quatro categorias principais.
Sinais de uso do produto. Para empresas com PLG e ferramentas onde o uso ativo diário é esperado, esses sinais têm o maior peso. Frequência de login, amplitude de adoção de funcionalidades, workflows ativos, tendências de volume de chamadas de API, e indicadores de colaboração (número de teammates ativos) são os inputs mais fortes. A chave é tendência, não nível absoluto. Uma conta que tem declínio de uso por 60 dias está em maior risco do que uma conta no mesmo nível absoluto de uso que foi estável.
Sinais de qualidade de relacionamento. Esses importam mais para contas enterprise de alto toque. Frequência de chamadas, taxas de resposta do CSM, conclusão de QBR, scores de NPS, e sentimento a partir de transcrições de chamadas. Se um champion ficou quieto, isso é um sinal. Se chamadas de CSM são consistentemente reagendadas, isso é um sinal. O padrão Meeting Intelligence do ACE Framework pode analisar gravações de chamadas para pontuar sentimento ao longo do tempo e sinalizar quando o tom mudou de engajado para transacional.
Sinais de saúde comercial. Timing de pagamento de fatura, uso em relação a limites contratuais, número de tickets de suporte questionando termos de precificação ou contrato, e iniciação de conversa de renovação. Esses são sinais tardios em vez de indicadores antecipados, mas são de alta precisão: uma conta que começa a questionar itens de linha na fatura tem muito mais probabilidade de fazer churn do que uma que paga em dia.
Sinais de sentimento de suporte. Tendência de volume de tickets, taxa de escalação, o tom do texto de tickets abertos, classificações de satisfação de tempo de resolução, e se os tickets são sobre problemas de produto ou sobre querer reembolsos ou cancelamentos. Um rápido aumento nos tickets de suporte combinado com baixas classificações de satisfação é um dos mais fortes preditores de churn de curto prazo.
Mas você só pode usar esses sinais se tiver os dados de treinamento para calibrá-los em relação ao seu próprio histórico de churn.
Construindo o Conjunto de Treinamento
É aqui que a maioria das equipes trava: o health scoring com IA requer dados históricos para treinar, e não apenas quaisquer dados.
Para treinar um modelo de previsão de churn significativo, você tipicamente precisa de 2 a 3 anos de histórico de conta e pelo menos 100 contas que fizeram churn no conjunto de treinamento. O modelo precisa aprender como o churn se parece em tipos, tamanhos e padrões de uso de produto de contas diferentes. Se a sua base de churn for muito pequena ou homogênea, o modelo vai overfit e não vai generalizar bem para as contas do seu portfólio atual.
Se você ainda não tem esses dados, a decisão correta não é pular o health scoring com IA. É começar com scoring baseado em regras bem projetado agora, registrar cada sinal que você está rastreando, e começar a construir o conjunto de dados de treinamento sistematicamente. Documente quando contas fazem churn e como foi o histórico de sinais delas nos 90 dias anteriores. Em 18 meses, você terá os dados para tornar a transição para scoring baseado em IA significativa.
O Gainsight trabalha desta forma: pode começar com dados de benchmark da Gainsight (derivados de padrões de churn na base de clientes deles) e depois se adaptar progressivamente aos seus padrões históricos específicos conforme esses dados se acumulam. O Planhat usa uma abordagem de modelo de dados onde você define a arquitetura de sinal e o modelo é treinado no seu próprio histórico de conta. O ChurnZero usa scoring baseado em benchmark que compara suas contas com benchmarks do setor para estágios de empresa similares, o que é útil quando você ainda não tem histórico de churn suficiente.
Mesmo um modelo bem treinado cria um problema se os próprios scores geram falsa confiança.
O Problema da Falsa Confiança
Um health score que prevê verde em contas que subsequentemente fazem churn é pior do que nenhum score. Dá falsa confiança a CSMs (e à liderança de CS), levando ao sub-investimento em contas em risco durante a janela em que a intervenção teria funcionado.
A métrica a rastrear é precisão nas classificações vermelhas: quando o modelo diz vermelho, com que frequência isso está correto? Um modelo que sinaliza 100 contas como vermelhas e 80 delas realmente fazem churn (80% de precisão) é muito mais acionável do que um modelo que sinaliza 100 contas como vermelhas e 40 delas fazem churn.
Há um trade-off aqui. Alta precisão nas flags vermelhas significa que você só está emitindo o alarme quando está confiante, o que significa que algumas contas que realmente estão em risco não serão sinalizadas. Alta recall significa sinalizar mais contas em risco mas também gerar mais falsos alarmes que aumentam a carga de trabalho do CSM e corroem a confiança no score.
Para a maioria das equipes de CS com capacidade limitada, precisão é mais importante do que recall. Um número menor de flags genuinamente de alto risco que preveem churn de forma confiável é mais útil do que uma lista abrangente onde os CSMs não conseguem distinguir sinais reais de ruído.
Teste seu modelo regularmente em relação a resultados reais. Pegue uma coorte de contas que foram pontuadas como verde há seis meses. Quantas fizeram churn? Pegue uma coorte pontuada como vermelha. Quantas renovaram? Esses backtests dizem se o modelo está realmente prevendo resultados ou apenas medindo comportamento tardio.
Precisão do modelo é um pré-requisito. Mas fazer CSMs agirem com base no score é o problema mais difícil.
Confiança e Adoção do CSM
Um health score que os CSMs ignoram não fornece valor algum. Obter adoção requer resolver um problema de confiança, não um problema de tecnologia.
CSMs desconfiam de health scores por três razões específicas. Primeiro, o score diz uma coisa e o senso de relacionamento deles diz outra, e o score nunca é atualizado quando enviam uma correção. Segundo, o score muda sem explicação: uma conta vira de amarelo para vermelho da noite para o dia e não há código de razão. Terceiro, quando o score está errado, faz perder tempo perseguindo contas que não precisam de atenção.
Cada um desses problemas tem solução.
Torne os códigos de razão visíveis. Não apenas "vermelho porque uso caiu" mas "a frequência de login desta conta caiu 45% nos últimos 30 dias, e contas com esse perfil que mostram esse padrão fizeram churn dentro de 90 dias em uma taxa histórica de 72%." CSMs que conseguem ver a evidência por trás do score se engajarão com ele em vez de substituí-lo silenciosamente.
Construa um mecanismo de override. CSMs devem conseguir sinalizar um score como impreciso e adicionar um código de razão. Esses overrides tornam-se dados de treinamento. Se um CSM consistentemente marca contas de baixo uso como verde e elas consistentemente renovam, o modelo aprende que baixo uso nesse tipo de conta não é um sinal de churn.
Execute sessões de calibração trimestralmente. Reúna a equipe de CS, analise contas onde o modelo estava certo e onde estava errado, e discuta os padrões. Isso constrói entendimento compartilhado do que o modelo está fazendo e constrói confiança através da transparência.
Confiança gera adoção. Adoção só importa se o score impulsiona ação.
Health Score como Gatilho de Workflow
A mudança de mentalidade mais importante para health scoring é esta: o score não é uma métrica de Dashboard. É um input de workflow.
Uma transição de verde para amarelo deve acionar automaticamente uma tarefa de CSM: "A Conta X mudou para amarelo. Revisar dados de uso e agendar check-in dentro de 5 dias úteis." Uma transição de amarelo para vermelho deve acionar uma escalação: revisão do líder de CS, opção de outreach com patrocinador executivo, iniciação de save play.
Sem essa integração de workflow, o health score é um número em um Dashboard que alguém olha antes de uma reunião de board. Com ela, cada sinal de risco gera uma ação.
Construa o save play primeiro, depois ative os gatilhos de health score. O erro de implementação mais comum é ativar o health scoring antes que o workflow de resposta exista, o que significa que quando uma conta fica vermelha, ninguém sabe o que fazer. O sistema identificou corretamente o risco e depois nada aconteceu.
Conectando ao Stack de CS Mais Amplo
Health scoring é a base. IA de expansão (coberta no artigo complementar sobre upsell e cross-sell) é construída sobre ela. Você precisa saber que uma conta está saudável antes de empurrar uma conversa de expansão. Uma conta que está amarela-para-vermelha em saúde não deve receber outreach de expansão.
AI Customer Success Manager para SaaS cobre como o health scoring se integra com preparação de QBR, plays de expansão, e automação de workflow de renovação como um sistema de inteligência de CS conectado.
Como Fica o Resultado Bom
Uma implementação madura de health scoring com IA em uma empresa SaaS com 200 contas enterprise ficará mais ou menos assim: cada conta tem um health score atualizado diariamente. O score vem com três a cinco códigos de razão explicando os sinais primários que o conduziram. Os CSMs têm uma fila de transições sinalizadas que precisam de ação hoje, esta semana, e este mês. Cada interação de save play é registrada de volta no sistema como dados de treinamento.
Duas vezes por ano, a equipe de CS Ops executa um backtest, comparando scores de seis meses atrás com os resultados reais de churn e renovação. Quando a precisão cai abaixo do threshold acordado, o modelo é retreinado.
A melhora de NRR desse sistema é mensurável: não porque o score seja mágico, mas porque garante que nenhuma conta de alto risco passe despercebida durante a janela de 90 dias quando o outreach proativo ainda funciona.
Construa o score que os CSMs confiam. Conecte-o a workflows que eles realmente usam. Depois meça se está prevendo as contas certas. Todo o resto são detalhes de implementação.
Adicionar sinais de sentimento de suporte a um modelo de saúde, especificamente análise baseada em LLM de linguagem de ticket de suporte e transcrição de chamada, consistentemente produz os maiores saltos de precisão em implantações de 2025-2026. Contas onde clientes usam frases como "estamos avaliando opções" ou "não estamos vendo o ROI que esperávamos" têm 4-6x mais probabilidade de fazer churn em 90 dias. Modelos puramente de uso não conseguem detectar esse sinal. Apenas modelos com acesso a dados conversacionais conseguem. (Arete SaaS Research, 2025)
Rework Analysis: O erro de implementação mais consistente que observamos é construir o Dashboard de health scoring antes de construir o workflow de save play. Equipes ficam empolgadas com a visualização de saúde, ativam os alertas, e depois não têm resposta definida quando uma conta vira vermelha. CSMs veem o alerta, não têm certeza do que fazer, não fazem nada, e a conta faz churn. O sistema identificou corretamente o risco. Os humanos não estavam prontos para agir. A sequência que funciona: projete o workflow de save play primeiro (o que fazemos quando a saúde vira vermelha?), teste-o manualmente com cinco contas em risco, depois ative os alertas de IA de saúde para acionar esse workflow automaticamente. Pontue o sistema na taxa de execução de save play, não no volume de alertas.
| Categoria de Sinal | Peso | Exemplos | Lead Time de Previsão |
|---|---|---|---|
| Sinais de uso do produto | Mais alto (para PLG e ferramentas de uso diário) | Tendência de frequência de login, profundidade de adoção de funcionalidades, volume de chamadas de API, amplitude de colaboração | 3-8 semanas |
| Sinais de relacionamento | Mais alto para contas enterprise | Tendência de sentimento de chamada, taxas de resposta do CSM, conclusão de QBR, estabilidade do champion | 4-8 semanas |
| Sinais comerciais | Alta precisão mas tardios | Timing de pagamento de fatura, uso vs. limites contratuais, iniciação de conversa de tier de precificação | 1-3 semanas |
| Sentimento de suporte | Misto (antecipado para frustração, tardio para cancelamento) | Tendência de volume de tickets, declínio de CSAT, taxa de escalação, análise de linguagem de ticket | 2-6 semanas |
Fonte: Gainsight, ChurnZero, Planhat, Arete SaaS Research (2024-2025)
Named Frameworks neste artigo: Multi-Signal Health Model, Anomaly Agent
Related:

Co-Founder, Rework.com
On this page
- Scoring Baseado em Regras vs. Health Scoring com IA
- O Padrão Anomaly Agent por Baixo
- O Framework "Multi-Signal Health Model"
- Categorias de Sinal e o Que Realmente Preveem
- Construindo o Conjunto de Treinamento
- O Problema da Falsa Confiança
- Confiança e Adoção do CSM
- Health Score como Gatilho de Workflow
- Conectando ao Stack de CS Mais Amplo
- Como Fica o Resultado Bom