Higiene de Dados do CRM com um AI Copilot

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Lixo entra, lixo sai.
Você já ouviu isso tantas vezes que parece um clichê. Mas em operações de vendas assistidas por AI, é a equação fundamental. Seu modelo de lead scoring é treinado com dados do CRM. Suas atribuições de tier de conta usam dados firmográficos do CRM. Sua previsão de pipeline é calculada a partir dos dados de etapa de deal. O roteamento de sinais de intent é disparado com base em registros de conta no CRM.
Toda função de AI no seu stack de vendas está downstream da qualidade dos dados do CRM. Quando esses dados são confusos, seus outputs de AI estão confiantemente errados. E confiantemente errado é pior do que admitidamente incerto, porque os representantes agem com base nisso. A Gartner estima que a má qualidade de dados custa às organizações uma média de US$ 15 milhões por ano, sendo os problemas de qualidade de dados no CRM uma das fontes de maior impacto desse custo para times comerciais.
Higiene de CRM não é um trabalho glamouroso. Líderes de RevOps sabem disso. A maioria já lançou um projeto de limpeza de dados, executou por um trimestre, declarou vitória e viu a qualidade dos dados degradar novamente em 6 meses. O modelo de limpeza trimestral não funciona porque os dados não se deterioram trimestralmente. Eles degradam continuamente, a um ritmo determinado pelo seu volume de deals, pela disciplina dos seus representantes e pelo ritmo de mudanças nas suas contas.
O padrão Workflow Copilot aplicado à higiene de CRM é um modelo diferente: detecção e correção automatizada e contínua, com uma camada de governança que mantém humanos na cadeia de decisão para qualquer coisa acima de um limiar de confiança. Este artigo cobre como ele funciona, os quatro tipos de problema que ele trata e por que é o investimento em infraestrutura que torna tudo mais no seu stack de AI mais confiável.
O que higiene de dados do CRM significa operacionalmente
Key Facts: O Custo de Dados Ruins no CRM
- A má qualidade de dados no CRM custa à empresa B2B média entre US$ 12,9 e US$ 15 milhões por ano através de gastos de marketing desperdiçados, oportunidades de vendas perdidas e ineficiências operacionais. (Gartner / ZoomInfo, 2025)
- Representantes de vendas desperdiçam 27% do tempo lidando com dados ruins, custando aproximadamente US$ 32.000 por representante ao ano em produtividade perdida. (Validity, 2025)
- Dados de contato B2B decaem a aproximadamente 2,1% ao mês, o que significa que 22-30% dos registros de contato do CRM se tornam imprecisos em um ano sem higiene ativa. (Salesgenie, 2025)
"Higiene de dados" é um termo abrangente. Para fins de RevOps, ele cobre quatro tipos distintos de problema:
Duplicatas. A mesma empresa existe em dois registros ("Acme Corp" e "Acme Corporation Inc"). O mesmo contato está no sistema três vezes após três eventos de importação diferentes. Duplicatas dividem o histórico de atividade, fragmentam o contexto de relacionamento e produzem contagens infladas de contatos que atrapalham suas atribuições de território.
Completude de campos. Campos obrigatórios estão vazios. Sem segmento de atuação. Sem contagem de funcionários. Sem data ou rodada de último aporte. Sem contato principal na conta. Essas lacunas quebram os modelos de scoring que usam esses campos como inputs e produzem células em branco em relatórios que deveriam ser superfícies de decisão.
Registros desatualizados. Nenhuma atividade registrada em 180 dias, mas o deal ainda está em aberto no pipeline. A empresa da conta foi adquirida há 8 meses, mas o registro de conta não foi atualizado. O champion principal saiu da empresa mas ainda está listado como contato principal. Registros desatualizados geram confiança falsa no pipeline e produzem oportunidades perdidas de outreach para prospects ativos.
Drift de enriquecimento. Os dados eram precisos quando foram inseridos e, desde então, ficaram errados por mudanças externas. Empresas se mudam. Contatos mudam de emprego. Números de telefone ficam inativos. Rodadas de investimento acontecem. Número de funcionários muda. O CRM não sabe; ele apenas armazena o que foi inserido. Com o tempo, a lacuna entre os registros do CRM e a realidade se expande.
Todos os quatro tipos de problema degradam a qualidade dos outputs de AI de formas específicas. Duplicatas confundem os modelos de scoring com dados de sinal divididos. Campos ausentes reduzem a precisão do modelo e produzem registros sem score. Registros desatualizados inflam os números de pipeline e distorcem as previsões. Drift de enriquecimento produz outreach para contatos errados e critérios de qualificação incorretos.
Como o Workflow Copilot trata a higiene
O padrão Workflow Copilot no ACE Framework descreve um loop de assistência contínua: Ingest do contexto atual, Analyze para identificar o que precisa de atenção, Generate de uma sugestão, Execute com aprovação humana (ou ação automatizada para casos de alta confiança), e repetir.
Aplicado à higiene do CRM:
Ingest lê o estado atual do CRM. Todos os registros, todos os logs de atividade, todos os valores de campos. Isso acontece de forma contínua (novos registros disparam verificações imediatas) e em lote agendado (varredura completa do banco de dados semanal).
Analyze identifica problemas de dados nos quatro tipos de problema:
- Detecção de duplicatas: correspondência por nome da empresa, domínio, número de telefone e similaridade de endereço
- Verificação de completude: pontuando cada registro em relação às definições de campos obrigatórios
- Avaliação de atualidade: sinalizando registros sem atividade registrada além de limites configuráveis
- Detecção de drift de enriquecimento: comparando dados do CRM com fontes de dados externas (bancos de dados de empresas, LinkedIn, pesquisa de domínio)
Generate produz uma correção sugerida para cada problema identificado:
- Para duplicatas: uma recomendação de merge especificando qual registro manter como principal e quais campos usar de cada registro
- Para campos ausentes: valores preenchidos automaticamente por fontes de enriquecimento, com scores de confiança
- Para registros desatualizados: mudança de status sugerida (marcar como inativo, requalificar, arquivar) com contexto
- Para drift: valores de campo atualizados pelo enriquecimento, claramente referenciados
Execute encaminha a correção sugerida por um de dois caminhos, dependendo da confiança:
- Alta confiança (acima do limiar): executa a correção automaticamente e registra a ação
- Abaixo do limiar: enfileira para revisão do representante ou do RevOps com a correção sugerida apresentada
A camada de governança é o que separa isso do caos. A execução automatizada de tudo produz um tipo diferente de problema de qualidade de dados: correções aplicadas em escala sem revisão podem propagar erros tão eficientemente quanto os corrigem. Para os princípios de governança mais amplos que se aplicam a todos os sistemas de AI, governança de AI sales ops e trilhas de auditoria cobre o framework em detalhes.
Dados de contato B2B decaem 2,1% ao mês, e 30% de todos os registros do CRM ficam obsoletos anualmente. Uma campanha de limpeza trimestral significa que a organização média opera com 5-7% de dados degradados durante a maior parte do ano.
The Confidence-Threshold Auto-Fix Rule
O Confidence-Threshold Auto-Fix Rule é o princípio de governança que determina quais correções de higiene do CRM são executadas automaticamente e quais exigem revisão humana. Ele tem três níveis: acima de 90% de confiança em uma fonte de enriquecimento conhecida dispara a correção automática com uma entrada no log de auditoria; entre 50-90% de confiança gera uma sugestão enfileirada para aprovação do RevOps ou representante; abaixo de 50% de confiança produz apenas um sinal, sem correção sugerida. A regra previne dois modos de falha: subautomação (um backlog que ninguém processa) e superautomação (erros confiantes propagados em escala). Os percentuais de limiar devem ser calibrados trimestralmente com base em revisões de auditoria amostradas das autocorreções.
Limiares de autocorreção vs. revisão do representante
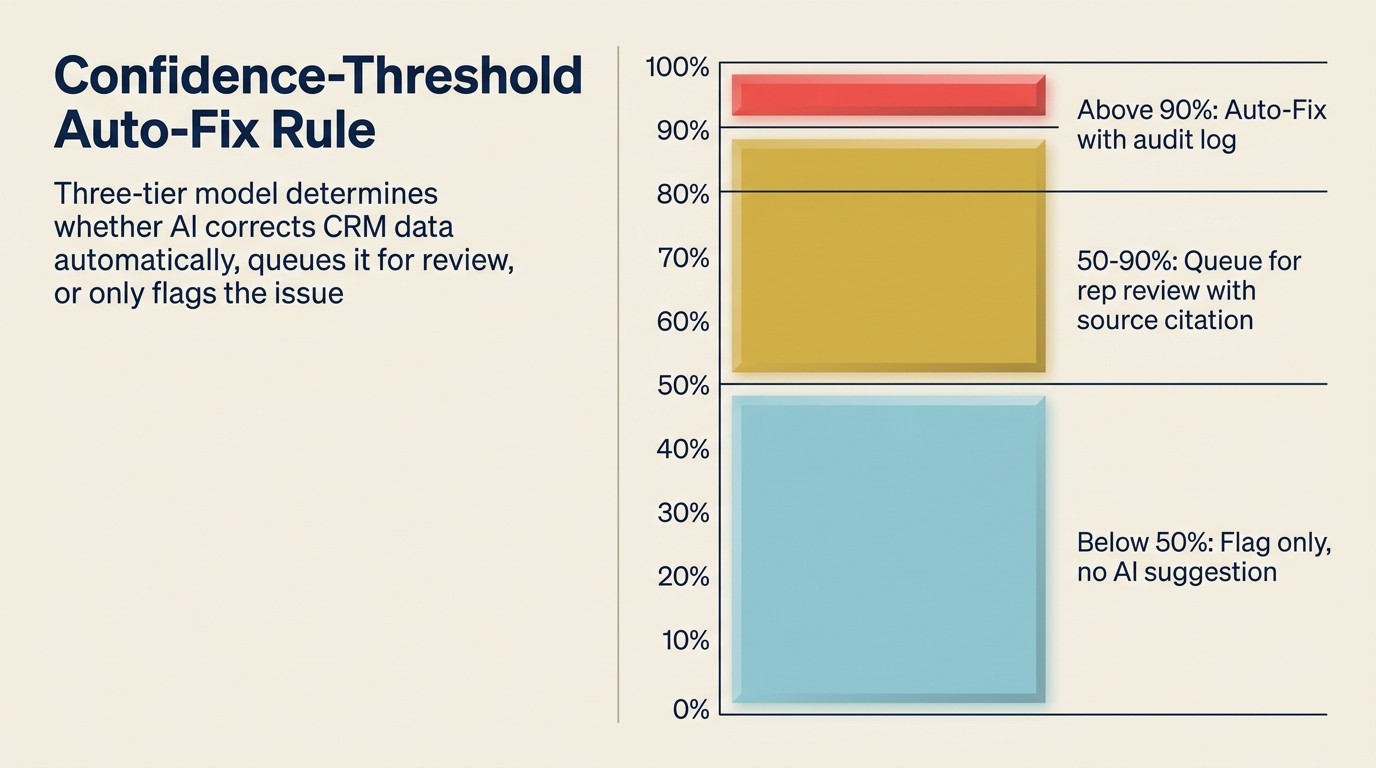
O modelo de governança é a decisão de design mais importante em um sistema de higiene de CRM por AI.
O que é autocorrigido:
- Registros duplicados com correspondência exata (mesmo endereço de e-mail, mesmo domínio, confirmada como mesma empresa) sem dados de campo conflitantes: merge automático, registrar o merge
- Campos ausentes onde a confiança da fonte de enriquecimento é alta (acima de 90%): preenchimento automático
- Registros sem atividade e sem histórico de deal com mais de 365 dias: arquivamento automático com janela de recuperação de 30 dias
O que vai para a fila de revisão:
- Duplicatas com correspondência aproximada (mesmo nome de empresa, domínios diferentes): apresentar sugestão de merge, exigir confirmação humana
- Campos ausentes onde a confiança no enriquecimento é moderada (50% a 90%): sugerir o preenchimento com citação da fonte, exigir confirmação
- Deals ativos desatualizados (sem atividade em 90 dias, status do deal ainda aberto): alertar o responsável pelo deal, não fechar automaticamente
- Drift de enriquecimento em campos-chave como nome da empresa ou contato principal: sinalizar para revisão do representante, não sobrescrever silenciosamente
O que é apenas sinalizado:
- Potencial drift de enriquecimento com baixa confiança: exibir como "isso pode estar desatualizado" sem sugerir uma correção específica
- Registros que parecem ter dados incompatíveis entre campos sem uma correção clara
A calibração do limiar exige ajuste com base no seu ambiente de dados. Comece conservador (mais revisão, menos automação) e migre para automação conforme você constrói confiança na precisão do modelo para seus padrões específicos de dados.
Uma forma útil de pensar sobre isso: se a AI cometer um erro neste nível de confiança, qual é a consequência? Para duplicatas com correspondência exata, o custo de um merge incorreto é recuperável. Para sobrescrever as informações de um contato-chave com dados de enriquecimento errados, a consequência é um representante ligando para a pessoa errada sobre um deal ativo. Perfis de risco diferentes exigem limiares diferentes.
Os quatro tipos de problema de higiene em profundidade

Duplicatas
Registros duplicados são o problema de dados do CRM mais comum e o mais computacionalmente interessante de detectar. Correspondências exatas por e-mail ou domínio são fáceis. Os casos difíceis são:
- "Acme Corp" e "Acme Corporation" (mesma empresa, strings de nome diferentes)
- Dois registros de contato para "João Silva" com o mesmo número de telefone, mas empresas diferentes listadas (mudança de emprego, não uma pessoa diferente)
- Uma empresa que foi adquirida e agora existe tanto como uma conta por conta própria quanto como subsidiária sob a adquirente
A deduplicação por AI usa múltiplos sinais de correspondência: similaridade de string no nome da empresa, correspondência de domínio, correspondência de endereço, correspondência de telefone e análise de grafo de rede (contatos vinculados à mesma empresa por caminhos diferentes). Combinar sinais produz um score de confiança para cada merge potencial.
A decisão operacional-chave: os merges devem ser automáticos, ou cada merge deve exigir revisão humana? Para organizações de alto volume com 50.000+ registros, exigir revisão humana em cada merge cria um backlog que ninguém vai processar. Defina seu limiar de automação e audite uma amostra de auto-merges mensalmente para verificar a precisão.
Completude de campos
As definições de campos obrigatórios variam por organização. Mas um padrão mínimo para operações de vendas assistidas por AI inclui: segmento de atuação da empresa, faixa de número de funcionários, data e rodada do último aporte, contato principal com e-mail verificado e status de lead qualificado para vendas.
A AI preenche campos ausentes a partir de fontes de enriquecimento: Clearbit, ZoomInfo, LinkedIn, Crunchbase e dados do site da empresa. A qualidade varia por tipo de campo. Número de funcionários e investimento são geralmente confiáveis. A classificação de setor pode variar (alguns provedores de enriquecimento usam sistemas de taxonomia diferentes). Dados de contato individual degradam rapidamente à medida que as pessoas mudam de emprego.
Rastreie as taxas de completude como uma métrica permanente de RevOps. Meta de 90%+ de completude em campos obrigatórios para contas ativas. A pesquisa do MIT Sloan sobre qualidade de dados constata que organizações que tratam a qualidade de dados como um processo contínuo, em vez de um projeto periódico, obtêm resultados três a quatro vezes melhores em suas iniciativas orientadas por dados. Quando a completude cair abaixo do limiar, investigue se o problema está no workflow de entrada de dados (representantes pulando campos) ou na cobertura do enriquecimento (seu provedor não tem dados para pequenas empresas no seu segmento-alvo).
Registros desatualizados
Registros desatualizados no pipeline são o problema de higiene mais perigoso porque produzem falsa confiança em receita. Um relatório de pipeline mostrando R$ 2,4M em deals em aberto é enganoso se R$ 800K disso está em deals que não tiveram nenhuma atividade em 6 meses.
A detecção de registros desatualizados por AI usa dados de timestamp de atividade: último e-mail, última ligação, última reunião, última nota no CRM. Registros que ultrapassam limiares configuráveis (90 dias para deals em etapa inicial, 180 dias para etapa final) são sinalizados.
A ação apropriada depende do tipo de registro. Para deals em aberto: alertar o responsável pelo deal para registrar atividade ou marcar o deal como inativo. Não feche automaticamente deals ativos. Para contatos sem atividade: verifique se ainda estão empregados na empresa antes de decidir o que fazer. Para contas sem atividade: diferencie entre contas que não estão em nenhuma sequência ativa (aceitável) e contas que deveriam estar em uma sequência de nutrição mas não estão.
Drift de enriquecimento
Este é o problema mais silencioso e um dos mais prejudiciais. Os dados estavam corretos quando foram inseridos. A realidade externa mudou. O CRM não foi atualizado.
Mudanças de emprego de contatos são as mais comuns: o champion que você estava cultivando saiu da empresa há 3 meses e seu representante ainda está enviando e-mails para o endereço antigo. Aquisições de empresas: a conta que você está perseguindo foi comprada e agora é uma subsidiária com um processo de procurement diferente. Eventos de aporte: a empresa acabou de captar uma Série B, o que muda seu poder de compra e provavelmente o cronograma para decisões de tecnologia.
A detecção de drift por AI compara registros do CRM com sinais externos: mudanças no LinkedIn (cargo ou empresa do contato muda), eventos de notícias (anúncios de aquisição, rodadas de investimento), mudanças no site da empresa. Quando uma incompatibilidade é detectada, ela aparece como um sinal em vez de uma correção automática, porque o contexto importa. "O LinkedIn deste contato agora mostra uma empresa diferente" é um sinal, não uma correção definitiva.
Higiene contínua vs. limpeza trimestral
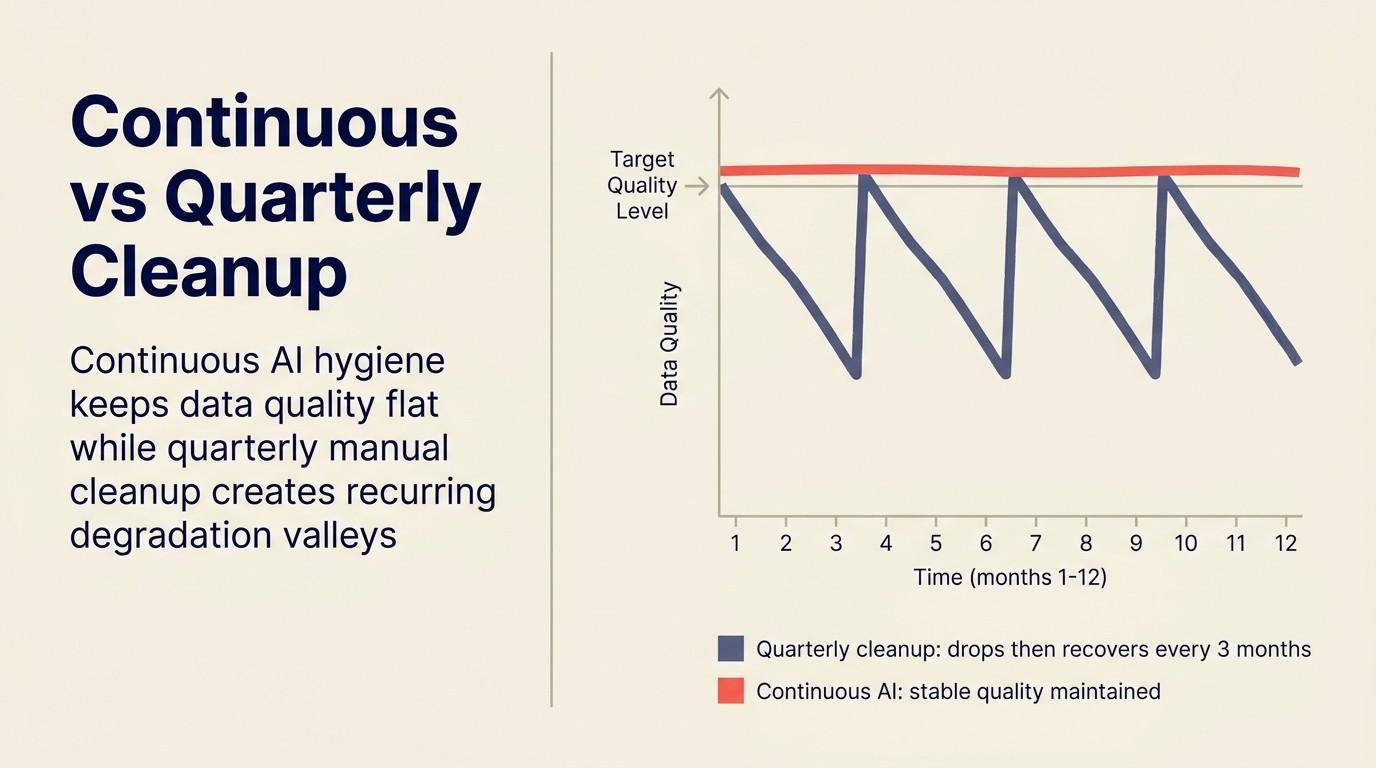
A maioria das organizações aborda a higiene do CRM como um projeto: campanhas de limpeza trimestrais, geralmente disparadas por uma revisão de previsão onde os números parecem errados ou uma auditoria onde a qualidade dos dados parece degradada.
O problema com campanhas trimestrais é a curva de degradação dos dados. Para uma organização com fluxo ativo de deals, aqui está uma estimativa aproximada de quão rapidamente cada tipo de problema se acumula:
- Novas duplicatas: 5 a 15 por semana de eventos de importação, entrada manual e integrações de sistema
- Lacunas de completude de campos: em cada novo registro criado sem um processo de intake completo
- Registros desatualizados: em cada deal que para, em cada contato que esfria
- Drift de enriquecimento: 2 a 3% dos registros de contato ativos ficam imprecisos por mês apenas por mudanças de emprego
Quando uma campanha de limpeza trimestral é executada, meses de degradação já se acumularam. A limpeza é um projeto maior cada vez. E ela não previne a degradação; apenas restaura a linha de base antes do próximo ciclo de deterioração.
A higiene contínua por AI muda a equação. Em vez de corrigir em lote meses de problemas acumulados, a AI opera continuamente e detecta problemas próximo ao momento em que ocorrem. A carga de manutenção por problema é menor. O piso de qualidade de dados é mais alto. E as funções de AI downstream assistidas, scoring, roteamento, previsão, operam com dados mais limpos ao longo de todo o trimestre, não apenas nas duas semanas após um projeto de limpeza.
Dependência upstream: por que dados limpos não são apenas uma questão de higiene
Toda função de AI no seu stack de vendas está downstream da qualidade de dados do CRM. Essa cadeia de dependência torna a higiene de dados um investimento estratégico, não apenas operacional.
AI Lead Scoring Beyond Rules-Based Models depende da completude de campos do CRM para os inputs de scoring. Dados ausentes de segmento ou número de funcionários produzem registros sem score ou com score impreciso.
From Call to CRM Update Automatically produz dados mais limpos como outputs, mas depende de registros de conta e contato corretamente estruturados para saber onde escrever as atualizações.
Next Best Action for Each Open Deal usa dados de etapa de deal, datas de última atividade e completude de contato para gerar recomendações. Dados de deal desatualizados e informações de contato ausentes degradam diretamente a qualidade das recomendações.
O efeito composto: problemas de higiene no CRM não produzem erros isolados. Eles se propagam. Um registro de conta duplicada significa que os sinais de scoring são divididos entre dois registros, reduzindo o intent aparente de ambos. Um deal desatualizado infla a previsão de pipeline, o que leva a planejamento de recursos excessivamente otimista. Um contato desatualizado significa que o outreach vai para a pessoa errada, que não gera resposta, que o modelo de scoring de AI interpreta como baixo engajamento, que reduz o score de prioridade da conta.
Dados limpos melhoram todos os outputs de AI downstream. Não se trata de ter registros organizados. Trata-se da qualidade de cada decisão gerada por AI que sua organização toma a partir desses registros.
Ferramentas de implementação
Rework CRM inclui higiene de dados assistida por AI como parte de sua camada de operações de vendas. Detecção de duplicatas, preenchimento de campos a partir de fontes de enriquecimento e sinalização de obsolescência estão integrados ao workflow de gerenciamento de conta e contato. O modelo de governança (autocorreção vs. fila de revisão) é configurável por tipo de campo e limiar de confiança.
Salesforce duplicate management oferece regras nativas de duplicata e regras de correspondência, com detecção e merge automatizados. Ferramentas de terceiros (Cloudingo, DemandTools) ampliam isso com lógica de correspondência mais sofisticada e operações em lote. O enriquecimento por AI é tipicamente adicionado via integração com Clearbit ou ZoomInfo.
HubSpot data quality tools inclui gerenciamento de duplicatas para contatos e empresas, com uma fila de revisão dedicada. Relatórios de integridade de dados a nível de campo mostram taxas de completude em todo o banco de dados. O enriquecimento nativo do HubSpot (via seu recurso de enriquecimento de dados) preenche campos básicos de empresa automaticamente para registros identificados.
Clay é uma opção mais composável para times que querem construir workflows de enriquecimento personalizados. Conecte múltiplas fontes de dados (Clearbit, Apollo, LinkedIn, dados de domínio), defina cascatas de enriquecimento (tente a fonte A, use a fonte B como fallback) e envie dados limpos de volta ao seu CRM. Exige mais configuração do que ferramentas nativas de CRM, mas oferece mais flexibilidade para casos de uso não padrão.
A capacidade Analyze cobre a lógica de detecção e classificação que sustenta a análise de higiene. O artigo sobre pré-requisito de prontidão de dados explica por que dados limpos no CRM são o requisito habilitador para todo sistema de AI no seu stack. As 12 ações da Gartner para melhorar a qualidade de dados é um recurso complementar prático para líderes de RevOps que constroem um programa formal de qualidade de dados junto com suas ferramentas de higiene por AI.
O argumento de infraestrutura
A higiene de CRM é a linha de orçamento menos glamourosa em um orçamento de RevOps. Ela não gera receita diretamente, não adiciona uma nova capacidade e não produz uma métrica que aparece em um relatório de conselho.
Mas é a infraestrutura que torna tudo o mais preciso. Precisão do lead scoring, precisão do roteamento, confiabilidade da previsão de pipeline, qualidade das próximas ações dos representantes: tudo isso é contingente à qualidade dos dados.
O modelo de higiene contínua assistida por AI muda a equação de recursos. Em vez de um grande projeto de limpeza por trimestre que consome 40 a 80 horas de tempo do RevOps, você tem um sistema sempre ativo que detecta e corrige problemas na origem. O tempo humano total necessário é menor. A qualidade dos dados é consistentemente mais alta.
E quando você adiciona uma nova capacidade de AI ao seu stack de vendas, você não está começando com um problema de dados. Você está construindo sobre dados limpos. Esse é o retorno composto do investimento em infraestrutura.
Higiene de dados não é um produto que você compra uma vez. É um processo que você executa continuamente. A AI torna possível executar esse processo sem crescimento proporcional de headcount. Esse é o argumento a favor disso. E é a razão pela qual todas as outras ferramentas de AI no seu stack funcionam melhor quando você acerta nessa.
Rework Analysis: Nos deployments de RevOps, a decisão de calibração inicial mais importante é o limiar de autocorreção para merges de duplicatas. Defini-lo muito baixo (auto-merge de correspondências aproximadas abaixo de 85% de confiança) cria um tipo diferente de problema de qualidade de dados: empresas legítimas com nomes semelhantes incorretamente fundidas, produzindo contaminação de histórico de atividade que é mais difícil de desfazer do que as duplicatas originais. Comece com 95% de confiança para auto-merge, verifique 50 auto-merges aleatórios no primeiro mês e ajuste o limiar com base na taxa de erros. A maioria dos times consegue migrar para 90% após o primeiro ciclo de calibração.
Organizações com programas contínuos de higiene de dados por AI mantêm 90%+ de completude de campos obrigatórios no CRM. Organizações que dependem de limpeza manual trimestral têm em média 65-75% de completude, com a precisão mais baixa nas seis semanas antes de cada ciclo de limpeza. (MIT Sloan data quality research)
Perguntas Frequentes
Qual é o custo real da má qualidade de dados no CRM?
A má qualidade de dados custa à empresa B2B média entre US$ 12,9 e US$ 15 milhões por ano através de gastos de marketing desperdiçados, oportunidades de vendas perdidas e ineficiências operacionais, segundo estimativas da Gartner. No nível individual do representante, eles desperdiçam 27% do tempo lidando com dados ruins, custando aproximadamente US$ 32.000 por representante ao ano. O custo organizacional se compõe porque toda função de AI downstream do CRM (lead scoring, previsão de pipeline, next best action) está produzindo outputs confiantemente errados a partir de inputs sujos.
Com que rapidez os dados do CRM decaem?
Dados de contato B2B decaem aproximadamente 2,1% ao mês, o que significa que 22-30% de todos os registros de contato ficam imprecisos em um ano sem higiene ativa. Mudanças de emprego são o principal fator: contatos mudam de empregadores, cargos e endereços de e-mail continuamente. Dados a nível de empresa (firmográficos, estágio de investimento, stack tecnológico) mudam mais lentamente, mas têm impacto igualmente significativo quando mudam, pois afetam os inputs do modelo de scoring e os critérios de qualificação.
O que é o Confidence-Threshold Auto-Fix Rule?
O Confidence-Threshold Auto-Fix Rule é um modelo de governança de três níveis para correções de CRM por AI: acima de 90% de confiança em uma fonte de enriquecimento conhecida dispara autocorreção com um log de auditoria; entre 50-90% de confiança enfileira uma sugestão para revisão humana; abaixo de 50% produz apenas um sinal. A regra previne subautomação (backlog que ninguém processa) e superautomação (erros confiantes em escala). Os limiares devem ser calibrados trimestralmente por meio de amostras de auditoria de autocorreções. A maioria dos times começa com 95% para o nível de autocorreção e migra para 90% após o primeiro ciclo de calibração.
Quais quatro tipos de problemas de dados do CRM a higiene por AI trata?
A higiene de CRM por AI trata duplicatas (mesma empresa ou contato em múltiplos registros), lacunas de completude de campos (campos obrigatórios vazios), registros desatualizados (deals abertos ou contatos sem atividade por 90-180+ dias) e drift de enriquecimento (dados que eram precisos quando inseridos mas ficaram incorretos por mudanças externas). Cada tipo de problema degrada diferentes funções de AI downstream: duplicatas dividem sinais de scoring, campos ausentes reduzem a precisão do modelo, registros desatualizados inflam previsões de pipeline e drift produz outreach para contatos errados.
Por que a limpeza trimestral do CRM é insuficiente?
A limpeza trimestral trata a qualidade de dados como um projeto, não como um processo. Para uma organização com fluxo ativo de deals, novas duplicatas se acumulam a 5-15 por semana, lacunas de completude aparecem em cada novo registro, deals desatualizados se acumulam constantemente e 2,1% dos contatos sofrem drift por mês. Quando uma campanha trimestral é executada, meses de degradação já se acumularam. A higiene contínua por AI detecta problemas próximo ao momento em que ocorrem, reduzindo tanto o backlog quanto as consequências de erros que persistem por 90 dias antes da correção.
Como a qualidade dos dados do CRM afeta o lead scoring por AI?
Os modelos de lead scoring por AI treinam e operam sobre dados do CRM. Campos ausentes (sem segmento de atuação, sem número de funcionários) produzem registros sem score ou com score impreciso. Registros duplicados dividem sinais de intent entre duas contas, fazendo cada uma parecer menos engajada do que realmente é. Dados de deal desatualizados distorcem os conjuntos de treinamento ao incluir deals inativos como se fossem prospects ativos. Organizações com taxas de completude de CRM de 90%+ apresentam precisão de lead scoring significativamente maior do que organizações com 65-75% de completude, porque o modelo tem dados de sinal mais completos para trabalhar.
O que ler a seguir
- Workflow Copilot: AI as Peer-Level Assistant: o padrão ACE por trás da assistência contínua de AI em workflows de vendas
- AI Lead Scoring Beyond Rules-Based Models: como a qualidade dos dados do CRM afeta diretamente a precisão do modelo de scoring
- Next Best Action for Each Open Deal: a função de AI downstream mais dependente de dados limpos de deal
- AI Sales Ops Governance and Audit Trails: frameworks de governança para operações automatizadas de dados

Co-Founder, Rework.com
On this page
- O que higiene de dados do CRM significa operacionalmente
- Como o Workflow Copilot trata a higiene
- The Confidence-Threshold Auto-Fix Rule
- Limiares de autocorreção vs. revisão do representante
- Os quatro tipos de problema de higiene em profundidade
- Duplicatas
- Completude de campos
- Registros desatualizados
- Drift de enriquecimento
- Higiene contínua vs. limpeza trimestral
- Dependência upstream: por que dados limpos não são apenas uma questão de higiene
- Ferramentas de implementação
- O argumento de infraestrutura
- O que ler a seguir