AIコパイロットによるCRMデータ品質管理

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
ゴミを入れればゴミが出る。
何度も聞いた言葉で陳腐に感じるかもしれません。しかしAI支援の営業オペレーションでは、これが根本的な方程式です。リードスコアリングモデルはCRMデータで学習されています。アカウントのティア割り当てはCRMのファーモグラフィックスから取得します。パイプライン予測はディールステージデータから算出されます。インテントシグナルのルーティングはCRM内のアカウントレコードに基づいて実行されます。
営業スタックにおけるすべてのAI機能は、CRMデータ品質の下流にあります。そのデータが汚れていると、AIのアウトプットは自信を持って間違った結果を出します。自信を持って間違った結果は、不確かだと認識されているものより悪いです。担当者がそれを基に行動するからです。Gartnerはデータ品質の低さが組織に年間平均1500万ドルのコストをもたらすと推定しており、CRMデータ品質の問題は商業チームにとって最も影響が大きいコスト源の一つです。
CRMのハイジーンは華やかな作業ではありません。RevOpsリーダーはこれを知っています。ほとんどの人はデータクリーンアッププロジェクトを立ち上げ、四半期間実行し、勝利宣言し、そして6ヶ月以内にデータ品質が再び低下するのを見てきました。四半期ごとのクリーンアップモデルは機能しません。データは四半期ごとに悪くなるのではないからです。ディールの量、担当者の規律、アカウントの変化のペースによって継続的に低下します。
CRMハイジーンに適用されたWorkflow Copilotパターンは別のモデルです。継続的で自動化された検出と修正、そして信頼度のしきい値を超えるものについては人間を意思決定のチェーンに保つガバナンスレイヤーを伴います。この記事では仕組み、対処する4つの問題タイプ、そしてなぜこれがAIスタックの他のすべてをより信頼性の高いものにするインフラ投資であるかを解説します。
CRMデータハイジーンが運用上意味すること
Key Facts: CRMデータ品質の悪さのコスト
- CRMデータ品質の低さは、マーケティング費の無駄、営業機会の損失、運用の非効率性を通じて、平均的なB2B企業に年間1290万〜1500万ドルのコストをもたらします。(Gartner / ZoomInfo、2025年)
- 営業担当者はデータ品質の悪さへの対処に時間の27%を無駄にし、生産性損失として1担当者あたり年間推定3万2000ドルかかっています。(Validity、2025年)
- B2Bの連絡先データは月に約2.1%の速度で古くなり、積極的なハイジーンなしに1年以内にCRMの連絡先レコードの22〜30%が不正確になります。(Salesgenie、2025年)
「データハイジーン」はあらゆることを指す包括的な用語です。RevOpsの目的では、4つの異なる問題タイプをカバーします:
重複。 同じ会社が2つのレコードとして存在します(「Acme Corp」と「Acme Corporation Inc」)。同じ連絡先が3つの異なるインポートイベントからシステムに3回入っています。重複はアクティビティの履歴を分割し、関係性のコンテキストを断片化し、テリトリー割り当てを混乱させる水増しされた連絡先数を生み出します。
フィールドの完全性。 必須フィールドが空です。業種が未入力。従業員数なし。最後の資金調達ラウンドなし。アカウントの主要連絡先なし。これらのギャップはそれらのフィールドを入力として使うスコアリングモデルを壊し、意思決定の表面であるべきレポートに空白のセルを生み出します。
陳腐化レコード。 アクティビティが180日間記録されていないが、ディールはパイプラインでまだオープンのまま。連絡先の会社が8ヶ月前に買収されたがアカウントレコードは更新されていない。主要Championが会社を去ったが、まだメインの連絡先としてリストに残っている。陳腐化レコードはパイプラインへの虚偽の信頼を生み出し、ライブのオポチュニティへのアウトリーチの見逃しを生み出します。
エンリッチメントドリフト。 データは入力時には正確で、その後外部の変化によって誤りになりました。会社が移転します。連絡先が転職します。電話番号が使われなくなります。資金調達ラウンドが起きます。従業員数が変わります。CRMは知らない。入力されたものを保存するだけです。時間が経つにつれ、CRMレコードと実態のギャップが広がります。
4つすべての問題タイプがAIのアウトプット品質を特定の方法で低下させます。重複は分割されたシグナルデータでスコアリングモデルを混乱させます。フィールドの欠如はモデルの精度を下げ、スコアリングされないレコードを生み出します。陳腐化レコードはパイプライン数値を水増しし、予測を歪めます。エンリッチメントドリフトは間違った連絡先へのアウトリーチと間違った資格審査基準を生み出します。
Workflow CopilotがどのようにハイジーンをHandleするか
ACEフレームワークのWorkflow Copilotパターンは継続的な支援ループを説明しています。現在のコンテキストをIngest し、注意が必要なものをAnalyze し、提案をGenerate し、人間の承認を伴って(または高信頼度のケースには自動アクションで)Execute し、そして繰り返す。
CRMハイジーンに適用すると:
Ingest は現在のCRMの状態を読み込みます。すべてのレコード、すべてのアクティビティログ、すべてのフィールド値。これは継続的なベース(新しいレコードが即時チェックをトリガー)と定期的なバッチベース(週次のフルデータベーススキャン)で行われます。
Analyze は4つの問題タイプにわたってデータ問題を識別します:
- 重複検出:会社名、ドメイン、電話番号、住所の類似性でのマッチング
- 完全性チェック:必須フィールド定義に対して各レコードをスコアリング
- 鮮度評価:設定可能なしきい値を超えてアクティビティが記録されていないレコードにフラグを立てる
- エンリッチメントドリフト検出:CRMデータを外部データソース(会社データベース、LinkedIn、ドメインルックアップ)と比較
Generate は識別された各問題の修正提案を生成します:
- 重複に対して:どのレコードをプライマリとして保持するか、各レコードからどのフィールドを取得するかを指定したマージ推奨
- 欠如フィールドに対して:信頼スコアを添えたエンリッチメントソースからの自動補完値
- 陳腐化レコードに対して:コンテキストを伴った提案ステータス変更(非アクティブにする、再資格審査、アーカイブ)
- ドリフトに対して:ソースが明記されたエンリッチメントからの更新フィールド値
Execute は信頼度に応じて、2つのパスのいずれかに提案された修正をルーティングします:
- 高信頼度(しきい値以上):修正を自動実行してアクションをログに記録
- しきい値以下:提案された修正が提示された状態で担当者またはRevOpsのレビューキューに入れる
ガバナンスレイヤーはこれを混乱から分けるものです。すべてのものへの自動実行は別のデータ品質問題を生み出します。レビューなしにスケールで適用された修正は、それらが修正するのと同じくらい効率的にエラーを伝播させます。すべてのAIシステムに適用される幅広いガバナンス原則については、AIセールスオペレーションのガバナンスと監査証跡がフレームワークを詳しく解説しています。
B2Bの連絡先データは月に2.1%の速度で古くなり、すべてのCRMレコードの30%が年間に時代遅れになります。四半期ごとのクリーンアップキャンペーンは、一年のほとんどの間、平均的な組織が5〜7%劣化したデータで運営していることを意味します。
信頼度しきい値自動修正ルール
信頼度しきい値自動修正ルールは、どのCRMハイジーン修正を自動実行するか、どれが人間のレビューを必要とするかを決定するガバナンス原則です。3段階あります:既知のエンリッチメントソースで90%以上の信頼度では監査ログエントリーと共に自動修正をトリガー、50〜90%の信頼度ではRevOpsまたは担当者の承認キューに入れる提案を生成、50%以下の信頼度ではフラグのみで修正提案なし。このルールは2つの障害モードを防ぎます:自動化が不十分(誰も処理しないバックログ)と過剰自動化(スケールで伝播する自信ある間違い)。しきい値のパーセンテージは、自動修正のサンプル監査レビューに基づいて四半期ごとにキャリブレーションすべきです。
自動修正 vs. 担当者レビューのしきい値
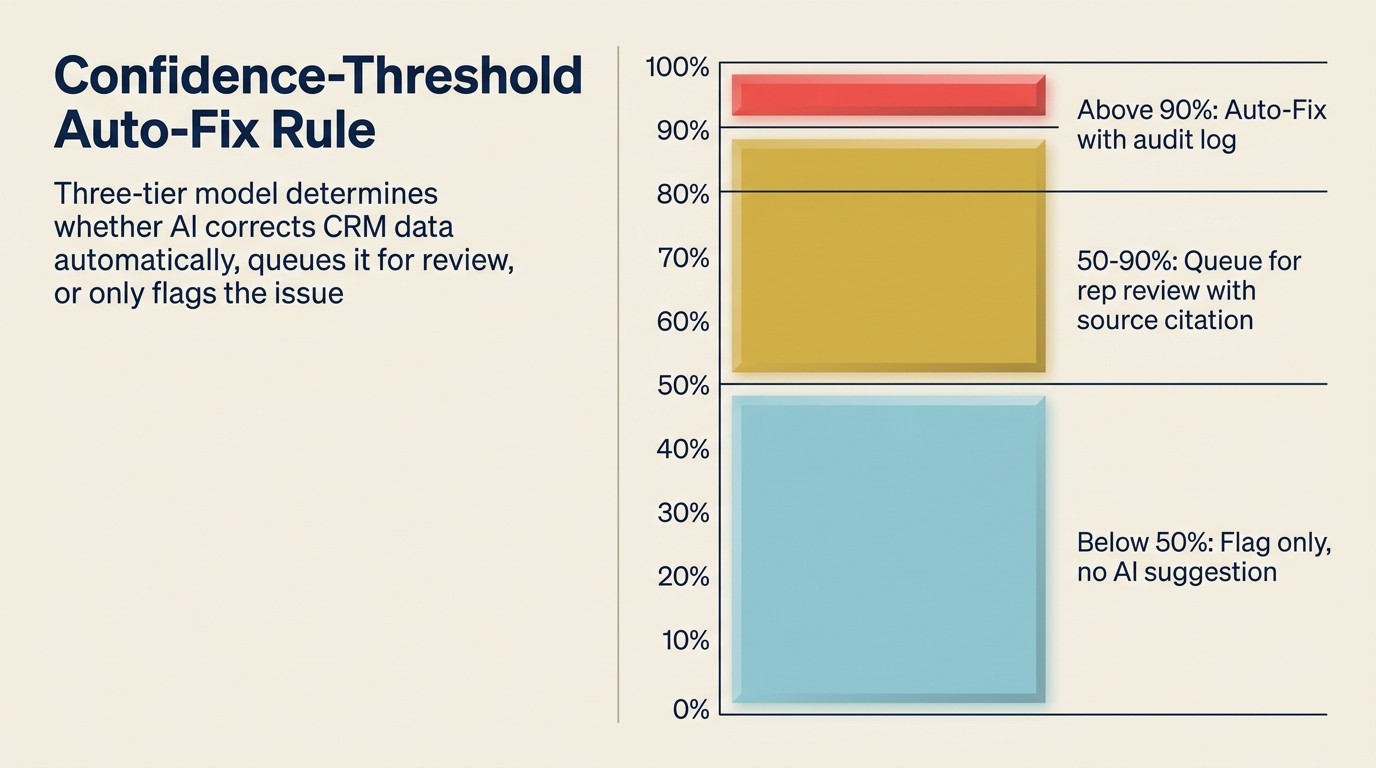
ガバナンスモデルはAI CRMハイジーンシステムで最も重要な設計決定です。
自動修正されるもの:
- 競合するフィールドデータなしの完全一致重複レコード(同じメールアドレス、同じドメイン、確認済みの同一会社):自動的にマージし、マージをログに記録
- エンリッチメントソースの信頼度が高い(90%超)欠如フィールド:自動補完
- アクティビティゼロかつディール履歴ゼロで365日以上経過したレコード:30日の回復期間を設けて自動アーカイブ
レビューキューに入れるもの:
- あいまいマッチの重複(同じ会社名、異なるドメイン):マージ提案を提示し、人間の確認を必要とする
- エンリッチメント信頼度が中程度(50〜90%)の欠如フィールド:ソースの引用と共に補完を提案し、確認を必要とする
- 陳腐化したアクティブディール(90日間アクティビティなし、ディールステータスがまだオープン):ディールオーナーにアラート、自動クローズはしない
- 会社名や主要連絡先などのキーフィールドへのエンリッチメントドリフト:担当者レビューのためにフラグを立てるが、サイレントに上書きしない
フラグのみにするもの:
- 低信頼度の潜在的なエンリッチメントドリフト:具体的な修正を提案せずに「古い可能性があります」として表示
- 明確な修正なしにフィールド間でデータが一致していないように見えるレコード
しきい値のキャリブレーションはデータ環境に基づいた調整が必要です。控えめに始め(より多くのレビュー、より少ない自動化)、特定のデータパターンに対するモデルの精度への信頼が積み上がるにつれて自動化に移行します。
考えるのに役立つ方法:AIがこの信頼度レベルで間違いを犯した場合、その結果はどれほど悪いか?完全一致の重複の場合、間違ったマージのコストは回復可能です。重要な連絡先の情報を間違ったエンリッチメントデータで上書きする場合、その結果は担当者がライブのディールについて間違った人物に電話することです。異なるリスクプロファイルは異なるしきい値を必要とします。
4つのハイジーン問題タイプの詳細

重複
重複レコードは最も一般的なCRMデータ問題であり、検出において最も計算上興味深いものです。メールやドメインの完全一致は簡単です。難しいケースは:
- 「Acme Corp」と「Acme Corporation」(同一会社、異なる名前の文字列)
- 同じ電話番号だが異なる会社がリストされた「John Smith」の2つの連絡先レコード(別人ではなく転職)
- 買収された会社が自社のアカウントとして、また買収側の子会社として両方存在する
AI重複排除は複数のマッチングシグナルを使用します。会社名の文字列類似性、ドメインマッチング、住所マッチング、電話マッチング、ネットワークグラフ分析(異なるパスで同じ会社にリンクされた連絡先)。シグナルを組み合わせることで、各潜在的なマージの信頼スコアが生成されます。
重要な運用上の決定:マージは自動であるべきか、すべてのマージが人間のレビューを必要とするか?50,000以上のレコードを運用している高ボリューム組織では、すべてのマージに人間のレビューを要求すると誰も処理しないバックログが生まれます。自動化のしきい値を定義し、月次で自動マージのサンプルを監査して精度を確認します。
フィールドの完全性
必須フィールドの定義は組織によって異なります。しかしAI支援の営業オペレーションの最低基準は、会社の業種バーティカル、会社の従業員数範囲、最後の資金調達日とラウンド、検証済みメール付きの主要連絡先、営業資格審査済みリードステータスを含みます。
AIはエンリッチメントソース(Clearbit、ZoomInfo、LinkedIn、Crunchbase、会社ウェブサイトデータ)から欠如フィールドを補完します。品質はフィールドタイプによって異なります。会社の従業員数と資金調達は一般的に信頼性が高いです。業種分類はドリフトすることがあります(一部のエンリッチメントプロバイダーは異なる分類体系を使用します)。個別の連絡先データは人々が転職するにつれて急速に古くなります。
完全性率は常時のRevOpsメトリクスとして追跡します。アクティブなアカウントの必須フィールドについて90%以上の完全性を目標にします。MITスローンのデータ品質に関する研究は、データ品質を定期的なプロジェクトではなく継続的なプロセスとして扱う組織は、データドリブンな取り組みから3〜4倍良い結果を得ることを発見しています。完全性がしきい値を下回った場合、問題がデータ入力ワークフロー(担当者がフィールドをスキップ)にあるのか、エンリッチメントカバレッジ(エンリッチメントプロバイダーがターゲットバーティカルの小規模企業のデータを持っていない)にあるのかを調査します。
陳腐化レコード
パイプラインの陳腐化レコードは最も危険なハイジーン問題です。虚偽の収益の信頼を生み出すからです。オープンディールで2.4億ドルを示すパイプラインレポートは、そのうちの8000万ドルが6ヶ月間アクティビティがないディールであれば誤解を招きます。
AI陳腐化レコード検出はアクティビティのタイムスタンプデータを使用します。最後のメール、最後のコール、最後のミーティング、最後のCRMノート。設定可能なしきい値(初期ステージのディールで90日、後期ステージで180日)を超えたレコードにフラグが立てられます。
適切なアクションはレコードタイプによって異なります。オープンディールには:ディールオーナーにアクティビティを記録するかディールを非アクティブにするかのアラートを送ります。アクティブなディールを自動クローズしないでください。アクティビティのない連絡先には:何をするかを決める前にまだ会社に在籍しているかを確認します。アクティビティのないアカウントには:アクティブシーケンスに入っていないアカウント(問題なし)と、ナーチャーシーケンスに入っているべきだが入っていないアカウントを区別します。
エンリッチメントドリフト
これは最も静かで、最もダメージを与える問題の一つです。データは入力時には正確で、外部の現実が変わりました。CRMは更新しませんでした。
連絡先の転職が最も一般的です。育てていたChampionが3ヶ月前に会社を去り、担当者はまだ古いアドレスにメールを送っています。会社の買収:追いかけているアカウントが買収され、異なる購買プロセスを持つ子会社になりました。資金調達イベント:会社がシリーズBを調達したばかりで、購買力とおそらくテクノロジー決定のタイムラインが変わります。
AIドリフト検出はCRMレコードを外部シグナルと比較します。LinkedIn の変更(連絡先の役職や会社の変更)、ニュースイベント(M&Aの発表、資金調達ラウンド)、会社ウェブサイトの変更。ミスマッチが検出されたとき、自動修正ではなくフラグとして表示されます。コンテキストが重要だからです。「この連絡先のLinkedInが別の会社を示しています」はシグナルであり、確定的な修正ではありません。
継続的なハイジーン vs. 四半期クリーンアップ
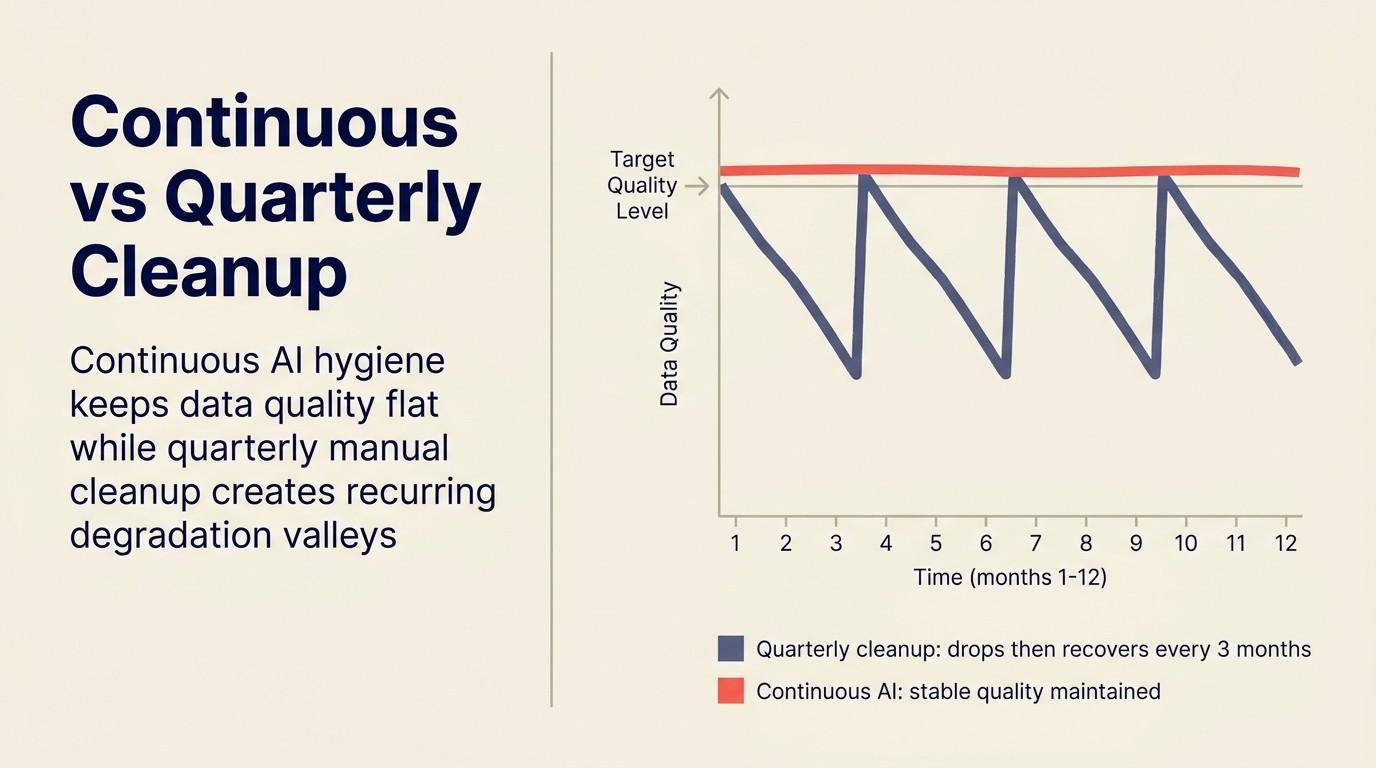
ほとんどの組織はCRMハイジーンをプロジェクトとしてアプローチします。数値が間違って見えるか、データ品質が低下して見える四半期ごとの予測レビューや監査によってトリガーされる四半期ごとのクリーンアップキャンペーン。
四半期ごとのキャンペーンの問題はデータ劣化の曲線です。アクティブなディールフローのある組織では、各問題タイプがどのくらいの速度で蓄積するかの大まかな見積もりです:
- 新しい重複:インポートイベント、手動入力、システム統合から週に5〜15件
- フィールド完全性のギャップ:完全なインテイクプロセスなしに作成されたすべての新しいレコード
- 陳腐化レコード:停滞するすべてのディール、コールドになるすべての連絡先
- エンリッチメントドリフト:転職だけで月に2〜3%のアクティブな連絡先レコードが不正確になる
四半期ごとのクリーンアップキャンペーンが実行される頃には、数ヶ月の劣化が蓄積されています。クリーンアップは毎回より大きなプロジェクトになります。そして劣化を防がない。ただベースラインに戻すだけで、次の劣化サイクルが始まる前に。
継続的なAIハイジーンはエコノミクスを変えます。数ヶ月分の蓄積された問題をバッチ修正するのではなく、AIは継続的に実行し問題が発生した近くでキャッチします。問題あたりのメンテナンス負荷が低くなります。データ品質のフロアが高くなります。そしてAI支援の下流機能、スコアリング、ルーティング、予測は、クリーンアッププロジェクト後の2週間だけでなく、四半期を通じてよりクリーンなデータで動作します。
上流の依存関係:クリーンなデータが単なるハイジーン問題ではない理由
営業スタックにおけるすべてのAI機能は、CRMデータ品質の下流にあります。この依存関係のチェーンがデータハイジーンを単なる運用的なものではなく、戦略的な投資にします。
AIリードスコアリング:ルールベースモデルを超えてはスコアリングの入力としてCRMフィールドの完全性に依存しています。業種や従業員数データが欠けているとスコアリングされないか不正確にスコアリングされたレコードが生まれます。
コールからCRM更新の自動化はアウトプットとしてよりクリーンなCRMデータを生み出しますが、更新をどこに書き込むかを知るために、アカウントと連絡先レコードが正しく構造化されていることに依存しています。
オープンディールごとの次のベストアクションはレコメンデーションを生成するためにディールステージデータ、最後のアクティビティ日付、連絡先の完全性を使用します。陳腐化したディールデータと欠けている連絡先情報はレコメンデーション品質を直接低下させます。
複利効果:CRMハイジーンの問題は孤立したエラーを生み出しません。伝播します。重複したアカウントレコードは、スコアリングシグナルが2つのレコードに分割され、両方で見かけ上のIntentを減らすことを意味します。陳腐化したディールはパイプライン予測を水増しし、それが過度に楽観的なリソース計画につながります。古くなった連絡先は間違った人物へのアウトリーチを意味し、それが応答なしを生み出し、AIスコアリングモデルが低エンゲージメントとして解釈し、アカウントの優先スコアを下げます。
クリーンなデータはすべてのAIアウトプットを下流で改善します。整然としたレコードを持つことではありません。それらのレコードからあなたの組織が下すすべてのAI生成決定の品質についてです。
実装ツール
Rework CRMは営業オペレーションレイヤーの一部としてAI支援のデータハイジーンを含んでいます。重複検出、エンリッチメントソースからのフィールド補完、陳腐化フラグがアカウントと連絡先管理ワークフローに組み込まれています。ガバナンスモデル(自動修正 vs. レビューキュー)はフィールドタイプと信頼度しきい値で設定可能です。
Salesforceの重複管理はネイティブの重複ルールとマッチングルールを提供し、自動検出とマージが可能です。サードパーティツール(Cloudingo、DemandTools)はより洗練されたマッチングロジックとバッチオペレーションでこれを拡張します。AIエンリッチメントは通常ClearbitやZoomInfoとの統合経由で追加されます。
HubSpotのデータ品質ツールは連絡先と会社の重複管理を含み、専用のレビューキューがあります。フィールドレベルのデータ健全性レポートがデータベース全体の完全性率を示します。HubSpotのネイティブエンリッチメント(データエンリッチメント機能経由)は識別されたレコードの基本的な会社フィールドを自動補完します。
Clayはカスタムエンリッチメントワークフローを構築したいチームのためのより組み合わせ可能なオプションです。複数のデータソース(Clearbit、Apollo、LinkedIn、ドメインデータ)を接続し、エンリッチメントのウォーターフォール(ソースAを試し、ソースBにフォールバック)を定義し、クリーンなデータをCRMに書き戻します。ネイティブCRMツールよりセットアップが多く必要ですが、非標準のユースケースには柔軟性が高いです。
Analyze機能はハイジーン分析の基礎となる検出と分類ロジックをカバーしています。データの準備要件の記事はクリーンなCRMデータがスタック内のすべてのAIシステムのゲーティング要件である理由を説明しています。Gartnerのデータ品質改善に向けた12のアクションは、AIハイジーンツールと並行して正式なデータ品質プログラムを構築するRevOpsリーダーの実践的な参考資料です。
インフラとしての議論
CRMハイジーンはRevOpsの予算で最も地味な項目です。直接的に収益を生み出さず、新しい機能を追加せず、取締役会のレポートに表示されるメトリクスを生み出しません。
しかし、他のすべてを正確にするインフラです。リードスコアリングの精度、ルーティングの正確さ、パイプライン予測の信頼性、担当者の次のアクションの品質:そのすべてがデータ品質に依存しています。
AI支援の継続的なハイジーンモデルはリソースの方程式を変えます。RevOpsの時間を40〜80時間消費する四半期ごとの大きなクリーンアッププロジェクトの代わりに、ソースで問題をキャッチして修正する常時稼働のシステムを持ちます。必要な人間の時間の合計が減ります。データ品質が一貫して高くなります。
そして新しいAI機能を営業スタックに追加するとき、データの問題から始めません。クリーンなデータの上に構築します。それがインフラ投資の複利リターンです。
データハイジーンは一度購入する製品ではありません。継続的に実行するプロセスです。AIは比例した人員増加なしにそのプロセスを実行することを可能にします。これがそのための議論です。そして、このひとつを正しく行うと、スタック内の他のすべてのAIツールがより良く機能する理由です。
Rework Analysis: RevOpsの展開では、最初の重要なキャリブレーション決定は重複マージの自動修正しきい値です。低く設定しすぎる(85%の信頼度以下のあいまいマッチを自動マージする)と、別のデータ品質問題を生み出します。似た名前を持つ正当な会社が誤ってマージされ、元の重複よりも解きほぐすのが難しいアクティビティ履歴の汚染が生じます。自動マージでは95%の信頼度から始め、最初の月に50件のランダムな自動マージを確認し、エラー率に基づいてしきい値を調整します。ほとんどのチームは最初のキャリブレーションサイクル後に90%に移行できます。
継続的なAIデータハイジーンプログラムを持つ組織は、必須CRMフィールドの90%以上のフィールド完全性を維持します。四半期ごとの手動クリーンアップに依存する組織の平均は65〜75%の完全性で、各クリーンアップサイクル前の6週間に精度が最も低くなります。(MITスローンのデータ品質研究)
よくある質問
CRMデータ品質の悪さは実際にいくらかかりますか?
Gartnerの推定によると、データ品質の低さはマーケティング費の無駄、営業機会の損失、運用の非効率性を通じて、平均的なB2B企業に年間1290万〜1500万ドルのコストをもたらします。個別の担当者レベルでは、営業担当者はデータ品質の悪さへの対処に時間の27%を無駄にし、1担当者あたり年間約3万2000ドルかかります。組織的なコストは複利で増加します。CRMの下流にあるすべてのAI機能(リードスコアリング、パイプライン予測、次のベストアクション)が汚染された入力から自信を持って間違った出力を生み出しているからです。
CRMデータはどのくらいの速度で古くなりますか?
B2Bの連絡先データは月に約2.1%の速度で古くなり、積極的なハイジーンなしに1年以内にすべての連絡先レコードの22〜30%が不正確になります。転職が主な原因です。連絡先は継続的に転職し、役職と電話番号が変わります。会社レベルのデータ(ファーモグラフィックス、資金調達ステージ、テックスタック)の変化はよりゆっくりですが、変化したときの影響は同等です。スコアリングモデルの入力と資格審査基準に影響するからです。
信頼度しきい値自動修正ルールとは何ですか?
信頼度しきい値自動修正ルールは、AI CRM修正のための3段階ガバナンスモデルです。既知のエンリッチメントソースで90%以上の信頼度では監査ログ付きで自動修正をトリガー、50〜90%の信頼度では人間のレビューのために提案をキュー、50%以下ではフラグのみ。このルールは自動化が不十分(誰も処理しないバックログ)と過剰自動化(スケールでの自信あるエラー)を防ぎます。しきい値は自動修正の監査レビューのサンプリングによって四半期ごとにキャリブレーションすべきです。ほとんどのチームは自動修正ティアで95%から始め、最初のキャリブレーションサイクル後に90%に移行します。
AIハイジーンが対処する4種類のCRMデータ問題は何ですか?
AI CRMハイジーンは、重複(同じ会社や連絡先が複数のレコードに)、フィールド完全性のギャップ(必須フィールドが空)、陳腐化レコード(90〜180日以上アクティビティのないオープンディールや連絡先)、エンリッチメントドリフト(入力時には正確だったが外部の変化によって誤りになったデータ)に対処します。各問題タイプは異なる下流AI機能を低下させます。重複はスコアリングシグナルを分割し、フィールドの欠如はモデルの精度を下げ、陳腐化レコードはパイプライン予測を水増しし、ドリフトは間違った連絡先へのアウトリーチを生み出します。
四半期ごとのCRMクリーンアップが不十分なのはなぜですか?
四半期ごとのクリーンアップはデータ品質をプロセスではなくプロジェクトとして扱います。アクティブなディールフローのある組織では、新しい重複が週に5〜15件蓄積し、フィールド完全性のギャップはすべての新しいレコードで現れ、陳腐化したディールは継続的に蓄積し、2.1%の連絡先が月に古くなります。四半期ごとのキャンペーンが実行される頃には、数ヶ月の劣化が蓄積されています。継続的なAIハイジーンは問題が発生した近くでキャッチし、90日間修正されずに続くエラーのバックログと結果の両方を削減します。
CRMデータ品質はAIリードスコアリングにどのような影響を与えますか?
AIリードスコアリングモデルはCRMデータで学習し、それに対して実行されます。フィールドの欠如(業種なし、従業員数なし)はスコアリングされないか不正確にスコアリングされたレコードを生み出します。重複レコードはIntentシグナルを2つのアカウントに分割し、それぞれが実際よりエンゲージメントが低く見えるようにします。陳腐化したディールデータは、非アクティブなディールをライブの見込み客として含めることでトレーニングセットを歪めます。90%以上のCRM完全性率を持つ組織は65〜75%の完全性を持つ組織より意味のある高いリードスコアリング精度を示します。モデルがより完全なシグナルデータを使えるからです。
次に読む記事
- Workflow Copilot: AI as Peer-Level Assistant: 営業ワークフローでの継続的なAIアシスタンスの背後にあるACEパターン
- AI Lead Scoring Beyond Rules-Based Models: CRMデータ品質がスコアリングモデルの精度にどう直接影響するか
- Next Best Action for Each Open Deal: クリーンなディールデータに最も依存する下流AI機能
- AI Sales Ops Governance and Audit Trails: 自動化されたデータオペレーションのガバナンスフレームワーク
