Kebersihan Data CRM dengan AI Copilot

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Sampah masuk, sampah keluar.
Anda sudah cukup mendengarnya sehingga ia terasa seperti klise. Tetapi dalam operasi jualan berbantu AI, ia adalah persamaan yang mengawal. Model penskoran lead Anda dilatih menggunakan data CRM. Penetapan peringkat akaun Anda ditarik dari firmografi CRM. Ramalan pipeline Anda dikira dari data peringkat tawaran. Penghalaan isyarat niat Anda diaktifkan berdasarkan rekod akaun dalam CRM.
Setiap fungsi AI dalam tumpukan jualan Anda adalah hiliran dari kualiti data CRM. Apabila data itu berselerak, output AI Anda salah dengan keyakinan. Dan salah dengan keyakinan lebih teruk daripada tidak pasti secara terbuka kerana wakil bertindak atasnya. Gartner menganggarkan bahawa kualiti data yang buruk menyebabkan organisasi rugi purata $15 juta setahun, dengan isu kualiti data CRM mewakili salah satu sumber impak tertinggi kos tersebut untuk pasukan komersial.
Kebersihan CRM bukan kerja yang glamor. Pemimpin RevOps tahu ini. Kebanyakan telah melancarkan projek pembersihan data, menjalankannya selama satu suku, mengisytiharkan kejayaan, dan menyaksikan kualiti data merosot semula dalam tempoh 6 bulan. Model pembersihan suku tahunan tidak berfungsi kerana data tidak rosak setiap suku tahun. Ia merosot secara berterusan, pada kadar yang didorong oleh volum tawaran Anda, disiplin wakil Anda, dan kadar perubahan dalam akaun Anda.
Corak Workflow Copilot yang digunakan untuk kebersihan CRM adalah model yang berbeza: pengesanan dan pembetulan automatik yang berterusan, dengan lapisan tadbir urus yang memastikan manusia dalam rantai keputusan untuk apa sahaja di atas ambang keyakinan. Artikel ini membincangkan cara ia berfungsi, empat jenis masalah yang ditanganinya, dan mengapa ia adalah pelaburan infrastruktur yang menjadikan semua yang lain dalam tumpukan AI Anda lebih boleh dipercayai.
Apa yang dimaksudkan kebersihan data CRM secara operasi
Fakta Utama: Kos Data CRM yang Buruk
- Kualiti data CRM yang buruk menyebabkan syarikat B2B purata rugi $12.9 hingga $15 juta setahun melalui perbelanjaan pemasaran yang terbuang, peluang jualan yang hilang, dan ketidakcekapan operasi. (Gartner / ZoomInfo, 2025)
- Wakil jualan membuang 27% masa mereka menangani data yang buruk, menyebabkan anggaran $32,000 setiap wakil setahun dalam produktiviti yang hilang. (Validity, 2025)
- Data kenalan B2B merosot kira-kira 2.1% sebulan, bermakna 22-30% rekod kenalan CRM menjadi tidak tepat dalam setahun tanpa kebersihan aktif. (Salesgenie, 2025)
"Kebersihan data" adalah istilah yang merangkumi banyak perkara. Untuk tujuan RevOps, ia meliputi empat jenis masalah yang berbeza:
Pendua. Syarikat yang sama wujud sebagai dua rekod ("Acme Corp" dan "Acme Corporation Inc"). Kenalan yang sama ada dalam sistem tiga kali dari tiga peristiwa import yang berbeza. Pendua memisahkan sejarah aktiviti, memecahkan konteks hubungan, dan menghasilkan kiraan kenalan yang melambung yang mengganggu tugasan wilayah Anda.
Kelengkapan medan. Medan yang diperlukan kosong. Tiada sektor industri. Tiada bilangan pekerja. Tiada pusingan pembiayaan terakhir. Tiada kenalan utama pada akaun. Jurang ini merosakkan model penskoran yang menggunakan medan tersebut sebagai input dan menghasilkan sel kosong dalam laporan yang sepatutnya menjadi permukaan keputusan.
Rekod lapuk. Tiada aktiviti yang dilog dalam 180 hari, tetapi tawaran masih terbuka dalam pipeline Anda. Syarikat kenalan telah diambil alih 8 bulan lalu tetapi rekod akaun belum dikemas kini. Champion utama telah meninggalkan syarikat tetapi masih disenaraikan sebagai kenalan utama. Rekod lapuk menghasilkan keyakinan pipeline yang palsu dan menghasilkan jangkauan yang terlepas kepada peluang langsung.
Hanyutan pengayaan. Data adalah tepat semasa dimasukkan dan sejak itu menjadi salah disebabkan perubahan luaran. Syarikat berpindah. Kenalan menukar pekerjaan. Nombor telefon tidak aktif. Pusingan pembiayaan berlaku. Bilangan pekerja berubah. CRM tidak tahu; ia hanya menyimpan apa yang dimasukkan. Dari masa ke masa, jurang antara rekod CRM dan kebenaran sebenar melebar.
Keempat-empat jenis masalah ini merendahkan kualiti output AI dengan cara yang khusus. Pendua mengelirukan model penskoran dengan data isyarat yang terpisah. Medan yang hilang mengurangkan ketepatan model dan menghasilkan rekod yang tidak mendapat skor. Rekod lapuk mengembungkan nombor pipeline dan memesongkan ramalan. Hanyutan pengayaan menghasilkan jangkauan kepada kenalan yang salah dan kriteria kelayakan yang salah.
Cara Workflow Copilot menangani kebersihan
Corak Workflow Copilot dalam ACE Framework menggambarkan gelung bantuan berterusan: Ingest konteks semasa, Analyze untuk mengenal pasti apa yang memerlukan perhatian, Generate cadangan, Execute dengan kelulusan manusia (atau tindakan automatik untuk kes keyakinan tinggi), kemudian ulangi.
Digunakan untuk kebersihan CRM:
Ingest membaca keadaan CRM semasa. Semua rekod, semua log aktiviti, semua nilai medan. Ini berlaku secara berterusan (rekod baharu mencetuskan pemeriksaan segera) dan secara terjadual dalam kelompok (imbasan pangkalan data penuh setiap minggu).
Analyze mengenal pasti isu data merentas empat jenis masalah:
- Pengesanan pendua: pemadanan pada nama syarikat, domain, nombor telefon, dan persamaan alamat
- Pemeriksaan kelengkapan: menilai setiap rekod terhadap definisi medan yang diperlukan
- Penilaian kesegaran: menandakan rekod tanpa aktiviti yang dilog melepasi ambang yang boleh dikonfigurasikan
- Pengesanan hanyutan pengayaan: membandingkan data CRM terhadap sumber data luaran (pangkalan data syarikat, LinkedIn, carian domain)
Generate menghasilkan cadangan pembetulan untuk setiap isu yang dikenal pasti:
- Untuk pendua: cadangan penggabungan yang menentukan rekod mana yang perlu disimpan sebagai utama dan medan mana yang perlu diambil dari setiap rekod
- Untuk medan yang hilang: nilai yang dilengkapkan secara automatik dari sumber pengayaan, dengan skor keyakinan
- Untuk rekod lapuk: perubahan status yang dicadangkan (tandakan tidak aktif, layakkan semula, arkibkan) dengan konteks
- Untuk hanyutan: nilai medan yang dikemas kini dari pengayaan, dengan sumber yang jelas
Execute menghalakan cadangan pembetulan melalui salah satu daripada dua laluan, bergantung kepada keyakinan:
- Keyakinan tinggi (di atas ambang): jalankan pembetulan secara automatik dan log tindakan
- Di bawah ambang: antrikan untuk semakan wakil atau RevOps dengan cadangan pembetulan yang dibentangkan
Lapisan tadbir urus adalah yang membezakan ini daripada huru-hara. Pelaksanaan automatik pada semuanya menghasilkan jenis masalah kualiti data yang berbeza: pembetulan yang digunakan pada skala tanpa semakan boleh menyebarkan ralat sama cekapnya dengan memperbaikinya. Untuk prinsip tadbir urus yang lebih luas yang digunakan merentas semua sistem AI, tadbir urus AI sales ops dan jejak audit membincangkan rangka kerja secara terperinci.
Data kenalan B2B merosot pada 2.1% sebulan, dan 30% semua rekod CRM menjadi lapuk setiap tahun. Kempen pembersihan suku tahunan bermakna purata organisasi beroperasi pada data yang merosot 5-7% untuk kebanyakan tahun.
The Confidence-Threshold Auto-Fix Rule
The Confidence-Threshold Auto-Fix Rule adalah prinsip tadbir urus yang menentukan pembetulan kebersihan CRM mana yang dilaksanakan secara automatik dan yang mana memerlukan semakan manusia. Ia mempunyai tiga peringkat: di atas 90% keyakinan pada sumber pengayaan yang diketahui mencetuskan auto-fix dengan entri log audit; antara 50-90% keyakinan menghasilkan cadangan yang diantrikan untuk kelulusan RevOps atau wakil; di bawah 50% keyakinan menghasilkan bendera sahaja, tiada cadangan pembetulan. Peraturan ini mencegah dua mod kegagalan: bawah-automasi (tunggakan yang tidak diproses oleh sesiapa) dan lebih-automasi (ralat yang yakin disebarkan pada skala). Peratusan ambang harus dikalibrasi setiap suku tahun berdasarkan semakan audit sampel auto-pembetulan.
Ambang auto-fix berbanding semakan wakil
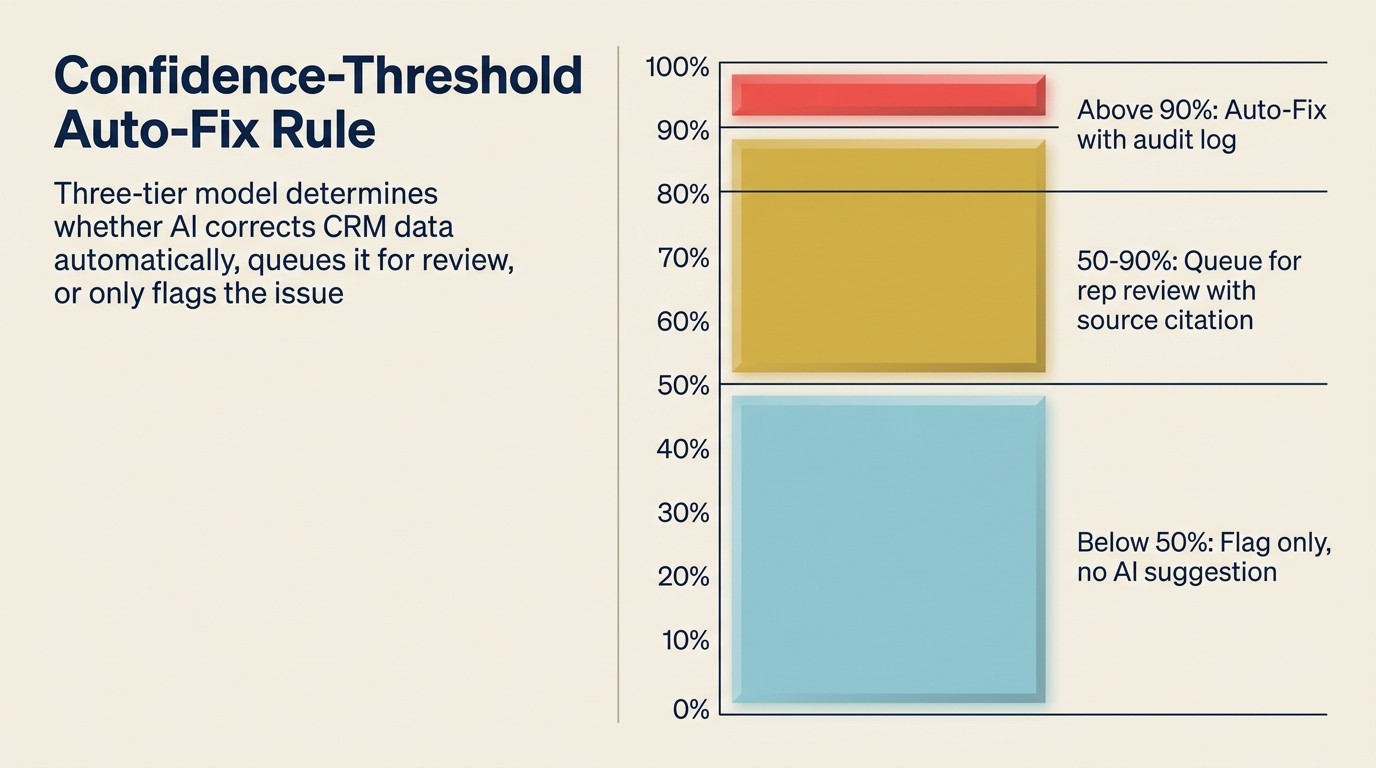
Model tadbir urus adalah keputusan reka bentuk yang paling penting dalam sistem kebersihan AI CRM.
Apa yang boleh dilakukan auto-fix:
- Rekod pendua padanan tepat (alamat e-mel yang sama, domain yang sama, syarikat yang disahkan sama) tanpa data medan yang bercanggah: gabungkan secara automatik, log penggabungan
- Medan yang hilang di mana keyakinan sumber pengayaan adalah tinggi (lebih daripada 90%): isi secara automatik
- Rekod tanpa aktiviti dan tiada sejarah tawaran yang lebih tua daripada 365 hari: arkib automatik dengan tetingkap pemulihan 30 hari
Apa yang diantrikan untuk semakan:
- Pendua padanan kabur (nama syarikat yang sama, domain berbeza): bentangkan cadangan penggabungan, perlukan pengesahan manusia
- Medan yang hilang di mana keyakinan pengayaan adalah sederhana (50% hingga 90%): cadangkan pengisian dengan petikan sumber, perlukan pengesahan
- Tawaran aktif yang lapuk (tiada aktiviti dalam 90 hari, status tawaran masih terbuka): maklumkan pemilik tawaran, jangan tutup secara automatik
- Hanyutan pengayaan pada medan utama seperti nama syarikat atau kenalan utama: tandakan untuk semakan wakil, jangan timpa secara senyap
Apa yang hanya mendapat bendera:
- Potensi hanyutan pengayaan dengan keyakinan rendah: tampilkan sebagai "ini mungkin sudah lapuk" tanpa mencadangkan pembetulan khusus
- Rekod yang nampaknya mempunyai data yang tidak sepadan merentas medan tanpa pembetulan yang jelas
Kalibrasi ambang memerlukan penalaan berdasarkan persekitaran data Anda. Mulakan dengan konservatif (lebih banyak semakan, kurang automasi) dan beralih ke arah automasi apabila Anda membina keyakinan terhadap ketepatan model untuk corak data khusus Anda.
Cara yang berguna untuk memikirkannya: jika AI membuat kesilapan pada tahap keyakinan ini, seberapa teruk akibatnya? Untuk pendua padanan tepat, kos penggabungan yang salah boleh dipulihkan. Untuk menimpa maklumat kenalan utama dengan data pengayaan yang salah, akibatnya adalah wakil menghubungi orang yang salah mengenai tawaran yang aktif. Profil risiko yang berbeza memerlukan ambang yang berbeza.
Empat jenis masalah kebersihan secara mendalam

Pendua
Rekod pendua adalah masalah data CRM yang paling biasa dan paling menarik dari segi pengiraan untuk dikesan. Padanan tepat pada e-mel atau domain adalah mudah. Kes yang sukar adalah:
- "Acme Corp" dan "Acme Corporation" (syarikat yang sama, rentetan nama yang berbeza)
- Dua rekod kenalan untuk "John Smith" dengan nombor telefon yang sama tetapi syarikat berbeza yang disenaraikan (pertukaran kerja, bukan orang yang berbeza)
- Syarikat yang diambil alih dan kini wujud sebagai akaun tersendiri dan sebagai anak syarikat di bawah pengambil alih
Penyahduplikatan AI menggunakan pelbagai isyarat pemadanan: persamaan rentetan pada nama syarikat, pemadanan domain, pemadanan alamat, pemadanan telefon, dan analisis graf rangkaian (kenalan yang dikaitkan dengan syarikat yang sama melalui laluan yang berbeza). Menggabungkan isyarat menghasilkan skor keyakinan untuk setiap potensi penggabungan.
Keputusan operasi utama: adakah penggabungan harus automatik, atau setiap penggabungan harus memerlukan semakan manusia? Untuk organisasi volum tinggi yang menjalankan 50,000+ rekod, memerlukan semakan manusia pada setiap penggabungan mencipta tunggakan yang tidak akan diproses oleh sesiapa. Tentukan ambang automasi Anda dan audit sampel auto-penggabungan setiap bulan untuk memeriksa ketepatan.
Kelengkapan medan
Definisi medan yang diperlukan berbeza-beza mengikut organisasi. Tetapi standard minimum untuk operasi jualan berbantu AI termasuk: sektor industri syarikat, julat bilangan pekerja, tarikh dan pusingan pembiayaan terakhir, kenalan utama dengan e-mel yang disahkan, dan status lead yang layak jualan.
AI mengisi medan yang hilang dari sumber pengayaan: Clearbit, ZoomInfo, LinkedIn, Crunchbase, dan data laman web syarikat. Kualiti berbeza mengikut jenis medan. Bilangan pekerja dan pembiayaan syarikat umumnya boleh dipercayai. Klasifikasi industri boleh hanyut (sesetengah pembekal pengayaan menggunakan sistem taksonomi yang berbeza). Data kenalan individu merosot dengan cepat apabila orang menukar pekerjaan.
Jejaki kadar kelengkapan sebagai metrik RevOps tetap. Sasaran kelengkapan 90%+ pada medan yang diperlukan untuk akaun aktif. Penyelidikan MIT Sloan tentang kualiti data mendapati bahawa organisasi yang menganggap kualiti data sebagai proses berterusan berbanding projek berkala melihat tiga hingga empat kali hasil yang lebih baik dari inisiatif berpacu data mereka. Apabila kelengkapan jatuh di bawah ambang, siasat sama ada isu itu dalam aliran kerja kemasukan data (wakil melangkau medan) atau dalam liputan pengayaan (pembekal pengayaan Anda tidak mempunyai data untuk syarikat kecil dalam sektor sasaran Anda).
Rekod lapuk
Rekod lapuk dalam pipeline adalah masalah kebersihan yang paling berbahaya kerana ia menghasilkan keyakinan hasil yang palsu. Laporan pipeline yang menunjukkan $2.4J dalam tawaran terbuka adalah mengelirukan jika $800K daripadanya adalah dalam tawaran yang tidak mempunyai sebarang aktiviti dalam 6 bulan.
Pengesanan rekod lapuk AI menggunakan data cap masa aktiviti: e-mel terakhir, panggilan terakhir, mesyuarat terakhir, nota CRM terakhir. Rekod yang melepasi ambang yang boleh dikonfigurasikan (90 hari untuk tawaran peringkat awal, 180 hari untuk peringkat akhir) mendapat bendera.
Tindakan yang sesuai bergantung pada jenis rekod. Untuk tawaran terbuka: maklumkan pemilik tawaran untuk sama ada log aktiviti atau tandakan tawaran sebagai tidak aktif. Jangan tutup tawaran aktif secara automatik. Untuk kenalan tanpa aktiviti: semak sama ada mereka masih bekerja di syarikat sebelum memutuskan tindakan. Untuk akaun tanpa aktiviti: bezakan antara akaun yang tidak dalam urutan aktif (tidak mengapa) dan akaun yang sepatutnya dalam urutan pemupukan tetapi tidak ada.
Hanyutan pengayaan
Ini adalah masalah yang paling sunyi dan salah satu yang paling merosakkan. Data adalah betul semasa dimasukkan. Realiti luaran berubah. CRM tidak dikemas kini.
Pertukaran kerja kenalan adalah yang paling biasa: champion yang Anda pupuk selama ini telah meninggalkan syarikat 3 bulan lalu dan wakil Anda masih menghantar e-mel ke alamat lama. Pengambilalihan syarikat: akaun yang Anda kejar telah dibeli dan kini merupakan anak syarikat dengan proses perolehan yang berbeza. Peristiwa pembiayaan: syarikat baru sahaja memperoleh Siri B, yang mengubah kuasa beli mereka dan mungkin garis masa mereka untuk keputusan teknologi.
Pengesanan hanyutan AI membandingkan rekod CRM terhadap isyarat luaran: perubahan LinkedIn (perubahan tajuk atau syarikat kenalan), peristiwa berita (pengumuman pengambilalihan, pusingan pembiayaan), perubahan laman web syarikat. Apabila ketidakpadanan dikesan, ia muncul sebagai bendera berbanding pembetulan automatik, kerana konteks adalah penting. "LinkedIn kenalan ini kini menunjukkan syarikat yang berbeza" adalah isyarat, bukan pembetulan yang muktamad.
Kebersihan berterusan berbanding pembersihan suku tahunan
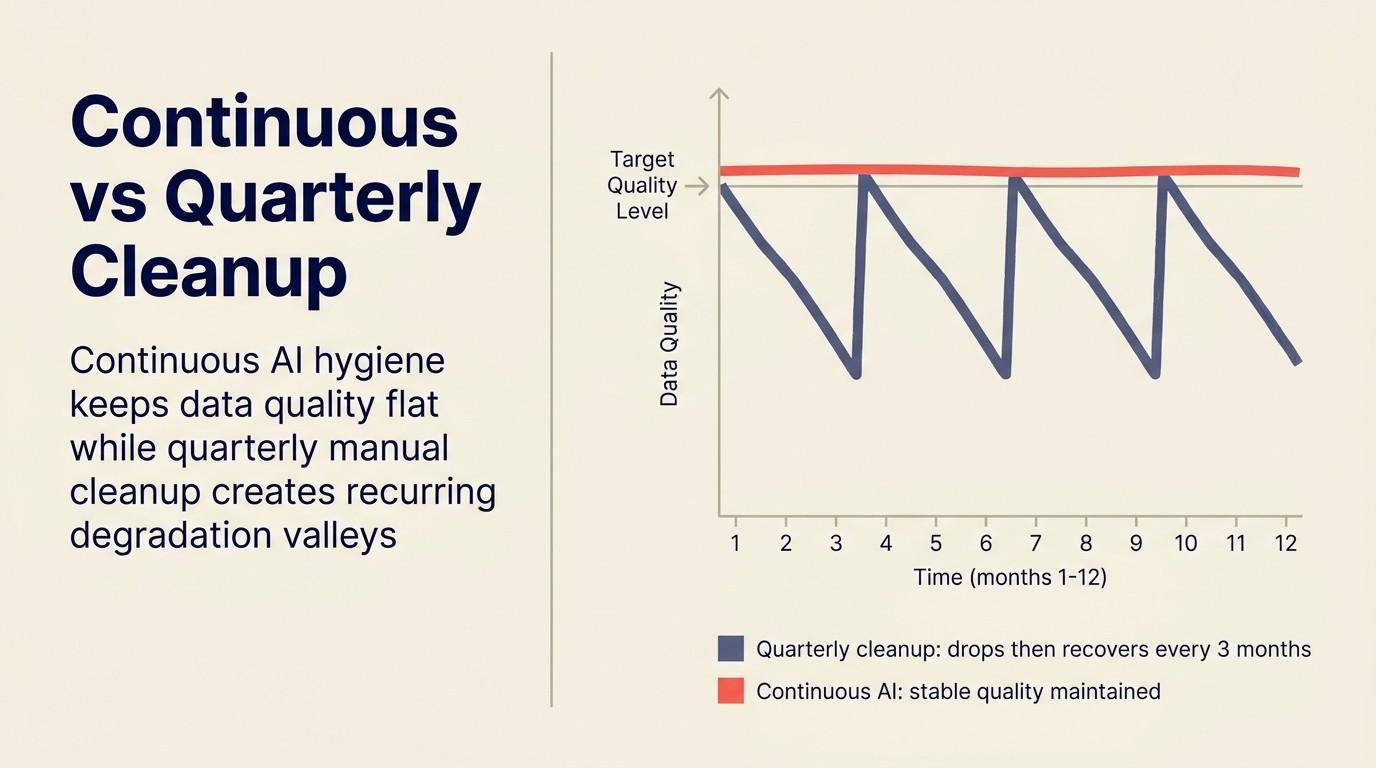
Kebanyakan organisasi mendekati kebersihan CRM sebagai projek: kempen pembersihan suku tahunan, biasanya dicetuskan oleh semakan ramalan di mana nombor kelihatan salah atau audit di mana kualiti data kelihatan merosot.
Masalah dengan kempen suku tahunan adalah keluk kemerosotan data. Untuk organisasi dengan aliran tawaran yang aktif, berikut adalah anggaran kasar betapa cepatnya setiap jenis masalah terkumpul:
- Pendua baharu: 5 hingga 15 setiap minggu dari peristiwa import, kemasukan manual, dan integrasi sistem
- Jurang kelengkapan medan: setiap rekod baharu yang dicipta tanpa proses pengambilan yang lengkap
- Rekod lapuk: setiap tawaran yang terhenti, setiap kenalan yang menjadi tidak aktif
- Hanyutan pengayaan: 2 hingga 3% rekod kenalan aktif menjadi tidak tepat setiap bulan dari pertukaran kerja sahaja
Menjelang kempen pembersihan suku tahunan dijalankan, berbulan-bulan kemerosotan telah terkumpul. Pembersihan adalah projek yang lebih besar setiap kali. Dan ia tidak mencegah kemerosotan; ia hanya memulihkan ke garis asas sebelum kitaran pereputan seterusnya.
Kebersihan AI yang berterusan mengubah ekonomi. Berbanding membetulkan kumpulan masalah yang terkumpul selama berbulan-bulan secara berkelompok, AI berjalan secara berterusan dan menangkap isu-isu hampir dengan masa ia berlaku. Beban kerja penyelenggaraan setiap isu adalah lebih rendah. Lantai kualiti data adalah lebih tinggi. Dan fungsi hiliran yang dibantu AI, penskoran, penghalaan, ramalan, semuanya beroperasi pada data yang lebih bersih sepanjang suku tahun, bukan sahaja dalam dua minggu selepas projek pembersihan.
Kebergantungan huluan: mengapa data yang bersih bukan sekadar kebimbangan kebersihan
Setiap fungsi AI dalam tumpukan jualan Anda adalah hiliran dari kualiti data CRM. Rantai kebergantungan ini menjadikan kebersihan data pelaburan strategik, bukan sekadar operasi.
AI Lead Scoring Beyond Rules-Based Models bergantung kepada kelengkapan medan CRM untuk input penskoran. Data industri atau bilangan pekerja yang hilang menghasilkan rekod yang tidak mendapat skor atau mendapat skor yang lemah.
From Call to CRM Update Automatically menghasilkan data CRM yang lebih bersih sebagai output, tetapi bergantung kepada rekod akaun dan kenalan yang disusun dengan betul untuk mengetahui di mana hendak menulis kemaskini.
Next Best Action for Each Open Deal menggunakan data peringkat tawaran, tarikh aktiviti terakhir, dan kelengkapan kenalan untuk menjana cadangan. Data tawaran yang lapuk dan maklumat kenalan yang hilang secara langsung merendahkan kualiti cadangan.
Kesan berganda: masalah kebersihan CRM tidak menghasilkan ralat terpencil. Ia merebak. Rekod akaun pendua bermakna isyarat penskoran dibahagikan merentas dua rekod, mengurangkan niat yang kelihatan untuk kedua-duanya. Tawaran yang lapuk mengembungkan ramalan pipeline, yang membawa kepada perancangan sumber yang terlalu optimistik. Kenalan yang lapuk bermakna jangkauan pergi kepada orang yang salah, yang tidak menghasilkan respons, yang diinterpretasikan oleh model penskoran AI sebagai penglibatan rendah, yang mengurangkan skor keutamaan akaun.
Data yang bersih meningkatkan setiap output AI hiliran. Ini bukan tentang mempunyai rekod yang kemas. Ia tentang kualiti setiap keputusan yang dijana AI yang dibuat oleh organisasi Anda dari rekod tersebut.
Alat pelaksanaan
Rework CRM termasuk kebersihan data berbantu AI sebagai sebahagian daripada lapisan operasi jualan. Pengesanan pendua, pengisian medan dari sumber pengayaan, dan penandaan kelapukan dibina ke dalam aliran kerja pengurusan akaun dan kenalan. Model tadbir urus (auto-fix berbanding antrean semakan) boleh dikonfigurasikan mengikut jenis medan dan ambang keyakinan.
Pengurusan pendua Salesforce menyediakan peraturan pendua dan peraturan pemadanan asli, dengan pengesanan dan penggabungan automatik. Alat pihak ketiga (Cloudingo, DemandTools) memperluaskan ini dengan logik pemadanan yang lebih canggih dan operasi kelompok. Pengayaan AI biasanya ditambahkan melalui integrasi dengan Clearbit atau ZoomInfo.
Alat kualiti data HubSpot termasuk pengurusan pendua untuk kenalan dan syarikat, dengan antrean semakan khusus. Pelaporan kesihatan data peringkat medan menunjukkan kadar kelengkapan merentas pangkalan data. Pengayaan asli HubSpot (melalui ciri pengayaan data) mengisi medan syarikat asas secara automatik untuk rekod yang dikenal pasti.
Clay adalah pilihan yang lebih boleh dikomposisi untuk pasukan yang ingin membina aliran kerja pengayaan tersuai. Sambungkan pelbagai sumber data (Clearbit, Apollo, LinkedIn, data domain), tentukan air terjun pengayaan (cuba sumber A, fallback ke sumber B), dan tolak data yang bersih kembali ke CRM Anda. Memerlukan lebih banyak persediaan berbanding alat CRM asli tetapi menawarkan lebih banyak fleksibiliti untuk kes penggunaan bukan standard.
Keupayaan Analyze membincangkan logik pengesanan dan klasifikasi yang mendasari analisis kebersihan. Artikel prasyarat kesediaan data menerangkan mengapa data CRM yang bersih adalah keperluan penting untuk setiap sistem AI dalam tumpukan Anda. 12 tindakan Gartner untuk meningkatkan kualiti data adalah sumber pendamping yang praktikal untuk pemimpin RevOps yang membina program kualiti data formal di samping alat kebersihan AI mereka.
Hujah infrastruktur
Kebersihan CRM adalah item baris yang paling tidak glamor dalam belanjawan RevOps. Ia tidak menjana hasil secara langsung, tidak menambah keupayaan baharu, dan tidak menghasilkan metrik yang muncul dalam laporan lembaga.
Tetapi ia adalah infrastruktur yang menjadikan segala yang lain tepat. Ketepatan penskoran lead, ketepatan penghalaan, kebolehpercayaan ramalan pipeline, kualiti tindakan seterusnya wakil: semuanya bergantung kepada kualiti data.
Model kebersihan berterusan berbantu AI mengubah persamaan sumber. Berbanding satu projek pembersihan besar setiap suku tahun yang menggunakan 40 hingga 80 jam masa RevOps, Anda mempunyai sistem yang sentiasa aktif yang menangkap dan membetulkan isu pada sumbernya. Jumlah masa manusia yang diperlukan adalah lebih rendah. Kualiti data secara konsisten lebih tinggi.
Dan apabila Anda menambahkan keupayaan AI baharu kepada tumpukan jualan Anda, Anda tidak bermula dari masalah data. Anda membina atas data yang bersih. Itulah pulangan berganda atas pelaburan infrastruktur.
Kebersihan data bukan produk yang Anda beli sekali. Ia adalah proses yang Anda jalankan secara berterusan. AI memungkinkan untuk menjalankan proses tersebut tanpa pertumbuhan bilangan pekerja yang setanding. Itulah hujah untuknya. Dan itulah sebabnya setiap alat AI lain dalam tumpukan Anda berfungsi lebih baik apabila Anda mendapat yang ini dengan betul.
Rework Analysis: Dalam penerapan RevOps, keputusan kalibrasi awal yang paling penting adalah ambang auto-fix untuk penggabungan pendua. Menetapkannya terlalu rendah (penggabungan automatik padanan kabur di bawah 85% keyakinan) mencipta jenis masalah kualiti data yang berbeza: syarikat sah dengan nama yang serupa digabungkan secara tidak betul, menghasilkan pencemaran sejarah aktiviti yang lebih sukar untuk diurai berbanding pendua asal. Mulakan dengan 95% keyakinan untuk auto-gabung, sahkan 50 auto-gabung rawak dalam bulan pertama, kemudian laraskan ambang berdasarkan kadar ralat. Kebanyakan pasukan boleh beralih ke 90% selepas kitaran kalibrasi pertama.
Organisasi dengan program kebersihan data AI yang berterusan mengekalkan kelengkapan medan 90%+ pada medan CRM yang diperlukan. Organisasi yang bergantung kepada pembersihan manual suku tahunan rata-rata 65-75% kelengkapan, dengan ketepatan terendah dalam enam minggu sebelum setiap kitaran pembersihan. (Penyelidikan kualiti data MIT Sloan)
Soalan Lazim
Berapa banyak sebenarnya kos kualiti data CRM yang buruk?
Kualiti data yang buruk menyebabkan syarikat B2B purata rugi $12.9 hingga $15 juta setahun melalui perbelanjaan pemasaran yang terbuang, peluang jualan yang hilang, dan ketidakcekapan operasi, menurut anggaran Gartner. Pada peringkat wakil individu, wakil jualan membuang 27% masa mereka menangani data yang buruk, menyebabkan kira-kira $32,000 setiap wakil setahun. Kos organisasi berganda kerana setiap fungsi AI hiliran CRM (penskoran lead, ramalan pipeline, tindakan seterusnya terbaik) menghasilkan output yang salah dengan keyakinan dari input yang kotor.
Seberapa cepat data CRM merosot?
Data kenalan B2B merosot kira-kira 2.1% sebulan, diterjemahkan kepada 22-30% semua rekod kenalan menjadi tidak tepat dalam setahun tanpa kebersihan aktif. Pertukaran kerja adalah pemacu utama: kenalan menukar majikan, tajuk, dan alamat e-mel secara berterusan. Data peringkat syarikat (firmografi, peringkat pembiayaan, tumpukan teknologi) berubah lebih perlahan tetapi memberi kesan yang sama apabila berubah, kerana ia mempengaruhi input model penskoran dan kriteria kelayakan.
Apakah Confidence-Threshold Auto-Fix Rule?
The Confidence-Threshold Auto-Fix Rule adalah model tadbir urus tiga peringkat untuk pembetulan AI CRM: di atas 90% keyakinan pada sumber pengayaan yang diketahui mencetuskan auto-pembetulan dengan log audit; antara 50-90% keyakinan mengantri cadangan untuk semakan manusia; di bawah 50% menghasilkan bendera sahaja. Peraturan ini mencegah bawah-automasi (tunggakan yang tidak diproses sesiapa) dan lebih-automasi (ralat yang yakin pada skala). Ambang harus dikalibrasi setiap suku tahun dengan menyampel semakan audit auto-pembetulan. Kebanyakan pasukan bermula pada 95% untuk peringkat auto-fix dan beralih ke 90% selepas kitaran kalibrasi pertama.
Empat jenis masalah data CRM apa yang ditangani oleh kebersihan AI?
Kebersihan AI CRM menangani pendua (syarikat atau kenalan yang sama dalam pelbagai rekod), jurang kelengkapan medan (medan yang diperlukan kosong), rekod lapuk (tawaran terbuka atau kenalan tanpa aktiviti selama 90-180+ hari), dan hanyutan pengayaan (data yang tepat semasa dimasukkan tetapi sejak itu menjadi salah melalui perubahan luaran). Setiap jenis masalah merendahkan fungsi AI hiliran yang berbeza: pendua memisahkan isyarat penskoran, medan yang hilang mengurangkan ketepatan model, rekod lapuk mengembungkan ramalan pipeline, dan hanyutan menghasilkan jangkauan kepada kenalan yang salah.
Mengapa pembersihan CRM suku tahunan tidak mencukupi?
Pembersihan suku tahunan menganggap kualiti data sebagai projek berbukan proses. Untuk organisasi dengan aliran tawaran yang aktif, pendua baharu terkumpul pada 5-15 setiap minggu, jurang kelengkapan medan muncul dengan setiap rekod baharu, tawaran lapuk terkumpul secara berterusan, dan 2.1% kenalan hanyut setiap bulan. Menjelang kempen suku tahunan dijalankan, berbulan-bulan kemerosotan telah terkumpul. Kebersihan AI yang berterusan menangkap isu hampir dengan masa ia berlaku, mengurangkan tunggakan dan akibat ralat yang berterusan selama 90 hari sebelum pembetulan.
Bagaimana kualiti data CRM mempengaruhi penskoran lead AI?
Model penskoran lead AI melatih dan berjalan terhadap data CRM. Medan yang hilang (tiada sektor industri, tiada bilangan pekerja) menghasilkan rekod yang tidak mendapat skor atau mendapat skor yang tidak tepat. Rekod pendua memisahkan isyarat niat merentas dua akaun, menjadikan setiap satu kelihatan kurang terlibat daripada yang sebenarnya. Data tawaran lapuk memesongkan set latihan dengan memasukkan tawaran tidak aktif seolah-olah ia adalah prospek langsung. Organisasi dengan kadar kelengkapan CRM 90%+ melihat ketepatan penskoran lead yang lebih tinggi berbanding organisasi dengan kelengkapan 65-75%, kerana model mempunyai data isyarat yang lebih lengkap untuk digunakan.
Apa yang perlu dibaca seterusnya
- Workflow Copilot: AI as Peer-Level Assistant: corak ACE di sebalik bantuan AI berterusan dalam aliran kerja jualan
- AI Lead Scoring Beyond Rules-Based Models: cara kualiti data CRM secara langsung mempengaruhi ketepatan model penskoran
- Next Best Action for Each Open Deal: fungsi AI hiliran yang paling bergantung kepada data tawaran yang bersih
- AI Sales Ops Governance and Audit Trails: rangka kerja tadbir urus untuk operasi data automatik

Co-Founder, Rework.com
On this page
- Apa yang dimaksudkan kebersihan data CRM secara operasi
- Cara Workflow Copilot menangani kebersihan
- The Confidence-Threshold Auto-Fix Rule
- Ambang auto-fix berbanding semakan wakil
- Empat jenis masalah kebersihan secara mendalam
- Pendua
- Kelengkapan medan
- Rekod lapuk
- Hanyutan pengayaan
- Kebersihan berterusan berbanding pembersihan suku tahunan
- Kebergantungan huluan: mengapa data yang bersih bukan sekadar kebimbangan kebersihan
- Alat pelaksanaan
- Hujah infrastruktur
- Apa yang perlu dibaca seterusnya