CRM Data Hygiene dengan AI Copilot

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Sampah masuk, sampah keluar.
Anda sudah cukup sering mendengarnya hingga terasa seperti klise. Tetapi dalam AI-assisted sales operations, ini adalah persamaan yang mengatur. Model lead scoring Anda dilatih pada data CRM. Penugasan tier akun Anda menarik dari firmografi CRM. Perkiraan pipeline Anda dihitung dari data tahap deal. Routing sinyal intent Anda dinyalakan berdasarkan catatan akun di CRM.
Setiap fungsi AI dalam tumpukan sales Anda berada di hilir kualitas data CRM. Ketika data itu berantakan, output AI Anda dengan percaya diri salah. Dan dengan percaya diri salah lebih buruk dari yang tidak pasti secara tegas karena rep bertindak berdasarkan hal itu. Gartner memperkirakan bahwa kualitas data yang buruk merugikan organisasi rata-rata $15 juta per tahun, dengan masalah kualitas data CRM mewakili salah satu sumber biaya tertinggi bagi tim komersial.
CRM hygiene bukan pekerjaan yang glamor. Pemimpin RevOps mengetahui ini. Sebagian besar telah meluncurkan proyek pembersihan data, menjalankannya selama satu kuartal, menyatakan kemenangan, dan menyaksikan kualitas data memburuk lagi dalam 6 bulan. Model pembersihan kuartalan tidak berfungsi karena data tidak menjadi buruk secara kuartalan. Ini menurun secara berkelanjutan, pada tingkat yang didorong oleh volume deal Anda, disiplin rep, dan laju perubahan dalam akun Anda.
Pola Workflow Copilot yang diterapkan pada CRM hygiene adalah model yang berbeda: deteksi dan koreksi otomatis yang berkelanjutan, dengan lapisan governance yang menjaga manusia dalam rantai keputusan untuk apa pun di atas ambang kepercayaan. Artikel ini mencakup cara kerjanya, empat jenis masalah yang ditanganinya, dan mengapa ini adalah investasi infrastruktur yang membuat semua hal lain dalam tumpukan AI Anda lebih andal.
Apa artinya CRM data hygiene secara operasional
Key Facts: Biaya Data CRM yang Buruk
- Kualitas data CRM yang buruk merugikan perusahaan B2B rata-rata $12,9 hingga $15 juta per tahun melalui pengeluaran pemasaran yang terbuang, peluang sales yang hilang, dan inefisiensi operasional. (Gartner / ZoomInfo, 2025)
- Sales rep membuang 27% waktu mereka menangani data yang buruk, dengan perkiraan biaya sekitar $32.000 per rep per tahun dalam produktivitas yang hilang. (Validity, 2025)
- Data kontak B2B mengalami penurunan sekitar 2,1% per bulan, artinya 22-30% catatan kontak CRM menjadi tidak akurat dalam setahun tanpa hygiene aktif. (Salesgenie, 2025)
"Data hygiene" adalah istilah catch-all. Untuk keperluan RevOps, ini mencakup empat jenis masalah yang berbeda:
Duplikat. Perusahaan yang sama ada sebagai dua catatan ("Acme Corp" dan "Acme Corporation Inc"). Kontak yang sama ada di sistem tiga kali dari tiga acara impor yang berbeda. Duplikat membagi riwayat aktivitas, memfragmentasi konteks hubungan, dan menghasilkan jumlah kontak yang meningkat yang mengacaukan penugasan wilayah Anda.
Kelengkapan kolom. Kolom yang diperlukan kosong. Tidak ada vertikal industri. Tidak ada jumlah karyawan. Tidak ada putaran pendanaan terakhir. Tidak ada kontak utama di akun. Kesenjangan ini merusak model scoring yang menggunakan kolom tersebut sebagai input dan menghasilkan sel kosong dalam laporan yang seharusnya menjadi permukaan keputusan.
Catatan basi. Tidak ada aktivitas yang dicatat dalam 180 hari, tetapi deal masih terbuka di pipeline Anda. Perusahaan kontak diakuisisi 8 bulan lalu tetapi catatan akun belum diperbarui. Champion utama meninggalkan perusahaan tetapi masih terdaftar sebagai kontak utama. Catatan basi menghasilkan kepercayaan pipeline yang salah dan menghasilkan outreach yang terlewat ke peluang yang masih hidup.
Drift pengayaan. Data akurat ketika dimasukkan dan sejak itu menjadi salah melalui perubahan eksternal. Perusahaan pindah. Kontak berganti pekerjaan. Nomor telepon tidak aktif. Putaran pendanaan terjadi. Headcount berubah. CRM tidak tahu; hanya menyimpan apa yang dimasukkan. Seiring waktu, kesenjangan antara catatan CRM dan kebenaran aktual melebar.
Keempat jenis masalah menurunkan kualitas output AI dengan cara tertentu. Duplikat membingungkan model scoring dengan data sinyal yang terbagi. Kolom yang hilang mengurangi akurasi model dan menghasilkan catatan yang tidak terskor. Catatan basi mengembungkan angka pipeline dan mendistorsi perkiraan. Drift pengayaan menghasilkan outreach ke kontak yang salah dan kriteria kualifikasi yang salah.
Cara Workflow Copilot menangani hygiene
Pola Workflow Copilot dalam ACE Framework menggambarkan loop bantuan berkelanjutan: Ingest konteks saat ini, Analyze untuk mengidentifikasi apa yang perlu diperhatikan, Generate saran, Execute dengan persetujuan manusia (atau tindakan otomatis untuk kasus kepercayaan tinggi), kemudian ulangi.
Diterapkan pada CRM hygiene:
Ingest membaca status CRM saat ini. Semua catatan, semua log aktivitas, semua nilai kolom. Ini terjadi secara berkelanjutan (catatan baru memicu pemeriksaan segera) dan secara terjadwal batch (pemindaian database penuh setiap minggu).
Analyze mengidentifikasi masalah data di empat jenis masalah:
- Deteksi duplikat: mencocokkan nama perusahaan, domain, nomor telepon, dan kesamaan alamat
- Pemeriksaan kelengkapan: menilai setiap catatan terhadap definisi kolom yang diperlukan
- Penilaian kesegaran: menandai catatan tanpa aktivitas yang dicatat melewati ambang yang dapat dikonfigurasi
- Deteksi drift pengayaan: membandingkan data CRM dengan sumber data eksternal (database perusahaan, LinkedIn, pencarian domain)
Generate menghasilkan perbaikan yang disarankan untuk setiap masalah yang diidentifikasi:
- Untuk duplikat: rekomendasi merge yang menentukan catatan mana yang dijaga sebagai primer dan kolom mana yang diambil dari setiap catatan
- Untuk kolom yang hilang: nilai yang diisi otomatis dari sumber pengayaan, dengan skor kepercayaan
- Untuk catatan basi: perubahan status yang disarankan (tandai tidak aktif, kualifikasi ulang, arsip) dengan konteks
- Untuk drift: nilai kolom yang diperbarui dari pengayaan, dengan sumber yang jelas
Execute merutekan perbaikan yang disarankan melalui salah satu dari dua jalur, tergantung pada kepercayaan:
- Kepercayaan tinggi (di atas ambang): auto-execute perbaikan dan catat tindakan
- Di bawah ambang: antrean untuk tinjauan rep atau RevOps dengan perbaikan yang disarankan disajikan
Lapisan governance adalah yang memisahkan ini dari kekacauan. Eksekusi otomatis pada segalanya menghasilkan jenis masalah kualitas data yang berbeda: koreksi yang diterapkan dalam skala besar tanpa tinjauan dapat menyebarkan kesalahan sama efisiennya dengan memperbaikinya. Untuk prinsip governance yang lebih luas yang berlaku di seluruh sistem AI, AI sales ops governance dan audit trails mencakup framework secara rinci.
Data kontak B2B mengalami penurunan 2,1% per bulan, dan 30% dari semua catatan CRM menjadi usang setiap tahun. Kampanye pembersihan kuartalan berarti organisasi rata-rata beroperasi pada data yang menurun 5-7% untuk sebagian besar tahun.
Aturan Auto-Fix Ambang Kepercayaan
Aturan Auto-Fix Ambang Kepercayaan adalah prinsip governance yang menentukan koreksi CRM hygiene mana yang dieksekusi secara otomatis dan mana yang memerlukan tinjauan manusia. Ini memiliki tiga tingkatan: di atas 90% kepercayaan pada sumber pengayaan yang diketahui memicu auto-fix dengan entri log audit; antara 50-90% kepercayaan menghasilkan saran yang diantrikan untuk persetujuan RevOps atau rep; di bawah 50% kepercayaan menghasilkan tanda saja, tidak ada koreksi yang disarankan. Aturan ini mencegah dua mode kegagalan: kurang otomatisasi (backlog yang tidak diproses siapa pun) dan terlalu banyak otomatisasi (kesalahan yang percaya diri disebarkan dalam skala besar). Persentase ambang harus dikalibrasi secara kuartalan berdasarkan tinjauan audit sampel dari auto-koreksi.
Ambang auto-fix vs. tinjauan rep
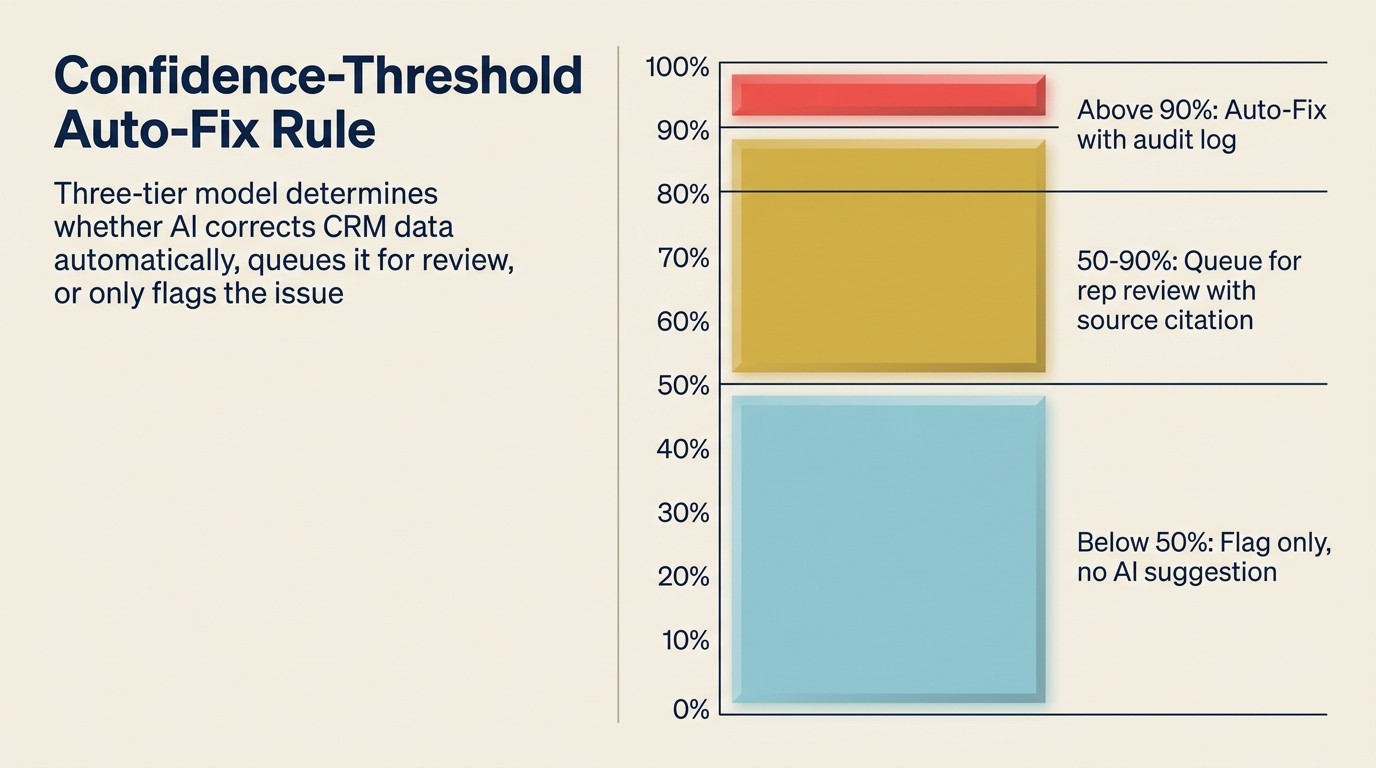
Model governance adalah keputusan desain paling penting dalam sistem AI CRM hygiene.
Apa yang di-auto-fix:
- Catatan duplikat exact-match (alamat email yang sama, domain yang sama, perusahaan yang sama dikonfirmasi) tanpa data kolom yang bertentangan: merge otomatis, catat merge
- Kolom yang hilang di mana kepercayaan sumber pengayaan tinggi (lebih dari 90%): isi secara otomatis
- Catatan tanpa aktivitas dan tanpa riwayat deal yang lebih tua dari 365 hari: auto-arsip dengan jendela pemulihan 30 hari
Apa yang diantrikan untuk tinjauan:
- Duplikat fuzzy-match (nama perusahaan yang sama, domain berbeda): sajikan saran merge, minta konfirmasi manusia
- Kolom yang hilang di mana kepercayaan pengayaan sedang (50% hingga 90%): sarankan pengisian dengan kutipan sumber, minta konfirmasi
- Deal aktif yang basi (tidak ada aktivitas dalam 90 hari, status deal masih terbuka): beri tahu pemilik deal, jangan auto-tutup
- Drift pengayaan pada kolom kunci seperti nama perusahaan atau kontak utama: tandai untuk tinjauan rep, jangan timpa secara diam-diam
Apa yang hanya ditandai:
- Potensi drift pengayaan dengan kepercayaan rendah: tampilkan sebagai "ini mungkin kedaluwarsa" tanpa menyarankan koreksi spesifik
- Catatan yang tampaknya memiliki data yang tidak cocok di seluruh kolom tanpa perbaikan yang jelas
Kalibrasi ambang memerlukan penyetelan berdasarkan lingkungan data Anda. Mulai konservatif (lebih banyak tinjauan, lebih sedikit otomatisasi) dan bergerak menuju otomatisasi seiring Anda membangun kepercayaan pada akurasi model untuk pola data spesifik Anda.
Cara berguna untuk memikirkannya: jika AI membuat kesalahan pada tingkat kepercayaan ini, seberapa buruk konsekuensinya? Untuk duplikat exact-match, biaya merge yang salah dapat dipulihkan. Untuk menimpa informasi kontak utama dengan data pengayaan yang salah, konsekuensinya adalah rep yang menelepon orang yang salah tentang deal yang masih berlangsung. Profil risiko yang berbeda memerlukan ambang yang berbeda.
Empat jenis masalah hygiene secara mendalam

Duplikat
Catatan duplikat adalah masalah data CRM yang paling umum dan paling menarik secara komputasional untuk dideteksi. Exact-match pada email atau domain mudah. Kasus yang sulit adalah:
- "Acme Corp" dan "Acme Corporation" (perusahaan yang sama, string nama berbeda)
- Dua catatan kontak untuk "John Smith" dengan nomor telepon yang sama tetapi perusahaan berbeda yang terdaftar (berganti pekerjaan, bukan orang berbeda)
- Perusahaan yang diakuisisi dan kini ada sebagai akun tersendiri dan sebagai anak perusahaan di bawah pengakuisisi
Deduplikasi AI menggunakan beberapa sinyal pencocokan: kesamaan string pada nama perusahaan, pencocokan domain, pencocokan alamat, pencocokan telepon, dan analisis grafik jaringan (kontak yang terhubung ke perusahaan yang sama melalui jalur berbeda). Menggabungkan sinyal menghasilkan skor kepercayaan untuk setiap potensi merge.
Keputusan operasional utama: apakah merge harus otomatis, atau apakah setiap merge memerlukan tinjauan manusia? Untuk organisasi bervolume tinggi yang menjalankan 50.000+ catatan, memerlukan tinjauan manusia pada setiap merge menciptakan backlog yang tidak akan diproses siapa pun. Tentukan ambang otomatisasi Anda dan audit sampel auto-merge setiap bulan untuk memeriksa akurasi.
Kelengkapan kolom
Definisi kolom yang diperlukan bervariasi berdasarkan organisasi. Tetapi standar minimum untuk AI-assisted sales operations mencakup: vertikal industri perusahaan, kisaran headcount perusahaan, tanggal pendanaan terakhir dan putaran, kontak utama dengan email yang terverifikasi, dan status sales-qualified lead.
AI mengisi kolom yang hilang dari sumber pengayaan: Clearbit, ZoomInfo, LinkedIn, Crunchbase, dan data situs web perusahaan. Kualitasnya bervariasi berdasarkan jenis kolom. Headcount perusahaan dan pendanaan umumnya dapat diandalkan. Klasifikasi industri bisa bergeser (beberapa penyedia pengayaan menggunakan sistem taksonomi yang berbeda). Data kontak individual menurun dengan cepat seiring orang berganti pekerjaan.
Lacak tingkat kelengkapan sebagai metrik RevOps yang berdiri. Target kelengkapan 90%+ pada kolom yang diperlukan untuk akun aktif. Penelitian MIT Sloan tentang kualitas data menemukan bahwa organisasi yang memperlakukan kualitas data sebagai proses berkelanjutan daripada proyek periodik melihat hasil tiga hingga empat kali lebih baik dari inisiatif berbasis data mereka. Ketika kelengkapan turun di bawah ambang, selidiki apakah masalahnya ada dalam alur kerja entri data (rep yang melewati kolom) atau dalam cakupan pengayaan (penyedia pengayaan Anda tidak memiliki data untuk perusahaan kecil di vertikal target Anda).
Catatan basi
Catatan basi dalam pipeline adalah masalah hygiene yang paling berbahaya karena menghasilkan kepercayaan pendapatan yang salah. Laporan pipeline yang menunjukkan $2,4M dalam deal terbuka menyesatkan jika $800K dari itu ada dalam deal yang tidak memiliki aktivitas selama 6 bulan.
Deteksi catatan basi AI menggunakan data timestamp aktivitas: email terakhir, panggilan terakhir, pertemuan terakhir, catatan CRM terakhir. Catatan yang melampaui ambang yang dapat dikonfigurasi (90 hari untuk deal tahap awal, 180 hari untuk tahap akhir) ditandai.
Tindakan yang tepat bergantung pada jenis catatan. Untuk deal terbuka: beri tahu pemilik deal untuk mencatat aktivitas atau menandai deal sebagai tidak aktif. Jangan auto-tutup deal aktif. Untuk kontak tanpa aktivitas: periksa apakah mereka masih bekerja di perusahaan sebelum memutuskan apa yang harus dilakukan. Untuk akun tanpa aktivitas: bedakan antara akun yang tidak dalam sequence aktif (oke) dan akun yang seharusnya dalam nurture sequence tetapi tidak.
Drift pengayaan
Ini adalah masalah yang paling tidak terlihat dan salah satu yang paling merusak. Data benar ketika dimasukkan. Realitas eksternal berubah. CRM tidak diperbarui.
Pergantian pekerjaan kontak adalah yang paling umum: champion yang telah Anda kembangkan meninggalkan perusahaan 3 bulan lalu dan rep Anda masih mengirim email ke alamat lama. Akuisisi perusahaan: akun yang Anda kejar dibeli dan kini menjadi anak perusahaan dengan proses pengadaan yang berbeda. Acara pendanaan: perusahaan baru saja mengumpulkan Series B, yang mengubah daya beli mereka dan mungkin garis waktu mereka untuk keputusan teknologi.
Deteksi drift AI membandingkan catatan CRM dengan sinyal eksternal: perubahan LinkedIn (perubahan jabatan atau perusahaan kontak), acara berita (pengumuman akuisisi, putaran pendanaan), perubahan situs web perusahaan. Ketika ketidakcocokan terdeteksi, ini muncul sebagai tanda daripada koreksi otomatis, karena konteks penting. "LinkedIn kontak ini sekarang menunjukkan perusahaan berbeda" adalah sinyal, bukan koreksi definitif.
Hygiene berkelanjutan vs. pembersihan kuartalan
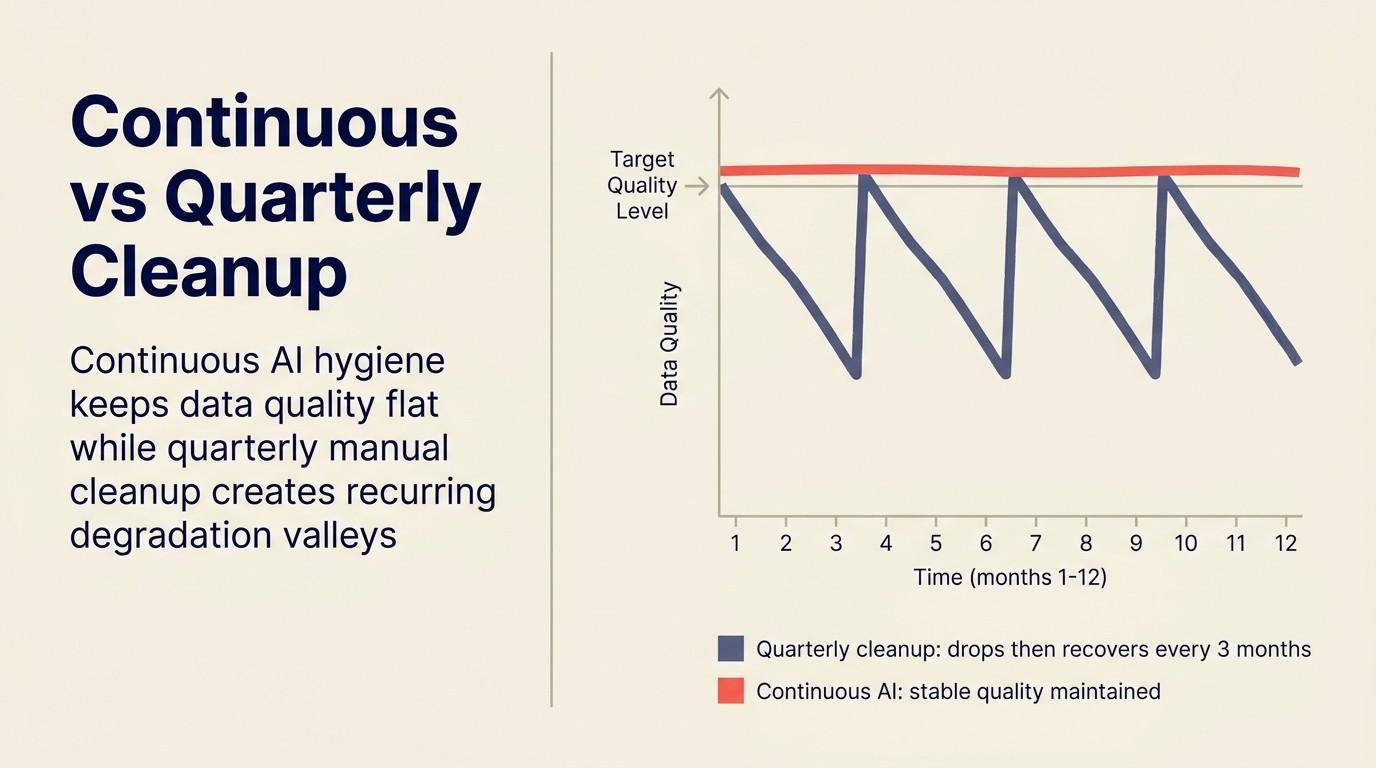
Sebagian besar organisasi mendekati CRM hygiene sebagai proyek: kampanye pembersihan kuartalan, biasanya dipicu oleh tinjauan perkiraan di mana angka terlihat salah atau audit di mana kualitas data tampak menurun.
Masalah dengan kampanye kuartalan adalah kurva degradasi data. Untuk organisasi dengan aliran deal aktif, berikut perkiraan kasar tentang seberapa cepat setiap jenis masalah terakumulasi:
- Duplikat baru: 5 hingga 15 per minggu dari acara impor, entri manual, dan integrasi sistem
- Kesenjangan kelengkapan kolom: setiap catatan baru yang dibuat tanpa proses intake yang lengkap
- Catatan basi: setiap deal yang terhenti, setiap kontak yang dingin
- Drift pengayaan: 2 hingga 3% dari catatan kontak aktif menjadi tidak akurat per bulan dari pergantian pekerjaan saja
Pada saat kampanye pembersihan kuartalan dijalankan, berbulan-bulan degradasi telah terakumulasi. Pembersihan adalah proyek yang lebih besar setiap kalinya. Dan tidak mencegah degradasi; hanya memulihkan ke baseline sebelum siklus pembusukan berikutnya.
Hygiene AI berkelanjutan mengubah ekonomi. Alih-alih mengoreksi batch bulan-bulan masalah yang terakumulasi, AI berjalan secara berkelanjutan dan menangkap masalah mendekati saat terjadinya. Beban kerja pemeliharaan per masalah lebih rendah. Lantai kualitas data lebih tinggi. Dan fungsi downstream berbantuan AI, scoring, routing, perkiraan, semuanya beroperasi pada data yang lebih bersih sepanjang kuartal, bukan hanya dalam dua minggu setelah proyek pembersihan.
Ketergantungan hulu: mengapa data bersih bukan hanya perhatian hygiene
Setiap fungsi AI dalam tumpukan sales Anda berada di hilir kualitas data CRM. Rantai ketergantungan ini menjadikan data hygiene investasi strategis, bukan hanya operasional.
AI Lead Scoring Beyond Rules-Based Models bergantung pada kelengkapan kolom CRM untuk input scoring. Data industri atau headcount yang hilang menghasilkan catatan yang tidak terskor atau terskor dengan buruk.
From Call to CRM Update Automatically menghasilkan data CRM yang lebih bersih sebagai output, tetapi bergantung pada catatan akun dan kontak yang terstruktur dengan benar untuk mengetahui ke mana harus menulis pembaruan.
Next Best Action for Each Open Deal menggunakan data tahap deal, tanggal aktivitas terakhir, dan kelengkapan kontak untuk menghasilkan rekomendasi. Data deal yang basi dan informasi kontak yang hilang secara langsung menurunkan kualitas rekomendasi.
Efek majemuk: masalah CRM hygiene tidak menghasilkan kesalahan yang terisolasi. Mereka menyebar. Catatan akun duplikat berarti sinyal scoring dibagi di antara dua catatan, mengurangi intent yang tampak untuk keduanya. Deal yang basi mengembungkan perkiraan pipeline, yang mengarah ke perencanaan sumber daya yang terlalu optimis. Kontak yang kedaluwarsa berarti outreach pergi ke orang yang salah, yang tidak menghasilkan respons, yang diinterpretasikan model AI scoring sebagai keterlibatan rendah, yang mengurangi skor prioritas akun.
Data yang bersih meningkatkan setiap output AI di hilir. Ini bukan tentang memiliki catatan yang rapi. Ini tentang kualitas setiap keputusan yang dihasilkan AI yang dibuat organisasi Anda dari catatan tersebut.
Alat implementasi
Rework CRM mencakup AI-assisted data hygiene sebagai bagian dari lapisan sales operations-nya. Deteksi duplikat, penyelesaian kolom dari sumber pengayaan, dan penandaan keusangan dibangun ke dalam alur kerja manajemen akun dan kontak. Model governance (auto-fix vs. antrean tinjauan) dapat dikonfigurasi berdasarkan jenis kolom dan ambang kepercayaan.
Manajemen duplikat Salesforce menyediakan aturan duplikat asli dan aturan pencocokan, dengan deteksi otomatis dan penggabungan. Alat pihak ketiga (Cloudingo, DemandTools) memperluas ini dengan logika pencocokan yang lebih canggih dan operasi batch. Pengayaan AI biasanya ditambahkan melalui integrasi dengan Clearbit atau ZoomInfo.
Alat kualitas data HubSpot mencakup manajemen duplikat untuk kontak dan perusahaan, dengan antrean tinjauan khusus. Pelaporan kesehatan data tingkat kolom menunjukkan tingkat kelengkapan di seluruh database. Pengayaan asli HubSpot (melalui fitur pengayaan datanya) mengisi kolom perusahaan dasar secara otomatis untuk catatan yang diidentifikasi.
Clay adalah opsi yang lebih dapat disusun untuk tim yang ingin membangun alur kerja pengayaan kustom. Hubungkan beberapa sumber data (Clearbit, Apollo, LinkedIn, data domain), tentukan waterfall pengayaan (coba sumber A, kembali ke sumber B), dan dorong data bersih kembali ke CRM Anda. Memerlukan lebih banyak setup daripada alat CRM asli tetapi menawarkan lebih banyak fleksibilitas untuk kasus penggunaan non-standar.
Kemampuan Analyze mencakup logika deteksi dan klasifikasi yang mendasari analisis hygiene. Artikel prasyarat kesiapan data menjelaskan mengapa data CRM yang bersih adalah persyaratan gating untuk setiap sistem AI dalam tumpukan Anda. 12 tindakan Gartner untuk meningkatkan kualitas data adalah sumber daya pendamping praktis untuk pemimpin RevOps yang membangun program kualitas data formal bersama tooling AI hygiene mereka.
Argumen infrastruktur
CRM hygiene adalah item baris yang paling tidak glamor dalam anggaran RevOps. Ini tidak secara langsung menghasilkan pendapatan, tidak menambahkan kemampuan baru, dan tidak menghasilkan metrik yang muncul dalam laporan dewan.
Tetapi ini adalah infrastruktur yang membuat segalanya akurat. Akurasi lead scoring, presisi routing, keandalan perkiraan pipeline, kualitas next-action rep: semuanya bergantung pada kualitas data.
Model hygiene berkelanjutan berbantuan AI mengubah persamaan sumber daya. Alih-alih satu proyek pembersihan besar per kuartal yang mengonsumsi 40 hingga 80 jam waktu RevOps, Anda memiliki sistem yang selalu aktif yang menangkap dan mengoreksi masalah di sumbernya. Total waktu manusia yang diperlukan lebih rendah. Kualitas data secara konsisten lebih tinggi.
Dan ketika Anda menambahkan kemampuan AI baru ke tumpukan sales Anda, Anda tidak mulai dari masalah data. Anda membangun di atas data yang bersih. Itulah pengembalian majemuk dari investasi infrastruktur.
Data hygiene bukan produk yang Anda beli sekali. Ini adalah proses yang Anda jalankan secara berkelanjutan. AI memungkinkan untuk menjalankan proses itu tanpa pertumbuhan headcount yang proporsional. Itulah argumen untuk itu. Dan itulah alasan mengapa setiap alat AI lain dalam tumpukan Anda bekerja lebih baik ketika Anda mendapatkan yang satu ini dengan benar.
Rework Analysis: Dalam deployment RevOps, keputusan kalibrasi awal yang paling penting adalah ambang auto-fix untuk merge duplikat. Menetapkannya terlalu rendah (auto-merging fuzzy-match di bawah 85% kepercayaan) menciptakan masalah kualitas data yang berbeda: perusahaan yang sah dengan nama serupa digabungkan secara salah, menghasilkan kontaminasi riwayat aktivitas yang lebih sulit untuk diurai daripada duplikat asli. Mulai pada 95% kepercayaan untuk auto-merge, verifikasi 50 auto-merge acak di bulan pertama, kemudian sesuaikan ambang berdasarkan tingkat kesalahan. Sebagian besar tim dapat beralih ke 90% setelah siklus kalibrasi pertama.
Organisasi dengan program AI data hygiene berkelanjutan mempertahankan kelengkapan kolom 90%+ pada kolom CRM yang diperlukan. Organisasi yang mengandalkan pembersihan manual kuartalan rata-rata kelengkapan 65-75%, dengan akurasi terendah dalam enam minggu sebelum setiap siklus pembersihan. (Penelitian kualitas data MIT Sloan)
Pertanyaan yang Sering Diajukan
Berapa banyak kualitas data CRM yang buruk sebenarnya merugikan?
Kualitas data yang buruk merugikan perusahaan B2B rata-rata $12,9 hingga $15 juta per tahun melalui pengeluaran pemasaran yang terbuang, peluang sales yang hilang, dan inefisiensi operasional, menurut perkiraan Gartner. Pada tingkat rep individual, sales rep membuang 27% waktu mereka menangani data yang buruk, dengan biaya sekitar $32.000 per rep per tahun. Biaya organisasi menguat karena setiap fungsi AI di hilir CRM (lead scoring, perkiraan pipeline, next-best-action) menghasilkan output yang dengan percaya diri salah dari input yang kotor.
Seberapa cepat data CRM mengalami penurunan?
Data kontak B2B mengalami penurunan sekitar 2,1% per bulan, yang berarti 22-30% dari semua catatan kontak menjadi tidak akurat dalam setahun tanpa hygiene aktif. Pergantian pekerjaan adalah pendorong utama: kontak berganti pemberi kerja, jabatan, dan alamat email secara berkelanjutan. Data tingkat perusahaan (firmografi, tahap pendanaan, tech stack) berubah lebih lambat tetapi sama berdampaknya ketika berubah, karena ini mempengaruhi input model scoring dan kriteria kualifikasi.
Apa itu Aturan Auto-Fix Ambang Kepercayaan?
Aturan Auto-Fix Ambang Kepercayaan adalah model governance tiga tingkat untuk koreksi CRM AI: di atas 90% kepercayaan pada sumber pengayaan yang diketahui memicu auto-koreksi dengan log audit; antara 50-90% kepercayaan mengantrekan saran untuk tinjauan manusia; di bawah 50% hanya menghasilkan tanda. Aturan ini mencegah kurang otomatisasi (backlog yang tidak diproses siapa pun) dan terlalu banyak otomatisasi (kesalahan yang percaya diri dalam skala besar). Ambang harus dikalibrasi secara kuartalan dengan meninjau sampel audit dari auto-koreksi. Sebagian besar tim mulai pada 95% untuk tingkat auto-fix dan beralih ke 90% setelah siklus kalibrasi pertama.
Empat jenis masalah data CRM apa yang ditangani AI hygiene?
AI CRM hygiene mengatasi duplikat (perusahaan atau kontak yang sama dalam beberapa catatan), kesenjangan kelengkapan kolom (kolom yang diperlukan kosong), catatan basi (deal terbuka atau kontak tanpa aktivitas selama 90-180+ hari), dan drift pengayaan (data yang akurat ketika dimasukkan tetapi sejak itu menjadi salah melalui perubahan eksternal). Setiap jenis masalah menurunkan fungsi AI downstream yang berbeda: duplikat membagi sinyal scoring, kolom yang hilang mengurangi akurasi model, catatan basi mengembungkan perkiraan pipeline, dan drift menghasilkan outreach ke kontak yang salah.
Mengapa pembersihan CRM kuartalan tidak cukup?
Pembersihan kuartalan memperlakukan kualitas data sebagai proyek daripada proses. Untuk organisasi dengan aliran deal aktif, duplikat baru terakumulasi 5-15 per minggu, kesenjangan kelengkapan kolom muncul dengan setiap catatan baru, deal basi terakumulasi secara konstan, dan 2,1% kontak menurun per bulan. Pada saat kampanye kuartalan dijalankan, berbulan-bulan degradasi telah terakumulasi. Hygiene AI berkelanjutan menangkap masalah mendekati saat terjadinya, mengurangi backlog dan konsekuensi kesalahan yang bertahan selama 90 hari sebelum koreksi.
Bagaimana kualitas data CRM mempengaruhi AI lead scoring?
Model AI lead scoring melatih dan berjalan terhadap data CRM. Kolom yang hilang (tidak ada vertikal industri, tidak ada headcount) menghasilkan catatan yang tidak terskor atau terskor tidak akurat. Catatan duplikat membagi sinyal intent di dua akun, membuat setiap tampak kurang terlibat dari yang sebenarnya. Data deal yang basi mendistorsi set pelatihan dengan menyertakan deal tidak aktif seolah-olah mereka adalah prospek yang masih berlangsung. Organisasi dengan tingkat kelengkapan CRM 90%+ melihat akurasi lead scoring yang lebih tinggi secara bermakna dibandingkan organisasi dengan kelengkapan 65-75%, karena model memiliki data sinyal yang lebih lengkap untuk digunakan.
Baca selanjutnya
- Workflow Copilot: AI as Peer-Level Assistant: pola ACE di balik bantuan AI berkelanjutan dalam alur kerja sales
- AI Lead Scoring Beyond Rules-Based Models: bagaimana kualitas data CRM secara langsung mempengaruhi akurasi model scoring
- Next Best Action for Each Open Deal: fungsi AI downstream yang paling bergantung pada data deal yang bersih
- AI Sales Ops Governance and Audit Trails: framework governance untuk operasi data otomatis

Co-Founder, Rework.com
On this page
- Apa artinya CRM data hygiene secara operasional
- Cara Workflow Copilot menangani hygiene
- Aturan Auto-Fix Ambang Kepercayaan
- Ambang auto-fix vs. tinjauan rep
- Empat jenis masalah hygiene secara mendalam
- Duplikat
- Kelengkapan kolom
- Catatan basi
- Drift pengayaan
- Hygiene berkelanjutan vs. pembersihan kuartalan
- Ketergantungan hulu: mengapa data bersih bukan hanya perhatian hygiene
- Alat implementasi
- Argumen infrastruktur
- Baca selanjutnya