Ticket-Deflection mit RAG im SaaS-Support
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Die Deflektionsrate ist die Kennzahl, die die meisten SaaS-Support-Teams bei der KI-Bewertung verfolgen. Sie ist auch die falsche Kennzahl, die man allein optimieren sollte.
Eine Deflektionsrate von 60 % klingt beeindruckend. Aber wenn 40 % dieser deflektierten Kunden eine falsche oder unvollständige Antwort erhalten haben, ihr Problem nicht gelöst haben und still ihre Produktnutzung reduzierten oder drei Tage später ein Ticket mit frustrierterem Ton öffneten, haben Sie Ihren Support-Betrieb nicht verbessert. Sie haben ein Problem hinter einer Kennzahl versteckt.
Das Ziel ist Deflection mit Zufriedenheit: Kunden, die genaue Antworten erhalten, ihr Problem lösen und kein Folge-Ticket öffnen müssen. Dieses Ziel erfordert einen anderen Design-Ansatz als die reine Deflektionsvolumen-Optimierung, und es beginnt damit, zu verstehen, wie Retrieval-Augmented Generation (RAG)-Deflection tatsächlich funktioniert.
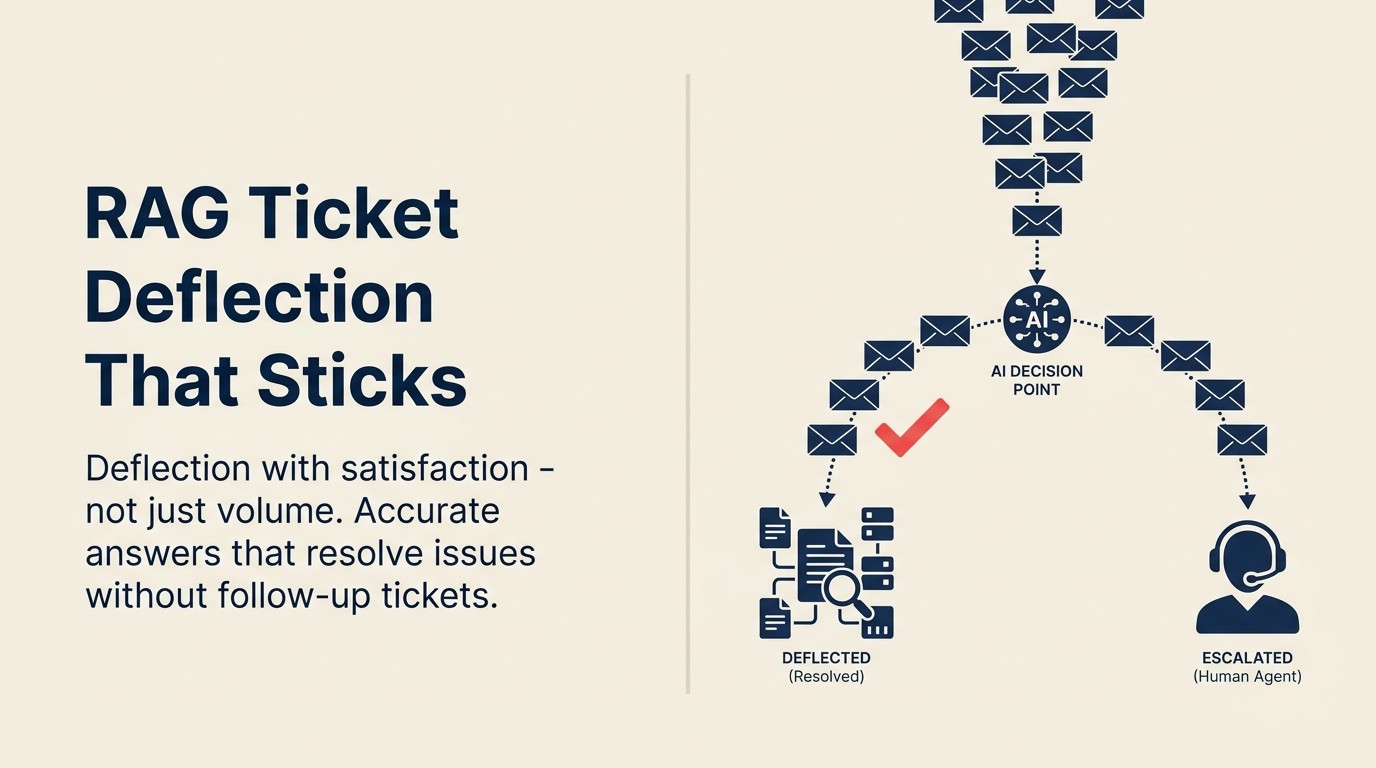
Wie RAG-Deflection funktioniert
Wenn ein Kunde eine Support-Nachricht einreicht, macht ein RAG-basiertes System Folgendes: Es nimmt die Frage, führt eine semantische Suche gegen den Wissensbasis-Corpus durch, ruft die relevantesten Dokumentationssegmente ab und generiert eine Antwort, die direkt aus diesem abgerufenen Inhalt schöpft. Die Antwort enthält Quellenlinks, damit der Kunde die Originaldokumentation lesen kann, wenn er mehr Details wünscht.
Der Abrufschritt ist das, was RAG von einem generischen Chatbot trennt. Ein generischer Chatbot generiert eine Antwort aus seinen Trainingsdaten. Er weiß vielleicht ungefähr, wie SaaS-Ticket-Systeme funktionieren, aber er kennt nicht Ihre spezifischen API-Fehlercodes, Ihr spezifisches Berechtigungsmodell oder die Workflow-Änderung, die Sie vor drei Wochen ausgeliefert haben. RAG ruft aus Ihrem tatsächlichen Inhalt ab, sodass die Antwort in der Wahrheit Ihres Produkts verankert ist, nicht in der Näherung des Modells. Das RAG Assistant Pattern erklärt die vollständige technische Architektur hinter diesem Abrufansatz.
Deshalb ist die Abrufqualität wichtiger als die Generierungsqualität für SaaS-Support. Eine leicht unbeholfene Antwort, die aus genauer, abgerufener Dokumentation generiert wurde, ist besser als eine polierte Antwort, die aus dem besten Versuch des Modells generiert wurde. Kunden wollen die richtige Antwort, nicht die flüssigste falsche.
Key Facts: RAG-Ticket-Deflection-Qualität
- RAG mit Knowledge Graphs erzielte eine 77,6-prozentige Verbesserung bei der Abrufgenauigkeit (gemessen am Mean Reciprocal Rank, einem Standard-Suchqualitätswert) und eine 28,6-prozentige Reduzierung der Lösungszeit beim Kundenservice-Team von LinkedIn (LinkedIn/MIT-Forschung, 2024)
- Heute werden nur 14 % der Kundenservice-Probleme vollständig im Self-Service gelöst, wobei 43 % der Kunden berichten, dass sie keine relevanten Self-Service-Inhalte finden können (Gartner, 2025)
- B2B-SaaS-Unternehmen, die KI-First-Support-Plattformen nutzen, verzeichnen 60 % höhere Ticket-Deflektionsraten im Vergleich zu traditioneller Help-Desk-Software, wobei die Leistungslücke fast vollständig durch die Qualität der Wissensbasis, nicht durch die KI-Modellqualität, erklärt wird (Pylon, 2025)
Das RAG Quality Gate
Das RAG Quality Gate ist eine dreistufige Bewertung, die vor jeder KI-Antwort an einen Kunden durchgeführt wird. Corpus-Qualitätsschwelle: Das abgerufene Dokument muss innerhalb eines definierten Aktualitätsfensters aktualisiert worden sein (empfohlen: 90 Tage für schnell ausliefernde SaaS-Produkte). Abruf-Konfidenz-Schwelle: Der semantische Ähnlichkeitswert zwischen der Frage des Kunden und dem abgerufenen Inhalt muss einen Mindestwert überschreiten, bevor eine Antwort generiert wird. Antwortpräzisions-Schwelle: Wenn der Abruf mehrere potenziell widersprüchliche Dokumente zurückgibt, markiert das System für menschliche Überprüfung, anstatt eine gemischte Antwort zu generieren, die halluzinieren könnte. Tickets, die eine Schwelle nicht erfüllen, werden mit dem Niedrig-Konfidenz-Signal an die menschliche Bearbeitung weitergeleitet.
Was in den RAG-Corpus gehört
Der Corpus ist alles, auf das die KI zugreifen kann. Für SaaS-Support umfasst ein gut gestalteter Corpus fünf Inhaltstypen.
Hilfedokumentation. Ihr primäres Help-Center: How-to-Leitfäden, Feature-Erklärungen, Troubleshooting-Walkthroughs, Integrations-Setup-Leitfäden. Das ist das Fundament. Es muss spezifisch sein (auf Artikelebene, nicht nur Kategorieebene), aktuell und konsistent genug organisiert, dass die semantische Suche zwischen einer Frage über Benutzerberechtigungen und einer Frage über API-Berechtigungen unterscheiden kann.
API- und Entwicklerdokumentation. Für entwicklerorientierte SaaS-Tools sind API-Docs, Webhook-Leitfäden, SDK-Referenzen und Fehlercode-Definitionen hochwertige Corpus-Inhalte. Entwickler-Tickets sind in der Regel präzise und technisch, und die Antworten sind meistens in der Dokumentation. Die Herausforderung ist, diese mit der Weiterentwicklung von APIs aktuell zu halten.
Produkt-Release-Notes. Das ist die am häufigsten vernachlässigte Corpus-Komponente. Jedes Feature-Release, jede API-Änderung und jeder Bug-Fix erzeugt neue Support-Fragen. Kunden, die letzte Woche ein Upgrade durchgeführt haben, fragen nach Verhalten, das sie vor dem Upgrade nicht gesehen haben. Wenn Release-Notes nicht im Corpus sind, beantwortet die KI mit veralteten Informationen.
Früher gelöste Tickets. Kategorisierte und anonymisierte gelöste Tickets sind hochwertige Corpus-Inhalte, besonders für Randfälle, die in den Hilfedokumentation nicht explizit abgedeckt sind. Wenn ein Kunde ein ungewöhnliches Fehlerverhalten beschreibt, kann ein gelöstes Ticket von einem früheren Kunden mit demselben Problem eine genauere Antwort liefern als ein Dokumentationsartikel, der nur den häufigen Fall abdeckt. Data readiness by pattern beschreibt, wie saubere, corpus-fähige Daten für RAG-Deployments tatsächlich aussehen.
FAQ und In-Produkt-Anleitungen. Kurzform-Antworten auf die häufigsten Fragen, Onboarding-Tipps und kontextuelle Anleitungen, die direkt aus dem Produkt verlinkt werden. Diese sind oft der semantisch ähnlichste Inhalt zu den Fragen, die Kunden tatsächlich stellen, was sie zu Hochabruf-Kandidaten macht.
Wissenslücken-Erkennung
Die wertvollste Ausgabe eines RAG-Support-Systems sind nicht die erfolgreichen Deflektionen. Es sind die Wissenslücken-Signale aus fehlgeschlagenen Abrufen. Forresters Analyse des Wissensmanagements im Kundenservice ergab, dass Organisationen mit reifen, gut strukturierten Wissensbasen deutlich höhere Lösungsraten und Kosteneinsparungen erzielen als solche, die Dokumentation als sekundäre Infrastruktur behandeln.
Wenn die KI versucht, relevante Inhalte für eine Frage abzurufen, und die am besten übereinstimmenden Dokumente niedrige Ähnlichkeitswerte haben, ist das ein Signal, dass der Corpus für diesen Fragetyp keine gute Abdeckung hat. Einige Systeme antworten trotzdem mit einer selbstsicheren Antwort (und nutzen das allgemeine Wissen des Modells, um die Lücke zu füllen). Bessere Systeme eskalieren das Ticket mit einem Flag, das ein Niedrig-Konfidenz-Abruf anzeigt.
Verfolgen Sie diese Niedrig-Konfidenz-Eskalationen als Dokumentationsrückstand. Jede steht für eine Frage, die Ihre Kunden stellen und die Ihre Dokumente nicht gut beantworten. Das zugrunde liegende menschliche Ticket zu lösen und dann einen Hilfeartikel aus dieser Lösung zu schreiben, ist der schnellste Weg, Ihre effektive Deflektionsabdeckung zu erweitern.
Intercom Fin verfolgt das über seine "Sources"-Funktion, die zeigt, welche Dokumente in KI-Antworten zitiert werden und welche Fragetypen Eskalationen ohne gute Quellübereinstimmungen generieren. Zendesk AI zeigt ähnliche Lückensignale durch seine Konversationsanalyse. Diese Lückenberichte, monatlich ausgeführt, werden zur Eingabe für Ihren Dokumentations-Sprint. Die Frage ist: Wie wissen Sie, wann die Deflektionsqualität tatsächlich funktioniert?
Messung der Deflektionsqualität
Deflektionsvolumen als einzelne Kennzahl ist irreführend. Sie brauchen vier Messungen zusammen.
Lösungsrate. Welcher Prozentsatz der KI-deflektierten Tickets schließt ohne eine Folgeinteraktion des Kunden? Ein deflektiertes Ticket, das sich innerhalb von 48 Stunden wieder öffnet, ist kein gelöstes Ticket. Verfolgen Sie die Wiederöffnungsrate als Qualitätssignal.
CSAT bei deflektierten Tickets. Wenn Kunden ihre Support-Erfahrung nach einer KI-Deflection bewerten, was sagen sie? Die meisten Plattformen ermöglichen es Ihnen, bei Ticket-Abschluss nach einem Daumen-hoch/Daumen-runter oder einer 1-5-Sterne-Bewertung zu fragen. CSAT bei KI-deflektierten Tickets im Vergleich zu menschlich bearbeiteten Tickets zeigt Ihnen, ob Kunden KI-Lösung zufriedenstellend oder nur minimal akzeptabel finden.
False-Deflection-Rate. Tickets, die von der KI als gelöst markiert wurden, bei denen der Kunde aber innerhalb von 7 Tagen ein neues Ticket zum gleichen Problem öffnete. Das ist das klarste Maß für schlechte Deflection: Die KI sagte, sie habe das Problem gelöst, aber das hat sie nicht. Hallucination risk by pattern erklärt die Bedingungen, unter denen selbst RAG-verankerte Systeme selbstsichere falsche Antworten produzieren.
Eskalationsrate nach KI-Versuch. Von den Tickets, bei denen die KI eine Antwort versucht hat, bevor ein Mensch eingeschritten ist, wie viele erforderten, dass der Mensch die KI-Antwort korrigiert oder vollständig ersetzt? Das misst, ob die KI menschlichen Agenten hilft oder mehr Arbeit für sie schafft.
Ein Support-Betrieb mit 40 % Deflektionsrate, 4,2/5 CSAT bei deflektierten Tickets, 8 % False-Deflection-Rate und 15 % Eskalationsrate nach KI-Versuch läuft gut. Ein Support-Betrieb mit 55 % Deflektionsrate, 3,1/5 CSAT, 22 % False-Deflection-Rate und 35 % Korrekturbedarf-Eskalationen ist es nicht. Höhere Deflektionsrate mit schlechteren Qualitätskennzahlen stellt eine netto negative Kundenerfahrung dar.
„Die Unternehmen, die nachhaltig 40-50 % Deflektionsrate mit hohem CSAT erreichen, nutzen keine bessere KI. Sie behandeln Dokumentation als Produkt-Asset mit der gleichen Sorgfalt, die sie auf das Produkt selbst anwenden. Die Wissensbasis-Aktualitäts-Verzögerung ist die richtige Kennzahl zum Verfolgen: das Durchschnittsalter von Artikeln relativ zur letzten Produktänderung, die sie abdecken." (Rework Analysis, 2025)
Deflektionsqualitäts-Benchmarks
| Kennzahl | Guter Schwellenwert | Warnsignal | Maßnahme erforderlich |
|---|---|---|---|
| Lösungsrate (kein Folge-Ticket innerhalb von 48h) | Über 85 % | 70-85 % | Häufige Wiederöffnungsthemen prüfen |
| CSAT bei deflektierten Tickets | 4,0/5 oder höher | 3,5-4,0/5 | Jüngste KI-Antworten auf Genauigkeit prüfen |
| False-Deflection-Rate (gleiches Problem, neues Ticket innerhalb von 7 Tagen) | Unter 8 % | 8-15 % | Fehlschlagende Dokumenttypen identifizieren |
| Eskalation mit KI-Korrektur-Rate | Unter 15 % | 15-25 % | KI-Antwortqualität nach Kategorie untersuchen |
Quellen: Zendesk CX Trends 2026, Intercom Fin Performance Data 2025, Gartner Customer Service AI Benchmark 2025
Das SaaS-Release-Kadenz-Problem
SaaS liefert schnell. Dokumentation hinkt hinterher. Das ist die häufigste Ursache für die Degradation der KI-Support-Qualität über die Zeit.
Wenn Sie ein neues Feature veröffentlichen, kennt die KI noch das alte Verhalten. Kunden, die das neue Feature nutzen, stellen Fragen zu Verhalten, das nicht existierte, als die Dokumente geschrieben wurden. Die KI ruft aus diesen alten Dokumenten ab und produziert eine Antwort, die vor drei Monaten richtig war und heute falsch ist.
Die Lösung ist, Ihren Dokumentationsaktualisierungsprozess in Ihren Release-Prozess einzubinden. Jedes Release sollte eine entsprechende Dokumentationsaufgabe haben: welche Hilfeartikel aktualisiert werden müssen, welche neuen Artikel erstellt werden müssen, welche API-Docs Versionshinweise benötigen. Das Release wird nicht ohne die Dokumentationsaufgaben in der Warteschlange ausgeliefert.
Für Release-Note-getriebene Fragen (Kunden fragen: "Hat sich das im letzten Release geändert?") werden die Release-Notes selbst zur primären Corpus-Quelle. Stellen Sie sicher, dass Release-Notes in einem Format veröffentlicht werden, aus dem das RAG-System abrufen kann, und nicht nur per E-Mail an Abonnenten gesendet und dann vergessen werden.
Einige Teams führen monatliche Corpus-Audits durch: Die 30 jüngsten erfolgreichen KI-Deflektionen herausziehen und die Quelldokumente überprüfen. Sind sie noch genau? Haben sich die darin beschriebenen Features verändert? Diese 2-stündige monatliche Übung verhindert ein langsames Abdriften hin zu selbstsicheren falschen Antworten.
Mehrsprachiger Support
B2B-SaaS-Unternehmen mit globaler Kundenbasis stehen vor einer mehrsprachigen Deflektionsherausforderung. Ihre Dokumente sind möglicherweise hauptsächlich auf Englisch. Ihre Kunden stellen möglicherweise Fragen auf Deutsch, Spanisch oder Japanisch.
Intercom Fin und Zendesk AI unterstützen beide mehrsprachigen Abruf, entweder durch mehrsprachige semantische Suche (Finden relevanter englischer Dokumente als Antwort auf eine in einer anderen Sprache gestellte Frage) oder durch direkten Abruf aus übersetzter Dokumentation, wenn diese existiert.
Der Qualitätsunterschied ist erheblich. Ein Kunde, der eine Frage auf Spanisch stellt und eine Antwort erhält, die aus englischen Dokumenten maschinell in Echtzeit übersetzt wurde, hat eine andere Erfahrung als ein Kunde, dessen Frage aus einem übersetzten Hilfeartikel mit der korrekten Terminologie für seine Sprache und Region beantwortet wird.
Für Kundensprachen mit hohem Volumen übersetzen Sie zunächst die Top-50-Hilfeartikel. Das deckt die meisten deflektierbaren Fragetypen mit muttersprachlichen Quellinhalten ab, und die Qualitätsverbesserung bei deflektierten Tickets ist sofort spürbar.
Segmentspezifische Corpora
Enterprise-Kunden und SMB-Kunden stellen unterschiedliche Fragen. Ein Enterprise-Kunde, der nach der Benutzerbereitstellung über SCIM fragt, stellt eine andere Frage als ein SMB-Kunde, der fragt, wie er ein neues Teammitglied hinzufügt.
Wenn Ihre Kundenbasis unterschiedliche Segmente mit bedeutend unterschiedlichen Support-Anforderungen hat, sollten Sie segmentbewussten Abruf in Betracht ziehen. Zendesk AI unterstützt das durch Kunden-Tagging, das beeinflusst, welcher Corpus zuerst durchsucht wird. Intercom Fin nutzt Konversations-Routing-Logik, die den Abruf zugunsten segmentspezifischer Dokumentation ausrichten kann.
Die praktische Umsetzung: Markieren Sie Ihre Hilfeartikel nach Kunden-Tier (SMB, Mid-Market, Enterprise) und leiten Sie eingehende Tickets mit Enterprise-Kunden-Tags zuerst zu Enterprise-Tier-Dokumentation weiter. Ein generischer Hilfeartikel über Benutzerverwaltung ist für SMB-Fragen in Ordnung. Ein Enterprise-Kunde, der nach SCIM-Bereitstellung fragt, sollte aus Ihrer Enterprise-Integrationsdokumentation abrufen, nicht aus Ihrem allgemeinen "Wie füge ich einen Benutzer hinzu"-Leitfaden.
Kontinuierlicher Verbesserungskreislauf
Ticket-Deflection mit RAG ist kein Deploy-and-Forget-System. Es verbessert sich kontinuierlich mit gezielten Investitionen.
Der Verbesserungskreislauf läuft auf einem monatlichen Zyklus. Ziehen Sie die Wissenslücken-Signale des vergangenen Monats heraus: Welche Ticket-Typen generierten Niedrig-Konfidenz-Abrufe, welche Fragen hatten hohe False-Deflection-Raten, welche Produktbereiche sahen die meisten Eskalationen nach KI-Versuchen? Wandeln Sie diese in Dokumentationsaufgaben um. Schreiben Sie die Artikel, aktualisieren Sie die veralteten, fügen Sie die Release-Notes hinzu, die nicht im Corpus waren.
Verfolgen Sie die Deflektionsqualität monatlich. Wenn der CSAT bei deflektierten Tickets steigt, funktioniert der Verbesserungskreislauf. Wenn er stagniert oder sinkt, hinkt die Dokumentation hinter Ihren Produktänderungen her.
Die Unternehmen, die nachhaltig 40-50 % Deflektionsrate mit hohem CSAT erreichen, nutzen keine bessere KI. Sie behandeln Dokumentation als Produkt-Asset mit derselben Sorgfalt, die sie auf ihr Produkt selbst anwenden. Gartner prognostiziert, dass Agentic AI bis 2029 80 % der häufigen Kundenservice-Probleme autonom ohne menschliche Intervention lösen wird, und die Organisationen, die am besten positioniert sind, diese Obergrenze zu erreichen, sind diejenigen, die jetzt Dokumentationsdisziplin aufbauen. Der Dokumentations-Sprint steht auf der Roadmap. Das Corpus-Audit steht im Support-Ops-Kalender. Wissenslückenberichte gehen an das Dokumentationsteam, nicht nur an das Support-Team. Product telemetry advantage in SaaS AI erklärt, wie In-Produkt-Nutzungsdaten Ihren Support-Corpus speisen und Fragen aufdecken können, bevor Kunden sie überhaupt stellen.
AI Support Agent for SaaS Self-Service behandelt die vollständige Tier-Struktur: wie RAG-Deflection mit Human-Agent-Assist und Spezialisten-Eskalation als vollständiges Support-System zusammenhängt.
AI Knowledge Base Maintenance for SaaS Docs geht tiefer auf den Dokumentations-Lebenszyklus ein: wie man Abdeckung prüft, Dokumente mit Releases aktuell hält und KI selbst nutzt, um den Corpus zu pflegen.
Multi-Tier AI Routing in SaaS Help Desk behandelt, was nach RAG-Deflection-Versuchen passiert: wie Tickets, die menschliche Bearbeitung benötigen, ohne manuelle Triage an den richtigen Agenten weitergeleitet werden.
Die Support-Teams, die mit RAG gewinnen, sind diejenigen, die die Deflektionsqualität neben dem Deflektionsvolumen verfolgen. Zufriedene Kunden, die sich selbst geholfen haben, ist das Ziel. Kunden, die still aufgegeben haben und gegangen sind, ist es nicht. Gestalten Sie von Anfang an für Ersteres.
Rework Analysis: Die False-Deflection-Rate ist die am meisten vernachlässigte Kennzahl im SaaS-Support-KI-Bereich. Teams optimieren für rohes Deflektionsvolumen, feiern eine 50-prozentige Deflektionsrate und verpassen, dass 18 % dieser "deflektierten" Kunden innerhalb von 7 Tagen ein neues Ticket zum gleichen Problem mit zusätzlicher Frustration geöffnet haben. Die reale Deflektionsrate ist nicht das, was das System berichtet. Sie ist das, was 7 Tage später passiert. Teams, die die 7-Tage-Wiederöffnungsrate neben dem Deflektionsvolumen verfolgen, stellen fest, dass ihre effektive Deflektionsrate typischerweise 10-15 Prozentpunkte unter der Kopfzahl liegt, und das ist die Zahl, die es zu optimieren gilt.
Häufig gestellte Fragen
Was ist der Unterschied zwischen Deflektionsrate und Lösungsrate im RAG-Support?
Die Deflektionsrate misst, wie viele Tickets die KI ohne Eskalation an einen Menschen bearbeitet. Die Lösungsrate misst, wie viele dieser KI-bearbeiteten Tickets tatsächlich gelöst wurden, d.h. der Kunde hat eine genaue Antwort erhalten und das Problem nicht wieder geöffnet. Eine 60-prozentige Deflektionsrate, bei der 20 % der Kunden dasselbe Ticket innerhalb von 7 Tagen wieder öffnen, entspricht einer tatsächlichen Lösungsrate von etwa 48 %. Die Optimierung für die Lösungsrate statt für die Deflektionsrate führt zu einer besseren Kundenerfahrung und einem höheren CSAT.
Was sollte in einen RAG-Corpus für SaaS-Support einfließen?
Fünf Inhaltstypen: Hilfedokumentation, API- und Entwicklerdokumente, Produkt-Release-Notes, anonymisierte gelöste Tickets sowie FAQ oder In-Produkt-Anleitungen. Release-Notes werden am häufigsten vernachlässigt. Jedes Feature-Release erzeugt neue Fragen, und wenn Release-Notes im Corpus fehlen, beantwortet die KI mit veralteten Informationen. Ein praktisches Dokumentations-Bereitschaftsziel: Die Top-50-Ticket-Typen sollten dedizierte, spezifische Hilfeartikel haben, die innerhalb der letzten 90 Tage aktualisiert wurden.
Wie erkennt man, wenn die RAG-Deflektionsqualität sinkt?
Drei Signale weisen auf eine Verschlechterung hin. Erstens: Der CSAT bei deflektierten Tickets fällt in einem rollierenden 30-Tage-Zeitraum unter 3,8/5. Zweitens: Die False-Deflection-Rate (gleiches Problem, neues Ticket innerhalb von 7 Tagen) steigt über 10 %. Drittens: Die KI-Korrekturrate bei Eskalationen (menschlicher Agent muss die KI-Antwort korrigieren oder ersetzen) steigt über 20 %. Jedes dieser Signale löst ein Dokumentations-Audit für die betroffenen Ticket-Kategorien aus.
Wie wirkt sich die SaaS-Auslieferungskadenz auf die RAG-Genauigkeit über die Zeit aus?
SaaS liefert kontinuierlich. Wenn sich ein Feature ändert, bleibt die Dokumentation, die sein altes Verhalten beschreibt, im Corpus und wird als Abrufergebnis für neue Fragen zurückgegeben. Die KI generiert selbstsichere Antworten auf Basis veralteter Quellmaterialien. Die Lösung ist, Dokumentationsaktualisierungen in den Release-Prozess einzubinden. Jedes Release sollte eine Dokumentationsaufgabe erzeugen: welche Artikel aktualisiert werden müssen, welche neuen Artikel erstellt werden müssen. Das Release wird nicht ohne eingereihte Dokumentationsaufgaben ausgeliefert.
Was ist Wissenslücken-Erkennung im RAG-Support?
Wissenslücken-Erkennung ist die Nutzung von Niedrig-Konfidenz-Abruf-Signalen zur Identifizierung nicht vorhandener Dokumentation. Wenn die KI einen Abruf versucht und die am besten übereinstimmenden Dokumente niedrige Ähnlichkeitswerte haben, wird der Ticket-Typ als Lücke protokolliert. Diese Lückenprotokolle, monatlich überprüft, werden zum Dokumentationsrückstand. Jede Lücke steht für eine Kundenfrage, die Ihre Dokumente nicht gut beantworten. Das menschliche Ticket zu lösen und daraus einen Hilfeartikel zu schreiben ist der schnellste Weg, die Deflektionsabdeckung zu erweitern.
Weiterführende Links:
- RAG Assistant Pattern: vollständige technische Architektur für Retrieval-Augmented Support-KI
- Hallucination Risk by Pattern: wo RAG-verankerte KI noch scheitert und wie Eskalationsschwellen kalibriert werden
- Data Readiness by Pattern: wie saubere, corpus-fähige Daten für RAG-Deployments aussehen
- AI Support Agent for SaaS Self-Service: die vollständige Tier-Struktur für SaaS-Support-KI
- Multi-Tier AI Routing in SaaS Help Desk: intelligentes Routing nach Deflektionsversuchen
- AI Knowledge Base Maintenance for SaaS Docs: den Corpus mit dem Produkt aktuell halten

Co-Founder, Rework.com