Deflección de Tickets con RAG en Soporte SaaS
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
La tasa de deflección es la métrica que la mayoría de los equipos de soporte SaaS monitorean cuando evalúan la IA. También es la métrica equivocada para optimizar por sí sola.
Una tasa de deflección del 60% suena impresionante. Pero si el 40% de esos clientes deflectados recibieron una respuesta incorrecta o incompleta, se rindieron sin resolver su problema, y silenciosamente redujeron su uso del producto o abrieron un ticket tres días después con un tono más frustrado, no ha mejorado su operación de soporte. Ha ocultado un problema detrás de una métrica.
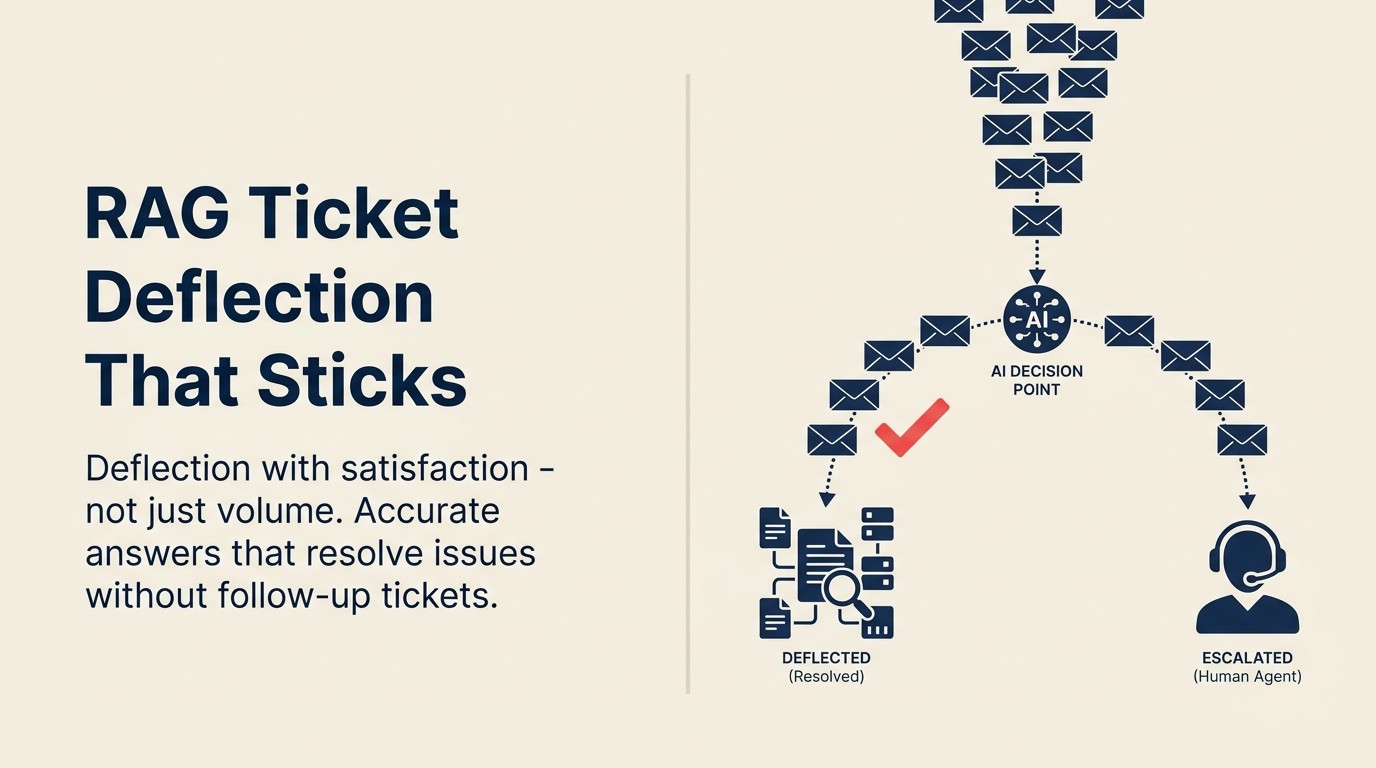
El objetivo es la deflección con satisfacción: clientes que obtienen respuestas precisas, resuelven su problema y no necesitan abrir un ticket de seguimiento. Ese objetivo requiere un enfoque de diseño diferente al de la optimización de volumen de deflección puro, y comienza con entender cómo funciona realmente la deflección con Generación Aumentada por Recuperación (RAG).
Cómo Funciona la Deflección con RAG
Cuando un cliente envía un mensaje de soporte, un sistema basado en RAG hace lo siguiente: toma la pregunta, ejecuta una búsqueda semántica contra el corpus de la knowledge base, recupera los fragmentos de documentación más relevantes y genera una respuesta que se basa directamente en ese contenido recuperado. La respuesta incluye enlaces a las fuentes para que el cliente pueda leer la documentación original si desea más detalles.
El paso de recuperación es lo que separa RAG de un chatbot genérico. Un chatbot genérico genera una respuesta a partir de sus datos de entrenamiento. Puede saber aproximadamente cómo funcionan los sistemas de tickets SaaS, pero no conoce sus códigos de error específicos de la API, su modelo de permisos específico, ni el cambio de workflow que lanzó hace tres semanas. RAG recupera de su contenido real, por lo que la respuesta está anclada en la verdad de su producto, no en la aproximación del modelo. El Patrón RAG Assistant explica la arquitectura técnica completa detrás de este enfoque de recuperación.
Por eso la calidad de la recuperación importa más que la calidad de la generación en el soporte SaaS. Una respuesta ligeramente imperfecta generada a partir de documentación recuperada precisa es mejor que una respuesta pulida generada a partir de la mejor suposición del modelo. Los clientes quieren la respuesta correcta, no la incorrecta más elocuente.
Key Facts: Calidad de Deflección de Tickets con RAG
- RAG con grafos de conocimiento logró una mejora del 77.6% en la precisión de recuperación (medida por rango recíproco medio, una puntuación estándar de calidad de búsqueda) y una reducción del 28.6% en el tiempo de resolución en el equipo de servicio al cliente de LinkedIn (investigación LinkedIn/MIT, 2024)
- Solo el 14% de los problemas de servicio al cliente se resuelven completamente en autoservicio hoy en día, con el 43% de los clientes reportando que no pueden encontrar contenido de autoservicio relevante (Gartner, 2025)
- Las empresas SaaS B2B que usan plataformas de soporte con IA primero ven un 60% más de deflección de tickets comparado con el software tradicional de help desk, con la brecha de rendimiento explicada casi en su totalidad por la calidad de la knowledge base, no por la calidad del modelo de IA (Pylon, 2025)
El RAG Quality Gate
El RAG Quality Gate es una evaluación de tres umbrales que se ejecuta antes de que cada respuesta de IA se entregue al cliente. Umbral de calidad del corpus: el documento recuperado debe haber sido actualizado dentro de una ventana de frescura definida (recomendado: 90 días para SaaS con lanzamientos rápidos). Umbral de confianza de recuperación: la puntuación de similitud semántica entre la pregunta del cliente y el contenido recuperado debe superar un valor mínimo antes de generar una respuesta. Umbral de precisión de respuesta: si la recuperación devuelve múltiples documentos potencialmente contradictorios, el sistema marca para revisión humana en lugar de generar una respuesta combinada que pueda alucinar. Los tickets que no superan ningún umbral se enrutan a gestión humana con la señal de baja confianza adjunta.
Qué va en el Corpus RAG
El corpus es todo a lo que la IA tiene acceso para recuperar. Para el soporte SaaS, un corpus bien diseñado incluye cinco tipos de contenido.
Documentación de ayuda. Su centro de ayuda principal: guías paso a paso, explicaciones de funcionalidades, guías de solución de problemas, guías de configuración de integraciones. Esta es la base. Necesita ser específica (a nivel de artículo, no solo a nivel de categoría), actualizada y organizada de manera suficientemente consistente para que la búsqueda semántica pueda distinguir entre una pregunta sobre permisos de usuario y una pregunta sobre permisos de API.
Documentación de API y desarrolladores. Para herramientas SaaS orientadas a desarrolladores, los docs de API, guías de webhooks, referencias de SDK y definiciones de códigos de error son contenido de corpus de alto valor. Los tickets de desarrolladores tienden a ser precisos y técnicos, y las respuestas generalmente están en la documentación. El desafío es mantenerlos actualizados a medida que las APIs evolucionan.
Notas de lanzamiento del producto. Este es el componente del corpus más frecuentemente descuidado. Cada lanzamiento de funcionalidad, cambio de API y corrección de errores genera nuevas preguntas de soporte. Los clientes que actualizaron la semana pasada preguntan sobre comportamientos que no existían antes de la actualización. Si las notas de lanzamiento no están en el corpus, la IA responde con información desactualizada.
Tickets resueltos anteriores. Los tickets resueltos categorizados y anonimizados son contenido de corpus de alta señal, especialmente para casos límite que no están explícitamente cubiertos en los docs de ayuda. Cuando un cliente describe un comportamiento de error inusual, un ticket resuelto de un cliente anterior con el mismo problema puede producir una respuesta más precisa que un artículo de documentación que solo cubre el caso común. Preparación de datos por patrón cubre cómo son realmente los datos limpios y listos para el corpus en despliegues de RAG.
Preguntas frecuentes y guías dentro del producto. Respuestas cortas a las preguntas más comunes, consejos de onboarding y guías contextuales vinculadas desde dentro del producto. Estos son frecuentemente el contenido más semánticamente similar a las preguntas que los clientes realmente hacen, lo que los convierte en candidatos de alta recuperación.
Detección de Brechas de Conocimiento
El output más valioso de un sistema de soporte con RAG no son las deflecciones exitosas. Son las señales de brechas de conocimiento de las recuperaciones fallidas. El análisis de Forrester sobre gestión del conocimiento en servicio al cliente encontró que las organizaciones con knowledge bases maduras y bien estructuradas logran tasas de resolución y ahorros de costos sustancialmente más altos que las que tratan la documentación como infraestructura secundaria.
Cuando la IA intenta recuperar contenido relevante para una pregunta y los documentos con mejor coincidencia tienen puntuaciones de similitud bajas, eso es una señal de que el corpus no tiene buena cobertura para ese tipo de pregunta. Algunos sistemas responderán con una respuesta segura de todos modos (usando el conocimiento general del modelo para llenar el vacío). Los mejores sistemas escalarán el ticket con una señal indicando recuperación de baja confianza.
Monitoree esas escaladas de baja confianza como un backlog de documentación. Cada una representa una pregunta que sus clientes hacen y que sus docs no responden bien. Resolver el ticket humano subyacente y luego escribir un artículo de ayuda a partir de esa resolución es la forma más rápida de expandir su cobertura efectiva de deflección.
Intercom Fin monitorea esto a través de su función "Sources", que muestra qué docs se están citando en las respuestas de IA y qué tipos de preguntas están generando escaladas sin buenas coincidencias de fuente. Zendesk AI expone señales de brechas similares a través de sus análisis de conversaciones. Estos informes de brechas, ejecutados mensualmente, se convierten en el input para su sprint de documentación. La pregunta es: ¿cómo sabe cuándo la calidad de la deflección realmente está funcionando?
Medición de la Calidad de la Deflección
El volumen de deflección como métrica única es engañoso. Necesita cuatro mediciones juntas.
Tasa de resolución. ¿Qué porcentaje de los tickets deflectados por IA se cierran sin una interacción de seguimiento del cliente? Un ticket deflectado que se vuelve a abrir dentro de las 48 horas no es un ticket resuelto. Monitoree la tasa de reapertura como señal de calidad.
CSAT en tickets deflectados. Cuando los clientes califican su experiencia de soporte después de una deflección por IA, ¿qué dicen? La mayoría de las plataformas permiten solicitar una calificación de aprobado/rechazado o de 1-5 estrellas al cerrar el ticket. El CSAT en tickets deflectados por IA versus tickets manejados por humanos le indica si los clientes encuentran la resolución por IA satisfactoria o simplemente mínimamente aceptable.
Tasa de falsa deflección. Tickets que fueron marcados como resueltos por la IA pero donde el cliente abrió un nuevo ticket dentro de los 7 días describiendo el mismo problema. Esta es la medida más clara de mala deflección: la IA dijo que resolvió el problema, pero no lo hizo. El riesgo de alucinación por patrón explica las condiciones bajo las cuales incluso los sistemas anclados en RAG producen respuestas incorrectas con confianza.
Tasa de escalada después del intento de IA. De los tickets donde la IA intentó una respuesta antes de que un humano la tomara, ¿en cuántos el humano tuvo que corregir o reemplazar completamente la respuesta de la IA? Esto mide si la IA está ayudando a los agentes humanos o creándoles más trabajo.
Una operación de soporte con un 40% de deflección, CSAT de 4.2/5 en tickets deflectados, tasa de falsa deflección del 8% y tasa de escalada después del intento de IA del 15% tiene un buen rendimiento. Una operación de soporte con un 55% de deflección, CSAT de 3.1/5, tasa de falsa deflección del 22% y escaladas que requieren corrección del 35% no lo tiene. Una deflección más alta con métricas de calidad peores representa una experiencia de cliente neta negativa.
"Las empresas que logran una deflección sostenida del 40-50% con alto CSAT no están usando mejor IA. Tratan la documentación como un activo de producto con el mismo rigor que aplican al producto en sí. El retraso en la frescura de la knowledge base es la métrica correcta a monitorear: la antigüedad promedio de los artículos en relación con el último cambio del producto que cubren." (Rework Analysis, 2025)
Benchmarks de Calidad de Deflección
| Métrica | Umbral Bueno | Señal de Advertencia | Acción Requerida |
|---|---|---|---|
| Tasa de resolución (sin seguimiento en 48h) | Por encima del 85% | 70-85% | Revisar los temas de reapertura más comunes |
| CSAT en tickets deflectados | 4.0/5 o superior | 3.5-4.0/5 | Auditar las respuestas de IA recientes en busca de precisión |
| Tasa de falsa deflección (mismo problema, nuevo ticket en 7 días) | Por debajo del 8% | 8-15% | Identificar los tipos de documentos que fallan |
| Tasa de escalada con corrección de IA | Por debajo del 15% | 15-25% | Investigar la calidad de las respuestas de IA por categoría |
Fuentes: Zendesk CX Trends 2026, Intercom Fin Performance Data 2025, Gartner Customer Service AI Benchmark 2025
El Problema del Ritmo de Lanzamientos SaaS
SaaS lanza rápido. La documentación se retrasa. Esta es la causa más común de degradación de la calidad del soporte IA con el tiempo.
Cuando se lanza una nueva funcionalidad, la IA todavía conoce el comportamiento anterior. Los clientes que usan la nueva funcionalidad hacen preguntas sobre comportamientos que no existían cuando se escribieron los docs. La IA recupera de esos docs antiguos y produce una respuesta que era correcta hace tres meses y es incorrecta hoy.
La solución es conectar su proceso de actualización de documentación a su proceso de lanzamiento. Cada lanzamiento debe tener una tarea de documentación correspondiente: qué artículos de ayuda necesitan actualizarse, qué artículos nuevos necesitan crearse, qué docs de API necesitan notas de versión añadidas. El lanzamiento no se publica sin que las tareas de documentación estén en cola.
Para las preguntas basadas en notas de lanzamiento (clientes que preguntan "¿cambió esto en el último lanzamiento?"), las notas de lanzamiento mismas se convierten en la fuente principal del corpus. Asegúrese de que las notas de lanzamiento se publiquen en un formato del que el sistema RAG pueda recuperar, no solo enviadas por correo a los suscriptores y luego olvidadas.
Algunos equipos ejecutan una auditoría mensual del corpus: extraen las 30 deflecciones de IA exitosas más recientes y revisan los documentos fuente. ¿Siguen siendo precisos? ¿Ha cambiado alguna de las funcionalidades que describen? Este ejercicio mensual de 2 horas previene una deriva lenta hacia respuestas incorrectas con confianza.
Soporte Multi-idioma
Las empresas SaaS B2B con bases de clientes globales enfrentan un desafío de deflección multilingüe. Sus docs pueden estar principalmente en inglés. Sus clientes pueden estar haciendo preguntas en alemán, español o japonés.
Intercom Fin y Zendesk AI manejan la recuperación en varios idiomas, ya sea mediante búsqueda semántica multilingüe (encontrando docs relevantes en inglés en respuesta a una pregunta formulada en otro idioma) o mediante recuperación directa de documentación traducida cuando existe.
La diferencia de calidad es significativa. Un cliente que hace una pregunta en español y recibe una respuesta generada a partir de docs en inglés traducida automáticamente en tiempo real tendrá una experiencia diferente a la de un cliente cuya pregunta se responde a partir de un artículo de ayuda traducido con la terminología correcta para su idioma y región.
Para los idiomas de clientes de alto volumen, traduzca primero los 50 artículos de ayuda principales. Eso cubre la mayoría de los tipos de preguntas deflectables con contenido fuente en idioma nativo, y la mejora de calidad en los tickets deflectados es inmediata.
Corpus Específicos por Segmento
Los clientes empresariales y los clientes de pequeñas empresas hacen preguntas diferentes. Un cliente empresarial que pregunta sobre el aprovisionamiento de usuarios a través de SCIM está haciendo una pregunta diferente a la de un cliente de pequeña empresa que pregunta cómo agregar un nuevo miembro del equipo.
Cuando su base de clientes tiene segmentos distintos con necesidades de soporte significativamente diferentes, considere la recuperación con conciencia de segmento. Zendesk AI soporta esto a través del etiquetado de clientes que influye en qué corpus se busca primero. Intercom Fin usa lógica de enrutamiento de conversaciones que puede sesgar la recuperación hacia la documentación específica del segmento.
La implementación práctica: etiquete sus artículos de ayuda por nivel de cliente (pequeña empresa, mercado medio, empresa) y enrute los tickets entrantes con etiquetas de cliente empresarial hacia la documentación de nivel empresarial primero. Un artículo genérico de ayuda sobre gestión de usuarios está bien para las preguntas de pequeñas empresas. Un cliente empresarial que pregunta sobre el aprovisionamiento SCIM debería recuperar de su documentación de integración empresarial, no de su guía general de "cómo agregar un usuario".
Ciclo de Mejora Continua
La deflección de tickets con RAG no es un sistema de instalar y olvidar. Mejora continuamente con inversión deliberada.
El ciclo de mejora funciona en un ciclo mensual. Extraiga las señales de brechas de conocimiento del mes anterior: qué tipos de tickets generaron recuperaciones de baja confianza, qué preguntas tuvieron altas tasas de falsa deflección, qué áreas del producto vieron más escaladas después de intentos de IA. Convierta esos en tareas de documentación. Escriba los artículos, actualice los desactualizados, agregue las notas de lanzamiento que no estaban en el corpus.
Monitoree la calidad de la deflección mes a mes. Si el CSAT en tickets deflectados está subiendo, el ciclo de mejora está funcionando. Si está estancado o bajando, la documentación está rezagándose frente a los cambios de su producto.
Las empresas que logran una deflección sostenida del 40-50% con alto CSAT no están usando mejor IA. Tratan la documentación como un activo de producto con el mismo rigor que aplican a su producto. Gartner predice que la IA agéntica resolverá autónomamente el 80% de los problemas comunes de servicio al cliente sin intervención humana para 2029, y las organizaciones mejor posicionadas para alcanzar ese techo son las que están construyendo disciplina de documentación ahora. El sprint de documentación está en el roadmap. La auditoría del corpus está en el calendario de ops de soporte. Los informes de brechas de conocimiento van al equipo de documentación, no solo al equipo de soporte. La ventaja de la telemetría de producto en IA SaaS explica cómo los datos de uso dentro del producto pueden alimentar su corpus de soporte e identificar preguntas antes de que los clientes siquiera las hagan.
Agente de Soporte IA para Autoservicio en SaaS cubre la estructura completa de niveles: cómo la deflección con RAG se conecta con la asistencia a agentes humanos y la escalada a especialistas como un sistema de soporte completo.
Mantenimiento de Knowledge Base con IA para Docs SaaS profundiza en el ciclo de vida de la documentación: cómo auditar la cobertura, mantener los docs actualizados con los lanzamientos y usar la propia IA para mantener el corpus.
Routing Multinivel con IA en Help Desk SaaS cubre qué sucede después de que RAG intenta la deflección: cómo los tickets que necesitan manejo humano se enrutan al agente correcto sin triaje manual.
Los equipos de soporte que ganan con RAG son los que monitorean la calidad de la deflección junto al volumen. El objetivo son los clientes satisfechos que se auto-atendieron. No los clientes que se rindieron y se fueron en silencio. Diseñe para los primeros desde el inicio.
Rework Analysis: La tasa de falsa deflección es la métrica menos monitoreada en IA de soporte SaaS. Los equipos optimizan para el volumen de deflección bruto, celebran una tasa del 50% y no notan que el 18% de esos clientes "deflectados" abrieron un nuevo ticket dentro de los 7 días con el mismo problema y frustración adicional. La tasa de deflección real no es lo que reporta el sistema. Es lo que sucede 7 días después. Los equipos que monitorean la tasa de reapertura a los 7 días junto al volumen de deflección descubren que su tasa de deflección efectiva es típicamente 10-15 puntos porcentuales más baja que el número del titular, y ese es el número a optimizar.
Leer Más:
- Patrón RAG Assistant: arquitectura técnica completa para IA de soporte con recuperación aumentada
- Riesgo de Alucinación por Patrón: dónde la IA anclada en RAG sigue fallando y cómo calibrar los umbrales de escalada
- Preparación de Datos por Patrón: cómo son los datos limpios y listos para el corpus en despliegues de RAG
- Agente de Soporte IA para Autoservicio en SaaS: la estructura completa de niveles para IA de soporte SaaS
- Routing Multinivel con IA en Help Desk SaaS: enrutamiento inteligente después de los intentos de deflección
- Mantenimiento de Knowledge Base con IA para Docs SaaS: mantener el corpus actualizado con su producto

Co-Founder, Rework.com
On this page
- Cómo Funciona la Deflección con RAG
- El RAG Quality Gate
- Qué va en el Corpus RAG
- Detección de Brechas de Conocimiento
- Medición de la Calidad de la Deflección
- Benchmarks de Calidad de Deflección
- El Problema del Ritmo de Lanzamientos SaaS
- Soporte Multi-idioma
- Corpus Específicos por Segmento
- Ciclo de Mejora Continua