Telemetry Loop untuk In-Product AI: Membangun Feedback yang Terus Berkembang
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
GitHub Copilot terukur semakin baik setiap beberapa bulan. Peningkatan itu bukan datang dari engineer GitHub yang bekerja lebih keras pada modelnya. Peningkatan itu datang dari jutaan developer yang menerima, memodifikasi, dan menolak saran Copilot setiap hari. Setiap interaksi adalah satu titik data. Setiap titik data mengisi versi model berikutnya. Produk ini membaik karena orang menggunakannya.
Inilah yang disebut telemetry loop: sistem terstruktur yang menangkap apa yang disarankan fitur AI, apa yang dilakukan pengguna selanjutnya, dan hasil apa yang mengikutinya. Ini adalah perbedaan antara fitur AI yang stagnan pada kualitas peluncurannya dan fitur AI yang terus berkembang.
Sebagian besar tim SaaS yang membangun fitur AI melewatkan ini. Mereka meluncurkan fitur. Mereka memantau angka adopsi. Mereka menyatakan sukses jika adopsi naik. Lalu, enam bulan kemudian, mereka bertanya-tanya mengapa saran AI mereka masih terasa generik dan mengapa churn di antara pengguna fitur AI tidak lebih baik dari pengguna non-AI.
Loop itulah yang penting. Model awal hanyalah kondisi awal.
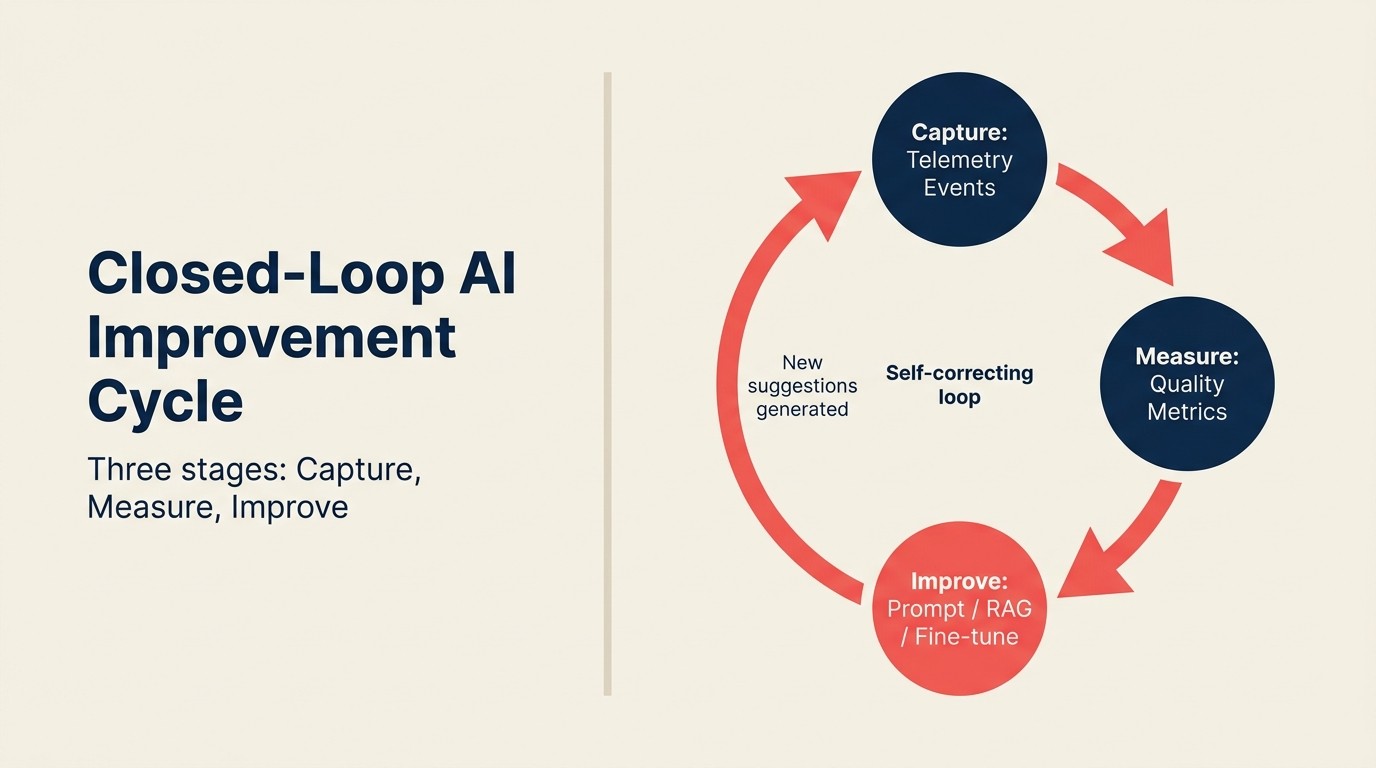
The Closed-Loop AI Improvement Cycle
The Closed-Loop AI Improvement Cycle adalah sistem feedback tiga tahap yang mengubah penggunaan AI dalam produk menjadi peningkatan model yang berkelanjutan. Capture: event telemetri terstruktur mencatat apa yang disarankan AI, apa yang dilakukan pengguna selanjutnya, dan hasil di hilir. Measure: sinyal agregat menghitung metrik kualitas berdasarkan jenis saran (acceptance rate, modification rate, outcome correlation). Improve: metrik kualitas diarahkan ke mekanisme peningkatan yang sesuai (prompt engineering untuk fitur berbasis API, penyesuaian parameter retrieval untuk fitur RAG, atau fine-tuning data untuk model kustom). Siklus ini tertutup ketika peningkatan menghasilkan saran baru yang menghasilkan event capture baru. Loop yang berhenti di Capture (mencatat event tanpa mengukur atau meningkatkan) bukanlah loop. Itu adalah arsip.
Apa sebenarnya telemetry loop itu
Telemetry loop memiliki tiga tahap, dipetakan ke kapabilitas Ingest dalam ACE Framework:
Capture: Kumpulkan sinyal terstruktur dari setiap interaksi fitur AI. Apa yang disarankan, apa yang ditampilkan, bagaimana konteksnya. Ini dipetakan langsung ke kapabilitas Ingest ACE Framework.
Measure: Agregasikan sinyal tersebut menjadi metrik kualitas. Suggestion acceptance rate, modification rate, outcome correlation.
Improve: Arahkan sinyal yang terukur kembali ke peningkatan model, penyempurnaan prompt, atau penyesuaian parameter retrieval.
Tanpa ketiga tahap tersebut, Anda tidak memiliki loop. Sebagian besar tim memiliki tahap pertama (mereka mencatat event di suatu tempat), melewatkan yang kedua (mereka tidak memiliki metrik kualitas), dan tidak pernah mencapai yang ketiga (data tersimpan di data warehouse dan tidak ada yang menindaklanjutinya).
Loop yang nyata harus tertutup. Output dari Improve mengalir kembali ke perilaku fitur AI, yang menghasilkan data Capture baru. Sistem mengoreksi dirinya sendiri dari waktu ke waktu.
Key Facts: Telemetry Loop dan Peningkatan AI
- Eksperimen sinyal perilaku LinkedIn menemukan bahwa sinyal perilaku memprediksi kualitas konten 4-6x lebih baik daripada penilaian eksplisit, itulah mengapa implicit feedback (accept/modify/reject) adalah sinyal bernilai tinggi dalam telemetry loop AI
- GitHub Copilot menulis hampir setengah kode developer, dan uji terkontrol menunjukkan developer menyelesaikan tugas 55% lebih cepat; kualitas ini mencapai level saat ini melalui jutaan sinyal penerimaan dan penolakan dari 15 juta+ pengguna, bukan melalui peningkatan model statis (Second Talent, 2025)
- McKinsey mendeskripsikan dinamika compounding ini secara eksplisit: eksperimen lebih cepat menghasilkan lebih banyak data, lebih banyak data meningkatkan kualitas model, kinerja lebih baik menarik lebih banyak pengguna, dan kesenjangan antara organisasi yang menjalankan loop ini dan yang tidak menjadi struktural seiring waktu (McKinsey State of AI, 2025)
Tiga jenis sinyal dari in-product AI

Tidak semua feedback setara. Ketiga jenisnya sangat berbeda dalam volume, akurasi, dan tingkat kesulitan pengumpulannya.
Explicit feedback adalah yang paling mudah dipahami dan paling tidak berguna dalam praktik. Thumbs-up, thumbs-down, prompt "apakah ini membantu?". Pengguna jarang memberikan explicit feedback dan inkonsisten. Seseorang yang mengklik thumbs-down sekali dan tidak pernah lagi bukan berarti tidak lagi punya pendapat. Mereka hanya berhenti mengklik. LinkedIn menjalankan eksperimen pada mekanisme explicit feedback dan menemukan bahwa sinyal perilaku memprediksi kualitas konten 4-6x lebih baik daripada penilaian eksplisit. Pola yang sama berlaku dalam konteks produk.
Implicit feedback adalah tempat sinyalnya berada. Pengguna tidak mengklik thumbs-down, tetapi mereka berperilaku jujur. Mereka menerima saran, mengedit saran, mengabaikan saran, atau membatalkan hasilnya dan mengerjakan tugas secara manual. Tindakan-tindakan ini memberi tahu Anda lebih banyak tentang kualitas daripada sistem rating apa pun.
Dua metrik implicit yang paling penting adalah:
- Suggestion acceptance rate: Berapa persen saran AI yang digunakan pengguna tanpa modifikasi?
- Modification rate: Dari saran yang diterima pengguna, berapa banyak yang mereka edit sebelum finalisasi?
Modification rate yang tinggi menandakan arah AI sudah benar tetapi detail-detailnya meleset. Acceptance rate rendah dengan manual-completion rate tinggi menandakan titik insertion saran salah atau ambang kualitas terlalu rendah. Ini adalah masalah yang berbeda dengan solusi yang berbeda.
Outcome feedback adalah yang paling sulit dikumpulkan dan paling berharga. Apakah tugas yang dibantu AI menghasilkan hasil yang lebih baik daripada cara manual? Apakah email yang dibuat AI mendapat balasan? Apakah respons support yang dibuat AI menyelesaikan tiket tanpa eskalasi? Apakah next action yang disarankan AI dalam CRM menghasilkan meeting yang terjadwal?
Outcome feedback mengharuskan Anda menghubungkan telemetri AI dengan outcome bisnis hilir, yang biasanya berarti menggabungkan data event dengan data CRM atau tiket support. Ini adalah investasi rekayasa. Tetapi begitu Anda memilikinya, Anda dapat menjawab pertanyaan yang sebenarnya paling diperhatikan setiap product leader: apakah AI kami membuat pelanggan lebih sukses, atau apakah hanya menghasilkan aktivitas?
Mengapa implicit feedback mengalahkan explicit
Ekonomi perilaku di sini konsisten di berbagai produk. Orang tidak melaporkan preferensi mereka secara akurat. Mereka mengatakan ingin satu hal dan melakukan hal lain. Ini berlaku untuk feedback fitur AI persis seperti berlaku untuk respons survei tentang fitur produk.
Tetapi lebih praktis lagi: rasio implicit feedback terhadap explicit feedback di sebagian besar produk adalah sekitar 50-banding-1 atau lebih. Untuk setiap pengguna yang mengklik thumbs-down, lima puluh pengguna membuat sinyal perilaku yang setara atau kualitasnya lebih tinggi. Mengoptimalkan hanya untuk explicit feedback berarti mengabaikan 98% sinyal yang bisa Anda gunakan.
Notion AI mempelajari ini lebih awal. Saran penulisan AI mereka disempurnakan berdasarkan bagaimana pengguna menerima, memodifikasi, atau mengganti teks yang disarankan, bukan terutama pada penilaian eksplisit. Engineer produk dapat melihat secara agregat jenis saran mana yang digunakan apa adanya versus ditulis ulang versus diabaikan. Tampilan agregat tersebut membentuk keputusan prompt engineering dan pemilihan model untuk versi berikutnya.
Pola yang sama terlihat dalam pengembangan fitur AI Linear. Saran triage bug dan prioritas mereka disempurnakan melalui kombinasi prioritas yang disarankan AI mana yang di-override oleh engineer, dan seberapa sering prioritas yang di-override secara manual ternyata cocok dengan urgensi resolusi aktual. Model tidak hanya dilatih dengan data berlabel. Model dilatih berdasarkan kesenjangan antara apa yang disarankan dan apa yang sebenarnya terjadi.
"Rasio implicit feedback terhadap explicit feedback di sebagian besar produk adalah 50-banding-1 atau lebih. Untuk setiap pengguna yang mengklik thumbs-down, lima puluh pengguna membuat sinyal perilaku yang setara atau kualitasnya lebih tinggi. Mengoptimalkan hanya untuk explicit feedback berarti mengabaikan 98% sinyal yang tersedia." (Rework Analysis, berdasarkan penelitian ekonomi perilaku LinkedIn)
"Fitur AI statis bukan netral. Mereka adalah biaya tanpa nilai compounding. Setiap bulan fitur tidak meningkat melalui telemetri, kesenjangan antara kualitasnya dan kompetitor yang menjalankan loop nyata semakin lebar. Keputusan untuk membangun loop adalah keputusan infrastruktur AI. Pilihan model lebih tidak penting." (Rework Analysis, 2025)
Perbandingan Kualitas dan Volume Sinyal
| Jenis Sinyal | Kesulitan Pengumpulan | Volume | Kualitas/Akurasi | Penggunaan Utama |
|---|---|---|---|---|
| Explicit (thumbs up/down) | Mudah | Sangat rendah (2-3% interaksi) | Buruk (pelaporan mandiri inkonsisten) | Penanda kasus tepi yang jarang |
| Implicit acceptance | Sedang | Tinggi (setiap saran ditampilkan) | Baik (sinyal perilaku jujur) | Acceptance rate, peningkatan model |
| Implicit modification | Sedang | Tinggi (setiap saran yang diterima) | Sangat baik (menunjukkan preference gap) | Prompt engineering, specificity tuning |
| Outcome feedback | Sulit (memerlukan data join) | Rendah (subset sesi) | Sangat baik (mengukur nilai aktual) | Pengukuran ROI, sinyal pelatihan |
Sumber: Penelitian sinyal perilaku AI LinkedIn, dokumentasi telemetri Notion AI, penelitian McKinsey AI Software Development 2025
Rework Analysis: Sebagian besar tim SaaS memiliki Tahap 1 telemetry loop (mencatat event) dan melewatkan Tahap 2 dan 3 (mengukur metrik kualitas dan menindaklanjutinya). Data tersimpan di warehouse dan tidak ada yang meninjaunya setiap minggu. Loop minimum yang layak terdiri dari empat komponen: event suggestion_shown, suggestion_accepted, dan suggestion_modified di Segment atau Amplitude; dashboard mingguan acceptance rate berdasarkan fitur; pertemuan tinjauan prompt dua mingguan di mana seseorang membaca data; dan komitmen untuk mengirimkan perubahan prompt bagi jenis saran dengan performa terlemah. Itulah seluruh loop-nya.
Desain skema untuk AI telemetri

Skema event sangat penting. Event yang tidak jelas menghasilkan sinyal yang tidak jelas. Jika telemetri Anda terlihat seperti ai_feature_used: true, Anda tidak dapat menghitung modification rate, tidak dapat segmentasi berdasarkan jenis saran, dan tidak dapat mengkorelasikan dengan outcome.
Skema AI telemetri minimal terlihat seperti ini:
suggestion_id: UUID (menghubungkan saran sepanjang siklus hidupnya)
feature_id: string (fitur AI mana yang menghasilkan ini)
session_id: string (terhubung ke konteks sesi pengguna)
context_hash: string (fingerprint dari konteks yang diterima AI)
suggestion_type: enum (draft, autocomplete, classification, recommendation)
suggestion_shown_at: timestamp
suggestion_accepted_at: timestamp or null
suggestion_modified: boolean
modification_delta: integer (character edit distance dari saran ke final)
user_dismissed: boolean
manual_completion: boolean (pengguna menyelesaikan tugas tanpa menggunakan saran)
outcome_event_id: string or null (FK ke outcome hilir, jika ditangkap)
Skema ini memungkinkan Anda menghitung setiap metrik yang penting untuk kualitas telemetry loop. context_hash sangat penting: ini memungkinkan Anda mengidentifikasi apakah konteks serupa mendapatkan saran yang secara konsisten lebih baik atau lebih buruk dari waktu ke waktu, yang merupakan pengukuran inti untuk peningkatan model.
Untuk tim yang menggunakan Segment atau Amplitude sebagai pipeline event mereka, skema ini dipetakan dengan bersih ke custom event dengan properti standar. Join outcome_event_id memerlukan langkah server-side enrichment atau join hilir di data warehouse Anda. Begitu skema Anda menangkap event yang tepat, apa yang Anda lakukan dengan sinyal tersebut sepenuhnya bergantung pada bagaimana fitur AI Anda dibangun.
Menggunakan loop untuk peningkatan model
Apa yang Anda lakukan dengan data telemetri bergantung pada bagaimana fitur AI Anda dibangun.
Untuk fitur berbasis GPT-4 atau Claude API (kasus paling umum untuk AI SaaS di 2026), mekanisme peningkatannya adalah prompt engineering. Modification rate tinggi pada jenis saran tertentu memberi tahu Anda bahwa prompt tidak cukup spesifik. Manual completion yang konsisten setelah saran AI memberi tahu Anda bahwa saran muncul di momen yang salah dalam workflow. Anda dapat mengiterasi prompt setiap minggu tanpa menyentuh model yang mendasarinya.
Untuk fitur RAG (Retrieval-Augmented Generation) (AI yang mengambil dari knowledge base sebelum menghasilkan), telemetri mengisi penyesuaian parameter retrieval. Jika pengguna secara konsisten mengabaikan saran AI yang mengutip bagian knowledge base tertentu, bagian tersebut sudah usang atau tidak relevan. Telemetri memberi tahu Anda sumber retrieval mana yang sebenarnya menghasilkan saran yang digunakan versus noise. Pemeliharaan AI knowledge base untuk SaaS mencakup cara menindaklanjuti sinyal ini untuk menjaga korpus retrieval tetap terkini.
Untuk model fine-tuned atau kustom (jarang untuk SaaS Series A-C), implicit feedback berkualitas tinggi dengan label outcome menjadi data pelatihan. Data modification rate secara efektif adalah dataset preferensi. Data outcome correlation adalah sinyal reinforcement. Ini adalah pendekatan yang diambil GitHub dengan Copilot dalam skala besar, tetapi memerlukan infrastruktur ML yang tidak seharusnya dibangun oleh sebagian besar tim SaaS sebelum mencapai kematangan Tahap 4.
Keunggulan kompetitif data yang terus berkembang
Setelah 12 bulan menjalankan telemetry loop yang nyata, sesuatu berubah dalam posisi kompetitif Anda.
Fitur AI Anda telah dilatih pada perilaku aktual pengguna aktual Anda yang melakukan kasus penggunaan aktual Anda. Bukan teks internet generik. Bukan dataset benchmark. Pola pengguna Anda, preferensi pengguna Anda, definisi "saran yang baik" menurut pengguna Anda.
Kompetitor yang meluncurkan fitur yang sama dengan model yang sama mulai dari nol. Mereka memiliki akses API yang sama dengan yang Anda miliki saat peluncuran. Tetapi mereka tidak memiliki 12 bulan data perilaku pengguna Anda. Mereka tidak bisa membelinya. Mereka harus mendapatkannya dengan menjalankan loop mereka sendiri selama 12 bulan.
Inilah bagaimana telemetry loop menjadi keunggulan kompetitif yang tahan lama. Bukan dari teknologinya, yang tersedia untuk semua orang, tetapi dari data perilaku terakumulasi yang membentuk kinerja teknologi untuk pengguna spesifik Anda.
Efek compounding dipercepat pada kematangan Tahap 4 dan 5, di mana fitur AI mulai berbagi sinyal lintas fungsi. Jika data outcome AI dalam produk Anda mengisi AI health scoring customer success Anda, dan akurasi AI health scoring Anda mengisi kembali fitur mana yang diprioritaskan AI dalam produk Anda, Anda sedang membangun sistem pembelajaran terintegrasi. Itu benar-benar sulit untuk direplikasi. McKinsey mendeskripsikan dinamika compounding ini secara eksplisit: eksperimen lebih cepat menghasilkan lebih banyak data, lebih banyak data meningkatkan kualitas model, kinerja lebih baik menarik lebih banyak pengguna, dan seiring waktu kesenjangan antara organisasi yang menjalankan loop ini dan yang tidak menjadi struktural. Tahap kematangan AI SaaS memetakan tampilan integrasi lintas fungsi ini pada setiap tahap.
Persyaratan privasi dan persetujuan
Feedback pengguna yang dikumpulkan dan digunakan untuk pelatihan model tidak bebas dari perspektif kepatuhan. GDPR (General Data Protection Regulation) Pasal 22 dan CCPA (California Consumer Privacy Act) keduanya memiliki persyaratan seputar pengambilan keputusan otomatis dan penggunaan data. Menggunakan data perilaku untuk meningkatkan fitur AI yang kemudian membuat saran kepada pengguna bisa jadi masuk dalam pengambilan keputusan otomatis dalam beberapa interpretasi.
Persyaratan praktis untuk sebagian besar perusahaan SaaS adalah: syarat dan ketentuan layanan serta kebijakan privasi Anda perlu secara eksplisit menyatakan bahwa Anda mengumpulkan data penggunaan produk untuk meningkatkan fitur AI, dan pengguna memerlukan jalur opt-out yang jelas. NIST's AI Risk Management Framework memberikan struktur yang berguna untuk mendokumentasikan bagaimana data feedback perilaku mengalir melalui pipeline peningkatan AI, yang semakin penting karena tim pengadaan perusahaan menjalankan tinjauan tata kelola AI mereka sendiri sebelum menyetujui alat SaaS. Ini berbeda dari pelatihan AI pada konten pengguna, yang memiliki persyaratan persetujuan yang lebih ketat.
Aturan yang lebih penting: jangan gunakan data spesifik pelanggan untuk meningkatkan AI bagi pelanggan lain tanpa persetujuan eksplisit. Pola perilaku agregat umumnya tidak masalah. Konten yang dibuat pengguna spesifik yang digunakan sebagai contoh pelatihan memerlukan arsitektur persetujuan yang lebih kuat.
Anti-pola: Fitur AI yang tidak pernah belajar
Kebalikan dari telemetry loop adalah fitur AI yang statis sejak hari pertama. Model yang sama, prompt yang sama, saran yang sama, terlepas dari apa yang dilakukan pengguna. Fitur-fitur ini ada di banyak produk SaaS saat ini. Mereka dibangun oleh tim yang memperlakukan AI sebagai kotak centang: "kirimkan, itu AI."
Tanda-tanda fitur AI statis:
- Kualitas saran tidak meningkat dalam interval 6 bulan
- Tim tidak memiliki tinjauan mingguan metrik fitur AI
- Tim data tidak memiliki dashboard yang melacak acceptance rate atau modification rate
- Perubahan prompt memerlukan satu sprint dan terjadi paling sering setiap kuartal
Fitur AI statis bukan netral. Mereka adalah biaya tanpa nilai compounding. Setiap bulan mereka tidak meningkat, kesenjangan antara kualitas AI Anda dan kompetitor yang menjalankan loop semakin melebar.
Keputusan untuk membangun loop adalah keputusan infrastruktur AI. Pilihan model lebih tidak penting.
Seperti apa "loop tertutup" dalam praktik
Telemetry loop yang tertutup menghasilkan ritual mingguan: tinjauan metrik fitur AI. Acceptance rate naik atau turun. Modification rate berdasarkan jenis saran. Korelasi outcome apa pun yang bergerak. Prompt disesuaikan berdasarkan sinyal. Versi baru dikirim.
Tim engineering GitHub Copilot secara berkala menerbitkan postingan tentang bagaimana mereka menggunakan data penerimaan dan metrik edit distance untuk mengevaluasi perubahan model. Changelog Linear menunjukkan peningkatan AI priority scoring di sebagian besar rilis bulanan, didorong oleh bagaimana engineer sebenarnya merespons saran. Ini bukan kebetulan. Ini adalah loop.
Untuk tim Anda, telemetry loop minimum yang layak adalah:
- Event
suggestion_shown,suggestion_accepted,suggestion_modifieddi Segment atau Amplitude - Dashboard mingguan dengan acceptance rate dan modification rate berdasarkan fitur
- Pertemuan tinjauan prompt setiap dua minggu di mana seseorang benar-benar membaca data
- Komitmen pada perubahan prompt yang meningkatkan jenis saran dengan performa terlemah
Itulah saja. Itulah loop-nya. Ini bukan ML engineering. Ini adalah disiplin produk.
Perusahaan yang akan menguasai kualitas fitur AI pada 2027 dan 2028 bukan mereka yang memilih model terbaik di 2025. Mereka adalah yang membangun loop di 2025 dan membiarkannya berjalan.
Pertanyaan yang Sering Diajukan
Apa itu telemetry loop untuk in-product AI?
Telemetry loop adalah sistem terstruktur yang menangkap apa yang disarankan fitur AI, apa yang dilakukan pengguna selanjutnya, dan hasil apa yang mengikutinya, kemudian mengarahkan sinyal tersebut kembali ke peningkatan model atau prompt. Tiga tahapnya adalah Capture (pengumpulan event terstruktur), Measure (metrik kualitas dari sinyal agregat), dan Improve (prompt engineering, penyesuaian retrieval, atau data pelatihan). Tanpa ketiga tahap tersebut, Anda memiliki arsip, bukan loop.
Mengapa implicit feedback lebih berharga dari explicit rating dalam AI telemetri?
Explicit rating (thumbs up/down) diberikan oleh 2-3% pengguna dan tidak secara akurat mencerminkan preferensi. Pengguna tidak melaporkan secara konsisten. Sinyal implicit (menerima, memodifikasi, atau mengabaikan saran) dihasilkan oleh 100% interaksi dan mencerminkan perilaku jujur. Rasionya sekitar 50-banding-1. Mengoptimalkan hanya untuk explicit feedback mengabaikan 98% sinyal yang tersedia.
Apa dua metrik implicit utama dalam AI telemetri?
Suggestion acceptance rate (berapa persen saran AI yang digunakan pengguna tanpa modifikasi?) dan modification rate (dari saran yang diterima pengguna, berapa banyak yang mereka edit sebelum finalisasi?). Modification rate tinggi berarti arah AI sudah benar tetapi detail-detailnya meleset. Acceptance rate rendah dengan manual completion tinggi berarti titik pemicu atau ambang kualitas salah. Metrik berbeda, solusi berbeda.
Bagaimana telemetry loop menciptakan keunggulan kompetitif?
Setelah 12 bulan menjalankan telemetry loop yang nyata, fitur AI Anda dilatih pada perilaku aktual pengguna aktual Anda yang melakukan kasus penggunaan aktual Anda. Kompetitor yang meluncurkan fitur yang sama dengan model yang sama mulai dari nol. Mereka memiliki akses API yang sama dengan yang Anda miliki saat peluncuran tetapi tidak memiliki 12 bulan data perilaku pengguna Anda. Mereka tidak bisa membelinya. Mereka harus mendapatkannya dengan menjalankan loop mereka sendiri selama 12 bulan.
Apa telemetry loop minimum yang layak?
Empat komponen: event suggestion_shown, suggestion_accepted, dan suggestion_modified yang dilacak di Segment atau Amplitude; dashboard mingguan dengan acceptance rate dan modification rate berdasarkan fitur; pertemuan tinjauan prompt dua mingguan di mana seseorang membaca data; dan komitmen untuk mengirimkan perubahan prompt bagi jenis saran dengan performa terlemah. Tidak diperlukan ML engineering pada tahap ini. Murni disiplin produk.
Persyaratan kepatuhan apa yang berlaku untuk behavioral telemetry dalam pelatihan AI?
GDPR Pasal 22 dan CCPA keduanya memiliki persyaratan seputar pengambilan keputusan otomatis dan penggunaan data. Syarat dan ketentuan layanan serta kebijakan privasi Anda harus secara eksplisit menyatakan bahwa Anda mengumpulkan data penggunaan produk untuk meningkatkan fitur AI, dengan jalur opt-out yang jelas. Jangan gunakan konten spesifik pelanggan untuk meningkatkan AI bagi pelanggan lain tanpa persetujuan eksplisit. Pola perilaku agregat (acceptance rate, modification rate) umumnya tidak masalah. Konten yang dibuat pengguna spesifik yang digunakan sebagai contoh pelatihan memerlukan arsitektur persetujuan yang lebih kuat.
Pelajari Lebih Lanjut:
- Apa itu Kapabilitas Ingest AI: lapisan Ingest ACE tempat telemetry loop dibangun
- Bagaimana AI Pattern Menggabungkan Kapabilitas: bagaimana data telemetri berkembang di berbagai AI pattern
- Fitur AI sebagai Produk: Di Mana Menambahkannya: cara mengidentifikasi fitur yang layak dibangun telemetry loop-nya
- AI Copilot Tertanam dalam UI Produk SaaS: fitur AI tertanam yang menghasilkan sinyal telemetri terkaya
- Tahap Kematangan AI SaaS: bagaimana integrasi telemetri lintas fungsi berkembang di berbagai tahap kematangan
- Keunggulan Product Telemetry dalam AI SaaS: bagaimana telemetri SaaS menciptakan keunggulan struktural atas kompetitor berbasis AI murni

Co-Founder, Rework.com
On this page
- The Closed-Loop AI Improvement Cycle
- Apa sebenarnya telemetry loop itu
- Tiga jenis sinyal dari in-product AI
- Mengapa implicit feedback mengalahkan explicit
- Perbandingan Kualitas dan Volume Sinyal
- Desain skema untuk AI telemetri
- Menggunakan loop untuk peningkatan model
- Keunggulan kompetitif data yang terus berkembang
- Persyaratan privasi dan persetujuan
- Anti-pola: Fitur AI yang tidak pernah belajar
- Seperti apa "loop tertutup" dalam praktik