Telemetry Loops para IA en Producto: Construyendo Feedback que se Multiplica
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
GitHub Copilot mejora de forma medible cada pocos meses. Esa mejora no proviene de que los ingenieros de GitHub trabajen más en el modelo. Proviene de millones de desarrolladores que aceptan, modifican y rechazan sugerencias de Copilot cada día. Cada interacción es un dato. Cada dato alimenta la siguiente versión del modelo. El producto mejora porque la gente lo usa.
Esto es un telemetry loop: un sistema estructurado que captura qué sugirió una función de IA, qué hizo el usuario a continuación y qué resultado se produjo. Es la diferencia entre una función de IA que alcanza un techo en su calidad de lanzamiento y una función de IA que se multiplica.
La mayoría de los equipos SaaS que construyen funciones de IA omiten esto. Lanzan la función. Observan las métricas de adopción. Declaran el éxito si la adopción sube. Y luego, seis meses después, se preguntan por qué sus sugerencias de IA siguen sintiéndose genéricas y por qué el churn entre usuarios de funciones de IA no es mejor que entre los no usuarios.
El loop es el punto central. El modelo inicial es solo la condición de partida.
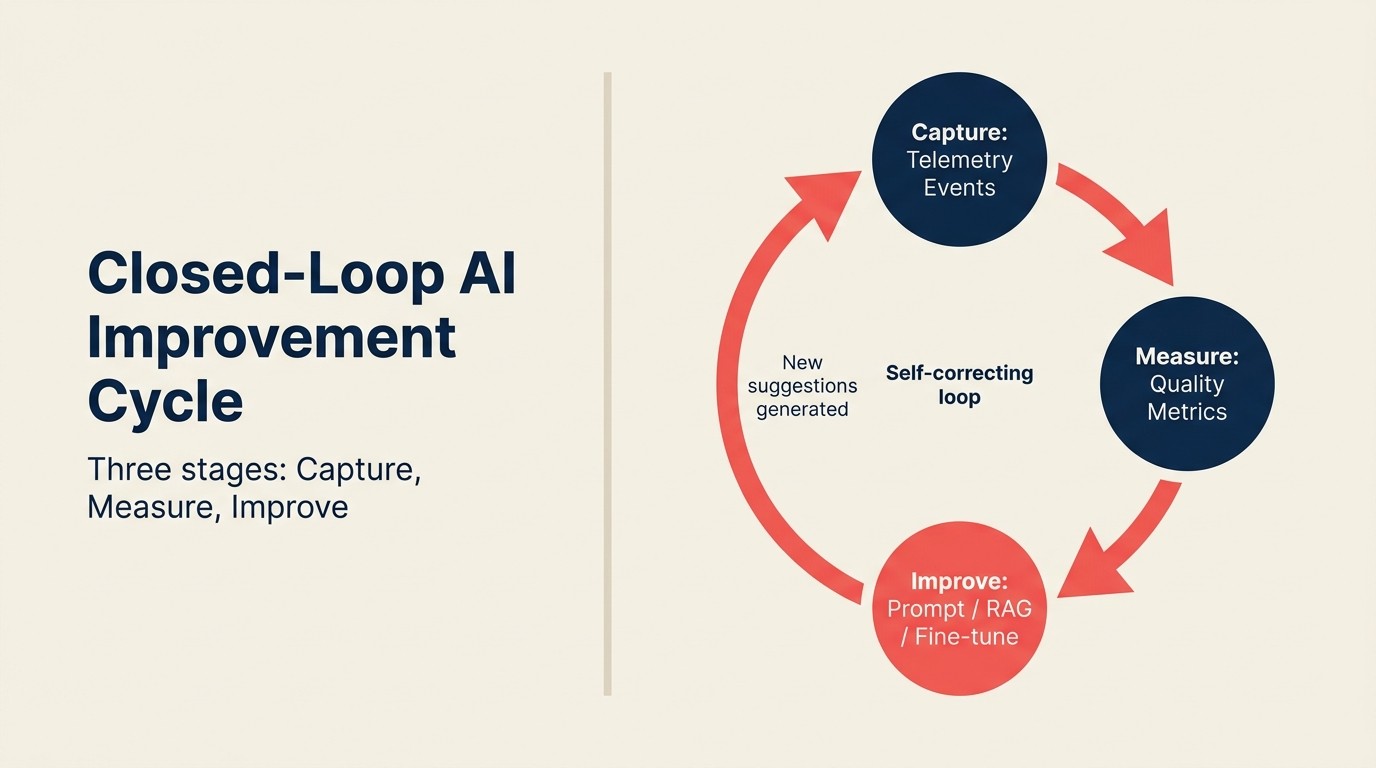
The Closed-Loop AI Improvement Cycle
The Closed-Loop AI Improvement Cycle es un sistema de feedback de tres etapas que convierte el uso de IA en producto en mejora continua del modelo. Capture: los eventos de telemetría estructurados registran qué sugirió la IA, qué hizo el usuario a continuación y el resultado posterior. Measure: las señales agregadas calculan métricas de calidad por tipo de sugerencia (tasa de aceptación, tasa de modificación, correlación de resultados). Improve: las métricas de calidad se dirigen al mecanismo de mejora apropiado (ingeniería de prompts para funciones basadas en API, ajuste de parámetros de recuperación para funciones RAG, o datos de fine-tuning para modelos personalizados). El ciclo se cierra cuando las mejoras generan nuevas sugerencias que producen nuevos eventos de captura. Un loop que se detiene en Capture (registrar eventos sin medir ni mejorar) no es un loop. Es un archivo.
Qué es realmente un telemetry loop
Un telemetry loop tiene tres etapas, mapeadas a la capacidad Ingest del ACE Framework:
Capture: Recopilar señales estructuradas de cada interacción con una función de IA. Qué se sugirió, qué se mostró, cuál era el contexto. Esto se mapea directamente a la capacidad Ingest del ACE Framework.
Measure: Agregar esas señales en métricas de calidad. Tasa de aceptación de sugerencias, tasa de modificación, correlación de resultados.
Improve: Dirigir las señales medidas de vuelta a la mejora del modelo, refinamiento de prompts o ajuste de parámetros de recuperación.
Sin las tres etapas, no existe un loop. La mayoría de los equipos tienen la primera etapa (registran eventos en algún lugar), se saltan la segunda (no tienen métricas de calidad) y nunca llegan a la tercera (los datos reposan en un data warehouse y nadie actúa sobre ellos).
Un loop real se cierra. El resultado de Improve retroalimenta el comportamiento de la función de IA, que genera nuevos datos de Capture. El sistema se autocorrige con el tiempo.
Key Facts: Telemetry Loops y Mejora de IA
- Los experimentos de señales de comportamiento de LinkedIn encontraron que las señales conductuales predijeron la calidad del contenido 4-6 veces mejor que las calificaciones explícitas, por eso el feedback implícito (aceptar/modificar/rechazar) es la señal de alto valor en los telemetry loops de IA
- GitHub Copilot escribe casi la mitad del código de un desarrollador, y las pruebas controladas muestran que los desarrolladores completan tareas un 55% más rápido; esta calidad alcanzó los niveles actuales gracias a millones de señales de aceptación y rechazo de más de 15 millones de usuarios, no a través de mejoras estáticas del modelo (Second Talent, 2025)
- McKinsey describe la dinámica de multiplicación explícitamente: la experimentación más rápida genera más datos, más datos mejoran la calidad del modelo, mejor rendimiento atrae más usuarios, y la brecha entre organizaciones que ejecutan estos loops y las que no se vuelve estructural con el tiempo (McKinsey State of AI, 2025)
Los tres tipos de señal de la IA en producto

No todo el feedback es igual. Los tres tipos varían enormemente en volumen, precisión y dificultad de recopilación.
El feedback explícito es el más fácil de entender y el menos útil en la práctica. Pulgares arriba, pulgares abajo, preguntas del tipo "¿fue esto útil?" Los usuarios dan feedback explícito con poca frecuencia e inconsistencia. Alguien que hace clic en pulgares abajo una vez y nunca más no ha dejado de tener opiniones. Ha dejado de hacer clic. LinkedIn realizó experimentos sobre mecanismos de feedback explícito y encontró que las señales conductuales predijeron la calidad del contenido 4-6 veces mejor que las calificaciones explícitas. El mismo patrón se observa en los contextos de producto.
El feedback implícito es donde vive la señal. Los usuarios no hacen clic en pulgares abajo, pero se comportan con honestidad. Aceptan una sugerencia, editan una sugerencia, ignoran una sugerencia, o deshacen el resultado y realizan la tarea manualmente. Estas acciones dicen más sobre la calidad que cualquier sistema de calificación.
Las dos métricas implícitas que más importan son:
- Tasa de aceptación de sugerencias: ¿Qué porcentaje de las sugerencias de IA usa el usuario sin modificaciones?
- Tasa de modificación: De las sugerencias que los usuarios aceptan, ¿cuántas editan antes de finalizar?
Una tasa de modificación alta indica que la dirección de la IA es correcta pero los detalles no. Una tasa de aceptación baja con alta tasa de finalización manual indica que el punto de inserción de la sugerencia es incorrecto o el umbral de calidad es demasiado bajo. Son problemas distintos con soluciones distintas.
El feedback de resultados es el más difícil de recopilar y el más valioso. ¿La tarea asistida por IA produjo un resultado mejor que el equivalente manual? ¿El email redactado con IA obtuvo respuesta? ¿La respuesta de soporte generada por IA resolvió el ticket sin escalación? ¿La siguiente acción sugerida por la IA en el CRM llevó a una reunión concertada?
El feedback de resultados requiere conectar la telemetría de IA con los resultados de negocio posteriores, lo que generalmente significa unir datos de eventos con datos del CRM o de tickets de soporte. Es una inversión de ingeniería. Pero una vez que se tiene, se puede responder a la pregunta que realmente le importa a cada líder de producto: ¿nuestra IA hace que los clientes sean más exitosos, o simplemente genera actividad?
Por qué el feedback implícito supera al explícito
La economía conductual aquí es consistente en todos los productos. Las personas no reportan con precisión sus preferencias. Dicen querer una cosa y hacen otra. Esto es cierto para el feedback de funciones de IA exactamente de la misma manera que es cierto para las respuestas a encuestas sobre características del producto.
Pero más prácticamente: la ratio de feedback implícito a feedback explícito en la mayoría de los productos es de aproximadamente 50 a 1 o superior. Por cada usuario que hace clic en pulgares abajo, cincuenta usuarios emitieron una señal conductual de calidad equivalente o superior. Optimizar solo para el feedback explícito significa ignorar el 98% de la señal disponible.
Notion AI aprendió esto temprano. Sus sugerencias de escritura con IA se refinan según cómo los usuarios aceptan, modifican o reemplazan el texto sugerido, no principalmente a través de calificaciones explícitas. Los ingenieros de producto pueden ver en conjunto qué tipos de sugerencias se usan tal cual versus las que se reescriben versus las que se ignoran. Esa vista agregada da forma a las decisiones de ingeniería de prompts y selección de modelos para la siguiente versión.
El mismo patrón es visible en el desarrollo de funciones de IA de Linear. Sus sugerencias de priorización y clasificación de bugs se refinan mediante la combinación de qué prioridades sugeridas por IA anulan los ingenieros, y con qué frecuencia las prioridades anuladas manualmente resultan coincidir con la urgencia de resolución real. El modelo no solo se entrena con datos etiquetados. Se entrena con la brecha entre lo que sugirió y lo que realmente ocurrió.
"La ratio de feedback implícito a feedback explícito en la mayoría de los productos es de 50 a 1 o superior. Por cada usuario que hace clic en pulgares abajo, cincuenta usuarios emitieron una señal conductual de calidad equivalente o superior. Optimizar solo para el feedback explícito significa ignorar el 98% de la señal disponible." (Rework Analysis, basado en investigación de economía conductual de LinkedIn)
"Las funciones de IA estáticas no son neutrales. Son un costo sin valor multiplicador. Cada mes que una función no mejora a través de telemetría, la brecha entre su calidad y la de un competidor que sí ejecuta un loop real se amplía. La decisión de construir el loop es la decisión de infraestructura de IA. La elección del modelo importa menos." (Rework Analysis, 2025)
Comparación de Calidad y Volumen de Señales
| Tipo de Señal | Dificultad de Recopilación | Volumen | Calidad/Precisión | Uso Principal |
|---|---|---|---|---|
| Explícito (pulgares arriba/abajo) | Fácil | Muy bajo (2-3% de las interacciones) | Deficiente (reporte propio inconsistente) | Señalización de casos extremos poco frecuentes |
| Aceptación implícita | Medio | Alto (cada sugerencia mostrada) | Buena (señal conductual honesta) | Tasa de aceptación, mejora del modelo |
| Modificación implícita | Medio | Alto (cada sugerencia aceptada) | Muy buena (muestra la brecha de preferencia) | Ingeniería de prompts, ajuste de especificidad |
| Feedback de resultados | Difícil (requiere unión de datos) | Bajo (subconjunto de sesiones) | Excelente (mide el valor real) | Medición de ROI, señal de entrenamiento |
Fuentes: Investigación de señales conductuales de IA de LinkedIn, documentación de telemetría de Notion AI, investigación de desarrollo de software de IA de McKinsey 2025
Rework Analysis: La mayoría de los equipos SaaS tienen la Etapa 1 del telemetry loop (registro de eventos) y se saltan las Etapas 2 y 3 (medición de métricas de calidad y actuación sobre ellas). Los datos reposan en un warehouse y nadie los revisa semanalmente. El loop mínimo viable consta de cuatro componentes: eventos suggestion_shown, suggestion_accepted y suggestion_modified en Segment o Amplitude; un dashboard semanal de tasa de aceptación por función; una reunión quincenal de revisión de prompts donde alguien lee los datos; y un compromiso de enviar cambios de prompts para los tipos de sugerencias con peor rendimiento. Ese es todo el loop.
Diseño del schema de telemetría de IA

El schema de eventos importa. Los eventos vagos crean señales vagas. Si la telemetría parece ai_feature_used: true, no se puede calcular la tasa de modificación, no se puede segmentar por tipo de sugerencia y no se puede correlacionar con resultados.
Un schema mínimo de telemetría de IA tiene este aspecto:
suggestion_id: UUID (vincula la sugerencia a lo largo de su ciclo de vida)
feature_id: string (qué función de IA generó esto)
session_id: string (conecta con el contexto de sesión del usuario)
context_hash: string (huella del contexto que recibió la IA)
suggestion_type: enum (draft, autocomplete, classification, recommendation)
suggestion_shown_at: timestamp
suggestion_accepted_at: timestamp o null
suggestion_modified: boolean
modification_delta: integer (distancia de edición de caracteres de la sugerencia al final)
user_dismissed: boolean
manual_completion: boolean (el usuario completó la tarea sin usar la sugerencia)
outcome_event_id: string o null (FK al resultado posterior, si se captura)
Este schema permite calcular cada métrica relevante para la calidad del telemetry loop. El context_hash es especialmente importante: permite identificar si contextos similares obtienen sugerencias consistentemente mejores o peores con el tiempo, que es la medición central para la mejora del modelo.
Para equipos que usan Segment o Amplitude como su pipeline de eventos, este schema se mapea de forma limpia sobre un evento personalizado con propiedades estándar. La unión de outcome_event_id requiere un paso de enriquecimiento del lado del servidor o una unión posterior en el data warehouse. Una vez que el schema captura los eventos correctos, lo que se hace con esas señales depende completamente de cómo está construida la función de IA.
Usar el loop para mejorar el modelo
Lo que se hace con los datos de telemetría depende de cómo está construida la función de IA.
Para funciones basadas en API de GPT-4 o Claude (el caso más común para IA SaaS en 2026), el mecanismo de mejora es la ingeniería de prompts. Una tasa de modificación alta en un tipo particular de sugerencia indica que el prompt no es lo suficientemente específico. La finalización manual consistente después de una sugerencia de IA indica que la sugerencia aparece en el momento incorrecto del flujo de trabajo. Se puede iterar sobre prompts semanalmente sin tocar el modelo subyacente.
Para funciones RAG (IA que recupera de una base de conocimiento antes de generar), la telemetría alimenta el ajuste de parámetros de recuperación. Si los usuarios ignoran consistentemente las sugerencias de IA que citan una sección particular de la base de conocimiento, esa sección está desactualizada o es irrelevante. La telemetría indica qué fuentes de recuperación producen realmente sugerencias utilizadas versus ruido. El artículo sobre mantenimiento de knowledge base de IA para SaaS describe cómo actuar sobre estas señales para mantener actualizado el corpus de recuperación.
Para modelos fine-tuned o personalizados (poco frecuente para SaaS de Series A-C), el feedback implícito de alta calidad con etiquetas de resultados se convierte en datos de entrenamiento. Los datos de tasa de modificación son efectivamente un conjunto de datos de preferencias. Los datos de correlación de resultados son una señal de refuerzo. Este es el enfoque que GitHub usa con Copilot a escala, pero requiere infraestructura de ML que la mayoría de los equipos SaaS no deberían construir antes de alcanzar la madurez de la Etapa 4.
El moat de datos con efecto multiplicador
Después de 12 meses ejecutando un telemetry loop real, algo cambia en la posición competitiva.
Las funciones de IA han sido entrenadas con el comportamiento real de los usuarios reales haciendo casos de uso reales. No texto genérico de internet. No conjuntos de datos de benchmarks. Los patrones de los usuarios, las preferencias de los usuarios, la definición que tienen los usuarios de "buena sugerencia."
Un competidor que lanza la misma función con el mismo modelo subyacente comienza desde cero. Tiene el mismo acceso a la API que se tenía al lanzamiento. Pero no tiene los 12 meses de datos de comportamiento de usuarios. No puede comprarlos. Tiene que ganarlos ejecutando su propio loop durante 12 meses.
Así es como los telemetry loops se convierten en una ventaja competitiva duradera. No por la tecnología, que está disponible para todos, sino por los datos de comportamiento acumulados que dan forma a cómo funciona la tecnología para los usuarios específicos.
El efecto multiplicador se acelera en la madurez de las Etapas 4 y 5, donde las funciones de IA comienzan a compartir señales entre funciones. Si los datos de resultados de la IA en producto alimentan la puntuación de salud de la IA de customer success, y la precisión de la IA de puntuación de salud retroalimenta las funciones que prioriza la IA en producto, se está construyendo un sistema de aprendizaje integrado. Eso es genuinamente difícil de replicar. McKinsey describe esta dinámica de multiplicación explícitamente: la experimentación más rápida genera más datos, más datos mejoran la calidad del modelo, mejor rendimiento atrae más usuarios, y con el tiempo la brecha entre organizaciones que ejecutan estos loops y las que no se vuelve estructural. El artículo sobre etapas de madurez de IA en SaaS mapea cómo se ve esta integración entre funciones en cada etapa.
Requisitos de privacidad y consentimiento
El feedback de usuario recopilado y utilizado para el entrenamiento del modelo no está libre de obligaciones de cumplimiento. El GDPR (Reglamento General de Protección de Datos) Artículo 22 y la CCPA (California Consumer Privacy Act) tienen requisitos sobre la toma de decisiones automatizada y el uso de datos. Usar datos de comportamiento para mejorar funciones de IA que luego hacen sugerencias a los usuarios podría considerarse toma de decisiones automatizada según algunas interpretaciones.
El requisito práctico para la mayoría de las empresas SaaS es el siguiente: los términos de servicio y la política de privacidad deben indicar explícitamente que se recopilan datos de uso del producto para mejorar las funciones de IA, y los usuarios necesitan una vía de exclusión voluntaria clara. El Marco de Gestión de Riesgos de IA del NIST proporciona una estructura útil para documentar cómo fluyen los datos de feedback de comportamiento a través de los pipelines de mejora de IA, lo que importa cada vez más a medida que los equipos de adquisiciones empresariales realizan sus propias revisiones de gobernanza de IA antes de aprobar herramientas SaaS. Esto es diferente del entrenamiento de IA sobre contenido del usuario, que tiene un requisito de consentimiento más estricto.
La preocupación por la fricción del UX es real pero solucionable. Notion, Linear y la mayoría de los principales productos de IA SaaS manejan esto a través de una sección de configuración de privacidad que explica qué se recopila, para qué se usa y cómo excluirse. La mayoría de los usuarios no se excluyen. Pero tener el mecanismo importa para el cumplimiento y la confianza.
La regla más importante: no usar datos específicos del cliente para mejorar la IA para otros clientes sin consentimiento explícito. Los patrones de comportamiento agregados generalmente están bien. El contenido específico generado por el usuario utilizado como ejemplos de entrenamiento requiere una arquitectura de consentimiento más sólida.
El antipatrón: funciones de IA que nunca aprenden
Lo opuesto a un telemetry loop es una función de IA que es estática desde el primer día. Mismo modelo, mismos prompts, mismas sugerencias, independientemente de lo que los usuarios hagan con ella. Estas funciones existen en muchos productos SaaS ahora mismo. Las construyeron equipos que trataron la IA como una casilla que marcar: "lanzarla, es IA."
Las señales de una función de IA estática:
- La calidad de las sugerencias no mejora en intervalos de 6 meses
- El equipo no tiene una revisión semanal de las métricas de funciones de IA
- El equipo de datos no tiene un dashboard que rastree la tasa de aceptación o la tasa de modificación
- Los cambios de prompts requieren un ciclo de sprint y ocurren trimestralmente en el mejor caso
Las funciones de IA estáticas no son neutrales. Son un costo sin valor multiplicador. Cada mes que no mejoran, la brecha entre la calidad de la IA y la de un competidor que sí ejecuta un loop se amplía.
La decisión de construir el loop es la decisión de infraestructura de IA. La elección del modelo importa menos.
Cómo se ve un "loop cerrado" en la práctica
Un telemetry loop cerrado produce un ritual semanal: la revisión de métricas de funciones de IA. Tasa de aceptación arriba o abajo. Tasa de modificación por tipo de sugerencia. Cualquier correlación de resultados en movimiento. Prompts ajustados según la señal. Nueva versión enviada.
El equipo de ingeniería de GitHub Copilot publica posts periódicos sobre cómo usan los datos de aceptación y las métricas de distancia de edición para evaluar los cambios del modelo. El changelog de Linear muestra mejoras en la puntuación de prioridades de IA en la mayoría de las publicaciones mensuales, impulsadas por cómo los ingenieros responden realmente a las sugerencias. No son coincidencias. Son loops.
Para el equipo, el telemetry loop mínimo viable es:
- Eventos
suggestion_shown,suggestion_acceptedysuggestion_modifieden Segment o Amplitude - Un dashboard semanal con tasa de aceptación y tasa de modificación por función
- Una reunión de revisión de prompts cada dos semanas donde alguien lee realmente los datos
- Un compromiso con los cambios de prompts que mejoren los tipos de sugerencias con peor rendimiento
Eso es todo. Ese es el loop. No es ingeniería de ML. Es disciplina de producto.
Las empresas que poseerán la calidad de las funciones de IA en 2027 y 2028 no son las que eligieron el mejor modelo en 2025. Son las que construyeron el loop en 2025 y lo dejaron funcionar.
Preguntas Frecuentes
¿Qué es un telemetry loop para IA en producto?
Un telemetry loop es un sistema estructurado que captura qué sugirió una función de IA, qué hizo el usuario a continuación y qué resultado se produjo, y luego dirige esas señales de vuelta a la mejora del modelo o de los prompts. Las tres etapas son Capture (recopilación estructurada de eventos), Measure (métricas de calidad a partir de señales agregadas) e Improve (ingeniería de prompts, ajuste de recuperación o datos de entrenamiento). Sin las tres etapas, se tiene un archivo, no un loop.
¿Por qué el feedback implícito es más valioso que las calificaciones explícitas en telemetría de IA?
Las calificaciones explícitas (pulgares arriba/abajo) las dan el 2-3% de los usuarios y no reflejan con precisión las preferencias. Los usuarios no reportan de forma consistente. Las señales implícitas (aceptar, modificar o ignorar una sugerencia) las genera el 100% de las interacciones y reflejan un comportamiento honesto. La ratio es aproximadamente 50 a 1. Optimizar solo para el feedback explícito ignora el 98% de la señal disponible.
¿Cuáles son las dos métricas implícitas clave en telemetría de IA?
La tasa de aceptación de sugerencias (¿qué porcentaje de las sugerencias de IA usa el usuario sin modificaciones?) y la tasa de modificación (de las sugerencias que los usuarios aceptan, ¿cuántas editan antes de finalizar?). Una tasa de modificación alta significa que la dirección de la IA es correcta pero los detalles no. Una tasa de aceptación baja con alta finalización manual significa que el punto de activación o el umbral de calidad es incorrecto. Métricas distintas, soluciones distintas.
¿Cómo crea un telemetry loop un moat competitivo?
Después de 12 meses ejecutando un telemetry loop real, las funciones de IA están entrenadas con el comportamiento real de los usuarios reales haciendo los casos de uso reales. Un competidor que lanza la misma función con el mismo modelo subyacente comienza desde cero. Tiene el mismo acceso a la API que se tenía al lanzamiento pero no los 12 meses de datos de comportamiento de los usuarios. No puede comprarlos. Tiene que ganarlos ejecutando su propio loop durante 12 meses.
¿Cuál es el telemetry loop mínimo viable?
Cuatro componentes: eventos suggestion_shown, suggestion_accepted y suggestion_modified rastreados en Segment o Amplitude; un dashboard semanal con tasa de aceptación y tasa de modificación por función; una reunión quincenal de revisión de prompts donde alguien lee los datos; y un compromiso de enviar cambios de prompts para los tipos de sugerencias con peor rendimiento. No se requiere ingeniería de ML en esta etapa. Pura disciplina de producto.
¿Qué requisitos de cumplimiento aplican a la telemetría de comportamiento para entrenamiento de IA?
El GDPR Artículo 22 y la CCPA tienen requisitos sobre la toma de decisiones automatizada y el uso de datos. Los términos de servicio y la política de privacidad deben indicar explícitamente que se recopilan datos de uso del producto para mejorar las funciones de IA, con una vía de exclusión voluntaria clara. No usar contenido específico del cliente para mejorar la IA para otros clientes sin consentimiento explícito. Los patrones de comportamiento agregados (tasas de aceptación, tasas de modificación) generalmente están bien. El contenido específico generado por el usuario utilizado como ejemplos de entrenamiento requiere una arquitectura de consentimiento más sólida.
Aprenda Más:
- What is Ingest AI Capability: la capa Ingest del ACE sobre la que se construyen los telemetry loops
- How AI Patterns Combine Capabilities: cómo los datos de telemetría se multiplican en múltiples patrones de IA
- Funciones de IA como Producto: Dónde Agregarlas: cómo identificar las funciones que vale la pena construir con un telemetry loop
- AI Copilots Integrados en la UI del Producto SaaS: las funciones de IA integradas que generan las señales de telemetría más ricas
- Etapas de Madurez de IA en SaaS: cómo evoluciona la integración de telemetría entre funciones a lo largo de las etapas de madurez
- The Product Telemetry Advantage in SaaS AI: cómo la telemetría SaaS crea un moat estructural sobre los competidores de IA pura

Co-Founder, Rework.com
On this page
- The Closed-Loop AI Improvement Cycle
- Qué es realmente un telemetry loop
- Los tres tipos de señal de la IA en producto
- Por qué el feedback implícito supera al explícito
- Comparación de Calidad y Volumen de Señales
- Diseño del schema de telemetría de IA
- Usar el loop para mejorar el modelo
- El moat de datos con efecto multiplicador
- Requisitos de privacidad y consentimiento
- El antipatrón: funciones de IA que nunca aprenden
- Cómo se ve un "loop cerrado" en la práctica