プロダクト内AIのためのテレメトリループ: 複利で成長するフィードバックの構築
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
GitHub Copilotは数ヶ月ごとに確実に改善されています。この改善はGitHubのエンジニアがモデルの改良に懸命に取り組んでいるからではありません。毎日何百万人もの開発者がCopilotの提案を承認、修正、却下していることで生まれています。すべてのインタラクションがデータポイントになります。すべてのデータポイントが次のモデルバージョンに反映されます。プロダクトは人々が使うことで改善されていくのです。
これがテレメトリループです。AI機能が何を提案し、ユーザーが次に何をし、その後どのような結果になったかを記録する構造化されたシステムです。これがリリース時の品質で止まるAI機能と、複利的に成長するAI機能の違いです。
AI機能を開発しているSaaSチームの多くはこのプロセスを省略しています。機能をリリースして、導入数字を見て、導入数が増えれば成功と判断します。そして6ヶ月後、AIの提案がいまだに汎用的で、AI機能利用ユーザーのChurnが非利用ユーザーと変わらないことに疑問を感じます。
ループこそが本質です。初期モデルは単なるスタート地点に過ぎません。
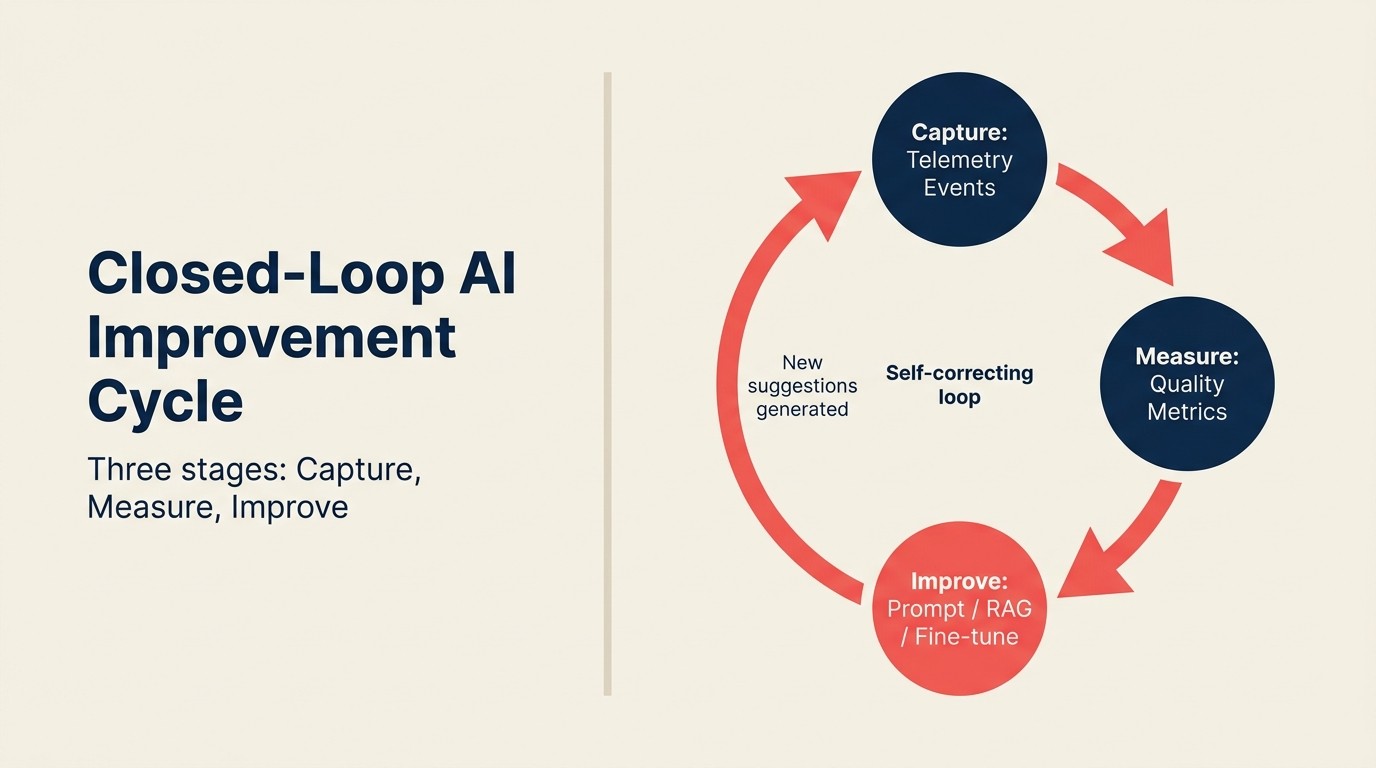
Closed-Loop AI Improvement Cycle
Closed-Loop AI Improvement Cycleは、プロダクト内AI利用を継続的なモデル改善へと変換する3段階のフィードバックシステムです。Capture: 構造化されたテレメトリイベントがAIの提案内容、ユーザーの次のアクション、その後の結果を記録します。Measure: 集約されたシグナルが提案タイプ別の品質指標(承認率、修正率、結果との相関)を算出します。Improve: 品質指標が適切な改善メカニズムへルーティングされます(APIベース機能にはプロンプトエンジニアリング、RAG機能には検索パラメータ調整、カスタムモデルにはFine-tuningデータ)。改善が新しい提案を生み出し、新しいCaptureイベントが生まれることでループが閉じます。Captureで止まるループ(イベントを記録するだけで測定も改善もしない)は、ループではなくアーカイブです。
テレメトリループの実態
テレメトリループには3つの段階があり、ACE FrameworkのIngest capabilityにマッピングされます。
Capture: すべてのAI機能インタラクションから構造化されたシグナルを収集します。何が提案され、何が表示され、どのようなコンテキストだったか。これはACE FrameworkのIngest capabilityに直接対応します。
Measure: これらのシグナルを品質指標に集約します。提案承認率、修正率、結果との相関です。
Improve: 測定されたシグナルをモデル改善、プロンプト改良、または検索パラメータ調整にフィードバックします。
3つの段階がすべて揃わなければループになりません。多くのチームは第1段階(どこかにイベントを記録する)だけを持ち、第2段階(品質指標がない)をスキップし、第3段階(データはデータウェアハウスに積み上がるだけで誰も活用しない)には到達しません。
本物のループは閉じます。ImproveのアウトプットがAI機能の動作にフィードバックされ、新しいCaptureデータが生まれます。システムは時間とともに自己修正していきます。
Key Facts: テレメトリループとAI改善
- LinkedInの行動シグナル実験では、行動シグナルが明示的な評価より4〜6倍精度よくコンテンツ品質を予測することが示されました。これがAIテレメトリループで暗黙的フィードバック(承認/修正/却下)が最も価値の高いシグナルである理由です
- GitHub Copilotは開発者のコードの約半分を書き、管理された実験ではタスク完了が55%速くなることが示されています。この品質は1,500万人以上のユーザーから得られた何百万もの承認・却下シグナルによって達成されたものであり、静的なモデル改善ではありません(Second Talent, 2025)
- McKinseyはこの複利的ダイナミクスを明確に説明しています。より速い実験がより多くのデータを生み、より多くのデータがモデル品質を改善し、より良いパフォーマンスがより多くのユーザーを引き寄せ、こうしたループを運用している組織とそうでない組織の差は構造的なものになっていくと言います(McKinsey State of AI, 2025)
プロダクト内AIの3種類のシグナル

すべてのフィードバックが同じ価値を持つわけではありません。3つのタイプは量、精度、収集の難易度において大きく異なります。
明示的フィードバックは最も理解しやすく、実用上は最も有用性が低いものです。サムズアップ、サムズダウン、「役に立ちましたか?」といったプロンプトです。ユーザーが明示的フィードバックを与えることは稀で、一貫性もありません。一度だけサムズダウンをクリックしてそれ以降は押さないユーザーは、意見を持つことをやめたのではなく、クリックをやめたのです。LinkedInは明示的フィードバックのメカニズムに関する実験を行い、行動シグナルが明示的な評価より4〜6倍精度よくコンテンツ品質を予測することを発見しました。同じパターンはプロダクトのコンテキストでも見られます。
暗黙的フィードバックこそがシグナルの本質です。ユーザーはサムズダウンをクリックしませんが、正直に行動します。提案を承認する、提案を編集する、提案を無視する、あるいは元に戻して手動でタスクを完了する。これらのアクションはどんな評価システムよりも品質についてを物語っています。
最も重要な2つの暗黙的指標は次の通りです。
- 提案承認率: ユーザーはAIの提案を修正なしでどれだけ使用しますか?
- 修正率: 承認した提案のうち、確定前に編集されたものはどれだけですか?
修正率が高い場合、AIの方向性は正しいが具体性が不十分であることを示します。承認率が低く手動完了率が高い場合、提案の挿入ポイントが間違っているか品質基準が低すぎることを示します。これらは異なる問題であり、異なる修正が必要です。
結果フィードバックは収集が最も難しく、最も価値が高いものです。AI支援タスクは手動の同等タスクより良い結果を生みましたか? AIが下書きしたメールは返信を得ましたか? AIが生成したサポート回答はエスカレーションなしにチケットを解決しましたか? CRMでAIが提案した次のアクションはミーティングの予約につながりましたか?
結果フィードバックには、AIテレメトリをビジネス上のダウンストリーム結果に接続することが必要で、通常はイベントデータをCRMまたはサポートチケットデータと結合する必要があります。エンジニアリングへの投資が必要です。しかし一度実現すれば、すべてのプロダクトリーダーが実際に知りたい質問に答えられます。自社のAIは顧客をより成功させているのか、それとも単にアクティビティを生み出しているだけなのか?
なぜ暗黙的フィードバックが明示的フィードバックに勝るのか
ここでの行動経済学的原理はプロダクト全体で一貫しています。人々は自分の好みを正確に自己申告しません。一方では一つのことを望むと言い、実際には別のことをします。AI機能のフィードバックにおいてもこれはまったく同様で、機能に関するアンケート回答と変わりません。
より実用的な観点からも: ほとんどのプロダクトで暗黙的フィードバックと明示的フィードバックの比率はおよそ50対1以上です。サムズダウンをクリックするユーザー1人につき、同等またはそれ以上の品質を持つ行動シグナルを50人のユーザーが発しています。明示的フィードバックのみを最適化することは、使えるシグナルの98%を無視することです。
Notion AIはこれを早くから学びました。彼らのAI文章提案は、明示的な評価ではなく、ユーザーが提案テキストをそのまま承認するか、修正するか、置き換えるかによって改良されています。プロダクトエンジニアは、どの提案タイプがそのまま使われ、どれが書き直され、どれが無視されるかを集計で確認できます。この集計ビューが次のバージョンのプロンプトエンジニアリングとモデル選定の決定を形成しています。
同様のパターンはLinearのAI機能開発にも見られます。バグのトリアージと優先度提案は、エンジニアがAIによる優先度提案をオーバーライドする頻度と、手動でオーバーライドした優先度が実際の解決緊急度と一致することが多いかどうかの組み合わせによって改良されています。モデルはラベル付きデータで訓練されるだけでなく、自分の提案と実際に起きたことのギャップからも学んでいます。
「ほとんどのプロダクトで暗黙的フィードバックと明示的フィードバックの比率はおよそ50対1以上です。サムズダウンをクリックするユーザー1人につき、同等またはそれ以上の品質を持つ行動シグナルを50人のユーザーが発しています。明示的フィードバックのみを最適化することは、使えるシグナルの98%を無視することです。」(Rework分析、LinkedInの行動経済学研究に基づく)
「静的なAI機能は中立ではありません。複利的な価値のないコストです。テレメトリを通じて改善されない月が続くたびに、自社のAI品質と本物のループを運用している競合との差は広がっていきます。ループを構築するという決断がAIインフラの決断です。モデルの選択はそれより重要ではありません。」(Rework分析, 2025)
シグナルの品質と量の比較
| シグナルタイプ | 収集難易度 | 量 | 品質/精度 | 主な用途 |
|---|---|---|---|---|
| 明示的(サムズアップ/ダウン) | 簡単 | 非常に低い(インタラクションの2〜3%) | 低(自己申告に一貫性なし) | まれなエッジケースのフラグ立て |
| 暗黙的承認 | 普通 | 高い(表示されたすべての提案) | 良い(誠実な行動シグナル) | 承認率、モデル改善 |
| 暗黙的修正 | 普通 | 高い(承認されたすべての提案) | 非常に良い(好みのギャップを示す) | プロンプトエンジニアリング、具体性の調整 |
| 結果フィードバック | 難しい(データ結合が必要) | 低い(セッションの一部) | 優秀(実際の価値を測定) | ROI測定、訓練シグナル |
出典: LinkedInのAI行動シグナル研究、Notion AIテレメトリドキュメント、McKinsey AI Software Development研究 2025
Rework分析: ほとんどのSaaSチームはテレメトリループのステージ1(イベント記録)を持ち、ステージ2と3(品質指標の測定とそれに基づく行動)をスキップしています。データはウェアハウスに積み上がり、誰も毎週確認しません。最小限のテレメトリループに必要なのは4つの要素です。SegmentまたはAmplitudeでのsuggestion_shown、suggestion_accepted、suggestion_modifiedイベント。機能別の週次承認率ダッシュボード。誰かが実際にデータを読む隔週のプロンプトレビューミーティング。そしてパフォーマンスが最も低い提案タイプのプロンプト変更をリリースするコミットメント。それがループの全てです。
AIテレメトリのスキーマ設計

イベントスキーマが重要です。曖昧なイベントは曖昧なシグナルを生みます。テレメトリがai_feature_used: trueのようなものであれば、修正率を計算できず、提案タイプ別にセグメント化できず、結果と相関させることもできません。
最小限のAIテレメトリスキーマは次のようになります。
suggestion_id: UUID (提案をライフサイクル全体で結びつける)
feature_id: string (どのAI機能がこれを生成したか)
session_id: string (ユーザーセッションコンテキストに接続)
context_hash: string (AIが受け取ったコンテキストのフィンガープリント)
suggestion_type: enum (draft, autocomplete, classification, recommendation)
suggestion_shown_at: timestamp
suggestion_accepted_at: timestamp or null
suggestion_modified: boolean
modification_delta: integer (提案から最終版までの文字編集距離)
user_dismissed: boolean
manual_completion: boolean (ユーザーが提案を使わずにタスクを完了した)
outcome_event_id: string or null (キャプチャされた場合、ダウンストリームの結果へのFK)
このスキーマによってテレメトリループの品質に重要なすべての指標を計算できます。context_hashは特に重要で、類似したコンテキストが時間の経過とともに一貫して良くなっているか悪くなっているかを特定できます。これはモデル改善の核心的な測定です。
SegmentまたはAmplitudeをイベントパイプラインとして使用しているチームにとって、このスキーマは標準プロパティを持つカスタムイベントにきれいにマッピングされます。outcome_event_idの結合にはサーバーサイドのエンリッチメントステップかデータウェアハウスでのダウンストリーム結合が必要です。スキーマが正しいイベントをキャプチャし始めたら、それらのシグナルをどう活用するかはAI機能がどのように構築されているかによって変わります。
モデル改善のためのループ活用
テレメトリデータをどう活用するかは、AI機能がどのように構築されているかによります。
GPT-4またはClaude APIベースの機能(2026年のSaaS AIで最も一般的なケース)の場合、改善メカニズムはプロンプトエンジニアリングです。特定の提案タイプで修正率が高い場合、プロンプトの具体性が不足していることを示します。AI提案後の一貫した手動完了は、提案がワークフローの誤ったタイミングで表示されていることを示します。基盤モデルに触れることなく毎週プロンプトを反復できます。
RAG (Retrieval-Augmented Generation)機能(生成前にナレッジベースから取得するAI)の場合、テレメトリは検索パラメータ調整にフィードバックされます。特定のナレッジベースセクションを引用したAI提案をユーザーが一貫して無視する場合、そのセクションは古くなっているか無関係です。テレメトリは、実際に使われる提案を生み出している検索ソースとノイズを教えてくれます。SaaSのAIナレッジベースメンテナンスでは、これらのシグナルに基づいて検索コーパスを最新に保つ方法を説明しています。
Fine-tunedまたはカスタムモデル(Series A-C SaaSでは稀)の場合、結果ラベル付きの高品質な暗黙的フィードバックが訓練データになります。修正率データは事実上、好みのデータセットです。結果相関データは強化シグナルです。これはGitHubがCopilotでスケールで採用しているアプローチですが、ほとんどのSaaSチームが成熟度ステージ4前に構築すべきでないMLインフラが必要です。
複利的なデータの堀
本物のテレメトリループを12ヶ月間運用した後、競合ポジションに変化が生まれます。
AI機能は、実際のユーザーが実際のユースケースで行う実際の行動から学んでいます。汎用的なインターネットテキストではありません。ベンチマークデータセットでもありません。自社ユーザーのパターン、自社ユーザーの好み、自社ユーザーが定義する「良い提案」です。
同じ機能を同じ基盤モデルでリリースする競合はゼロからスタートします。リリース時と同じAPIアクセス権を持っています。しかし自社の12ヶ月間のユーザー行動データはありません。購入することもできません。自分たちのループを12ヶ月間運用することで獲得するしかないのです。
これがテレメトリループが持続的な競合優位性になる仕組みです。誰でも利用できる技術からではなく、特定のユーザーに対して技術がどのように機能するかを形成する蓄積された行動データから生まれます。
複利効果は成熟度ステージ4と5で加速し、AI機能が機能横断的にシグナルを共有し始めます。プロダクト内AIの結果データがCustomer SuccessのAIヘルススコアリングに反映され、ヘルススコアリングAIの精度がプロダクト内AIの優先機能にフィードバックされれば、統合された学習システムを構築していることになります。それは本当に真似が難しいものです。McKinseyはこの複利的ダイナミクスを明確に説明しています。より速い実験がより多くのデータを生み、より多くのデータがモデル品質を改善し、より良いパフォーマンスがより多くのユーザーを引き寄せ、時間とともにこうしたループを運用している組織とそうでない組織の差は構造的なものになります。SaaS AIの成熟度ステージでは、この機能横断的な統合が各ステージでどのように見えるかを説明しています。
プライバシーと同意の要件
モデル訓練のために収集されたユーザーフィードバックはコンプライアンスの観点から自由ではありません。GDPR(一般データ保護規則)第22条とCCPA(カリフォルニア消費者プライバシー法)はいずれも自動意思決定とデータ利用に関する要件を持っています。ユーザーへの提案を行うAI機能の改善に行動データを使用することは、一部の解釈では自動意思決定の範囲に含まれる可能性があります。
ほとんどのSaaS企業に求められる実用的な要件はこれです。利用規約とプライバシーポリシーに、AI機能の改善のためにプロダクト利用データを収集することを明示し、ユーザーには明確なオプトアウト手段を提供する必要があります。NISTのAIリスク管理フレームワークは、行動フィードバックデータがAI改善パイプラインをどのように流れるかを文書化するための有用な構造を提供しています。これはSaaSツールを承認する前に独自のAIガバナンスレビューを実施するエンタープライズ調達チームにとって重要性が増しています。これはより厳格な同意要件を持つユーザーコンテンツに基づくAI訓練とは異なります。
UXの摩擦に関する懸念は現実ですが解決可能です。Notion、Linear、そして主要なSaaS AIプロダクトのほとんどは、収集内容、用途、オプトアウト方法を説明するプライバシー設定セクションで対応しています。大半のユーザーはオプトアウトしません。しかしその仕組みを持つことはコンプライアンスと信頼のために重要です。
より重要なルール: 明示的な同意なしに、特定の顧客のデータを他の顧客向けのAI改善に使用しないでください。集計された行動パターンは一般的に問題ありません。訓練例として使用される特定のユーザー生成コンテンツにはより強固な同意アーキテクチャが必要です。
アンチパターン: 学習しないAI機能
テレメトリループの対極にあるのが、初日から静的なAI機能です。ユーザーが何をしても、同じモデル、同じプロンプト、同じ提案が続きます。こうした機能は今多くのSaaSプロダクトに存在しています。AIをチェックボックスとして扱ったチームが構築したものです。「リリースした、AIだから」というわけです。
静的なAI機能のサイン:
- 6ヶ月の間隔で提案品質が改善されない
- チームがAI機能指標の週次レビューを持っていない
- データチームが承認率や修正率を追跡するダッシュボードを持っていない
- プロンプト変更にスプリントサイクルが必要で、最良でも四半期に一度しか行われない
静的なAI機能は中立ではありません。複利的な価値のないコストです。改善されない月が続くたびに、自社のAI品質と本物のループを運用している競合との差は広がっていきます。
ループを構築するという決断がAIインフラの決断です。モデルの選択はそれより重要ではありません。
実際に「ループが閉じた」状態とは
閉じたテレメトリループは週次の儀式を生み出します。AI機能指標のレビューです。承認率の上昇・下降。提案タイプ別の修正率。動いている結果相関。シグナルに基づいて調整されたプロンプト。リリースされた新バージョン。
GitHub CopilotのエンジニアリングチームはGitHub Copilot Engineering Blogに、承認データと編集距離指標を使ってモデルの変更を評価する方法について定期的な投稿を公開しています。LinearのChangelogは、ほぼ毎月のリリースでAI優先度スコアリングの改善を示しています。これは偶然ではありません。ループがあるのです。
チームにとっての最小限のテレメトリループは:
- SegmentまたはAmplitudeの
suggestion_shown、suggestion_accepted、suggestion_modifiedイベント - 機能別の承認率と修正率を示す週次ダッシュボード
- 誰かが実際にデータを読む隔週のプロンプトレビューミーティング
- パフォーマンスが最も低い提案タイプを改善するプロンプト変更へのコミットメント
それだけです。それがループです。MLエンジニアリングは必要ありません。プロダクトの規律です。
2027年と2028年にAI機能の品質を勝ち取る企業は、2025年に最良のモデルを選んだ企業ではありません。2025年にループを構築して継続させた企業です。
よくある質問
プロダクト内AIのテレメトリループとは何ですか?
テレメトリループは、AI機能が何を提案し、ユーザーが次に何をし、その後どのような結果になったかを記録し、それらのシグナルをモデルまたはプロンプトの改善にフィードバックする構造化されたシステムです。3つの段階はCapture(構造化されたイベント収集)、Measure(集約されたシグナルからの品質指標)、Improve(プロンプトエンジニアリング、検索調整、または訓練データ)です。3つの段階がすべて揃わなければループではなくアーカイブです。
AIテレメトリで暗黙的フィードバックが明示的な評価より価値がある理由は?
明示的な評価(サムズアップ/ダウン)はユーザーの2〜3%しか行わず、好みを正確に反映しません。ユーザーは一貫して自己申告しません。暗黙的シグナル(提案を承認、修正、または無視する)は100%のインタラクションから生成され、誠実な行動を反映します。比率はおよそ50対1です。明示的フィードバックのみを最適化することは、使えるシグナルの98%を無視することです。
AIテレメトリの2つの主要な暗黙的指標は何ですか?
提案承認率(ユーザーはAIの提案を修正なしでどれだけ使用しますか?)と修正率(承認した提案のうち、確定前に編集されたものはどれだけですか?)です。修正率が高い場合はAIの方向性は正しいが具体性が不足していることを意味します。承認率が低く手動完了率が高い場合は、トリガーポイントまたは品質基準が間違っていることを意味します。異なる指標には異なる修正が必要です。
テレメトリループはどのように競合優位性を生み出しますか?
本物のテレメトリループを12ヶ月間運用した後、AI機能は実際のユーザーが実際のユースケースで行う実際の行動から学んでいます。同じ機能を同じ基盤モデルでリリースする競合はゼロからスタートします。リリース時と同じAPIアクセスはありますが、自社の12ヶ月間のユーザー行動データはありません。購入することもできません。自分たちのループを12ヶ月間運用することで獲得するしかないのです。
最小限のテレメトリループとは?
4つの要素です。SegmentまたはAmplitudeでのsuggestion_shown、suggestion_accepted、suggestion_modifiedイベント。機能別の承認率と修正率を示す週次ダッシュボード。誰かが実際にデータを読む隔週のプロンプトレビューミーティング。そしてパフォーマンスが最も低い提案タイプのプロンプト変更をリリースするコミットメント。この段階ではMLエンジニアリングは不要です。プロダクトの規律だけです。
行動テレメトリとAI訓練にはどのようなコンプライアンス要件がありますか?
GDPRの第22条とCCPAはいずれも自動意思決定とデータ利用に関する要件を持っています。利用規約とプライバシーポリシーには、AI機能の改善のためにプロダクト利用データを収集することを明示し、明確なオプトアウト手段を提供する必要があります。明示的な同意なしに特定の顧客のコンテンツを他の顧客向けのAI改善に使用しないでください。集計された行動パターン(承認率、修正率)は一般的に問題ありません。訓練例として使用される特定のユーザー生成コンテンツにはより強固な同意アーキテクチャが必要です。
関連記事:
- AIのIngest Capabilityとは: テレメトリループが構築されるACE Ingestレイヤー
- AIパターンのCapabilityの組み合わせ方: テレメトリデータが複数のAIパターンにわたってどのように複利的に機能するか
- 製品としてのAI機能: どこに追加するか: テレメトリループを構築する価値のある機能を特定する方法
- SaaS製品UIに埋め込まれたAI Copilot: 最も豊富なテレメトリシグナルを生成する埋め込みAI機能
- SaaS AIの成熟度ステージ: 機能横断的なテレメトリ統合が成熟度ステージ全体でどのように発展するか
- SaaS AIのプロダクトテレメトリアドバンテージ: SaaSテレメトリが純粋AIの競合に対してどのように構造的な堀を生み出すか
