Etapa 2 a 3: De Piloto a Escalado, Escapando del Purgatorio del Piloto
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Su piloto de AI funcionó. A los usuarios les gusta. Los primeros números son alentadores. El equipo de representantes de desarrollo de ventas ahorra tres horas a la semana en personalización de emails. Las tasas de respuesta subieron un 12%. El responsable del piloto presenta los resultados. El liderazgo asiente.
Entonces alguien pregunta: "¿Cómo escalamos esto?"
Y de repente nadie sabe la respuesta.
Esto es el purgatorio del piloto. Es el espacio entre "el piloto funcionó" y "tenemos AI corriendo en producción". Es donde la mayoría de las organizaciones de Etapa 2 se quedan atascadas, a veces un año, a veces más. Forrester identifica la dispersión de casos de uso como una de las mayores barreras para escalar la AI: las empresas a menudo tienen docenas de pilotos pero carecen de un framework para priorizarlos y activarlos. El piloto permanece en el limbo mientras el equipo debate infraestructura, espera el presupuesto, discute sobre la titularidad, o simplemente ejecuta otro piloto porque eso se siente más seguro que el compromiso que requiere la producción.
Entender por qué ocurre el purgatorio del piloto es el primer paso para escapar de él. Si todavía está en la Etapa 1, lea primero Etapa 1 a 2: De Ad-Hoc a Piloto.
Cómo se ve el purgatorio del piloto
Datos Clave: Desafíos de Piloto a Escala
- Forrester identifica la dispersión de casos de uso como una de las mayores barreras para escalar AI; las empresas a menudo tienen docenas de pilotos pero carecen de un framework para priorizarlos y activarlos en producción (Forrester, 2025)
- Las organizaciones que han escalado AI (Etapa 3+) generan retornos totales para los accionistas a 3 años aproximadamente 4 veces más altos que los rezagados en AI; la brecha entre líderes y rezagados se amplía con cada año de retraso en la Etapa 2 (BCG, 2025)
- McKinsey encontró que pasar de pilotos exitosos de AI al despliegue en toda la empresa requiere adoptar una mentalidad de escalado, tomar un enfoque modular para construir activos de AI y acortar el ciclo de vida de desarrollo de analítica, requisitos para los que la mayoría de los equipos en etapa de piloto no están estructurados (McKinsey, 2025)
El purgatorio del piloto tiene síntomas consistentes.
Pilotos que permanecen en piloto durante 12+ meses. El límite de tiempo establecido en el acta va y viene. Nadie decide explícitamente escalar. Nadie cierra explícitamente el piloto. Simplemente sigue corriendo a bajo volumen, consumiendo algo de esfuerzo sin entregar valor a escala de producción.
Múltiples herramientas competidoras evaluadas simultáneamente. En lugar de comprometerse con una herramienta y escalarla, el equipo abre evaluaciones de dos o tres alternativas. "Queremos asegurarnos de elegir la correcta." Dieciocho meses después todavía no han elegido ninguna.
Ejecutivos esperando "un punto de dato más". El piloto produjo buenos resultados, pero el liderazgo quiere un tamaño de muestra más grande, un período de tiempo más largo, o un caso de uso más complejo antes de comprometerse. El listón sigue moviéndose.
Sin decisiones de infraestructura tomadas. El piloto corrió en una configuración de nube gestionada por el proveedor sin compromisos arquitectónicos de la empresa. El escalado requeriría decisiones sobre almacenamiento de datos, alojamiento de modelos, titularidad de API y monitoreo que nadie ha tomado todavía.
El equipo del piloto está agotado. Las mismas tres personas que ejecutaron el piloto están siendo pedidas para ejecutar los próximos dos pilotos mientras también se les pide descubrir cómo escalar el primero. Están extendidas, sin estructura y empezando a desconectarse. El análisis de McKinsey encontró que hacer la transición de pilotos exitosos de AI al despliegue efectivo de AI en toda la empresa requiere adoptar una mentalidad de escalado, tomar un enfoque modular para construir activos de AI y acortar el ciclo de vida de desarrollo de analítica, ninguna de las cuales puede hacer un equipo agotado de tres personas.
Si dos o más de estas afirmaciones son verdaderas, está en el purgatorio del piloto. La salida requiere disciplina de ejecución, no más evaluación.
"La transición de Etapa 2 a 3 falla más a menudo no porque el piloto era incorrecto sino porque el equipo trata el despliegue en producción como una versión más grande del piloto. No lo es. La producción requiere compromisos de infraestructura, gestión del cambio más allá de los voluntarios, gobernanza de costos y un responsable de Operaciones de AI nombrado. Las empresas que ejecutan la Etapa 3 con infraestructura de Etapa 2 enfrentan incidentes, sorpresas de costos y colapso de adopción." (Rework)
El Test de Cruce de Etapa 2 a 3
Un diagnóstico de cuatro requisitos que confirma que una organización ha cruzado genuinamente de la Etapa 2 a la Etapa 3, en lugar de reetiquetado un piloto escalado como producción. Requisito 1: Un caso de uso está desplegado para todos los usuarios previstos (no un cohorte de voluntarios), con monitoreo activo. Requisito 2: Las decisiones de infraestructura compartida están documentadas y comprometidas (proveedor de modelo, base de datos vectorial, stack de observabilidad), no ad hoc por caso de uso. Requisito 3: Un segundo caso de uso está en piloto activo usando la infraestructura del Requisito 2 como su base. Requisito 4: Existe un responsable de Operaciones de AI nombrado con responsabilidad explícita por el tiempo de actividad de los sistemas de producción, los incidentes y el versionado de modelos. Las organizaciones que cumplen solo el Requisito 1 están ejecutando un piloto escalado, no un despliegue de Etapa 3.
Criterios de salida de la Etapa 3
La Etapa 3 no es simplemente "más pilotos". Es una postura operativa cualitativamente diferente. Esto es lo que debe ser verdad para reclamarla.
| Requisito | Qué significa | Brecha común |
|---|---|---|
| Un caso de uso en producción | Desplegado para todos los usuarios previstos, no solo un cohorte de voluntarios. Despliegue completo con monitoreo en su lugar. | Todavía ejecutándose a escala de piloto solo para los usuarios "correctos" |
| Decisiones de infraestructura compartida tomadas | Base de datos vectorial, proveedor de modelo, herramientas de guardrails y stack de observabilidad: seleccionados y comprometidos | Todavía usando la infraestructura ad hoc del piloto. Cada caso de uso corriendo en stacks de proveedores separados. |
| Un segundo caso de uso en piloto activo | Prueba de que el aprendizaje del Piloto 1 se transfirió al Piloto 2. No solo planeado: en ejecución. | Toda la energía fue a escalar el Piloto 1. Sin capacidad para nuevos casos de uso. |
| Titularidad de Operaciones de AI | Individuo nombrado o equipo pequeño responsable de los sistemas de AI de producción: tiempo de actividad, respuesta a incidentes, versionado de modelos | Responsable del piloto todavía ejecutando producción además de su trabajo diario |
Los cuatro requisitos deben ser verdad antes de llamar a la organización Etapa 3. El que más comúnmente se omite es la infraestructura compartida. También es el que causa los problemas más costosos si se omite.
Las decisiones de infraestructura que requiere la Etapa 3
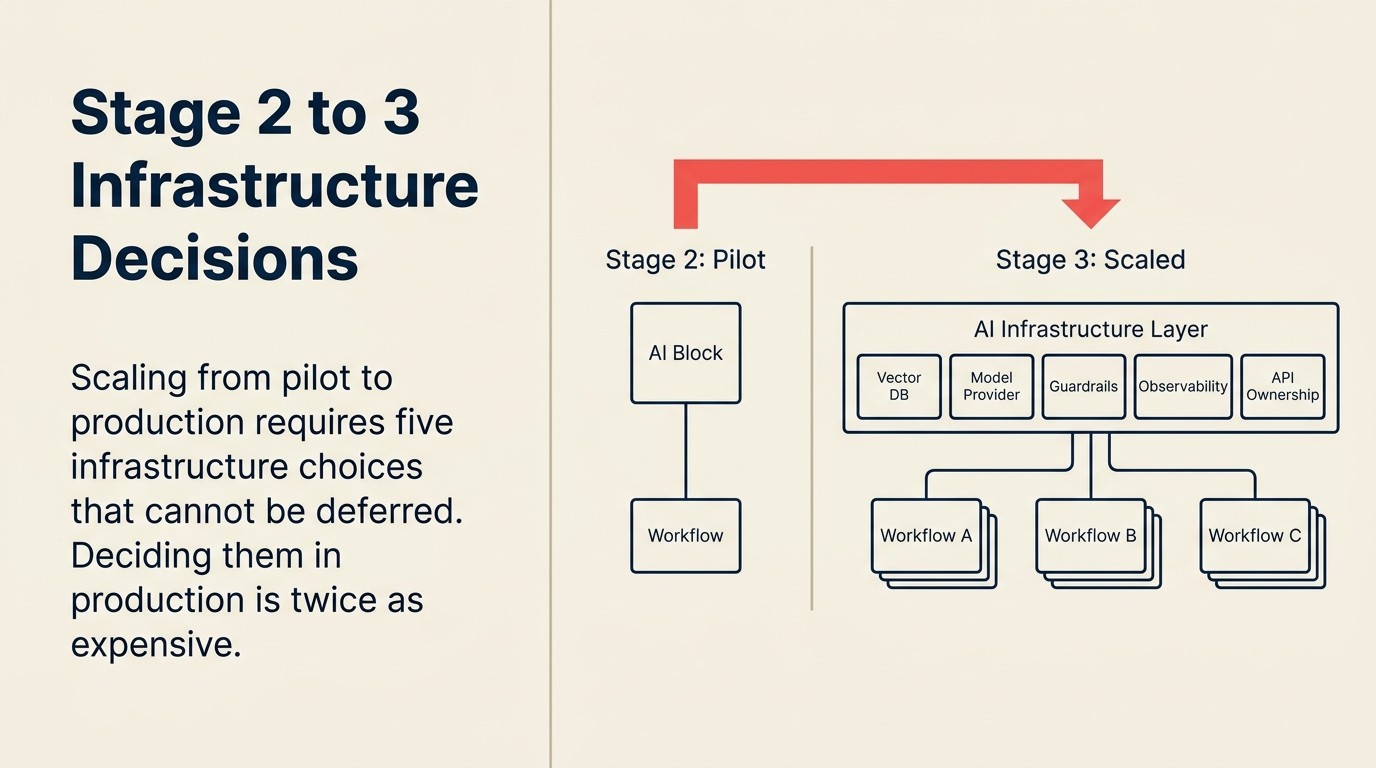
Esta es la parte que sorprende a la mayoría de los líderes de transformación que vienen de un entorno de compra de SaaS. La AI a escala de producción requiere compromisos arquitectónicos que no aplican a las herramientas ordinarias de SaaS. Debe tomar estas decisiones antes del escalado, no después.
Elección de base de datos vectorial. Si sus aplicaciones de AI implican generación aumentada por recuperación (RAG), búsqueda en documentos internos o memoria entre interacciones, necesita una base de datos vectorial. Las principales opciones en 2026 son Pinecone, Weaviate, Qdrant y pgvector (para equipos ya en PostgreSQL). La elección importa menos que tomarla. Ejecutar diferentes casos de uso en diferentes almacenes vectoriales crea fragmentación que es costosa de revertir.
Decisiones de proveedor de modelo. ¿Con qué proveedores de modelos de lenguaje de gran escala (LLM) está estandarizando? ¿OpenAI, Anthropic, Google o una combinación? Los acuerdos empresariales tienen diferentes precios, términos de manejo de datos y características de rendimiento. Usar el nivel gratuito de ChatGPT para pilotos está bien. Las cargas de trabajo de producción necesitan acuerdos empresariales adecuados con Acuerdos de Procesamiento de Datos (DPA) y compromisos de SLA.
Herramientas de guardrails. ¿Cómo evita que la AI produzca outputs dañinos, incorrectos o que no corresponden a la marca a escala? En la etapa de piloto, un humano revisa cada output. A escala de producción, eso no es posible. Los guardrails corren como capas de pre y post-procesamiento alrededor de las llamadas al modelo. Las opciones van desde la ingeniería de prompts personalizada hasta herramientas de propósito específico como Guardrails AI o las capas de seguridad de LlamaIndex.
Stack de observabilidad. ¿Cómo sabe cuándo su AI está rota? A escala de piloto, el responsable del piloto lo nota. A escala de producción, necesita registro, alertas y dashboards. Qué métricas importan: latencia de respuesta, tasa de error, tasa de fallback, disparadores de revisión humana. Este es el único componente de infraestructura que la mayoría de los equipos descubre que necesita solo después de un incidente de producción.
Titularidad de API y límites de velocidad. ¿Quién posee las claves de API para sus proveedores de modelo? En la etapa de piloto: probablemente la persona que configuró el piloto. A escala de producción: una cuenta de servicio propiedad de IT, con límites de velocidad establecidos para prevenir picos de costos y con políticas de rotación por seguridad.
Estas no son decisiones de IT de forma aislada. Son compromisos arquitectónicos que afectan a cada caso de uso de AI que construirá después. Tomarlas conjuntamente, antes de escalar, ahorra meses de reelaboración.
La lista de verificación de despliegue en producción

"Vamos a poner esto en producción" significa cosas diferentes para diferentes equipos. Para los sistemas de AI, la producción tiene un significado específico. Estas ocho cosas deben ser verdad.
1. El monitoreo está activo. No "lo revisaremos ocasionalmente." Monitoreo activo con alertas para picos de tasa de error, degradación de latencia y patrones de output inusuales.
2. La lógica de fallback existe. Cuando la AI falla (tiempo de espera del modelo, activación de guardrail, límite de velocidad), ¿qué pasa? El usuario no debe ver una pantalla en blanco ni un mensaje de error sin procesar. Defina el fallback: mostrar output en caché, encolar para revisión humana, rechazar cortésmente.
3. Las puertas de revisión humana están definidas. ¿Qué outputs requieren revisión humana antes de la acción? Para comunicaciones externas redactadas por AI, defina si el humano revisa antes de enviar (requerido) o después de enviar (demasiado tarde). Establezca esta regla antes de entrar en funcionamiento.
4. El versionado del modelo está rastreado. Cuando el proveedor de modelos actualiza su modelo, sus outputs pueden cambiar. Necesita un registro de qué versión del modelo estaba corriendo cuándo, para poder diagnosticar cambios de output inexplicables.
5. La respuesta a incidentes existe. Si la AI envía información incorrecta a un cliente, ¿a quién llama? ¿En qué orden? ¿Cuál es el SLA para la resolución? Escriba el runbook antes de necesitarlo.
6. La comunicación con usuarios está hecha. Todos los usuarios previstos saben que la AI está corriendo en producción, entienden qué hace, y han sido capacitados sobre cómo revisar, corregir y escalar los outputs.
7. El monitoreo de costos está activo. Las cargas de trabajo de AI de producción pueden generar picos de costos inesperados. El consumo de tokens, el volumen de llamadas a la API y la selección de modelos afectan el costo. Alguien posee el reporte de costos mensual.
8. Los acuerdos de procesamiento de datos están firmados. Si la AI procesa datos personales o datos confidenciales de la empresa, el DPA de su proveedor debe estar en vigor antes de la producción. "Agregaremos el DPA después de escalar" es una violación de cumplimiento, no un ítem de backlog.
Esta lista de verificación es la diferencia entre "desplegado" y "producción". La mayoría de los equipos cumple 5 de 8. Los tres que omiten son los que causan incidentes.
Escalando la gestión del cambio: de voluntarios a todos
Los pilotos corren con voluntarios. Las personas en su cohorte de piloto levantaron la mano. Estaban curiosas sobre la AI, dispuestas a experimentar y tolerantes con los bordes ásperos. No son una muestra representativa de toda su población de usuarios.
La escala de producción involucra a todos. Y todos incluye a los escépticos, los con tiempo limitado, los "esto parece más trabajo no menos", y los que están en silencio preocupados de que si la AI hace bien su trabajo, no tendrán trabajo.
Aquí es donde más comúnmente se estancan las transiciones de Etapa 2 a 3. El piloto funcionó en 20 representantes de desarrollo de ventas que se ofrecieron como voluntarios. El equipo completo tiene 80 SDRs, incluidos 30 que llevan cinco años haciendo este trabajo y no están entusiasmados con cambiar su workflow.
El playbook de gestión del cambio para la Etapa 3 tiene cuatro partes.
Capacite para el nuevo workflow, no para la herramienta. Los empleados resisten las herramientas. Aceptan las mejoras de workflow. No ejecute "capacitación en herramientas de AI". Ejecute "recorrido del nuevo workflow de SDR" que resulta incluir la herramienta de AI. Muestre el antes y el después. Haga visible el ahorro de tiempo.
Dé a los escépticos una entrada segura. No exija la AI como único camino. Deje que los escépticos la usen opcionalmente al principio. La prueba social de colegas obteniendo mejores resultados es más persuasiva que un mandato ejecutivo.
Aborde el miedo directamente. Si no nombra explícitamente la preocupación "¿me reemplazará esto?", dominará cada conversación informal sobre el despliegue. Nómbrelo en la reunión general. Describa la evolución del rol: lo que maneja la AI, lo que hacen los humanos que la AI no puede. Sea específico. La vaguedad empeora el miedo.
Mida la adopción, no solo los resultados. ¿Cuántos usuarios están realmente usando el workflow de AI a diario? ¿Semanalmente? ¿Para nada? Rastree la adopción con la misma seriedad que rastrea los resultados del negocio. La baja adopción explica los resultados de bajo rendimiento, y es reparable si se detecta pronto.
Gobernanza en la Etapa 3: del borrador a la función
En la Etapa 2, tenía una política mínima viable. En la Etapa 3, tiene AI corriendo en producción en múltiples casos de uso. Los requisitos de gobernanza se expanden en consecuencia.
Función de aprobación de herramientas. Alguien revisa las solicitudes de nuevas herramientas de AI, aplica el framework de clasificación de datos y emite aprobaciones. No un comité. Una persona con un proceso y un plazo de respuesta.
Titularidad de incidentes. Cuando ocurre un incidente de AI de producción (output incorrecto, exposición de datos, fallo del modelo), ¿quién posee la resolución? En la Etapa 3, esto es un rol nombrado: líder de Operaciones de AI o equivalente. No una lista de email compartida.
Revisión trimestral de política. La AI avanza rápido. Su lista de herramientas aprobadas de hace seis meses puede incluir herramientas que han cambiado sus términos de manejo de datos. Cree un evento de calendario: revisión trimestral, dos horas, lista de herramientas aprobadas más registro de incidentes.
Línea base de registros de auditoría. Para cada workflow de AI con capacidad Execute (AI que toma acciones en sistemas), necesita un registro de lo que hizo la AI, cuándo y con qué resultado. Este es un requisito legal y de cumplimiento a escala de producción en la mayoría de las jurisdicciones, y es la base para solucionar problemas cuando algo sale mal. Consulte Registros de Auditoría para Acciones Execute de AI para conocer los requisitos de un registro de auditoría de grado de producción.
Análisis de Rework: Basado en patrones de despliegue de AI empresarial, las tres decisiones de infraestructura que más comúnmente se difieren hasta después de un incidente de producción son: el stack de observabilidad (los equipos descubren que lo necesitan cuando no pueden diagnosticar por qué los outputs se degradaron), los Acuerdos de Procesamiento de Datos con proveedores de modelo (abordados post-despliegue cuando Legal señala la brecha de cumplimiento), y el monitoreo de costos (revelado cuando llega la primera factura sorpresa). Los tres son baratos de implementar antes de la producción. Los tres son costosos de retrofitar después de un incidente. La lista de verificación de despliegue en producción de este artículo está específicamente secuenciada para garantizar que los tres se aborden antes de entrar en funcionamiento.
El recálculo de ROI en la Etapa 3
Los pilotos demuestran la factibilidad. La producción demuestra la economía. Estas son preguntas diferentes.
Un piloto con 20 usuarios durante 60 días que ahorra 3 horas por usuario por semana se ve así en términos anualizados: 20 usuarios x 3 horas x 48 semanas = 2.880 horas ahorradas. A un costo totalmente cargado promedio de $50/hora, eso es $144.000 en valor laboral anualizado.
Pero ¿qué cuesta realmente ejecutar esa AI en producción? Costos de API de modelo, tiempo del equipo de Operaciones de AI, costos de infraestructura, overhead de monitoreo. Si el costo total de propiedad anual es de $40.000, el ROI es de $104.000 neto. Ese es un caso de negocio claro.
Ejecute este cálculo antes de su compromiso de escalado en la Etapa 3. Y use números reales, no los precios de la etapa de piloto del proveedor. Pida a su proveedor de modelo precios de producción a su volumen esperado de tokens. Pregunte cuánto cuesta el tiempo de su contratación de Operaciones de AI. Agregue un 20% por overhead que no ha anticipado.
Un ejemplo real de Etapa 2 a 3
Una empresa SaaS de 200 personas ejecutó un piloto exitoso con un Agente de Soporte de AI en el T3 de 2025. El piloto mostró que la AI podía resolver el 35% de los tickets de soporte entrantes sin participación humana, liberando 15 horas por semana por ingeniero de soporte.
Antes de escalar, tomaron tres decisiones de infraestructura: se estandarizaron en OpenAI Enterprise para su proveedor de modelos, se comprometieron con Pinecone como su base de datos vectorial para la base de conocimiento de soporte, y desplegaron LangSmith para la observabilidad.
Contrataron a un Líder de Operaciones de AI en el T4 de 2025. Esa persona fue dueña de la lista de verificación de despliegue en producción, ejecutó la capacitación de usuarios, escribió el runbook de incidentes y configuró el dashboard de monitoreo de costos.
Para el T1 de 2026, el Agente de Soporte de AI estaba en producción para todo el equipo de soporte. En paralelo, lanzaron el Piloto 2: un asistente de Operaciones de Ventas con AI que redacta resúmenes de llamadas y recomendaciones de próximos pasos directamente en el CRM. Ese piloto está en ejecución ahora, con la infraestructura del Piloto 1 como base.
No ejecutaron cinco pilotos en paralelo. Ejecutaron uno bien, comprometieron la infraestructura y usaron esa base para el siguiente. Esa es la transición de Etapa 2 a 3 hecha correctamente.
Qué sigue
El despliegue en producción es la Etapa 3. El paso a la Etapa 4 es de un orden de magnitud diferente: AI no como una capa encima de sus workflows sino tejida en su modelo operativo central. La mayoría de las empresas del mercado medio no estarán listas para la Etapa 4 durante otros dos o tres años.
Pero entender qué requiere la Etapa 4 ayuda a invertir correctamente en la Etapa 3. No solo está escalando herramientas. Está construyendo la infraestructura y la gobernanza de la que depende la Etapa 4. Esa inversión se compone hacia adelante.
Lea: Etapa 3 a 4: De Escalado a Integrado para los requisitos organizacionales y arquitectónicos.
Lea: Las 5 Etapas de Madurez de AI para ver el modelo completo de madurez y dónde se ubica la Etapa 3.
Lea: Playbook de Respuesta a Incidentes de AI antes de su primer despliegue en producción. Querrá tenerlo listo antes de necesitarlo.
Vea también:
- El Costo Honesto de la Transformación con AI: la inversión en infraestructura requerida en la Etapa 3 modelada contra el caso de negocio
- Secuenciando Patrones de AI en un Roadmap Plurianual: cómo priorizar sus casos de uso segundo y tercero después de que el Piloto 1 tenga éxito

Co-Founder, Rework.com
On this page
- Cómo se ve el purgatorio del piloto
- El Test de Cruce de Etapa 2 a 3
- Criterios de salida de la Etapa 3
- Las decisiones de infraestructura que requiere la Etapa 3
- La lista de verificación de despliegue en producción
- Escalando la gestión del cambio: de voluntarios a todos
- Gobernanza en la Etapa 3: del borrador a la función
- El recálculo de ROI en la Etapa 3
- Un ejemplo real de Etapa 2 a 3
- Qué sigue