Alfabetización en AI: La Nueva Habilidad del Lugar de Trabajo que Toda Organización Necesita
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
"Todos necesitan aprender AI" es el mandato que emana de directorios y equipos ejecutivos en 2026. Pero, ¿qué significa eso en realidad para un gerente de cuentas de 52 años que nunca ha usado ChatGPT? ¿O para un representante junior de Customer Success que lo usa a diario para borradores de email pero nunca ha cuestionado si lo que le dijo era preciso?
La alfabetización en AI no es una sola habilidad. Es un conjunto de competencias que difieren según el rol, el nivel de responsabilidad y el perfil de riesgo de las herramientas de AI que cada persona usa. La misma organización necesita que sus colaboradores individuales (ICs) dominen la verificación de outputs, que sus gerentes rediseñen flujos de trabajo asistidos por AI y que sus ejecutivos gobiernen las decisiones de inversión en AI, y esos son tres programas diferentes, no una única sesión de capacitación obligatoria.
Comprender dónde encaja cada rol en el ACE Framework ayuda a calibrar qué componentes de alfabetización importan más. Los empleados que operan en el límite de Execute necesitan las habilidades de verificación más sólidas. Los empleados que solo usan capacidades Generate necesitan profundidad en ingeniería de prompts.
Este artículo define los cuatro componentes de la alfabetización en AI, los mapea a los niveles de rol y ofrece a los COOs y CHROs una estructura de programa que realmente funciona para empleados no técnicos, incluidos los más escépticos y los que corren mayor riesgo de usar AI de manera deficiente.
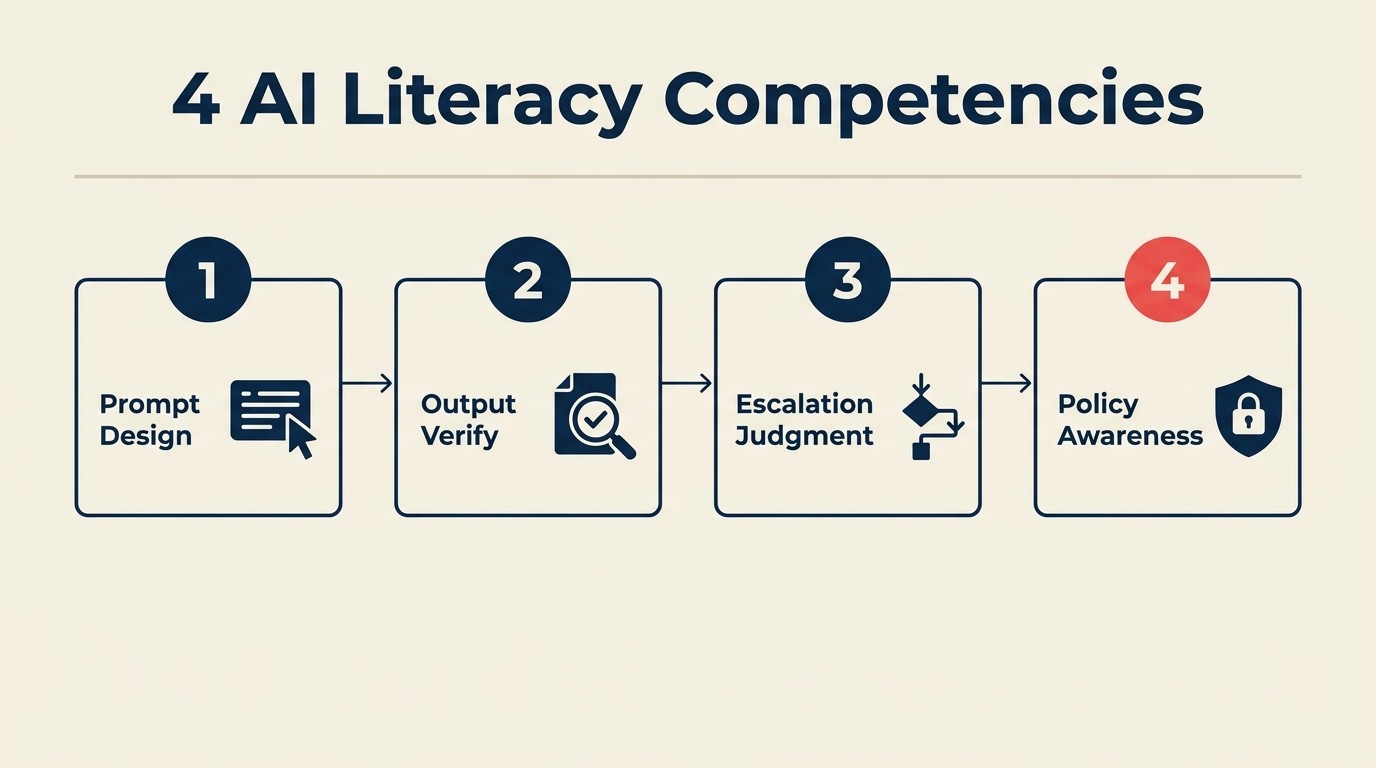
Los cuatro componentes de la alfabetización en AI

Key Facts: La Brecha de Alfabetización en AI
- El 59% de la fuerza laboral global requerirá capacitación para 2030, con AI y macrodatos encabezando la lista de habilidades necesarias, pero solo el 35% de las organizaciones actualmente tiene un programa maduro de actualización de habilidades para toda la fuerza laboral. (WEF / DataCamp)
- Las organizaciones con programas formales de capacitación en AI logran una adopción de AI 2,3 veces más rápida y un ROI de AI un 67% mayor en comparación con las que dependen del aprendizaje informal. (OCDE)
- El 42% de los empleados dice que su empleador espera que aprendan AI por su cuenta, mientras que el 34% reporta sentirse no preparado para los cambios impulsados por AI en su rol. (DataCamp 2026 Literacy Report)
Estos no son cuatro niveles de sofisticación. Son cuatro competencias distintas. Alguien puede ser excelente en ingeniería de prompts y pésimo en verificación de outputs. Ambas importan. Tratar la alfabetización en AI como un espectro de "principiante a avanzado" pasa por alto esa brecha.
El Informe del Futuro del Empleo 2025 del WEF estima que el 59% de la fuerza laboral global requerirá capacitación para 2030, con AI y macrodatos encabezando la lista de habilidades necesarias, aunque lo que "habilidades de AI" significa operativamente para un analista financiero o un representante de Customer Success difiere dramáticamente de lo que significa para un científico de datos.
1. Bases de ingeniería de prompts
No es programación. No es "construir sistemas de AI." Solo es disciplina de comunicación con AI.
La ingeniería de prompts, al nivel necesario para la alfabetización laboral, es la habilidad de dar al AI instrucciones claras y ricas en contexto que produzcan un output útil. Incluye entender que los prompts vagos producen outputs vagos, que proporcionar contexto y ejemplos mejora dramáticamente los resultados y que iterar en un prompt cuando el primer output es incorrecto es una habilidad, no una señal de fracaso.
Para un representante de ventas, esto significa saber que "escríbeme un email para este prospecto" produce peores resultados que "escribe un email de primer contacto para un VP de Operaciones en una empresa de logística de 150 personas que ha expresado interés en reducir el trabajo manual de reportes. Tono: directo y breve. Extensión: menos de 150 palabras. Incluye una pregunta específica al final."
Eso no es conocimiento técnico. Es disciplina de comunicación que se puede enseñar en una tarde y refinar en unas pocas semanas de práctica.
Lo que no es: aprender a escribir código, entender la arquitectura de modelos de lenguaje de gran escala o convertirse en un "experto en AI." Los empleados que escuchan "ingeniería de prompts" y asumen que requiere formación en ciencias de la computación se desconectarán. El encuadre importa.
2. Verificación de outputs
Este es el componente más subestimado y la brecha más peligrosa en la mayoría de las organizaciones.
Los sistemas de AI generan output que suena seguro independientemente de su precisión. Una alucinación bien documentada de un modelo de lenguaje de gran escala (LLM) importante citó un artículo académico inexistente con un autor, revista y título que sonaban reales. La persona que lo recibió no lo verificó. Lo citó en un informe para un cliente. El cliente se dio cuenta.
La verificación de outputs es el hábito de preguntar: ¿es esto realmente cierto? ¿Dónde lo verificaría? ¿Cuándo requiere este output verificación antes de actuar sobre él? ¿Cuándo no?
La mayoría de los empleados que usan herramientas de AI no han desarrollado este hábito porque no se les ha enseñado que el output de AI es probabilístico, no autoritario. El modelo mental que muchos empleados tienen se acerca más a "AI es como un motor de búsqueda muy inteligente" que a "AI genera respuestas plausibles que son frecuente pero no siempre precisas." La diferencia de comportamiento entre esos dos modelos mentales es significativa.
Específicamente: un empleado que piensa que AI es como una búsqueda confiará en los outputs de alta confianza. Un empleado que entiende AI como probabilístico preguntará "¿cuál es la consecuencia si esto está mal?" antes de actuar en consecuencia. Para un primer borrador de bajo riesgo de un email interno, la consecuencia es menor. Para una respuesta de cumplimiento, un cálculo financiero o una afirmación sobre un competidor en un documento de ventas, la consecuencia es significativa.
La verificación de outputs significa hacer coincidir el esfuerzo de verificación con la consecuencia del error, no verificar todo ni confiar en todo.
3. Juicio de cuándo escalar
Un subconjunto de la verificación de outputs, pero suficientemente específico para merecer su propio componente.
El juicio de cuándo escalar es la decisión sobre qué outputs de AI requieren revisión humana antes de actuar y cuáles pueden proceder. Esto es especialmente importante para todo lo que toca decisiones de capacidad Execute: outputs de AI que se enviarán a clientes, se ingresarán en sistemas financieros o se actuarán sin un segundo par de ojos. El artículo Riesgo de Alucinación por Patrón ofrece a empleados y gerentes un mapa concreto de riesgos para qué patrones de AI requieren la mayor disciplina de verificación.
Los empleados sin este juicio cometen uno de dos errores. O sobre-verifican (creando un cuello de botella donde cada output de AI recibe revisión humana, eliminando las ganancias de eficiencia), o sub-verifican (enviando contenido generado por AI sin verificar, creando problemas de calidad o peores).
La versión organizacional de esta competencia es el diseño de rutas de escalación: construir reglas claras sobre qué decisiones de AI requieren revisión del gerente, cuáles requieren revisión legal y cuáles pueden proceder de manera autónoma. La versión individual es la capacidad del empleado para reconocer en qué situación se encuentra.
Un representante de servicio al cliente que recibe una sugerencia de respuesta generada por AI para una pregunta rutinaria sobre el estado de un pedido no necesita escalar. El mismo representante que recibe una respuesta generada por AI para una queja sobre la seguridad de un producto debe escalar. Conocer esa distinción no es obvio; requiere capacitación y un documento de política claro.
4. Conciencia de políticas
Entender las reglas de clasificación de datos de la organización y la lista de herramientas de AI aprobadas no es opcional. Es un requisito de cumplimiento, y no cumplirlo crea riesgo real.
El componente de conciencia de políticas de la alfabetización en AI incluye:
- Qué herramientas de AI están aprobadas para uso con qué categorías de datos
- Qué significa "datos sensibles" en su contexto (información personal identificable de clientes, datos financieros, planes estratégicos, hojas de ruta de productos no publicadas)
- Cuándo se le permite pegar datos en una herramienta de AI externa y cuándo no
- Qué hacer si no está seguro
La mayoría de los empleados que usan herramientas de AI no han sido informados sobre estas preguntas porque la política aún no existe, o existe pero no ha sido comunicada. Construir la alfabetización en AI requiere tener primero una política de uso de AI. Si no tiene una, Construyendo su Política de Uso de AI es el prerrequisito.
La conciencia de políticas no necesita ser complicada. Para la mayoría de los empleados, se reduce a una regla: no ponga datos en una herramienta de AI externa que no pegaría en un foro público. Ese no es un marco de cumplimiento completo, pero es un principio de inicio que previene la exposición inadvertida de datos más común.
Alfabetización en AI por nivel de rol
Los cuatro componentes son universales, pero la profundidad y el enfoque difieren por nivel.
Colaboradores individuales
El conjunto de competencias central es las bases de ingeniería de prompts más la verificación de outputs. Todo lo demás se construye sobre estos.
Los colaboradores individuales (ICs) usan AI principalmente como una herramienta de productividad. Están generando borradores, analizando conjuntos de datos, resumiendo documentos y a veces ejecutando tareas rutinarias de flujo de trabajo con asistencia de AI. Su superficie de riesgo es principalmente de calidad: output de AI de baja calidad que no detectan antes de que llegue a algún lugar que importa.
Objetivo de capacitación: cada IC puede escribir un prompt estructurado que consistentemente produce un output utilizable, sabe cuándo verificar antes de actuar y entiende qué herramientas están aprobadas para su rol.
Inversión de tiempo: 4-6 horas de capacitación inicial, actualización trimestral de 1 hora.
Gerentes
Los gerentes necesitan las competencias de IC más dos áreas adicionales: juicio de cuándo escalar y rediseño de flujos de trabajo para el trabajo asistido por AI.
Los gerentes necesitan el juicio de cuándo escalar porque están estableciendo normas de escalación para sus equipos. Si un gerente trata todo el output de AI como pre-verificado, su equipo también lo hará. Si un gerente verifica explícitamente las afirmaciones de AI antes de usarlas en reportes, su equipo ve ese comportamiento modelado.
El rediseño de flujos de trabajo es la habilidad específicamente gerencial: dado que su equipo ahora tiene productividad asistida por AI, ¿cómo reestructura el trabajo? ¿Cuál es el nuevo estándar de calidad para un primer borrador? ¿Quién revisa el output de AI antes de que salga al exterior? ¿Cómo mide la productividad cuando AI está haciendo parte del trabajo? Estas son preguntas de diseño de gestión que requieren alfabetización en AI para responder bien.
Objetivo de capacitación: los gerentes pueden rediseñar los flujos de trabajo del equipo en torno a las capacidades de AI, establecer normas de verificación apropiadas y explicar la política de escalación a sus reportes.
Inversión de tiempo: 6-8 horas de capacitación inicial, actualización trimestral de 2 horas.
Ejecutivos
Los ejecutivos necesitan todo lo anterior más la alfabetización estratégica en AI: la capacidad de tomar decisiones de inversión, gobernar el riesgo de AI y evaluar las capacidades de los proveedores sin entender la implementación técnica.
La alfabetización estratégica en AI incluye entender la diferencia entre las capacidades de AI (lo que el ACE Framework llama Ingest, Analyze, Predict, Generate, Execute) suficientemente bien como para evaluar si una inversión propuesta en AI coincide con las necesidades reales de la organización. Incluye la gobernanza del riesgo: saber qué decisiones de AI requieren supervisión ejecutiva, cuál es la exposición de responsabilidad de la organización por errores de AI en contextos de cara al cliente y cómo evaluar las afirmaciones de ROI de AI honestamente.
Un ejecutivo que no distingue entre las capacidades Generate y Predict aprobará inversiones en AI que no coincidan con su caso de uso. Un ejecutivo que no puede evaluar las afirmaciones de ROI con el escepticismo adecuado comprará en exceso por promesas de proveedores o comprará de menos por temor a retornos no probados.
Objetivo de capacitación: los ejecutivos pueden hacer las preguntas correctas en las reuniones con proveedores, tomar decisiones de inversión en AI defendibles y gobernar el riesgo de AI sin delegarlo completamente al CTO.
Inversión de tiempo: taller de medio día, briefing trimestral sobre desarrollos de AI relevantes para el negocio.
El Estándar de Alfabetización en AI de 5 Componentes
El Estándar de Alfabetización en AI de 5 Componentes define la preparación organizacional en AI en cinco dimensiones medibles: competencia en ingeniería de prompts (prompts estructurados que producen output utilizable), hábito de verificación de outputs (hacer coincidir el esfuerzo de verificación con la consecuencia del error), juicio de escalación (saber qué outputs de AI requieren revisión humana antes de actuar), conciencia de políticas (entender las herramientas aprobadas y las reglas de clasificación de datos) y capacidad de rediseño de flujos de trabajo (para gerentes: reestructurar el trabajo del equipo en torno a la productividad asistida por AI). Una organización es alfabetizada en AI cuando los cinco componentes se practican activamente, no solo se capacitan.
Quotable: "Las organizaciones con programas formales de capacitación en AI logran una adopción de AI 2,3 veces más rápida y un ROI de AI un 67% mayor en comparación con las que dependen del aprendizaje informal o autodirigido." (OCDE)
Quotable: "La verificación de outputs es la brecha que causa el mayor daño real. La brecha de ingeniería de prompts es visible: los empleados que no saben cómo hacer prompts obtienen malos outputs y lo notan. La brecha de verificación de outputs es invisible: los empleados que confían en el output de AI, no lo verifican y actúan incorrectamente en base a él."
Quotable: "El 42% de los empleados dice que su empleador espera que aprendan AI por su cuenta, pero los empleados que no reciben capacitación formal en alfabetización en AI son significativamente más propensos a usar herramientas de AI para tareas de alta consecuencia sin verificación." (DataCamp 2026 AI Literacy Report)
| Nivel de Rol | Competencias Centrales | Profundidad Adicional | Inversión en Capacitación |
|---|---|---|---|
| Colaboradores individuales | Ingeniería de prompts + verificación de outputs | Conciencia de políticas | 4-6 horas inicial, 1 hora trimestral |
| Gerentes | Todas las competencias de IC | Juicio de escalación + rediseño de flujos de trabajo | 6-8 horas inicial, 2 horas trimestral |
| Ejecutivos | Todas las competencias de gerentes | Evaluación de inversiones en AI + gobernanza del riesgo | Taller de medio día, briefing trimestral |
Rework Analysis: Basado en patrones de programas de alfabetización en AI empresarial, las organizaciones que construyen la verificación de outputs como una competencia distinta con nombre explícito (en lugar de incorporarla en la "ingeniería de prompts") ven tasas significativamente menores de errores generados por AI que llegan a stakeholders externos. Los programas que funcionan tratan la verificación como un hábito a construir, no como una advertencia que se menciona una vez en una presentación de capacitación.
Opciones de formato de capacitación

Tres formatos, cada uno con compensaciones reales.
La práctica en el trabajo es la más económica y a menudo la más efectiva para las personas que ya están motivadas. Dé a los empleados acceso a herramientas de AI aprobadas, una biblioteca de prompts estructurada para sus casos de uso más comunes y un ciclo de retroalimentación donde puedan compartir ejemplos de output de AI que los sorprendió. La limitación: no funciona bien para empleados escépticos o ansiosos. La práctica asume disposición para intentarlo. Un programa obligatorio en el trabajo para un gerente de cuentas de 52 años poco dispuesto produce frustración, no alfabetización.
Los programas estructurados han sido desarrollados por proveedores incluyendo Section School (AI for Business, ampliamente utilizado para capacitación a nivel de IC), CoreLabs (certificación de AI en el lugar de trabajo con pistas específicas por rol) y Microsoft AI Skills Initiative (integrado con despliegues de Microsoft 365 Copilot). Estos son útiles para las competencias centrales porque crean un vocabulario compartido y una línea base. La limitación: son genéricos, y lo genérico no cubre las herramientas, políticas o normas de escalación específicas de su organización. Funcionan mejor como punto de partida que usted personaliza con su capa de política interna.
La capacitación proporcionada por proveedores está disponible de Anthropic (currículo AI Fluency), Google (Grow with Google AI) y Microsoft (programas de adopción de Copilot). Estos son específicos de la herramienta y frecuentemente gratuitos o de bajo costo. Son excelentes para la verificación de outputs y la ingeniería de prompts dentro de la herramienta específica. La limitación: no cubren la política de la organización, el marco de escalación ni la conciencia entre herramientas.
La recomendación práctica: use un programa estructurado (Section School o CoreLabs) para las competencias centrales a nivel de IC, superponga el contenido de política específico de su organización encima y use la capacitación del proveedor para la incorporación específica de la herramienta. No intente construir todo desde cero.
Estructura de incorporación de 4 semanas:
- Semana 1: Conceptos básicos de AI y resumen de herramientas aprobadas (enfoque en conciencia de políticas)
- Semana 2: Práctica de ingeniería de prompts con ejemplos específicos del rol (práctico)
- Semana 3: Ejercicios de verificación de outputs usando ejemplos reales de sus flujos de trabajo
- Semana 4: Escenarios de cuándo escalar y diseño de flujos de trabajo del equipo
Actualización trimestral: Sesión de 60 minutos que cubre un ejemplo real de la organización de output de AI que requirió corrección, más cualquier actualización de política o nuevas aprobaciones de herramientas.
La brecha de alfabetización que la mayoría de las organizaciones subestima
La verificación de outputs es la brecha que causa el mayor daño real, y es la que la mayoría de las organizaciones omiten en sus programas de capacitación en AI porque no se siente urgente. La investigación de McKinsey sobre prioridades de actualización de habilidades para la era de GenAI encuentra que la mayoría de las empresas gasta desproporcionadamente en programas de alfabetización que son visibles y fáciles de medir, mientras invierten insuficientemente en la calidad de adopción, que es donde viven la verificación de outputs y el juicio de escalación.
La brecha de ingeniería de prompts es visible: los empleados que no saben cómo hacer prompts obtienen malos outputs y lo notan. Se quejan de la herramienta o dejan de usarla. Esa retroalimentación crea presión para capacitar.
La brecha de verificación de outputs es invisible: los empleados que no verifican obtienen malos outputs, no lo notan y actúan en base a ellos. Envían información incorrecta a un cliente. Usan una estadística fabricada en una presentación ante el directorio. Toman una decisión basada en un análisis de AI que interpretó incorrectamente los datos. El error aparece más tarde, frecuentemente sin un rastro claro de vuelta a la herramienta de AI.
La causa raíz de la mayoría de los errores de flujos de trabajo de AI en las organizaciones son los empleados que confían en el output de AI sin el hábito de preguntar "¿es esto realmente correcto?" Construir ese hábito requiere capacitación explícita que nombre el problema directamente: AI genera respuestas incorrectas que suenan seguras, y usted necesita saber cuándo verificar.
Cómo medir la alfabetización en AI
¿Cómo sabe cuándo la organización está suficientemente alfabetizada en AI?
Los indicadores adelantados funcionan mejor que las tasas de finalización de certificaciones, que miden la asistencia, no la competencia.
La tasa de adopción de herramientas indica si los empleados están usando las herramientas en absoluto. La baja adopción a los 90 días después de la capacitación sugiere una barrera de flujo de trabajo (la herramienta no está integrada en cómo la gente realmente trabaja) o una barrera de habilidades (la probaron, obtuvieron un output deficiente y pararon). Distinga entre estas antes de intervenir.
La tasa de incidentes es la tasa a la que los errores generados por AI llegan a stakeholders externos (clientes, socios). Rastréelos por separado de los errores internos. Los incidentes de AI externos son los que tienen consecuencias reales y los que más justifican la inversión en capacitación de verificación de outputs. El Registro de Riesgos de AI: Qué Rastrear proporciona el formato de seguimiento de incidentes, incluyendo cómo puntuar el riesgo de alucinación por tipo de sistema de AI.
La calidad de prompts es evaluable mediante muestreo. Tome 20 prompts que los empleados enviaron a herramientas de AI la semana pasada (con el manejo de privacidad adecuado) y evalúelos frente a los criterios de prompt estructurado de la capacitación. Un equipo donde el 70% o más de los prompts incluyen contexto e instrucciones de output específicas ha absorbido la capacitación. Un equipo donde el 80% o más de los prompts son solicitudes vagas de una línea no lo ha hecho.
El comportamiento de escalación puede medirse como la proporción de outputs de AI revisados antes del uso externo versus los outputs totales generados. Esta es una métrica proxy: puede rastrearla mirando los pasos del flujo de trabajo donde la revisión está documentada, pero requiere incorporar el paso de revisión en el flujo de trabajo en lugar de dejarlo como opcional.
Una organización es alfabetizada en AI cuando los empleados pueden distinguir cuándo usar AI versus cuándo no, saben cómo hacer prompts suficientemente bien para obtener un output utilizable, verifican los outputs cuando importan y entienden qué herramientas están permitidas para qué datos. Ese es un estándar alcanzable. La mayoría de las organizaciones aún no están ahí, pero la mayoría puede llegar en seis meses con un programa deliberado.
Para contexto sobre cómo la alfabetización en AI se conecta con el diseño de roles, consulte Evolución de Roles con AI: Qué Cambia y Para Quién. La conversación más difícil sobre por qué los empleados están ansiosos sobre AI en primer lugar está en El Miedo al Reemplazo: El Tema Incómodo, la lectura complementaria que muchos líderes necesitan antes de iniciar un programa de alfabetización.
La política fundamental que los empleados deben entender antes de que la capacitación en alfabetización pueda afianzarse se cubre en Construyendo su Política de Uso de AI. Y porque un empleado que teme que su trabajo está desapareciendo no se involucrará honestamente con la capacitación en AI independientemente de qué tan bien esté diseñado el currículo, Comunicando los Cambios de AI a los Empleados cubre cómo tener esa conversación primero. Hágalo antes del programa de alfabetización, no después.

Co-Founder, Rework.com
On this page
- Los cuatro componentes de la alfabetización en AI
- 1. Bases de ingeniería de prompts
- 2. Verificación de outputs
- 3. Juicio de cuándo escalar
- 4. Conciencia de políticas
- Alfabetización en AI por nivel de rol
- Colaboradores individuales
- Gerentes
- Ejecutivos
- El Estándar de Alfabetización en AI de 5 Componentes
- Opciones de formato de capacitación
- La brecha de alfabetización que la mayoría de las organizaciones subestima
- Cómo medir la alfabetización en AI