ステージ2から3へ:パイロットからスケールへ、パイロット煉獄からの脱出
Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
AIパイロットは成功した。ユーザーは気に入っている。初期の数字は有望だ。SDRチームはメール個別対応で週3時間の削減を実現し、返信率は12%向上した。パイロット担当者が成果を報告する。経営幹部は頷く。
そして誰かが問う。「これをどうスケールさせるのか?」
突然、誰も答えを知らない。
これがパイロット煉獄(Pilot purgatory)だ。「パイロットが成功した」と「AIが本番稼働している」の間に存在する空間であり、多くのステージ2組織が立ち往生する場所だ。時には1年、時にはそれ以上。Forresterはユースケースの無秩序な拡散をAIスケールの最大障壁の一つと特定している。企業は数十のパイロットを持ちながら、それらを優先順位付けして本番化するフレームワークを持っていない。予算を待ちながら、所有権を巡って議論しながら、あるいは本番化に必要なコミットメントを避けるために別のパイロットを立ち上げながら、パイロットは宙吊り状態のまま放置される。
パイロット煉獄が発生する理由を理解することが、そこから抜け出す第一歩だ。まだステージ1にいるなら、先にステージ1から2へ:Ad-HocからPilotへを読んでほしい。
パイロット煉獄の実態
主要データ:パイロットからスケールへの課題
- Forresterは、ユースケースの無秩序な拡散をAIスケールの最大障壁の一つと特定している。企業は数十のパイロットを持ちながら、本番化のフレームワークを持っていない(Forrester、2025年)
- AIをスケールした企業(ステージ3以上)は、AIで遅れをとる企業と比べて3年間の株主総利回りが約4倍高い。ステージ2での遅延が長くなるほど、リーダーとラガードの差は拡大する(BCG、2025年)
- McKinseyは、AIパイロットの成功から全社展開への移行には、スケーリングマインドセットの採用、AIアセット構築のモジュラーアプローチ、分析開発ライフサイクルの短縮が必要であり、これらはほとんどのパイロット段階チームが実行できる体制にないと指摘している(McKinsey、2025年)
パイロット煉獄には一貫した症状がある。
12カ月以上パイロットのままのプロジェクト。 チャーターで設定された期限が来ても去っても、スケールを明示的に決断する者がいない。パイロットを明示的に中止する者もいない。低いボリュームで稼働し続け、本番規模の価値を生み出さないまま工数だけを消費する。
同時進行する複数のツール評価。 一つのツールにコミットしてスケールするのではなく、2つか3つの代替案の評価を開始する。「正しいものを選ぶことを確認したい」。18カ月後もまだ選べていない。
「もう一つのデータポイント」を待つ経営幹部。 パイロットは良い結果を出したが、経営幹部はコミットする前に、より大きなサンプルサイズ、より長い期間、またはより複雑なユースケースを求める。基準は動き続ける。
インフラの意思決定が行われていない。 パイロットはベンダーが管理するクラウド設定で動いており、会社からのアーキテクチャ的コミットメントはなかった。スケールにはデータストレージ、モデルホスティング、API所有権、モニタリングについての意思決定が必要だが、誰もまだ決めていない。
パイロットチームが疲弊している。 パイロットを運営した同じ3人が、次の2つのパイロットの運営と最初のパイロットのスケール方法の検討も求められている。過負荷で、体制が整っておらず、離脱し始めている。McKinseyの分析では、AIパイロットの成功から効果的な全社展開への移行には、スケーリングマインドセット、AIアセット構築のモジュラーアプローチ、分析開発ライフサイクルの短縮が必要であり、疲弊した3人チームには実行できない。
これらのうち2つ以上が当てはまるなら、パイロット煉獄にいる。脱出には、さらなる評価ではなく実行規律が必要だ。
「ステージ2から3への移行が最も多く失敗するのは、パイロットが間違っていたからではなく、チームが本番デプロイをパイロットの拡大版として扱うからだ。それは違う。本番にはインフラへのコミットメント、ボランティアを超えた変革管理、コストガバナンス、そして指名されたAI Operations責任者が必要だ。ステージ2のインフラでステージ3を運営する企業は、インシデント、コスト超過、採用崩壊に直面する。」(Rework)
ステージ2から3への移行テスト(Stage 2-to-3 Crossing Test)
組織がステージ2からステージ3に本当に移行したことを確認する4要件の診断ツール。スケールしたパイロットを本番と言い換えただけではないことを確かめる。要件1:一つのユースケースが、ボランティアコホートではなく、意図したすべてのユーザーに対してモニタリング付きで本番デプロイされている。要件2:共有インフラの意思決定が文書化されコミットされている(モデルプロバイダー、ベクターデータベース、オブザーバビリティスタック)。ユースケースごとのアドホックな判断ではない。要件3:2つ目のユースケースが、要件2のインフラを基盤として使用したアクティブなパイロット段階にある。要件4:本番システムの稼働率、インシデント、モデルバージョニングに対して明確な責任を持つ、指名されたAI Operations責任者が存在する。要件1のみを満たす組織はスケールしたパイロットを運営しているのであり、ステージ3のデプロイメントではない。
ステージ3の達成要件
ステージ3は単に「より多くのパイロット」ではない。質的に異なる運営姿勢だ。それを主張するには以下がすべて真である必要がある。
| 要件 | 意味すること | よくあるギャップ |
|---|---|---|
| 一つのユースケースが本番稼働 | ボランティアコホートではなく、すべての対象ユーザーにデプロイ。モニタリング付きのフルロールアウト | 「適切な」ユーザーのみを対象にパイロット規模で運営中 |
| 共有インフラの意思決定完了 | ベクターデータベース、モデルプロバイダー、ガードレールツール、オブザーバビリティスタック:選択されコミットされている | パイロットのアドホックなインフラをそのまま使用。各ユースケースが別々のベンダースタックで稼働 |
| 2つ目のユースケースがアクティブなパイロット段階 | パイロット1の学びがパイロット2に転用された証拠。計画中ではなく、実際に稼働中 | すべてのエネルギーがパイロット1のスケールに消費され、新しいユースケースへの余力なし |
| AI Operations責任者の存在 | 本番AIシステムの責任を持つ指名された個人または小チーム:稼働率、インシデント対応、モデルバージョニング | パイロット担当者が通常業務と並行して本番を運営し続けている |
ステージ3を名乗る前に、4つの要件がすべて真である必要がある。最も頻繁に省略されるのは共有インフラだ。そしてそれを省略した場合に最も高額な問題が発生する。
ステージ3が必要とするインフラの意思決定
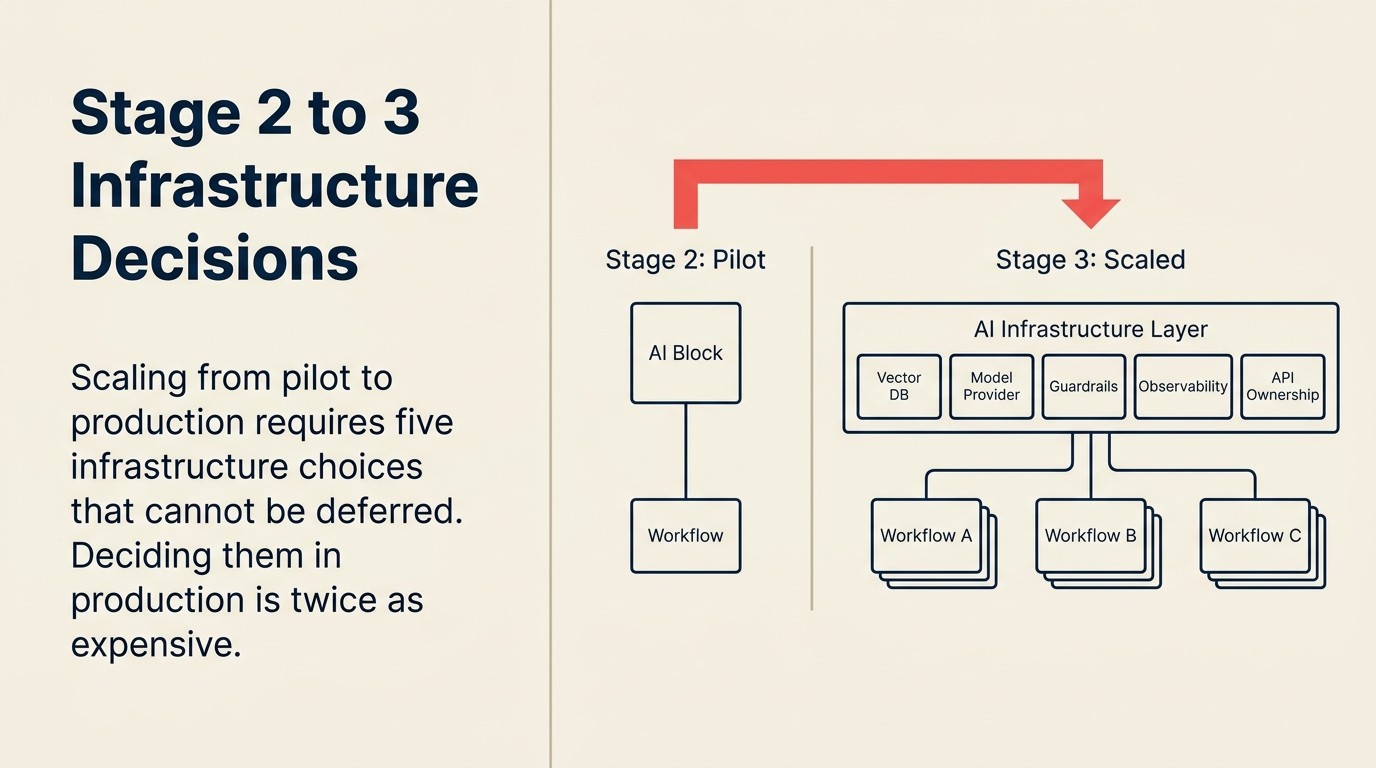
これはSaaS製品の導入背景を持つ多くのトランスフォーメーション責任者が驚く部分だ。本番規模のAIには、通常のSaaSツールには適用されないアーキテクチャ上のコミットメントが必要だ。これらの決定はスケール後ではなく、スケール前に行う必要がある。
ベクターデータベースの選択。 AIアプリケーションがRAG(検索拡張生成)、社内文書検索、またはインタラクション間のメモリを使用する場合、ベクターデータベースが必要だ。2026年の主要オプションはPinecone、Weaviate、Qdrant、そしてすでにPostgreSQLを使用しているチーム向けのpgvectorだ。何を選ぶかより、決断することの方が重要だ。異なるユースケースを異なるベクターストアで実行すると、後から解消するのにコストがかかる分断が生じる。
モデルプロバイダーの意思決定。 どのLLM(大規模言語モデル)プロバイダーを標準化するか。OpenAI、Anthropic、Google、またはその組み合わせか。エンタープライズ契約はそれぞれ異なる価格、データ取り扱い条件、パフォーマンス特性を持つ。パイロットでChatGPT無料プランを使うのは問題ない。本番ワークロードには、データ処理契約(DPA)とSLAコミットメントを含む適切なエンタープライズ契約が必要だ。
ガードレールツール。 スケールした状態で、AIが有害、不正確、またはブランドに反するアウトプットを生成することをどう防ぐか。パイロット段階では人間がすべてのアウトプットを確認する。本番規模ではそれは不可能だ。ガードレールはモデル呼び出しの前後処理レイヤーとして実行される。カスタムプロンプトエンジニアリングから、Guardrails AIやLlamaIndexのセーフティレイヤーのような専用ツールまでオプションは様々だ。
オブザーバビリティスタック。 AIが壊れたことをどうやって知るか。パイロット規模ではパイロット担当者が気づく。本番規模ではロギング、アラート、ダッシュボードが必要だ。重要な指標は:レスポンスレイテンシ、エラーレート、フォールバックレート、人間によるレビュートリガー。これは多くのチームが本番インシデント後に初めて必要性を発見するインフラコンポーネントだ。
APIの所有権とレートリミット。 モデルプロバイダーのAPIキーは誰が所有するか。パイロット段階ではパイロットをセットアップした人が持っている可能性が高い。本番規模では、コストスパイクを防ぐためのレートリミットとセキュリティのためのローテーションポリシーを持つ、ITが管理するサービスアカウントが必要だ。
これらはIT部門単独の決定ではない。その後に構築するすべてのAIユースケースに影響するアーキテクチャ上のコミットメントだ。スケール前に共同で決定することで、何カ月もの手直しを節約できる。
本番デプロイのチェックリスト

「本番に移行する」という言葉は、チームによって異なる意味を持つ。AIシステムにとって、本番には具体的な意味がある。以下の8つが真である必要がある。
1. モニタリングが稼働中。 「時々確認する」ではなく、エラーレートの急増、レイテンシの低下、異常なアウトプットパターンに対するアラートを伴うアクティブなモニタリング。
2. フォールバックロジックが存在する。 AIが失敗した場合(モデルタイムアウト、ガードレールトリガー、レートリミット)、何が起きるか。ユーザーに空白画面や生のエラーメッセージを見せてはならない。フォールバックを定義する:キャッシュされたアウトプットを表示、人間によるレビューのためにキュー、適切に拒否する。
3. 人間の承認ゲートが定義されている。 どのアウトプットが行動前に人間のレビューを必要とするか。AI が作成した対外コミュニケーションについては、人間が送信前にレビューするか(必須)、送信後にレビューするか(遅すぎる)を定義する。このルールをゴーライブ前に設定する。
4. モデルバージョニングが追跡されている。 モデルプロバイダーがモデルを更新すると、アウトプットが変化する可能性がある。説明のつかないアウトプット変化を診断できるよう、どのモデルバージョンがいつ稼働していたかの記録が必要だ。
5. インシデント対応が存在する。 AIが顧客に誤った情報を送信した場合、誰に連絡するか。どの順番で。解決のSLAは何か。必要になる前にランブックを書く。
6. ユーザーへのコミュニケーションが完了している。 すべての対象ユーザーがAIが本番で稼働していることを認識し、何をするかを理解し、アウトプットのレビュー、修正、エスカレーション方法について研修を受けている。
7. コストモニタリングが稼働中。 本番AIワークロードは予期しないコストスパイクを生成することがある。トークン消費量、API呼び出し量、モデル選択はすべてコストに影響する。誰かが月次コストレポートを管理している。
8. データ処理契約が締結されている。 AIが個人データや社外秘データを処理する場合、ベンダーのDPAを本番前に締結する必要がある。「スケール後にDPAを追加する」はバックログアイテムではなくコンプライアンス違反だ。
このチェックリストが「デプロイ済み」と「本番」の違いだ。ほとんどのチームは8つのうち5つをクリアする。省略する3つがインシデントを引き起こすものだ。
変革管理のスケール:ボランティアから全員へ
パイロットはボランティアで動く。パイロットコホートにいる人たちは手を挙げた人たちだ。AIに好奇心があり、実験に積極的で、荒削りな部分を許容できる人たちだ。彼らは全ユーザー集団の代表的なサンプルではない。
本番規模はすべての人を対象とする。そして「すべての人」には懐疑論者、時間のない人、「これは楽になるどころか仕事が増える」と思う人、そしてAIが自分の仕事をうまくやれば自分の仕事がなくなると密かに心配している人が含まれる。
ここがステージ2から3への移行が最も頻繁に停滞する場所だ。パイロットは志願した20人のSDRで機能した。フルチームには80人のSDRがいて、そのうち30人は5年間この仕事をしており、ワークフローの変更に積極的ではない。
ステージ3の変革管理の実践方法は4つある。
ツールではなく、新しいワークフローのためのトレーニング。 従業員はツールに抵抗するが、ワークフローの改善は受け入れる。「AIツールトレーニング」を実施しない。たまたまAIツールを含む「新しいSDRワークフローウォークスルー」を実施する。変更前後を見せ、時間の節約を可視化する。
懐疑論者に安全な入口を与える。 まず採用を義務化せず、任意で使用できるようにする。同僚がより良い結果を出しているという社会的証明は、経営幹部からの指示よりも説得力がある。
恐れを正面から扱う。 「AIに置き換えられるか」という懸念を明示的に口にしなければ、ロールアウトに関するすべての非公式な会話を支配するだろう。全社会議でそれを言葉にする。役割の進化を説明する:AIが処理すること、人間にしかできないこと。具体的に。曖昧さは恐れを悪化させる。
アウトカムだけでなく採用状況を測定する。 実際にAIワークフローを毎日使用しているユーザーは何人か。毎週は。まったく使っていない人は。ビジネスアウトカムと同じ真剣さで採用指標を追跡する。低い採用率はパフォーマンス不足の結果を説明するものであり、早期に発見すれば修正可能だ。
ステージ3のガバナンス:ドラフトから機能へ
ステージ2では最低限のポリシーがあった。ステージ3では複数のユースケースにわたってAIが本番稼働している。ガバナンスの要件はそれに応じて拡大する。
ツール承認機能。 誰かが新しいAIツールのリクエストを審査し、データ分類フレームワークを適用し、承認を発行する。委員会ではなく、プロセスと対応時間を持つ一人の人間。
インシデント所有権。 本番AIインシデントが発生した場合(誤ったアウトプット、データ漏洩、モデル障害)、誰が解決の責任を持つか。ステージ3では、これは指名された役割だ:AI Operationsリードまたは相当者。共有メーリングリストではない。
四半期ごとのポリシーレビュー。 AIは速く動く。6カ月前の承認ツールリストには、データ取り扱い条件を変更したツールが含まれている可能性がある。カレンダーイベントを作成する:四半期ごとのレビュー、2時間、承認ツールリストとインシデントログ。
監査証跡のベースライン。 すべてのExecute機能を持つAIワークフロー(AIがシステム内でアクションを取る場合)については、AIが何をしたか、いつ、どのような結果かのログが必要だ。これはほとんどの法域で本番規模における法的およびコンプライアンス要件であり、何かが間違ったときのトラブルシューティングの基盤でもある。本番グレードの監査証跡が必要なものについては、AI Execute アクションの監査証跡を参照してほしい。
Rework分析: エンタープライズAIデプロイメントパターンに基づくと、本番インシデント後まで後回しにされることが最も多い3つのインフラ決定は、オブザーバビリティスタック(アウトプットが低下した原因を診断できないときに初めて必要性を発見する)、モデルプロバイダーとのデータ処理契約(法務がコンプライアンスの欠陥を指摘した際にデプロイ後に対処される)、そしてコストモニタリング(最初の予想外の請求書が届いたときに浮上する)だ。3つとも本番前に実装するのは低コストだ。インシデント後に後から組み込むのは高コストだ。この記事の本番デプロイチェックリストは、これら3つがゴーライブ前に対処されることを確実にするために、特定の順序で構成されている。
ステージ3でのROI再計算
パイロットは実現可能性を証明する。本番は経済性を証明する。これらは異なる問いだ。
60日間で20人のユーザーが参加し、週3時間を節約するパイロットは、年換算でこのように見える:20ユーザー×3時間×48週=年間2,880時間の節約。完全負荷コストを1時間あたり5,000円とすると、年換算で1,440万円の労働価値だ。
しかし、そのAIを本番で実行するのに実際にいくらかかるか。モデルAPIコスト、AI Operationsチームの工数、インフラコスト、モニタリングオーバーヘッド。年間総保有コストが400万円なら、ROIは1,040万円純利益だ。明確なビジネスケースだ。
ステージ3のスケーリングコミットメント前にこの計算を行う。そして実際の数字を使う。パイロット段階のベンダー価格ではなく。モデルプロバイダーに予想トークン量での本番価格を尋ねる。AI Operations採用者に工数コストを尋ねる。予期しないオーバーヘッドのために20%を追加する。
ROI測定の全フレームワーク(重要な側面:節約された時間、コスト削減、品質改善、収益インパクト)については、AI ROIの証明が困難な理由を参照してほしい。
ステージ2から3への実例
200人規模のSaaS企業が2025年第3四半期にAIサポートエージェントで成功したパイロットを実施した。パイロットは、AIが人間の関与なしに受信サポートチケットの35%を解決でき、サポートエンジニア1人あたり週15時間を解放することを示した。
スケール前に3つのインフラ決定を行った:モデルプロバイダーをOpenAI Enterpriseに標準化、サポートナレッジベース用ベクターデータベースとしてPineconeにコミット、オブザーバビリティのためにLangSmithをデプロイした。
2025年第4四半期にAI Operationsリードを採用した。その人物が本番デプロイチェックリストを管理し、ユーザートレーニングを実施し、インシデントランブックを作成し、コストモニタリングダッシュボードを設定した。
2026年第1四半期までに、AIサポートエージェントはサポートチームフル体制に向けて本番稼働した。並行して、パイロット2を開始した:CRM内で通話サマリーと次のステップの推奨事項を直接作成するAI Sales Operationsアシスタントだ。そのパイロットは今まさに稼働中であり、パイロット1のインフラが基盤となっている。
5つのパイロットを並行して実施しなかった。一つを適切に実施し、インフラをコミットし、その基盤を次のパイロットに活用した。それがステージ2から3への移行の正しいやり方だ。
次のステップ
本番デプロイがステージ3だ。ステージ4への移行は一桁違う規模感だ:ワークフローの上にAIを重ねるのではなく、コアオペレーティングモデルにAIが織り込まれている状態だ。ほとんどの中堅企業はあと2~3年はステージ4の準備ができていないだろう。
しかしステージ4が何を必要とするかを理解することで、ステージ3での正しい投資が可能になる。単にツールをスケールしているのではない。ステージ4が依存するインフラとガバナンスを構築している。その投資は将来に複利で効いていく。
ステージ3から4へ:ScaledからIntegratedへで、組織的およびアーキテクチャ上の要件を確認してほしい。
AIマチュリティの5ステージでフルマチュリティモデルとステージ3の位置づけを確認してほしい。
最初の本番デプロイ前にAIインシデント対応プレイブックを読んでほしい。必要になる前に準備しておくべきものだ。
関連記事:
- AIトランスフォーメーションの正直なコスト:ステージ3のインフラ投資をビジネスケースに対してモデル化
- 多年度ロードマップでのAIパターンのシーケンシング:パイロット1成功後の2つ目と3つ目のユースケースの優先順位付け方法
