Playbook de Respuesta a Incidentes de AI: Cómo Responder Cuando la AI Falla

Turn this article into takeaways for your work.
Each assistant summarizes the article only for you and suggests best practices for your work.
Un chatbot de AI le dice a un cliente que se le debe un reembolso que no le corresponde. Un resumidor de AI omite una cláusula contractual crítica durante una revisión de due diligence, y la omisión no se detecta hasta después de firmar. Un modelo de puntuación de leads de AI empieza a enrutar a sus prospectos de mayor valor hacia los representantes incorrectos, y nadie lo nota durante tres semanas.
Estos son incidentes de AI. Y son diferentes de los incidentes de IT que su equipo ya sabe cómo manejar.
¿Su proceso de respuesta a incidentes conoce la diferencia? Si no, responderá demasiado lentamente a las señales incorrectas, escalará las cosas equivocadas y perderá los problemas que están afectando silenciosamente cientos de decisiones antes de que nadie lo note.
Este playbook es para CIOs, líderes de seguridad y equipos de transformación que construyen su primera capacidad de respuesta a incidentes específica de AI, o que auditan si su proceso existente es adecuado. Se conecta con Cómo Construir su Política de Uso de AI (que define el alcance autorizado de AI) y Trazas de Auditoría para Acciones Execute de AI (que proporciona la base de evidencia para la investigación).
Cómo los incidentes de AI difieren de los incidentes de IT

Key Facts: Riesgo de Incidentes de AI
- GDPR Article 33 requiere notificación a la autoridad supervisora relevante dentro de las 72 horas de tener conocimiento de una violación de datos personales; el reloj de 72 horas comienza cuando la organización toma conocimiento, no cuando la investigación está completa (GDPR Article 33)
- Las categorías de incidentes de AI incluyen alucinación, error de Execute, sesgo, exposición de datos y drift del modelo; la respuesta a incidentes de IT tradicional (construida en torno a fallos binarios arriba/abajo) pasa por alto la naturaleza latente y probabilística de los fallos de AI que pueden afectar cientos de decisiones antes de ser detectados (investigación del NIST Cybersecurity Framework)
- Gartner predice que más del 40% de los proyectos de AI agéntica serán cancelados para 2027, con los frameworks de gobernanza que no siguen el ritmo como la causa principal; la infraestructura de respuesta a incidentes es uno de los tres componentes de gobernanza más frecuentemente ausentes (Gartner, 2025)
La respuesta a incidentes de IT tradicional está construida en torno a un modelo simple: los sistemas están arriba o abajo. Un servidor se desconecta, un servicio devuelve un error 500, un enlace de red falla. El incidente es binario e inmediato. La detección es rápida, generalmente automatizada. La corrección es técnica: restaurar el servicio.
Los incidentes de AI no funcionan así. La función Respond del NIST Cybersecurity Framework describe la respuesta a incidentes como contener y gestionar los impactos de los eventos detectados, pero el CSF fue diseñado en torno a fallos técnicos binarios y detectables. Los incidentes de AI requieren un modelo de detección y respuesta significativamente diferente.
Son probabilísticos. Un sistema de AI que funciona "bien" la mayoría de las veces puede estar tomando decisiones incorrectas para un subconjunto específico de inputs: un segmento de clientes particular, un tipo de documento particular, un idioma particular. Las métricas de precisión generales lucen aceptables. La cola está fallando gravemente.
Son latentes. Un modelo de puntuación sesgado, una base de conocimiento alucinante, una vulnerabilidad de inyección de prompts, estos pueden operar durante semanas o meses antes de que alguien lo note. La analogía en IT sería un servidor que corrompe datos silenciosamente el 3% del tiempo en lugar de fallar por completo.
A menudo son invisibles hasta que son de consecuencia. Una AI que envía información incorrecta a los clientes, toma decisiones discriminatorias en la contratación o filtra datos hacia un contexto de prompt no genera un error 500. Puede generar una queja de cliente, una consulta de un regulador o una llamada de un periodista. Este es uno de los modos de fracaso de gobernanza que descarrila transformaciones de AI bien financiadas.
La causa raíz es más difícil de encontrar. Los incidentes de IT tienen causas raíz técnicas: una mala configuración, un error de código, un fallo de hardware. Los incidentes de AI pueden resultar del comportamiento del modelo (el modelo siempre iba a fallar en este tipo de input), del diseño del prompt (el prompt es inconsistente en ciertos casos límite), de la calidad de los datos (los datos de entrenamiento o recuperación estaban incorrectos), de un fallo de integración (el output correcto se generó pero se ejecutó la acción incorrecta) o del comportamiento del usuario (los humanos comenzaron a usar la herramienta de una manera para la que no fue diseñada).
Cada tipo de causa raíz requiere una respuesta diferente.
"Los incidentes de AI no se anuncian con un error 500. Un modelo de puntuación sesgado puede operar durante meses antes de que alguien lo note. Una AI que envía información incorrecta a los clientes no falla. Genera una queja de cliente. El proceso de respuesta a incidentes que funciona para interrupciones de IT perderá la mayoría de los fallos de AI hasta que se conviertan en crisis." (Rework)
La Taxonomía de Incidentes de AI de 4 Tipos
Un framework de clasificación para categorizar los incidentes de AI por tipo de causa raíz, habilitando un diagnóstico más rápido y una respuesta más específica. Tipo 1 (Alucinación): la AI generó contenido factualmente incorrecto que se actuó sobre él. Tipo 2 (Error de Execute): la AI tomó una acción de consecuencia incorrectamente, con consecuencias en el mundo real. Tipo 3 (Sesgo): la AI tomó decisiones sistemáticamente discriminatorias que afectan a un subconjunto de población; mayor exposición regulatoria. Tipo 4 (Exposición de Datos): el input del prompt o el output de AI reveló información que debería haber estado protegida; puede activar la obligación de notificación de 72 horas de GDPR Article 33. Tipo 5 (Drift del Modelo): el rendimiento de la AI se ha degradado con el tiempo sin un único momento de fallo detectable; el tipo de incidente que se pasa por alto con mayor frecuencia. Cada tipo tiene una señal de detección distinta, un plazo de respuesta y un enfoque de investigación de causa raíz. Usar el protocolo de respuesta incorrecto para el tipo de incidente produce una resolución más lenta y puede pasar por alto problemas sistémicos.
Taxonomía de incidentes de AI
Antes de poder responder a un incidente de AI, necesita saber qué tipo de incidente tiene.
Tipo 1: Incidente de alucinación
La AI generó contenido factualmente incorrecto que se actuó sobre él. Un cliente recibió información incorrecta sobre su cobertura de póliza. Un agente de soporte usó una respuesta generada por AI para resolver incorrectamente un ticket. Un documento escrito por AI contenía citas fabricadas.
Señal de detección: queja del cliente, revisión interna de calidad, reporte del empleado, error del sistema posterior causado por actuar sobre información incorrecta.
Preguntas clave en la respuesta: ¿El output fue revisado antes de usarse? ¿Fue un caso aislado o el modelo consistentemente alucina en este tipo de pregunta? ¿Hay un cambio de prompt que lo resolvería?
Tipo 2: Error de Execute
La AI tomó una acción de consecuencia incorrectamente. Este es el tipo de incidente más urgente en tiempo, porque las acciones Execute cambian el estado del mundo. Reembolso incorrecto emitido. Correo electrónico enviado a la lista de destinatarios incorrecta. Registros de CRM actualizados con datos incorrectos. Flujo de trabajo activado que no debería haberse activado.
Señal de detección: queja del cliente, discrepancia en la conciliación financiera, error de proceso posterior, reporte del empleado.
Preguntas clave en la respuesta: ¿Puede revertirse la acción? Si es así, ¿quién está autorizado para revertirla y cómo? ¿Quién fue afectado? ¿La causa raíz está en el modelo de AI, la lógica del disparador o la integración entre el output de AI y el sistema externo?
Tipo 3: Incidente de sesgo
La AI tomó decisiones sistemáticamente discriminatorias. Un modelo de puntuación enrutó desproporcionalmente a candidatos de cierta demografía hacia el rechazo. Una AI adyacente al crédito rechazó solicitudes a diferentes tasas para clases protegidas. Una AI de contratación filtró candidatos basándose en factores correlacionados con características protegidas.
Señal de detección: auditoría demográfica de resultados, reporte del empleado, consulta del regulador, desafío legal de un individuo afectado.
Preguntas clave en la respuesta: ¿Cuánto tiempo estuvo operando el sistema con este sesgo? ¿Cuántos individuos fueron afectados? ¿Qué remediación se le debe a las partes afectadas? ¿Está este modelo aún en producción?
Este tipo de incidente tiene la mayor exposición regulatoria. El asesor legal debe involucrarse de inmediato.
Tipo 4: Incidente de exposición de datos
El input del prompt o el output de AI reveló información que debería haber estado protegida. La información del Cliente A apareció en la respuesta de AI del Cliente B. Los datos personales de un empleado se incluyeron en un contexto de prompt accesible para usuarios no autorizados. Los datos internos confidenciales se enviaron al sistema de AI de un proveedor que no estaba autorizado para recibirlos.
Señal de detección: queja del cliente de ver los datos de otro usuario, auditoría interna, reporte del empleado, alerta de monitoreo sobre infracciones de clasificación de datos.
Preguntas clave en la respuesta: ¿Qué datos fueron expuestos? ¿A quién? ¿Era PII, PHI, datos financieros o datos empresariales confidenciales? ¿Fue un evento único o un fallo sistemático?
Nota sobre GDPR Article 33: si la exposición involucró datos personales de residentes de la UE, puede tener una obligación de notificación de 72 horas a la autoridad supervisora relevante. Esto no es opcional. El reloj comienza cuando toma conocimiento del incidente, no cuando completa la investigación.
Tipo 5: Drift del modelo
El rendimiento de la AI se ha degradado con el tiempo sin que nadie lo haya notado. El modelo de puntuación que tenía una precisión del 78% en el primer trimestre está al 61% en el tercer trimestre. El sistema de recuperación que devolvía los documentos correctos ahora devuelve los desactualizados. La calidad de generación que era aceptable se ha degradado a medida que el modelo o el contexto de recuperación ha cambiado.
Señal de detección: métricas de monitoreo (si las ha construido), métricas de resultados empresariales (tasa de conversión de leads en descenso, satisfacción del cliente cayendo, calidad de resolución de tickets de soporte en declive), reportes de empleados de que la AI "no es tan buena como antes."
Este es el tipo de incidente que se pasa por alto con mayor frecuencia porque no hay un único momento de fallo. Se acumula.
El framework de respuesta de 4 niveles

Una vez que haya identificado el tipo de incidente, el nivel determina quién responde, con qué rapidez y qué sucede primero.
Nivel 4: Investigar
Criterios: Error interno del output de AI, sin exposición externa, sin impacto en el cliente aún. Una alucinación descubierta durante la revisión interna de calidad. Un output de Generate que era incorrecto pero no se actuó sobre él. Drift del modelo detectado por el monitoreo interno antes de que afectara los resultados.
Ventana de respuesta: 24 horas para la evaluación inicial.
Quién responde: El equipo responsable del sistema de AI. No se requiere escalamiento a menos que la evaluación revele exposición externa.
Acciones: Documente el incidente en el registro de riesgos de AI. Determine la causa raíz. Evalúe si el problema es sistémico o aislado. Implemente la corrección o solución alternativa. Programe revisión post-incidente.
Nivel 3: Contener
Criterios: Output incorrecto orientado al cliente que el cliente no actuó sobre él. Una respuesta de chatbot incorrecta pero el cliente no actuó sobre ella. Un borrador de correo con información incorrecta que se detectó antes de enviar.
Ventana de respuesta: 4 horas para la decisión de contención.
Quién responde: Líder del equipo más contacto de seguridad de IT. Notificación a la dirección (sin escalamiento al CIO a menos que se convierta en Nivel 2 o superior).
Acciones: Contenga el problema (deshabilite la función de AI afectada si sigue produciendo outputs incorrectos). Evalúe la amplitud: ¿fue afectado este cliente, o potencialmente otros? Documente. Determine si la comunicación proactiva con el cliente está justificada (generalmente no para el Nivel 3, a menos que el output incorrecto pudiera causar daño al cliente si actúa sobre él más tarde).
Nivel 2: Respuesta al incidente
Criterios: Error de Execute orientado al cliente, incidente de exposición de datos que ha sido contenido, alucinación sobre la que los clientes actuaron.
Ventana de respuesta: 1 hora para la respuesta inicial, gestión continua hasta la resolución.
Quién responde: CIO y líder de seguridad notificados dentro de la hora. Asesor legal en espera. Equipo de comunicaciones comprometido para la redacción de la notificación al cliente.
Acciones: Evalúe el impacto (cuántos clientes, qué datos, qué acciones tomadas). Contenga (deshabilite el flujo de trabajo afectado, revierta las acciones Execute donde sea posible). Plan de comunicación con el cliente: ¿los clientes afectados necesitan ser notificados? ¿Qué necesitan saber? Evaluación de notificación regulatoria: ¿constituye esto una violación notificable bajo GDPR Article 33? Documente todo en tiempo real.
Nivel 1: Crisis
Criterios: Exposición regulatoria confirmada o probable, impacto masivo en clientes, incidente de sesgo con individuos afectados, exposición de datos sensibles personales a escala.
Ventana de respuesta: Inmediata. El CEO y el Asesor General deben estar en el circuito dentro de la primera hora.
Quién responde: Liderazgo ejecutivo, asesor legal, comunicaciones externas, asuntos regulatorios si aplica.
Acciones: Decisión ejecutiva sobre si suspender el sistema de AI por completo pendiente de investigación. Asesor legal externo comprometido. Comunicación con clientes y reguladores redactada y revisada. Revisión post-crisis programada. Si hay datos personales de la UE involucrados y la violación es notificable, el reloj de 72 horas bajo GDPR Article 33 está corriendo.
GDPR Article 33 y requisitos de notificación
GDPR Article 33 requiere notificación a la autoridad supervisora relevante dentro de las 72 horas de tomar conocimiento de una violación de datos personales, a menos que la violación "sea improbable que resulte en un riesgo para los derechos y libertades de las personas naturales."
Un incidente de AI puede constituir una violación de datos personales si:
- Un sistema de AI procesó datos personales de una manera que resultó en divulgación no autorizada
- Un output de AI que contenía datos personales fue enviado a un destinatario no autorizado
- Un sistema de AI tomó una decisión automatizada usando datos personales de una manera que no fue divulgada a los interesados
- La inyección de prompts u otra explotación llevó a la exfiltración de datos
El reloj de 72 horas comienza cuando toma conocimiento de la violación, no cuando la investigación está completa. Puede enviar una notificación inicial que diga "somos conscientes de un incidente, la investigación está en curso" y complementarla más tarde. Esperar hasta que la investigación esté completa antes de notificar no es conforme.
Para organizaciones con sede en EE. UU. que operan en industrias reguladas, existen requisitos análogos: la Regla de Notificación de Violaciones de HIPAA para violaciones de PHI, las reglas de divulgación de ciberseguridad de la SEC para incidentes materiales de ciberseguridad, y las leyes estatales de notificación de violaciones.
Revisión post-incidente: análisis de causa raíz de AI
La revisión post-incidente para un incidente de AI sigue una estructura diferente a la revisión post-mortem estándar de IT.
Las revisiones post-mortem de IT preguntan: ¿qué fallo técnico causó la interrupción? Corrija el fallo técnico, restaure el servicio.
Las revisiones post-incidente de AI hacen cuatro preguntas:
¿Fue esto un fallo del modelo? ¿La AI produjo un output incorrecto porque el modelo subyacente estaba equivocado, alucinando o tenía un rendimiento deficiente en este tipo de input? Si sí: ¿qué cambios de prompt, mejoras de recuperación o actualizaciones del modelo evitarían la recurrencia? ¿Debería continuar usándose este modelo para este caso de uso?
¿Fue esto un fallo del prompt o del diseño? ¿La AI produjo un output incorrecto porque el prompt era ambiguo, la ventana de contexto era insuficiente o el flujo de trabajo no estaba diseñado para manejar este input? Si sí: esta es a menudo la causa raíz más corregible. Rediseñe la plantilla de prompt, añada validación de input o añada guardrails.
¿Fue esto un fallo de datos? ¿La AI produjo un output incorrecto porque los datos de recuperación estaban desactualizados, los datos de entrenamiento estaban sesgados o los datos de input estaban malformados? Si sí: la gobernanza de datos es la corrección, no el modelo.
¿Fue esto un fallo de integración? ¿La AI produjo el output correcto pero la integración entre el sistema de AI y el sistema Execute posterior falló? Si sí: la causa raíz de gobernanza de AI es menos importante que la corrección de ingeniería de integración. Pero también: ¿había un paso de revisión humana que debería haber detectado esto antes del Execute?
Documente la causa raíz en el registro de riesgos de AI. Actualice los documentos de gobernanza de AI relevantes. Si el incidente reveló una brecha en su diseño de revisión humana, corrija la brecha.
Construir la cultura de reporte
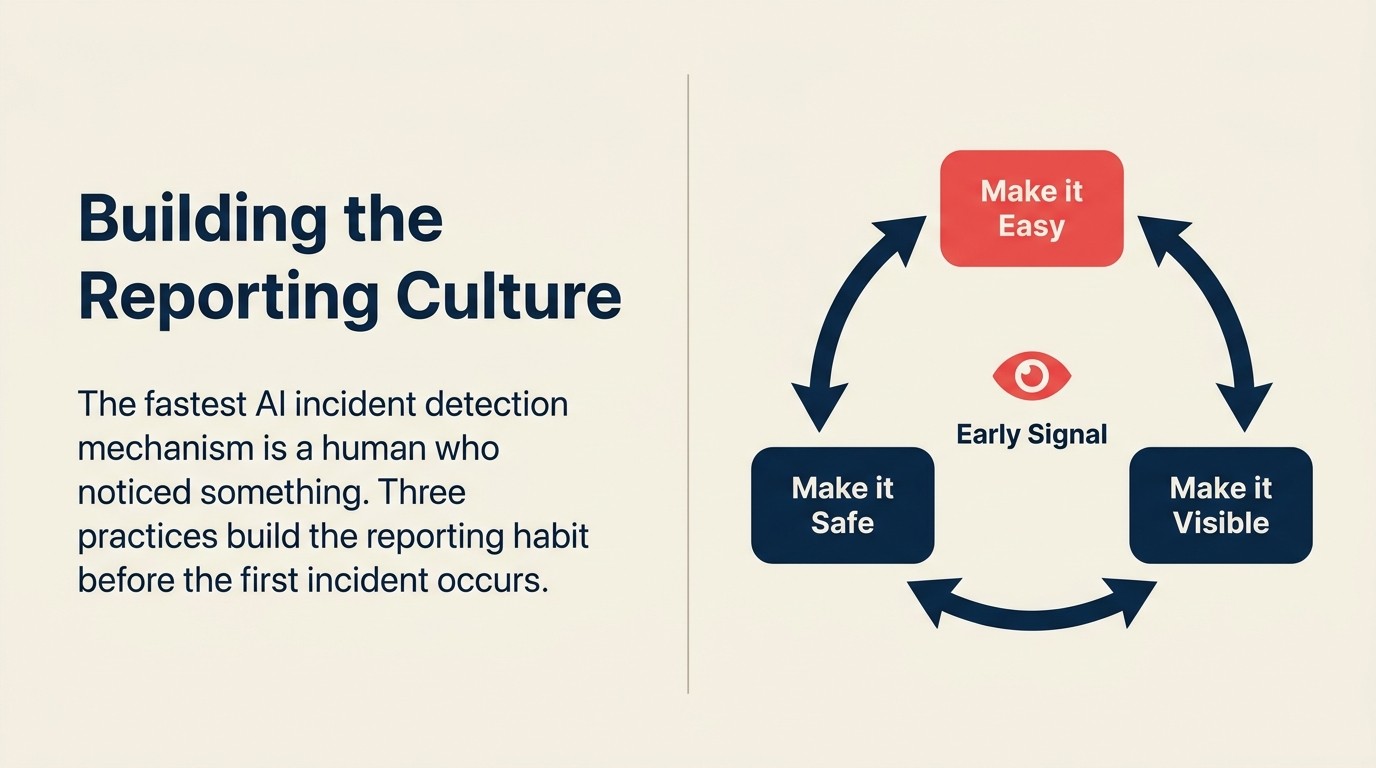
La brecha más peligrosa en cualquier programa de respuesta a incidentes de AI no es el playbook. Son los empleados que ven un problema y no lo reportan.
Un empleado que notó que el chatbot de AI estaba dando información incorrecta sobre reembolsos el martes pasado. Un ingeniero que vio un patrón anómalo en los registros de output de AI pero no estaba seguro de si importaba. Un gerente de éxito del cliente que escuchó una queja sobre una recomendación generada por AI pero la descartó como un caso aislado.
Cada uno de estos es una señal temprana. La mayoría de los incidentes de AI que se convierten en crisis comenzaron como señales que fueron vistas y no se actuó sobre ellas.
Construir una cultura de reporte significa tres cosas:
Haga el reporte fácil. Un canal interno, un formulario, una dirección de correo electrónico. Los empleados no deberían tener que navegar organigramas para reportar un posible problema de AI.
Haga el reporte seguro. Los empleados que reportan problemas no deben ser culpados por el incidente ni por generar una falsa alarma. La respuesta a un reporte, incluso si resulta ser un no-incidente, debe ser "gracias por señalarlo." Si los reportantes se sienten culpados, dejarán de reportar.
Haga el reporte visible. Cuando un reporte lleva a que se detecte un incidente genuino temprano, cuéntele al equipo. No "tuvimos un incidente importante" sino "porque alguien señaló una anomalía la semana pasada, detectamos un problema antes de que afectara a los clientes." La prueba social de que el reporte importa construye el hábito.
Los documentos de gobernanza, las trazas de auditoría y los niveles de respuesta existen para gestionar los incidentes después de que ocurran. La cultura de reporte es lo que determina si se entera de los problemas temprano o tarde.
Lo que este playbook no reemplaza
Este playbook rige la respuesta a incidentes específicos de AI. No reemplaza su proceso existente de respuesta a incidentes de IT, su proceso de respuesta a violaciones de datos bajo GDPR o CCPA, ni su proceso de RR. HH. para quejas relacionadas con discriminación. Esos procesos siguen aplicando. Para los incidentes que involucran tanto un fallo de AI como una violación de datos, ambos playbooks se ejecutan en paralelo.
Conecte este playbook con su framework de trazas de auditoría, que proporciona la evidencia que necesitará durante la investigación del incidente. Conéctelo con su política de uso de AI, que define el alcance autorizado de las acciones de AI. Y conéctelo con su registro de riesgos de AI, donde se documentan los patrones de riesgo conocidos de incidentes pasados para que los futuros incidentes se detecten más rápido.
Rework Analysis: Basado en los patrones de incidentes de AI empresarial, la razón más común por la que los incidentes de AI menores escalan a crisis no es el incidente en sí sino el retraso en la detección. Un incidente de sesgo que afecta al 15% de los outputs de un modelo de puntuación puede ejecutarse durante 8 a 12 semanas antes de aparecer en las métricas empresariales. Una exposición de datos en un contexto de AI compartido puede no surgir hasta que un cliente reporta ver los datos de otro usuario. La sección de cultura de reporte de este playbook existe porque el mecanismo de detección más rápido es un humano que notó algo y lo reportó. Cada semana de retraso en la detección compone la exposición regulatoria, el número de clientes afectados y la complejidad de la remediación.
El objetivo no es tener un playbook que nunca necesite usar. Es estar preparado cuando lo haga.
Y las empresas que ejecutan las respuestas a incidentes más limpias son las que construyeron la cultura de reporte mucho antes del primer incidente. Por lo que la pregunta real es: ¿sabe su equipo adónde ir cuando ve algo incorrecto?
Vea también:
- Puertas de Aprobación de AI y Revisión de Proveedores: la puerta previa al despliegue que reduce la frecuencia con la que necesitará este playbook
- Clasificación de Datos para Acceso de AI: el framework de niveles de datos que determina si un incidente de Tipo 4 requiere notificación de violación
- Etapa 3 a 4: De Escalado a Integrado: por qué la respuesta formal a incidentes se vuelve obligatoria en la Etapa 4
- La Agenda de AI del CEO en 18 Meses: dónde encaja la infraestructura de respuesta a incidentes en la Fase 1 de la hoja de ruta de transformación

Co-Founder, Rework.com
On this page
- Cómo los incidentes de AI difieren de los incidentes de IT
- La Taxonomía de Incidentes de AI de 4 Tipos
- Taxonomía de incidentes de AI
- Tipo 1: Incidente de alucinación
- Tipo 2: Error de Execute
- Tipo 3: Incidente de sesgo
- Tipo 4: Incidente de exposición de datos
- Tipo 5: Drift del modelo
- El framework de respuesta de 4 niveles
- Nivel 4: Investigar
- Nivel 3: Contener
- Nivel 2: Respuesta al incidente
- Nivel 1: Crisis
- GDPR Article 33 y requisitos de notificación
- Revisión post-incidente: análisis de causa raíz de AI
- Construir la cultura de reporte
- Lo que este playbook no reemplaza